
Abstract
Huntington’s disease is caused by an expanded CAG tract in HTT. The length of the CAG tract accounts for over half the variance in age at onset of disease, and is influenced by other genetic factors, mostly implicating the DNA maintenance machinery. We examined a single nucleotide variant, rs79727797, on chromosome 5 in the TCERG1 gene, previously reported to be associated with Huntington’s disease and a quasi-tandem repeat (QTR) hexamer in exon 4 of TCERG1 with a central pure repeat. We developed a method for calling perfect and imperfect repeats from exome-sequencing data, and tested association between the QTR in TCERG1 and residual age at motor onset (after correcting for the effects of CAG length in the HTT gene) in 610 individuals with Huntington’s disease via regression analysis. We found a significant association between age at onset and the sum of the repeat lengths from both alleles of the QTR (p = 2.1 × 10−9), with each added repeat hexamer reducing age at onset by one year (95% confidence interval [0.7, 1.4]). This association explained that previously observed with rs79727797. The association with age at onset in the genome-wide association study is due to a QTR hexamer in TCERG1, translated to a glutamine/alanine tract in the protein. We could not distinguish whether this was due to cis-effects of the hexamer repeat on gene expression or of the encoded glutamine/alanine tract in the protein. These results motivate further study of the mechanisms by which TCERG1 modifies onset of HD.
Similar content being viewed by others

Introduction
Huntington’s disease (HD) is an autosomal dominant neurodegenerative disorder caused by an expanded CAG tract in exon 1 of the huntingtin gene (HTT). It typically manifests as a progressive movement disorder, often associated with debilitating cognitive, psychiatric and behavioural problems1. Symptoms usually start in mid-life, progressing over 10–30 years to dementia and premature death2. The CAG tract is polymorphic in the normal population with 6–35 CAGs, with 36 or more CAGs in HD subjects. There is an inverse correlation between CAG tract length and age at onset of disease symptoms, accounting for up to 70% of the variance in age at onset1,3,4,5. Genome-wide association studies (GWAS) have shown that other genetic variants also influence age at onset of HD, including variants in genes in DNA damage repair pathways and sequence variants in the CAG tract6,7,8. The most recent genetic modifier GWAS in HD (GeM-HD GWAS)7 revealed 21 independent signals at 14 loci. We observed that one of the significant loci on chromosome 5 (5BM1) contained TCERG1, the only putative genetic modifier of HD onset in the GWAS to have been previously reported9,10. The 5BM1 locus (146 Mbp; hg19) has one significant single nucleotide variant (SNV), rs79727797 (p = 3.8 × 10−10), with each minor allele conferring 2.3 years later onset of HD than expected from the subjects’ CAG repeat length. SNV rs79727797 is within the TCERG1 gene and very close to the tandem repeat locus (Fig. 1a) previously implicated in modifying HD age at onset9,10.

a The sequence of the tandem repeat region in exon 4 of TCERG1 (orange). The blue polygon bounds quasi-tandem repeat (QTR) the central part of which contains pure repeat, CAGGCC hexanucleotide short tandem repeat (STR). b The TCERG1 protein domains and location of the repeat tract. c The variant alleles seen at the tandem repeat locus arranged in descending order of prevalence.
TCERG1 (Transcriptional Elongation Regulator 1; previously known as CA150) protein couples transcriptional elongation and splicing, regulating the expression of many genes11,12. It is highly conserved across human and mouse (97.8% identity between proteins). In humans, TCERG1 is extremely intolerant to loss of function variants (observed/expected variants = 0.13, 90% CI 0.07–0.23) and is in the 5% of genes most intolerant of amino acid missense substitutions, (observed/expected variants = 0.61, 90% CI 0.56–0.67)13. TCERG1 binds to HTT and its expression can rescue mutant HTT neurotoxicity in rat and mouse model systems14. TCERG1 contains a repeat tract of 38 tandem hexanucleotides: a central perfect short tandem repeat (STR) of (CAGGCC)6 embedded in a larger imperfect hexanucleotide ‘quasi’ tandem repeat (QTR; Fig. 1a, b; chr5:145,838,546–145,838,773 on hg19). The whole tract is translated in TCERG1 protein as an imperfect 38 glutamine/alanine (QA) repeat interrupted with occasional valines (V; Supplementary Fig. 1).
Previously, a study of 432 American HD patients showed a nominally significant association of earlier onset with longer QTR length in TCERG1 (p = 0.032, not corrected for multiple testing)9. A study of 427 individuals from Venezuelan HD kindreds10 testing 12 polymorphisms previously associated with HD gave a p-value of 0.07 (not corrected for multiple testing) comparing the 306 bp allele (corresponding to the reference 38-repeat QTR) with all other alleles for association with age at onset. Neither study tested the effects of repeat length directly, instead inferring it from the length of the amplified PCR products, including the flanking primer sequences.
We directly determined the repeat tract sequence in TCERG1 in 610 HD patients by using short-read exome-sequencing data15. We then assessed the association of repeat alleles with age at onset of HD. We used a subset of 468 individuals for whom SNV data were available to test whether the rs79727797 variant was tagging the tandem repeat in TCERG1 and whether the tandem repeat was likely to be the functional variant involved in modifying HD age at onset.
Results
Alleles observed at the TCERG1 hexamer repeat
Subjects came from the REGISTRY16 and PREDICT-HD17 studies, and in Registry were individuals with the largest difference between their observed age at motor onset and that expected given their CAG repeat length, and in PREDICT those with the most extreme phenotype given their CAG repeat length, as in McAllister et al.15.
The 38-unit QTR locus is in exon 4 of TCERG1 and SNV rs79727797 just 3’ to exon 19, separated by 50 kbp (Fig. 1a). The length of the QTR is polymorphic and we identified eight different alleles, mostly varying by central STR length (Fig. 1c). The reference allele (A1), with a central (CAGGCC)6 STR, is by far the most common allele, representing 91.3% of all alleles sequenced in our study (Table 1). Alternative alleles with central STRs of different lengths were observed (Fig. 1c), of which the most common was (CAGGCC)3 (4.1% of alleles; A2, Table 1). This three-repeat allele is in linkage disequilibrium with the minor allele of rs79727797: in our cohort, correlation between the SNV and allele A2 is 99% (see also Supplementary Fig. 2 for QTR and STR genotype distributions with GG and GA rs79727797 genotypes).
Association with age-at onset of HD
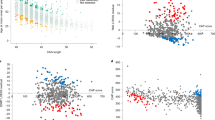
The distribution of genotypes observed in our study is given in Fig. 2. We tested for association between residual age at onset of HD and the QTR length. As there are two alleles, we examined the association with residual age at the onset of the larger or smaller repeat length, the sum of repeat lengths, and the difference between repeat lengths in each patient. We consistently found higher levels of significance in the association between residual age at onset and the sum of the repeat lengths than in the associations with the difference between repeat lengths, or maximum or minimum repeat lengths in each individual (Supplementary Table 1). The association of the sum of the QTR lengths from both alleles with residual age at onset was genome-wide significant (p = 5.0 × 10−9 and 2.0 × 10−8 without and with multiple testing correction, respectively) (Supplementary Table 1). Logistic regression analyses using the extremes of the residual age at onset showed a similar pattern. The relationship between the sum of the hexamer repeats and the residual age at onset in HD is illustrated in Fig. 3 (see also Supplementary Fig. 3 for equivalent analyses of STR). Panels A-C show that subjects with extreme late onset have more copies of the shorter alleles than those with extreme early onset, and this difference becomes more pronounced as the extremes become greater. The negative correlation between the sum of QTR lengths in an individual and residual age at onset of HD is shown in Fig. 3d, with one year earlier HD onset for each added repeat hexamer (black dashed line in Fig. 3d, 95% confidence interval [0.7, 1.4]). We estimated the QTR effect size using the regression with selection analysis described in Methods. Since our HD cohort mainly contains age at onset extremes, the linear regression analysis (grey dashed line in Fig. 3d) overestimates the QTR effect size, giving 2.75 years earlier for each added hexamer. However, it can be used for comparison of the association significance between different models because it provides approximately the same p-value as the regression with selection analysis (Supplementary Table 2). Supplementary Table 2 shows a significant negative association between age at onset and the sum of QTR repeat lengths in both the REGISTRY and PREDICT-HD samples. Notably, (Table S2), the effect size estimated in the REGISTRY sample using regression with selection (0.98 years earlier onset for each added hexamer) is similar to that observed in the PREDICT-HD sample, where the selection is less extreme (1.26 years earlier onset for each added hexamer). This is an indication that applying regression with selection has successfully corrected for the bias in effect size induced by the extreme onset selection in the REGISTRY sample. The associations are similar but slightly less significant when the STR length is used rather than the full QTR length: p = 6.5 ×10−9 for linear regression (Supplementary Table 3). However, since the sample size is relatively small, a larger sample would be needed to establish whether there is any significant difference between these results.

a Quasi-tandem repeat (QTR) genotypes. b Short tandem repeat (STR) genotypes. Black numbers mark genotype counts. Red and blue numbers indicate mean residual ages at onset for individual genotypes, early onset in red, late onset in blue.

a–c Histograms showing distribution of the sum of two QTR repeat lengths Nsum = Nmin + Nmax for the groups with early (red, R < −Rthr) and late (blue, R > Rthr) onsets. Panels (a, b, and c) correspond to the residual age at onset threshold Rthr of 0, 13, and 20 years, respectively. d Association of the sum of two QTR repeat lengths Nsum with the residual age at onset for the entire HD cohort. Red pluses indicate mean residual age at onset for every sum of QTR repeat lengths. Grey and black dashed lines are plotted using coefficients of the linear regression analysis and regression with selection.
The sum of QTR lengths was found to predict residual age at onset significantly better than the difference in QTR lengths, the minimum or maximum QTR length, or the number of copies of the 3-repeat allele (Supplementary Table 4, “Methods”). QTR lengths are thus likely to influence age at onset in an additive manner.
The relationship of the association between residual age at onset and the sum of QTR repeat lengths with those of neighbouring SNVs is shown in Fig. 4 for the 468 individuals with both SNV and sequencing data. In these individuals, the significance of the association between residual age at onset and sum of repeat lengths (p = 1.2 × 10−7) was greater than that observed with the most significant SNV, rs79727797 (p = 3.6 × 10−5). To determine whether the sum of the QTR lengths or rs79727797 was driving the association with age at onset, we performed a conditional analysis in the 468 individuals with both SNV and sequencing data. When the association of rs79727797 with residual age at onset was conditioned on the sum of the QTR lengths, the p-value in our sequenced cohort dropped from p = 3.6 × 10−5 to p = 0.83. However, conditioning the association of age at onset with the sum of QTR lengths on rs79727797 genotypes, it remained significant (p = 9.2 × 10−4), indicating that the hexanucleotide QTR, and not rs7977797, is likely to be driving the signal in our data (Fig. 4). Using the STR gave very similar results. Manhattan plots of SNV associations with residual age at onset for the 468 individuals with SNV data, conditioning on the sum of QTR lengths and rs7977797 in turn, are shown in Supplementary Fig. 4.

The associations of age at onset with the sum of STR (red cross) and QTR (blue cross) repeat lengths in all 610 subjects are also shown. The bar on the right of the plot indicates the strength of linkage disequilibrium (r2) between each SNV and the tandem repeat. The p-value threshold for genome-wide significance (5 × 10−8) is shown with a black dashed line.
Gene expression analyses
TCERG1 has significant cis-expression quantitative trait loci (eQTLs), which can be used in conjunction with GWAS data to predict gene expression18 in several tissues: GTeX19 whole blood, PsychEncode20 cortex, and eQTLGen whole blood21. rs79727797 is significantly associated only with expression of the nearby gene PPP2R2B (expansions in which cause SCA12) in eQTLGen (p = 1.13 × 10−16), with the A allele that is associated with later onset being associated with increased expression of PPP2R2B. However, there are several SNVs more significantly associated with PPP2R2B expression in eQTLGen, and these have only modest significance in the GeM-GWAS (p-values of ~0.07, see Supplementary Data). Likewise, the most significant eQTL SNVs for TCERG1 in eQTLGen are not associated with HD age at onset in GeM (Supplementary Data). Notably, rs79727797 is not significantly associated with TCERG1 expression (p = 0.45). This indicates that gene expression (at least in whole blood) is unlikely to be the mechanism through which TCERG1 influences age at onset in HD. This is corroborated by summary Mendelian Randomisation analyses using the eQTLGen expression data, which were non-significant (p = 0.974 for TCERG1, p = 0.07 for PPP2R2B). Co-localisation analyses further showed that the eQTL and GWAS signals were different for both genes (co-localisation probability = 0). The lack of overlap between GeM GWAS association and eQTLGen and eQTL for TCERG1 and PPR2R2B can be seen graphically in Supplementary Figs. 3, 4.
We used FUSION22 to perform TWAS analyses of the GeM-HD dataset using the PsychENCODE20 cortex expression data. There was a significant negative association between TCERG1 expression and age at onset (Z = −2.71, p = 0.00671): increased TCERG1 expression is associated with earlier HD onset. Although the plot of eQTL and GWAS association (Supplementary Fig. 8) shows some overlap in signal, as does the table of significant eQTLs (Supplementary Data), a co-localisation analysis does not show evidence that the eQTL and GWAS signals share the same causal variant (co-localisation probability = 0.0745). However, this analysis is inconclusive due to the relatively weak eQTL and GWAS signals (note that rs79727797 is not included in the analysis since the PsychENCODE sample is too small to demonstrate association with expression). No TWAS analyses were possible for PPP2R2B, since an insufficient proportion of variation in expression is attributable to SNVs. However, the plot of PsychENCODE eQTL and GWAS association (Supplementary Fig. 8) and table of significant eQTLs (Supplementary Data) show little overlap, which is supported by a co-localisation analysis (co-localisation probability = 0.0376).
Discussion
TCERG1 is the only previously detected candidate gene for modifying HD age at onset to be confirmed by genome-wide association7. Our conditional analysis is consistent with the hexanucleotide tandem repeat in exon 4 explaining the signal attributed to the GWAS-significant SNV rs79727797 (which tags the three-repeat allele A2). The strength of the effect is directly proportional to the repeat length of the TCERG1 QTR, with shorter repeats associated with later onset and longer repeats with earlier onset of HD. The previous finding that a slightly earlier than expected age at onset was detected in individuals whose longest allele is one and a half hexanucleotide repeats longer than the reference9 is consistent with our results (the participants with the genotype (38,40) in Fig. 2A most likely correspond to the inaccurately sized genotype (38,39.5) in Ref. 9). The effect of the number of hexanucleotide repeats appears to be additive with each additional repeat giving one year earlier onset of HD: sum of repeats is significantly better associated with age at onset than either individual repeat allele or the difference between them (Supplementary Table 4). The previous study9 did not find that fitting the combined length of the two alleles improved the significance of the association with age at onset but did not formally compare the various models for allele length. That we were able to show a significant difference is likely due both to a larger sample, in which power was further increased by sampling individuals with extreme ages at onset, and to testing repeat lengths directly rather than allele lengths. Given the GWAS-significant signal at this locus in an unselected HD population7 we expect that this finding will replicate in unselected HD patients. Replication through sequencing the hexamer repeat in a larger unselected cohort is needed to assess the true effect size and the relationship of the modifier effect to repeat length.
TCERG1 has known functions in transcriptional elongation and splicing11,12. It is in the top 5% of genes most intolerant of missense mutations, suggesting an essential role in cell biology13. How the TCERG1 hexanucleotide repeat length modifies HD onset is unknown. Possibilities include cis or trans modulation of TCERG1 or other gene expression, modulation of RNA splicing or transcription-splicing coupling, and effects on somatic expansion of the CAG repeat in HTT. Effects could be mediated by the tandem repeat in DNA or RNA, or by the translated (QA)n tract in protein. The QTR has a slightly stronger association signal than the central STR, which may reflect an association with the length of the QA repeat in the protein rather than the CAGGCC hexamer in the DNA but more work is required to substantiate this observation. In DNA, repeat loci can modulate gene expression in cis23,24, while transcribed repeats in RNA, especially tri- and hexamer repeats, can alter splicing, associate with R-loops and alter RNA stability or binding25. The hexamer repeat in TCERG1 could act via altering the expression of TCERG1 or the nearby gene PPP2R2B. In our analysis evidence for the involvement of TCERG1/PPP2R2B expression in modification of HD age at onset is unclear. It was not possible to test the association of the TCERG1 repeat with expression directly and the tagging SNV (rs79727797) is relatively rare (minor allele frequency = 2.4%), so requires a very large expression sample to show any association. Only eQTLGen (whole blood) is sufficiently large (n = 31,684), and in this sample rs79727797 is significantly associated with PPP2R2B rather than TCERG1 expression. However, the summary Mendelian Randomisation analyses are not significant for either gene, suggesting that neither TCERG1 nor PPP2R2B expression is causally involved in modifying age at onset in HD, at least in blood. A significant TWAS association was observed in the PsychENCODE cortex expression data between increased TCERG1 expression and earlier age at onset, although there was little evidence that the eQTL and GWAS signals were colocalised. However, rs79727797 was not part of the TWAS predictor, due to the insufficient size of the PsychENCODE eQTL dataset. This weakened the GWAS signal, and thus reduced the power of the co-localisation analysis. Furthermore, it was impossible to perform TWAS or co-localisation analyses in caudate or striatum due to the lack of suitable eQTL datasets (the GTEx caudate sample is too small to show eQTL association with TCERG1). Hodges et al.26 did not observe significant differential expression of TCERG1 between HD patients and controls in caudate, although this study assessed expression via microarrays rather than more modern techniques. Langfelder et al.27 observed significantly increased TCERG1 expression in the striata of Q111, Q140, and Q175 mice relative to wild type. However, this has been suggested to be a compensatory homoeostatic response to promote neuron survival28, and such an effect would be difficult to model in a human eQTL sample. Therefore, it is possible that increased TCERG1 expression is associated with earlier onset of HD but corroborating evidence from other samples or direct experimentation is required for confirmation. Consistent with the observations of Langfelder et al.27, immunostaining of post-mortem human brain showed increased nuclear TCERG1 in HD caudate and cortex compared with normal controls, and increased staining with HD grade, suggesting that there may be a localisation effect of the repeat as suggested previously14 and that excess nuclear TCERG1 is deleterious in HD9.
The hexanucleotide tandem repeat in TCERG1 encodes an imperfect (QA)n repeat in the protein and there are conflicting data on the role of this repeat in modulating normal TCERG1 function. One reporter assay found the QA repeat to be dispensable for TCERG-mediated transcriptional repression14, whereas a larger study in two cell lines found the QA repeat to be required for TCERG1-induced repression of the C/EBPα transcription factor29. A minimum of 17 QA repeats was required for this activity. When the QA repeat was deleted ΔQA-TCERG1 colocalised with wild-type TCERG1 and prevented its canonical relocalisation from nuclear speckles to pericentromeric regions, implicating a possible dominant-negative mode of action. This is consistent with the QA repeat being required to retain the nuclear localisation of TCERG114, though not for its effect on transcription, although these overexpression experiments do not distinguish the effects of DNA, RNA, and protein. A dominant negative mode of action would be inconsistent with the additive genetic effect we observe, although the effects we see relate only to differences of up to 5 units of the QA repeat in each TCERG1 allele, rather than a complete deletion of the QA tract. Effects of this smaller modulation in the QA repeat are therefore likely to be more subtle. Taken together with the evidence that increased nuclear localisation of TCERG1 is seen in HD mouse brain27 it is plausible that the alteration in nuclear localisation conferred by the repeat could be responsible for the observed effect of TCERG1 on age at onset. It remains possible that TCERG1 has a novel function in HD cells with an expanded HTT CAG repeat unrelated to its normal function.
Many of the known genetic modifiers of age at onset of HD are proteins that act on DNA, particularly those involved in mismatch repair. These appear to operate by altering the levels of instability and expansion of the HTT CAG repeat, though there is also evidence for wider DNA repair deficits in HD30,31. It is possible that TCERG1 modifies HD onset by acting directly or indirectly on the mechanisms regulating somatic expansion. Expansions of the inherited HTT CAG length are most marked in non-dividing neurons, suggesting that these events take place during transcription or DNA repair. TCERG1 affects the processivity of RNA polymerase and splicing events during transcription, especially co-transcription11,12. During co-transcription it appears to bind and dissociate from stalled spliceosome complexes transiently12 and the QA repeat might modulate this transient binding as it does with the C/EBPα interaction29. HTT exon 1 contains an RNAPII pause site32, associated with co-transcriptional splicing33,34,35. Pausing associated with co-transcriptional splicing of HTT could stabilise the DNA-RNA hybrid R-loops that occur during active transcription36,37,38. Stabilised R-loops would give opportunities for increased binding and processing by the DNA repair machinery, and promote somatic expansion of the CAG repeat in HTT exon 1. Pausing might also promote aberrant splicing of HTT exon 1 which is regulated by RNAPII transcription speed39. This would likely generate a vicious cycle as lengthening repeats lead to increased RNAPII pausing followed by further dysregulation of exon 1 splicing and production of toxic exon 1 HTT species40. Stabilised R-loops are also associated with increased levels of DNA breaks in CAG/CTG repeats cleaved by MutLγ, encoded by MLH1/MLH3, both associated with modulating the length of CAG and other expansions41,42,43: MLH1 is associated with altered age at onset of HD44. Of note, knockdown of TCERG1 in HEK293T cells leads to dysregulation of over 400 genes, including downregulation of MLH111.
The role of TCERG1 in transcription could signal its involvement in the widespread transcriptional dysregulation that is seen in HD11,26,45. TCERG1 is involved in the assembly of small nuclear ribonucleoproteins in mRNA processing46. It also interacts with huntingtin9. In yeast, proteins containing a (QA)15 tract can bind to a fragment of mutant huntingtin containing 103 glutamines to suppress its toxicity47. In amyotrophic lateral sclerosis and some cases of frontotemporal dementia, TCERG1 increases the levels of TDP-43, the major constituent of the pathological hallmark inclusions in mammalian cells48. Notably, TDP-43 is observed alongside mHTT in extranuclear pathogenic inclusions in HD49. The genetic association of the CAGGCC/QA repeat in TCERG1 with age at onset of HD is robust, with a hint that it might operate at level of the protein rather than DNA. More work is needed to clarify the mechanism by which it alters onset in HD and whether this is related to previously reported pathophysiologies or a new pathway. It provides a further potential treatment target in this incurable disease.
In conclusion, we have identified a variable hexanucleotide QTR in TCERG1 as a modifier of HD onset, with one year reduction in age at onset of HD for each additional hexamer repeat. Elucidation of the mechanism of its modifier effect will inform research into pathogenesis in HD and, potentially, other repeat expansion disorders, and could identify new therapeutic targets.
Methods
Subject details
We analysed genetic and phenotypic data of 506 patients with HD from the EHDN REGISTRY study (http://www.ehdn.org16; initially we had 507 individuals, but then we excluded one individual with unreliably called TCERG1 QTR due to low sequencing depth coverage), and 104 individuals from the PREDICT-HD study50. Ethical approval for Registry was obtained in each participating country. Investigation of deidentified PREDICT-HD subjects was approved by the Institutional Review Board of Partners HealthCare (now Mass General Brigham). Participants from both studies gave written informed consent. Experiments were conducted in accordance with the declaration of Helsinki and ethical approval was Cardiff University School of Medicine SMREC 19/55.
DNA of the 506 REGISTRY HD individuals was provided by BioRep Inc. (Milan, Italy) from low-passage lymphoblastoid cells. For most of our HD patients (496 individuals), we measured the length of uninterrupted HTT exon 1 CAG repeat using an Illumina MiSeq platform51. For the remaining 10 individuals, we used BioRep CAG lengths determined using Registry protocols (https://www.enroll-hd.org/enrollhd_documents/2016-10-R1/registry-protocol-3.0.pdf). For individuals from the PREDICT-HD study, DNA was obtained from blood DNA and we used the CAG length recorded in the study. SNV genotype data were available for 468 of the REGISTRY individuals, as part of the GeM GWAS7.
Age at onset was assessed as described in Ref. 11. For REGISTRY age at motor onset data, where onset was classified as motor or oculomotor by the rating clinician, the clinician’s estimate of onset was used for onset estimation. For all other onset types, we used the clinical characteristics questionnaire for motor symptoms. PREDICT-HD age at motor onset was as recorded in the study, determined using the age where the diagnostic confidence level = 4. The selection of the REGISTRY and PREDICT-HD samples are described in detail in Ref. 11. Briefly, the REGISTRY samples were selected for having extreme early or late onset compared to that predicted by their CAG length. The PREDICT-HD samples were selected based on extreme predicted early or late onset. These originally constituted 232 individuals, of whom we analysed on those 104 who had a known age at motor onset.
Calling tandem hexamer from whole-exome-sequencing (WES) data
For the Registry-HD cohort (N = 506), sequencing was performed at Cardiff University15. Whole-exome libraries were generated using TruSeq® rapid exome library kits (Illumina, 20020617) according to Illumina protocols (https://emea.support.illumina.com/downloads/truseq-rapid-exome-library-prep-reference-guide-1000000000751.html). Libraries were sequenced on a HiSeq 4000 using 75 bp paired-end reads. For the PREDICT-HD participants, an in-solution DNA probe based hybrid selection method was used to generate Illumina exome-sequencing libraries. A HiSeq 2500 was used to generate 76 bp paired end reads. De-multiplexed reads for both sets of exomes were aligned using BWA v0.7.5a52, generating variant-ready binary alignment (BAM) files which were used for STR/QTR calling. Individuals with more than one sequencing run were merged into a single BAM file. The human genome assembly hg19 was used for sequence alignment. The genotyping was performed using universal variant caller (UVC) software openly available at https://github.com/LobanovSV/UVC.git. This software allows to call SNPs, INDELs, STRs, QTRs and any their combination in several steps: (i) align single reads to the reference genome using unique matching algorithm; (ii) remove reads with bad alignment score; (iii) find all possible combinations of insertions and deletions appearing from single read alignment; (iv) re-align reads to all of those combinations and choose the best one (i.e. having the smallest mismatch error); (v) correct alignment of single reads using their pairs as well as other reads; (vi) split reads into two (if possible) groups of similar size but with different allele sequence; (vii) correct read alignment using alignments of other samples. To align single reads to the reference genome, we construct the match matrix (Supplementary Fig. 9) and select the path minimising the mismatch error \({\it{M}} = {\it{m}} + \mathop {\sum}\nolimits_i^N {{\Delta }} _{{{\mathrm{i}}}} \cdot \exp \left( {5 - l_i} \right)\) Here, m is sum of mismatch nucleotides, N is number of gaps, Δi is the gap height (the distance between two match pieces adjoining the i-th gap), and li is minimal length of two match pieces. The mismatch error of this form takes into account the highly mutative nature of STRs/QTRs and allows to unbiasedly align reads with any combination of SNPs, INDELs, STRs and/or QTRs. For instance, the naive straight red line in Supplementary Fig. 9 has the mismatch error M = 2 (m = 2, N = 0), whereas the correct blue path with 3 hexamer deletion has much smaller mismatch error M = 6.2 × 10−13 (m = 0, N = 1, ∆i = 18, li = 36). If the right adjoining piece is located above the left one (for example, the break of the blue line in Supplementary Fig. 9), the gap is attributed as a deletion. Conversely, the discontinuity is attributed as an insertion. Finally, we create an alignment track with rows containing sequences of mapped paired reads. To simplify genotyping, we expand the sequence of the reference genome by inserting asterisks to the loci at which the reads have insertions. Conversely, we substitute nucleotide deletions in the reads by asterisks. This manoeuvre permits insertions and deletions to be treated as substitutions. After that we consider loci where some sequence reads have nucleotides different from the reference. We utilise these loci to retrieve the allele sequences by separating the reads into two groups in such a way that all reads in a single group have the same nucleotides at these loci.
Sanger sequencing to confirm QTR sequences
To validate our tandem hexamer calls from WES data, we performed Sanger sequencing of four samples: two homozygous for the reference QTR allele (A1/A1 genotype), one heterozygous for a shorter QTR allele (A1/A2 genotype), and one heterozygous for a longer QTR allele (A1/A4 genotype). The QTR locus in TCERG1 was amplified by PCR using forward (5′-AACTGACACCTATGCTTG-3′) and reverse (5′-GTTGAAGTGGATACTGCA-3′) primers as described in the reference9. Amplicons were Sanger sequenced (LGC, Germany) in both directions using forward (5′-AACTGACACCTATGCTTGCAG-3′) and reverse (5′-GAAGTGGATACTGCAGGTGC-3′) primers, and sequences compared to their respective calls from short-read exome-sequencing data. Sequences from Sanger and exome-sequencing matched in each of the four cases.
Measuring TCERG1 QTR lengths using capillary electrophoresis
To confirm TCERG1 QTR lengths derived from exome-sequencing data, the QTR locus in TCERG1 was amplified by PCR using a fluorescently labelled forward (5′-FAM-AACTGACACCTATGCTTG-3′) and unlabelled reverse (5′-GTTGAAGTGGATACTGCA-3′) primer before sizing by capillary electrophoresis (ABI 3730 genetic analyzer) and Genescan against a LIZ600 ladder of size standards (Thermofisher). In total we tested QTR length calls for 101 individuals from the Registry-HD sample: the 73 who had at least one non-reference QTR length allele (A2–A8) and 28 who were called as homozygous for the reference (A1) allele. The reference allele A1 was predicted to produce a PCR fragment of 307 bp. In all samples, this allele was consistently sized at 299 bp by capillary electrophoresis. We attributed this to the repetitive nature of the sequence and the specific analyzer used. In all 101 individuals tested, allelic QTR lengths relative to the reference A1 allele QTR length exactly matched those called using exome-sequencing data.
Calculation of age at onset residuals
Expected ages of onset were calculated from patient CAG length data (measured as described above) using the Langbehn model53. Residual ages at motor onset were then calculated taking the difference between the expected onset from the recorded clinical age at motor onset, as performed elsewhere7.
Association of age at onset with STR/QTR repeats
Linear regression was performed of the age at onset residual on the repeat statistic (sum, diff, max, min, #3 rep). Since the sample was selected to have extreme values (positive and negative) of this residual, linear regression is likely to overestimate the effect of the repeat on onset in the general HD patient population. Therefore, regression with selection (see “Regression with selection” section below) was used to estimate the true effect size. A dichotomous phenotype was derived by selecting individuals with extreme late (positive residual greater than a pre-defined criterion) or early (negative residual less than a pre-defined criterion) onset. Association of the dichotomous phenotype with repeat statistic was tested via logistic regression.
To formally test which repeat statistics best predict age at onset, we proceeded as follows: For each pair of statistics A and B, a linear regression of residual age-at-onset on statistic A was performed as a baseline. Then statistic B was added to the regression and the significance of the improvement in fit assessed using ANOVA. Statistics were defined as “best fitting” if the addition of no other statistic gave a significant improvement in fit.
Regression with selection
Initial selection
We performed whole-exome sequencing of a small sub-group of the EHDN REGISTRY study. To increase statistical power, we selected individuals with the largest absolute value of the residual age at onset R.
The probability density function of the residual ages at onset in the selected sample p(R) is that of a normal distribution with mean 0 and standard deviation σ
multiplied by a selection function
and normalised to have unitary integral
Here, σ is the standard deviation of the initial HD population (EHDN REGISTRY study), Rthr is the selection threshold, and ∆ is the selection width, which was infinitely small, ∆→0.
The expected probability density of the initial HD population \(p_{\Bbb N}\left( R \right)\), selection function S(R), and expected probability density p(R) of the selected HD sub-group are shown in Supplementary Fig. 10.
Correction of the age at onset residuals
To improve the accuracy of the correction of age at onset for CAG length, we additionally measured the length of the uninterrupted HTT exon 1 CAG repeat using an Illumina MiSeq platform for 496 individuals from our HD cohort and corrected the HD age at onset residuals. Some individuals who had age at onset residual above the threshold Rthr shifted to the region with |R| below the threshold Rthr after correction. Conversely, some individuals who would have corrected age at onset residual above the threshold Rthr, were not selected because their uncorrected |R| were below the threshold Rthr. The correction has therefore widened the selection function, corresponding to a non-zero selection width ∆.
The probability density function p(R) of our HD group with corrected residuals can be modelled in the same way as described above, but with finite selection width ∆.
We estimated parameters of the selection function S(R) by minimising maximum absolute difference D between the expected \(F_e\left( {\left| R \right|} \right)\) and observed \(F_o\left( {\left| R \right|} \right)\) cumulative probabilities
The observed cumulative probability \(F_o\left( {\left| R \right|} \right)\) and expected one \(F_e\left( {\left| R \right|} \right)\) with optimal parameters \(\sigma = 7.02,R_{{{{\mathrm{thr}}}}} = 17.6,\Delta = 3.30\) are shown in Supplementary Fig. 11a. The one-sample Kolmogorov–Smirnov p-value is 0.81. The selection and probability densities are shown in Supplementary Fig. 11b, c.
Likelihood function
In the linear regression, the errors
are normally distributed \(\varepsilon _i\sim {\Bbb N}(0,\sigma ^2)\) and are independent across individuals. The likelihood \({{{\mathcal{L}}}}_{{{{\mathrm{LR}}}}}\left( {\sigma ,\beta _0,\beta _1|R_i,x_i} \right)\) is
where \(p_{\Bbb N}\left( {\varepsilon _i} \right)\) is the probability density function of normal distribution, Eq. (1). Here, σ, β0, and β1 are unknown standard deviation, intercept, and effect size, respectively; Ri and xi are age at onset residual and sum of TCERG1 QTR lengths of a specific individual.
In the regression with selection, the distribution of the errors differs between individuals. The likelihood \({{{\mathcal{L}}}}\left( {\sigma ,\beta _0,\beta _1|R_i,x_i} \right)\) is
Note, the integral in the denominator depends on the individual’s sum of QTR lengths xi. Here, S(R) is the selection function, Eq. (2).
We estimated the unknown parameters σ, β0, and β1 by maximising the likelihood function of all observations
and used the likelihood-ratio test (comparing the likelihood maximised over σ, β0, β1 to that maximised over σ and β0, holding β1 = 0) to obtain the significance of the association.
Analyses to test for correlation between genetically predicted expression and age at onset
FUSION22 was used to perform TWAS analyses on the PsychENCODE data using pre-computed predictors downloaded from http://resource.psychencode.org/. Summary Mendelian Randomisation was used to perform TWAS analyses on eQTLGen blood expression using cis-eQTL data downloaded from https://www.eqtlgen.org/cis-eqtls.html . Co-localisation analyses to test if eQTL and age at onset signal share the same causal SNV were performed using COLOC54.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Sequence data has been deposited at the European Genome-phenome Archive (EGA), which is hosted by the EBI and the CRG, under accession number EGAS00001006383. Further information about EGA can be found on https://ega-archive.org.
Code availability
The software performing regression with selection and STR/QTR calling are freely available from https://github.com/LobanovSV at the RegressionWithSelection and UVC repositories, respectively.
References
McAllister, B. et al. Timing and impact of psychiatric, cognitive, and motor abnormalities in huntington disease. Neurology 96, e2395–e2406.
Bates, G. P. et al. Huntington disease. Nat. Rev. Dis. Prim. 1, 15005 (2015).
Lee, J.-M. et al. CAG repeat expansion in Huntington disease determines age at onset in a fully dominant fashion. Neurology 78, 690–695 (2012).
Tabrizi, S. J. et al. Predictors of phenotypic progression and disease onset in premanifest and early-stage Huntington’s disease in the TRACK-HD study: analysis of 36-month observational data. Lancet. Neurol. 12, 637–649 (2013).
Wexler, N. S. et al. Venezuelan kindreds reveal that genetic and environmental factors modulate Huntington’s disease age of onset. Proc. Natl. Acad. Sci. USA 101, 3498–3503 (2004).
Genetic Modifiers of Huntington’s Disease (GeM-HD) Consortium. Identification of genetic factors that modify clinical onset of Huntington’s disease. Cell 162, 516–526 (2015).
Genetic Modifiers of Huntington’s Disease (GeM-HD) Consortium. CAG repeat not polyglutamine length determines timing of Huntington’s disease onset. Cell 178, 887–900.e14 (2019).
Hensman Moss, D. J. et al. Identification of genetic variants associated with Huntington’s disease progression: a genome-wide association study. Lancet Neurol 16, 701–711 (2017).
Holbert, S. et al. The Gln-Ala repeat transcriptional activator CA150 interacts with huntingtin: neuropathologic and genetic evidence for a role in Huntington’s disease pathogenesis. Proc. Natl. Acad. Sci. 98, 1811–1816 (2001).
Andresen, J. M. et al. Replication of twelve association studies for Huntington’s disease residual age of onset in large Venezuelan kindreds. J. Med. Genet. 44, 44–50 (2007).
Muñoz-Cobo, J. P. et al. Transcriptional elongation regulator 1 affects transcription and splicing of genes associated with cellular morphology and cytoskeleton dynamics and is required for neurite outgrowth in neuroblastoma cells and primary neuronal cultures. Mol. Neurobiol. 54, 7808–7823 (2017).
Sánchez-Hernández, N. et al. The in vivo dynamics of TCERG1, a factor that couples transcriptional elongation with splicing. RNA 22, 571–582 (2016).
Karczewski, K. J. et al. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature 581, 434–443 (2020).
Arango, M. et al. CA150 expression delays striatal cell death in overexpression and knock-in conditions for mutant huntingtin neurotoxicity. J. Neurosci. 26, 4649–4659 (2006).
McAllister, B. et al. Exome sequencing of individuals with Huntington’s disease implicates FAN1 nuclease activity in slowing CAG expansion and disease onset. Nat. Neurosci. 25, 446–457 (2022).
Orth, M. et al. Observing Huntington’s disease: the European Huntington’s disease network’s REGISTRY. PLoS Curr. 2, RRN1184 (2010).
Paulsen, J. S. et al. Preparing for preventive clinical trials: the Predict-HD study. Arch. Neurol. 63, 883–890 (2006).
Zhu, Z. et al. Integration of summary data from GWAS and eQTL studies predicts complex trait gene targets. Nat. Genet. 48, 481–487 (2016).
Lonsdale, J. et al. The Genotype-Tissue Expression (GTEx) project. Nature Genetics 45, 580–585 (2013).
Gandal, M. J. et al. Shared molecular neuropathology across major psychiatric disorders parallels polygenic overlap. Science 359, 693–697 (2018).
Võsa, U. et al. Unraveling the polygenic architecture of complex traits using blood eQTL meta-analysis. bioRxiv 18, 10 (2018).
Gusev, A. et al. Integrative approaches for large-scale transcriptome-wide association studies. Nat. Genet. 48, 245–252 (2016).
Gymrek, M. et al. Abundant contribution of short tandem repeats to gene expression variation in humans. Nat. Genet. 48, 22–29 (2015).
Mousavi, N., Shleizer-Burko, S. & Gymrek, M. Profiling the genome-wide landscape of tandem repeat expansions. bioRxiv https://doi.org/10.1101/361162 (2018).
Hannan, A. J. Tandem repeats mediating genetic plasticity in health and disease. Nat. Rev. Genet. 19, 286–298 (2018).
Hodges, A. et al. Regional and cellular gene expression changes in human Huntington’s disease brain. Hum. Mol. Genet. 15, 965–977 (2006).
Langfelder, P. et al. Integrated genomics and proteomics define huntingtin CAG length-dependent networks in mice. Nat. Neurosci. 19, 623–633 (2016).
Megret, L. et al. Shape deformation analysis reveals the temporal dynamics of cell-type-specific homeostatic and pathogenic responses to mutant huntingtin. Elife 10, 1–25 (2021).
Miller, N. J., Schick, K., Timchenko, N., Harrison, E. & Roesler, W. J. The glutamine-alanine repeat domain of TCERG1 is required for the inhibition of the growth arrest activity of C/EBPα. J. Cell. Biochem. 117, 612–620 (2016).
Maiuri, T. et al. DNA damage repair in huntington’s disease and other neurodegenerative diseases. Neurotherapeutics 16, 948–956 (2019).
Massey, T. H. & Jones, L. The central role of DNA damage and repair in CAG repeat diseases. Dis. Model. Mech 11, dmm031930 (2018).
Watts, J. A. et al. cis elements that mediate RNA polymerase II pausing regulate human gene expression. Am. J. Hum. Genet. 105, 677–688 (2019).
Alexander, R. D., Innocente, S. A., Barrass, J. D. & Beggs, J. D. Splicing-dependent RNA polymerase pausing in yeast. Mol. Cell 40, 582–593 (2010).
Carrillo Oesterreich, F., Preibisch, S. & Neugebauer, K. M. Global analysis of nascent rna reveals transcriptional pausing in terminal exons. Mol. Cell 40, 571–581 (2010).
Wilhelm, B. T. et al. Differential patterns of intronic and exonic DNA regions with respect to RNA polymerase II occupancy, nucleosome density and H3K36me3 marking in fission yeast. Genome Biol. 12, R82 (2011).
Lin, Y., Dent, S. Y. R., Wilson, J. H., Wells, R. D. & Napierala, M. R loops stimulate genetic instability of CTG·CAG repeats. Proc. Natl. Acad. Sci. U.S.A. 107, 692–697 (2010).
Freudenreich, C. H. R-loops: targets for nuclease cleavage and repeat instability. Curr. Genet. 64, 789–794 (2018).
Khristich, A. N. & Mirkin, S. M. On the wrong DNA track: molecular mechanisms of repeat-mediated genome instability. J. Biol. Chem. 295, 4134–4170 (2020).
Neueder, A. et al. The pathogenic exon 1 HTT protein is produced by incomplete splicing in Huntington’s disease patients. Sci. Rep. 7, 1307 (2017).
Neueder, A., Dumas, A. A., Benjamin, A. C. & Bates, G. P. Regulatory mechanisms of incomplete huntingtin mRNA splicing. Nat. Commun. 9, 3955 (2018).
Pinto, R. M. et al. Mismatch repair genes Mlh1 and Mlh3 modify CAG instability in Huntington’s disease mice: genome-wide and candidate approaches. PLoS Genet 9, e1003930 (2013).
Zhao, X., Zhang, Y., Wilkins, K., Edelmann, W. & Usdin, K. MutLγ promotes repeat expansion in a Fragile X mouse model while EXO1 is protective. PLOS Genet. 14, e1007719 (2018).
Neil, A. J., Liang, M. U., Khristich, A. N., Shah, K. A. & Mirkin, S. M. RNA-DNA hybrids promote the expansion of Friedreich’s ataxia (GAA)n repeats via break-induced replication. Nucleic Acids Res. 46, 3487–3497 (2018).
Lee, J.-M. et al. A modifier of Huntington’s disease onset at the MLH1 locus. Hum. Mol. Genet. 26, 3859–3867 (2017).
Pearson, J. L., Robinson, T. J., Muñoz, M. J., Kornblihtt, A. R. & Garcia-Blanco, M. A. Identification of the cellular targets of the transcription factor TCERG1 reveals a prevalent role in mRNA processing. J. Biol. Chem. 283, 7949–7961 (2008).
Moreno-Castro, C. et al. Role for the splicing factor TCERG1 in Cajal body integrity and snRNP assembly. J. Cell Sci. 132, jcs232728 (2019).
Ripaud, L. et al. Overexpression of Q-rich prion-like proteins suppresses polyQ cytotoxicity and alters the polyQ interactome. Proc. Natl. Acad. Sci. USA 111, 18219–18224 (2014).
Pons, M. et al. Identification of TCERG1 as a new genetic modulator of TDP-43 production in Drosophila. Acta Neuropathol. Commun. 6, 138 (2018).
Schwab, C., Arai, T., Hasegawa, M., Yu, S. & McGeer, P. L. Colocalization of transactivation-responsive DNA-binding protein 43 and Huntingtin in inclusions of Huntington disease. J. Neuropathol. Exp. Neurol. 67, 1159–1165 (2008).
Paulsen, J. S. et al. Detection of Huntington’s disease decades before diagnosis: the Predict-HD study. J. Neurol. Neurosurg. Psychiatry 79, 874–880 (2008).
Ciosi, M. et al. Library preparation and MiSeq sequencing for the genotyping-by-sequencing of the Huntington disease HTT exon one trinucleotide repeat and the quantification of somatic mosaicism. Protoc. Exch. https://doi.org/10.1038/protex.2018.089 (2018).
Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 25, 1754–1760 (2009).
Langbehn, D. R. et al. A new model for prediction of the age of onset and penetrance for Huntington’s disease based on CAG length. Clin. Genet. 65, 267–277 (2004).
Giambartolomei, C. et al. Bayesian test for colocalisation between pairs of genetic association studies using summary statistics. PLoS Genet. 10, e1004383 (2014).
Acknowledgements
The authors thank all the patients who contributed data to this research. We thank the Institute of Medical Genetics, Cardiff University for use of the ABI 3730 Genescan allele sizing service. S.L., B.Mc. were supported by CHDI, B.Mc. and S.L. by ARUK, B.Mc. by a PhD studentship from Cardiff University School of Medicine. J.F.G. and M.E.M. received support from NIH grant NS091161 and from the CHDI Foundation, Inc. J-M.L. received support from grant R01NS105709. A.E.R. received support from MRC, Wellcome Trust, Campaign for Alzheimer’s Research in Europe, Horizon 2020, JPND and Health and Care Research Wales. L.J., N.M.W. and P.H. were supported by an MRC Centre grant (MR/L010305/1). L.J., P.H., T.H.M. and N.D.A. were supported by CHDI. T.H.M. was supported by a Welsh Clinical Academic Track Fellowship, an MRC Clinical Training Fellowship (MR/P001629/1) and a Patrick Berthoud Charitable Trust Fellowship through the Association of British Neurologists. B.Mc., T.H.M and L.J. were supported by Brain Research Trust (No. 201617-06). Two of the authors of this publication are members of the European Reference Network for Rare Neurological Diseases - Project ID No. 739510. This work was performed using the computational facilities of the Advanced Research Computing @ Cardiff (ARCCA) Division, Cardiff University. The Registry study is supported by the European Huntington’s Disease Network (EHDN), funded by CHDI Foundation, Inc. The funding source had no role in study design; in the collection, analysis and interpretation of data; in the writing of the report; and in the decision to submit the paper for publication. We thank Vincent Dion for commenting on the manuscript.
This paper is dedicated to the memory of Lesley Jones.
Author information
Authors and Affiliations
Consortia
Contributions
Conceptualisation: T.H.M., L.J.; Methodology: S.L., B.Mc.; Software: S.L.; Validation: M.Mc.K., T.H.M.; Formal Analysis: S.L., P.H.; Investigation: S.L., B.Mc., M.Mc.K.; Resources: B.Mc., G.B.L., A.E.R., M.O., EHDN Registry, J.S.P., PREDICT-HD, J.-M.L., M.E.M., J.F.G.; Data curation: S.L.; Writing – original draft: S.L., P.H., T.H.M., L.J; Writing—review and editing; J.-M.L., M.E.M., J.F.G., J.D.L., M.R., T.H.M., L.J.; Visualisation: S.L.; Supervision: T.H.M., P.H., L.J., N.M.W.; Project administration: T.H.M., L.J.; Funding acquisition: L.J., P.H, T.H.M., M.R., N.M.W. Please note that Professor Lesley Jones died in June 2022 during the final revision of this paper, whilst genetic data were being uploaded to EGA and we were awaiting an accession number. Professor Jones reviewed and edited all versions of the paper, contributing to the project as detailed above.
Corresponding author
Ethics declarations
Competing interests
J.F.G.: Scientific Advisory Board member and has a financial interest in Triplet Therapeutics, Inc. His NIH-funded project is using genetic and genomic approaches to uncover other genes that significantly influence when diagnosable symptoms emerge and how rapidly they worsen in Huntington disease. The company is developing new therapeutic approaches to address triplet repeat disorders such Huntington’s disease, myotonic dystrophy and spinocerebellar ataxias. His interests were reviewed and are managed by Massachusetts General Hospital and Partners HealthCare in accordance with their conflict of interest policies. G.B.L.: Consulting services, advisory board functions, clinical trial services and/or lectures for Allergan, Alnylam, Amarin, AOP Orphan Pharmaceuticals AG, Bayer Pharma AG, CHDI Foundation, GlaxoSmithKline, Hoffmann-LaRoche, Ipsen, ISIS Pharma, Lundbeck, Neurosearch Inc, Medesis, Medivation, Medtronic, NeuraMetrix, Novartis, Pfizer, Prana Biotechnology, Sangamo/Shire, Siena Biotech, Temmler Pharma GmbH and Teva Pharmaceuticals. He has received research grant support from the CHDI Foundation, the Bundesministerium für Bildung und Forschung (BMBF), the Deutsche Forschungsgemeinschaft (DFG), the European Commission (EU-FP7, JPND). His study site Ulm has received compensation in the context of the observational Enroll-HD Study, TEVA, ISIS and Hoffmann-Roche and the Gossweiler Foundation. He receives royalties from the Oxford University Press and is employed by the State of Baden-Württemberg at the University of Ulm. A.E.R.: Chair of European Huntington’s Disease Network (EHDN) executive committee, Global PI for Triplet Therapeutics L.J. is a member of the scientific advisory boards of LoQus23 Therapeutics and Triplet Therapeutics. T.H.M. is an associate member of the scientific advisory board of LoQus23 Therapeutics. J-M.L is a member of the Scientific Advisory Board of GenEdit, Inc., J.D.L is a paid board member for F. Hoffmann-La Roche Ltd and uniQure biopharma B.V., and he is a paid consultant for Vaccinex Inc, Wave Life Sciences USA Inc, Genentech Inc, Triplet Therapeutics Inc, PTC Therapeutics Inc, and Remix Therapeutics. S.L., B.Mc., J-M.L., M.E.M., M.R., N.M.W., M.O. and P.H.: nothing to disclose.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lobanov, S.V., McAllister, B., McDade-Kumar, M. et al. Huntington’s disease age at motor onset is modified by the tandem hexamer repeat in TCERG1. npj Genom. Med. 7, 53 (2022). https://doi.org/10.1038/s41525-022-00317-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41525-022-00317-w
