
Abstract
We sought to find clinical subtypes of posttraumatic stress disorder (PTSD) in veterans 6–10 years post-trauma exposure based on current symptom assessments and to examine whether blood biomarkers could differentiate them. Samples were males deployed to Iraq and Afghanistan studied by the PTSD Systems Biology Consortium: a discovery sample of 74 PTSD cases and 71 healthy controls (HC), and a validation sample of 26 PTSD cases and 36 HC. A machine learning method, random forests (RF), in conjunction with a clustering method, partitioning around medoids, were used to identify subtypes derived from 16 self-report and clinician assessment scales, including the clinician-administered PTSD scale for DSM-IV (CAPS). Two subtypes were identified, designated S1 and S2, differing on mean current CAPS total scores: S2 = 75.6 (sd 14.6) and S1 = 54.3 (sd 6.6). S2 had greater symptom severity scores than both S1 and HC on all scale items. The mean first principal component score derived from clinical summary scales was three times higher in S2 than in S1. Distinct RFs were grown to classify S1 and S2 vs. HCs and vs. each other on multi-omic blood markers feature classes of current medical comorbidities, neurocognitive functioning, demographics, pre-military trauma, and psychiatric history. Among these classes, in each RF intergroup comparison of S1, S2, and HC, multi-omic biomarkers yielded the highest AUC-ROCs (0.819–0.922); other classes added little to further discrimination of the subtypes. Among the top five biomarkers in each of these RFs were methylation, micro RNA, and lactate markers, suggesting their biological role in symptom severity.
Similar content being viewed by others

Introduction
Distinct subtypes of posttraumatic stress disorder (PTSD), a heterogeneous disorder, have been sought to isolate differentiating clinical features and their biological mechanisms so that recommendations can be made for more precise treatments and prognostic indicators can be identified. A natural starting point for developing clinical subtypes is derived from the four sets of symptom criteria for PTSD defined in the diagnostic statistical manual (DSM-5)1,2: intrusion, avoidance, negative alterations in cognitions and mood, and alterations in arousal and reactivity. Subtype suggestions have been made based on externalization features3, and for a dissociative subtype that includes depersonalization and derealization symptoms and delayed onset4,5. Other symptoms that commonly co-occur with PTSD, including anxiety and depressive symptoms, have also been considered in the search for PTSD subtypes6. Clusters of distinct clinical symptoms are desirable for defining subtypes, but several subtyping studies at best have led to subgroups distinguished on symptom severity and comorbidities7. While biological correlates of PTSD including multi-omic blood biomarkers8, cortisol9, neurocognitive markers10, neuroimaging markers11,12, and voice markers13 have been studied, to date only a few studies have shown their value for characterizing subtypes. Among these, neurocognitive functioning has been shown to differentiate clinically defined severity subtypes6. The dissociative subtype of PTSD is associated with altered resting-state functional connectivity of the amygdala11 and altered subcortical white matter connectivity12. Zhang et al.14 demonstrated that electroencephalography (EEG) functional connectivity defined subtypes for PTSD and major depressive disorder (MDD) predict differential treatment response when comparing psychotherapy to placebo for PTSD, and antidepressant medication versus placebo for MDD. Notably, epigenetic markers have been used to define PTSD subtypes, which are then shown to differ on clinical characteristics15, a reversal of the usual approach.
Analytic methods used to identify subtypes have evolved from statistical clustering approaches to modern methods of machine learning that are essentially unsupervised searches for patterns involving between persons’ distance measures. The most common statistical method used in prior studies of the heterogeneity in PTSD symptom presentations is latent profile analysis (LPA)5,6,16,17 in which the probability of being in a latent class is modeled. The probability is assumed to be represented by a weighted mixture of normally distributed random variables in which each represents a subtype and the weights are the probabilities of subtype membership for a given feature profile. Normality assumptions, difficulty in parameter estimation, and limits on the number of variables that can be considered reduce the usefulness of this statistical approach. In our study, we used the machine learning method of random forests (RF)18 to obtain a distance measure between subjects in conjunction with an unsupervised statistical clustering method, partitioning around medoids (PAM)19, to identify subtypes. This is a novel approach that quantifies the distance between subjects as small if they frequently fall in the same terminal nodes of the RF trees grown to classify the disorder versus healthy controls (HC). RF are also used in our report to identify biological correlates of the subtypes. Several advantages accrue to the use of RF most germane here is the ability to include large sets of both binary and continuous features even with modest sample sizes, and to provide a distance metric for clustering that is related to the purpose of the clusters. Further, RF are developed with internal validation procedures achieved through out-of-bag sampling20 in which numerous repetitions of random bootstrap samples used in training models are evaluated on the left-out samples to obtain robust estimates of the AUC of the RF ROC and its modeling errors. Sophisticated variable reduction methods are available such as “shaving”21 based on measures of a feature’s importance to the classifier22 and enable a reduction in the number of features considered.
The goal of the current study is to discover PTSD subtypes that are homogeneous in clinical symptoms and to determine whether multi-omic blood biomarkers can differentiate them. To identify subtypes, we considered a large array of clinical symptom items captured in 16 validated self-report and clinical assessment scales (see Fig. 1 and Table S1) that are commonly used in practice to assess PTSD and its comorbidities in clinical research settings. The distance between subjects is captured by the proximity matrix of an RF grown to classify cases vs HC with these clinical symptoms. To establish the comparative importance of multi-omic blood biomarkers in contrast with other candidate predictor classes of subtypes, we also examined whether five additional feature classes improved classification. The novelty of our work lies in the large number of clinical items considered in subtyping, the use of a proximity matrix from an RF in a clustering algorithm to identify the symptom severity subtypes, and the separate validation of the subtypes with a large class of multi-omic markers that previously have been demonstrated by our group to differentiate PTSD from HC8.

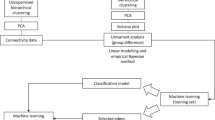
Panel 1: Flow chart of analytic steps. Panel 2: Specific procedures.
While a best-practice procedure for the external validation of subtypes has not yet been described in the psychometric or statistical literature, the logic and flow of the present work have been informed by the criteria described by Dalenberg et al.23. These authors propose that to be useful subtypes must be (1) clinically relevant, (2) reliably measured, and (3) have different biological mechanisms. We address each of these criteria as follows: (1) clinical relevance is attested to by the intuitive face validity of the identified clusters, (2) reliable measurement by the use of only items from reliable and well-validated assessment scales as defining features, and (3) the different biological mechanisms of subtypes shown by the ability of a parsimonious set of biomarkers to accurately classify subjects into the clinical subtypes.
Methods
Background
The discovery and validation samples utilized for subtyping are male Iraq and Afghanistan veterans, a group documented to have an increased risk for PTSD. The lifetime prevalence of PTSD in US veterans of the Vietnam War and subsequent conflicts, including the Iraq and Afghanistan Wars, is estimated to be between 10.1% and 30.9%24,25,26. We studied participants from the PTSD system biology consortium (SBC)8, a collaboration of the US Army and multiple academic centers enrolling subjects, identifying biological markers, and advancing diagnostics for high throughput clinical screening to identify military service-related PTSD. Comprehensive biological, clinical, and neurocognitive data on Iraq and Afghanistan male veterans exposed to military trauma were assessed 6–10 years post-deployment. Participants were evaluated with the clinician-administered PTSD scale for DSM-IV (CAPS)1 to determine if they met diagnostic criteria, the structured clinical interview for DSM–IV (SCID)27 to assess other psychiatric disorders, and the peritraumatic dissociative experiences questionnaire28, a rater measure of peritraumatic dissociation, self-report measures of symptoms of PTSD and associated co-morbidities and measures of neurocognitive functioning. Historical information was collected on adverse childhood events and pre-military trauma exposure. Blood was drawn yielding over one million biomarkers including GWAS, DNA methylation, miRNAs, metabolomics, proteomics, small molecules, endocrine markers, routine clinical lab panels, and biometric/physiological markers. A mixed-method approach of analytic and qualitative methods labeled “wisdom of crowds” was used to reduce features into 343 unique candidates and include, as reported in our paper8, COMBINER29, polygenic risk30,31, as well as traditional SVM-RFE, RF, and other classification algorithms and feature selection approach, including p-value, q-value, and fold-change filtering. From the 343 features, 28 were down-selected to be included in an RF classifier of previously deployed Iraq and Afghanistan veterans with military service-related PTSD cases and HC. The PTSD SBC sample was comprised of 166 male veterans, 83 who met DSM-IV diagnostic criteria for a current diagnosis of PTSD with a CAPS total score ≥40 (cases), and 83 who were HC with a CAPS total score ≤20.
Discovery sample
Our discovery sample is a subset of the 166 male Iraq and Afghanistan veterans drawn from our PTSD SBC sample8. Besides the above-specified cut-points for CAPs (inclusion criteria), other inclusion/exclusion criteria included stable on medications in the prior month, no prominent suicidality in the past three months, no psychotic or bipolar disorders, no severe drug use disorder in the past year, no open head injury and no major medical illness or neurological conditions. The HC were selected similar in age and ethnicity to the cases. The discovery sample size was reduced from 166 to 145 because some missing data could not be validly imputed; the resulting discovery sample size for the current study was 74 cases and 71 HC.
Validation sample
An independent validation sample of 62 male Iraq and Afghanistan veterans, 26 PTSD cases and 36 HC, also drawn from the earlier SBC study8 with similar characteristics to the discovery sample, was used in the current study to validate the RF that generated the distance metric for the clustering algorithm used to find subtypes. Table 1 displays and compares background characteristics of the discovery and validation samples.
Variables
Clinical items for finding subtypes of PTSD
Figure 1 and Table S1 list the 16 clinical scales whose individual items were used to subtype cases and include the CAPS, the PDEQ (a rater administered peritraumatic dissociative experiences scale), and other commonly used reliable and validated self-report symptom scales.
Feature classes for describing and classifying symptom severity subtypes
The multi-omic blood biomarkers used for classifying the identified clinical PTSD subtypes included GWAS, DNA methylation, miRNAs, metabolomics, proteomics, small molecules, endocrine, routine clinical labs, and biometric/physiological markers. They are the same as 343 selected in our earlier study for classifying PTSD cases and HC8, with the exception of GABR which was removed because of extreme outlier values. The markers are displayed in Table S2 and the number of markers within a class in Table S3. Five additional feature classes were included to determine their value in classification: current medical co-morbidities, current neurocognitive functioning, demographics, past psychiatric history, and pre-military trauma. None of these feature classes were incorporated into the primary search for clinical subtypes as they are not easily collected in most clinical settings (e.g., neurocognitive functioning), are not current mental state assessments (e.g., past psychiatric history, pre-military trauma), or had category frequencies in the sample that were non-representative of the target population (e.g., demographics) used in forming the subtypes but are considered for their ability to discriminate the clinical subtypes. To further describe the sample and derived subtypes, current SCID diagnoses of alcohol and depressive psychiatric disorder were also collected.
Data analytic methods
Figure 1 summarizes the analytic steps of the study procedures.
Random forests
The machine learning method used was RF, an ensemble method that combines independent decision trees whose terminal nodes determine class membership18. A final vote summarizes the individual tree results generating a probability of membership in a class. Each tree in an RF uses an internal validation method, a bootstrap method to select a sample from the dataset to train the decision tree, and the remaining sample (out-of-bag, OOB) to estimate the prediction error20. This can be repeated multiple times as specified by the user. Varying the probability threshold-level defining membership in a class generates a receiver operating curve (ROC) and its area under the curve (AUC-ROC), which is used to measure classification accuracy. The importance of each feature to the RF, the mean reduction in Gini index22, is measured by the average reduction obtained in the ambiguity of classification at a node when it is used as a splitting variable in comparison to ambiguity at the two descendant nodes of the split. Shaving eliminates less important variables to classification21. The least important features are first eliminated, the RF rerun with the reduced set, its AUC computed and the process continued until an optimal AUC is selected as the largest value obtained with the smallest set of unshaved variables. The programs were run using R software32 and specialized source coding for modeling and subsequent clustering have been placed in GitHub33.
Clustering method to find subtypes based on clinical symptoms
Subtypes of PTSD cases were obtained using the clustering program, PAM19. The distance between subjects, a required input to any clustering algorithm, was obtained by a novel use of the proximity matrix of an RF to classify cases versus HC. An RF parses subjects based on feature splits ending in a terminal node in which persons have the same pattern of feature interactions. The proximity between two PTSD cases is defined based on the frequency across the decision trees of the RF of being in the same terminal node. For the PAM algorithm, the measure of distance between cases was one minus the entries in the resulting proximity matrix. Because the discovery and validation sample sizes were not large, we restricted the number of clusters to two, and label the resulting clusters S1 and S2.
Classifying subtypes with biomarkers and other feature classes
To estimate how well biomarkers classified subjects into subtypes, three RFs classifier models were grown with multiple feature classes: S1 vs. HC, S2 vs. HC, S2 vs. S1, and an RF to classify all cases vs HC for comparative purposes. For each of these, six separate RFs were grown using the six supplementary feature classes, and their AUC-ROCs compared to assess the extent to which they improved classification over that from blood biomarkers alone (see Table S4). Additional RF pooling of all classes was also grown.
Canonical correlation
We used canonical correlations34 to examine whether the variables we found to be “important” in our RF distinguishing cases and controls were correlated with the variables we found in our earlier classifier for PTSD cases and controls8. To compare the relationship between two sets of features, X1, X2,…Xu and Y1, Y2, …Yv, canonical-correlation analysis was used to find the linear combination of the X variables and the linear combination of the Y variables that has the maximum correlation with each other. The pair of linear combinations of the X’s and Y’s are called the first canonical variables. In a second step, a similar maximization procedure seeks to find the linear combination of the X variables and the linear combination of the Y variables that maximizes their correlation subject to the constraint that they are uncorrelated with the first pair of canonical variables. The method continues until the canonical correlations are too small to be of interest. The maximum number possible is the smaller of u and v. We report on the first three canonical correlations obtained from comparing the important biomarkers from our earlier and current study.
Validation approaches
Internal validation of any of the RFs grown for this study was intrinsic to the bootstrap method used in which we employed 4000 bootstrap samples to grow the trees, and estimated errors from the out-of-bag samples. For external validation of the RF used for clustering, it was scored with the independent but demographically similar validation sample of 62 male veterans who had been assessed on the same clinical scales. Table 1 displays the results of a comparison of the characteristics of the discovery to the validation sample.
Internal validation of the PAM clusters was measured by silhouette scores35 that calculate the extent to which members in a cluster are close to each other and distant from members in other clusters (see Fig. S1a). Multidimensional scaling was used to visualize the clusters via a diffusion map36 (see Fig. S1b). Face validity of the derived subtypes was appraised by determining whether differences in the item scores between the individuals in the subtypes were statistically different and clinically interpretable. Figure S2 displays plots of the mean item clinical scores among groups. Statistical differences in the total scale and subset scores of the clinical scales between S1, S2, and HC were tested with an ANOVA; and between: S1 vs. HC, S2 vs. HC, and S2 vs. S1 with Wilcoxon rank-sum tests. Significance is reported based on a family-wise error rate, (p < 0.0001). Results are displayed in Table 2. Totals and subscales of the clinical scores were also multivariately compared for the first principal component (PC1) (see Table S5) of a principal component analysis (see the first entry in Table 2).
However, to our knowledge, there are no available methods to externally validate the clusters themselves, as the ground truth, i.e., the “true” clusters in a validation sample are not known. Further, our external validation sample contained only 26 PTSD cases which, even if we knew the truth, would generate even smaller samples in the subtypes for any meaningful statistical testing. The ability to accurately classify persons into the PTSD clinical subtypes based on the blood biomarkers, a form of concurrent validity, was considered to provide external validation of the subtypes and by Dalenberg’s criteria of meaningfulness of clinical subtypes23 that they are distinguishable by distinct biological mechanisms.
Results
Identifying PTSD subtypes in the discovery sample
Two clinical subtypes of PTSD cases were found with PAM: the first, designated as S1, comprised of 26 (35.1%) cases and the second, designated as S2, of 48 (64.8%) cases. Table 3 displays the means (sds) of descriptive characteristics of S1 and S2. Subjects in the subtypes were similar on race/ethnicity, education, body mass index, cholesterol, and HbA1c. They did not differ on their use of psychotropic medications (71% in S1 and 62% in S2) but higher percents in S2 have current and lifetime depression (p < 0.05; 94% of members of S2 compared to 69% in S1).
S1 and S2 differ in clinical severity. The mean CAPS score of individuals in S1 is 54.3 (sd 6.6), and of those in S2 is 75.6 (sd 14.6). Those in S2 compared to S1 have significantly higher mean severity scores on almost all individual items of the 16 clinical scales (see Fig. S2). In the principal component analysis of the total scale and subscale scores of the clinical scales used for subtyping, PC1 accounted for 64% of the total variance and had fairly equal factor weights on all of the clinical scale scores. Each of the additional principal components accounted for ≤5% of the total variance (see Table S5). All summary scale scores statistically differed between groups overall and in most pairwise comparisons of groups as noted in Table 2. In particular, the mean PC1 score of those in S2 was three times that of the S1 group.
Validation
Figure S1b, a two-dimensional diffusion mapping of the RF distance scores based on a multidimensional scaling procedure, displays clear separation of HC from S1 and S2 and indicates greater dispersion among the members of S1 compared to S2. The silhouette scores reflect this: S1 = −0.25, S2 = 0.54 in comparison to HC = 0.76 (see Fig. S1a). The RF used to obtain the proximity of cases was scored with the external validation sample yielding an AUC of 0.99. The ability to classify persons into subtypes based on biological and other variables distinct from the subtyping variables with high accuracy reported below, a form of concurrent validity, was considered supportive of the external validity of the subtypes.
Biomarker classification of PTSD subtypes
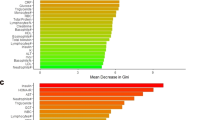
The subtypes were accurately classified with a multi-omic panel of 342 biological markers that RF analyses substantially reduced to 71 unique “important” biological markers over all intergroup comparisons. Table S4 displays the AUCs for each intergroup comparison for each feature class and the feature classes pooled. The AUCs and the number of important features in each of the down-selected intergroup models are: S1 vs. S2: AUC = 0.819, number of markers = 10; HCs vs. S1: AUC = 0.911, number of markers = 23; HCs vs. S2: AUC = 0.922, number of markers = 37. Supplementary Table S6 displays the set of important multi-omic features identified in any of the intergroup contrasts (n = 71), the mean (sd) values for each subtype, and HCs.
Table 4 displays for the top 5 markers in each comparison (n = 15 markers) the results of significance tests of equality of the means between the groups in an intergroup classification. Indicated is whether the marker found to be significant was up or down-regulated in the more severe group, as determined by a comparison of mean values. For comparisons of S2 vs. HC and of S1 vs. HC, mean values of the top five features of the groups significantly differed, and all markers except lactate were downregulated in the more severe group. The top five markers in the RF comparing S2 to HC were lactate, CG20720918 and CG03267026 and miR-106b.3p, and miR-93.3p. For S1 vs. S2 only one marker, cg13034868 statistically differed between groups indicating downregulation in the severe group.
Classification into subtypes by other feature classes
When all feature classes were included in RFs for intergroup classification models, the AUCs only slightly increased over that for biomarkers alone. For example, when all classes are combined (see Table S4), the AUC of S2 vs. HC is 0.968, only a 5% increase over that obtained with blood biomarkers alone (0.922). No feature class alone provided greater accuracy than did the biomarker class alone. In the classification model of S2 vs. HCs, neuro-cognitive functions and psychiatric history had AUCs of 0.72 and 0.84 with vocabulary test scores and lifetime major depression ranked as the most important features in these RF (see Table S7).
Discussion
S2 is clinically a more severely ill group, with clinical item scores indicating greater severity for almost every item of all clinical scales considered, underscored by a mean total CAPs score difference between subtypes of 21 points (54.3 vs. 75.6). Almost all in S2 reported having lifetime major depression. Among the six feature classes studied, multi-omic biomarkers provided the highest accuracy for classification into subtypes, suggesting that clinically defined subtypes have strong biological underpinnings. Subtyping into clinical severity groups and high accuracy classification models using multi-omic blood markers provides strong support for biological associations with levels of PTSD severity.
That biological markers can be used for the classification of PTSD vs. HC was previously reported by our consortium in Dean et al.8 using 28 biomarkers. Using our RF methods and down selecting from the same 342 markers, in the present study we obtained an RF with 48 biomarkers, six of which are in common with the original 28, resulting in a high AUC of 0.91. That our current markers do not totally overlap with the original 28 may be explained in part by strong correlations among many molecular markers. To test this assumption we examined the canonical correlations of the 22 non-overlapping features from our earlier study with the 42 non-overlapping markers from our current study. The first three canonical correlations were 0.94, 0.90, and 0.84, demonstrating high correlations between the two sets of markers.
There are several published reports on the possible biological connections of markers to PTSD. We discuss the top five most important markers in the RF of the most extreme severity group contrast, S2 vs. HC37,38,39,40,41,42,43,44,45,46,47,48 viewing this contrast as most likely to identify signature pathways. Lactate, an important marker, is elevated, as was also found in earlier studies of the SBC8,37. It also has been found to be elevated in anxiety and panic disorder38. Cerebral lactate level is elevated in patients with schizophrenia39. Lactate is a marker for anaerobic metabolism, which is frequently elevated during physiological stress such as hypoxia, infection, and inflammation. As PTSD is a multi-systemic disorder, it is not surprising that there are stress responses at the cellular level, which may be a cause or the result of PTSD meriting further investigation.
The other four top markers in the RF classifying S2 vs. HC are CG20720918 (GORASP2), CG03267026 (BRSK2), miR-106b, and miR-93. These are molecular markers that are differentially expressed in various neurological and psychiatric illnesses. Both GORASP2 and BRSK2 genes are involved in the endoplasmic reticulum (ER) stress response which often results in apoptosis. GORASP2 encodes Golgi reassembly-stacking protein 2, also called GRASP55 (Golgi reassembly-stacking protein of 55 kDa), a membrane protein important in maintaining the stacking of Golgi cisternae. DNA hypomethylation of GORASP2 is associated with medial temporal epilepsy40. The transcriptional level of GORASP2 is also found to be altered in patients with Alzheimer’s disease (AD)41. Copy number variation of GORASP2 has also been found in autism spectrum disorder (ASD)42. On the other hand, BRSK2 encodes brain-specific kinase-2 involved in apoptosis as an ER stress response and also has a role in axon development. BRSK2 has been recently found to be a strong risk gene for ASD43. Autoantigen against BRSK2 was also found in paraneoplastic limbic encephalitis44. The relationship between the two microRNAs, miR-106b and miR-93, and PTSD is more enigmatic. Micro RNAs are short single-stranded non-coding RNAs that regulate gene expression by binding to complementary sequences in their target mRNAs′ 3′-untranslated region (UTR), and also to a lesser extent to the 5′-UTR and coding regions. Both of these miRNAs have lower levels in the S2 subtype compared to the HC subjects. They are derived from the MCM7 (mini-chromosome maintenance) gene, which encodes a protein essential for the initiation of eukaryotic genome replication and belongs to the highly conserved miR-106b-25 cluster. The serum levels of miR-106b have been shown to be upregulated in both schizophrenia and bipolar disorder45,46, which is the opposite of our finding in the S2 subtype patients. On the other hand, serum miR-93 levels are significantly decreased in patients with AD47. It is possible that PTSD patients have significant ER stress at the subcellular level, although the exact mechanism merits further investigation. On the other hand, as microRNAs target multiple molecular pathways simultaneously based on their sequence homology, not on function, it is not surprising that similar changes in serum microRNA levels may be found in different diseases. The mechanism of action of microRNAs is complex and involves a variety of signaling pathways and target genes. For example, studies have shown that miR-106b and miR-93 induce the migration, invasion, and proliferation of cancer cells and simultaneously enhance the activity of the phosphatidylinositol-3 kinase (PI3K)/AKT pathway48. Whether the PI3K/AKT pathway is disturbed in PTSD, other neurological or psychiatric diseases and cancers remains unclear. However, it is likely that PTSD involves dysregulation of multiple pathways.
Limitations
Our discovery sample was modest in size, limiting the identification of subtypes to two groups. Its restriction to males limits its generalizability. Our findings require replication in larger and more diverse samples, including female veterans and trauma-exposed civilians with and without PTSD. Our participants were 6–10 years post their index traumatic events, not allowing for subtyping closer in time to exposure. In addition, we did not include participants with other psychiatric disorders, leaving unanswered the question of whether our findings generalize to severity subgroups of other disorders. While considering a large set of multi-omic blood markers biomarkers, we did not include structural, functional, molecular, and EEG neuroimaging markers, and to do so might have increased classification accuracy of the PTSD subtypes modeled. Identified biomarkers differed between models, but might be highly correlated or otherwise multivariately related. Further exploration is required of identified multivariate marker profiles to clarify their relationship to each other and to severity.
Conclusions
Our findings suggest that male veterans with military service-related PTSD with more severe symptoms across a wide range of clinical scales assessing PTSD and its comorbidities can be biologically distinguished from HC on blood biomarkers most of which are mRNA and methylation markers. Down-regulation of these markers in relationship to severity is suggested while an increase in mean serum lactate levels was noted. There is evidence in the literature that the top five biological markers that differentiated the more severe group from HC are also associated with various neurological and psychiatric illnesses. Biological markers outperform other potential predictor classes—current medical comorbidities, neurocognitive functioning, demographics, pre-military trauma, and psychiatric history—as evidenced by their substantially higher AUCs.
The importance of the associations among the biological features and clinical severity is likely a reflection of a complex disorder. Studies of the mechanistic pathways and similarities with other illnesses may provide directions for future research for understanding the biological basis of PTSD. The use of well-calibrated biological markers for PTSD subtype classification can help bring symptom-based diagnosis to a more objective laboratory basis and facilitate the development of treatments targeted to severity.
Disclaimer
The opinions or assertions contained herein are the private views of the authors and are not to be construed as official, or as reflecting true views of the Department of the Army or the Department of Defense.
References
Blake, D. D. et al. The development of a clinician-administered PTSD scale. J. Trauma. Stress 8, 75–90 (1995).
Weathers, F. W. et al. The clinician-administered PTSD scale for DSM-5 (CAPS-5): development and initial psychometric evaluation in military veterans. Psychol. Assess. 30, 383–395 (2018).
Forbes, D., Elhai, J. D., Miller, M. W. & Creamer, M. Internalizing and externalizing classes in posttraumatic stress disorder: a latent class analysis. J. Trauma. Stress 23, 340–349 (2010).
Lanius, R. A. et al. Emotion modulation in PTSD: clinical and neurobiological evidence for a dissociative subtype. Am. J. Psychiatry 167, 640–647 (2010).
Wolf, E. J. et al. A latent class analysis of dissociation and posttraumatic stress disorder: evidence for a dissociative subtype. Arch. Gen. Psychiatry 69, 698–705 (2012).
Jongedijk, R. A., van der Aa, N., Haagen, J. F. G., Boelen, P. A. & Kleber, R. J. Symptom severity in PTSD and comorbid psychopathology: a latent profile analysis among traumatized veterans. J. Anxiety Disord. 62, 35–44 (2019).
Ben-Zion, Z. et al. Multi-domain potential biomarkers for post-traumatic stress disorder (PTSD) severity in recent trauma survivors. Transl. Psychiatry 10, 208 (2020).
Dean, K. R. et al. Multi-omic biomarker identification and validation for diagnosing warzone-related post-traumatic stress disorder. Mol. Psychiatry 25, 3337–3349 (2020).
Galatzer-Levy, I. R., Ma, S., Statnikov, A., Yehuda, R. & Shalev, A. Y. Utilization of machine learning for prediction of post-traumatic stress: a re-examination of cortisol in the prediction and pathways to non-remitting PTSD. Transl. Psychiatry 7, e1070 (2017).
Samuelson, K. W. et al. Predeployment neurocognitive functioning predicts postdeployment posttraumatic stress in Army personnel. Neuropsychology 34, 276–287 (2020).
Nicholson, A. A. et al. The dissociative subtype of posttraumatic stress disorder: unique resting-state functional connectivity of basolateral and centromedial amygdala complexes. Neuropsychopharmacology 40, 2317–2326 (2015).
Sierk, A., Manthey, A., Brakemeier, E. L., Walter, H., & Daniels, J. K. The dissociative subtype of posttraumatic stress disorder is associated with subcortical white matter network alterations. Brain Imaging Behav. https://doi.org/10.1007/s11682-020-00274-x (2020).
Marmar, C. R. et al. Speech‐based markers for posttraumatic stress disorder in US veterans. Depress. Anxiety 36, 607–616 (2019).
Zhang, Y. et al. Identification of psychiatric disorder subtypes from functional connectivity patterns in resting-state electroencephalography. Nat. Biomed. Eng. https://doi.org/10.1038/s41551-020-00614-8 (2020).
Routing, Y. et al. Epigenetic biotypes of post-traumatic stress disorder in war-zone exposed veteran and active duty males. Mol. Psychiatry https://doi.org/10.1038/s41380-020-00966-2 (2020).
Oberski, D. Human–computer interaction series modern statistical methods for HCI. in Mixture Models: Latent Profile and Latent Class Analysis (eds Robertson, J. & Kaptein, M.) (Springer, Cham, Switzerland 2016).
Cloitre, M., Garvert, D. W., Brewin, C. R., Bryant, R. A., & Maercker, A. Evidence for proposed ICD-11 PTSD and complex PTSD: a latent profile analysis. Eur. J. Psychotraumatol. 4, https://doi.org/10.3402/ejpt.v4i0.20706 (2013).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Kaufman, L & Rousseeuw, P. J. Ch. 2 partitioning around medoids (program pam). in Finding Groups in Data: An Introduction to Cluster Analysis Wiley Series in Probability and Statistics. 68–125 (John Wiley & Sons, Inc, Hoboken, 1990).
Breiman, L. Out-of-bag estimation. (Statistics Department, University of California, 1998).
Genuer, R., Poggi, J. M. & Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 31, 2225–2236 (2010).
Nembrini, S., König, I. R. & Wright, M. N. The revival of the Gini importance? Bioinformatics 34, 3711–3718 (2018).
Dalenberg, C. J., Glaser, D. & Alhassoon, O. M. Statistical support for subtypes in posttraumatic stress disorder: the how and why of subtype analysis. Depress. Anxiety 29, 671–678 (2012).
Marmar, C. R. et al. Course of posttraumatic stress disorder 40 years after the Vietnam War: findings from the National Vietnam Veterans longitudinal study. JAMA Psychiatry 72, 875–881 (2015).
Steenkamp, M. M., Litz, B. T., Hoge, C. W. & Marmar, C. R. Psychotherapy for military-related PTSD: a review of randomized clinical trials. JAMA 314, 489–500 (2015).
Seal, K. H., Bertenthal, D., Miner, C. R., Saunak, S. & Marmar, C. Bringing the war back home: mental health disorders among 103,788 US veterans returning from Iraq and Afghanistan seen at Department of Veterans Affairs facilities. Arch. Intern. Med. 167, 476–482 (2007).
First, M. B., Spitzer, R. L., Gibbon, M. & Williams, J. B. User’s Guide for the Structured Clinical Interview for DSM-IV Axis I Disorders SCID-I: Clinician Version. (Amer. Psychiatric Pub Inc., Washington D.C., 1997).
Marmar, C. R. et al. Peritraumatic dissociation and posttraumatic stress in male Vietnam theater veterans. Am. J. Psychiatry 151, 902–907 (1994).
Yang, R., Daigle, B. J. Jr., Petzold, L. R. & Doyle, F. J. III Core module biomarker identification with network exploration for breast cancer metastasis. BMC Bioinform. 13, 12 (2012).
Chatterjee, N., Shi, J. & García-Closas, M. Developing and evaluating polygenic risk prediction models for stratified disease prevention. Nat. Rev. Genet. 17, 392–406 (2016).
Duncan, L. E. et al. Largest GWAS of PTSD (N=20 070) yields genetic overlap with schizophrenia and sex differences in heritability. Mol. Psychiatry 23, 666–673 (2018).
Team, R. C. R: A language and environment for statistical computing (R Foundation for Statistical Computing, Vienna, 2018).
Ziqiang, L. Subtyping models and clustering. https://github.com/zl138453/Subtype-paper.
Hotelling, H. Relations between two sets of variates. Biometrika. 28, 321–377 (1936).
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Comput. Appl. Math. 20, 53–65 (1987).
Cox, M & Cox, T. Handbook of Data Visualization. Multidimensional Scaling. (Springer: Berlin, 2008). .
Mellon, S. H. et al. Metabolomic analysis of male combat veterans with post traumatic stress disorder. PLoS ONE 14, e0213839 (2019).
Maddock, R. J., Carter, C. S. & Gietzen, D. W. Elevated serum lactate associated with panic attacks induced by hyperventilation. Psychiatry Res. 38, 301–311 (1991).
Rowland, L. M. et al. Elevated brain lactate in schizophrenia: a 7 T magnetic resonance spectroscopy study. Transl. Psychiatry 6, e967 (2016).
Long, H. Y. et al. Blood DNA methylation pattern is altered in mesial temporal lobe epilepsy. Sci. Rep. 7, 43810 (2017).
Ray, M., Ruan, J. & Zhang, W. Variations in the transcriptome of Alzheimer’s disease reveal molecular networks involved in cardiovascular diseases. Genome Biol. 9, R148 (2008).
Martin, J. et al. Biological overlap of attention-deficit/hyperactivity disorder and autism spectrum disorder: evidence from copy number variants. J. Am. Acad. Child Adolesc. Psychiatry 53, 761–770 (2014).
Feliciano, P. et al. Exome sequencing of 457 autism families recruited online provides evidence for autism risk genes. NPJ Genom. Med. 4, 1–14 (2019).
Sabater, L., Gómez-Choco, M., Saiz, A. & Graus, F. BR serine/threonine kinase 2: a new autoantigen in paraneoplastic limbic encephalitis. J. Neuroimmunol. 170, 186–190 (2005).
Camkurt, M. A. et al. Investigation of dysregulation of several microRNAs in peripheral blood of schizophrenia patients. Clin. Psychopharmacol. Neurosci. 14, 256–260 (2016).
Camkurt, M. A. et al. MicroRNA dysregulation in manic and euthymic patients with bipolar disorder. J. Affect. Disord. 261, 84–90 (2020).
Dong, H. et al. Serum microRNA profiles serve as novel biomarkers for the diagnosis of Alzheimer’s disease. Dis. Mark. 2015, 1–11 (2015).
Li, N. et al. MiR-106b and miR-93 regulate cell progression by suppression of PTEN via PI3K/Akt pathway in breast cancer. Cell Death Dis. 8, e2796 (2017).
Acknowledgements
This work was supported by funding from the U.S. Army Research Office, through award numbers W81XWH-18-C-0160 and W911NF-17-1-0069. We gratefully acknowledge discussions on subtyping with Arieh Shalev, MD.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
C.R.M. has received research and clinical program funding from National Institute on Alcohol Abuse and Alcoholism (NIAAA), National Institute of Mental Health (NIMH). Department of Defense (DoD), U.S. Army Medical Research & Acquisition Activity (USAMRA), U.S. Army Telemedicine & Advanced Technology Research Center (TATRC), Steven & Alexandra Cohen Foundation, Cohen Veterans Bioscience (CVB). Cohen Veterans Network (CVN), Robin Hood Foundation. McCormick Foundation, Home Depot Foundation, Bank of America Foundation, Brockman Foundation, Mother Cabrini Foundation, City of New York, has served as a PTSD Fellow for the George W. Bush Institute, is serving on the Scientific Advisory Board, and has equity in Receptor Life Sciences, Inc. is serving on the Clinical Science Advisory Group for Otsuka Pharmaceuticals. C.R.M. and has a pending patent (WO2017172487A1) entitled “Detecting or treating post-traumatic stress syndrome.” K.J.R. serves on advisory boards for Takeda, Janssen, and Verily, and has received sponsored research support from Alkermes, Alto Neuroscience, and Brainsway. He receives funding from the National Institute of Health (NIH) and the Brain and Behavior Research Fund.
Protection of human subjects
The investigators have adhered to the policies for the protection of human subjects as prescribed in AR 70–25 and the IRB of the NYU Grossman School of Medicine. It is a secondary analysis of de-identified data.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Siegel, C.E., Laska, E.M., Lin, Z. et al. Utilization of machine learning for identifying symptom severity military-related PTSD subtypes and their biological correlates. Transl Psychiatry 11, 227 (2021). https://doi.org/10.1038/s41398-021-01324-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41398-021-01324-8
This article is cited by
-
Applications of artificial intelligence−machine learning for detection of stress: a critical overview
Molecular Psychiatry (2024)
-
Deriving psychiatric symptom-based biomarkers from multivariate relationships between psychophysiological and biochemical measures
Neuropsychopharmacology (2022)
-
Identifying subtypes of PTSD to promote precision medicine
Neuropsychopharmacology (2022)
-
Post-traumatic stress disorder: clinical and translational neuroscience from cells to circuits
Nature Reviews Neurology (2022)
