
Abstract
The aim of this study was to identify asthma phenotypes through cluster analysis. Cluster analysis was performed using self-reported characteristics from a cohort of 1291 Swedish asthma patients. Disease burden was measured using the Asthma Control Test (ACT), the mini Asthma Quality of Life Questionnaire (mini-AQLQ), exacerbation frequency and asthma severity. Validation was performed in 748 individuals from the same geographical region. Three clusters; early onset predominantly female, adult onset predominantly female and adult onset predominantly male, were identified. Early onset predominantly female asthma had a higher burden of disease, the highest exacerbation frequency and use of inhaled corticosteroids. Adult onset predominantly male asthma had the highest mean score of ACT and mini-AQLQ, the lowest exacerbation frequency and higher proportion of subjects with mild asthma. These clusters, based on information from clinical questionnaire data, might be useful in primary care settings where the access to spirometry and biomarkers is limited.
Similar content being viewed by others

Introduction
Despite progress in asthma treatment, the number of patients with poorly controlled disease remains high1. One reason for this is the heterogeneous character of the disease, involving complex pathophysiological processes2.
The heterogeneity in asthma is manifested by varying risk of exacerbation and the inconsistent response to therapy3. In order to optimize management for patients with different disease severity, asthma has been classified into groups (phenotypes). Phenotype is defined as an observable characteristic of a subject resulting from the interaction between the genotype and environmental factors4. Because asthma stratification is based on complex not linear combination of symptoms, lung function and treatment protocols, unbiased cluster analysis has been found to be a useful method for identification of asthma clusters. The majority of previous research has been conducted using multiple measurements such as sputum, serum and bronchoalveolar lavage fluid cell counts and biomarkers, exhaled nitric oxide (FENO), pulmonary function tests and genetic data5,6. The majority of those phenotypes have been studied in patients severe asthma and have not been validated in an independent cohort. Meanwhile, the majority of patients with asthma are detected, treated and followed-up in primary care where there usually is no access to complex data3,7.
Despite several previously identified phenotypes of severe asthma, the clinical perspective on asthma outcome has not been sufficiently optimized8. Furthermore, the correlation between severity of asthma and molecular findings is low9. Only a few attempts have been made to identify clinical phenotypes in mild-to-moderate asthma that might be applicable in asthma patients in primary care10,11,12,13.
In the current study, we aimed to characterize asthma phenotypes by using a limited set of variables obtained from a patient’s questionnaire that can be easily collected and used in routine primary care practice. We applied unsupervised cluster analysis that enabled us to stratify data set without any previously defined hypothesis. The results reproducibility were further studies in one independent population of asthma patients.
Results
Study population
The baseline characteristics were quite similar in both cohorts as shown in Table 1. We did not detect any significant difference for most of the variables, except that the mean age of participants was slightly higher and reported allergy against pollen and pets slightly lower in the validation cohort than in the discovery cohort. Approximately two-thirds of all patients with asthma were under the care of a primary care physician. The quality of the data was good, and the proportion of the missing values for the variables quite low (Table 1). Imputation was not used for missing values.
Cluster analysis in discovery cohort
The cluster analysis of the discovery cohort resulted in identification of three clusters (phenotypes), as three clusters gave the highest silhouette distance. The majority of the parameters were significantly different between the phenotypes (Supplementary Figs. 1 and 2, Table 2).
Phenotype 1 defined as early onset predominantly female asthma was characterized by younger age, female predominance, early onset disease, high prevalence of night awakenings due to asthma symptoms, reported allergy against pollen and pets, rhinitis and sinusitis, slightly lower BMI and low prevalence of diabetes, cardiovascular disease and sleep apnea. This group had the highest percent of subjects with a high education.
Phenotype 2 defined as adult onset predominantly female asthma included predominantly women of higher age and most had an adult onset asthma. The prevalence of allergy against pollen and pets was low whereas the prevalence of rhinitis, cardiovascular disease, diabetes and sleep apnea was high. This phenotype also had the highest rate of current and ex-smoker as well as the highest rate of subjects with only compulsory education and the highest proportion of participants that exercised less than once a month.
Phenotype 3 defined as adult onset predominantly male asthma included predominantly men with adult onset asthma and a low prevalence of allergy and rhinitis. The rate of sinusitis, gastroesophageal reflux disorder (GERD), depression/anxiety, night awaking due to asthma was the lowest in this group. This group included the highest proportion of patients that reported no current asthma, defined as no current asthma medication and asthma symptoms.
Comparison of discovery and validation cohort
We used the second independent asthma cohort, the validation cohort, to repeat the cluster analysis (Table 3). In this population, the optimal number of clusters was also three (Supplementary Figs. 1 and 2). The majority of characteristics of the cluster-generated phenotypes corresponded to those in the discovery cohort with a few exceptions. The mean age of subjects with early onset predominantly female asthma in the validation population was higher in comparison to corresponding group in the discovery cohort. There were also some differences in the prevalence of cardiovascular disease, diabetes, sleep apnea and smoking habits. More specifically, the incidence rate of all cardiovascular disease, diabetes and sleep apnea was the highest in adult onset predominantly female asthma and the lowest in adult onset predominantly male asthma in the discovery cohort. In contrast, in the validation cohort, diabetes and cardiovascular disease was the highest in adult onset predominantly male asthma and the lowest in the early onset predominantly female phenotype while sleep apnea was quite similar across the groups. The distribution of smoking habits varied in both populations. There were more never smokers in both phenotypes with adult onset asthma in the discovery cohort than in the validation cohort. The rate of ex-smokers was higher in the adult onset predominantly female asthma but lower in adult onset predominantly male asthma in the discovery cohort than in the validation cohort.
Disease burden
The results concerning mini-AQLQ, ACT, exacerbation frequency, defined as either the number of emergency visits due to asthma in the last 12 months or usage of OCS during the last 6 months, self-reported asthma severity and treatment steps, had a similar pattern in both populations (Supplementary Table 2, Figs. 1–4). Early onset predominantly female asthma had lowest mean score of mini-AQLQ and the highest rate of exacerbations, while adult onset predominantly male phenotype had the highest mean score of ACT and mini-AQLQ and the lowest rate of exacerbations. A higher proportion of patients in early onset predominantly female asthma used inhaled corticosteroids (ICS) compared to the other two phenotypes. Adult onset predominantly male asthma had the higher rate of patients without ICS treatment (Table 4). In this group the proportion of patients reporting very mild or mild asthma was the highest. Additionally, this phenotype also had the highest proportion of patients reporting no current asthma (Fig. 4).

The hinge denotes the 50% percentiles of the observed data for each phenotype. The whisker (upper or lower) extends from the hinge to maximum 1.5 times of the interquartile range, or IQR. The outliers are those beyond the end of the whiskers and are plotted individually.

The hinge denotes the 50% percentiles of the observed data for each phenotype. The whisker (upper or lower) extends from the hinge to maximum 1.5 times of the interquartile range, or IQR. The outliers are those beyond the end of the whiskers and are plotted individually.

a The mean rate of exacerbation (%) defined as the number of asthma-related emergency visits due to asthma in the last 12 months. b The mean rate of exacerbation (%) defined as the usage of oral corticosteroids as prednisolone and betamethasone.

The proportion of individuals in each of three phenotypes is presented.
Discussion
In this study we performed a cluster analysis of two independent population of asthma patients. By using the patients-reported data of the discovery cohort (n = 1291), we developed the cluster model and identified three phenotypes with distinct demographic and clinical characteristics. Then, we repeated the cluster analysis in a second independent population, the validation cohort (n = 748) where we were able to replicate the division into three similar groups. The disease burden was measured by validated instruments such as ACT, mini-AQLQ as well as by self-reported exacerbation, patients-reported severity and treatment.
Our main finding was that both cohorts consisted of three corresponding phenotypes of asthma patients that had different levels of asthma control and asthma-related quality of life. In line with the previous studies we found that sex and age of asthma onset were key factors across the three identified groups3,5. Therefore, we named the phenotypes as early onset predominantly female, adult onset predominantly female, and adult onset predominantly male asthma. Adult onset predominantly male asthma with a low rate of atopy had well-controlled asthma and the highest rate of patients without ICS treatment. In this phenotype we found the highest proportion of patients that reported no current asthma as they had no ongoing asthma medication or symptoms. The poorest asthma control and the highest use of ICS was found in early onset predominantly female, also characterized by a high rate of atopy. This finding was similar to Haldar et al.12, who performed the first cluster analysis on primary care data. They reported that patients with early onset atopic asthma had the worst outcomes. In contrast, in the study by Khusial et al. the phenotype early atopic had the most favorable outcomes of AQLQ, asthma control and used the lowest dosage of ICS. However, in Khusial’s study, the exacerbation phenotype was distinguished as a separate group of patients. Interestingly, the early atopic included an approximately equal number of men and women while exacerbators consist of 75% females10.
In the present study early onset predominantly female cluster had the lowest asthma control, had the highest prevalence of GERD, sinusitis, depression and anxiety. This is in accordance with previous studies that found that GERD and sinusitis were positively correlated to higher severity and poor control of the disease5,11,14 and similar to earlier reports that depression and anxiety were risk factors for severe asthma15. There was some difference between the cohorts and corresponding phenotypes regarding the prevalence of diabetes and cardiovascular disease. The higher age of patients in the validation population, particularly in early onset predominantly female phenotype, might be the reason for the higher prevalence of cardiometabolic disease in this population. To our knowledge our study is the first cluster analysis evaluating associations of cardiometabolic conditions in relation to phenotypes of asthma in primary care. The highest rate of current smokers was found in adult onset predominantly female asthma and the highest rate of never smokers in early onset predominantly female asthma. Previous studies showed that smoking was less common in people with higher educational level16 and the highest rate of patients with university education was found in early onset predominantly female asthma. Notably, we did not find any differences between reported physical activities between the phenotypes.
A few previous papers have reported results from cluster analysis in two independent populations. One example is Siroux et al.9 that used a French case-control and family-based study (EGEA2) and the European Community Respiratory Health survey II and identified four asthma phenotypes, mainly based on either atopy or the age of onset. A few studies have attempted to replicate the findings of earlier studies. Savenije et al.17 applied the same phenotypes in the Dutch children (n = 3789) as previously identified by an unsupervised statistical approach in the UK in the Avon Longitudinal Study of Parents and Children18. As a result, five of six phenotypes identified in ALSPAC was successfully replicated. However, 63% of the UK primary care patients in a 2019 study of Nissen et al.19 did not fit in any of the phenotypes that were described in a mix of UK primary and secondary care patients in a study of Haldar et al.12 10 years earlier.
We propose to use this cluster classification to identify patients at risk at primary health-care centers. In order to facilitate asthma patient classification, patients with newly diagnosed asthma could be asked to answer some questions by a mobile app or online questionnaire. Different asthma phenotypes may need different levels of management. Early onset predominantly female asthma had the highest disease burden. Because of this perhaps primary care attention should direct more attention on early onset predominantly female. These patients may require frequent visits and tight contact with asthma nurses. In contrast to this, adult onset predominantly male asthma has the most favorable results. These patients might not need health-care visits and could instead be asked to complete the questionnaire every third month. This would facilitate optimal use of the physicians and nurse resources.
The main strength of our study is the use of two randomly selected large cohorts with asthma, both collected at the health-care centers (mainly in the primary care) close in time. Therefore, the number of patients per phenotype was quite large. Our study was completely based on the questionnaire. Another strength was that our study was based on self-reported data from standardized protocols and validated questionnaires, which can give a more nuanced picture than register data. Previously only Ortega et al.11 had based the cluster analysis with asthma patients only on questionnaire data. However, that study used the hypothesis-driven (supervised) cluster analysis that had clearly defined aim (to determine the phenotype at the highest risk of exacerbation)11. Instead, we performed Partitioning Around Medoids (PAM), an unsupervised (data-driven) cluster analysis without previously defined hypothesis. The PAM method is robust and suitable when having both numerical and categorical data, while most other traditional methods such as k-means or hierarchical clustering methods were limited to numerical data, and latent class methods work are limited to categorical data. We based our study on standardized protocols and validated outcome tools, such as mini-AQLQ and ACT, that made our results stronger. The exacerbation rate was one of the outcome variables that was used to control if the groups were related to the clinical outcome. It would, however, also be interesting to make a model where exacerbation rate was included in the cluster analysis as it is a variable that is clinically easy to collect. One problem with the use of self-reported data is that patients may differ in understanding, defining, and remembering20. Another limitation was that both the cohorts were collected in the same region of Sweden and they may not represent the whole Swedish population. Furthermore, we did not have access to pulmonary function measures that some researchers consider as one of the most important discriminant variables in cluster analysis of asthma5,21,22. On the other hand, spirometric measurements and other laboratory variables may not be available in all primary care centers3,23.
In conclusion, we were able to detect three distinct patient phenotypes of asthma, similarly in two independent populations, by using cluster analysis. Moreover, the clustering was based on patient-reported data rather than biomarkers, which increases the feasibility and clinical use of the method, particularly in primary care.
Methods
Data collection
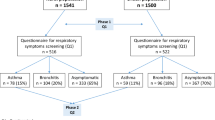
This study is based on two independent Swedish asthma cohorts from the PRAXIS study collected in 2012 and 2015. Characteristics of the two patient populations were reported in more detail in previous publication24. Briefly, both cohorts were identified for research purpose in seven country councils in central Sweden. Eight randomly selected primary health-care centers, one randomly selected department of internal medicine and one respiratory medicine department were included in each council. Randomly selected adult patients, with a doctor’s diagnosis of asthma (ICD-10 code J45) in the medical records, were sent a questionnaire. The first, discovery cohort comprised patients that were contacted for the first time in 2015. The response rate was 46% (n = 1291) where 915 subjects were from primary care and 376 were from hospitals24. The second, validation cohort was used to confirm the results of the analyses in the discovery cohort. The validation cohort answered in 2005 a brief postal questionnaire and in 2012 a more extensive patient questionnaire that was identical to the one used in the validation cohort25. The response rate was 62% (n = 750). Two patients were excluded as they were already in the first cohort that resulted in 748 subjects.
The study protocols were approved by the regional ethics review committee in Uppsala (DNr 2011/318). All participants gave written informed consent.
Questionnaire
The PRAXIS questionnaire collected information on demographic, self-reported asthma characteristics and other relevant information24. For this study we used selected items from this questionnaire (Supplementary Table 1). The selection of variables was based on previous cluster analysis in primary care10,11,12. We included age, sex, body mass index (BMI in kg/m2) and smoking status (never smoker, ex-smoker and current smoker included current daily smoker and occasional smoker). In order to determine disease severity, we added age of onset (≤15; 17–45; ≥46 years), night awakening due to asthma symptoms (cough, wheeze and/or dyspnea), reported allergy against pollen and pets and rhinitis. Additionally, we included co-morbidity with cardiovascular conditions (high blood pressure, heart disease and stroke), diabetes, depression and/or anxiety, sleep apnea, GERD and sinusitis. Information on the educational status and the physical activity was also collected.
Outcome variables
The following variables were used to identify differences in the different cluster-generated groups: mini Asthma Quality of Life Questionnaire (mini-AQLQ)26, Asthma Control Test (ACT)27, exacerbation rate defined as asthma-related emergency visits in primary and/or secondary care in the last 12 months or defined as the use of per oral corticosteroids (OCS: prednisolone or betamethasone) due to asthma symptoms during the last 6 months, patients-reported severity of asthma (no current asthma/very mild/mild/moderate/severe) and maintenance treatment steps grouped such as (a) no inhaled corticosteroids (ICS); (b) ICS alone; (c) ICS and long acting beta-2 agonist and/or leukotriene antagonist (Supplementary Table 1).
Data-driven cluster analysis, statistic
Data-driven cluster analysis was performed in the discovery cohort. The cluster analysis was then repeated in the validation cohort. Fourteen variables including continuous variables (age, BMI) and categorical variables (sex, age of onset, allergy against pollen or pets, rhinitis, diabetes, cardiovascular disease, depression and anxiety, sleep apnea, GERD, sinusitis, night awaking last week, smoking) were selected for clustering analysis. All the variables are listed in Table 1. The PAM analysis was selected to conduct the analysis mostly because we have both continuous variables and categorical variables, and PAM is well-known for robustness and suitable for arbitrary distance28, while other clustering methods are limited to either numerical data or categorical data.
The cluster analysis includes the following steps:
-
(1)
The Gower distance was used to construct the dissimilarity matrix, since there was a mixture of numerical variables and categorical variables29.
-
(2)
The number of clustering was selected according to the silhouette distance. To get the optimal number of clusters, the number of clusters from 2 to 10 was tried, and the one that generated the largest silhouette width was selected (Supplementary Fig. 1).
-
(3)
The PAM analysis was conducted by the pam function in the cluster package in R version 3.5.3)30.
Statistical analysis
The categorical variables were calculated as percent within one cohort or one group. The numerical variables, including age, BMI, ACT and mini-AQLQ, were presented as mean and SD. The outcome variables as mini-AQLQ and ACT were shown as median and interquartile range (IQR). To study if there are differences among the clusters, ANOVA analysis was used for the numerical variables (age, BMI) and chi-square test was applied for the categorical variables (other 12 categorical variables). The p values were corrected for multiple comparisons by the Benjamini & Hochberg method31. The Spearman rank correlation was calculated to detect the association between the self-reported severity and the ACT score/exacerbation history.
Reporting summary
Further information on experimental design is available in the Nature Research Reporting Summary linked to this article.
Data availability
All data that support the findings of this study have been deposited in the PRAXIS database (https://www.researchweb.org/is/fourol/project/157771) and it is available on request from the authors.
References
Gold, L. S., Smith, N., Allen-Ramey, F. C., Nathan, R. A. & Sullivan, S. D. Associations of patient outcomes with level of asthma control. Ann. Allergy Asthma Immunol. 109, 260–265.e262 (2012).
Wenzel, S. E. Emergence of biomolecular pathways to define novel asthma phenotypes. Type-2 immunity and beyond. Am. J. Respir. Cell Mol. Biol. 55, 1–4 (2016).
Wenzel, S. E. Asthma phenotypes: the evolution from clinical to molecular approaches. Nat. Med. 18, 716–725 (2012).
Rice, J. P., Saccone, N. L. & Rasmussen, E. Definition of the phenotype. Adv. Genet. 42, 69–76 (2001).
Moore, W. C. et al. Identification of asthma phenotypes using cluster analysis in the Severe Asthma Research Program. Am. J. Respir. Crit. Care Med. 181, 315–323 (2010).
Wu, W. et al. Unsupervised phenotyping of Severe Asthma Research Program participants using expanded lung data. J. Allergy Clin. Immunol. 133, 1280–1288 (2014).
Green, L. A., Fryer, G. E. Jr., Yawn, B. P., Lanier, D. & Dovey, S. M. The ecology of medical care revisited. N. Engl. J. Med. 344, 2021–2025 (2001).
Shrine, N. et al. Moderate-to-severe asthma in individuals of European ancestry: a genome-wide association study. Lancet Respir. Med. 7, 20–34 (2019).
Siroux, V. et al. Identifying adult asthma phenotypes using a clustering approach. Eur. Respir. J. 38, 310–317 (2011).
Khusial, R. J. et al. Longitudinal outcomes of different asthma phenotypes in primary care, an observational study. NPJ Prim. Care Respir. Med. 27, 55 (2017).
Ortega, H., Miller, D. P. & Li, H. Characterization of asthma exacerbations in primary care using cluster analysis. J. Asthma 49, 158–169 (2012).
Haldar, P. et al. Cluster analysis and clinical asthma phenotypes. Am. J. Respir. Crit. Care Med. 178, 218–224 (2008).
Boer, S. et al. Development and validation of personalized prediction to estimate future risk of severe exacerbations and uncontrolled asthma in patients with asthma, using clinical parameters and early treatment response. J. Allergy Clin. Immunol. Pr. 7, 175–182.e175 (2019).
Schatz, M., Rachelefsky, G. & Krishnan, J. A. Follow-up after acute asthma episodes: what improves future outcomes? J. Allergy Clin. Immunol. 124, S35–42 (2009).
Wang, L. et al. Identification and validation of asthma phenotypes in Chinese population using cluster analysis. Ann. Allergy Asthma Immunol. 119, 324–332 (2017).
Lee, C. W. & Kahende, J. Factors associated with successful smoking cessation in the United States, 2000. Am. J. Public Health 97, 1503–1509 (2007).
Savenije, O. E. et al. Comparison of childhood wheezing phenotypes in 2 birth cohorts: ALSPAC and PIAMA. J. Allergy Clin. Immunol. 127, 1505–1512 e1514 (2011).
Henderson, J. et al. Associations of wheezing phenotypes in the first 6 years of life with atopy, lung function and airway responsiveness in mid-childhood. Thorax 63, 974–980 (2008).
Nissen, F. et al. Clinical profile of predefined asthma phenotypes in a large cohort of UK primary care patients (Clinical Practice Research Datalink). J. Asthma Allergy 12, 7–19 (2019).
Austin, J., Dunn, D., Huster, G. & Rose, D. Development of scales to measure psychosocial care needs of children with seizures and their parents. 1. J. Neurosci. Nurs. 30, 155–160 (1998).
Vasquez, M. M., Zhou, M., Hu, C., Martinez, F. D. & Guerra, S. Low lung function in young adult life is associated with early mortality. Am. J. Respir. Crit. Care Med. 195, 1399–1401 (2017).
Sorkness, R. L. et al. Lung function in adults with stable but severe asthma: air trapping and incomplete reversal of obstruction with bronchodilation. J. Appl. Physiol. 104, 394–403 (2008).
Coates, A. L. et al. Spirometry in primary care. Can. Respir. J. 20, 13–21 (2013).
Sundh, J. et al. Health-related quality of life in asthma patients—a comparison of two cohorts from 2005 and 2015. Respir. Med. 132, 154–160 (2017).
Stegberg, M. et al. Changes in smoking prevalence and cessation support, and factors associated with successful smoking cessation in Swedish patients with asthma and COPD. Eur. Clin. Respir. J. 5, 1421389 (2018).
Juniper, E. F., Buist, A. S., Cox, F. M., Ferrie, P. J. & King, D. R. Validation of a standardized version of the Asthma Quality of Life Questionnaire. Chest 115, 1265–1270 (1999).
Schatz, M., Zeiger, R. S., Vollmer, W. M., Mosen, D. & Cook, E. F. Determinants of future long-term asthma control. J. Allergy Clin. Immunol. 118, 1048–1053 (2006).
Kaufman, L. & Rousseau, P. J. in Statistical Data Analysis based on the L1 -Norm and Related Methods (ed. Dodge, Y.) 405−416 (North-Holland, 1987).
Gower, J. C. A General Coefficient of Similarity and Some of Its Properties. Int. Biometric Soc. 27, 857–871 (1972).
R core Team. R: A Language and Environment for Statistical Computing (R Foundation for Statistical Computing, Vienna, Austria) https://www.R-project.org/ (2019).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. 57, 289–300 (1995).
Acknowledgements
The PRAXIS study was supported by grants from the county councils of the Uppsala-Örebro Health Care region, the Swedish Heart and Lung Association, the Swedish Asthma and Allergy Association, the Bror Hjerpstedts Foundation, the Center for Clinical Research, Dalarna. Open access funding provided by Uppsala University.
Author information
Authors and Affiliations
Contributions
M.A.K.—study design, data analysis, discussion and manuscript writing. X.Z.—data analysis and discussion. J.S.—data collection, manuscript writing and discussion. B.S.—data collection, manuscript writing and discussion. K.L.—data collection, manuscript writing and discussion. A.M.—data analysis, manuscript writing and discussion. H.S.—data collection, manuscript writing and discussion. S.M.—manuscript writing and discussion. A.N.—data collection, manuscript writing and discussion. C.J.—study design, data analysis and manuscript writing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kisiel, M.A., Zhou, X., Sundh, J. et al. Data-driven questionnaire-based cluster analysis of asthma in Swedish adults. npj Prim. Care Respir. Med. 30, 14 (2020). https://doi.org/10.1038/s41533-020-0168-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41533-020-0168-0
This article is cited by
-
Risk factors for severe adult-onset asthma: a multi-factor approach
BMC Pulmonary Medicine (2021)
-
Asthma phenotypes in primary care
npj Primary Care Respiratory Medicine (2020)
