
Abstract
Background:
Although many low-penetrant genetic risk factors for breast cancer have been discovered, knowledge about the effect of multiple risk alleles is limited, especially in women <50 years. We therefore investigated the association between multiple risk alleles and breast cancer risk as well as individual effects according to age-approximated pre- and post-menopausal status.
Methods:
Ten previously described breast cancer-associated single-nucleotide polymorphisms (SNPs) were analysed in a joint European biobank-based study comprising 3584 breast cancer cases and 5063 cancer-free controls. Genotyping was performed using MALDI-TOF mass spectrometry, and odds ratios were estimated using logistic regression.
Results:
Significant associations with breast cancer were confirmed for 7 of the 10 SNPs. Analysis of the joint effect of the original 10 as well as the statistically significant 7 SNPs (rs2981582, rs3803662, rs889312, rs13387042, rs13281615, rs3817198 and rs981782) found a highly significant trend for increasing breast cancer risk with increasing number of risk alleles (P-trend 5.6 × 10−20 and 1.5 × 10−25, respectively). Odds ratio for breast cancer of 1.84 (95% confidence interval (CI): 1.59–2.14; 10 SNPs) and 2.12 (95% CI: 1.80–2.50; 7 SNPs) was seen for the maximum vs the minimum number of risk alleles. Additionally, one of the examined SNPs (rs981782 in HCN1) had a protective effect that was significantly stronger in premenopausal women (P-value: 7.9 × 10−4).
Conclusion:
The strongly increasing risk seen when combining many low-penetrant risk alleles supports the polygenic inheritance model of breast cancer.
Similar content being viewed by others

Main
In addition to the highly penetrant (BRCA1, BRCA2 and TP53) and moderately penetrant (CHEK2, ATM, BRIP1 and PALB2) genetic variants conferring increased risk for breast cancer, low-penetrant risk has been linked with common genetic variants (e.g., FGFR2, TOX3, MAP3K1 and LSP1) by genome-wide association studies (GWASs) (Easton et al, 2007; Stacey et al, 2007; Turnbull and Rahman, 2008; Ghoussaini and Pharoah, 2009).
Early GWASs on breast cancer reported findings of several new breast cancer susceptibility loci (Easton et al, 2007; Hunter et al, 2007). Subsequent studies rapidly confirmed these results and added new potential risk alleles (Gold et al, 2008; Ahmed et al, 2009; Zheng et al, 2009; Hemminki et al, 2010; Long et al, 2010; Turnbull et al, 2010). Low-risk alleles in at least 25 different loci (>35 single-nucleotide polymorphisms (SNPs)) have now been identified through GWASs (Hindorff et al, 2011). Together, they are thought to represent roughly 8% of the familial breast cancer cases, a proportion that might increase somewhat when the true causal variants are identified (Ghoussaini and Pharoah, 2009; Turnbull et al, 2010). The polygenic model of inheritance, in which each variant contributes a small risk in many individuals, is often invoked to account for a substantial amount of the population attributable risk (PAR) (Dragani et al, 1996; Fletcher and Houlston, 2010).
The six common susceptibility loci reported in 2007 by Easton et al (2007), Hunter et al (2007) and Stacey et al (2007) have been verified in other studies (Gorodnova et al, 2010; Hemminki et al, 2010; Turnbull et al, 2010; Fletcher et al, 2011). The present large study, based on five well-defined study populations from Northern Europe, first aimed to investigate the significance of eight SNPs from these loci, three additional SNPs with P<0.05 in phase 3 of Easton et al (2007), and a variant in CASP8 discovered by the candidate gene approach (Cox et al, 2007), with special reference to age-approximated menopausal status. Furthermore, we wished to address the potential polygenic inheritance of genetic risk factors and breast cancer, that is, the association between an increasing number of risk alleles and breast cancer risk. Two studies of this issue (Reeves et al, 2010; Wacholder et al, 2010) have reported that multiple low-risk alleles do indeed increase breast cancer risk; however, neither of them included women <50 years of age. We therefore set out to perform a large investigation of the polygenic inheritance of breast cancer in women of a wide age span.
Materials and methods
Study populations
The study was performed within the European network of excellence Cancer Control using Population-based Registries and Biobanks (CCPRB). A total of 9395 samples (3882 cases and 5513 controls) were selected for genotyping (Table 1). The study was approved by an ethical institutional review board in each participating country and the following study populations were included.
MDCS
The Malmö Diet and Cancer Study (MDCS) is a prospective cohort study initiated in 1991. It comprises a total of 17 035 female residents of Malmö Sweden recruited between 1991 and 1996 (Berglund et al, 1993; Manjer et al, 2001). By linkage to the national cancer registry until 31 December 2007, 730 incident cases of invasive breast cancer were identified among MDCS participants and subsequently matched to 1460 controls from the same cohort according to sex, age (±6 months) and date of sampling at baseline (±2 months). Median age at breast cancer diagnosis was 65 years (range 45–84). In all, 33 cases and 65 controls were ⩽50 years of age at the time of diagnosis.
MPP
The Malmö Preventive Project (MPP) is a preventive case-finding programme started in 1974 (Berglund et al, 2000). Between 1977 and 1992, 10 902 women were recruited and more than 40% attended a re-examination (started in 2002) that included storing samples for DNA analysis (Nilsson et al, 2006; Pukkala et al, 2007). Among those women distinct from participants in MDCS and for whom DNA samples were available, 215 prospective invasive breast cancer cases (median age 61 years, range 32–79, 25 age ⩽50 years) were identified by cancer registry linkage up until 31 December 2007 and subsequently matched to 430 controls (50 age ⩽50 years). Matching criteria were: sex, age (±6 months) and date of sampling at baseline (±2 months). Together with the MDCS they comprise the Southern Swedish cohort.
The MDCS/MPP and the present analyses were approved by the Ethical Committee at Lund University (LU 51-90, Dnr 2009/652 and Dnr 2009/682); when donating blood, participants also signed a general consent form allowing research on their samples.
NSHDS
The North Sweden Health and Disease Study (NSHDS) include the Västerbotten Intervention Programme (VIP) and the Mammography Screening Programme (MSP), initiated in 1985 and 1995, respectively. Participants in the VIP are screened at 40, 50 and 60 years of age and mammography screening and blood sampling is performed among women between 50 and 69 years of age (Pukkala et al, 2007). Through linkage with the cancer registry up to 31 December 2008, 1680 prospective cases of invasive breast cancer (median age 56 years, range 27–95) were identified and subsequently matched to 2369 controls by sex, age (±6 months) and date of sampling at baseline (±2 months; 474 cases and 606 controls ⩽50 years of age. The NSHDS and the present analyses were approved by the Ethical Committee at Umeå University (Dnr 2010-147-132 and 07-141); when donating blood, participants also signed a general consent form allowing research on their samples.
ICELAND
The Icelandic samples were collected between 1998 and 2006 and represents 45–77% of all Icelandic women with invasive breast cancer diagnosed between 1957 and 2007. The rate of participation varied somewhat depending on the year of diagnosis and was highest between 1999 and 2003 (77%). Unmatched controls were collected between 2000 and 2004, either from women who participated in the population-based cervical or breast cancer screening programme and found free of breast cancer or from older women in retirement homes who had not been diagnosed with breast cancer, to generally reflect the ages of the cases. By linkage to the Icelandic cancer registry in 2008, we identified cases diagnosed before 31 December 2007. A total of 866 cases (median age 55 years, range 22–98, 314 ⩽50 years) and 948 controls (median age 58 years, range 25–102, 256 ⩽50 years) had DNA available and were eligible to us.
The use of these samples was approved by the data protection (200605037) and Science Ethics Committee in Reykjavik (VSNb2006050001/03-16 and VSNb2005070008/03-16).
POLAND
Cases with early onset or familial breast cancer, free from BRCA1/2 mutations, were recruited at the genetic counselling clinic in Silesia between 1997 and 2006. This collection included 391 cases (median age 46 years, range 22–81, 315 ⩽50 years) that were used in the present study. Samples from 306 unmatched controls (median age 43 years, range 18–71, 233 ⩽50 years) were collected between 2003 and 2009 from healthy women attending the same clinic, but who had no family history of breast cancer.
The use of the Polish samples was approved by the Bioethical Commission at the Centre of Oncology in Gliwice (20 November 2001). All subjects signed an informed consent form before donating their samples.
SNP selection
All GWAS-identified loci associated with breast cancer and published before 31 June 2007 were initially included in the study (Easton et al, 2007; Hunter et al, 2007; Stacey et al, 2007). Individual SNPs were selected from the publications by Easton et al (2007) and Stacey et al (2007). This primary selection included 11 GWAS-identified SNPs. Three of these (rs3803663, rs12443621 and rs8051542), all situated in TOX3, have been shown to exhibit linkage (Easton et al, 2007; Reeves et al, 2007), and rs12443621 and rs80515442 were consequently excluded from further analysis. One SNP in CASP8 identified using the candidate gene approach was also included (Cox et al, 2007). The final selection therefore consisted of 10 SNPs (Table 2).
Assay design and genotyping
The SEQUENOM MassARRAY Designer software (San Diego, CA, USA) included eight of the above SNPs in a single multiplex assay. The SNP analyses were performed on a MALDI-TOF mass spectrometer (SEQUENOM MassArray) using standard iPLEX reagents and protocol (SEQUENOM) and 10 ng DNA as PCR template. Primer sets were from Metabion (Martinsried, Germany).
The SNPs rs2981582 and rs1045485 were analysed by a separate TaqMan ‘assay by design’ genotyping assay on a 7900HT instrument, using Master Mix No UNG from Applied Biosystems (Foster City, CA, USA) according to the manufacturer's instructions. Reaction mixtures (6 μl) containing 2 ng of DNA template and primers (rs2981582 forward primer 5′-CAGCACTCATCGCCACTTAATG-3′, reverse primer 5′-GACACCACTCGGACTGCT-3′, and probes 5′-VIC-TCTCCGCAAACAGG-MGB-3′ and 5′-FAM-CTCTCCACAAACAGG-MGB-3′) (rs1045485 forward primer 5′-ACCACGACCTTTGAAGAGCTT-3′, reverse primer 5′-ACTGTGGTCCATGAGTTGGTAGAT-3′, and probes 5′-VIC-CCCCACGATGACTG-MGB-3′ and 5′-FAM-CCCCACCATGACTG-MGB-3′) were subjected to 2 min at 50 °C and 10 min at 95 °C, followed by 50 PCR cycles of 95 °C for 15 s and 60 °C for 1 min.
Quality control
Approximately 3% of samples from the NSHDS, 5% of the samples from Iceland and 8% of the Polish cases (total N=270) were included as blinded duplicates to assess the quality of the genotyping assay.
Statistical analysis
Individual samples producing results in <80% of the assays were excluded before statistical analyses in order to eliminate samples with poor-quality DNA and in concordance with Easton et al (2007). Genotype data from control samples were tested for consistency with Hardy–Weinberg equilibrium (HWE) using a χ2 P-value cutoff of 0.001. Unconditional logistic regression models were used to measure the association between genotype for each SNP and the risk for breast cancer, using homozygotes for the common allele as reference, with adjustments for age and cohort. The material was stratified for age, ⩽50 vs >50 years, as a proxy for menopausal status. Furthermore, the analyses were repeated separately in each cohort. Per allele odds ratio (OR) and P-trend was calculated using 0, 1 or 2 copies of the minor allele as a continuous variable. The OR of <1.0 indicates that the major allele is the risk allele. To examine heterogeneity between the age groups, adjusted case–case models using unconditional logistic regression analysis were used and P-values of <0.05 were considered statistically significant. The P-value for heterogeneity (Phet) of OR between cohorts was calculated using the Breslow–Day test.
For each participant the total number of risk alleles was calculated, and logistic regression was used to estimate OR and P-trend for each numerical group of risk alleles. The same calculation was also performed using only the seven SNPs exhibiting significance. The maximum number of risk alleles was 20 and 14, respectively, that is, 2 for each SNP. Breast cancer risk for individuals with up to ⩾11/8 risk alleles was compared with the group with ⩽6/3 risk alleles. The median number of risk alleles among both cases and control population was 8 (model including all 10 SNPs) and 5 (model including 7 SNPs), and in order to estimate the risk increase/decrease in individuals with the highest and lowest numbers of risk alleles, 8/5 risk alleles was also set as a reference. The women were also stratified according to age (⩽50 vs >50 years) to assess potential differences in penetrance between age groups with increasing numbers of risk alleles.
To compare estimated risks in the present study with previous reports, OR and P-values for trends reported in original reports are presented together with the results of the present analyses.
Results
Of the initial 9395 samples selected for the project, 8647 (92.0%) were successfully retrieved and genotyped for ⩾80% of the SNPs. All SNPs had genotyping success rates of >90%, with an average of 97.8%. Results of all 3240 analyses performed on the 270 duplicate samples were in 100% concordance. All SNPs but one (rs4666451) passed the HWE cutoff (P<0.001).
Associations between seven of the reported SNPs and breast cancer were replicated in our material, with age-adjusted ORs for these SNPs in close proximity to ORs previously described (Cox et al, 2007; Easton et al, 2007; Stacey et al, 2007). The P-trend value for four of the SNPs (rs2981582, rs3803662, rs889312 and, rs13281615) was <0.001 and for the remaining three SNPs (rs13387042, rs3817198 and rs981782) was <0.01 (Table 2).
One of the SNPs (rs30099) exhibited an age-adjusted OR near to what was originally reported (Easton et al, 2007), but it did not pass the significance threshold of 0.05 (Table 2).
Associations of the two remaining SNPs with breast cancer were not replicated. The SNP rs1045485 (CASP8) did not reach significance, although the point estimate of the per-allele OR among women >50 years (0.92, 95% CI: 0.82–1.02) approaches that initially described by Cox et al (2007) (0.88, 95% CI: 0.84–0.92). Minor allele frequency (MAF) in our material was 0.24. The final SNP (rs4666451) had 5.8% missing values, failed the HWE cutoff (P<0.001) and had an OR that deviated from that reported (MAF was 0.35).
Stratification analysis
Stratification of participants into age groups ⩽50 vs >50 years to approximate menopausal discrimination revealed different association in young vs older women for one of the SNPs (rs981782), whose protective effect was more pronounced in younger (per allele OR 0.82, 95% CI: 0.73–0.93) than in older women (homozygous OR 0.94, 95% CI: 0.87–1.01; Table 3). The difference was statistically significant with a P-value of 7.9 × 10−4.
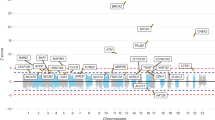
Stratification of results according to study population (Figure 1) revealed similar effects for most SNPs, although rs13387042 was most strongly associated with risk in the Icelandic samples (Phet=0.02). The original data set was also adjusted for study population but no difference in results was seen compared with the age-adjusted or unadjusted analysis (results not shown).

Per allele OR and 95% CI for all SNPs by participating cohorts. The area of the square for each study-population is proportional to the inverse of the variance of the estimate. Horizontal lines represent 95% CI and diamonds represent the summary OR.
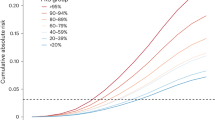
Finally, both cases and controls were classified according to the individual burden of risk alleles including both all 10 original SNPs and the SNPs statistically significantly associated with risk within this study (rs2981582, rs3803662, rs889312, rs13387042, rs13281615, rs3817198 and rs981782). A successive increase in point estimate from an OR of 1 for the group with the minimum number of risk alleles (⩽6/3 alleles) to an OR of 1.84 (95% CI 1.59–2.14; 10 SNP analysis) and 2.12 (95% CI: 1.80–2.50; 7 SNP analysis) for the group carrying the maximum number of risk alleles (⩾11/8 risk alleles) was detected (overall P for trend: 5.6 × 10−20 and 1.5 × 1025, respectively; Table 3a and b). When the mean number of risk alleles in the population was used as the reference (in the model including the significant seven SNPs), the maximum risk increase was 1.42 (95% CI: 1.22–1.66) for ⩾3 risk alleles above mean and a maximum protection of 0.67 (0.58–0.78) for women with ⩾2 risk alleles below mean. Results from the 10 SNP analyses were highly similar (Table 3a). The overall frequency distribution of odds ratios in the 10 SNP model is shown in Figure 2. We found no significant difference between age groups when the women were stratified according to age (⩽50 vs >50 years; results not shown).

The distribution of risk alleles from the 10 SNPs amongst all women analysed in our study populations (n=8647), as well as the OR associated with having a certain number of risk alleles compared with the median number (8). Odds ratios are depicted by filled circles and 95% confidence intervals by black lines.
Discussion
Our study replicated the breast cancer association of 7 out of 10 previously described low risk alleles (Cox et al, 2007; Easton et al, 2007; Stacey et al, 2007), with nearly identical point estimates as the original studies. By comparing the total number of risk alleles in cases and controls, a highly significant increasing risk for breast cancer with an increasing number of risk alleles was seen. Calculations were primarily based on the original set of 10 SNPs and the observed association is compatible with a polygenic contribution to breast cancer in the absence of highly penetrant cancer genes (Dragani et al, 1996; Turnbull and Rahman, 2008; Ghoussaini and Pharoah, 2009). We also performed risk-score calculations using only the seven SNPs that originally reached significance in our study and the results were an even stronger risk trend, indicating that it might be useful to construct selective SNP panels for different populations. In this discussion, ORs are compared with the group with lowest number of risk alleles as the study population is enriched for breast cancer compared with a total background population.
The intergenic SNP rs981782 in HCN1 on 5p12, a region previously yielding significant SNPs for breast and other cancers (Ghoussaini and Pharoah, 2009), was one of the three SNPs we studied that had secondary significance in the study of Easton et al (2007). We found that the protective effect of the minor allele was notably more pronounced in premenopausal breast cancer (women ⩽50 years), despite the fact that this group included only 2232 individuals compared with 6398 individuals in the age group of >50 years. The P-value (7.9 × 10−4) for heterogeneity between age groups was highly significant. Previous reports did not find this difference, which could be because of differences in age stratification and/or inclusion (Easton et al, 2007; Reeves et al, 2010; Wacholder et al, 2010). In a fine mapping of the region, Stacey et al (2008) identified two SNPs in the same region (rs4415084 and rs10941679) as possible causal variants behind this association, and linked these SNPs to higher risk of ER-receptor-positive breast cancer.
SNP rs13387042 on 2q35, originally reported by Stacey et al (2007), was identified in a screening panel containing 1600 Icelandic women and verified in a large panel of 4554 cases and 17 577 controls containing Icelandic as well as non-Icelandic women. Our results for the Swedish and Polish cohorts differed from the Icelandic population (Phet=0.02), whose carriers of the rs13387042 A allele demonstrate an increased risk. The 2q35 locus has also been verified in other non-Icelandic populations (Milne et al, 2009), indicating that this SNP is generally associated with breast cancer. Nevertheless, the significantly higher risk that we found in Iceland is noteworthy.
For SNP rs1045485 in CASP8, originally discovered by Cox et al (2007) through candidate gene analysis, we found a similar point estimate as in the original study for women >50 years of age, although the association with breast cancer did not achieve significance in our cohorts. A recent meta-analysis (Sergentanis and Economopoulos, 2009) concluded that CASP8 rs1045485 does reduce the risk of breast cancer in minor allele carriers, at least in Caucasian populations.
Our study includes cases and controls from five different study populations in three different countries, representing different northern European inhabitants. Each cohort has its own strengths and weaknesses. The Swedish NHSDS and MDCS cohorts have matched controls to cases in the same prospective population-based study, age and duration of follow-up. Enrolment in the MDCS has shown a slight selection towards higher socioeconomic status than the general population, but this selection is the same for cases and controls (Manjer et al, 2001). The MDCS participants were recruited at age 44–65 years. The exclusion of prevalent cases removes early breast cancer cases from this population. Although the NHSDS participants were primarily included from age 40 and upwards, the mammography subcohort included some case as young as 27 years. In Iceland, prevalent cases of breast cancer were recruited at varying times after diagnosis, resulting in an exclusion of early lethal cases and older women with other causes of death. A similar bias is present in the MPP cohort despite prospective population-based design, as DNA samples were acquired from only ∼40% of cases and matched controls participating in a follow-up visit. It is therefore possible that these two study populations are biased towards breast cancer cases with more favourable outcome. The Polish cases are recruited from families with multiple breast cancer cases, or because of early onset of breast cancer, something that seems to strengthen the association between rs981782 and breast cancer in women ⩽50 years that is especially prominent in this cohort (Figure 1).
Methodological strengths include the exclusion of samples with <80% successful genotypes and by 100% concordant genotypes in 270 duplicate samples. Although the use of P<0.05 as significance limit is appropriate for a replication study verifying reported associations, the occurrence of false negative findings cannot be excluded. Lack of significance, in particular of the CASP8 (rs1045485) association, might be attributable to insufficient statistical power.
The FGFR2 and TOX3 SNPs have consistently been verified in published reports (Huijts et al, 2007; Gorodnova et al, 2010; Hemminki et al, 2010; Turnbull et al, 2010), whereas replication of the other low-penetrant SNPs has been less constant. At least two previous studies (Reeves et al, 2010; Wacholder et al, 2010) have analysed the association between the number of risk alleles and overall breast cancer risk. Wacholder et al (2010) analysed almost 6000 women with breast cancer aged 50–79 years. They had highly similar results to ours, but pointed out the fact that addition of a risk score obtained from adding genotypes from 10 low-penetrant SNPs contributed little to breast cancer risk prediction over and above the established clinical risk prediction models that include age at first childbirth, Gail score and the number of first-degree relatives with breast cancer.
In the present study we used a simple addition of the number of risk alleles, but still obtained almost exactly the same result as the study of Reeves et al (2010), although these authors took into account the magnitudes of the individual SNP effects. Thus, the additive approach appears to be sufficient for risk score calculation.
Our findings, including total risk score, are well in line with previous studies. A novel finding for this study was the fact that the protective effect of the HCN1 SNP rs981782 was significantly stronger in women ⩽50 years of age. Odds ratios presented both here and in the other two studies consistently show that total risk scores based on low-penetrant SNPs adds only very modest improvement to risk prediction models based on medical data, and are therefore not likely to have an immediate clinical use. However, we can show that simple calculation of the number of risk alleles gives highly reproducible risk scores between studies and could be useful in further studies of the genetic predisposition to breast cancer.
Change history
29 March 2012
This paper was modified 12 months after initial publication to switch to Creative Commons licence terms, as noted at publication
References
Ahmed S, Thomas G, Ghoussaini M, Healey CS, Humphreys MK, Platte R, Morrison J, Maranian M, Pooley KA, Luben R, Eccles D, Evans DG, Fletcher O, Johnson N, dos Santos Silva I, Peto J, Stratton MR, Rahman N, Jacobs K, Prentice R, Anderson GL, Rajkovic A, Curb JD, Ziegler RG, Berg CD, Buys SS, McCarty CA, Feigelson HS, Calle EE, Thun MJ, Diver WR, Bojesen S, Nordestgaard BG, Flyger H, Dork T, Schurmann P, Hillemanns P, Karstens JH, Bogdanova NV, Antonenkova NN, Zalutsky IV, Bermisheva M, Fedorova S, Khusnutdinova E, Kang D, Yoo KY, Noh DY, Ahn SH, Devilee P, van Asperen CJ, Tollenaar RA, Seynaeve C, Garcia-Closas M, Lissowska J, Brinton L, Peplonska B, Nevanlinna H, Heikkinen T, Aittomaki K, Blomqvist C, Hopper JL, Southey MC, Smith L, Spurdle AB, Schmidt MK, Broeks A, van Hien RR, Cornelissen S, Milne RL, Ribas G, Gonzalez-Neira A, Benitez J, Schmutzler RK, Burwinkel B, Bartram CR, Meindl A, Brauch H, Justenhoven C, Hamann U, Chang-Claude J, Hein R, Wang-Gohrke S, Lindblom A, Margolin S, Mannermaa A, Kosma VM, Kataja V, Olson JE, Wang X, Fredericksen Z, Giles GG, Severi G, Baglietto L, English DR, Hankinson SE, Cox DG, Kraft P, Vatten LJ, Hveem K, Kumle M, Sigurdson A, Doody M, Bhatti P, Alexander BH, Hooning MJ, van den Ouweland AM, Oldenburg RA, Schutte M, Hall P, Czene K, Liu J, Li Y, Cox A, Elliott G, Brock I, Reed MW, Shen CY, Yu JC, Hsu GC, Chen ST, Anton-Culver H, Ziogas A, Andrulis IL, Knight JA, Beesley J, Goode EL, Couch F, Chenevix-Trench G, Hoover RN, Ponder BA, Hunter DJ, Pharoah PD, Dunning AM, Chanock SJ, Easton DF (2009) Newly discovered breast cancer susceptibility loci on 3p24 and 17q23.2. Nat Genet 41: 585–590
Berglund G, Elmstahl S, Janzon L, Larsson SA (1993) The Malmo Diet and Cancer Study. Design and feasibility. J Intern Med 233: 45–51
Berglund G, Nilsson P, Eriksson KF, Nilsson JA, Hedblad B, Kristenson H, Lindgarde F (2000) Long-term outcome of the Malmo preventive project: mortality and cardiovascular morbidity. J Intern Med 247: 19–29
Cox A, Dunning AM, Garcia-Closas M, Balasubramanian S, Reed MW, Pooley KA, Scollen S, Baynes C, Ponder BA, Chanock S, Lissowska J, Brinton L, Peplonska B, Southey MC, Hopper JL, McCredie MR, Giles GG, Fletcher O, Johnson N, dos Santos Silva I, Gibson L, Bojesen SE, Nordestgaard BG, Axelsson CK, Torres D, Hamann U, Justenhoven C, Brauch H, Chang-Claude J, Kropp S, Risch A, Wang-Gohrke S, Schurmann P, Bogdanova N, Dork T, Fagerholm R, Aaltonen K, Blomqvist C, Nevanlinna H, Seal S, Renwick A, Stratton MR, Rahman N, Sangrajrang S, Hughes D, Odefrey F, Brennan P, Spurdle AB, Chenevix-Trench G, Beesley J, Mannermaa A, Hartikainen J, Kataja V, Kosma VM, Couch FJ, Olson JE, Goode EL, Broeks A, Schmidt MK, Hogervorst FB, Van’t Veer LJ, Kang D, Yoo KY, Noh DY, Ahn SH, Wedren S, Hall P, Low YL, Liu J, Milne RL, Ribas G, Gonzalez-Neira A, Benitez J, Sigurdson AJ, Stredrick DL, Alexander BH, Struewing JP, Pharoah PD, Easton DF (2007) A common coding variant in CASP8 is associated with breast cancer risk. Nat Genet 39: 352–358
Dragani TA, Canzian F, Pierotti MA (1996) A polygenic model of inherited predisposition to cancer. FASEB J 10: 865–870
Easton DF, Pooley KA, Dunning AM, Pharoah PD, Thompson D, Ballinger DG, Struewing JP, Morrison J, Field H, Luben R, Wareham N, Ahmed S, Healey CS, Bowman R, Meyer KB, Haiman CA, Kolonel LK, Henderson BE, Le Marchand L, Brennan P, Sangrajrang S, Gaborieau V, Odefrey F, Shen CY, Wu PE, Wang HC, Eccles D, Evans DG, Peto J, Fletcher O, Johnson N, Seal S, Stratton MR, Rahman N, Chenevix-Trench G, Bojesen SE, Nordestgaard BG, Axelsson CK, Garcia-Closas M, Brinton L, Chanock S, Lissowska J, Peplonska B, Nevanlinna H, Fagerholm R, Eerola H, Kang D, Yoo KY, Noh DY, Ahn SH, Hunter DJ, Hankinson SE, Cox DG, Hall P, Wedren S, Liu J, Low YL, Bogdanova N, Schurmann P, Dork T, Tollenaar RA, Jacobi CE, Devilee P, Klijn JG, Sigurdson AJ, Doody MM, Alexander BH, Zhang J, Cox A, Brock IW, MacPherson G, Reed MW, Couch FJ, Goode EL, Olson JE, Meijers-Heijboer H, van den Ouweland A, Uitterlinden A, Rivadeneira F, Milne RL, Ribas G, Gonzalez-Neira A, Benitez J, Hopper JL, McCredie M, Southey M, Giles GG, Schroen C, Justenhoven C, Brauch H, Hamann U, Ko YD, Spurdle AB, Beesley J, Chen X, Mannermaa A, Kosma VM, Kataja V, Hartikainen J, Day NE, Cox DR, Ponder BA (2007) Genome-wide association study identifies novel breast cancer susceptibility loci. Nature 447: 1087–1093
Fletcher O, Houlston RS (2010) Architecture of inherited susceptibility to common cancer. Nat Rev Cancer 10: 353–361
Fletcher O, Johnson N, Orr N, Hosking FJ, Gibson LJ, Walker K, Zelenika D, Gut I, Heath S, Palles C, Coupland B, Broderick P, Schoemaker M, Jones M, Williamson J, Chilcott-Burns S, Tomczyk K, Simpson G, Jacobs KB, Chanock SJ, Hunter DJ, Tomlinson IP, Swerdlow A, Ashworth A, Ross G, dos Santos Silva I, Lathrop M, Houlston RS, Peto J (2011) Novel breast cancer susceptibility locus at 9q31.2: results of a genome-wide association study. J Natl Cancer Inst 103: 425–435
Ghoussaini M, Pharoah PD (2009) Polygenic susceptibility to breast cancer: current state-of-the-art. Future Oncol 5: 689–701
Gold B, Kirchhoff T, Stefanov S, Lautenberger J, Viale A, Garber J, Friedman E, Narod S, Olshen AB, Gregersen P, Kosarin K, Olsh A, Bergeron J, Ellis NA, Klein RJ, Clark AG, Norton L, Dean M, Boyd J, Offit K (2008) Genome-wide association study provides evidence for a breast cancer risk locus at 6q22.33. Proc Natl Acad Sci USA 105: 4340–4345
Gorodnova TV, Kuligina E, Yanus GA, Katanugina AS, Abysheva SN, Togo AV, Imyanitov EN (2010) Distribution of FGFR2, TNRC9, MAP3K1, LSP1, and 8q24 alleles in genetically enriched breast cancer patients versus elderly tumor-free women. Cancer Genet Cytogenet 199: 69–72
Hemminki K, Muller-Myhsok B, Lichtner P, Engel C, Chen B, Burwinkel B, Forsti A, Sutter C, Wappenschmidt B, Hellebrand H, Illig T, Arnold N, Niederacher D, Dworniczak B, Deissler H, Kast K, Gadzicki D, Meitinger T, Wichmann HE, Kiechle M, Bartram CR, Schmutzler RK, Meindl A (2010) Low-risk variants FGFR2, TNRC9 and LSP1 in German familial breast cancer patients. Int J Cancer 126: 2858–2862
Hindorff LA, Junkins HA, Hall PN, Mehta JP, Manolio TA (2011) A catalog of published genome-wide association studies; available at: www.genome.gov/gwastudies (accessed on 2 May 2011)
Huijts PE, Vreeswijk MP, Kroeze-Jansema KH, Jacobi CE, Seynaeve C, Krol-Warmerdam EM, Wijers-Koster PM, Blom JC, Pooley KA, Klijn JG, Tollenaar RA, Devilee P, van Asperen CJ (2007) Clinical correlates of low-risk variants in FGFR2, TNRC9, MAP3K1, LSP1 and 8q24 in a Dutch cohort of incident breast cancer cases. Breast Cancer Res 9: R78
Hunter DJ, Kraft P, Jacobs KB, Cox DG, Yeager M, Hankinson SE, Wacholder S, Wang Z, Welch R, Hutchinson A, Wang J, Yu K, Chatterjee N, Orr N, Willett WC, Colditz GA, Ziegler RG, Berg CD, Buys SS, McCarty CA, Feigelson HS, Calle EE, Thun MJ, Hayes RB, Tucker M, Gerhard DS, Fraumeni Jr JF, Hoover RN, Thomas G, Chanock SJ (2007) A genome-wide association study identifies alleles in FGFR2 associated with risk of sporadic postmenopausal breast cancer. Nat Genet 39: 870–874
Long J, Cai Q, Shu XO, Qu S, Li C, Zheng Y, Gu K, Wang W, Xiang YB, Cheng J, Chen K, Zhang L, Zheng H, Shen CY, Huang CS, Hou MF, Shen H, Hu Z, Wang F, Deming SL, Kelley MC, Shrubsole MJ, Khoo US, Chan KY, Chan SY, Haiman CA, Henderson BE, Le Marchand L, Iwasaki M, Kasuga Y, Tsugane S, Matsuo K, Tajima K, Iwata H, Huang B, Shi J, Li G, Wen W, Gao YT, Lu W, Zheng W (2010) Identification of a functional genetic variant at 16q12.1 for breast cancer risk: results from the Asia Breast Cancer Consortium. PLoS Genet 6: e1001002
Manjer J, Carlsson S, Elmstahl S, Gullberg B, Janzon L, Lindstrom M, Mattisson I, Berglund G (2001) The Malmo Diet and Cancer Study: representativity, cancer incidence and mortality in participants and non-participants. Eur J Cancer Prev 10: 489–499
Milne RL, Benitez J, Nevanlinna H, Heikkinen T, Aittomaki K, Blomqvist C, Arias JI, Zamora MP, Burwinkel B, Bartram CR, Meindl A, Schmutzler RK, Cox A, Brock I, Elliott G, Reed MW, Southey MC, Smith L, Spurdle AB, Hopper JL, Couch FJ, Olson JE, Wang X, Fredericksen Z, Schurmann P, Bremer M, Hillemanns P, Dork T, Devilee P, van Asperen CJ, Tollenaar RA, Seynaeve C, Hall P, Czene K, Liu J, Li Y, Ahmed S, Dunning AM, Maranian M, Pharoah PD, Chenevix-Trench G, Beesley J, Bogdanova NV, Antonenkova NN, Zalutsky IV, Anton-Culver H, Ziogas A, Brauch H, Justenhoven C, Ko YD, Haas S, Fasching PA, Strick R, Ekici AB, Beckmann MW, Giles GG, Severi G, Baglietto L, English DR, Fletcher O, Johnson N, dos Santos Silva I, Peto J, Turnbull C, Hines S, Renwick A, Rahman N, Nordestgaard BG, Bojesen SE, Flyger H, Kang D, Yoo KY, Noh DY, Mannermaa A, Kataja V, Kosma VM, Garcia-Closas M, Chanock S, Lissowska J, Brinton LA, Chang-Claude J, Wang-Gohrke S, Shen CY, Wang HC, Yu JC, Chen ST, Bermisheva M, Nikolaeva T, Khusnutdinova E, Humphreys MK, Morrison J, Platte R, Easton DF (2009) Risk of estrogen receptor-positive and -negative breast cancer and single-nucleotide polymorphism 2q35-rs13387042. J Natl Cancer Inst 101: 1012–1018
Nilsson PM, Nilsson JA, Berglund G (2006) Population-attributable risk of coronary heart disease risk factors during long-term follow-up: the Malmo Preventive Project. J Intern Med 260: 134–141
Pukkala E, Andersen A, Berglund G, Gislefoss R, Gudnason V, Hallmans G, Jellum E, Jousilahti P, Knekt P, Koskela P, Kyyronen PP, Lenner P, Luostarinen T, Love A, Ogmundsdottir H, Stattin P, Tenkanen L, Tryggvadottir L, Virtamo J, Wadell G, Widell A, Lehtinen M, Dillner J (2007) Nordic biological specimen banks as basis for studies of cancer causes and control--more than 2 million sample donors, 25 million person years and 100 000 prospective cancers. Acta Oncol 46: 286–307
Reeves GK, Pirie K, Beral V, Green J, Spencer E, Bull D (2007) Cancer incidence and mortality in relation to body mass index in the Million Women Study: cohort study. BMJ 335: 1134
Reeves GK, Travis RC, Green J, Bull D, Tipper S, Baker K, Beral V, Peto R, Bell J, Zelenika D, Lathrop M (2010) Incidence of breast cancer and its subtypes in relation to individual and multiple low-penetrance genetic susceptibility loci. JAMA 304: 426–434
Sergentanis TN, Economopoulos KP (2009) Association of two CASP8 polymorphisms with breast cancer risk: a meta-analysis. Breast Cancer Res Treat 120: 229–234
Stacey SN, Manolescu A, Sulem P, Rafnar T, Gudmundsson J, Gudjonsson SA, Masson G, Jakobsdottir M, Thorlacius S, Helgason A, Aben KK, Strobbe LJ, Albers-Akkers MT, Swinkels DW, Henderson BE, Kolonel LN, Le Marchand L, Millastre E, Andres R, Godino J, Garcia-Prats MD, Polo E, Tres A, Mouy M, Saemundsdottir J, Backman VM, Gudmundsson L, Kristjansson K, Bergthorsson JT, Kostic J, Frigge ML, Geller F, Gudbjartsson D, Sigurdsson H, Jonsdottir T, Hrafnkelsson J, Johannsson J, Sveinsson T, Myrdal G, Grimsson HN, Jonsson T, von Holst S, Werelius B, Margolin S, Lindblom A, Mayordomo JI, Haiman CA, Kiemeney LA, Johannsson OT, Gulcher JR, Thorsteinsdottir U, Kong A, Stefansson K (2007) Common variants on chromosomes 2q35 and 16q12 confer susceptibility to estrogen receptor-positive breast cancer. Nat Genet 39: 865–869
Stacey SN, Manolescu A, Sulem P, Thorlacius S, Gudjonsson SA, Jonsson GF, Jakobsdottir M, Bergthorsson JT, Gudmundsson J, Aben KK, Strobbe LJ, Swinkels DW, van Engelenburg KC, Henderson BE, Kolonel LN, Le Marchand L, Millastre E, Andres R, Saez B, Lambea J, Godino J, Polo E, Tres A, Picelli S, Rantala J, Margolin S, Jonsson T, Sigurdsson H, Jonsdottir T, Hrafnkelsson J, Johannsson J, Sveinsson T, Myrdal G, Grimsson HN, Sveinsdottir SG, Alexiusdottir K, Saemundsdottir J, Sigurdsson A, Kostic J, Gudmundsson L, Kristjansson K, Masson G, Fackenthal JD, Adebamowo C, Ogundiran T, Olopade OI, Haiman CA, Lindblom A, Mayordomo JI, Kiemeney LA, Gulcher JR, Rafnar T, Thorsteinsdottir U, Johannsson OT, Kong A, Stefansson K (2008) Common variants on chromosome 5p12 confer susceptibility to estrogen receptor-positive breast cancer. Nat Genet 40: 703–706
Turnbull C, Ahmed S, Morrison J, Pernet D, Renwick A, Maranian M, Seal S, Ghoussaini M, Hines S, Healey CS, Hughes D, Warren-Perry M, Tapper W, Eccles D, Evans DG, Hooning M, Schutte M, van den Ouweland A, Houlston R, Ross G, Langford C, Pharoah PD, Stratton MR, Dunning AM, Rahman N, Easton DF (2010) Genome-wide association study identifies five new breast cancer susceptibility loci. Nat Genet 42: 504–507
Turnbull C, Rahman N (2008) Genetic predisposition to breast cancer: past, present, and future. Annu Rev Genomics Hum Genet 9: 321–345
Wacholder S, Hartge P, Prentice R, Garcia-Closas M, Feigelson HS, Diver WR, Thun MJ, Cox DG, Hankinson SE, Kraft P, Rosner B, Berg CD, Brinton LA, Lissowska J, Sherman ME, Chlebowski R, Kooperberg C, Jackson RD, Buckman DW, Hui P, Pfeiffer R, Jacobs KB, Thomas GD, Hoover RN, Gail MH, Chanock SJ, Hunter DJ (2010) Performance of common genetic variants in breast-cancer risk models. N Engl J Med 362: 986–993
Zheng W, Long J, Gao YT, Li C, Zheng Y, Xiang YB, Wen W, Levy S, Deming SL, Haines JL, Gu K, Fair AM, Cai Q, Lu W, Shu XO (2009) Genome-wide association study identifies a new breast cancer susceptibility locus at 6q25.1. Nat Genet 41: 324–328
Acknowledgements
We thank Anders Dahlin (MDCS and MPP), Gudridur Olafsdottir and Laufey Trygvadottir (Iceland) for data retrieval, Holmfridúr Hilmarsdottir (Iceland), Åsa Ågren (NSHSD), Jolanta Pamula-Pilat and Karolina Tecza (Poland) for sample retrieval and handling and Maria Sterner and Liselott Hall at RSKC (Malmö) research facility for technical assistance. This study was funded by the EU 6th Framework Network of Excellence Cancer Control and Prevention using Registries and Biobanks (CCPRB), contract no. LSHC-CT-2004-503465.
Author information
Authors and Affiliations
Corresponding author
Additional information
This work is published under the standard license to publish agreement. After 12 months the work will become freely available and the license terms will switch to a Creative Commons Attribution-NonCommercial-Share Alike 3.0 Unported License.
Rights and permissions
From twelve months after its original publication, this work is licensed under the Creative Commons Attribution-NonCommercial-Share Alike 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/3.0/
About this article
Cite this article
Harlid, S., Ivarsson, M., Butt, S. et al. Combined effect of low-penetrant SNPs on breast cancer risk. Br J Cancer 106, 389–396 (2012). https://doi.org/10.1038/bjc.2011.461
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/bjc.2011.461
Keywords
This article is cited by
-
Discovery of breast cancer risk genes and establishment of a prediction model based on estrogen metabolism regulation
BMC Cancer (2021)
-
Significant association of TOX3/LOC643714 locus-rs3803662 and breast cancer risk in a cohort of Iranian population
Molecular Biology Reports (2019)
-
A polygenic risk score for breast cancer risk in a Taiwanese population
Breast Cancer Research and Treatment (2017)
-
Association of single nucleotide polymorphism rs3803662 with the risk of breast cancer
Scientific Reports (2016)
-
Association of three SNPs in TOX3 and breast cancer risk: Evidence from 97275 cases and 128686 controls
Scientific Reports (2015)
