
Abstract
The main promise of quantum computing is to efficiently solve certain problems that are prohibitively expensive for a classical computer. Most problems with a proven quantum advantage involve the repeated use of a black box, or oracle, whose structure encodes the solution. One measure of the algorithmic performance is the query complexity, i.e., the scaling of the number of oracle calls needed to find the solution with a given probability. Few-qubit demonstrations of quantum algorithms, such as Deutsch–Jozsa and Grover, have been implemented across diverse physical systems such as nuclear magnetic resonance, trapped ions, optical systems, and superconducting circuits. However, at the small scale, these problems can already be solved classically with a few oracle queries, limiting the obtained advantage. Here we solve an oracle-based problem, known as learning parity with noise, on a five-qubit superconducting processor. Executing classical and quantum algorithms using the same oracle, we observe a large gap in query count in favor of quantum processing. We find that this gap grows by orders of magnitude as a function of the error rates and the problem size. This result demonstrates that, while complex fault-tolerant architectures will be required for universal quantum computing, a significant quantum advantage already emerges in existing noisy systems.
Similar content being viewed by others
Introduction
The limited size of engineered quantum systems and their extreme susceptibility to noise sources have made it hard so far to establish a clear advantage of quantum over classical computing. Although the classical success probability has been exceeded in two-qubit demonstrations of the Deutsch–Jozsa1 and Grover2 algorithms, the required number of oracle queries has so far remained comparable. A promising avenue to highlight a quantum advantage is offered by a new family of algorithms designed for machine learning.3,4,5,6 In this class of problems, artificial intelligence methods are employed to discern patterns in large amounts of data, with little or no knowledge of underlying models. A particular learning task, known as binary classification, is to identify an unknown mapping between a set of bits onto 0 or 1. An example of binary classification is identifying a hidden parity function,7, 8 defined by the unknown bit-string k, which computes f(D,k) = D · k mod 2 on a register of n data bits D = {D 1,D 2…,D n } (Fig. 1a). The result, i.e., 0 (1) for even (odd) parity, is mapped onto the state of an additional bit A. The learner has access to the output register of an example oracle circuit that implements f on random input states, on which he/she has no control. Repeated queries of the oracle allow the learner to reconstruct k. However, any physical implementation suffers from errors, both in the oracle execution itself and in readout of the register. In the presence of errors, the problem becomes hard. Assuming that every bit introduces an equal error probability, the best known algorithms have a number of queries growing as 𝒪(n) and runtime growing almost exponentially with n.7,8,9 In view of the classical hardness of learning parity with noise (LPN), parity functions have been suggested as keys for secure and computationally easy authentication.10, 11

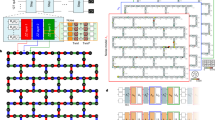
Implementation of a parity function in a superconducting circuit. a Conceptual diagram of parity learning. The (classical or quantum) oracle f ideally maps the parity of a subset of n data bits (or qubits), defined by the bit string k, into bit A. Repeated queries of the oracle allow the reconstruction of k by reading the output register. b Gate sequence implementing a quantum parity oracle with k = 11…1. Random examples are generated by preparing the data qubits {D 1,…,D n } in a uniform superposition. Vertical lines indicate CNOT gates between each D i (control) and the ancilla qubit A (target). Quantum learning differs from classical learning only by the addition of single-qubit gates (dashed boxes) applied before measurement (see also Supplementary Information). c Optical image of the superconducting quantum processor (qubits in red). A is coupled to each D i by means of two bus resonators (blue). Each qubit is also coupled to a dedicated resonator for control and readout (green)27
The picture is different when the oracle is implemented by a quantum circuit and the algorithm can process quantum superpositions of input states. In this case, applying a coherent operation on all qubits after an oracle query ideally creates the entangled state
In particular, when A is measured to be in |1〉, |D〉 will be projected onto |k〉. With constant error per qubit, learning from a quantum oracle requires a number of queries that scales as 𝒪(log n), and has a total runtime that scales as 𝒪(n).12 This gives the quantum algorithm an exponential advantage in query complexity and a super-polynomial advantage in runtime.
In this work, we implement a LPN problem in a superconducting quantum circuit using up to five qubits, realizing the experiment proposed in Ref. 12. We construct a parity function with bit-string k using a series of CNOT gates between the ancilla and the data qubits (Fig. 1b). We then present two classes of learners for k and compare their performance. The first class simply measures the output qubits in the computational basis and analyzes the results. The measurement collapses the state into a random {D, f(D , k)} basis state, reproducing an example oracle of the classical LPN problem. The second class performs some quantum computation (coherent operations), followed by classical analysis, to infer the solution. We show that, beyond a minimum complexity of the problem, the quantum approach outperforms the classical one. Furthermore, as the classical problem becomes rapidly intractable as noise is added to the output register, the performance gap widens.
Results
The quantum device used in our experiment consists of five superconducting transmon qubits, A, D 1, …, D 4, and seven microwave resonators (Fig. 1c). Five of the resonators are used for individual control and readout of the qubits, to which they are dispersively coupled.13 The center qubit A plays the role of the result and is coupled to the data register {D i } via the remaining two resonators. This coupling allows the implementation of cross-resonance (CR) gates14 between A (used as control qubit) and each D i (target), constituting the primitive two-qubit operation for the circuit in Fig. 1b (full gate decomposition in the Supplementary Information). Each qubit is measured by probing its respective readout resonator with a near-resonant microwave pulse. The output signals are then demodulated and integrated at room temperature to produce the homodyne voltages \(\{{V}_{{D}_{1}},\ldots {V}_{{D}_{n}},{V}_{A}\}\) (see Supplementary Information for the detailed experimental setup).
To implement a uniform random example oracle for a particular k, we first prepare the data qubits in a uniform superposition (Fig. 1b). Preparing such a state ensures that all parity examples are produced with equal probability and is also key in generating a quantum advantage. We then implement the oracle as a series of CNOT gates, each having the same target qubit A and a different control qubit D i for each k i = 1. Finally, the state of all qubits is read out (with the optional insertion of Hadamard gates, see discussion below). The oracle mapping to the device is limited by imperfections in the two-qubit gates, with average fidelities 88–94%, characterized by randomised benchmarking15 (see Supplementary Table S1). Readout errors in the register \({\eta }_{{D}_{i}}\), defined as the average probability of assigning a qubit to the wrong state, are limited to 20–40% by the onset of inter-qubit crosstalk at higher measurement power (see data in the Supplementary Information). A Josephson parametric amplifier16 in front of the amplification chain of A suppresses its low-power readout error to η A = 5%.
Having implemented parity functions with quantum hardware, we now proceed to interrogate an oracle N times and assess our capability to learn the corresponding k. We start with oracles with register size n = 2, involving D 1, D 2, and A. We consider two classes of learning strategies, classical (C) and quantum (Q). In C, we perform a projective measurement of all qubits right after execution of the oracle. This operation destroys any coherence in the oracle output state, thus making any analysis of the result classical. The measured homodyne voltages \(\{{V}_{{D}_{1}},\ldots {V}_{{D}_{n}},{V}_{A}\}\) are converted into binary outcomes, using a calibrated set of thresholds (see Methods). Thus, for every query, we obtain a binary string {a,d 1,d 2}, where each bit is 0 (1) for the corresponding qubit detected in |0〉 (|1〉). Ideally, a is the linear combination of d 1,d 2 expressed by the string k (Fig. 1a). However, both the gates comprising the oracle and qubit readout are prone to errors (see values in the Supplementary Information). To find the k that is most likely to have produced our observations, at each query m we compute the expected ã k,m = d m ·k mod 2 for the measured D = {d 1,d 2} m and the 4 possible values of k. We then select the k which minimizes the Hamming distance to the measured results a 1,…,a N of N queries, i.e., \({\sum }_{m=1}^{N}|{a}_{m}-{\tilde{a}}_{{\bf{k}},m}|\).7 In the case of a tie, k is randomly chosen among those producing the minimum distance. As expected, the error probability p of obtaining the correct answer decreases with N (Fig. 2a). Interestingly, the difficulty of the problem depends on k and increases with the number of k i = 1. This can be intuitively understood as needing to establish a higher correlation between data qubits when the weight of k increases.

Error probability p to identify a 2-bit oracle k as a function of the number of queries N. For both classical a and quantum b learners, one of the four oracles k is applied, followed by the simultaneous measurement of all qubits. Hadamard gates are applied prior to measurement in the quantum case (Fig. 1b). See text for a description of the solvers in the two scenarios. Inset: number of queries N 1%(k) required to reach 1% error for the classical (empty bars) and quantum (solid) solver
Our second approach (Q) takes advantage of the quantum correlations between ancilla and data qubits at the output of the oracle. Instead of directly measuring the qubits as above, we first apply a Hadamard gate on each. These local operations generate quantum interference between terms in the superposition state, ideally producing the desired result (Eq. (1)). This technique is widely used in quantum algorithms to increase the probability of obtaining the desired outcomes.17 In this case, whenever A is measured to be in |1〉 (with 50% probability), the data register will ideally be projected onto the solution, |D 1,D 2〉 = |k 1,k 2〉. We therefore digitize and postselect our results on the outcomes where a = 1 and perform a bit-wise majority vote on \({\{{d}_{1},{d}_{2}\}}_{1\ldots \tilde{N}}\). Despite every individual query being subject to errors, the majority vote is effective in determining k (Fig. 2b). We assess the performance of the two solvers by comparing the number of queries N 1% required to reach p = 0.01 (Fig. 2c). Whereas Q performs comparably or worse than C for k = 00, 01 or 10, Q requires less than half as many queries as C for the hardest oracle, k = 11. We note that, while these results are specific to the lowest oracle and readout errors we can achieve, a systematic advantage of quantum over classical learning will become clear in the following.
So far we have adhered to a literal implementation of the classical LPN problem, where each output can only be either 0 or 1. However, the actual measurement results are the continuous homodyne voltages \(\{{V}_{{D}_{1}},\ldots {V}_{{D}_{n}},{V}_{A}\}\), each having mean and variance determined by the probed qubit state and by the measurement efficiency.13 This additional resource can be exploited to improve the learner’s capabilities. A more effective strategy for C uses Bayesian estimation to calculate the probability of any possible k for the measured output voltages, and select the most probable (see Methods). This approach is expensive in classical processing time (scaling exponentially with n), but drastically reduces the error probability \(\overline{p}\), averaged over all k, at any N (Fig. 3). To improve on Q, we still postselect the oracle queries on the digitized outcome a = 1. Then, instead of digitizing the corresponding \(\{{V}_{{D}_{i}}\}\) as above, we digitize their averages \(\{\langle {V}_{{D}_{i}}\rangle \}\), obtaining our best guess for k (see Methods). This procedure simply replaces the majority vote between multiple noisy observations with a single observation, with variance reduced by the number of postselected queries. Using the analog results, not only does Q retain an advantage over C (smaller p for given N), but it does so without introducing an overhead in classical processing.

Learning error probability \(\overline{p}\) averaged over all the n-bit oracles k, for different n and solvers. a n = 2, b n = 3. Making use of the analog measurements \(\{{V}_{{D}_{1}},\ldots {V}_{{D}_{n}},{V}_{A}\}\) (squares) improves over the digital solvers in Fig. 2 (circles) for both classical (empty symbols) and quantum (solid symbols) learning. The analog solver in Q proves to be the most efficient solution. Moreover, the gap between Q and C grows with n. The same dataset is used in Figs 2 and 3, with D 3 ignored in the analysis for n = 2. See Supplementary Information for the p(N) corresponding to each 3-bit k
The superiority of Q over C becomes even more evident when the oracle size n grows from 2 to 3 data qubits (Fig. 3b). Whereas Q solutions are marginally affected, the best C solver demands almost an order of magnitude higher N to achieve a target error. Maximizing the resources available in our quantum hardware, we observe an even larger gap for oracles with n = 4 (data in the Supplementary Information), suggesting a continued increase of quantum advantage with the problem size.
As predicted, quantum parity learning surpasses classical learning in the presence of noise. To investigate the impact of noise on learning, we introduce additional readout error on either A or on all D i . This can be easily done by tuning the amplitude of the readout pulses, effectively decreasing the signal-to-noise ratio.18 When the ancilla assignment error probability η A grows (Fig. 4a), the number of queries \({\overline{N}}_{\mathrm{1 \% }}\) (the average of N 1% over all k) required by the C solver increases by up to 2 orders of magnitude in the measured range (see also data in the Supplementary Information). Conversely, using Q, \({\overline{N}}_{\mathrm{1 \% }}\) only changes by a factor of ~3. Key to this performance gap is the optimization of the digitization threshold for \(\{\langle {V}_{{D}_{i}}\rangle \}\) at each value of η A (see Methods). When η A is increased, an interesting question is whether postselection on V A remains always beneficial. In fact, for η A > 0.25, it becomes more convenient to ignore V A and use the totality of the queries (Q′ in Fig. 4a).

Robustness of quantum parity learning to noise. Number of queries \({\overline{N}}_{\mathrm{1 \% }}\) for \(\overline{p}\mathrm{=0.01}\) for variable readout error η of ancilla a or data b qubits, with n = 3. η is tuned by setting the readout power of the corresponding qubit(s). Empty (solid) circles correspond to the analog C (Q) solver. a, \({\overline{N}}_{\mathrm{1 \% }}\) diverges for η A→0.5 for C, while it stays limited for Q. When \({\eta }_{{\rm{A}}} \gtrsim 0.25\), it is preferable to ignore V A altogether (Q′, triangles). b Whereas both C and Q are severely affected by a noisy data register, Q remains superior and the performance gap increases with η D. Results are out of scale for C and \({\eta }_{{\rm{D}}}\gtrsim 0.4\). The corresponding N 1% are not computed, due to the processing time of several hours that would be required. See Methods for an explanation of the error bars
Similarly, we step the readout error of the data qubits, with average η D, while setting η A to the minimum. Not only does Q outperform C at every step, but the gap widens with increasing η D.
The computational advantage of quantum learning, which appears in the reduction of the number of oracle calls, is even more significant when accounting for the post-processing time. For example, finding k at η A = 0.44 with 1% error (Fig. 4a) takes C about 10 times longer in post-processing relative to Q. Moreover, the processing time for C grows exponentially with n, as the Bayesian solver must track probabilities for each possible k. Conversely, Q consists only of binary comparisons (for postselection on A), averages, and a final digitization (for D), thus scaling linearly with n.
Finally, to verify that our results are not limited to highly noisy systems, we have implemented all 4-bit k on a second device with lower gate and readout errors, particularly for \({\eta }_{{D}_{i}}\). Whereas the required number of queries is greatly reduced for both learners, the performance gap remains in favor of Q (see Supplementary Information).
Discussion
A numerical model including the measured η A,η D, qubit decoherence, and gate errors (see Supplementary Information) modeled as depolarization noise is in very good agreement with the measured N 1% at all η A,η D. This model allows us to extrapolate N 1% to the extreme cases of zero and maximum noise. Obviously, when η D = 0.5, readout of the data register contains no information, and N 1% consequently diverges. On the other hand a random ancilla result (η A = 0.5) does not prevent a quantum learner from obtaining k. In this limit, the predicted factor of ~2 in \({\overline{N}}_{\mathrm{1 \% }}\) between Q and Q′ can be intuitively understood as Q indiscriminately discards half of the queries, while Q′ uses all of them. (See Supplementary Information for theoretical bounds on the scaling of \({\overline{N}}_{\mathrm{1 \% }}\) for different solvers.)
It is worth noting that the quantum advantage here demonstrated is not limited to a noisy realization of the oracle. Lower gate errors, as achieved by a future fault-tolerant processor, will reduce N 1% for both Q and C solvers. Nevertheless, for a given oracle, classical learning will remain more susceptible to measurement errors (η A,η D), preserving the performance gap with Q.12
In conclusion, we have implemented a LPN algorithm in a quantum setting. We have demonstrated a superior performance of quantum learning compared to its classical counterpart, where the performance gap increases with added noise in the query outcomes. A quantum learner, with the ability of physically manipulating the output of a quantum oracle, is expected to find the hidden k with a logarithmic number of queries and linear runtime as function of the problem size, whereas a passive classical observer would require a linear number of queries and nearly exponential runtime. We have shown that the difference in classical and quantum queries required for a target error rate grows with the oracle size in the experimentally accessible range, and that quantum learning is much more robust to noise. We expect that future experiments with increased oracle size will further demarcate a quantum advantage, in support of the predicted asymptotic behavior. Furthermore, our experiment provides a novel method to benchmark the performance of a quantum algorithm using the same hardware to construct the equivalent classical problem. As prototype quantum computers continue to grow, we expect this approach to become increasingly useful in determining the quantum advantage attainable in complex problems.
Methods
Pulse calibration
Single- and two-qubit pulses are calibrated by an automated routine, executed periodically during the experiments. For each qubit, first the transition frequency is calibrated with Ramsey experiments. Second, π and π/2 pulse amplitudes are calibrated using a phase estimation protocol.19 The pulse amplitudes, modulating a carrier through an I/Q mixer (diagram in the Supplementary Information) are adjusted at every iteration of the protocol until the desired accuracy or signal-to-noise limit is reached. Pulses have a Gaussian envelope in the main quadrature and derivative-of-Gaussian in the other, with DRAG parameter20 calibrated beforehand using a sequence amplifying phase errors.21 A CR i gate14, 22 on qubits {A,D i } consists of two pulses applied on A at the D i frequency, separated by a refocusing π pulse on A. For some frequency conditions (mainly that the qubit-qubit detuning is smaller than their anharmonicity), this sequence implements a D i rotation, controlled by A. The gate is calibrated in a two-step procedure, determining first the optimum duration and then the optimum phase corresponding to the unitary \(C{R}_{i}={Z}_{A}{X}_{{D}_{i}}(\pi \mathrm{/2})\).
Experimental setup
A detailed schematic of the experimental setup is illustrated in the Supplementary Information. For each qubit, signals for readout and control are delivered to the corresponding resonator through an individual line through the dilution refrigerator. For an efficient use of resources, we apply frequency division multiplexing23 to generate the five measurement tones by sideband modulation of three microwave sources. Moreover, the same pair of BBN APS (arbitrary waveform generators) channels produce the readout pulses for {D 1,D 2}, and another one for {D 3,D 4}. Similarly, the output signals are pairwise combined at base temperature, limiting the number of HEMTs and digitizer channels to three. The attenuation on the input lines, distributed at different temperature stages, is a compromise between suppression of thermal noise impinging on the resonators (affecting qubit coherence) and the input power required for CR gates.
Gate sequence
CNOT gates can be decomposed in terms of CR gates using the relation \({{\rm{CNOT}}}_{12}=({Z}_{90}^{-}\otimes {X}_{90}^{-}){{\rm{CR}}}_{12}\).24 Moreover, the role of control and target qubits are swapped, using CNOT12 = (H 1⊗H 2)CNOT21(H 1⊗H 2). The first of these H gates is absorbed into state preparation for the LPN sequence (Fig. 1a and Supplementary Information). Similarly, when two CNOTs are executed back to back, two consecutive H gates on A are canceled out. In order to maintain the oracle identical in C and Q, we do not compile the H gates in the CNOTs with those applied before measurement in Q.
Sample size
For each set of oracle k, readout errors η A,η D, solver type, and register size n, we measure the result of 100,000 oracle queries. Each set is accompanied by n+2 calibration points (averaged 10,000 times), providing the distributions of \({V}_{A},{V}_{{D}_{1}},\ldots ,{V}_{{D}_{n}}\) for the collective ground state and for single-qubit excitations (n data and 1 ancilla qubit). These distributions are then used to determine the optimum digitization threshold (for digital solvers) or as input to the Bayesian estimate in C. To obtain p(N), we resample the full data set with 2000–4000 random subsets of each size N.
Statistical analysis
Error bars are obtained by first computing the credible intervals for p at each set {N,k,η A,η D}. These intervals are computed with Jeffreys beta distribution prior \({\rm{Beta}}(\frac{1}{2},\frac{1}{2})\) for Bernoulli trials, with a credible level of 100%−(100–95%)/8≈99.36%. This ensures that, under a union bound, the average of estimates for 8 different k is inside the credible interval with a probability of at least 95%. We then perform antitonic regression on the upper and lower bounds of the credible intervals to ensure monotonicity as function of N, and find the intercept to p = 0.01 for each k. The bounds on the value \({\overline{N}}_{\mathrm{1 \% }}\) averaged over k is computed by interval arithmetic on the credible intervals of N 1% for each k.
Classical solver with Bayesian estimate
An improved classical solver for the LPN problem can be constructed when the oracle provides an analog output. Approximating the distributions of each bit value as Gaussian25 (neglecting qubit transitions during readout), this solver corresponds to a Bayesian estimate of k after a series of observations of the data and ancilla bits. More formally, taking a uniform prior distribution for all binary strings produced by the oracle, one computes the (unnormalized) posterior p(D i ) distribution for each data bit D i the output of the oracle,
The (unnormalized) posterior distribution \({p}_{m}({\boldsymbol{k}}|{{V}_{{\rm{D}}}},{V}_{A})\) for k after the mth query, on the other hand, is given by
where p 0(k) is the prior distribution. Here and above, \(\{{V}_{{D}_{1}},\ldots {V}_{{D}_{n}},{V}_{A}\}\) are rescaled to have mean 0 and 1 for the corresponding qubit in |0〉 and |1〉, respectively. Iterating this procedure (while updating p(k) at each iteration), and then choosing the most probable \({{\boldsymbol{k}}}_{{\rm{Bayes}}}={\text arg}{\max _{\bf k}} p({k})\), one obtains an estimate for k.
Analog quantum solver with postselection on A
While postselection on A is performed equally on both digital (Fig. 2) and analog (Figs. 3 and 4) Q solvers, in the analog case all postselected \(\{{V}_{{D}_{i}}\}\) are averaged together. Finally, the results \(\{\langle {V}_{{D}_{i}}\rangle \}\) are digitized to determine the most likely k. The choice of digitization threshold for each D i depends on: a) the readout voltage distributions ρ 0 and ρ 1 for the two basis states, each characterized by a mean μ and a variance σ 2; b) η A. Ideally (η A = 0 and perfect oracle), the distribution of each query output \({V}_{{D}_{i}}\) matches ρ 0 (ρ 1) for k i = 0(1). When η A > 0, the distribution for k i = 1 becomes the mixture \({\rho }_{{k}_{i}\mathrm{=1}}={\eta }_{{\rm{A}}}{\rho }_{0}+(1-{\eta }_{{\rm{A}}}){\rho }_{1}\). This mixture has mean (1−η A)μ 1+η A μ 0 and variance \((1-{\eta }_{{\rm{A}}}){\sigma }_{1}^{2}+{\eta }_{{\rm{A}}}{\sigma }_{0}^{2}-2{\eta }_{{\rm{A}}}(1-{\eta }_{{\rm{A}}}){\mu }_{0}{\mu }_{1}\). Instead, \({\rho }_{{k}_{i}\mathrm{=0}}={\rho }_{0}\) independently of η A. We approximate the expected distribution of the mean \(\langle {V}_{{D}_{i}}\rangle\) with a Gaussian having average and variance obtained from \({\rho }_{{k}_{i}\mathrm{=0}}({\rho }_{{k}_{i}\mathrm{=1}})\) for k i = 0(1). Finally, we choose the digitization threshold for \({V}_{{D}_{i}}\) which maximally discriminates these two Gaussian distributions. We note that the number of queries scales the variance of both distributions equally and therefore does not affect the optimum threshold. Furthermore, this calibration protocol is independent of the oracle (see Supplementary Information).
Analog quantum solver without postselection
The analysis without ancilla (Q′) closely follows the steps outlined in the last paragraph. For the purpose of extracting the optimum digitization thresholds, we consider η A = 0.5 in the expressions above. This corresponds to an equal mixture of ρ 0 and ρ 1 when k i = 1.
Data deposition and code availability
The full dataset and the Julia26 code used for this analysis are available at https://doi.org/10.5281/zenodo.268731.
References
Yamamoto, T. et al. Quantum process tomography of two-qubit controlled-Z and controlled-NOT gates using superconducting phase qubits. Phys. Rev. B 82, 184515 (2010).
Dewes, A. et al. Quantum speeding-up of computation demonstrated in a superconducting two-qubit processor. Phys. Rev. B 85, 140503 (2012).
Schuld, M., Sinayskiy, I. & Petruccione, F. An introduction to quantum machine learning. Contemp. Phys. 56, 172–185 (2015).
Manzano, D., Pawowski, M. & Brukner, Č. The speed of quantum and classical learning for performing the k-th root of NOT. New J. Phys. 11, 113018 (2009).
Lloyd, S., Mohseni, M. & Rebentrost, P. Quantum algorithms for supervised and unsupervised machine learning. arXiv:quant-ph/1307.0411 (2013).
Wiebe, N., Granade, C., Ferrie, C. & Cory, D. G. Hamiltonian learning and certification using quantum resources. Phys. Rev. Lett. 112, 190501 (2014).
Angluin, D. & Laird, P. Learning from noisy examples. Mach. Learn. 2, 343–370 (1988).
Blum, A., Kalai, A. & Wasserman, H. Noise-tolerant learning, the parity problem, and the statistical query model. J. ACM 50, 506–519 (2003).
Lyubashevsky V. The Parity Problem in the Presence of Noise, Decoding Random Linear Codes, and the Subset Sum Problem. In Approximation, Randomization and Combinatorial Optimization. Algorithms and Techniques. Lecture Notes in Computer Science, vol. 3624 (eds Chekuri, C., Jansen, K., Rolim, J. D. P. & Trevisan, L.) (Springer, Berlin, Heidelberg, 2005).
Hopper, N. J. & Blum, M. Secure human identification protocols. In Advances in Cryptology — ASIACRYPT 2001, vol. 2248. Lecture Notes in Computer Science, (eds Boyd, C.) 52–66 (Springer, Berlin, Heidelberg, 2001).
Pietrzak, K. Cryptography from Learning Parity with Noise. In SOFSEM 2012: Theory and Practice of Computer Science. SOFSEM 2012. Lecture Notes in Computer Science, vol. 7147. (eds Bieliková, M., Friedrich, G., Gottlob, G., Katzenbeisser, S. & Turán, G.) (Springer, Berlin, Heidelberg, 2012).
Cross, A. W., Smith, G. & Smolin, J. A. Quantum learning robust against noise. Phys. Rev. A 92, 012327 (2015).
Blais, A., Huang, R.-S., Wallraff, A., Girvin, S. M. & Schoelkopf, R. J. Cavity quantum electrodynamics for superconducting electrical circuits: An architecture for quantum computation. Phys. Rev. A 69, 062320 (2004).
Rigetti, C. & Devoret, M. Fully microwave-tunable universal gates in superconducting qubits with linear couplings and fixed transition frequencies. Phys. Rev. B 81, 134507 (2010).
Magesan, E., Gambetta, J. M. & Emerson, J. Characterizing quantum gates via randomized benchmarking. Phys. Rev. A 85, 042311 (2012).
Hatridge, M., Vijay, R., Slichter, D. H., Clarke, J. & Siddiqi, I. Dispersive magnetometry with a quantum limited SQUID parametric amplifier. Phys. Rev. B 83, 134501 (2011).
Cleve, R., Ekert, A., Macchiavello, C. & Mosca, M. Quantum algorithms revisited. Proc. R. Soc. Lond. A 454, 339–354 (1998).
Vijay, R., Slichter, D. H. & Siddiqi, I. Observation of quantum jumps in a superconducting artificial atom. Phys. Rev. Lett. 106, 110502 (2011).
Kimmel, S., Low, G. H. & Yoder, T. J. Robust calibration of a universal single-qubit gate set via robust phase estimation. Phys. Rev. A 92, 062315 (2015).
Motzoi, F., Gambetta, J. M., Rebentrost, P. & Wilhelm, F. K. Simple pulses for elimination of leakage in weakly nonlinear qubits. Phys. Rev. Lett. 103, 110501 (2009).
Lucero, E. et al. Reduced phase error through optimized control of a superconducting qubit. Phys. Rev. A 82, 042339 (2010).
Chow, J. M. et al. Universal quantum gate set approaching fault-tolerant thresholds with superconducting qubits. Phys. Rev. Lett. 109, 060501 (2012).
Jerger, M. et al. Frequency division multiplexing readout and simultaneous manipulation of an array of flux qubits. Appl. Phys. Lett. 101, 042604 (2012).
Chow, J. M. et al. Implementing a strand of a scalable fault-tolerant quantum computing fabric. Nature Comm 5, 4015 (2014).
Gambetta, J., Braff, W. A., Wallraff, A., Girvin, S. M. & Schoelkopf, R. J. Protocols for optimal readout of qubits using a continuous quantum nondemolition measurement. Phys. Rev. A 76, 012325 (2007).
Bezanson, J., Edelman, A., Karpinski, S. & Shah, V. B. Julia: a fresh approach to numerical computing. arXiv:cs/1411.1607 (2014).
Córcoles, A. et al. Demonstration of a quantum error detection code using a square lattice of four superconducting qubits. Nat. Comm 6, 6979 (2015).
Acknowledgements
We thank George A. Keefe and Mary B. Rothwell for device fabrication, T. Ohki for technical assistance, H. Krovi for discussions, and I. Siddiqi for providing the Josephson parametric amplifier. This research was funded by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), through the Army Research Office contract no. W911NF-10-1-0324. All statements of fact, opinion or conclusions contained herein are those of the authors and should not be construed as representing the official views or policies of IARPA, the ODNI, or the U.S. Government.
Author information
Authors and Affiliations
Contributions
C.A.R. and B.R.J. developed the BBN APS and the data acquisition software, D.R. and A.D.C. carried out the experiment, D.R., M.P.S., and B.R.J. performed the data analysis, M.P.S. implemented the solvers and developed the theoretical models, D.R. and M.P.S. wrote the manuscript with comments from the other authors, A.W.C. and J.A.S. contributed to the initial design of the experiment, B.R.J., J.M.C., and J.M.G. supervised the project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ristè, D., da Silva, M.P., Ryan, C.A. et al. Demonstration of quantum advantage in machine learning. npj Quantum Inf 3, 16 (2017). https://doi.org/10.1038/s41534-017-0017-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-017-0017-3
This article is cited by
-
Quantum deep generative prior with programmable quantum circuits
Communications Physics (2024)
-
Quantum convolutional neural networks for multiclass image classification
Quantum Information Processing (2024)
-
Efficient representation of bit-planes for quantum image processing
Multimedia Tools and Applications (2024)
-
Shallow quantum neural networks (SQNNs) with application to crack identification
Applied Intelligence (2024)
-
Towards quantum enhanced adversarial robustness in machine learning
Nature Machine Intelligence (2023)
