
Abstract
Frailty models are important for survival data because they allow for the possibility of unobserved heterogeneity problem. The problem of heterogeneity can be existed due to a variety of factors, such as genetic predisposition, environmental factors, or lifestyle choices. Frailty models can help to identify these factors and to better understand their impact on survival. In this study, we suggest a novel quasi xgamma frailty (QXg-F) model for the survival analysis. In this work, the test of Rao–Robson and Nikulin is employed to test the validity and suitability of the probabilistic model, we examine the distribution’s properties and evaluate its performance in comparison with many relevant cox-frailty models. To show how well the QXg-F model captures heterogeneity and enhances model fit, we use simulation studies and real data applications, including a fresh dataset gathered from an emergency hospital in Algeria. According to our research, the QXg-F model is a viable replacement for the current frailty modeling distributions and has the potential to improve the precision of survival analyses in a number of different sectors, including emergency care. Moreover, testing the ability and the importance of the new QXg-F model in insurance is investigated using simulations via different methods and application to insurance data.
Similar content being viewed by others
Introduction
Survival analysis is an important statistical tool that is used to investigate time-to-event data. One example of this type of data is the period of time that passes between the diagnosis of an illness and the occurrence of an interesting event, such as death or recurrence. Survival analysis is extensively utilized in a wide variety of fields, including medicine, biology, economics, engineering, and the social sciences. In survival analysis, one of the most important assumptions to make is that the time-to-event data follow an independent and identical (IID) distribution. This assumption is not always accurate, and the data are vulnerable to unobserved heterogeneity or fragility, both of which have the potential to have an effect on a person’s chance of surviving. Shared frailty models and independent frailty models are the two primary categories of frailty models that may be found in the medical literature. Shared frailty models operate under the presumption that all persons within a cluster have the same type of vulnerability, whereas independent frailty models operate under the presumption that each person has their own particular vulnerability. The usage of shared frailty models is common in situations in which the individuals who make up a cluster are linked to one another, for as in the case of twins or members of the same family. Independent frailty models are often utilized in situations in which the people who make up a cluster are not connected to one another in any way, such as patients who are participating in a therapeutic trial. Estimating the hazard-rate function, which is the chance of an occurrence occurring at a particular period, can be done with the use of fragility models. Predicting an individual’s or a group’s chance of survival by using the hazard-rate function is possible. This can be done for an individual or for a group of persons. It is also possible to utilize frailty models to determine which factors are related with an increased or decreased risk of an occurrence. (for further reading, see1,2,3).
In frailty modelling, the most fundamental premise is that the observed data are produced by a mix of independent and identically distributed random variables (IIRRV) and a random frailty factor that reflects the unobserved heterogeneity in the data. This is known as the independent and IIRRV model. According to Aalen and Tretli4, frailty modelling has been shown to be a useful method for evaluating survival data in a variety of settings, including cancer research, clinical trials, and epidemiology. The analysis of survival data can be greatly aided by the use of frailty models. They can be used to predict the probability of survival for an individual or a group of persons, and they can assist in the identification of characteristics that are related with an increased or decreased risk of an occurrence. Numerous distributions, such as the gamma distribution1,5, the compound Poisson distribution6,7, the log-normal distribution8. Pickles and Crouchley9 examined the effectiveness of conditional and mixture likelihood approaches in estimating models incorporating frailty effects in censored bivariate survival data. Their study revealed that mixture methods exhibit remarkable resilience to frailty distribution misspecification. Additionally, the paper includes an illustrative example involving the onset times of chest pain induced by three endurance exercise tests during a drug treatment trial involving heart patients. Therneau and colleagues (2002) showed that exact solutions for gamma shared frailty models can be achieved through penalized estimation. Likewise, Gaussian frailty models are closely associated with penalized models. Efficient fitting of frailty models with penalized likelihoods can be facilitated by leveraging computational techniques available for penalized models. We have incorporated penalized regression into the coxph function of S-Plus and demonstrate the algorithms with examples employing the Cox model. Box–Steffensmeier and De Boef10 conducted a comparison of different models for analyzing recurrent event data characterized by both heterogeneity and event dependence. They found that the conditional frailty model offers the most comprehensive approach to addressing the diverse conditions of heterogeneity and event dependence, utilizing a frailty term, stratification, and gap time formulation of the risk set. The study evaluates the effectiveness of recurrent event models frequently employed in practical applications through Monte Carlo simulations, and applies the insights gained to data concerning chronic granulomatous disease and cystic fibrosis.
Recently, Jiang and Haneuse11 introduced a novel class of transformation models tailored for semi-competing risks analysis, allowing for the non-parametric specification of the frailty distribution. The weighted Lindley frailty (see12), have been suggested in the statistical and reliability literature to explain the frailty term. However, the ability of these distributions to truly represent the variability of the data is limited due to the constraints they impose.
It has been demonstrated that the new QXg-F model is a suitable replacement for the gamma frailty model, the compound Poisson frailty model, the log-normal frailty model, and the weighted Lindley frailty model. It is important to note that the new frailty model is derived based on the quasi Xgamma (QXg) model that was initially presented by Sen and Chandra (2017). This is something that should be mentioned. The proposed QXg-F model is able to take into account unobserved variability, which helps to improve the fit of the frailty model. The suggested distribution is based on the QXg-F model, which has been shown to have good flexibility in modelling a wide range of data types. This flexibility has been proved through modelling. We extend the QXg-F model by incorporating a fragility component and show that the resulting distribution possesses desirable features such as positive support, skewness, and kurtosis. The Nikulin Rao and Robson (NIK-RR) test is a modified version of the chi-squared goodness-of-fit test that was proposed by Nikulin13, Nikulin14, Nikulin15, Nikulin13, and Rao and Robson16 for completed data. This test was used to validate the proposed QXg-F model. In the event where censored data are present, an adjusted version of the chi-squared goodness-of-fit test known as the Bagdonavicius–Nikulin (B-NIK) test was developed by Bagdonavicius and Nikulin17. This test was used to validate the suggested QXg-F model. It is worth noting that the literature (statistical and actuarial) contains many important extensions and various applications of the x-gamma distribution, see for example18,19,20
It is worth mentioning that, both the NIK-RR test statistic and the B-NIK test statistic are statistical tests used to assess the goodness of fit of a distribution to a set of data. However, there are some important differences between the two tests:
-
The NIK-RR test statistic is a general test of goodness of fit, meaning it can be used to test the goodness of fit to any distribution. On the other hand, the B-NIK test statistic is specifically designed to test the goodness of fit to the normal distribution.
-
The NIK-RR test statistic is based on the comparison of the ECDF to a reference distribution, while the B-NIK test statistic is based on the comparison of the sample mean and variance to their expected values under the assumption of normality.
-
The NIK-RR test statistic has been shown to be more powerful than the B-NIK test statistic in some situations, especially when the sample size is small or when the data is not exactly normal.
For the purpose of this investigation, we gathered fresh, actual data from an Algerian emergency room, and we referred to this information as emergency care data. We model the time-to-event data for the individuals in the sample who have a given medical condition by utilising methodologies from survival analysis. The newly collected data on emergency care is analyzed using the recommended QXg-F model, the frailty model under the Weibull baseline hazard-rate function (WBH-F) (also known as the Weibull frailty (W-F) model), and the Gompertz baseline hazard-rate function (GBH-F) (also known as the Gompertz frailty (G-F) model. We show that the QXg-F model that was recommended is a good fit for the new data on emergency care, and that it produces correct estimates of the survival function and the hazard rate. Therefore, the QXg-F model demonstrated its superiority when compared to both the W-F model and the G-F model. Furthermore, in the field of analysing and evaluating the risks that insurance companies are exposed to by evaluating and analysing insurance claims data by studying a set of commonly used financial indicators such as the value-at-risk (V-R), tail-value-at-risk (TLV-R), tail variance (T-VC), tail Mean-Variance (TM-V), and the mean excess loss (M-EXL) function (see Furman The following methods of estimation are addressed for the purpose of computing the primary key risk indicators (KRIs): the maximal likelihood estimate, also known as maximum likelihood estimation (MaxLE), the ordinary least squares estimation, also known as OrLSE, the weighted least squares estimation, and the Anderson Darling estimation, also known as AnDE. These four aforementioned approaches were used and applied in two different directions of financial and actuarial assessment, one of which was simulation under three confidence levels (C-Ls), and various sample sizes are considered for applications to insurance claims data. The other route involved the use of these methods in a different manner.
The main motivation of this paper is to:
-
Present a new flexible frailty model called the QXg-F model for the survival analysis.
-
Employ the QXg-F model in the survival analysis under a newly collected data called emergency care data.
-
Using the MaxLE method is used for estimating the QXg-F model’s parameters of WBH-F and in case of GBH-F.
-
Propose an alternative frailty model which overcomes the weak point of the gamma frailty model.
-
Testing the validity using the NIK-RR test statistic in case of complete data.
-
Testing the validity using the B-NIK test statistic in case of censored data.
-
Test the ability of the new QXg-F model in risk analysis by studying a set of commonly used financial indicators such as the V-R, TLV-R, T-VC, TM-V, M-EXL function under different estimation methods like the MaxLE method, OrLSE method, the WLSE method, and the AnDE method.
In short, the primary focus of this study is the introduction of the QXg-F Model. This model expands upon the traditional gamma frailty model by using a more adaptable distribution, namely the Xgamma distribution. By doing this, it offers a more adaptable method for modelling the vulnerability impact in the context of emergency care data. This model enables a more precise depiction of the unobserved variability among individuals, a common occurrence in healthcare data sets. The research utilizes the QXg-F Model to analyze a dataset from the emergency care area. The conducted survival study within the model yields valuable data regarding the probability of survival and rates of hazard for patients. It aids in identifying the key elements that have a major impact on survival outcomes in this particular scenario. The authors perform thorough validation tests to evaluate the performance of the QXg-F Model. They utilize goodness-of-fit tests, cross-validation, and other validation approaches to guarantee the accuracy and dependability of the model. The results of these tests establish confidence in the model’s ability to capture the underlying heterogeneity in the data.
The paper expands its analysis to include risk assessment, enabling a thorough review of patient outcomes in the emergency care context. The practical ramifications of this research are highly relevant for healthcare practitioners, as it can provide valuable insights for making decisions regarding the allocation of resources, treatment procedures, and patient prioritization. The QXg-F Model is a new and inventive statistical technique. This tool enhances the selection of frailty models for survival analysis, therefore serving as a vital asset in the statistical toolkit for researchers across many disciplines. By utilizing the model on emergency care data, the research establishes a connection between theoretical statistical technique and practical healthcare applications. This study offers valuable information on survival outcomes and risk factors that can inform clinical decision-making. The model used in this study has undergone comprehensive validation testing, ensuring its reliability and robustness. Researchers can be certain of its relevance to other datasets exhibiting comparable properties. The results of this study have significant ramifications for both the scientific community and medical professionals. The QXg-F Model holds promise as a valuable instrument for analyzing healthcare data, specifically in the realm of emergency care. The capacity to consider diversity and precisely calculate survival probabilities can aid healthcare practitioners in making well-informed decisions about patient care and resource distribution. Moreover, the paper’s focus on validation and testing establishes a benchmark for statistical modelling in the healthcare field. Implementing this methodology in additional research endeavours can bolster the dependability of findings and guarantee that statistical models faithfully depict the fundamental facts.
The Cox-frailty model
Consider the Cox proportional hazard (Cox-PH) model (see21) and an unexplained source of heterogeneity. Let \(Z>0\) and for an unobserved random variable that represents the frailty of the object. Then, the hazard-rate function for the i\(^{th}\) item is
where \(\lambda _{0}(\cdot )\) refers to the hazard-rate function of the baseline model, \(\underline{\varvec{\beta }}=\underline{ \varvec{\beta }}_{\left( p\times 1\right) }\) is the vector of unknown regression coefficients for all \(p<n\) (see22), where subject i has a unique frailty \(z_{i}\), which is an unobserved non-negative number. Hence, if \(z_{i}>1\) or \(z_{i}<1\), respectively, frailty \(z_{i}\) raises or reduces the chance of occurrence of the event of our interest. The Cox-PH model is produced as a specific instance where \(z_{i}=1\) for every i. The following is how the model in Eq. (1) is used to determine the conditional survival function for the ith subject:
where the cumulative baseline hazard-rate function is \(\Lambda _{0}(t_{i})=\int _{0}^{t_{i}}\lambda _{0}(s)ds\). The conditional survival function (2) thus indicates the likelihood that the i\(^{th}\) subject will live until time \(t_{i}\) given \(Z=z_{i}\). We must integrate out the conditional survival function (Eq. 2) on frailty in order to obtain the marginal survival (Mar-S) function, which does not depend on unseen variables. Keep in mind that this is equal to computing the frailty distribution’s Laplace transform. In reality, if f(z) is the frailty distribution, then we may get the following by integrating \(S(t_{i}\mid z_{i},x_{i})\) from Eq. (2) on \(Z=z_{i}\):
where \(L_{f}(\cdot )\) stands for the frailty distribution’s Laplace transform, and the appropriate marginal probability density function (MPDF) is
Take into account that the Laplace transform has a closed form for each of the distributions above. As a result, Eq. (3) may be used to derive the marginal hazard (Mar-H) function as follows:
where \(L_{f}^{^{\prime }}(t)=\frac{\partial }{\partial t}L_{f}(t)\). The risk and survival of a person randomly selected from the research population are therefore calculated using the hazard and Mar-S functions (illustrated above) (see23). If the frailty distribution does not have a Laplace transform in closed form, it becomes necessary to use numerical integration or Markov Chain Monte Carlo methods (see24,25,26,27). The consideration of frailty distribution is crucial for ensuring computational simplicity in both univariate and multivariate survival data modeling (see9,23). Hazard and Mar-S functions were created in this study.
The QXg-F model
Following Sen and Chandra (2017), the probability density function (PDF) of the QXg model can be expressed as
where \(\underline{\textbf{P}}=\left( \zeta ,\theta \right) .\) Consider the frailty model in Eq. (1) where Z is our frailty variable which has a QXg distribution with mean one. This assumption is required to identify the parameters of the derived model (see28). Hence, employing Mazucheli’s29 alternate parameterization of the QXg model in terms of mean, the PDF of the QXg-F model becomes
where \(\zeta >0\) represents the (unknown) shape parameter. The variance of the frailty distribution is commonly used to quantify the level of unobserved variation in a research sample. If the PDF (5) is assumed to be our frailty model, then, the variance can be expressed as
The frailty PDF (6)’s Laplace transform, depending on its variance and \(S\in {\mathbb {R}}\), is given by:
where \({\mathbb {C}}\left[ \sigma ^{2}\right] =13-12\sigma ^{2}\) and\(\ \sigma ^{2}\le \frac{13}{12}.\) In order to maintain simplicity, we analyze (7) at \(S=\Lambda _{0}(t_{i})\xi _{i}\), where \(\xi _{i}\) =\(\exp (x_{i}^{T}\underline{ \varvec{\beta }})\), and find that the Mar-S function (Eq. 3) under QXg-F model is provided by
The resulting Mar-H function (Eq. 4) is as follows:
where
and
The QXg-F model under the WBH-F
Consider the baseline W model, then have:
where \(\kappa >0\) represents the shape parameter and \(\rho >0\) represents the scale parameter. The hazard-rate function of the Weibull distribution drops monotonously for \(\kappa <1\); it is constant over time for \(\kappa =1\) (exponential distribution); and it grows monotony when \(\kappa >1\)23. As a result of plugging Eq. (10) into Eqs. (9) and (8), the QXg-F model’s Mar-S and hazard functions with WBH-F are, respectively,
and
The QXg-F model under the GBH-F
Consider the baseline G model, then have:
where \(\kappa _{1}>0\) and \(\rho _{1}>0\) are the shape and scale parameters. If \(\kappa _{1}<0\), the Gompertz distribution is flawed (Calsavara et al. (2019a) and Calsavara et al. (2019b)), since its cumulative hazard-rate function converges to the constant \(-\dfrac{\rho _{1}}{\kappa _{1}}\) for \(t\rightarrow \infty\), resulting in a cure or long-term survivors fraction \(p_{0}=exp(\frac{\rho _{1}}{\kappa _{1}})\) in the research population. The exponential distribution is derived as a special case for \(\kappa _{1}=0\). As a result, the Gompertz distribution’s hazard-rate function might be decreasing \((\kappa _{1}<0)\), constant \((\kappa _{1}=0)\), or increasing \((\kappa _{1}>0)\). The Mg-Su and hazard functions of the QXg-F model with GBH-F are calculated by inserting Eq. (12) into Eqs. (9) and (8),
and
Estimating the QXg-F model
Case of WBH-F
The MxLEs have appealing qualities under specific regularity constraints, such as consistency, efficiency, asymptotic normality, and others30. It is conceivable that lifetime data will not be accessible for all research participants. Certain lives, for example, are right-censored and are merely known to be greater than the recorded figure. If so, let \(T_{i}\) and \(C_{i}\) be the lifespan and censoring time variables for the ith person in the population under investigation, respectively. Assume \(T_{i}\) and \(C_{i}\) are independent random variables, and \(\delta _{i}=\textbf{I}_{(T_{i}\le C_{i})}\) is the censoring indicator (i.e., \(\delta _{i}=1\) if \(T_{i}\) is lifetime, and \(\delta _{i}=0\) otherwise). Then we see that \(t_{i}=min\{T_{i},C_{i}\}\). Let \(x_{i}\) represent a \(p\times 1\) vector of variables observed in the \(i^{th}\) subject. The likelihood function for the model parameter vector \(\underline{\textbf{P}}\) under non-informative censoring is thus provided from a sample of n participants as \(L(\underline{\textbf{P}})=\overset{n}{\underset{i=1}{\prod }}\lambda (t_{i}\mid x_{i})^{\delta _{i}}S(t_{i}\mid x_{i}),\) where \(S(\cdot \mid x_{i})\) and \(\lambda (\cdot \mid x_{i})\) are the Mg-Su and hazard functions given in Eqs. (8) and (9). As a result, the associated log-likelihood function is calculated using the natural logarithm of \(L(\underline{\textbf{P}})\). Then, the log likelihood function for \(\underline{\textbf{P}}=(\kappa ,\rho ,\sigma ^{2},\underline{ \varvec{\beta }})\) is given by
where: \(r=\overset{n}{\underset{i=1}{\sum }}\delta _{i}\) is the failure number,
and
Setting the nonlinear system of the score equations \(\textbf{I}_{\left( \kappa \right) }=0,\textbf{I}_{\left( \rho \right) }=0,\textbf{I}_{\left( \sigma ^{2}\right) }=0\) and \(\textbf{I}_{\left( \underline{\varvec{\beta }} \right) }=0\) and solving them simultaneously yields the MaxLE \(\widehat{ \underline{\textbf{P}}}=(\widehat{\kappa },\widehat{\rho },\widehat{\sigma ^{2}},\widehat{\underline{\varvec{\beta }}})^{\intercal }\). It is usually more convenient to use nonlinear optimization methods to solve these equations; such as the quasi-Newton algorithm to numerically maximize \(\log L(\underline{\textbf{P}})\), for more applications see30.
Simulations: case of WBH-F
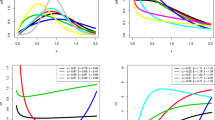
We consider the QXg-F model with WBH-F. The data were simulated \(N=13,000\) times; with parameter values \(\kappa =0.8,\) \(\rho =0.9,\) \(\sigma ^{2}=0.6,\) \(\beta _{1}=0.5\) and sample sizes \(n=20,\) \(n=50,\) \(n=300\) and \(n=1000\). Due to Ravi and Gelpert31, the BB (Barzilai-Borwein) algorithm is considered for estimating the average values of the MaxLE. \(\widehat{\kappa },\widehat{\rho },\widehat{\sigma ^{2}},\widehat{ \beta _{1}}\) parameters and their mean squared errors (MSE). Results are presented in Table 1. From Table 1, we observe that the maximum likelihood estimates for the QXg-F model with WBH-F are convergent.
Case of GBH-F
Using the GBH-F, the log-likelihood function for \(\underline{ \textbf{P}}=(\kappa _{1},\rho _{1},\sigma ^{2},\beta )\) is given as follows:
where
and
Maximizing the log-likelihood functions Eqs. (16) and (17), respectively, yields the appropriate MaxLE estimators \(\widehat{\underline{\textbf{P}}}\) of parameter vectors \(\underline{\textbf{P}}\). It is worth noting that \(\widehat{\underline{\textbf{P}}}\) does not have a closed form. These optimization approaches are implemented in BBsolve R software packages (Ravi and Gilbert31).
Simulations: case of GBH-F
We consider the QXg-F model with GBH-F. The data were simulated \(N=13,000\) times; with parameter values\(\kappa =1.07,\) \(\rho =0.5,\) \(\sigma ^{2}=0.7,\) \(\beta _{1}=0.3\) and sample sizes \(n=20,n=50,n=300\) and \(n=1000\). Using the R software and the Barzilai-Borwein (BB) algorithm (Ravi and Gilbert31) for calculating the averages of the simulated values of the maximum likelihood estimators \(\widehat{\kappa },\widehat{\rho },\widehat{\sigma ^{2}},\widehat{ \beta _{1}}\) parameters and their mean squared errors (MSE). Results are presented in Table 2. From Table 2, we observe that the maximum likelihood estimates for the QXg-F model with GBH-F are convergent.
Validating the QXg-F model using the NIK-RR test
There are many applications for the NIK-RR test statistic, making it a valuable tool for statistical analysis. It is particularly useful for selecting a model, assessing the goodness of fit of a model, and pinpointing problems with a model (more details may be found in Nikulin13, Nikulin14, Nikulin15, Nikulin13, and Rao and Robson16. The NIK-RR test statistic’s capacity to identify deviations from normalcy that other statistical tests might miss is one of its main features. Under the NIK-RR statistic, we need to test the following null hypothesis
Then, the NIK-RR statistic can be expressed as
where
and
refers to the information matrix where
and
The \(Y^{2}(\widehat{\underline{\textbf{P}}}_{n})\) statistic has \(\left( b-1\right)\) degrees of freedom (DF) and is accompanied by the \(\chi _{b-1}^{2}\) distribution, where the random sample. \(x_{1},x_{2},\cdots ,x_{n}\) are collected in \(\textbf{I}_{1},\textbf{I}_{2},\ldots ,\textbf{I}_{b}\) (these b subintervals are mutually disjoint: \(\textbf{I}_{j}=]a_{j,b}-1;a_{j,b}]\) ). The intervals \(\textbf{I}_{j}\)’s limits for \(a_{j,b}\) are determined as follows
and
Uncensored assessing for the NIK-RR statistic
To verify the null hypothesis \(H_{0}\) We thus produced the NIK-RR statistics of the QXg-F model to confirm that the sample is a 13000 using simulated samples n=25, n=50, n=150, n=350, n=550 and n=1000. Regarding various theoretical levels \(\left( \epsilon =0.01,0.02,0.05,0.1\right)\), for the null hypothesis, we compute the average of the non-rejection numbers. \(Y^{2}\le\) \(\chi _{\epsilon }^{2}\left( b-1\right)\). The appropriate empirical and theoretical levels are presented in Table 3. It is evident that there is a good agreement between the calculated empirical level value and its equal theoretical level value. We therefore conclude that the proposed test is quite good for the QXg-F distribution.
Validation testing under the QXg-F and the B-NIK
According to Bagdonavicius and Nikulin17 and Bagdonavicius et al.32, one can verify the suitability of the QXg-F model when the parameters are unknown and the data are censored where null hypothesis can be expressed as
Let’s divide the limited amount of time \([0,\tau ]\) into \(\kappa |\kappa =1,2,\cdots ,s\) shorter time periods. Where is the maximum runtime of the research and \(\textbf{I}_{j}=(a_{j-1},a_{j,b}];\) \(0=<a_{0,b}<a_{1,b}...<a_{ \kappa -1,b}<a_{\kappa ,b}=+\infty .\) The anticipated worth of \(\widehat{ a_{j,b}}\) can be said the following if \(x_{(i)}\) is the \(i^{th}\) element in the ordered statistics \((x_{(1)},,,x_{(n)})\) and if \(\varvec{\Lambda }^{-1}\) refers to the cumulative hazard-rate function and
where
and
The \(a_{j,b}\) functions for random data, and the \(e_{j,Z}\) For the \(\kappa\) selected periods, anticipated failure rates are equal. Statistical data \(Y_{n}^{2}=\textbf{Z}^{T}\widehat{\textbf{S}}^{-1}\textbf{Z}\), where \(\textbf{Z}=(Z_{1},...,Z_{\kappa })^{x},\) \(Z_{j}=\frac{1}{\sqrt{n}}(\textbf{W} _{j,Z}-e_{j,Z})|_{\left( \ j=1,2,...,\kappa \right) }\) and \(\textbf{W}_{j,Z}\) can be used to test a hypothesis since it reflects the total number of failures that have been recorded throughout these time-shared. The elements of the B-NIK test statistic
where
and
and
Censored-assessment under the B-NIK test
It is intended that the sample that was produced \(\left( N=13000\right)\) will be censored at \(25\%\) and that DF\(=5\) To check if the sample agrees with the QXg-F model’s null hypothesis, grouping intervals will be used. For various theoretical levels, we determine the average value of the non-rejection numbers of the null hypothesis. \(\left( \epsilon =0.01,0.02,0.05,0.1\right)\), where \(Y^{2}\le\) \(\chi _{\epsilon }^{2}\left( r-1\right)\). The theoretical and empirical levels are compared in Table 4, which demonstrates how closely the determined empirical level matches the value of the relevant theoretical level. We conclude that the customized test is ideally suited to the QXg-F model as a consequence.
We conclude from these findings that the empirical significance level of the \(Y_{n}^{2}\) The theoretical significance level of the chi- square distribution with specific degrees of freedom aligns with the statistical significance level at which it becomes significant. Therefore, based on this evidence, the censored data obtained from the QXg-F distribution can be effectively fitted using the recommended test.
The emergency care data
In medicine, frailty models are used to analyze the risk factors and prognosis of various diseases. They allow researchers to examine the impact of individual-level covariates (such as age, gender, and genetic factors) on patient outcomes, while also considering unmeasured or unobserved factors that may influence the risk of disease progression or mortality. Frailty models are often used in epidemiological studies, clinical trials, and studies involving patient cohorts to assess the effects of different treatments or interventions.
The emergency department of a the hospital of the public proximity health institution (Echatt, El tarf, Algeria), provided real data that were collected throughout the month of March 2023, which was used in the current study. The goal of this study was to examine, in a sample of people seeking medical care at the department, the relationship between various clinical variables and emergency room outcomes. The necessary approvals were obtained, and data collection was conducted under ethical guidelines. There were 30 different persons in the dataset, each of whom represented a distinct observation. Each person’s age (years), minimum and maximum blood pressure (mmHg), blood glucose level (mg/dL), cardiac frequency (BPM), and oxygen saturation (SaO2 %) were measured as six different variables. Strenuous measures were put in place during the data collection process to guarantee data quality and accuracy. This required accurate patient data documentation, adherence to established measurement techniques, and routine quality checks to catch any missing information or discrepancies. The thorough data collection process and the diversity of the patient population make this dataset valuable for examining the links between clinical factors and emergency room outcomes. By assessing the QXg-F model distribution’s goodness-of-fit and its capacity to faithfully represent the observed patterns and variability in emergency care data, we are able to explore the validity and application of the distribution. We present the point estimates for each fitted model (QXg-F model with Weibull baseline hazard-rate function and QXg-F model with Gompertz baseline hazard-rate function). The well known modified chi-squared test (see17) is supplied to identify the best model among all fitted models to this data.
Validation of the QXg-F model under the Weibull baseline hazard-rate function
Assuming that these data are distributed according to the QXg-F model with Weibull baseline hazard-rate function. Then, using R statistical software (the BB package), the maximum likelihood estimates of the parameter vector \(\underline{\textbf{P}}\) are obtained as
According to Bagdonavičius and Nikulin17 for censored data, we take for example 5 intervals \(\left( r=5\right)\) as number of classes. The elements of the estimated Fisher information matrix \(I\left( \widehat{ \underline{\textbf{P}}}\right)\) are presented as follows:
Then we calculate the value of the test statistic as \(Y_{n}^{2}=8.076495.\) The critical value is \(\chi _{0.05}^{2}(4)=9.488>Y_{n}^{2},.\) This data can be fitted by our proposed QXg-F model with Weibull baseline hazard-rate function in proper manner.
Validation of the QXg-F model under the Gompertz baseline hazard-rate function
Assuming that these data are distributed according to the QXg-F model with Gompertz baseline hazard-rate function. Then, using R statistical software (the BB package), the maximum likelihood estimator of the parameter vector \(\underline{\textbf{P}}\) can be obtained as
We take \(r=5\) intervals and the estimated Fisher matrix expressed as
then we calculate the value of the Bagdonavičius and Nikulin17 statistic : \(Y_{n}^{2}=7.43821106\). For different critical values : \(\alpha =5\%\) and \(\alpha =10\%\), we find \(Y^{2}<\chi _{0.05}^{2}\left( 5-1\right) =9.488\) and \(Y^{2}<\chi _{0.1}^{2}\left( 5-1\right) =7.779\) respectively. Hence we reason that the emergency care data is compatible with our proposed QXg-F model with Gompertz baseline hazard-rate function.
Testing the ability of the new QXg-F model in risk analysis
In risk analysis, frailty models can be used to predict the probability of an event taking place, such as the risk of developing a specific disease or suffering a specific adverse event, while also taking into consideration individual characteristics that may influence how the risk is affected. To model risks and to construct models for risk prediction, fragility models have been utilized in a wide variety of sectors, including epidemiology, medical research, and actuarial science, amongst others. The use of frailty models can provide more accurate estimates of risk and increase understanding of the underlying mechanisms that determine the risk of an occurrence. Both of these benefits can be realized simultaneously. In the fields of insurance and actuarial science, frailty models are applied in order to take into account the fact that individuals’ rates of death are very variable. This variation may be attributable to a wide range of factors, such as age, gender, current health state, lifestyle choices, and genetic predisposition. Insurers can more properly price their insurance products using frailty models, and they can also better control the risks to which they are exposed. In the fields of insurance and actuarial science, some of the specific uses of frailty models include the following:
-
1.
It is possible to employ frailty models in order to estimate the probable future mortality of a group of individuals, which may subsequently be used in order to price life insurance premiums.
-
2.
The present value of an annuity is the amount of money that an individual would need to invest today in order to obtain a guaranteed income stream for the rest of their life. Frailty models can be used to estimate the present value of an annuity. This is the amount of money that an individual would need to invest today in order to acquire this income stream.
-
3.
Identifying and managing the risks that are connected to a specific insurance product or portfolio of products can be accomplished with the assistance of frailty models. To identify high-risk individuals who are more prone to file claims, an insurer might, for instance, utilize a frailty model.
-
4.
The application of fragility models is a powerful instrument that has the potential to enhance the precision and effectiveness of insurance pricing as well as risk management. Frailty models are anticipated to become increasingly more commonly employed in the insurance sector as the discipline of actuarial science continues to develop and progress.
The application of frailty models in the fields of actuarial science and insurance provides the following additional benefits:
-
1.
Insurers may benefit from using frailty models since it helps them gain a better understanding of the risk of loss connected with a certain individual or group of individuals. This can lead to decisions regarding pricing and underwriting that are more accurate.
-
2.
Insurance companies can build solutions that are more suited to meet the requirements of individual clients with the use of frailty models. This may result in improved levels of satisfaction and loyalty among customers.
-
3.
Insurers can automate a significant portion of the work that is related with risk assessment and pricing with the use of frailty models. This may result in cost savings as well as enhanced operational efficacy.
Risk indicators for the new QXg-F model
It is not necessary to supply any further characterization of risk exposure beyond what may be provided by probability-based distributions. Most of the time, one value or at the very least a small collection of numbers is used to describe the level of risk exposure. These data on risk exposure are plainly functions of a particular model. They are commonly referred to as important key risk indicators (KRIs), which is an abbreviation for key risk indicator. Actuaries and risk managers commonly concentrate their efforts on evaluating the possibility of an adverse outcome, which can be communicated through the use of the V-R indicator at a specific probability or confidence level.
This indicator is frequently used to calculate the amount of capital needed to deal with such probable negative situations. The V-R of the QXg-F model at the \(100q\%\) level, say V-R\(\left( Z;\underline{\textbf{P}}\right)\) or \(\pi \left( q\right)\), is the \(100q\%\) quantile (or percentile). Then, we can simply write
where \(Q\left( U\right)\) is quantile function of the QXg-F model, for a one-year time when \(q=99\%\), the interpretation is that there is only a very small chance (\(1\%\)) that the insurance company will be bankrupted by an adverse outcome over the next year. Generally speaking, if the distribution of gains (or losses) is limited to the normal distribution, it is acknowledged that the number V-R\(\left( Z;\underline{\textbf{P}}\right)\) meets all coherence requirements. The data sets for insurance such as the insurance claims and reinsurance revenues are typically skewed whether to the right or to the left , though. Using the normal distribution to describe the revenues from reinsurance and insurance claims is not suitable. The TLV-R \(\left( Z;\underline{\textbf{P}}\right)\) of Z at the \(100q\%\) confidence level is the expected loss given that the loss exceeds the \(100q\%\) of the distribution of Z, then the TLV-R of Z can be expressed as
The quantity TLV-R\(\left( Z;\underline{\textbf{P}}\right)\), which gives further details about the tail of the QXg-F distribution, is therefore the average of all the V-R values mentioned above at the confidence level q. Moreover, the TLV-R(Z) can also be expressed as TLV-R\(\left( Z;\underline{ \textbf{P}}\right) =e\left( Z;\underline{\textbf{P}}\right) +\)V-R\(\left( Z; \underline{\textbf{P}}\right) ,\) where \(e\left( Z;\underline{\textbf{P}} \right)\) is the mean excess loss (M-EXL\(\left( Z;\underline{\textbf{P}} \right)\)) function evaluated at the \(100q\%^{th}\) quantile (see33,34,35). When the \(e\left( Z;\underline{ \textbf{P}}\right)\) value vanishes, then TLV-R\(\left( Z;\underline{\textbf{P }}\right) =\)V-R\(\left( Z;\underline{\textbf{P}}\right)\) and for the very small values of \(e\left( Z;\underline{\textbf{P}}\right)\), the value of TLV-R\(\left( Z;\underline{\textbf{P}}\right)\) will be very close to V-R\(\left( Z;\underline{\textbf{P}}\right) .\)The T-VC risk indicator, which Furman and Landsman36 developed, calculates the loss’s deviation from the average along a tail. Explicit expressions for the T-VC risk indicator under the multivariate normal distribution were also developed by Furman and Landsman36. The T-VC risk indicator (T-VC\(\left( Z;\underline{\textbf{P} }\right)\)) can then be expressed as
As a statistic for the best portfolio choice, Landsman37 developed the TMVK risk indicator, which is based on the T-VC risk indicator. Consequently, the TMVK risk indicator may be written as
Then, for any RV, TMVK\(\left( Z;\underline{\textbf{P}}\right)>\)T-VC\(\left( Z;\underline{\textbf{P}}\right)\) and, for \(\pi =1\), TMVK\(\left( Z; \underline{\textbf{P}}\right) =\)TLV-R\(\left( Z;\underline{\textbf{P}}\right) .\)
Assessing under different estimation methods via simulations
In this section, we assess the MaxLE, the OLS, the WLSE, the AnDE methods for calculating the KRIs. These quantities are estimated using \(N=1,000\) with different sample sizes \((n=20,50,100)\) and three confidence levels (C-Ls) (\(q=(50\%,60\%,70\%,90\%,99\%)\)). All results are reported in Table 5 (KRIs under artificial data for n=20), Table 6 (KRIs under artificial data for n=50) and Table 7 (KRIs under artificial data for n=100) from which we conclude: V-R\(\left( Z;\underline{\textbf{P}}\right)\), TLV-R\(\left( Z; \underline{\textbf{P}}\right)\) and TMVK\(\left( Z;\underline{\textbf{P}} \right)\) increase when q increases for all estimation methods. V-R\(\left( Z;\underline{\textbf{P}}\right) _{\text {WLS}}<\)V-R\(\left( Z;\underline{ \textbf{P}}\right) _{\text {AnDE}}<\)V-R\(\left( Z;\underline{\textbf{P}} \right) _{\text {MaxLE}}<\) V-R\(\left( Z;\underline{\textbf{P}}\right) _{\text { OrLSE}}\) for most q. TLV-R\(\left( Z;\underline{\textbf{P}}\right) _{\text { WLS}}<\)TLV-R\(\left( Z;\underline{\textbf{P}}\right) _{\text {AnDE}}<\)TLV-R\(\left( Z;\underline{\textbf{P}}\right) _{\text {MaxLE}}<\)TLV-R\(\left( Z; \underline{\textbf{P}}\right) _{\text {OrLSE}}\) for most q.
Assessing under different estimation methods via insurance data
As a concrete example, in this section of the essay, we take a look at the insurance claims payment triangle from the perspective of a United Kingdom Motor Non-Comprehensive account. We find the years 2007 to 2013 to be the most convenient origin era. The data on the claims are presented within the insurance claims payment data frame in the format that one would typically find it organised within a database. The first column contains information pertaining to the origin year, which can fall anywhere between 2007 and 2013, the development year, as well as the incremental payments. It is essential to point out that the data on insurance claims were initially analysed using a probability-based distribution. This was done in the beginning of the process. The ability of the insurance company to deal with events of this nature is something that actuaries, regulators, investors, and rating agencies all place a high level of weight on. This study suggests a number of KRI quantities for the left-skewed insurance claims data based on the QXg-F distribution. These quantities include VAR, TVAR, T-VC, and TM-V (see38 for more information). In Table 8, the KRIs that are included under the insurance calculations data are broken down according to each and every estimating method used for the QXg-F model.
Based on Table 8, the following results can be highlighted:
-
1.
In general, whatever the risk assessment method:
$$\begin{aligned} \text {V-R}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)<\text {V-R}(Z; \widehat{\underline{\textbf{P}}}|1-q=40\%) \\< & {} ...<\text {V-R}(Z;\widehat{\underline{\textbf{P}}}|1-q=5\%)<\text {V-R}(Z; \widehat{\underline{\textbf{P}}}|1-q=1\%). \end{aligned}$$ -
2.
Also,
$$\begin{aligned} \text {TLV-R}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)<\text {TLV-R}(Z; \widehat{\underline{\textbf{P}}}|1-q=40\%) \\< & {} ...<\text {TLV-R}(Z;\widehat{\underline{\textbf{P}}}|1-q=5\%)<\text {TLV-R} (Z;\widehat{\underline{\textbf{P}}}|1-q=1\%). \end{aligned}$$ -
3.
In general, whatever the risk assessment method:
$$\begin{aligned} \text {T-VC}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)>\text {T-VC}(Z; \widehat{\underline{\textbf{P}}}|1-q=40\%) \\> & {} ...>\text {T-VC}(Z;\widehat{\underline{\textbf{P}}}|1-q=5\%)>\text {T-VC}(Z; \widehat{\underline{\textbf{P}}}|1-q=1\%). \end{aligned}$$ -
4.
Moreover
$$\begin{aligned} \text {TMVK}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)>\text {TMVK}(Z; \widehat{\underline{\textbf{P}}}|1-q=40\%) \\> & {} ...>\text {TMVK}(Z;\widehat{\underline{\textbf{P}}}|1-q=5\%)>\text {TMVK}(Z; \widehat{\underline{\textbf{P}}}|1-q=1\%). \end{aligned}$$ -
5.
Finally
$$\begin{aligned} \text {MELS}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)>\text {MELS}(Z; \widehat{\underline{\textbf{P}}}|1-q=40\%) \\> & {} ...>\text {MELS}(Z;\widehat{\underline{\textbf{P}}}|1-q=5\%)>\text {MELS}(Z; \widehat{\underline{\textbf{P}}}|1-q=1\%). \end{aligned}$$ -
6.
Under the MaxLE method: The V-R\(\left( Z;\widehat{\underline{\textbf{P} }}\right)\) is monotonically increasing indicator, the TLV-R\(\left( Z; \widehat{\underline{\textbf{P}}}\right)\) is increases steadily and continuously. However the T-VC\(\left( Z;\widehat{\underline{\textbf{P}}}\right)\), the TMVK\(\left( Z;\widehat{\underline{\textbf{P}}}\right)\) and the MELS\(\left( Z;\widehat{\underline{\textbf{P}}}\right)\) are increases steadily and continuously.
-
7.
Under the OrLSE method: The V-R\(\left( Z;\widehat{\underline{\textbf{P} }}\right)\) is monotonically increasing indicator, the TLV-R\(\left( Z; \widehat{\underline{\textbf{P}}}\right)\) is increases steadily and continuously. However the T-VC\(\left( Z;\widehat{\underline{\textbf{P}}}\right)\), the TMVK\(\left( Z;\widehat{\underline{\textbf{P}}}\right)\) and the MELS\(\left( Z;\widehat{\underline{\textbf{P}}}\right)\) are increases steadily and continuously.
Discussion
In this study, we proposed a novel quasi xgamma frailty (QXg-F) model for survival analysis. The QXg-F model aims to capture the complex interplay between frailty and survival outcomes, providing a more comprehensive understanding of the heterogeneity present in the data. To assess the suitability of the QXg-F model, we employ the Nikulin-Rao-Robson goodness-of-fit test, which evaluates how well the model’s distribution fits the observed data.
Our investigation extends beyond model development to include an in-depth examination of the QXg-F model’s properties and performance compared to other commonly used distributions in frailty modeling. Through simulation studies and real data applications, including a novel dataset from an emergency hospital in Algeria, we demonstrate the QXg-F model’s ability to accurately capture heterogeneity and improve model fit. Our findings suggest that the QXg-F model represents a promising alternative to existing frailty modeling distributions, with potential applications in various sectors, including emergency care.
Furthermore, we explore the utility and significance of the QXg-F model in insurance settings. By conducting simulations and applying the model to insurance data, we assess its performance and relevance in predicting survival outcomes and estimating risk in insurance contexts. This analysis provides valuable insights into the QXg-F model’s applicability beyond healthcare, highlighting its potential to enhance risk assessment and decision-making in insurance-related scenarios. Here are a few potential limitations that could be addressed:
-
The study may rely on certain assumptions about the underlying data distribution or the relationship between variables. It would be beneficial to validate these assumptions rigorously, as any inaccuracies or deviations could impact the validity of the findings.
-
The study’s conclusions may be based on a specific dataset, such as emergency care data, which could limit the generalizability of the results. Assessing the robustness of the findings across different datasets or populations would enhance the study’s applicability and relevance.
-
Introducing a novel model like the QXg-F model may add complexity to the analysis. While sophisticated models can offer valuable insights, they may also be more challenging to interpret and implement in practice. It would be helpful to provide clear explanations and guidelines for applying the model in real-world scenarios.
-
If the study includes risk analysis for emergency care data, it is essential to transparently outline the assumptions and methodologies used in the risk assessment. This ensures that stakeholders can critically evaluate the risk estimates and understand the associated uncertainties.
-
The analysis may overlook external factors or confounding variables that could influence the survival outcomes or introduce bias into the results. Accounting for potential confounders and conducting sensitivity analyses would enhance the study’s validity and reliability.
Conclusions and future points
This work suggested and analysed a flexible frailty model called as the quasi-Xgamma frailty (QXg-F) probapility model for statistical modeling of the unobserved-heterogeneity in survival and reliability data sets. We established both unconditional survival and hazard functions when we calculated the Laplace transform of this frailty distribution. The baseline hazard functions used to construct the two QXg-F models were the Gompertz and Weibull hazard functions are considered. The QXg distribution’s Laplace transform offers an easy mathematical technique for producing analytical formulas for the QXg-F model’s unconditional survival and hazard functions. All mathematical formulas and equations necessary for analysis the QXg-F model based on Gompertz (GBH-F) and Weibull hazard-rate function (WBH-F) have been derived and analyses. Many of the new algebraic derivations have been simplified and analyzed within the framework of this paper.
Simulation analyses pointed out that the convergence properties of the MLEs were satisfied under varying censoring proportions (\(0\%,\)\(10\%,\) \(30\%,\) and \(50\%\) of censoring), as expected. The proposed test statistic element formulations were developed using the QXg-F model. In addition to performing as expected, the modified chi-squared test confirmed its capacity to discover unobserved heterogeneity among small and large samples (\(n=25,\) \(n=50,\)\(n=150,\) \(n=350,\) \(n=550\)and \(n=1000\)).
The simulation results shows that the proposed test for the QXg-F model performs well in both completed and censored data sets. It indicates that the test is robust as well as accurate for testing the goodness of fit of our proposed model to real-life survival data. Through the presented simulation studies, the new QXg-F model under the GBH-F and WBH-F models has proven its efficiency and flexibility, and the model’s capabilities are characterized by efficiency, adequacy, consistency, and convergence. All of these results nominate the model for statistical modeling operations for new medical data.
As for the aspect of risk analysis under the new QXg-F model, we have conducted a comprehensive study to analyze the values at risk within the framework of a set of actuarial indicators, which are used for the first time in this framework of statistical analysis. For greater robustness in the estimation and actuarial analysis processes, we used more than one method to estimate the parameters of the new model, by also presenting some important comparisons. For assessing risk under different estimation methods via simulations, the following results are highlighted:
-
V-R\(\left( Z;\underline{\textbf{P}}\right)\), TLV-R\(\left( Z; \underline{\textbf{P}}\right)\) and TMVK\(\left( Z;\underline{\textbf{P}} \right)\) increase when q increases for all estimation methods.
-
V-R\(\left( Z;\underline{\textbf{P}}\right) _{\text {WLS}}<\)V-R\(\left( Z; \underline{\textbf{P}}\right) _{\text {AnDE}}<\)V-R\(\left( Z;\underline{ \textbf{P}}\right) _{\text {MaxLE}}<\) V-R\(\left( Z;\underline{\textbf{P}} \right) _{\text {OrLSE}}\) for most q values.
-
TLV-R\(\left( Z;\underline{\textbf{P}}\right) _{\text {WLS}}<\)TLV-R\(\left( Z;\underline{\textbf{P}}\right) _{\text {AnDE}}<\)TLV-R\(\left( Z; \underline{\textbf{P}}\right) _{\text {MaxLE}}<\)TLV-R\(\left( Z;\underline{ \textbf{P}}\right) _{\text {OrLSE}}\) for most q values.
For assessing risk under different estimation methods via the insurance data, the following results are highlighted:
-
1.
For all risk assessment methods:
$$\begin{aligned} \text {V-R}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)<...<\text {V-R}(Z; \widehat{\underline{\textbf{P}}}|1-q=1\%), \\ \text {TLV-R}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)<...<\text {TLV-R} (Z;\widehat{\underline{\textbf{P}}}|1-q=1\%).\\ \text {T-VC}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)>...>\text {T-VC} (Z;\widehat{\underline{\textbf{P}}}|1-q=1\%), \\ \text {TMVK}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)>...>\text {TMVK} (Z;\widehat{\underline{\textbf{P}}}|1-q=1\%).\\ \text {MELS}(Z;\widehat{\underline{\textbf{P}}}|1-q= & {} 50\%)>...>\text {MELS}(Z; \widehat{\underline{\textbf{P}}}|1-q=1\%). \end{aligned}$$ -
2.
Under the all estimation method, the V-R is monotonically increasing indicator, the TLV-R in monotonically increasing indicator. However the T-VC, the TMVK and the MELS are monotonically decreasing.
Some potential points and directions for future academic works:
-
1.
Explore further refinements and extensions of the QXg-F model. Researchers can work on developing more robust versions of the model to better capture the complexities of heterogeneity in emergency care data.
-
2.
Investigate how time-varying covariates can be integrated into the QXg-F model. This could be important for capturing changes in patient characteristics and risk factors over time.
-
3.
Apply the QXg-F model to real-life emergency care data and provide practical insights. This could involve analyzing specific medical conditions, patient cohorts, or healthcare facilities. See Goual et al.39,40 and Goual and Yousof41 for more relevant applications.
-
4.
Explore other advanced validation tests and sensitivity analyses to ensure the model’s reliability and robustness, especially in the context of emergency care data where patient outcomes can be time-sensitive and complex.
-
5.
Extend the use of the QXg-F model for predictive modeling.
-
6.
Introduce some new risk analysis indicators under the QXg-F model.
-
7.
Develop strategies for handling missing data within the context of emergency care data, as missing data is often prevalent in healthcare datasets. Evaluate how the model copes with missing information and propose imputation techniques.
-
8.
Explore methods to enhance the interpretability of the QXg-F model. This is crucial for healthcare practitioners to make informed decisions based on the model’s output.
-
9.
Investigate the feasibility of integrating the model into clinical decision support systems in emergency care settings. This could involve developing user-friendly software tools for healthcare professionals.
-
10.
Conduct epidemiological studies using the QXg-F model to gain insights into the patterns of diseases or health conditions in specific populations, including their survival probabilities and risk factors.
-
11.
Address ethical and privacy concerns related to the use of emergency care data, especially when conducting research involving patient records. Explore methods for de-identification and data anonymization.
-
12.
Investigate the model’s potential to aid in resource allocation decisions in emergency care, such as optimizing the allocation of healthcare personnel and equipment based on predicted patient needs.
-
13.
Applying the intelligent solution predictive networks and neuro-computational intelligence for analyzing the emergency care data set (see42 and43 and44).
Data availibility
The dataset can be provided by Hamami Loubna upon requested.
References
Vaupel, J. W., Manton, K. G. & Stallard, E. The impact of heterogeneity in individual frailty on the dynamics of mortality. Demography 16(3), 439–454 (1979).
Li, Y., Betensky, R. A., Louis, D. N. & Cairncross, J. G. The use of frailty hazard models for unrecognized heterogeneity that interacts with treatment: Considerations of efficiency and power. Biometrics 58(1), 232–236 (2002).
Therneau, T. M., Grambsch, P. M. & Pankratz, V. S. Penalized survival models and frailty. J. Comput. Graph. Stat. 12(1), 156–175 (2003).
Aalen, O. O. & Tretli, S. Analysing incidence of testis cancer by means of a frailty model. Cancer Causes Control 10, 285–292 (1999).
Clayton, D. G. A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika 65(1), 141–151 (1978).
Aalen, O. O. Heterogeneity in survival analysis. Stat. Med. 7, 1121–1137 (1988).
Aalen, O. O. Modelling heterogeneity in survival analysis by the compound Poisson distribution. Ann. Appl. Probab. 4(2), 951–972 (1992).
McGilchrist, C. A. & Aisbett, C. W. Regression with frailty in survival analysis. Biometrics 47, 461–466 (1991).
Pickles, A. & Crouchley, R. A comparison of frailty models for multivariate survival data. Stat. Med. 14(13), 1447–1461 (1995).
Box-Steffensmeier, J. M. & De Boef, S. Repeated events survival models: The conditional frailty model. Stat. Med. 25(20), 3518–3533 (2006).
Jiang, F. & Haneuse, S. A semi-parametric transformation frailty model for semi-competing risks survival data. Scand. J. Stat. 44(1), 112–129 (2017).
Mota, A., Milani, E. A., Calsavara, V. F., Tomazella, V. L. , Le ão, J., Ramos, P.L., Ferreira, P.H. & Louzada, F. Weighted Lindley frailty model: Estimation and application to lung cancer data. Lifetime Data Anal.27(4), 561–587 (2021).
Nikulin, M. S. Chi-squared test for normality. Proc. Int. Vilnius Conf. Probab. Theory Math. Stat. 2, 119–122 (1973a).
Nikulin, M. S. Chi-squared test for continuous distributions with shift and scale parameters. Theory Probab. Appl. 18, 559–568 (1973b).
Nikulin, M. S. On a Chi-squared test for continuous distributions. Theory Probab. Appl. 19, 638–639 (1973).
Rao, K. C. & Robson, D. S. A Chi-square statistic for goodness-of-fit tests within the exponential family. Commun. Stat. 3, 1139–1153 (1974).
Bagdonavičius, V. & Nikulin, M. Chi-squared goodness-of-fit test for right censored data. Int. J. Appl. Math. Stat. 24, 30–50 (2011).
Alizadeh, M., Afshari, M., Ranjbar, V., Merovci, F. & Yousof, H. M. A novel XGamma extension: applications and actuarial risk analysis under the reinsurance data. São Paulo. J Math Sci 1–31 (2023)
Yousof, H. M., Ali, M. M., Aidi, K. & Ibrahim, M. The modified Bagdonavičius–Nikulin goodness-of-fit test statistic for the right censored distributional validation with applications in medicine and reliability. Stat. Transit. New Ser. 24(4), 1–18 (2023a).
Yousof, H. M., Goual, H., Khaoula, M. K., Hamedani, G. G., Al-Aefaie, A. H., Ibrahim, M., Butt, N. S. & Salem, M. A novel accelerated failure time model: Characterizations, validation testing, different estimation methods and applications in engineering and medicine. Pak. J. Stat. Oper. Res. 691–717 (2023).
Cox, D. R. Regression models and life-tables. J. R. Stat. Soc. Ser. B (Methodol.) 34(2), 187–202 (1972).
Ibrahim, J., Chen, M. & Sinha, D. Bayesian Survival Analysis Springer Series in Statistics 978–981 (Springer, 2001).
Wienke, A. Frailty Models in Survival Analysis (CRC Press, 2010).
Balakrishnan, N. & Peng, Y. Generalized gamma frailty model. Stat. Med. 25(16), 2797–2816 (2006).
Hougaard, P. Analysis of Multivariate Survival Data (Springer, 2012).
Faradmal, J., Talebi, A., Rezaianzadeh, A., & Mahjub, H. Survival analysis of breast cancer patients using Cox and frailty models (2012).
Robert, C., & Casella, G. Monte Carlo Statistical Methods. (Springer , 2013).
Elbers, C. & Ridder, G. True and spurious duration dependence: The identifiability of the proportional hazard model. Rev. Econ. Stud. 49(3), 403–409 (1982).
Mazucheli, J., Coelho-Barros, E. A. & Achcar, J. A. An alternative reparametrization for the weighted Lindley distribution. Pesquisa Oper. 36(2), 345–353 (2016).
Lehmann, E. L. & Casella, G. Theory of Point Estimation (Springer, 2006).
Ravi, V. & Gilbert, P. D. BB: An R package for solving a large system of nonlinear equations and for optimizing a high-dimensional nonlinear objective function. J. Statist. Software. 32(4), 1–26 (2009).
Bagdonavičius, V., Levuliene, R. J. & Nikulin, M. Chi-squared goodness-of-fit tests for parametric accelerated failure time models. Commun. Stat.-Theory Methods 42(15), 2768–2785 (2013).
Acerbi, C. & Tasche, D. On the coherence of expected shortfall. J. Bank. Finance 26, 1487–1503 (2002).
Tasche, D. Expected shortfall and beyond. J. Bank. Finance 26, 1519–1533 (2002).
Wirch, J. Raising value at risk. N. Am. Actuarial J. 3, 106–115 (1999).
Furman, E. & Landsman, Z. Tail variance premium with applications for elliptical portfolio of risks. AS-TIN Bull. 36(2), 433–462 (2006).
Landsman, Z. On the tail mean-variance optimal portfolio selection. Insur. Math. Econ. 46, 547–553 (2010).
Artzner, P. Application of coherent risk measures to capital requirements in insurance. N. Am. Actuar. J. 3, 11–25 (1999).
Goual, H., Yousof, H. M. & Ali, M. M. Validation of the odd Lindley exponentiated exponential by a modified goodness of fit test with applications to censored and complete data. Pak. J. Stat. Oper. Res. 6, 745–771 (2019).
Goual, H. & Yousof, H. M. Validation of Burr XII inverse Rayleigh model via a modified Chi-squared goodness-of-fit test. J. Appl. Stat. 47(3), 393–423 (2020).
Goual, H., Yousof, H. M. & Ali, M. M. Lomax inverse Weibull model: Properties, applications, and a modified Chi-squared goodness-of-fit test for validation. J. Nonlinear Sci. Appl. (JNSA) 13(6), 330–353 (2020).
Anwar, N., Ahmad, I., Kiani, A. K., Shoaib, M., & Raja, M. A. Z. Intelligent solution predictive networks for non-linear tumor-immune delayed model. Comput. Methods Biomech. Biomed. Eng. 1–28 (2023).
Shoaib, M. et al. Intelligent networks knacks for numerical treatment of nonlinear multi-delays SVEIR epidemic systems with vaccination. Int. J. Mod. Phys. B 36(18), 2250100 (2022).
Shoaib, M. et al. Neuro-computational intelligence for numerical treatment of multiple delays SEIR model of worms propagation in wireless sensor networks. Biomed. Signal Process. Control 84, 104797 (2023).
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R735), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors are very grateful to Dr. Fassi Souad, the coordinating physician at the Neighborhood Public Health Institution in El Chatt, El Tarf, Algeria, for his significant assistance in gathering data for this study. His knowledge and assistance during the data gathering process were critical in guaranteeing the quality and correctness of the information gathered. I am deeply grateful to Dr. Fassi for his devotion and collaborative efforts, which contributed greatly to the overall success of our work.
Author information
Authors and Affiliations
Contributions
All authors participated and had equal shares in all stages of preparing the paper and made essential contributions to it. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Loubna, H., Goual, H., Alghamdi, F.M. et al. The quasi-xgamma frailty model with survival analysis under heterogeneity problem, validation testing, and risk analysis for emergency care data. Sci Rep 14, 8973 (2024). https://doi.org/10.1038/s41598-024-59137-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-59137-w
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
