
Abstract
Bipolar disorder (BD) is a highly heritable neuropsychiatric disease characterized by recurrent episodes of depression and mania. Research suggests that the cumulative impact of common alleles explains 25–38% of phenotypic variance, and that rare variants may contribute to BD susceptibility. To identify rare, high-penetrance susceptibility variants for BD, whole-exome sequencing (WES) was performed in three affected individuals from each of 27 multiply affected families from Spain and Germany. WES identified 378 rare, non-synonymous, and potentially functional variants. These spanned 368 genes, and were carried by all three affected members in at least one family. Eight of the 368 genes harbored rare variants that were implicated in at least two independent families. In an extended segregation analysis involving additional family members, five of these eight genes harbored variants showing full or nearly full cosegregation with BD. These included the brain-expressed genes RGS12 and NCKAP5, which were considered the most promising BD candidates on the basis of independent evidence. Gene enrichment analysis for all 368 genes revealed significant enrichment for four pathways, including genes reported in de novo studies of autism (padj < 0.006) and schizophrenia (padj = 0.015). These results suggest a possible genetic overlap with BD for autism and schizophrenia at the rare-sequence-variant level. The present study implicates novel candidate genes for BD development, and may contribute to an improved understanding of the biological basis of this common and often devastating disease.
Similar content being viewed by others

Introduction
Bipolar disorder (BD) is a complex neuropsychiatric disorder characterized by recurrent episodes of mania and depression. BD has a lifetime prevalence of 1%, and an estimated heritability of ~60–85%1,2,3. The World Health Organization ranks BD among the largest contributors to the global burden of disease3.
Genetic linkage studies, candidate gene studies, and genome-wide association studies (GWAS) have generated initial insights into the genetic architecture of BD. Recent GWAS have identified several common susceptibility loci for BD4,5,6,7,8,9. However, BD-driving pathways and networks remain largely unknown10. Models of BD are consistent with a polygenic contribution of common and rare variants to disease susceptibility11. Research has demonstrated that the cumulative impact of common alleles explains an estimated 25–38% of BD phenotypic variance12,13. Another substantial contribution to BD susceptibility is expected to come from rare variants14. A promising approach to the identification of rare, high-penetrance variants in BD is the investigation of large, multiply affected pedigrees. In these families, the existence of a co-segregating genetic variant of strong effect may be more likely than in sporadic patients10,15.
Initial whole-exome and whole-genome sequencing studies of BD patients have implicated a number of candidate genes. Preliminary results suggest an enrichment of rare genetic variants in: (i) specific gene sets, i.e., calcium signaling, axon guidance, cyclic adenosine monophosphate response element binding protein (CREB) signaling, potassium channels, and G protein-coupled receptors16,17,18,19,20,21; and (ii) genes that have been reported to harbor de novo nonsense and missense variants in studies of schizophrenia and autism22. Furthermore, a trio-based exome-sequencing study suggested that de novo variants may also be implicated in BD etiology, particularly, in patients with an early age of onset23. However, limited overlap in implicated genes is evident between studies, suggesting that the analysis of further pedigrees and samples is warranted before definitive conclusions can be drawn10.
The aim of the present study was to identify rare, high-penetrance susceptibility variants for BD via whole-exome sequencing (WES) in large BD pedigrees from Spain and Germany.
Materials and methods
Sample description
A total of 27 multigenerational, multiply affected Spanish (n = 23) and German (n = 4) families were investigated. A detailed description of the phenotypic assessment of the Spanish families is provided elsewhere24. In brief, the diagnostic assessment of affected and unaffected individuals in the Spanish families was performed using: the Schedule for Affective Disorders and Schizophrenia (SADS)25; the Operational Criteria Checklist for Psychotic Illness (OPCRIT)26; a review of medical records; and interviews with first and/or second-degree family members using the Family Informant Schedule and Criteria (FISC)27. Consensus best estimate diagnoses were assigned by two or more independent senior psychiatrists and/or psychologists, in accordance with the Diagnostic and Statistical Manual of Mental Disorders IV (DSM IV). In affected and unaffected members of the German families, phenotypic assessment and the assignment of diagnoses were performed by an experienced psychiatrist28.
No relationships were reported between the 27 individual families. In each of the 27 families, three individuals with BD were selected for WES (Supplementary Figure 1). These individuals were selected on the basis of being as distantly genetically-related as possible. The 81 selected individuals (37.0% male) had a DSM IV diagnosis of BD type I (n = 69); BD type II (n = 9); or BD not otherwise specified (NOS, n = 3).
The study was approved by the respective local ethics committees. Written informed consent was obtained from all participants prior to inclusion.
WES
Library enrichment for WES was conducted using SureSelectXTHuman All Exon v5 from Agilent Technologies (Santa Clara, CA, USA). Enriched samples were sequenced using an Illumina HiSeq2500 system (San Diego, CA, USA), and a 2 × 125 base pair (bp) paired end sequencing approach. Mean coverage of the sequences was 68.28×, and 96.90% of the sequencing reads had a coverage of >10×. Sequencing data were annotated according to the GRCh37/hg19 reference genome. The sequencing data are available upon request.
A detailed plan of the analytical steps is presented in the Supplement (Supplementary Figure 2). In a first step, separate analyses were conducted for each of the 27 families. For each of the three selected family members, Variant Calling Files were generated using the VARBANK pipeline (https://varbank.ccg.uni-koeln.de). The VARBANK pipeline integrates a number of publically available sequencing analysis tools. Among others, various GATK tools are used for diverse processing steps. The VARBANK pipeline is therefore based on GATK core components. VARBANK filter criteria were set for the detection of heterozygous variants (allele read frequency between 25% and 75%). Sequencing reads with a coverage of ≥10× were included in the subsequent analyses. The analyses focused on single-nucleotide variants/polymorphisms (SNVs, SNPs) and insertions or deletions (InDels) that: (i) resulted in an alteration in primary protein structure; or (ii) had strong splice site effects29. Only variants shared by all three investigated family members were included in the subsequent variant analysis, as these variants might be responsible for the exceptional aggregation of BD in the respective multiply affected families. The present rationale is based on the assumption that in multiply affected families, individual rare variants with a relatively strong effect (penetrance) on disease development may segregate. By concentrating solely on variants that were present in all three sequenced patients, the analysis focused on variants with a potentially high penetrance, and knowingly overlooked rare, disease-associated variants with lower penetrance. Although the term “segregation” is used in describing the exome-sequencing results, it should be noted that only “allele sharing” is actually observed. However, owing to the rarity of the identified variants, the observation of allele sharing between three exome-sequenced individuals from a given family is likely to reflect true segregation (i.e., identity-by-state = identity-by-descent).
The identified variants were filtered for a minor allele frequency (MAF) < 0.1% using the data of the Exome Aggregation Consortium (ExAC, http://exac.broadinstitute.org, release 0.3, non-psychiatric subsets)30. The majority of ExAC data originate from Europe (around 60%), and were thus considered appropriate in terms of estimating the MAF of variants identified in the present cohort.
To obtain functional predictions for the identified variants, the dbNSFP database was accessed. In accordance with Purcell et al.31,32,33, the five prediction tools SIFT, PolyPhen-2 HumDiv, PolyPhen-2 HumVar, LRT, and MutationTaster were used for the analysis of SNVs and SNPs. Only variants predicted to be potentially/probably damaging by at least three of the five prediction tools were included in the final list (Supplementary Table 1). For the analysis of InDels, the prediction tools MutationTaster and PROVEAN/SIFT were used. Only InDels predicted to be damaging by at least one of the three prediction tools were included in the subsequent analyses. Owing to their potential impact on protein function, nonsense variants that were classified as (probably) disease causing by the MutationTaster tool were included in the final list (Supplementary Table 1). For each of the identified variants, visual inspection of the sequencing reads in the VARBANK database was performed in order to control for technical artifacts.
Kinship analysis
A kinship analysis was conducted for the 81 exome-sequenced individuals from the 27 multiplex families using the Sample Kinship analysis tool within the VARBANK pipeline. This tool determines the proportion of alleles that are shared between pairs of individuals. The thresholds for shared variant analysis are: MAF < 0.1%; target distance < 100 bp; and passing of GATK’s variant quality score recalibration filter. The resulting values are the number and percentage of shared alleles. The results report the pairwise comparison of one individual with all other individuals within the investigated cohort.
Technical validation and extended segregation analyses
Using Sanger sequencing, technical validation and extended segregation analyses were performed for variants that were both: (i) rare, non-synonymous, and predicted to be potentially/probably damaging according to the above-mentioned criteria; and (ii) located in genes that harbored variants in at least two independent families. Extended segregation analysis was conducted in all family members (affected and unaffected) for whom DNA was available (Supplementary Figure 1). Primers for these experiments were designed using Primer334. Cycle Sequencing was conducted with the BigDye Terminator v3.1. Sanger sequencing was conducted using an ABI3130 Genetic Analyzer (Life Technologies, Carlsbad, CA, USA). Primer sequences and PCR conditions are obtainable upon request.
Rare variant association testing using RareIBD
RareIBD analyses were performed for the 16 rare variants that were investigated in the extended segregation analysis. RareIBD is a rare variant association method for large and extended pedigrees. RareIBD was selected as it is applicable to pedigrees with different family structures and those in which individuals in the top generations are missing35. RareIBD analysis (v1.2, http://genetics.bwh.harvard.edu/rareibd/) was conducted using the segregation analysis data of all family members for whom DNA was available. For the RareIBD analysis, individuals were defined as being affected if they were diagnosed with BD type I, BD type II, or BD NOS. All other individuals were defined as unaffected. RareIBD software settings were applied in accordance with the standard recommendations for the analysis. The resulting p values were Bonferroni-corrected for multiple testing according to the number of investigated variants (n = 16). For the quality control of the generated pedigree files, pedigrees were drawn using the CRAN-package kinship2, and the generated figures were then inspected to confirm correct family structure36.
Brain expression of candidate genes
To determine whether candidate genes identified in the WES analyses are expressed in the human brain, the Genotype-Tissue Expression (GTEx) database was accessed (https://gtexportal.org/)37. The GTEx Portal comprises expression data from multiple brain regions. Using the GTEx data, average expression values were generated for 12 different brain regions (excluding the spinal cord). Genes with a mean expression of > 0.5 Reads Per Kilobase Million were considered brain-expressed.
Investigation of identified candidate genes in published datasets
A literature search was conducted to determine whether candidate genes identified in the present study had been reported in previous independent next-generation sequencing studies of BD patients or in BD GWAS8,9,18,19,20,22,23,38,39,40,41,42.
Gene set enrichment analysis
For the 368 genes that harbored rare, non-synonymous, and segregating variants, a systematic investigation of gene set enrichment was performed using the permutation-based method described in Goes et al.22, in order to account for potential confounders, such as coding length, sequencing coverage, and overall mutability. Testing was performed for an enrichment of genes reported in previous de novo studies of autism and schizophrenia, and genes encoding postsynaptic density (PSD) proteins or targets of the fragile X mental retardation protein (FMRP)22. In brief, curated gene lists were retrieved from studies that had summarized genes with de novo nonsense and missense variants in autism (n = 1781), and schizophrenia (n = 670), as well as genes encoding proteins found in the PSD (n = 1398) and the FMRP pathway (n = 795)43,44. Newly curated lists of de novo autism and schizophrenia gene sets were also included in the permutation-based gene set enrichment analysis. The novel autism gene set was downloaded from the database de novo-db (version 1.5) and annotated using the Variant Effect Predictor (VEP) tool45,46. Non-synonymous variants that showed an association with a primary autism phenotype were selected, resulting in a set of 3679 genes. The novel schizophrenia gene set was compiled from seven published whole-exome studies of schizophrenia trios44,47,48,49,50,51,52. All available exonic variants were combined and re-annotated using the VEP tool, which is based on the Gencode v19 genome build46. The novel schizophrenia data set comprised 714 genes with at least one de novo non-synonymous variant.
The permutation-based gene set enrichment analysis was also performed for 55 additional gene sets that had shown association with BD in previous sequencing studies or GWAS9,16,17,20,21,53. Where possible, the original pathway definitions given in the respective studies were used. When this was not possible, current pathway definitions were obtained from the databases Gene Ontology (GO, http://geneontology.org/); Kyoto Encyclopedia of Genes and Genomes (KEGG, https://www.genome.jp/kegg/); and Molecular Signatures Database (MSigDB, software.broadinstitute.org/gsea/msigdb)54,55,56,57,58,59.
Tests were then conducted to determine whether the 368 genes that harbored rare non-synonymous segregating variants in the present cohort were enriched for any of these 61 gene sets. The gene set enrichment analysis was also performed for 139 genes that harbored rare non-synonymous segregating variants, which were predicted to be potentially/probably damaging by all applied prediction tools.
An equal number of genes captured by the present WES study were selected at random and matched with our candidate genes for the following three potentially confounding metrics: cumulative exon length (± 20%); sequence coverage (± 20%); and a gene-specific measure of intolerance to missense variation (ExAC missense constraint z score). A total of 10,000 permutations were performed, and the number of times that randomly selected genes were found in each of the gene sets was counted. To obtain empirical p values, a comparison was made between the observed degree of overlap and gene sets with this null distribution.
The Benjamini & Hochberg method was applied to the resulting 122 p values in order to perform a false discovery rate correction. Adjusted p values of < 0.05 were considered statistically significant.
Results
The kinship analysis revealed that individuals from different families shared a maximum of 3% of rare variants, which corresponds to a relationship that is more distant than second-degree cousin status. The analysis therefore confirmed the absence of close genetic relationships between the 27 investigated families.
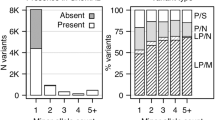
WES revealed that a total of 378 rare, non-synonymous, and potentially functional variants were carried by all three investigated members in at least one family. These 378 variants spanned a total of 368 genes (Supplementary Table 1). Eight of these genes harbored rare segregating variants in at least two independent families (ADGB, DCAF5, NCKAP5, PKHD1L1, AOAH, CAND2, DIDO1, and RGS12; Table 1). All of the 16 rare variants detected in these eight genes were validated by Sanger sequencing (validation rate of 100%). Re-analysis of data from the GTEx database revealed that six of the eight genes are expressed in the human brain (Table 2). The two exceptions were PKHD1L1 and ADGB.
Extended segregation analysis of these 16 rare variants revealed that the variants in ADGB, DCAF5, NCKAP5, PKHD1L1, and RGS12 might display high penetrance. In contrast, rare variants in AOAH, CAND2, and DIDO1 were also detected in several unaffected family members, suggesting that these variants are less likely to be highly penetrant (Table 2).
In the RareIBD association analysis, two variants showed a nominally significant association with disease status: (i) variant p.N4041Y in the PKHD1L1 gene (pnom = 0.0305); and (ii) variant p.R923Q in DCAF5 (family 0009, pnom = 0.0097). However, neither of these associations withstood stringent Bonferroni correction for multiple testing (Table 2).
A total of 139 genes harbored rare, non-synonymous variants that were carried by all three affected family members and predicted to be potentially/probably damaging by all applied prediction tools. A broader list of rare segregating variants, which were predicted to be potentially/probably damaging by at least one of the applied tools, is provided in the Supplement (Supplementary Table 2).
Analyses were performed to determine whether any of the 368 genes with rare and potentially functional variants have been implicated in previous next-generation sequencing studies or GWAS of BD. This revealed a total of 19 overlapping genes. These included ANK3, which has been implicated in both BD GWAS and sequencing studies (Table 3).
Permutation-based gene set enrichment analyses for the 368 genes revealed significant enrichment for a total of four gene sets after correction for multiple testing (Table 4). Of the four gene sets investigated in Goes et al.22, a significant enrichment was found for the de novo autism gene set (81 observed vs. 44.4 expected, padj < 0.006, Table 4). Analyses of the larger, newly curated de novo autism and schizophrenia gene sets both revealed significant enrichment (padj < 0.006 and padj = 0.015, respectively; Table 4). Of the 55 additional gene sets that had shown association with BD in previous studies, only “Regulation of anatomical structure size” showed a significant enrichment in the present study (padj = 0.015).
In the gene set enrichment analyses for the 139 genes (harboring rare non-synonymous variants predicted to be potentially/probably damaging by all applied prediction tools), none of the tested pathways showed a significant enrichment after correction for multiple testing. However, 10 gene sets showed a nominally significant enrichment. These included the de novo autism gene set from Goes et al.22, and the two larger, newly curated de novo autism and schizophrenia gene sets (Supplementary Table 3).
Discussion
In the present WES investigation of 81 affected individuals from 27 multigenerational and multiply affected BD families, a total of 378 rare, non-synonymous, and potentially functional variants were carried by all three investigated members of at least one family. These variants were located in 368 genes. Eight of these genes harbored rare segregating variants in two independent families. In the extended segregation analysis, five of these genes carried variants with full or nearly full penetrance. The lack of formal statistical evidence in the RareIBD analysis was probably attributable to the limited sizes of the pedigrees.
These five genes included the brain-expressed genes RGS12 and NCKAP5, which were considered the most promising BD candidates on the basis of independent evidence. The brain-expressed gene RGS12 is located on chromosome 4p16.3, and belongs to the GTPase activating protein (GAP) family. GAPs are regulators of heterotrimeric G-proteins, and facilitate the hydrolyzing of the alpha subunits from GTP. The RGS proteins thereby drive G-proteins into an inactive GDP form, which results in the downregulation of GPCR signaling60,61. In a GWAS of 24,025 patients and controls, the present authors identified common variation in ADCY2 as a risk factor for BD8. Interestingly, ADCY2 is regulated by heterotrimeric G-proteins, which provides further evidence for the involvement of this pathway in BD development62. RGS12 is also of interest in terms of its functional role in the coordination of Ras-dependent signals, which are necessary for the promotion and/or maintenance of neuronal differentiation63. In addition, WES studies identified rare de novo missense mutations in RGS12 in two independent schizophrenia patients (p.P518L and p.R702L)52,64. In view of the reported genetic overlap between schizophrenia and BD13, this finding renders RGS12 a highly promising candidate in terms of follow-up analyses.
To date, NCKAP5 has been implicated in GWAS of BD, schizophrenia, hypersomnia, personality traits, and mood states65,66,67,68. This cumulative evidence for an association with neuropsychiatric disease and other phenotypes, combined with the present WES finding, suggests that NCKAP5 may contribute to the development and maintenance of a broad spectrum of psychiatric disorders, including BD. However, the function of NCKAP5 remains unknown, which precludes speculation concerning biological processes of relevance to BD.
In the gene DCAF5, the same variant (p.R923Q) was found in two independent families (Table 2). Furthermore, in family 0009, the variant showed a nominally significant association in the RareIBD analysis (pnom = 0.0097, pcorr = 0.1552). The DCAF5 gene encodes the DDB1 and CUL4 associated factor 5. Rare chromosomal microdeletions involving DCAF5 have been described in patients with intellectual disability, congenital heart defects, and facial dysmorphism69. However, no association with psychiatric disorders has yet been reported. A plausible hypothesis is that the identified variant has a higher allele frequency in the Spanish population than in the ExAC data used for the estimation of variant frequency in the present study. However, the kinship analysis confirmed the absence of any close genetic relationship between the 27 investigated families.
A comparison of the 368 genes implicated in the present study with those identified in previous BD GWAS and sequencing studies revealed a total of 19 overlapping genes (Table 3). Interestingly, these included several genes of relevance to the cytoskeleton, e.g., ANK3, MACF1, MYO10, and SYNE170. This is consistent with the findings of previous studies, which suggested a potential contribution of cytoskeleton pathways to BD etiology71,72.
The 378 identified rare genetic variants showed significant enrichment in the de novo autism gene set retrieved from Goes et al.22 (padj < 0.006), as well as in the larger, newly curated de novo autism gene set (padj < 0.006). These results support the findings of the exome-sequencing study by Goes et al.22, which investigated 36 cases from eight multiply affected BD families. The present data and those of Goes et al. add to accumulating evidence of an etiological genetic overlap between BD and autism73,74,75.
For the three remaining gene sets retrieved from Goes et al.22, no significant enrichment was detected after correction for multiple testing. However, the analysis of the larger, newly curated de novo schizophrenia gene set revealed significant enrichment (padj = 0.015). This provides further evidence for a substantial genetic correlation between BD and schizophrenia at the rare-sequence-variant level22.
Of the 55 additional gene sets that have shown association with BD in previous studies, only “Regulation of anatomical structure size” showed a significant enrichment in the present study (padj = 0.015; Supplementary Table 3). This gene set was reported to be associated with BD in the pathway analysis of GWAS data performed by the Psychiatric Genomics Consortium53. The gene set contains 472 genes with an involvement in processes that modulate the size of anatomical structures54,55.
The aim of the present enrichment analysis was to enable a comprehensive investigation of gene sets with a previously reported association with BD in our 27 multiply affected families. The findings of previous studies are at least partially heterogeneous, as: (i) the previously reported associations are based on different datasets (i.e., common variants in GWAS vs. rare variants in sequencing studies); (ii) the various studies investigated individuals of different ethnicities; and (iii) the various sequencing studies applied different strategies, filter criteria, and enrichment analysis methods. This may be one reason for the relatively small overlap with previously reported BD associations found in the present study. Alternatively, this small overlap may be attributable to the presence of very pronounced inter-familial heterogeneity with respect to individual disease genes/pathways. To assess this, future analyses, involving uniform methods and filter strategies and large BD samples, are required.
The present WES step was restricted to BD cases only. The main reason for this approach was to facilitate data analysis, which had to take into account the different family structures. The possible presence of a candidate variant in unaffected family members was not an exclusion criterion, as available data on the genetic architecture of psychiatric disorders suggest that such variants have reduced penetrance76. To determine their degree of penetrance, a post hoc segregation analysis of the identified candidate variants was performed. The presence of a high-penetrance variant in a large proportion of older, unaffected individuals of a pedigree is unlikely. Of the 16 identified variants (Table 2), three were detected in several unaffected family members, which suggests that they are less likely to be highly penetrant. However, given the small number of affected and unaffected individuals on which they are based, estimations of penetrance must be viewed with great caution.
The power of the present study to detect strong association between rare variants and BD was limited. Previous authors have discussed potential determinants of the statistical power for calculating associations between a phenotype and rare variants, including study design, selected MAF cutoffs, and sample size77,78. To confirm the associations identified in the present study, replication studies and comprehensive analyses in additional, densely affected families are warranted. This could be achieved via combined analyses of exome-sequencing data in international Consortia, such as the Bipolar Sequencing Consortium79. To reduce genetic heterogeneity, investigation of families with an accumulation of distinct subphenotypes could also be considered. The investigation of such families might also generate novel insights into differences in the genetic background of diverse clinical presentations18,80.
The present analyses focused on rare variants (MAF < 0.1%) with strong predicted effects on protein function. As rare variants with moderate effects may also contribute to BD susceptibility, a second filtering step was performed using relaxed criteria with regard to the applied prediction tools (broader variant list in Supplementary Table 2). Future studies of a larger number of multiplex families are required to: (i) assess their relevance in terms of BD etiology; and (ii) investigate the potential contribution of rare and low-frequency variants with a higher MAF (0.1–5%) to the high prevalence of BD in these families.
A limitation of the present study was that the estimation of the MAFs was based on reference data from the ExAC30. These data include diverse ethnicities and represent a mixture of different populations with a focus on European samples, which should largely correspond to the ethnicity of the Spanish and German populations81. To determine the exact ethnicity of the investigated families, further analyses are necessary, e.g., a principal component analysis using genome-wide genotype data. The present authors are currently generating these data within the frame-work of a follow-up study.
In conclusion, rare and potentially functional variants identified in 27 multiply affected Spanish and German families implicated a total of 368 genes in BD etiology. Eight of these genes were detected in at least two independent families. The most promising variants were identified in the gene RGS12, which has been reported in previous next-generation sequencing studies of schizophrenia. Gene set analysis provided further evidence for a significant enrichment of rare segregating variants in genes reported in de novo studies of autism and schizophrenia, which suggests a possible genetic overlap of BD with autism and schizophrenia at the level of rare-sequence variants. The present data suggest novel BD candidate genes, and may contribute to an improved understanding of the biological basis of this common and often devastating disease.
References
Bienvenu, O. J., Davydow, D. S. & Kendler, K. S. Psychiatric ‘diseases’ versus behavioral disorders and degree of genetic influence. Psychol. Med. 41, 33–40 (2011).
Lichtenstein, P. et al. Common genetic determinants of schizophrenia and bipolar disorder in Swedish families: a population-based study. Lancet 373, 234–239 (2009).
Merikangas, K. R. et al. Prevalence and correlates of bipolar spectrum disorder in the world mental health survey initiative. Arch. Gen. Psychiatry 68, 241–251 (2011).
Ferreira, M. A. et al. Collaborative genome-wide association analysis supports a role for ANK3 and CACNA1C in bipolar disorder. Nat. Genet. 40, 1056–1058 (2008).
Psychiatric GWAS Consortium Bipolar Disorder Working Group. Large-scale genome-wide association analysis of bipolar disorder identifies a new susceptibility locus near ODZ4. Nat. Genet. 43, 977–983 (2011).
Cichon, S. et al. Genome-wide association study identifies genetic variation in neurocan as a susceptibility factor for bipolar disorder. Am. J. Hum. Genet. 88, 372–381 (2011).
Chen, D. T. et al. Genome-wide association study meta-analysis of European and Asian-ancestry samples identifies three novel loci associated with bipolar disorder. Mol. Psychiatry 18, 195–205 (2013).
Mühleisen, T. W. et al. Genome-wide association study reveals two new risk loci for bipolar disorder. Nat. Commun. 5, 3339 (2014).
Stahl, E. A. et al. Genome-wide association study identifies 30 loci associated with bipolar disorder. Nat. Genet. 51, 793–803 (2019).
Maaser, A. et al. Exome sequencing in large, multiplex bipolar disorder families from Cuba. PLoS ONE 13, e0205895 (2018).
Craddock, N. & Sklar, P. Genetics of bipolar disorder. Lancet 381, 1654–1662 (2013).
Lee, S. H., Wray, N. R., Goddard, M. E. & Visscher, P. M. Estimating missing heritability for disease from genome-wide association studies. Am. J. Hum. Genet. 88, 294–305 (2011).
Lee, S. H. et al. Genetic relationship between five psychiatric disorders estimated from genome-wide SNPs. Nat. Genet. 45, 984–994 (2013).
Wainschtein, P. et al. Recovery of trait heritability from whole genome sequence data. Preprint at https://www.biorxiv.org/content/10.1101/588020v1 (2019).
Collins, A. L. et al. Identifying bipolar disorder susceptibility loci in a densely affected pedigree. Mol. Psychiatry 18, 1245–1246 (2013).
Cruceanu, C. et al. Rare susceptibility variants for bipolar disorder suggest a role for G protein-coupled receptors. Mol. Psychiatry 23, 2050–2056 (2018).
Chen, Y. C. et al. A hybrid likelihood model for sequence-based disease association studies. PLoS Genet. 9, e1003224 (2013).
Cruceanu, C. et al. Family-based exome-sequencing approach identifies rare susceptibility variants for lithium-responsive bipolar disorder. Genome 56, 634–640 (2013).
Kerner, B. et al. Rare genomic variants link bipolar disorder with anxiety disorders to CREB-regulated intracellular signaling pathways. Front. Psychiatry 4, 154 (2013).
Strauss, K. A. et al. A population-based study of KCNH7 p.Arg394His and bipolar spectrum disorder. Hum. Mol. Genet. 23, 6395–6406 (2014).
Ament, S. A. et al. Rare variants in neuronal excitability genes influence risk for bipolar disorder. Proc. Natl Acad. Sci. USA 112, 3576–3581 (2015).
Goes, F. S. et al. Exome sequencing of familial bipolar disorder. JAMA Psychiatry 73, 590–597 (2016).
Kataoka, M. et al. Exome sequencing for bipolar disorder points to roles of de novo loss-of-function and protein-altering mutations. Mol. Psychiatry 21, 885–893 (2016).
Guzman-Parra, J. et al. The Andalusian Bipolar Family (ABiF) Study: protocol and sample description. Rev. Psiquiatr. Salud. Ment. 11, 199–207 (2018).
Endicott, J. & Spitzer, R. L. A diagnostic interview: the schedule for affective disorders and schizophrenia. Arch. Gen. Psychiatry 35, 837–844 (1978).
McGuffin, P., Farmer, A. & Harvey, I. A polydiagnostic application of operational criteria in studies of psychotic illness. Development and reliability of the OPCRIT system. Arch. Gen. Psychiatry 48, 764–770 (1991).
Mannuzza, S., Fyer, A. J., Endicott, J., Klein, D. F. & Robins, L. Family Informant Schedule and Criteria (FISC). Anxiety Disorders Clinic, New York State Psychiatric Institute, New York (1985).
Reif, A. et al. A neuronal nitric oxide synthase (NOS-I) haplotype associated with schizophrenia modifies prefrontal cortex function. Mol. Psychiatry 11, 286–300 (2006).
Yeo, G. & Burge, C. B. Maximum entropy modeling of short sequence motifs with applications to RNA splicing signals. J. Comput. Biol. 11, 377–394 (2004).
Lek, M. et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature 536, 285–291 (2016).
Purcell, S. M. et al. A polygenic burden of rare disruptive mutations in schizophrenia. Nature 506, 185–190 (2014).
Liu, X., Jian, X. & Boerwinkle, E. dbNSFP: a lightweight database of human nonsynonymous SNPs and their functional predictions. Hum. Mutat. 32, 894–899 (2011).
Liu, X., Jian, X. & Boerwinkle, E. dbNSFP v2.0: a database of human non-synonymous SNVs and their functional predictions and annotations. Hum. Mutat. 34, E2393–2402 (2013).
Untergasser, A. et al. Primer3–new capabilities and interfaces. Nucleic Acids Res. 40, e115 (2012).
Sul, J. H. et al. Increasing generality and power of rare-variant tests by utilizing extended pedigrees. Am. J. Hum. Genet. 99, 846–859 (2016).
Sinnwell, J. P., Therneau, T. M. & Schaid, D. J. The kinship2 R package for pedigree data. Hum. Hered. 78, 91–93 (2014).
GTEx Consortium. The Genotype-Tissue Expression (GTEx) project. Nat. Genet. 45, 580–585 (2013).
Fiorentino, A. et al. Analysis of ANK3 and CACNA1C variants identified in bipolar disorder whole genome sequence data. Bipolar Disord. 16, 583–591 (2014).
Green, E. K. et al. Association at SYNE1 in both bipolar disorder and recurrent major depression. Mol. Psychiatry 18, 614–617 (2013a).
Georgi, B. et al. Genomic view of bipolar disorder revealed by whole genome sequencing in a genetic isolate. PLoS Genet. 10, e1004229 (2014).
Green, E. K. et al. Replication of bipolar disorder susceptibility alleles and identification of two novel genome-wide significant associations in a new bipolar disorder case-control sample. Mol. Psychiatry 18, 1302–1307 (2013b).
Chen, D. T. et al. Genome-wide association study meta-analysis of European and Asian-ancestry samples identifies three novel loci associated with bipolar disorder. Mol. Psychiatry 18, 195–205 (2013).
Iossifov, I. et al. The contribution of de novo coding mutations to autism spectrum disorder. Nature 515, 216–221 (2014).
Fromer, M. et al. De novo mutations in schizophrenia implicate synaptic networks. Nature 506, 179–184 (2014).
Turner, T. N. et al. denovo-db: a compendium of human de novo variants. Nucleic Acids Res 45, D804–D811 (2017).
McLaren, W. et al. The ensembl variant effect predictor. Genome Biol. 17, 122 (2016).
Girard, S. L. et al. Increased exonic de novo mutation rate in individuals with schizophrenia. Nat. Genet. 43, 860–863 (2011).
Xu, B. et al. De novo gene mutations highlight patterns of genetic and neural complexity in schizophrenia. Nat. Genet. 44, 1365–1369 (2012).
Takata, A., Ionita-Laza, I., Gogos, J. A., Xu, B. & Karayiorgou, M. De novo synonymous mutations in regulatory elements contribute to the genetic etiology of autism and schizophrenia. Neuron 89, 940–947 (2016).
McCarthy, S. E. et al. De novo mutations in schizophrenia implicate chromatin remodeling and support a genetic overlap with autism and intellectual disability. Mol. Psychiatry 19, 652–658 (2014).
Gulsuner, S. et al. Spatial and temporal mapping of de novo mutations in schizophrenia to a fetal prefrontal cortical network. Cell 154, 518–529 (2013).
Guipponi, M. et al. Exome sequencing in 53 sporadic cases of schizophrenia identifies 18 putative candidate genes. PLoS ONE 9, e112745 (2014).
Network and Pathway Analysis Subgroup of Psychiatric Genomics Consortium. Psychiatric genome-wide association study analyses implicate neuronal, immune and histone pathways. Nat. Neurosci. 18, 199–209 (2015).
Ashburner, M. et al. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 25, 25–29 (2000).
The Gene Ontology Consortium. The Gene Ontology Resource: 20 years and still GOing strong. Nucleic Acids Res. 47, D330–D338 (2019).
Kanehisa, M. & Goto, S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 28, 27–30 (2000).
Kanehisa, M., Sato, Y., Furumichi, M., Morishima, K. & Tanabe, M. New approach for understanding genome variations in KEGG. Nucleic Acids Res. 47, D590–D595 (2019).
Kanehisa, M. Toward understanding the origin and evolution of cellular organisms. Protein Sci. 28, 1947–1951 (2019).
Subramanian, A. et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl Acad. Sci. USA 102, 15545–15550 (2005).
Ross, E. M. & Wilkie, T. M. GTPase-activating proteins for heterotrimeric G proteins: regulators of G protein signaling (RGS) and RGS-like proteins. Annu Rev. Biochem. 69, 795–827 (2000).
Snow, B. E. et al. GTPase activating specificity of RGS12 and binding specificity of an alternatively spliced PDZ (PSD-95/Dlg/ZO-1) domain. J. Biol. Chem. 273, 17749–17755 (1998).
Ostrom, R. S., Bogard, A. S., Gros, R. & Feldman, R. D. Choreographing the adenylyl cyclase signalosome: sorting out the partners and the steps. Naunyn. Schmiedebergs Arch. Pharm. 385, 5–12 (2012).
Willard, M. D. et al. Selective role for RGS12 as a Ras/Raf/MEK scaffold in nerve growth factor-mediated differentiation. EMBO J. 26, 2029–2040 (2007).
Xu, B. et al. Exome sequencing supports a de novo mutational paradigm for schizophrenia. Nat. Genet. 43, 864–868 (2011).
Khor, S. S. et al. Genome-wide association study of HLA-DQB1*06:02 negative essential hypersomnia. PeerJ 1, e66 (2013).
Luciano, M. et al. Genome-wide association uncovers shared genetic effects among personality traits and mood states. Am. J. Med. Genet B Neuropsychiatr. Genet. 159B, 684–695 (2012).
Wang, K. S., Liu, X. F. & Aragam, N. A genome-wide meta-analysis identifies novel loci associated with schizophrenia and bipolar disorder. Schizophr. Res. 124, 192–199 (2010).
Smith, E. N. et al. Genome-wide association study of bipolar disorder in European American and African American individuals. Mol. Psychiatry 14, 755–763 (2009).
Oehl-Jaschkowitz, B. et al. Deletions in 14q24.1q24.3 are associated with congenital heart defects, brachydactyly, and mild intellectual disability. Am. J. Med. Genet. A 164A, 620–626 (2014).
O’Leary, N. A. et al. Reference sequence (RefSeq) database at NCBI: current status, taxonomic expansion, and functional annotation. Nucleic Acids Res. 44, D733–745 (2016).
Zhao, Z. et al. Transcriptome sequencing and genome-wide association analyses reveal lysosomal function and actin cytoskeleton remodeling in schizophrenia and bipolar disorder. Mol. Psychiatry 20, 563–572 (2015).
Benitez-King, G. et al. The microtubular cytoskeleton of olfactory neurons derived from patients with schizophrenia or with bipolar disorder: Implications for biomarker characterization, neuronal physiology and pharmacological screening. Mol. Cell Neurosci. 73, 84–95 (2016).
Song, J. et al. Bipolar disorder and its relation to major psychiatric disorders: a family-based study in the Swedish population. Bipolar Disord. 17, 184–193 (2015).
Selten, J. P., Lundberg, M., Rai, D. & Magnusson, C. Risks for nonaffective psychotic disorder and bipolar disorder in young people with autism spectrum disorder: a population-based study. JAMA Psychiatry 72, 483–489 (2015).
Green, E. K. et al. Copy number variation in bipolar disorder. Mol. Psychiatry 21, 89–93 (2016).
Marshall, C. R. et al. Contribution of copy number variants to schizophrenia from a genome-wide study of 41,321 subjects. Nat. Genet. 49, 27–35 (2017).
Bansal, V., Libiger, O., Torkamani, A. & Schork, N. J. Statistical analysis strategies for association studies involving rare variants. Nat. Rev. Genet. 11, 773–785 (2010).
Ionita-Laza, I. & Ottman, R. Study designs for identification of rare disease variants in complex diseases: the utility of family-based designs. Genetics 189, 1061–1068 (2011).
Shinozaki, G. & Potash, J. B. New developments in the genetics of bipolar disorder. Curr. Psychiatry Rep. 16, 493 (2014).
Benazzi, F. Classifying mood disorders by age-at-onset instead of polarity. Prog. Neuropsychopharmacol. Biol. Psychiatry 33, 86–93 (2009).
Nelis, M. et al. Genetic structure of Europeans: a view from the North-East. PLoS ONE 4, e5472 (2009).
Adzhubei, I., Jordan, D. M. & Sunyaev, S. R. Predicting functional effect of human missense mutations using PolyPhen-2. Curr. Protoc. Hum. Genet. Chapter 7, Unit7.20 (2013).
Acknowledgements
We thank Christine Schmäl for her critical reading of the manuscript. The study was supported by the German Federal Ministry of Education and Research (BMBF) through the Integrated Network IntegraMent (Integrated Understanding of Causes and Mechanisms in Mental Disorders), under the auspices of the e:Med Programme (grant 01ZX1314A/01ZX1614A to M.M.N. and S.C., grant 01ZX1314G/01ZX1614G to M.R.) and through ERA-NET NEURON, “SynSchiz—Linking synaptic dysfunction to disease mechanisms in schizophrenia—a multilevel investigation“ (01EW1810 to MR). The study was also supported by the German Research Foundation (DFG; grant FOR2107; RI908/11-1 and RI908/11–2 to M.R.; NO246/10-1 and NO 246/10-2 to M.M.N.), and the Swiss National Science Foundation (SNSF, grant 156791 to S.C.). M.M.N. is a member of the DFG-funded Excellence-Cluster ImmunoSensation.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Forstner, A.J., Fischer, S.B., Schenk, L.M. et al. Whole-exome sequencing of 81 individuals from 27 multiply affected bipolar disorder families. Transl Psychiatry 10, 57 (2020). https://doi.org/10.1038/s41398-020-0732-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41398-020-0732-y
This article is cited by
-
Progress and Implications from Genetic Studies of Bipolar Disorder
Neuroscience Bulletin (2024)
-
Role of microtubule actin crosslinking factor 1 (MACF1) in bipolar disorder pathophysiology and potential in lithium therapeutic mechanism
Translational Psychiatry (2023)
-
Neurotransmission-related gene expression in the frontal pole is altered in subjects with bipolar disorder and schizophrenia
Translational Psychiatry (2023)
-
Pedigree-based study to identify GOLGB1 as a risk gene for bipolar disorder
Translational Psychiatry (2022)
-
Roles and mechanisms of ankyrin-G in neuropsychiatric disorders
Experimental & Molecular Medicine (2022)
