
Abstract
In this paper, we present a human-based computation approach for the analysis of peripheral blood smear (PBS) images images in patients with Sickle Cell Disease (SCD). We used the Mechanical Turk microtask market to crowdsource the labeling of PBS images. We then use the expert-tagged erythrocytesIDB dataset to assess the accuracy and reliability of our proposal. Our results showed that when a robust consensus is achieved among the Mechanical Turk workers, probability of error is very low, based on comparison with expert analysis. This suggests that our proposed approach can be used to annotate datasets of PBS images, which can then be used to train automated methods for the diagnosis of SCD. In future work, we plan to explore the potential integration of our findings with outcomes obtained through automated methodologies. This could lead to the development of more accurate and reliable methods for the diagnosis of SCD.
Similar content being viewed by others

Introduction
Supervised machine learning methods rely on tagged training data1. The more tagged training data that is available, the more accurately the model can learn to recognize patterns and generalize to unseen data.
Crowdsourcing and Human-Based Computation (HBC) has become an increasingly popular approach for acquiring training labels in machine learning classification tasks, as it can be a cost-effective way to share the labeling effort among a large number of annotators. This approach can be particularly useful in cases where expert labeling is expensive or not feasible, or where a large amount of labeled data is needed to train a machine learning model2. There exist various tactics for human users to contribute their problem-solving skills3:
-
Altruistic contribution This strategy involves appealing to the altruistic nature of individuals willing to contribute their time and skills to solve problems for the common good4,5,6.
-
Gamification This strategy involves creating engaging and fun video games incorporating problem-solving tasks7,8,9.
-
Forced labor This strategy involves forcing website users to perform a task if they want to use its services10,11.
-
Microtask markets This strategy involves breaking down complex tasks into smaller, simpler tasks and then outsourcing them to a large group of people12,13.
Sickle Cell Disease (SCD) is a serious inherited blood disorder that affects millions of people worldwide. The disease is caused by a mutation in the HBB gene, which codes for one of the components of the hemoglobin protein, which produces abnormal hemoglobin molecules that can cause the Red Blood Cells (RBCs) to have the shape of a sickle or half-moon instead of the smooth, circular shape as normal RBCs have14. According to data from the World Health Organization (WHO)15, it is estimated that approximately 5% of the global population possesses the genetic traits associated with haemoglobin disorders, primarily SCD and thalassaemia. Furthermore, more than 300,000 infants born annually are afflicted with severe haemoglobin disorders. Globally, SCD resulted in 112,900 fatalities in 1990, 176,200 fatalities in 2013, and 55,3000 fatalities in 2016, as reported in previous studies16,17.
Morphological analysis of Peripheral Blood Smear (PBS) is a vital diagnostic aid for SCD. PBS cannot be used for diagnosing newborns (due to sickling of cells not occurring until the baby is a bit older and switches from producing hemoglobin F to hemoglobin A), which is actually the optimal time of diagnosing SCD. It is thus only suitable for diagnosing older babies/children and adults, but also useful for monitoring treatment outcomes of already diagnosed patients. However, it is a labor-intensive and time-consuming process, which can lead to delays in diagnosis and treatment. To address this issue, automated methods for analyzing blood samples are developed, which use image analysis and machine learning algorithms to detect and count sickle cells18,19,20. Due to this demanding and prolonged process, there is limited public availability of tagged PBS datasets from patients with SCD14,18,21,22,23.
We performed a systematic literature review24 about the use of crowdsourcing HBC systems for the analysis of medical images. From the findings of this systematic literature review, we derived guidelines for practitioners and scientists to help them improve their research on the topic. Non-expert HBC for RBC analysis showed promising results to detect malaria parasites in digitized blood sample images8,9 and a first attempt for SCD25. In the literature, we also found non-expert HBC approaches used for labeling various types of medical images24, including tomographs, MRIs, retinal images, breast cancer images, endoscopic images, microscopy images, polyps, and biomarkers. Mitry et al.26 showed encouriging results of crowdsourcing in retinal image analysis. They achieved sensitivity of 96% in normal versus severely abnormal detections, even without any restriction on eligible participants. Lung nodule detection with sensitivity of over 90% for 20 patient CT datasets 27 showed that crowdsourcing can provide highly accurate training data for computer-aided algorithms. Analysing biomedical images in Gurari et al. 28, Gurari et al. found that after experts, non-experts performed better than algorithms and that fusing those results together yielded improved final results.
In this paper, we present an approach for the analysis of PBS images in patients affected by SCD through crowdsourcing HBC with non-expert individuals using the Mechanical Turk (MTurk) that is an online crowdsourcing platform that allows individuals and businesses to outsource small tasks or “Human Intelligence Tasks” to a global network of workers. The design and experimental framework of our approach strictly adhered to the guidelines recommended by Petrovic et al.24 in the context of crowdsourcing methodologies. Additionally, we leveraged the expert-tagged erythrocytesIDB dataset, provided by Gonzalez et al.18, to establish the accuracy and reliability of our analysis. We utilized the predefined categories by the dataset: circular, elongated, and other cell classifications to facilitate SCD diagnosis, as meticulously curated and labeled by medical experts, to maintain consistency with the dataset’s structure, crucial for accurate analysis and cross-study comparisons.
The aim of our research was not to substitute automated procedures utilized for diagnostic assistance in the context of patients afflicted with SCD. Instead, the main objective was to investigate the feasibility of using HBC to help label large datasets to facilitate the training of automated methods, particularly in situations where expert assistance is not possible. In such instances, we were chiefly interested in determining the circumstances under which we can place almost complete confidence in the labels provided by non-expert users via HBC.
Methods and experiments
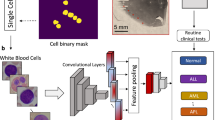
In this section, we propose the utilization of MTurk as a valuable tool for the analysis of PBS images obtained from patients with SCD. The dataset employed for this research comprised a comprehensive collection of PBS images derived from individuals diagnosed with SCD, obtained from a reputable medical institution. Prior to conducting the analysis, a preprocessing stage was executed to segment individual cells from full images. Subsequently, the preprocessed images were uploaded to the MTurk platform29, where a group of trained workers, who perform a wide range of tasks in exchange for payment, known as MTurkers, were assigned the task of examining and annotating various properties of the PBS within the images. The responses collected from the MTurkers were then subjected to a quantitative measure.
Dataset
We used erythrocytesIDB18, available at http://erythrocytesidb.uib.es/, which is a database of prepared blood samples from patients with SCD. The samples were obtained from voluntary donors by pricking their thumbs and collecting a drop of blood on a sheet. The blood was spread and fixed with a May-Grünwald methanol solution, and the images were acquired using a Leica microscope and a Kodak EasyShare V803 camera. Each image was labeled by a medical expert from “Dr. Juan Bruno Zayas” Hospital General in Santiago de Cuba, and the images were classified based on the specialist’s criteria for circular, elongated, and other cells. Examination of PBS by experienced individuals looking for features of SCD can be a sensitive test30.
Image preprocessing
Individual cells were extracted from full images of erythrocytesIDB. The Chan-Vese active contour model31 was employed for image segmentation. This model was chosen due to its exceptional performance in achieving a broader range of convergence and effectively handling topological changes.
The Chan-Vese method was employed without prior preprocessing steps. The application of this method resulted in the generation of a binarized image, after eliminating small objects that could potentially disrupt the subsequent classification process. We used a regularization parameter (\(\mu\)) value of 0.2 and a maximum iteration limit of 1000. However, it is noteworthy that the specified maximum iteration value was nominal, as convergence was achieved much earlier for the images under investigation.
MTurk task design for PBS image analysis of patients with SCD
The proposed approach’s design and experimental framework closely followed the guidelines proposed by Petrovic et al.24 regarding crowdsourcing methodologies. We defined a task on MTurk titled: “Sicklemia: Classify Red Blood Cells”, with a description that prompts MTurkers to determine the type of RBC: Circular, Elongated, or Other. This task was clearly visible to MTurkers, ensuring their comprehension. It was appropriately labeled as “image, classify, red blood cells” to facilitate search and filtering based on MTurker interests.
In order to ensure a comprehensive understanding of the tasks that needed to be performed by the MTurker, a set of detailed crafted instructions was meticulously prepared. These instructions were thoughtfully designed to not only provide clear guidance but also incorporate illustrative examples for each specific task type (see Fig. 1).

Instructions for cell classification.
Each MTurker was tasked with reviewing images in pairs (Fig. 2). For each image pair, MTurkers were required to indicate the type of cell (Circular, Elongated, or Other). They received a reward of 0.01$ for every classified image pair. It is important to note that not all registered MTurkers were eligible to perform these tasks, as two conditions were imposed:
-
Additional Requirement: Require that MTurkers be Masters to do their tasks. Master Workers on MTurk have a high success rate, holding the Masters Qualification for quality, experience, and a variety of tasks, determined through statistical analysis.
-
HIT Approval Rate (%) for all Requesters’ HITs greater than 90%.

Cell classification task.
These conditions were imposed as a means of selectively filtering external MTurkers, thereby incurring a nominal cost of \(0.01\$ \)$ per processed image. Consequently, the overall cost amounts to \(0.02\$ \)$ per classified image, accounting for the multiple layers of scrutiny and assessment involved in the classification process. The requirement for each image to undergo processing by a total of five distinct MTurkers ensured a robust and reliable outcome through a collective endeavor. This multi-worker approach not only aimed to promote the reliability and accuracy of the classification results but also sought to mitigate potential biases or errors that may arise from relying solely on the judgment of a single worker. By harnessing the collective efforts of multiple MTurkers, the aim was to leverage diverse perspectives and expertise, thereby enhancing the overall quality and credibility of the classification process. This inclusive and collaborative approach aligns with the principles of scientific rigor and objectivity, providing a comprehensive and dependable foundation for the research findings presented in this study.
MTurk parameters
The parameters of the task were configured in order to obtain the quality of the responses needed to ensure a valid analysis and minimize the economic spending:
-
Reward per assignment: \(0.01\$ \)$.
-
Number of assignments per task: 5.
-
Time allotted per assignment: 1 h.
-
Task expiration period: 3 days.
-
Auto-approval and payment of MTurkers: 7 days.
MTurkers requirements:
-
Require MTurkers to be Masters to perform tasks: Yes.
-
Additional qualifications for MTurkers: HIT Approval Rate (%) for all Requester’s HIT greater than 90%.
-
Task Visibility: Hidden (Only MTurkers who meet my qualification requirements can see and preview my tasks).
Measurements
Given a MTurker, their accuracy can be determined by comparing their responses to the Ground Truth (GT) for each image, where GT is the correct and known label or category of the image. To assess the classification performance, we generated the confusion matrix, which is a summary of the model’s predictions versus the actual GT values, and is typically a square table with rows and columns representing the actual classes or categories and the predicted classes, respectively. We also provided raw data and calculated the Accuracy Rate and F-measure32,33. We also utilized the Sickle Cell Disease Diagnosis Support score (SDS-score) as a measure proposed in Delgado-Font et al.21 to assess the classification of three classes of RBCs investigated in this study: circular, elongated cell, and other deformations. The SDS-score was designed to aid in the evaluation of SCD analysis. It was determined by calculating the ratio of the sum of true positives for all three classes to the number of sickle cells classified as other deformations and vice versa, divided by the sum of the aforementioned numerator and the sum of incorrect classifications associated with circular cells. The SDS-score indicates the usefulness of the method’s results in supporting the analysis of the studied disease.
Moreover, the classification task involves imbalanced classes due to the larger quantity of circular cells compared to elongated or deformed cells. To address this issue and evaluate the overall process, we employed two measures: Class Balance Accuracy (CBA)21,34 and Matthews Correlation Coefficient (MCC)21,35. These measures provide valuable insights into the performance and effectiveness of our approach.
Regarding Accuracy Rate, for each image there were responses from \(k=5\) MTurkers. If three or more responses coincided, there was a consensus and the response determined by the MTurkers was considered. The response configurations that yielded a valid response were: 5 (complete consensus), 4-1 (four out of the five MTurkers agreed on one class, while the remaining MTurker selected a different one, 3-1-1 (three out of the five MTurkers agreed on one category, while each of the remaining two MTurkers selected a different one from the remaining categories), and 3-2 (three out of the five MTurkers agreed on one class, while the remaining two MTurkers selected a different one). Otherwise, N/A (not answer) response was considered. The response configuration that did not yield a valid response was 2-2-1 (two out of the five MTurkers agreed on one class, another two MTurkers agreed on a different class, and the remaining MTurker selected yet another class). MTurkers were deemed correct if their response matched the ground truth classification.
Finally, in this study, we elucidated the methodology for computing the Accuracy Rate under the assumption of independence. Specifically, we considered the classification proficiency of a particular cell type among the MTurkers, denoting the average accuracy for this type as \(\alpha\). Subsequently, we estimated accuracy (X) through the following procedure:
where first term is the case 5 MTurkers classify correctly, second term 4 classify correctly and the other one mistakes, and last term 3 MTurkers classify correctly and 2 misclassify.
Results and discussion
The accuracies for each cell type and each MTurker are detailed in Table 1. The circular cell type demonstrated an accuracy of \(86.74\%\), while the elongated and other cell types exhibited an accuracy of \(67.58\%\) and \(61.20\%\) respectively. Notably, when the elongated and other classes were combined into a unified category, an overall accuracy of \(92.99\%\) was attained. These results highlighted the distinct accuracies associated with different cell types and underscored the enhanced performance achieved by consolidating specific categories.
The adoption of a consensus-based cell type selection method, wherein a consensus was reached when 3 or more MTurkers selected the same class, produced a improved accuracy as shown in Table 2. In 20 cases there was not consensus, so the responses were considered as N/A. Notably, this approach demonstrated an overall improvement in accuracy. The results highlighted the effectiveness of leveraging consensus among multiple MTurkers to enhance the accuracy of cell type classification.
Assuming independence among the classifications, the following levels of accuracy should be obtained using the individual accuracy of 5 MTurkers, see Table 3. The estimated outcomes exhibited superior performance compared to the observed results. This disparity challenges the assumption of independence, indicating a propensity for MTurkers to commit similar errors. These findings substantiated the inadequacy of assuming independence within the realm of MTurker behavior, underscoring the presence of correlated errors among MTurkers. The implications of these results highlighted the need for a deeper understanding of the underlying factors influencing MTurker judgments and the importance of considering inter-rater agreement in future studies.
In Fig. 3, we present a collection of images showcasing instances where the MTurkers exhibit errors. The classification process employed a voting-based system, where the first row pertains to circular cell types, the second row corresponds to elongated cells, and the last row represents other cell types. The visual analysis clearly indicates the presence of challenging cases that pose difficulties for accurate classification. These observations shed light on the intricacies involved in effectively categorizing certain cell types and emphasize the importance of addressing classification uncertainties in MTurker-based studies.

MTurk miss-classifications. The top row shows circular cells, the middle row shows elongated cells, and the bottom row shows other cell types. Each label shows the class that the MTurkers have classified them, the numbers in parenthesis show the votes: circular, elongated and other. These miss-classifications are indicative of the difficulty of accurately classifying cells.
Unlike computational methods, the results obtained by MTurkers provided additional information on the reliability of the decision made. This reliability was determined by the number of consensus in determining the cell’s class. We separately analyzed three cases: when all 5 MTurkers agreed (463 cases), when 4 MTurkers agreed (226 cases), and when 3 MTurkers agreed (135 cases). In Tables 4 and 5 we show the metrics we obtained in these cases and compared them with the state-of-art of automated methods for analyzing blood samples14,18,21,22,23. Elongated and other cells can be consolidated because the misclassification of the normal cells as the elongated or other cells will cause the alert to the medical specialist that the patient’s condition has worsened and that the therapy should be changed21. Then, it is up to the specialist to review the diagnosis and to decide whether the more drastic treatment should be prescribed. This type of error is not so serious because the treatment usually has no side effects. More dangerous scenario would be to classify deformed cells (elongated or other) as normal. In this case, the specialist could decide that the patient is not at risk of a vaso-occlusive crisis, and the necessary treatment would not be applied. To support the diagnosis in a good way, classifiers need to minimize the misclassification rate of elongated cells and cells with other deformations as normal cells, and the misclassification of normal cells as elongated and cells with other deformations. On the one hand, we can observe that if there was absolute consensus (55% of the cases) or if 4 out of 5 MTurkers agreed (26% of the cases), the probability of error was very low. On the other hand, we can observe that there were only 24 cases without a consensus and 135 cases where there was consensus among 3 MTurkers, meaning these cases should be reviewed by a specialist, out of a total of 848 (19% of the cases).
The objective of our research is not to replace automated procedures utilized for diagnostic assistance in the context of patients afflicted with SCD. Instead, our focus is on investigating the feasibility of employing HBC to tag large datasets, thereby facilitating the training of automated methods, especially in situations where expert assistance is not feasible. The results demonstrate that in cases where there is a strong consensus among the MTurkers, the outcomes are comparable to the state-of-the-art automated methods. As a result, our proposed approach proves to be effective in annotating large datasets. The more tagged training data that is available, the more accurately the model can learn to recognize patterns and generalize to unseen data.
In our investigation of individual MTurkers, a notable observation emerged: an increase in the number of classifications did not yield an improvement in accuracy. This finding is visually represented in Fig. 4. The results challenge the prevailing assumption that increased participation levels invariably lead to enhanced performance. These findings prompt a reevaluation of the role of quantity versus quality in the context of MTurker contributions, raising important considerations for optimizing crowd-based classification tasks.

Ratio of cells correctly classified regarding to the number of cells classified. We can observe that this calculation can be approximated through a linear regression. The classification ratio is maintained independently of the number of classified cells.
Conclusions
This research paper introduced an approach for the analysis of Red Blood Cell images in patients afflicted by Sickle Cell Disease. The proposed method leverages crowdsourcing Human-based Computation by engaging non-expert individuals through the Mechanical Turk microtask market, especially in situations where expert assistance is not feasible.
The findings of this study indicate that when a robust consensus is achieved among the Mechanical Turk micro-task market workers, the results exhibit that probability of error is very low, based on comparison with expert analysis. Consequently, our proposed approach could be employed for dataset annotation.
The present study incorporates the confusion matrices, along with the raw data, within the results to facilitate researchers in computing additional metrics. The dataset utilized in this research can be accessed at http://erythrocytesidb.uib.es/. In the interest of advancing scientific knowledge, it is advantageous for authors to share their raw data and image datasets used in their investigations.
The morphological analysis of PBS as a diagnostic tool for SCD are still used by some health systems and hospitals, even so we acknowledge recent developments in SCD point-of care diagnostics36. In this work we verified that non-expert users had good results in labeling tasks for circular, elongated and other, with the aim that as further work we can tag large PBS datasets from patients with SCD with non-expert users to feed automated methods. Moreover, we consider that our method could be transferable to new cells morphologies37 for other hemoglobinopathies that can be detected/analyzed/diagnosed by visual inspection methods. For this reason, as a further work we are interested in validating our proposal with other hemoglobinopathies.
Moreover, this research endeavors to establish the fundamental principles for the effective labeling of extensive datasets, particularly in scenarios where expert involvement is unfeasible. As part of future work, it foresees explorations aimed at investigating the potential integration of these findings with outcomes obtained through automated methodologies. Within the context of extensive dataset labeling, the incorporation of human-decided, reliable labels in conjunction with those obtained through automated methods holds notable significance. This dual-input approach has the potential to mitigate the risk of preserving errors and biases inherent in automated methods during the final labeling process. Consequently, this methodology could lead to a reduction in the transfer of such biases during the training of subsequent models, ultimately enhancing the quality of derived insights and predictive outcomes.
Data availability
erythrocytesIDB http://erythrocytesidb.uib.es/.
References
Ørting, S., Doyle, A., Hilten, A., Hirth, M., Inel, O., Madan, C.R., Mavridis, P., Spiers, H. & Cheplygina, V. A survey of crowdsourcing in medical image analysis. arXiv:1902.09159 (2019)
Ruiz, P., Morales-Álvarez, P., Coughlin, S., Molina, R. & Katsaggelos, A. K. Probabilistic fusion of crowds and experts for the search of gravitational waves. Knowl.-Based Syst. 261, 110183 (2023).
Quinn, A.J. & Bederson, B.B. Human computation: A survey and taxonomy of a growing field. in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 1403–1412 (2011)
Raddick, M. J. et al. Galaxy zoo: Exploring the motivations of citizen science volunteers. Astron. Educ. Rev. 9(1), 010103 (2010).
Kawrykow, A. et al. Phylo: A citizen science approach for improving multiple sequence alignment. PloS One 7(3), 31362 (2012).
Pharoah, P. D. Cell slider: Using crowd sourcing for the scoring of molecular pathology. Cancer Res. 74(19–Supplement), 303–303 (2014).
Schwamb, M. E. et al. Planet hunters: A transiting circumbinary planet in a quadruple star system. Astrophys. J. 768(2), 127 (2013).
Luengo-Oroz, M. A., Arranz, A. & Frean, J. Crowdsourcing malaria parasite quantification: An online game for analyzing images of infected thick blood smears. J. Med. Internet Res. 14(6), 167 (2012).
Mavandadi, S. et al. Distributed medical image analysis and diagnosis through crowd-sourced games: A malaria case study. PloS One 7(5), 37245 (2012).
Von Ahn, L., Blum, M., Hopper, N.J. & Langford, J. Captcha: Using hard ai problems for security. in Eurocrypt 2656, 294–311 (2003). Springer
McCoy, A. B. et al. Development and evaluation of a crowdsourcing methodology for knowledge base construction: Identifying relationships between clinical problems and medications. J. Am. Med. Informatics Assoc. 19(5), 713–718 (2012).
Nguyen, T. B. et al. Distributed human intelligence for colonic polyp classification in computer-aided detection for ct colonography. Radiology 262(3), 824–833 (2012).
Wang, S., Anugu, V., Nguyen, T., Rose, N., Burns, J., McKenna, M., Petrick, N. & Summers, R.M. Fusion of machine intelligence and human intelligence for colonic polyp detection in ct colonography. in 2011 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, pp. 160–164 (2011). IEEE
Petrović, N., Moyà-Alcover, G., Jaume-i-Capó, A. & González-Hidalgo, M. Sickle-cell disease diagnosis support selecting the most appropriate machine learning method: Towards a general and interpretable approach for cell morphology analysis from microscopy images. Comput. Biol. Med. 126, 104027 (2020).
World Health Organization: Sickle Cell Disease. https://www.afro.who.int/health-topics/sickle-cell-disease. Accessed: 31/10/2023
Abubakar, I., Tillmann, T. & Banerjee, A. Global, regional, and national age-sex specific all-cause and cause-specific mortality for 240 causes of death, 1990–2013: A systematic analysis for the global burden of disease study 2013. Lancet 385(9963), 117–171 (2015).
Naghavi, M. et al. Global, regional, and national age-sex specific mortality for 264 causes of death, 1980–2016: A systematic analysis for the global burden of disease study 2016. Lancet 390(10100), 1151–1210 (2017).
González-Hidalgo, M., Guerrero-Pena, F., Herold-García, S., Jaume-i-Capó, A. & Marrero-Fernández, P. D. Red blood cell cluster separation from digital images for use in sickle cell disease. IEEE J. Biomed. Health Informatics 19(4), 1514–1525 (2015).
Alzubaidi, L., Fadhel, M. A., Al-Shamma, O., Zhang, J. & Duan, Y. Deep learning models for classification of red blood cells in microscopy images to aid in sickle cell anemia diagnosis. Electronics 9(3), 427 (2020).
Bushra, S.N. & Shobana, G. Paediatric sickle cell detection using deep learning—A review. in 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), pp. 177–183 (2021). IEEE
Delgado-Font, W. et al. Diagnosis support of sickle cell anemia by classifying red blood cell shape in peripheral blood images. Med. Biol. Eng. Comput. 58, 1265–1284 (2020).
Asakura, T., Hirota, T., Nelson, A. T., Reilly, M. P. & Ohene-Frempong, K. Percentage of reversibly and irreversibly sickled cells are altered by the method of blood drawing and storage conditions. Blood Cells Molecules Diseases 22(3), 297–306 (1996).
Acharya, V. & Kumar, P. Identification and red blood cell automated counting from blood smear images using computer-aided system. Med. Biol. Eng. Comput. 56, 483–489 (2018).
Petrović, N., Moyà-Alcover, G., Varona, J. & Jaume-i-Capó, A. Crowdsourcing human-based computation for medical image analysis: A systematic literature review. Health Inform. J. 26(4), 2446–2469 (2020).
Jaume-i-Capó, A., Mena-Barco, C. & Moyà-Alcover, B. Analysis of blood cell morphology in touch-based devices using a captcha. in Proceedings of the XVII International Conference on Human Computer Interaction, pp. 1–2 (2016)
Mitry, D. et al. Crowdsourcing as a novel technique for retinal fundus photography classification: Analysis of images in the epic norfolk cohort on behalf of the ukbiobank eye and vision consortium. PloS One 8(8), 71154 (2013).
Boorboor, S., Nadeem, S., Park, J.H., Baker, K. & Kaufman, A. Crowdsourcing lung nodules detection and annotation. in: Medical Imaging 2018: Imaging Informatics for Healthcare, Research, and Applications, 10579, 342–348 (2018). SPIE
Gurari, D., Theriault, D., Sameki, M., Isenberg, B., Pham, T.A., Purwada, A., Solski, P., Walker, M., Zhang, C., Wong, J.Y., et al.: How to collect segmentations for biomedical images? A benchmark evaluating the performance of experts, crowdsourced non-experts, and algorithms. in 2015 IEEE Winter Conference on Applications of Computer Vision, pp. 1169–1176 (2015). IEEE
Amazon Mechanical Turk: Introduction to Amazon Mechanical Turk. https://docs.aws.amazon.com/AWSMechTurk/latest/AWSMechanicalTurkGettingStartedGuide/SvcIntro.html. Accessed: 31/10/2023
Bakulumpagi, D. et al. Peripheral blood smear as a diagnostic tool for sickle cell disease in a resource limited setting. Pediatrics 146(1-MeetingAbstract), 297–298 (2020).
Chan, T. F. & Vese, L. A. Active contours without edges. IEEE Trans. Image Process. 10(2), 266–277 (2001).
Stąpor, K. Evaluating and comparing classifiers: Review, some recommendations and limitations. in (Kurzynski, M., Wozniak, M. & Burduk, R., eds.) Proceedings of the 10th International Conference on Computer Recognition Systems CORES 2017, pp. 12–21. Springer, Cham (2018)
Labatut, V. & Cherifi, H.: Accuracy measures for the comparison of classifiers. in (Ali, A.-D., ed.) The 5th International Conference on Information Technology, pp. 15. Al-Zaytoonah University of Jordan, Amman, Jordan (2011). https://hal.archives-ouvertes.fr/hal-00611319
Mosley, L. A balanced approach to the multi-class imbalance problem. PhD thesis, Iowa State University, Industrial and Manufacturing Systems Engineering Department (2013)
Gorodkin, J. Comparing two k-category assignments by a k-category correlation coefficient. Comput. Biol. Chem. 28(5–6), 367–374. https://doi.org/10.1016/j.compbiolchem.2004.09.006 (2004).
Ilyas, S., Sher, M., Du, E. & Asghar, W. Smartphone-based sickle cell disease detection and monitoring for point-of-care settings. Biosensors Bioelectron. 165, 112417 (2020).
Lynch, E.C. Peripheral blood smear. Clinical Methods: The History, Physical, and Laboratory Examinations. 3rd Edn. (1990)
Funding
Project PID2019-104829RA-I00 “EXPLainable Artificial INtelligence systems for health and well-beING (EXPLAINING)” funded by MCIN/AEI/10.13039/501100011033.
Author information
Authors and Affiliations
Contributions
J.B., G.M., and A.J. wrote the main manuscript text. A.J. and N.P. wrote the state of the art. J.B. prepared the data and executed the experiments. All authors designed the experimentation and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rubio, J.M.B., Moyà-Alcover, G., Jaume-i-Capó, A. et al. Crowdsourced human-based computational approach for tagging peripheral blood smear sample images from Sickle Cell Disease patients using non-expert users. Sci Rep 14, 1201 (2024). https://doi.org/10.1038/s41598-024-51591-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-51591-w
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
