
Abstract
Breast cancer is a disease with high heterogeneity. Many issues on tumorigenesis and progression are still elusive. It is critical to identify genes that play important roles in the progression of tumors, especially for tumors with poor prognosis such as basal-like breast cancer and tumors in very young women. To facilitate the identification of potential regulatory or driver genes, we present the Breast Cancer Integrative Platform (BCIP, http://www.omicsnet.org/bcancer/). BCIP maintains multi-omics data selected with strict quality control and processed with uniform normalization methods, including gene expression profiles from 9,005 tumor and 376 normal tissue samples, copy number variation information from 3,035 tumor samples, microRNA-target interactions, co-expressed genes, KEGG pathways, and mammary tissue-specific gene functional networks. This platform provides a user-friendly interface integrating comprehensive and flexible analysis tools on differential gene expression, copy number variation, and survival analysis. The prominent characteristic of BCIP is that users can perform analysis by customizing subgroups with single or combined clinical features, including subtypes, histological grades, pathologic stages, metastasis status, lymph node status, ER/PR/HER2 status, TP53 mutation status, menopause status, age, tumor size, therapy responses, and prognosis. BCIP will help to identify regulatory or driver genes and candidate biomarkers for further research in breast cancer.
Similar content being viewed by others


Introduction
Breast cancer is a frequently diagnosed carcinoma and is the leading cause of cancer death among females worldwide. An estimated 1,676,600 cases were diagnosed and 521,900 deaths occurred in 2012, accounting for 25% of the total cancer cases and 15% of all the cancer deaths among females1. Breast cancer is a heterogeneous disease with a high degree of diversity in morphology, histology, pathological features, and molecular alterations, such as gene mutations and abnormal expression2. Researches based on gene expression (GE) patterns have classified breast cancer into distinct subgroups corresponding to different prognostic outcomes and therapeutic responses3,4,5,6. A number of studies have focused on the recognition of biomarkers and characterization of gene function in particular breast cancer subgroups7,8,9,10.
Triple-negative breast cancer (TNBC) is a highly aggressive subtype of breast cancer and the vast majority is basal-like phenotype11. Due to its high genetic heterogeneity, TNBC does not possess a common genetic mutation and thus lacks effective targeted therapies12. However, several studies based on GE have identified several critical genes that may be potential druggable targets for the treatment of TNBC13,14,15. For example, MELK has been characterized as an oncogenic kinase essential for basal-like breast cancer (BBC) via a kinome-wide screening, integrative analysis with multiple GE datasets, and further in vitro and in vivo experiments14. BCL11A has also been reported to be a novel TNBC oncogene by in silico analysis of several microarray datasets and subsequent experimental validations15. These studies suggest that GE profiles are important resources for regulatory gene and biomarker identification in breast cancer. Differential expression analysis, copy number variation (CNV) analysis, survival analysis, and co-expression analysis on multiple credible and qualified datasets are effective approaches for recognizing novel regulatory genes and biomarkers.
In order to help researchers use gene expression profiles, some databases and tools have been developed16,17,18,19. However, integrative platforms combined with multi-omics data and customized analysis tools for breast cancer are still lacking. In this study, we developed BCIP, which provides differential expression analysis, copy number variation analysis, survival analysis, co-expression analysis, microRNA (miRNA) regulation analysis, and pathway analysis for query genes. To ensure the reliability of the analysis, we collected and obtained GE profile data on 9,381 samples from 29 datasets with strict quality control and uniform processing. We also incorporated CNV information on 3,035 samples, 324,219 miRNA-target interactions, 286 KEGG pathways, and data from tissue-specific gene functional networks of mammary gland and mammary epithelium. In order to facilitate researchers’ analysis of the specific subgroups they focused on, we developed a comprehensive and flexible interface that permits users to customize subgroups with single or combined clinical features of interest, including subtypes, grades, stages, metastasis status, lymph node status, prognosis, age, tumor size, ER/PR/HER2 status, TP53 mutation status, menopause status, and therapy response. BCIP will be a valuable tool for the identification of regulatory or driver genes in breast cancer.
Methods
Data collection and processing
We initially retrieved and collected data from NCBI Gene Expression Omnibus20 (GEO), European Genome-phenome Archive of EMBL European Bioinformatics Institute21 (EMBL-EBI), and The Cancer Genome Atlas22 (TCGA) with the following criteria: (1) gene microarray or high-throughput sequencing data of RNAs extracted from primary breast tumor or adjacent normal tissues; (2) the sample size of each dataset is no less than 50; (3) clinical information were provided together with the dataset, mainly including subtypes, histological grades, pathologic stages, ER/PR/HER2 status, and prognosis; (4) the dataset was available for download before Jan 1, 2016, which was the latest date we collected the datasets. Finally, we obtained a preliminary collection of 86 independent datasets. To assure adequate specimens in subgrouping, we assessed the sample number demand and removed the datasets with less than 100 samples. The rest 30 datasets include 27 datasets from GEO (measured by Affymetrix microarray), 2 datasets from TCGA (measured by Agilent microarray and Illumina HiSeq), and 1 dataset of the METABRIC from EBI (measured by Illumina HT-12 v3 microarray).
Then we performed quality control, normalization and duplicate removing on all the 30 datasets. Quality control was carried out by simpleaffy and affyPLM R packages on each of the 27 GEO datasets independently. The raw data of each dataset were then normalized, summarized, and log-transformed using robust multi-array average (RMA) function of affy R package. The probe-based expression was converted into GE profiles, and the gene containing multiple probes was represented by the probe with the largest interquartile range across the samples. For the METABRIC dataset, we deleted 12 samples since 8 samples were duplicated in the discovery and validation sets and 4 were represented twice in the validation set. We used the processed expression matrix data of METABRIC directly23. For the TCGA Agilent and RNA-Seq data, we removed 22 samples without matched clinical information and used level_3 log2 normalized data from TCGA directly.
Furthermore, the tumor purity of the samples profiled on Affymetrix platforms was detected through a robust method, ESTIMATE, which uses the ESTIMATE-based tumor purity score developed by Affymetrix data to evaluate tumor purity24. This method was not applied to predict the tumor purity of the samples profiled on Affymetrix Human Genome U133B Array because of the insufficiency of the gene signatures intersection. Depending on the results of tumor purity estimation (Supplementary Figure S1), we eliminated one dataset with the lowest mean tumor purity, in order to reduce noises caused by diverse tumor purity. Finally, GE profiles of a total of 26,339 genes from 9,381 samples of 29 datasets were available for transcriptome analysis.
Sample subgrouping features
We compiled a series of clinical features along with each sample for sample subgrouping. For samples with some clinical features that were not initially provided (mainly ER−/+/PR−/+/HER2−/+, TNBC, and PAM50 subtypes) in certain collected datasets, we defined these features using a computational method based on GE profiles. Expressions of ER, PR, and HER2 were respectively fitted by a Gaussian bimodal distribution model and the parameters were estimated via EM algorithm using Mclust function in mclust R package. The expression status for ER, PR, and HER2 were discriminated as positive (ER+, PR+, and HER2+) or negative (ER−, PR−, and HER2−). On the basis of the identification of ER, PR, and HER2 positive or negative expression status, we classified samples into TNBC or non-TNBC subtype6. Samples defined as ER−, PR− and HER2− status were identified as TNBC and otherwise non-TNBC. Molecular classification for PAM50 subtypes was provided in some datasets, and if not, we classified the patients into the five intrinsic breast cancer subtypes using the 50-gene subtype classifier, PAM504. The feature of the prognosis status was classified into good/poor prognosis using the median survival time as the delimitation.
Copy number variation
We obtained CNV data for 28,678 genes of 3,035 samples from METABRIC and TCGA. Both the DNA microarray platforms of the 2 datasets are Affymetrix Genome-Wide Human SNP Array 6.0. The numerical values of CNV were processed, summarized, and normalized relying on the relative intensity of probe hybridization on the arrays. Segmented data were converted to the gene level matrix using GISTIC 2.025, which were annotated for gene content based on hg19/GRCh37 for the TCGA data. For the METABRIC data, we generated a patient-by-gene CNV matrix through the processed segment data by matching the overlap of the segments with the gene regions whose annotations and coordinates were given by hg18/Ensembl 54. For more accurate and reliable analysis, we set the gain/loss threshold to 0.1 and −0.1, respectively. When the CNV value of a gene is greater than 0.1, the gene is defined as copy number gain. When the CNV value of a gene is smaller than −0.1, the gene is defined as copy number loss.
Statistical analysis
All the statistical analysis were performed using R programming platform. An unpaired t test was used for differential GE analysis in Transcriptome Analysis for 2 subgroups. One-way analysis of variance (ANOVA) was used for more than 2 subgroups if GE satisfied the assumption of a normal distribution, and if not, the non-parametric test (Kruskal–Wallis test) was used to assess statistical differences among these subgroups. The survfit function of survival R package was used for survival analysis. Kaplan-Meier curves and log-rank test were used to assess survival differences. In Transcriptome Survival Analysis, we classified patients into 2 groups according to an optimal GE cutoff value based on the Cutoff Finder application26. This program will traverse the GE values of all patients and the optimal cutoff value can minimizes the p value of survival differences. In CNV Survival Analysis, patients are separated into 2 groups according to their CNV status (gain/loss) of the query gene. Hazard ratio (HR) was calculated using Cox proportional hazards regression model. Co-expression analysis was performed using cox function of WGCNA R package. The correlation of GE was evaluated by Pearson correlation coefficient (PCC) as well as false discovery rate (FDR) adjusted p-value. The genes with absolute PCC ≥ 0.3 and adjusted p-value ≤ 0.05 were considered co-expressed in Co-expression Analysis.
Database schema and implementation
BCIP was implemented based on the Apache HTTP server 2.2 with MySQL 5.1.73 at the back end and the PHP 5.5.31, HTML, and JavaScript at the front end. All the computing programs were completed with R 3.2.3 and dependent packages.
Results
Overview of BCIP
BCIP is a gene-centered platform that provides (1) differential expression analysis, survival analysis, and co-expression analysis based on transcriptome data; (2) differential analysis and survival analysis based on CNVs; (3) miRNA regulation analysis on miRNA-target interactions; (4) KEGG pathway analysis; and (5) network analysis on mammary tissue-specific gene function networks (Fig. 1a). BCIP provides a user-friendly interface consisting of four panels: Analysis Type, Sample Subgrouping, Dataset, and Result (Fig. 1b). A gene symbol can be input in the text field where we provide a fuzzy matching function. Users can then select any of 5 analytical categories in the Analysis Type panel, including Transcriptome Analysis, Copy Number Variation Analysis, MicroRNA-target Interaction Analysis, Pathway Analysis, and Gene Functional Network Analysis. After selecting analytical category, users can customize subgroups with single or combined clinical features of interest in the Sample Subgrouping panel. BCIP provides a total of 15 clinical features, including TNBC and non-TNBC subtypes, PAM50 subtypes, histological grades, pathologic stages, metastasis status, lymph node status, ER/PR/HER2 status, TP53 mutation status, menopause status, age, tumor size, therapy responses, and prognosis. The Dataset panel provides all of the available datasets for the selected options in the Analysis Type and Sample Subgrouping. Finally, the Result panel returns corresponding graphical and tabular presentation and analysis results after choosing from the above options.

(a) Data sources and applications of BCIP. The same color system was used to characterize the correspondence, while the inner light-colored donut chart represents the data sources and the outer deep-colored donut chart indicates the corresponding applications (analysis types). (b) Overview of the data portal of BCIP. The panel of 4 modules includes: Analysis Type, Sample Subgrouping, Dataset, and Result.
Transcriptome Analysis
We collected GE data of breast cancer tissue samples from publicly available databases of GEO, EMBL-EBI and TCGA and obtained 86 datasets. After excluding the datasets with insufficient samples (less than 100) or low tumor purity, we finally retained 29 datasets with the GE profiles of 9,381 samples (Fig. 2a and Supplementary Table S1). The GE profiles are used for differential expression analysis, survival analysis, and co-expression analysis.
-
Differential expression analysis. There are 2 options for differential expression analysis in Analysis Type: cancer vs normal, cancer vs cancer. The cancer vs normal option is designed to show the expression difference between the tumor and normal tissues. The cancer vs cancer option supports differential analysis in tumor samples among user-defined subgroups. Users are allowed to customize specific subgroups with single or combined clinical features of interest. Differential expression analysis results will be illustrated with a box plot in the Result panel. Dataset and chart information are also presented below the graph. For example, MELK, a recently reported oncogenic kinase in BBC14, has the highest expression level in basal-like subtype in the METABRIC dataset (Fig. 2b, left panel). When both TNBC and non-TNBC in the Triple-negative breast cancer group and pre-menopause/post-menopause in the Menopause status group are selected, BCIP will divide samples into 4 subgroups according to the combination of 2 groups (Fig. 2b, right panel).
-
Survival analysis. Survival analysis is provided to investigate the association of gene with clinical prognosis. BCIP offers 5 survival types, including overall survival (OS), disease-specific survival (DS), disease-free survival (DFS), recurrence-free survival (RFS), and distant metastasis-free survival (DMFS). Users can perform survival analysis in the specific subgroup customized with single or combined clinical features of interest. Patients in the specific subgroup are divided into 2 groups according to an optimal cutoff of the GE levels. The optimal cutoff is determined by the Cutoff Finder that maximizes the survival differences between 2 groups26. Notably, the cutoff value can be flexibly moved through a slider bar. Kaplan-Meier survival curves will be redrawn dynamically with the change of the cutoff value, together with the p-value and HR. Figure 2c and d show the overall survival analysis results of MELK in all patients of the GSE7390 dataset and in the samples younger than 50 years old of the METABRIC dataset, respectively.
-
Co-expression analysis. Co-expression analysis is widely used to provide clues for potential associations among genes, proteins, and other biomolecules in various carcinomas27,28,29. Given a gene, BCIP displays the top 20 co-expression genes in the form of a circle dot where positive and negative correlations are represented by red and green, respectively (Fig. 2e). All of the co-expression genes with absolute PCC ≥ 0.3 and adjusted p-value ≤ 0.05 are presented in descending order of PCCs in the table below the graph. Scatter plots of GE levels of the co-expressed genes and the query gene are provided when clicking on the dots or the last column of the table. Notably, BCIP permits users to investigate co-expression relationship in any specified subgroup that users customized with the clinical features of interest.

(a) Flow chart of the transcriptome data processing procedures. (b) Box plots showing differential gene expression of MELK in breast cancer PAM50 subtypes (left) and other subgroups (right): TNBC AND premenopause, TNBC AND postmenopause, non-TNBC AND premenopause, and non-TNBC AND postmenopause. The tables display detailed information of the dataset and each subgroup of the chart. (c,d) The low (blue curve) and high (red curve) levels of MELK expression groups are correlated with the overall survival times in all patients of the GSE7390 dataset (p-value = 0.00047, HR = 3.067622) or in the patients younger than 50 years old of the METABRIC dataset (p-value = 8.524475e-08, HR = 2.350915). (e) The circle dots show the top 20 genes co-expressed with MELK in basal-like subtype patients of the METABRIC dataset. Positive and negative correlation is respectively distinguished by red and green circles. The table lists co-expressed genes with PCC ≥ 0.3 and adjusted p-value ≤ 0.05. Scatter plot showing the expression status of MELK and CEP55.
Copy Number Variation Analysis
CNVs exist pervasively in human genomes and contribute to the diversity and susceptibility of numerous diseases30. It may be an important factor in cancer occurrence and development. A series of studies and attempts have been carried out to explore the impact of CNV on breast cancer31,32,33. We collected and incorporated CNVs information of 3,035 tumor samples from METABRIC and TCGA. BCIP provides differential analysis and survival analyses for CNV data.
-
Differential analysis between copy number gain/loss. The proportions of samples with CNV (copy number gain and loss) of the query gene in any user-defined subgroups are respectively displayed in a histogram. A table matching the histogram provides details of the sample numbers and the proportions of copy number gain/loss in the corresponding subgroups. For example, MELK has a much higher (more than 2 times) proportion of samples with copy number gain in basal-like subtype than other PAM50 subtypes (Fig. 3a), which provides a clue to explain its high expression in BBC.
Figure 3: Visualization of copy number variations (CNVs) based analyses reveals CNV status and survival correlation. 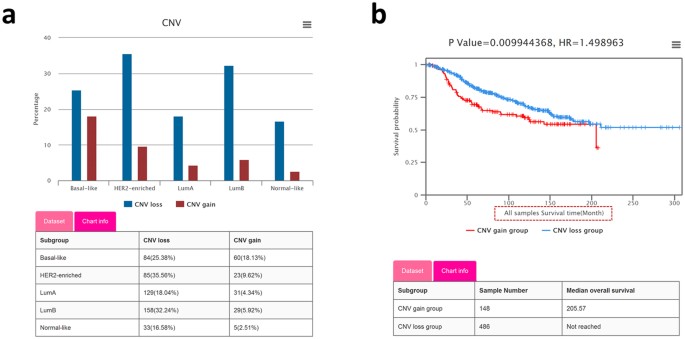
(a) Histogram depicting the percentage of samples with MELK copy number losses/gains in each PAM50 subtype of the METABRIC dataset. (b) Kaplan-Meier plot showing the disease-specific survival rate comparison between patients with MELK copy number losses (blue curve) and copy number gains (red curve), and the tables showing the sample numbers and median survival times of the 2 groups.
-
Survival analysis with CNV data. Survival analysis based on gene CNVs will shed light on the correlation between prognostic outcomes and CNV status. BCIP provides 5 survival types (OS, DS, DFS, RFS, and DMFS), permitting users to perform analysis in specific subgroups customized with single or combined clinical features of interest. Samples are separated into 2 groups according to their CNV status (gain/loss) of the query gene. The Kaplan-Meier plot shows that the samples with MELK copy number gain have shorter disease-specific survival times than those with copy number loss in the METABRIC dataset (Fig. 3b).

MicroRNA-target Interaction Analysis
miRNAs are small non-coding RNAs that can regulate protein-coding messenger RNAs (mRNAs) at the post-transcriptional level34. The pivotal role of miRNAs is known as a modulator participating in various biological processes. Numerous studies suggest that dysregulation of miRNAs may contribute to the initiation and progression of cancers35, and miRNAs can be regarded as diagnostic signatures or therapeutic biomarkers in breast cancer36,37. To facilitate researchers’ investigations into potential regulation mechanisms of query genes, BCIP provides MicroRNA-target Interaction Analysis, which illustrates miRNAs targeting the query gene. There is a total of 324,219 miRNA-target interactions between 2,619 miRNAs and 14,884 target genes from miRTarBase38 that are maintained in BCIP. All of these interactions are experimentally validated.
-
miRNA-target interactions. The results for miRNA-target interactions analysis are presented as a table and list the mature miRNAs that target the input gene and the corresponding experiment types (Fig. 4). Experiment types of reporter assay, Western blot, real-time quantitative PCR (qPCR) are regarded as strong evidence, while microarray, next-generation sequencing (NGS), and pulsed stable isotope labeling by amino acids in cell culture (pSILAC) are regarded as less strong evidence for the interactions between miRNAs and genes38. In addition, external links to the miRBase database and PubMed have been embedded in the table for the added convenience in retrieving corresponding information.
Figure 4: The miRNA-target interactions table lists the experimentally validated mature miRNAs that target MELK. 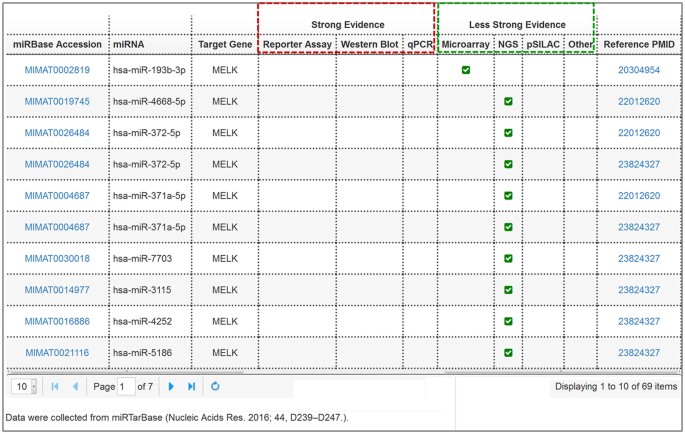
The red box and green box respectively represent the strong experiment evidence (reporter assay, Western blot, and qPCR) and less strong evidences (microarray and next-generation sequencing experiments).

Pathway Analysis
It is known that some biological pathways involved in metabolism, apoptosis, and signal transduction play critical roles in cell proliferation and differentiation during tumorigenesis and cancer development. Understanding which pathways a gene participates in will be of great help for researchers in characterizing its functions in breast cancer. We have collected 22,455 linked entries between 6,755 genes and 286 human pathways from the KEGG database39.
-
KEGG pathways. A table consisting of pathway classes, pathway IDs, and pathway names are presented in the KEGG pathways analysis results to depict pathway information (Fig. 5). The thumbnail images in the last column can pop-up pathway maps when clicked. The pathway maps contain molecular interaction and reaction networks in which the query gene was involved. The query gene is highlighted in red.
Figure 5: KEGG pathway analysis results and pathway map visualization of BRCA1. 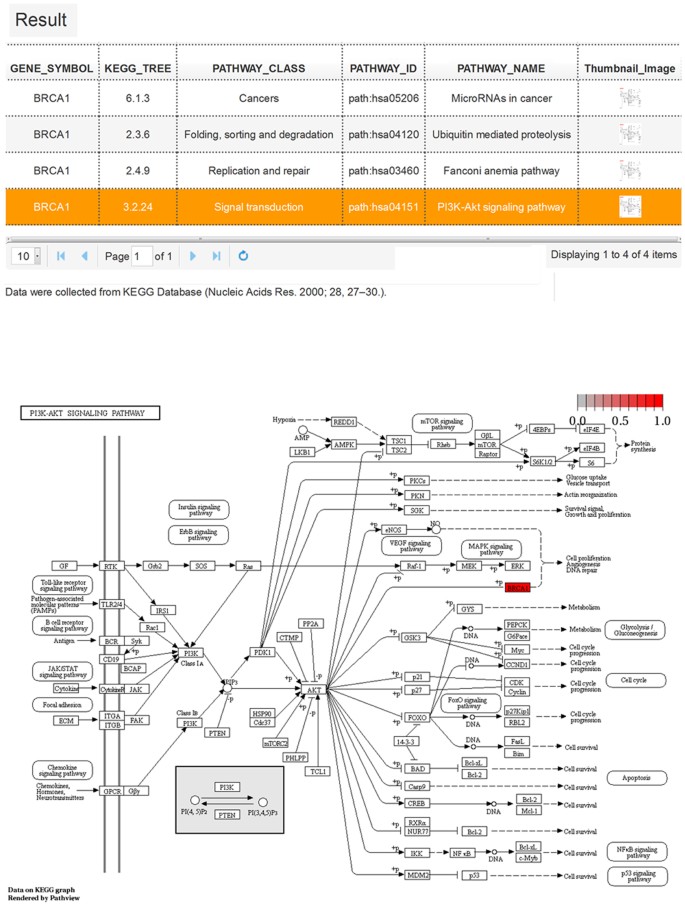
The table lists all of the pathways involving gene BRCA1, which consists of the KEGG tree, pathway class, pathway ID, and pathway name. The schematic representation showing the PI3K-Akt signaling pathway map39, which depicts the molecular interaction and reaction network. Gene BRCA1 is highlighted in red.

Gene Functional Network Analyses
Each biomolecule is located in complex biological networks and exerts its functions together with other related molecules. Notably, gene expression as well as gene-gene functional relationships in the complex biological regulation network may be tissue-specific18,40. Identifying a gene’s functional partner in specified tissue can facilitate researchers to infer gene functions and molecular mechanisms. Here we provide mammary tissue-specific gene functional networks analysis. Data on both mammary epithelium and mammary gland gene functional networks were collected and processed from the GIANT webserver40.
-
Mammary epithelium and gland networks. Users are allowed to search gene functional relationships in mammary epithelium and gland gene functional networks. The dynamic network shows a subset of the entire network, and the nodes and edges are controlled by the slider bars of the maximum number of genes and the minimum relationship confidence (Fig. 6). A table below the network lists the details of the top 50 functional related genes in descending order of the average edge score, which reflects the relationship strength between the 2 genes. Clicking on any gene leads to a new table showing the corresponding detail about that gene.
Figure 6: Visualization of the mammary epithelium-specific gene functional network. 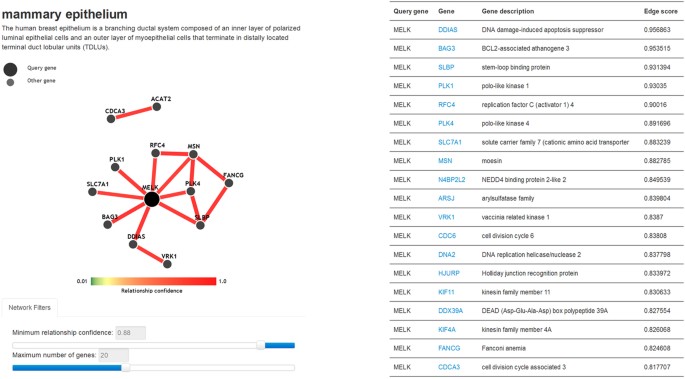
The dynamic network displays the front portion of the entire network of MELK with 50 other genes. The number of genes in the network is controlled by the slider bar of the minimum relationship confidence and the maximum number of genes. The table lists the top 50 related genes in accordance with the priority of average edge score.

Case Study and Discussion
For a query gene, BCIP helps to demonstrate its potential as a biomarker or regulatory gene in breast cancer. Take MELK, a promising therapeutic target of BBC reported recently, as an example to demonstrate the utility and advantage of BCIP14. Differential expression analysis shows that MELK has a much higher expression level in tumors than adjacent normal tissues across all of the available datasets (Supplementary Figure S2) and has the highest expression level in basal-like subtype among PAM50 subtypes across all of the datasets (Supplementary Figure S3). When subgroups are customized with tumor grades, we found that higher MELK expression level was significantly associated with higher histological grades among all of the datasets (Supplementary Figure S4). Survival analysis shows that overexpression of MELK is strongly correlated with poor prognosis (Supplementary Figure S5–9). These in silico results indicate that MELK might play roles in BBC.
To provide clues of the possible molecular mechanism of MELK in BBC, we further analyzed the co-expression genes and regulatory miRNAs of MELK. In basal-like subtype of the METABRIC dataset, MELK was significantly co-expressed with 78 genes with PCC > 0.6, including CDCA5, TPX2, and CEP55 (Fig. 2e). Several studies have demonstrated that TPX2 and CEP55 are critical molecules for breast cancer migration, invasion, cell proliferation, and metastasis41,42,43. CDCA5 has been reported to play a crucial role in human lung carcinogenesis and has the potential of being a therapeutic target for oral squamous cell carcinoma44,45. These results may be valuable clues for the investigation of potential function and molecular mechanism of MELK in breast cancer. Additionally, we found miRNAs targeting MELK, including hsa-miR-193b-3p and hsa-miR-372-5p (Fig. 4). Previous studies have shown that miR-193b represses cell proliferation and regulates cyclin D1 in melanoma46, and miR-372 suppresses tumor proliferation, invasion, and migration in various tumor types47,48. This result indicates that MELK might be regulated by miR-193b-3p and miR-372-5p in breast cancer.
We have developed BCIP, a user-friendly, open-access, integrative analysis platform that integrates almost 10,000 tumor and normal tissue samples of breast cancer. It will facilitate the identification of potential biomarkers and regulatory genes in breast cancer. Compared with other bioinformatics resources and analysis tools, BCIP has 3 unique characteristics: (i) BCIP incorporates multiple analysis types, including differential expression analysis, copy number variation and survival analysis, gene co-expression analysis, miRNA regulation analysis, KEGG pathways presentation, and mammary tissue-specific gene functional network analysis. All of these analysis tools help to sketch an overview of a gene in breast cancer. (ii) It provides dozens of datasets that are screened from publicly available databases, selected with strict quality control and processed with uniform normalization methods. Users can observe the consistency of the analysis results across multiple datasets, which will be helpful to evaluate the robustness of analysis results. (iii) BCIP permits users to perform analysis in specific breast cancer subgroups that are customized with single or combined clinical features of interest, including molecular subtypes, therapy response, and various clinical features.
Lots of studies have been done to identify biomarkers and to uncover molecular mechanisms of tumorigenesis, cell invasion, and metastasis in breast cancer. However, many tumors with high invasion and poor outcomes, such as TNBC or basal-like tumors, still lack well-defined molecular biomarkers and therapy targets due to the high heterogeneity. BCIP serves as a convenient and efficient platform to identify biomarkers, characterize potential functions and mechanisms of genes in breast cancer. Researchers can find clues for subsequent experiments and clinical analysis. In our future work, we will continue incorporating newly available, credible data into BCIP and provide reliable supports for researchers of breast cancer.
Additional Information
How to cite this article: Wu, J. et al. BCIP: a gene-centered platform for identifying potential regulatory genes in breast cancer. Sci. Rep. 7, 45235; doi: 10.1038/srep45235 (2017).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Change history
22 December 2017
A correction has been published and is appended to both the HTML and PDF versions of this paper. The error has been fixed in the paper.
References
Torre, L. A. et al. Global cancer statistics, 2012. CA. Cancer J. Clin. 65, 87–108 (2015).
Polyak, K. Heterogeneity in breast cancer. J. Clin. Invest. 121, 3786–3788 (2011).
Sørlie, T. et al. Gene expression patterns of breast carcinomas distinguish tumor subclasses with clinical implications. Proc. Natl. Acad. Sci. 98, 10869–10874 (2001).
Parker, J. S. et al. Supervised Risk Predictor of Breast Cancer Based on Intrinsic Subtypes. J. Clin. Oncol. 27, 1160–1167 (2009).
Reis-Filho, J. S. & Pusztai, L. Gene expression profiling in breast cancer: classification, prognostication, and prediction. The Lancet 378, 1812–1823 (2011).
Lehmann, B. D. et al. Identification of human triple-negative breast cancer subtypes and preclinical models for selection of targeted therapies. J. Clin. Invest. 121, 2750–2767 (2011).
Rivenbark, A. G., O’Connor, S. M. & Coleman, W. B. Molecular and Cellular Heterogeneity in Breast Cancer: Challenges for Personalized Medicine. Am. J. Pathol. 183, 1113–1124 (2013).
Jin, Y. et al. FOXC1 is a critical mediator of EGFR function in human basal-like breast cancer. Ann. Surg. Oncol. 21, 758–766 (2014).
Cheng, G. et al. Higher levels of TIMP-1 expression are associated with a poor prognosis in triple-negative breast cancer. Mol. Cancer 15, 30 (2016).
Bastien, R. R. L. et al. PAM50 breast cancer subtyping by RT-qPCR and concordance with standard clinical molecular markers. BMC Med. Genomics 5, 44 (2012).
Perou, C. M. Molecular Stratification of Triple-Negative Breast Cancers. The Oncologist 16, 61–70 (2011).
Abramson, V. G., Lehmann, B. D., Ballinger, T. J. & Pietenpol, J. A. Subtyping of triple-negative breast cancer: Implications for therapy. Cancer 121, 8–16 (2015).
Wang, Y. et al. CDK7-Dependent Transcriptional Addiction in Triple-Negative Breast Cancer. Cell 163, 174–186 (2015).
Wang, Y. et al. MELK is an oncogenic kinase essential for mitotic progression in basal-like breast cancer cells. eLife 3, e01763 (2014).
Khaled, W. T. et al. BCL11A is a triple-negative breast cancer gene with critical functions in stem and progenitor cells. Nat. Commun. 6, 5987 (2015).
Kapushesky, M. et al. Gene Expression Atlas at the European Bioinformatics Institute. Nucleic Acids Res. 38, D690–D698 (2010).
Rhodes, D. R. et al. ONCOMINE: A Cancer Microarray Database and Integrated Data-Mining Platform. Neoplasia N. Y. N 6, 1–6 (2004).
Liu, X., Yu, X., Zack, D. J., Zhu, H. & Qian, J. TiGER: A database for tissue-specific gene expression and regulation. BMC Bioinformatics 9, 271 (2008).
Zilliox, M. J. & Irizarry, R. A. A Gene Expression Barcode for Microarray Data. Nat. Methods 4, 911–913 (2007).
Barrett, T. et al. NCBI GEO: archive for functional genomics data sets—update. Nucleic Acids Res. 41, D991–D995 (2013).
Lappalainen, I. et al. The European Genome-phenome Archive of human data consented for biomedical research. Nat. Genet. 47, 692–695 (2015).
Tomczak, K., Czerwińska, P. & Wiznerowicz, M. The Cancer Genome Atlas (TCGA): an immeasurable source of knowledge. Contemp. Oncol. 19, A68–A77 (2015).
Curtis, C. et al. The genomic and transcriptomic architecture of 2,000 breast tumours reveals novel subgroups. Nature 486, 346–352 (2012).
Yoshihara, K. et al. Inferring tumour purity and stromal and immune cell admixture from expression data. Nat. Commun. 4, 2612 (2013).
Mermel, C. H. et al. GISTIC2.0 facilitates sensitive and confident localization of the targets of focal somatic copy-number alteration in human cancers. Genome Biol. 12, R41 (2011).
Budczies, J. et al. Cutoff Finder: A Comprehensive and Straightforward Web Application Enabling Rapid Biomarker Cutoff Optimization. PLOS ONE 7, e51862 (2012).
Ingthorsson, S. et al. HER2 induced EMT and tumorigenicity in breast epithelial progenitor cells is inhibited by coexpression of EGFR. Oncogene 35, 4244–4255 (2016).
Zhang, X.-H. et al. Coexpression of VEGF-C and COX-2 and its association with lymphangiogenesis in human breast cancer. BMC Cancer 8, 4 (2008).
Ma, L. & Jiang, T. Clinical implications of Ezrin and CD44 co-expression in breast cancer. Oncol. Rep. 30, 1899–1905 (2013).
Ueno, T. et al. Genome-wide copy number analysis in primary breast cancer. Expert Opin. Ther. Targets 16, S31–S35 (2012).
Krepischi, A. C. et al. Germline DNA copy number variation in familial and early-onset breast cancer. Breast Cancer Res. 14, R24 (2012).
Masson, A. L. et al. Expanding the genetic basis of copy number variation in familial breast cancer. Hered. Cancer Clin. Pract. 12, 15 (2014).
Suehiro, Y. et al. Germline copy number variations associated with breast cancer susceptibility in a Japanese population. Tumour Biol. 34, 947–952 (2013).
Ambros, V. The functions of animal microRNAs. Nature 431, 350–355 (2004).
van Schooneveld, E. et al. Dysregulation of microRNAs in breast cancer and their potential role as prognostic and predictive biomarkers in patient management. Breast Cancer Res. 17, 21 (2015).
Tashkandi, H., Shah, N., Patel, Y. & Chen, H. Identification of new miRNA biomarkers associated with HER2-positive breast cancers. Oncoscience 2, 924–929 (2015).
Bertoli, G., Cava, C. & Castiglioni, I. MicroRNAs: New Biomarkers for Diagnosis, Prognosis, Therapy Prediction and Therapeutic Tools for Breast Cancer. Theranostics 5, 1122–1143 (2015).
Chou, C.-H. et al. miRTarBase 2016: updates to the experimentally validated miRNA-target interactions database. Nucleic Acids Res. 44, D239–D247 (2016).
Kanehisa, M. & Goto, S. KEGG: Kyoto Encyclopedia of Genes and Genomes. Nucleic Acids Res. 28, 27–30 (2000).
Greene, C. S. et al. Understanding multicellular function and disease with human tissue-specific networks. Nat. Genet. 47, 569–576 (2015).
Yang, Y. et al. TPX2 promotes migration and invasion of human breast cancer cells. Asian Pac. J. Trop. Med. 8, 1064–1070 (2015).
Wang, Y., Jin, T., Dai, X. & Xu, J. Lentivirus-mediated knockdown of CEP55 suppresses cell proliferation of breast cancer cells. Biosci. Trends 10, 67–73 (2016).
Inoda, S. et al. Cep55/c10orf3, a tumor antigen derived from a centrosome residing protein in breast carcinoma. J. Immunother. 32, 474–485 (2009).
Nguyen, M.-H. et al. Phosphorylation and activation of cell division cycle associated 5 by mitogen-activated protein kinase play a crucial role in human lung carcinogenesis. Cancer Res. 70, 5337–5347 (2010).
Tokuzen, N., Nakashiro, K., Tanaka, H., Iwamoto, K. & Hamakawa, H. Therapeutic potential of targeting cell division cycle associated 5 for oral squamous cell carcinoma. Oncotarget 7, 2343–2353 (2015).
Chen, J. et al. MicroRNA-193b Represses Cell Proliferation and Regulates Cyclin D1 in Melanoma. Am. J. Pathol. 176, 2520–2529 (2010).
Huang, X., Huang, M., Kong, L. & Li, Y. miR-372 suppresses tumour proliferation and invasion by targeting IGF2BP1 in renal cell carcinoma. Cell Prolif. 48, 593–599 (2015).
Wu, G. et al. Mir-372 down-regulates the oncogene ATAD2 to influence hepatocellular carcinoma proliferation and metastasis. BMC Cancer 14, 107 (2014).
Acknowledgements
This work was supported by a grant from China National High Technology Research and Development Program 2014AA020604 (X. Ying). The authors gratefully acknowledge the technical assistance for platform construction from Mingming Su, Honglei Li, Jiemin Zou, and Xinlei Zhang. This study makes use of data generated by Molecular Taxonomy of Breast Cancer International Consortium, the authors greatly thank to the METABRIC group for the approval of the data usage. The authors gratefully acknowledge the copyright permission of KEGG for pathway map image used in our article.
Author information
Authors and Affiliations
Contributions
J.W. and S.H. carried out the majority of the data analysis and platform construction, participated in the platform and web page design, and drafted the manuscript. Y.C. participated in providing technical assistance to platform construction. Z.L. and J.Z. provided guidance for data processing procedures, and participated in part of data analysis. H.Y. and Q.S. contributed to the data collection and arrangement from publicly available databases. N.S. provided guidance to the study. X.Y. conceived the study and platform construction, contributed to the web page design, and revised the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Wu, J., Hu, S., Chen, Y. et al. BCIP: a gene-centered platform for identifying potential regulatory genes in breast cancer. Sci Rep 7, 45235 (2017). https://doi.org/10.1038/srep45235
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep45235
This article is cited by
-
Comment on “Prognostic and Clinical Significance of Human Leukocyte Antigen Class I Expression in Breast Cancer: A Meta‑Analysis”
Molecular Diagnosis & Therapy (2024)
-
Targeting nucleotide metabolism enhances the efficacy of anthracyclines and anti-metabolites in triple-negative breast cancer
npj Breast Cancer (2021)
-
Improving existing analysis pipeline to identify and analyze cancer driver genes using multi-omics data
Scientific Reports (2020)
-
Effective breast cancer combination therapy targeting BACH1 and mitochondrial metabolism
Nature (2019)
-
Loss of PICH promotes chromosome instability and cell death in triple-negative breast cancer
Cell Death & Disease (2019)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
