





« Prev Next »

Cells Can Replicate Their DNA Precisely
How is DNA replicated?
Replication occurs in three major steps: the opening of the double helix and separation of the DNA strands, the priming of the template strand, and the assembly of the new DNA segment. During separation, the two strands of the DNA double helix uncoil at a specific location called the origin. Several enzymes and proteins then work together to prepare, or prime, the strands for duplication. Finally, a special enzyme called DNA polymerase organizes the assembly of the new DNA strands. The following description of this three-stage process applies generally to all cells, but specific variations within the process may occur depending on organism and cell type.
What triggers replication?
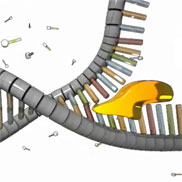
Figure 1: Helicase (yellow) unwinds the double helix.
The initiation of DNA replication occurs in two steps. First, a so-called
initiator protein unwinds a short stretch of the DNA double helix. Then, a
protein known as helicase attaches
to and breaks apart the hydrogen bonds between the bases on the DNA strands,
thereby pulling apart the two strands. As the helicase moves along the DNA
molecule, it continues breaking these hydrogen bonds and separating the two
polynucleotide chains (Figure 1).
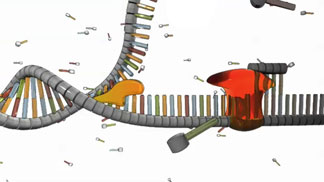
Figure 2: While helicase and the initiator protein (not shown) separate the two polynucleotide chains, primase (red) assembles a primer. This primer permits the next step in the replication process.
Meanwhile, as the helicase separates the strands, another enzyme called primase briefly attaches to each strand and assembles a foundation at which replication can begin. This foundation is a short stretch of nucleotides called a primer (Figure 2).
How are DNA strands replicated?
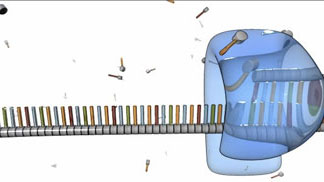
Figure 3: Beginning at the primer sequence, DNA polymerase (shown in blue) attaches to the original DNA strand and begins assembling a new, complementary strand.

Figure 4: Each nucleotide has an affinity for its partner. A pairs with T, and C pairs with G.
As DNA polymerase makes its way down the unwound DNA strand, it relies upon the pool of free-floating nucleotides surrounding the existing strand to build the new strand. The nucleotides that make up the new strand are paired with partner nucleotides in the template strand; because of their molecular structures, A and T nucleotides always pair with one another, and C and G nucleotides always pair with one another. This phenomenon is known as complementary base pairing (Figure 4), and it results in the production of two complementary strands of DNA.

Figure 5: A new DNA strand is synthesized. This strand contains nucleotides that are complementary to those in the template sequence.
Base pairing ensures that the sequence of nucleotides in the existing template strand is exactly matched to a complementary sequence in the new strand, also known as the anti-sequence of the template strand. Later, when the new strand is itself copied, its complementary strand will contain the same sequence as the original template strand. Thus, as a result of complementary base pairing, the replication process proceeds as a series of sequence and anti-sequence copying that preserves the coding of the original DNA.
How long does replication take?
In the prokaryotic bacterium E. coli, replication can occur at a rate of 1,000 nucleotides per second. In comparison, eukaryotic human DNA replicates at a rate of 50 nucleotides per second. In both cases, replication occurs so quickly because multiple polymerases can synthesize two new strands at the same time by using each unwound strand from the original DNA double helix as a template. One of these original strands is called the leading strand, whereas the other is called the lagging strand. The leading strand is synthesized continuously, as shown in Figure 5. In contrast, the lagging strand is synthesized in small, separate fragments that are eventually joined together to form a complete, newly copied strand.
Further Exploration
Key Questions
eBooks
This page appears in the following eBook















