
Abstract
The large-scale structural ingredients of the brain and neural connectomes have been identified in recent years. These are, similar to the features found in many other real networks: the arrangement of brain regions into modules and the presence of highly connected regions (hubs) forming rich-clubs. Here, we examine how modules and hubs shape the collective dynamics on networks and we find that both ingredients lead to the emergence of complex dynamics. Comparing the connectomes of C. elegans, cats, macaques and humans to surrogate networks in which either modules or hubs are destroyed, we find that functional complexity always decreases in the perturbed networks. A comparison between simulated and empirically obtained resting-state functional connectivity indicates that the human brain, at rest, lies in a dynamical state that reflects the largest complexity its anatomical connectome can host. Last, we generalise the topology of neural connectomes into a new hierarchical network model that successfully combines modular organisation with rich-club forming hubs. This is achieved by centralising the cross-modular connections through a preferential attachment rule. Our network model hosts more complex dynamics than other hierarchical models widely used as benchmarks.
Similar content being viewed by others
Introduction
The study of interconnected natural systems as complex networks has uncovered common principles of organisation across scientific domains. Two pervasive features are (i) the grouping of the nodes into modules and (ii) the presence of highly connected nodes or hubs. It was soon recognised that these two features are signatures of hierarchical organisation but attempts to incorporate both into realistic network models have been of limited success1. Currently, the most popular hierarchical models recursively divide modules into smaller modules2. These networks, however, lack of hubs. Investigation of the brain’s connectivity has shed light on how nature efficiently combines the two features. Real connectomes are modular with the cross-modular connections centralised through highly connected brain regions which form a rich-club3,4,5.
The nervous system acquires information about the environment through different channels, known as sensory modalities. Information from each channel is independently processed by specialised neural compartments. An adequate and efficient integration of the information of those different channels is necessary for survival6,7. In a series of numerical experiments, Tononi and Sporns attempted to identify the right topologies that help optimally balance the coexistence of both segregated subsystems and an efficient integration of their information8. Starting from an ensemble of random graphs, an evolutionary algorithm would select those networks with the largest complexity. In subsequent iterations the winners would be mutated – slightly rewired – to produce another population to start over. The underlying assumption was that an increase of the neural complexity defined by the authors would lead to networks with balanced capacity to integrate and segregate information9. This procedure gave rise to networks with interconnected communities capturing the relevance of modules for the segregation of information. However, the optimised networks lacked of hubs and rich-clubs. Dynamical models on modular networks have shown that there is a balanced rate in the number of inter- to intra-modular links that optimises the complexity of the network dynamics10,11. This phenomenon has also been observed in contagion spreading, where the contagion threshold depends on the node’s degree12. Too few links between the communities leads to clustered (segregated) dynamics but no efficient interaction between them. On the contrary, too many connections between communities easily leads to a globally synchronised network meaning there is integration but no dynamical segregation. A balance is achieved in between. However, it can be argued that in modular networks integration is not efficient because it happens via global synchrony, which is an undesirable state of neural networks.
Despite these and other past efforts, the relation between a network’s complexity and its capacity to segregate and integrate information is yet unresolved and confusing. In particular, their causal relation requires clarification. While it seems plausible to assume that the needs of neural systems to integrate and segregate information may have led to the development of complex topological features, e.g., modules and rich-clubs, the opposite is not necessarily true. A network optimised for high complexity does not necessarily end developing modules and hubs, nor being good for integrating and segregating information. The aim of the present paper is to test and corroborate this causal relation only in one direction, namely, that the hierarchical centralisation of cross-modular connections through rich-clubs leads to enhanced functional complexity. For that purpose we consider both real neural connectomes and synthetic network models. We study the evolution of their functional complexity as the networks undergo a transition towards global synchrony by gradually increasing the weights of the links. We find that functional complexity emerges for intermediate values of the tuning parameter; when the nodes are neither independent from each other nor globally synchronised.
By comparing the real networks to randomised versions in which either the presence of hubs or the modular structure are destroyed, we find that both topological features are crucial ingredients for the networks to achieve high functional complexity. In the randomised networks complexity is always reduced. To clarify the precise impact of rich-clubs we have also carried out a lesion study. Selective removal of the links between the hubs leads to a reduction of functional complexity in all cases. The reduction is significant compared to random lesions. In the case of the human dataset we also observe that the dynamics of the brain, at rest, reflects a state with the largest complexity that its anatomical connectome can host. Last, we introduce a new model of hierarchical networks inspired on the topology of neural and brain networks. Our hierarchical network model successfully combines nested modules with the presence of hubs. This is achieved by centralising the inter-modular connectivity through a few nodes by a preferential attachment rule. These networks achieve higher complexity than other well-known benchmark models.
The manuscript is organised as follows. First we introduce a measure of functional complexity that is based on the variability of the pair-wise cross-correlations of the nodes. We then investigate the complexity of neural networks in comparison to surrogate networks. Finally we compare the complexity of common random and hierarchical network models and we introduce the new model of modular and hierarchical networks with centralised inter-modular connectivity.
Measuring functional complexity
Despite the common use of the term “complex networks” a formal quantitative measure is missing to determine how complex a network is. Here we take an indirect approach and estimate the complexity of the collective dynamics that the network can host. In general, the complexity of a coupled dynamical system is a combination of the temporal complexity of the signals traced by the individual nodes and of the spatial formation of clusters. Because we are here interested on the influence of the network’s topology and because the temporal complexity depends on the model chosen for the node dynamics, we study the spatial aspect of complexity. We refer to this as functional complexity for consistency with the term functional connectivity to denote the time-averaged dynamical interdependencies between neural populations.
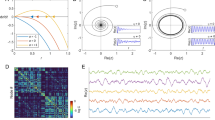
Given a network of N coupled dynamical nodes, e.g. neurones, cortical regions or oscillators, its pair-wise correlation matrix R reflects the degree of interdependencies among the nodes. When the nodes are disconnected from each other, they are also dynamically independent and hence, no complex collective dynamics emerge. All correlation values are rij ≈ 0, Fig. 1(top). In the opposite extreme, when the nodes are strongly coupled, the network becomes synchronised. However, global synchrony is neither a complex state because all nodes follow the same behaviour. In this case all the correlation values are rij ≈ 1, Fig. 1(bottom). Complexity emerges when the collective dynamics are characterised by intermediate states, between independence and global synchrony. Such states are reflected by a broad distribution of rij values, Fig. 1(middle).

Illustration of the measure for functional complexity.
When the collective dynamics of a network are close to independence or to global synchrony (top and bottom panels) the distribution of the cross-correlation values are characterised by narrow peaks close to rij = 0 or to rij = 1. Complex dynamical interactions happen when the collective behaviour is characterised by intermediate states leading to a broad distribution of the correlation values (middle panel). Red lines correspond to the uniform distribution,  , where m is the number of bins.
, where m is the number of bins.
At the two extreme cases, independence and global synchrony, the distribution p(rij) of pair-wise correlations is characterised by a narrow distribution. In between, at the range in which the network dynamics are more complex, the distribution becomes broader. After these observations we define the functional complexity C of the network as the variability of p(rij). Now, there are different manners to evaluate the variance of a distribution. For example, in ref. 13, complexity was defined as the normed entropy of p(rij). Here, we choose to define complexity as the difference between the observed distribution p(rij) and the uniform distribution. If p(rij) is estimated in m bins, the uniform distribution is  for all bins μ = 1, 2, …, m. Hence, functional complexity is quantified as the integral between the two distributions, which is replaced by the sum of their differences over the bins:
for all bins μ = 1, 2, …, m. Hence, functional complexity is quantified as the integral between the two distributions, which is replaced by the sum of their differences over the bins:

where |·| means the absolute value and  is a normalisation factor that represents the extreme case in which the p(rij) is a Dirac-delta function δm. That is, when all rij values fall in the same bin as it happens when the nodes are either mutually independent or globally synchronised. Because we are only interested in the pair-wise interactions we discard the diagonal entries rii from the calculations.
is a normalisation factor that represents the extreme case in which the p(rij) is a Dirac-delta function δm. That is, when all rij values fall in the same bin as it happens when the nodes are either mutually independent or globally synchronised. Because we are only interested in the pair-wise interactions we discard the diagonal entries rii from the calculations.
After comparing different alternatives to quantify C we found that the measure in Eq. (1) to be the most convenient solution; see Supplementary Information. This choice turned to be the most sensitive to discriminate between network topologies and also the most robust to variation in the number of bins. The reason is that the integral does not simply evaluate the broadness of the distribution but, more generally, its divergence from uniformity. This measure of functional complexity is easy to apply to empirical and to simulated data. While in this paper we study cross-correlations, the measure can be applied to any other metric of pair-wise functional connectivity, e.g. mutual information.
Functional complexity of neural connectomes
In this section we investigate the functional complexity of anatomical brain and neural connectomes. We study the binary corticocortical connectivities of cats, macaque monkeys and humans, and also the neuronal wiring of the C. elegans (see Materials and Methods). We will refer to these as the structural connectivities (SC) and we will denote their corresponding correlation matrices R as their functional connectivities (FC). For each SC network we study the evolution of its FC as the collective dynamics undergo a transition from independence to global synchrony. This transition is controlled by increasing the weights, or coupling strength g, of the SC links. We compare the results to two types of surrogate networks: (i) rewired networks that conserve the degree distribution and (ii) random modular networks which preserve the community structure of the original network, see Materials and Methods. In the rewired networks the hubs are still present although the modular structure vanishes. The modularity preserving random networks conserve the number of links within and across modules but alter the degree distribution and the hubs disappear. For completeness, we also compare the results to those of random graphs with the same size and number of links. All results for surrogate networks are averages over 1000 realisations. In order to quantify more precisely the impact of the rich-club, we also include a lesion study. After selective removal of the links between the rich-club hubs functional complexity is reduced. This reduction is compared to ensembles of randomly lesioned networks.
To evaluate the functional complexity of the SC matrices we first need to estimate their FC matrices at different values of the coupling strength, g. Because we want to emphasise the contribution of the network’s topology on the dynamics it can host we need to discard, as much as possible, other sources of influence on the network dynamics. For this reason we introduce a heuristic mapping to analytically estimate the correlation matrices R out of the SC without the need to run detailed simulations, Eqs (5) and (7). See details in Materials and Methods. Assuming the network consists of a set of coupled Gaussian noise sources the time-averaged cross-correlation matrix R of the system can be analytically estimated out of the structural connectivity matrix9. In this framework the correlation between brain regions can be understood as the total influence exerted by one region over another, accumulated over all possible paths of all lengths within the network. The coupling (the weight of the links), serves as a resolution parameter determining the range of correlations. When g is weak perturbations quickly decay allowing only for local correlations between neighbouring nodes. As the coupling grows the range of the correlations gradually increases. For strong coupling, perturbations propagate along the whole network causing global correlations. An unrealistic property of the Gaussian diffusion model is that the system leads to divergent dynamics at strong couplings. Motivated by the fact that in neural systems the signals attenuate, that is, information fed into the network rapidly disappears or is transformed instead of perpetually propagate along the network, we solve the divergence problem introducing an exponential decay for the diffusion of the signals over longer paths. This exponential decay guarantees that, once the network is globally correlated, an increase in coupling has no influence and the system does not diverge. This property is shared by widely applied models for generic oscillatory and neural dynamics, e.g., Kuramoto oscillators and neural-mass models. Simulations performed with those models show the same qualitative behaviour as our exponential mapping; see Supplementary Information.
Comparison to surrogate networks
The results for the neural and brain connectomes are shown in Fig. 2. As expected, C vanishes at the extremes, when g = 0 and when g is large enough for the networks to globally synchronise. Complexity emerges at intermediate levels of g. Find sample correlation matrices in Supplementary Fig. S1. All real networks (solid red lines) achieve larger complexity than the surrogates along the whole range of g. The bar plots summarise the peak values. The lowest peak corresponds always to the random graphs (dotted lines) while the rewired (solid gray lines) and the modularity preserving (dashed lines) networks take intermediate complexities. These results show that it is the combination of hubs and modular structure what allows the real networks to reach larger functional complexities. Destroying one of these features, either the hubs (by randomising the networks to conserve only their modularity) or the modular structure (by rewiring links to conserve only the degrees), leads to a notable reduction in complexity. Another observation is that the transition to synchrony of the real networks is slower than that of the surrogates. This shows that there is a wide range of g for which the complexity remains high.

Functional complexity of anatomical connectomes.
Comparison between the evolution of complexity for four neural networks (solid red lines) and the results for surrogate networks: random graphs (dotted lines), rewired networks conserving degrees of nodes (dashed lines), and modularity preserving random graphs (dashed lines). The right-hand panels summarise the peak complexities achieved in each case. Note that absolute values are not comparable across species due to the different size and densities of the connectomes. Meaningful are the relative differences with the surrogates.
Since the rewiring procedure does not necessarily disconnect the hubs from each other, it remains unclear what is the precise impact of the rich-club itself on the complexity. How is complexity altered when the hubs are disconnected from each other? In order to investigate this in more detail we have performed a lesioning study. First, we have identified the rich-clubs on each of the four empirical networks, see Supplementary Information, and then we have selectively removed all the links between the rich-club hubs. These comprise only a small fraction of the total number of links and thus, small but measurable changes in complexity are expected. After selective removal of the rich-club links from the SC matrices their corresponding FC matrices were computed for the optimal g at which the complexity C(real) of the original networks were maximal. We find that, compared to the original networks, the functional complexity C(lesion) in the lesioned networks decreases in all the four cases. See Table 1.
The remaining question is whether the observed decrease is due to the selective removal of rich-club links, or a natural consequence of perturbing the network by lesioning links. To test this we performed random lesions removing the same number of links from each SC. The rich-club links were excluded from the random lesions. We generated 100,000 realisations for each SC. In the cases of the C. elegans and of the macaque connectomes we find that none of the randomly lesioned networks had lower complexity than the selectively lesioned SC. In the case of the cat’s connectome, only 1.5% of the randomly lesioned networks resulted in lower complexity. In the human SC, 22% of the randomly lesioned networks lead to lower complexity than the targeted lesion. These results confirm that the rich-club is also an important feature for the functional complexity in the networks. In all cases the selective removal of rich-club links led to a measurable decrease in C, which resulted significant in three of the four datasets.
Complexity of human resting-state FC
To finish this section on the complexity of neural connectomes we turn our attention to the human connectome. We compare the functional complexity for theoretically estimated FCs and empirically obtained FCs. First, we consider SC matrices for 21 participants obtained through diffusion imaging and tractography. We estimate the theoretical FCs applying the exponential mapping to the SCs of every participant. As before, we scan for the whole range of couplings g. The evolution of the average correlations and the corresponding functional complexity for each participant are shown in Fig. 3(a) and (b), solid gray curves. The population averages are represented by the red solid curves. Second, we obtained empirical FC matrices for a cohort of 16 subjects via resting-state functional magnetic resonance, see Materials and Methods. Mean correlations and functional complexity were calculated out of the empirical FCs, solid horizontal lines in Fig. 3(a) and (b). The blue solid lines represent the population averages for the empirical values. Comparing the theoretical estimates and the empirical observations we find that the functional complexity of the human brain at rest lies, within the limitations of cross-subject variability, at the peak functional complexity the anatomical SCs gives rise to. Moreover, we note that this intersection happens at the coupling strength at which the simulated FCs fit closest the empirical FCs, Fig. 3(c). Here we have quantified closeness as the Euclidean distance between the theoretical FC and the empirical FC matrices, diagonal entries ignored.

Comparison between estimated and empirical functional connectivity in human resting-state.
(a) Mean correlation and (b) functional complexity of simulated and empirical functional connectivity (FC) matrices. Horizontal lines are the results from empirical FC (one value per subject). Given empirical structural connectomes (tractography) corresponding FC matrices were estimated for increasing coupling g. Bold lines are population averages of the individual results in gray. (c) Euclidean distance between the theoretical FCs and the empirical FCs at different values of g. Green bold curve is the population average. Vertical lines in the three panels mark the g at which the fit is best.
In this section we have shown that the combination of modular architecture and hubs forming rich-clubs in anatomical connectomes are key ingredients for their high functional complexity. We have also found that, within the constrains of the simple diffusive model here employed and of the cross-subject variability, the human brain at rest appears to lie in a dynamical state which matches the largest complexity that the underlying anatomical connectome can host. In the following, we want to better understand how those anatomical features give rise to larger functional complexity. Therefore, we study and compare the complexity of several benchmark graph models.
Functional complexity of synthetic network models
In this section we study the functional complexity of common synthetic network models: random, scale-free and hierarchical. We also introduce a new model of hierarchical networks which is inspired by the properties of neural and brain networks. As in the previous section, for each network we first estimate the expected correlation matrix R applying the exponential mapping (see Material and Methods, Eqs (5) and (7)) and then we calculate the functional complexity C out of the R matrices using Eq. (1).
Random and scale-free networks
We begin studying random and scale-free graphs of N = 1000 nodes and link densities ρ = 0.01, 0.05, 0.1 and 0.2. As expected, the average correlations  increases monotonically with coupling strength g, Fig. 4(a) and (c), reflecting the transition the networks undergo from independence to global synchrony. Full circles (●) and full triangles (▲) mark the coupling at which 〈r〉 = 0.85. Considering the real coupling strength before normalisation, we see that dense networks are easier to synchronise; they reach 〈r〉 = 0.85 at weaker coupling, Fig. 4(e). Functional complexity always peaks in the middle of the transition, when 〈r〉 ≈ 0.5, Fig. 4(b) and (d). The complexity of scale-free networks is notably higher than that of random graphs. The reason for this difference is that in scale-free networks the hubs synchronise with each other earlier than the rest of the nodes14,15. Therefore, at intermediate values of g a synchronised population (composed by the hubs) coexists with the rest of nodes which are weakly correlated. See the correlation matrices in Supplementary Fig. S2. Finally, we observe that the peak complexity decreases with density in both random and scale-free graphs, Fig. 4(f).
increases monotonically with coupling strength g, Fig. 4(a) and (c), reflecting the transition the networks undergo from independence to global synchrony. Full circles (●) and full triangles (▲) mark the coupling at which 〈r〉 = 0.85. Considering the real coupling strength before normalisation, we see that dense networks are easier to synchronise; they reach 〈r〉 = 0.85 at weaker coupling, Fig. 4(e). Functional complexity always peaks in the middle of the transition, when 〈r〉 ≈ 0.5, Fig. 4(b) and (d). The complexity of scale-free networks is notably higher than that of random graphs. The reason for this difference is that in scale-free networks the hubs synchronise with each other earlier than the rest of the nodes14,15. Therefore, at intermediate values of g a synchronised population (composed by the hubs) coexists with the rest of nodes which are weakly correlated. See the correlation matrices in Supplementary Fig. S2. Finally, we observe that the peak complexity decreases with density in both random and scale-free graphs, Fig. 4(f).

Functional complexity of random and scale-free networks.
(a) Mean correlation and (b) functional complexity for random graphs of N = 1000 nodes. (c) and (d), same for scale-free networks. (e) Coupling strength required for the network to reach average correlation 〈r〉 = 0.85 depends on the density of the network. The real coupling is greal = g/λmax, where λmax is the largest eigenvalue. (f) Peak complexities reached by the networks depends on link density. All results are averages of 100 realisations.
Modular networks
We now generate networks of N = 256 nodes arranged into four modules of 64 nodes. Both the internal and the external links are seeded at random. We compare networks of varying modular strength by tuning the ratio of internal to external links while conserving the total mean degree to 〈k〉 = 24. Mean internal degree kint is varied from 12 to 24 and the mean external degree kext is varied accordingly from 12 to 0. The strength of the modular organisation is quantified by the modularity measure q16. When (kint, kext) = (12, 12) the network is almost a random graph. When kint increases (and kext decreases) the modules turn stronger until they become disconnected at (kint, kext) = (24, 0).
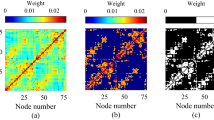
Figure 5(a) shows that the larger the modularity, the stronger is the coupling required to globally synchronise the network. The modules internally synchronise at rather weak couplings but to synchronise the modules with each other requires further effort, Fig. 5(b). The sparser the connections between the modules, the more difficult it is to synchronise them. As a consequence the distribution of correlations takes a bimodal form (see also Supplementary Fig. S2) with one peak corresponding to the weak cross-modular interactions and a second peak for the stronger within-modular correlations. The behaviour of complexity is rather different and does not monotonically increase with modularity, Fig. 5(c) and (d). In agreement with previous observations in modular networks of coupled phase oscillators10,11, we find an optimal ratio of internal to external degrees for which complexity maximises. In our case this happens for the networks with (kext, kint) = (5, 19) and modularity q = 0.50.

Functional complexity of modular networks.
(a) Average correlation and (c) functional complexity of modular networks as coupling strength g increases. Networks of N = 256 nodes divided into 4 communities. Results for networks of different modularity (ratio of internal to external links) are shown, all with same number of links. (b) Example correlation matrices R (blue is for rij = 0 and red for rij = 1). Data for one network with q = 0.542. (d) Peak complexity achieved by modular networks depends on modularity, compared to peak complexity of random graphs (gray line). All data points are averages of 100 realisations.
Hierarchical and modular networks
We finish the section studying the complexity of hierarchical and modular (HM) networks. We compare three models; the first two are well known in the literature and we introduce a new model which is motivated by the properties of real brain networks. Additionally, we will compare the results to those of equivalent random and rewired networks conserving the degrees.
Fractally hierarchical and modular networks
In an attempt to combine the modular organisation and the scale-free degree distribution found in metabolic networks, Ravasz and Barabási proposed a tree-like, self-similar network model1,17. The generating motif of size N0 is formed of a central hub surrounded by a ring of N0 − 1 nodes. To add hierarchical levels, every node is replaced by such a motif in which the original node becomes a local hub. Finally, to achieve a scale-free-like degree distribution the hubs are connected to all non-hub nodes at the lower branches. The example shown in Fig. 6 is the version with N0 = 5 and three hierarchical levels with a total of 125 nodes. For the calculations we consider a version with N0 = 6 and three hierarchical levels leading to a total size of N = 216. Due to the deterministic nature of the model, this is the closest we can approximate to the 256 nodes of the other hierarchical networks we study. The evolution of the average correlation 〈r〉 and of the complexity C are shown in Fig. 7(a) and (b). The mean correlation of the Ravasz-Barabási network does not distinguish from that of the rewired networks. The model achieves a very poor complexity which is overcome by both the random and the rewired networks. The large complexity of the random networks in this case can be explained by its sparse density (see Fig. 4) of only ρ = 0.031. The reason for why the Ravasz-Barabási model fails to match even the complexity of the rewired networks, despite having a scale-free-like degree distribution is because, by construction, the hubs of the model are preferentially connected to the non-hub nodes at the lower branches. This choice leads to a situation in which the hubs are poorly connected with each other, contrary to what happens in many real networks whose hubs form rich-clubs. The Ravasz-Barabási model lacks of a rich-club (see Supplementary Fig. S7).

Hierarchical and modular network models.
The Ravasz-Barabási model is a fractally hierarchical structure that was proposed to reproduce hierarchical features of many natural networks which posses both modules and a scale-free degree distribution. The Random HM model by Arenas, Díaz-Guilera & Pérez-Vicente is a nested modular network in which sets of random subgraphs (the modules) are randomly linked to form larger communities. We introduce a new model, the Centralised HM model which combines a nested modular hierarchy with a scale-free-like degree distribution. This is achieved by centralising inter-modular connections through hubs that form local and global rich-clubs.

Functional complexity of hierarchical and modular (HM) networks.
Mean correlation (upper panels) and functional complexity (lower panels) of three hierarchical and modular network models as the coupling strength g is increased. (a) and (b) Ravasz & Barabási model, (c) and (d) Random HM model and, (e) and (f) Centralised HM network model. All curves are averages for 100 realisations. Variances were very small in all cases and are omitted. For each realisation of the RHM and the CHM models, 100 random and 100 rewired networks were generated.
Random hierarchical and modular (RHM) networks
In refs 2,18, Arenas, Díaz-Guilera and Pérez-Vicente introduced a hierarchical network model in which a network of N = 256 nodes is divided into four modules of 64 nodes, each subdivided into another four submodules of 16 nodes, see Fig. 6. The links within and across modules at all levels are shed at random. The hierarchy is defined by the increasing density at the deeper levels. In the previous section we found that in a network composed of four modules of 64 nodes complexity was optimised when the mean external and internal degrees were (kext, kint) = (5, 19). Taking these as the starting point we set the mean degree of the nodes at the first level to be k1 = kext = 5. The remaining 19 links are distributed among the two deeper levels. The combination k2 = 6 and k3 = 13 maximises the functional complexity.
The average correlation and the functional complexity of the model are shown in Fig. 7(c) and (d). The behaviour of the Random HM networks is very similar to that of modular networks. The transition to global synchrony is governed by the interaction between the four large modules because synchrony between the small submodules is easily achieved; see corresponding correlation matrices in Supplementary Fig. S2. The largest complexity reached by the model is C = 0.48, only slightly above the one of the similar modular network.
Centralised hierarchical and modular (CHM) networks
The coexistence of modules and scale-free-like degree distributions is a rather general observation in empirical networks. However, a model that adequately combines both features is missing. In brain connectomes both features are combined through the presence of a rich-club on top of the modular organisation. That is, cross-modular connections are not fully random but tend to be centralised through the hubs3,19,20. Hence, we now propose a hierarchical network model which combines both features, modules and hubs, inspired by the observations in brain connectomes. For that we modify the Random HM model and replace the random connectivity between modules by a preferential attachment rule. This is achieved by sorting the nodes within a module and assigning them a probability to link with external communities proportional to their rank. See Materials and Methods for details. In the following we set the inter-modular links to be seeded with exponent γ2 = 2.0 and the links between the four major modules (at the top level) to be placed with γ1 = 1.7. These values for the exponents are chosen such that hubs in the resulting networks have rich-clubs comparable to those in brain connectomes, see Supplementary Fig. S7.
The average correlation and the functional complexity of the Centralised HM model are shown in Fig. 7(e) and (f). The peak complexity is C = 0.57, overcoming those of the other HM networks here investigated. Also, its decay at the strong coupling regime is slower than that of random and rewired networks, as observed in the empirical brain connectomes, indicating that the model is robust against accidentally falling into global synchrony. To keep the network away from global synchrony is a desirable feature for many real systems, specially for brain connectomes.
So far, we have shown that a network model constructed with the topological features of empirical neural networks, a combination of modular structure with hubs centralising the cross-modular connections, achieves larger complexity than standard hierarchical network models. Specially relevant is the improvement over the fractal model by Ravasz and Barabási, which has been the only network model proposed so far to combine the modular organisation and the presence of hubs in biological networks.
Summary and Discussion
In the present paper we have investigated the richness of collective dynamics that networks of different characteristics can host. For that, we have proposed a measure of functional complexity based on the variability in the strength of functional interactions between the nodes. It captures the fact that complexity vanishes in the two trivial extremal cases: when the nodes are independent of each other and when the network is globally synchronised. Functional complexity emerges at intermediate states, when the collective dynamics spontaneously organise into clusters which interact with each other.
First, we have found that perturbation of brain’s connectivity such that its modular structure is destroyed while the degrees are conserved, and the other way around, leads to networks with reduced functional complexity. The result is in agreement with the observation that rich clubs increase the set of attractors in a network of spin-glass elements beyond a scale-free topology21. We also find that the regime of high complexity is stable and robust against the network accidentally shifting towards global synchrony.
Second, we have compared the theoretically estimated functional connectivity to empirical resting-state functional connectivity in humans. We have found that, within the limitations of the heuristic mapping here employed, the human brain at rest matches the largest functional complexity that the underlying anatomical connectome can host. This carries profound implications for understanding the relationship between structural and functional connectivity. Although the origin and the detailed role of the resting-state dynamics are still debated, it is well-known that the resting-state activity is highly structured into spatio-temporal patterns22. There is wide agreement that both consciousness and cognitive capacities benefit from the presence of a large pool of accessible states and to the ability to switch between them. This is supported by the finding that the dynamical repertoire of the brain is drastically decreased during sleep23 and under anaesthesia24,25. The variability of brain signals have been found to increase with age from childhood to adulthood26.
Last, but not least, we have introduced a new graph model of hierarchical and modular networks that leads to higher functional complexity than any of the models previously proposed and commonly used as benchmarks. Our model succeeds where previous efforts have failed: to combine nested modules with highly connected nodes. Specially remarkable is the improvement over the fractal model by Ravasz and Barabási, which was introduced to explain the co-existence of modular and scale-free-like degree distribution in biological networks1,17. The model fails to foster complex dynamics; it is even outperformed by comparable random and rewired graphs. The reason is that, by construction, the hubs of the Ravasz-Barabási networks are disassortative. That is, they are poorly connected with other hubs. This is contrary to the observations in brain connectomes whose hubs tend to be assortative and form rich-clubs (see Supplementary Fig. S7). Our hierarchical network model solves the problem by centralising the cross-modular communications through hubs with a preferential attachment rule.
Complexity, modules, hubs, integration and segregation
The idea that cortical function is a combination of specialised processing by segregated neural components and their subsequent integration is an old concept in neuroscience6,7. For example, the Global Workspace Theory by Baars postulated the integration into a global workspace of the information processed in parallel by specialised sensory systems27. The lack of whole-brain structural and activity data restricted the discussions to a theoretical ground for decades. During the 1990s, the study of empirical long-range connectivity in the cat’s and macaque’s cortex evidenced that corticocortical connectivity is modular. Regions specialised in a sensory modality are more often interconnected than with regions of other modalities28,29.
The question of which is the optimal network structure that allows the brain to optimally segregate and integrate information was investigated by Tononi and Sporns in a series of network optimisation studies. Initially random networks were mutated – slightly rewired – and selected to maximise a cost function refered as neural complexity8,9. This procedure gave rise to modular networks as those empirically observed. While modular organisation is a signature of segregation, the integration of information in modular networks can only happen via the global synchrony of the network. Global synchrony is both a rather inefficient strategy to integrate information and an undesirable state of the brain. To solve the puzzle it was proposed, again within the framework of the Global Workspace Theory, that integration might be performed by interconnected hubs which have access to the information in different segregated modules30,31,32. Closer analysis of the long-range connectivity in the cat’s cortex confirmed that corticocortical connectivity is indeed organised as a modular structure with a set of rich-club hubs centralising the multisensory communications3,19,33. Similar architectures have also been identified in the human anatomical connectome4 and in the neural architecture of the Caenorhabditis elegans5. These findings are the starting point for the hypothesis that the specialisation of cortical regions to different sensory modality may have triggered the segregation of cortical regions into network modules, while the rich-club hubs may be the responsible for the integration step3,20,32,33,34. We shall notice that this scenario, although reasonable and plausible, is still a working hypothesis which needs empirical demonstration. Results on the functional organisation of the brain during rest and task start to support the hypothesis35. The identification alone of the modular architecture with rich-clubs does neither explain how does the brain perform the integration step. Because integration is inherently related to the dynamic nature of the sensory inputs36, models of propagation of information in networks will become relevant to understand this question in the future37.
A common source of confusion in the literature arises from the implicit causal relationships which have been drawn between the network’s structural features, its complexity and its capacity to integrate and segregate information. The network optimisation performed by Tononi & Sporns illustrates some of these limitations. On the one hand, the procedure led to modular networks without hubs. Thus it remains an open question whether optimisation of complexity alone results in the network topologies we observe empirically. It would be of high interest to use multidimensional optimisation methods which can account for several constraints38 to clarify this question. Even if the results were negative, that optimisation of complexity alone does not generate hierarchical networks with modules and hubs, this would be important to better understand the “driving-forces” which shaped the brain’s connectivity along evolution. On the other hand, Tononi and Sporns presupposed that maximisation of the neural complexity measure implied an increase of the network’s capacity to integrate and segregate information. However, this causal relation has never been demonstrated. When comparing to our functional complexity measure, we find that neural complexity monotonically increases with coupling strength and is maximal when the networks are globally synchronised, see Supplementary Information. This contradicts the intention of neural complexity, which was proposed to identify networks with optimal balance between integration and segregation. At the globally synchronised state there is no segregation and hence, no optimal balance. In order to overcome this limitation Zhao, Zhou and Chen proposed an alternative measure of complexity based on the entropy of the distribution of cross-correlation values10,13. Here, we have adopted their approach but we have replaced the nonlinear entropy function by the integral between the observed and the uniform distributions. This choice considerably enhances the discriminative power of the measure and its robustness to variation in the number of bins to estimate the distribution. Find a comparison in the Supplementary Information.
Summarising, in this paper we could confirm that the hierarchical organisation of networks into modules interconnected via rich-club hubs lead to an increase of their functional complexity. As we have argued, the opposite might not be true. This, and the precise causal relations between a network’s complexity and its capacity to integrate and segregate information are still open questions which demand clarification. Explicit efforts are required within the field of brain connectivity to corroborate or discard the validity of these working hypothesis. In the mean-time, we shall refrain from taking these causal relations for granted; specially, when applying such concepts to evaluate and interpret clinical conditions39,40.
Limitations
The temporal evolution of the functional complexity is a relevant aspect we have ignored here. A complete characterisation still requires further developments because the complexity of a coupled dynamical system is composed by two aspects. One is the formation of complex coalitions between the nodes. This is the interaction complexity that we have studied here and which we have coined as functional complexity. The other aspect is the complexity of the time-courses traced by the individual signals, or by the system as a whole. From a temporal perspective, neither random nor periodic signals are complex41. Random signals are unpredictable but represent fully disordered behaviour. Periodic signals are predictable but represent ordered behaviour. On the other hand, chaotic signals are complex because they are the result of an intricate mixture of order and unpredictability. However, we should notice that a set of chaotic elements may be synchronised giving rise to low functional complexity; a set of coupled periodic signals could result into heterogeneous spatial correlations due to the network’s topology leading to high functional complexity.
The results here presented are to be considered under the constraints and the limitations of the heuristic exponential mapping we have introduced to theoretically estimate the networks’ functional connectivity. (i) The model is an estimation of the time-averaged cross-correlation and is therefore not suitable to evaluate temporal fluctuations. (ii) In diffusion models the nodes are considered as passive relay stations for the flow of information while brain regions and neurones likely perform nonlinear transformations to the incoming information through active and complex dynamics at the local circuits.
Neural dynamics emerge from nonlinear interaction together with external stochastic perturbations, characterised by complex oscillations. Detailed collective dynamics may depend on various factors, including nonlinearity in the local dynamics and the form of the interactions. However, some generic properties may not be dominantly determined by such details, especially the dependence of the dynamical correlation on the network topology. Dynamical cross-correlation (functional connectivity) measures the interdependence between brain areas over relatively long time scales, thus are mainly determined by the slow modes which can be captured by the first few modes in the expansion of the local dynamics and coupling functions42. Estimations derived from linear Gaussian processes make good sense to capture the correlated fluctuations around the leading linear modes, but it diverges at strong couplings because it ignores the higher order dynamics. To gain some understanding, we have illustrated how a Gaussian diffusion process can be interpreted in terms of the networks’ graph properties, in particular on the role played by communication paths of different length.
The heuristic exponential mapping we have proposed further improves such a strategy by effectively taking some high-order contributions into consideration; specially, the decay of information along the path. It accounts for the fact that information in a neural system is used or transformed instead of perpetually diffuse within the network. This avoids the divergence problems of the linearised Gaussian diffusion process without the need to consider a particular dynamical model. This is also the reason for why the simple exponential mapping can capture the behaviour of some coupled dynamical models, e.g., Kuramoto and neural mass models (see Supplementary Fig. S6). An advantage of the exponential mapping for the exploratory purposes of the current paper was the computational efficiency. It would have been impractical to perform the extensive set of comparisons with surrogate networks if actual simulations were to be run for every datapoint.
Outlook
From a practical point of view our measure of functional complexity is an excellent candidate as a clinical marker for connectivity-related conditions. Over the last decade it has been consistently reported how resting-state functional connectivity differs across healthy subjects and patients suffering from diverse conditions43. Most of those reports are based in the graph analysis of functional connectivity which unfortunately depend on several arbitrary choices44,45, e.g., the need to set a threshold to binarise the correlation matrix. Our measure of complexity requires no unreasoned choices, it is easy to apply and interpret. The measure can be applied to any metric of pair-wise functional connectivity, e.g., mutual information, despite we restricted here to cross-correlation. It is also very fast to compute and is thus suitable for real-time monitoring systems.
The new hierarchical graph model we have introduced represents a very satisfactory compromise to combine hierarchically modular architecture with a broad degree distribution. From a biological point of view, however, we recognise the need to define models which can explain how brain networks developed their current topology in the course of evolution. We foresee that the key ingredients of such evolutionary models are: (i) identification of the “driving-forces”, e.g., the balancing between integration and segregation, and (ii) a growth process that accounts for the increase in the number of neurones or cortical surface over time46,47. Other ingredients shall include (iii) the trade-off between the cost and the efficiency of the resulting networks given the spatial constraints of the brain48,49,50 and (iv) the patterns of axonal growth during development51.
As a final remark, we shall notice that although we have here restricted to the study of neural and brain connectomes, we are confident that the modular organisation with centralised intercommunication is a general principle of organisation in biological networks. We find it reasonable that the assumption of balancing between integration and segregation as the principal driving-force to shape the large-scale neural connectomes, is also applicable to other networked biological systems. For example, we recently reported that the transcriptional regulatory network of the Mycobacterium tuberculosis shares fundamental properties with those of neural neural networks52. In the end, the transcriptional regulatory network is the system responsible in the small bacterium to collect information of the environment through different channels, to process and interpret that information, and to efficiently combine it to “take decisions” that improve the chances of survival.
Materials and Methods
Connectivity datasets
Find in Table 2 a summary of properties of the empirical connectomes used in this paper.
Caenorhabditis elegans
The C. elegans is a small nematode of approximately 1 mm long and is one of the most studied organisms. Its nervous system consists of 302 neurones which communicate through gap junctions and chemical synapses. We use the collation performed by Varshney et al. in ref. 5; the data can be obtained in http://wormatlas.org/neuronalwiring.html. After organising and cleaning the data we ended with a network of N = 275 neurones and L = 2990 links between them. For the general purposes of the paper we consider two neurones connected if there is at least one gap junction or one chemical synapse between them. We ignored all neurones that receive no inputs because they are always dynamically independent. The resulting network has a density of ρ = 0.04 and a reciprocity of 0.470 meaning that 47% of links join neurones A and B in both directions while the remaining 53% connect two neurones in only one direction. Most of the reciprocal connections come from the gap junctions, which are always bidirectional; only 21% of the chemical synapses are devoted to connect two neurones in both directions.
Cat cortex
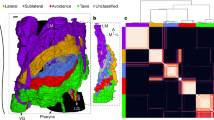
The dataset of the corticocortical connections in cats was created after an extensive collation of literature reporting anatomical tract-tracing experiments53,54. It consists of a parcellation into N = 53 cortical areas of one cerebral hemisphere and L = 826 fibres of axons between them. After application of data mining methods29,53 the network was found to be organised into four distinguishable clusters which closely follow functional subdivisions: visual, auditory, somatosensory-motor and frontolimbic. The network has a density of ρ = 0.30 and 73% of the connections are reciprocal.
Macaque monkey
The macaque network is based on a parcellation of one cortical hemisphere into N = 95 areas and L = 2390 directed projections between them48. The dataset, which can be downloaded from http://www.biological-networks.org, is a collation of tract-tracing experiments gathered in the CoCoMac database (http://cocomac.org)55. Ignoring all cortical areas that receive no input we ended with a reduced network of N = 85 cortical areas. The network has a density of ρ = 0.33 and reciprocity r = 0.74.
Human structural connectivity
Structural connectivity was acquired from 21 healthy right-handed volunteers. Find full details in refs 56,57. This study was approved by the National Research Ethics Service (NRES) committee South Central – Berkshire in Bristol and carried out in accordance with the approved guidelines. All participants gave written informed consent.
Diffusion imaging data were acquired on a Philips Achieva 1.5 Tesla Magnet in Oxford from all participants using a single-shot echo planar sequence with coverage of the whole brain. The scanning parameters were echo time (TE) = 65 ms, repetition time (TR) = 9390 ms, reconstructed matrix 176 × 176 and reconstructed voxel size of 1.8 × 1.8 mm and slice thickness of 2 mm. Furthermore, DTI data were acquired with 33 optimal nonlinear diffusion gradient directions (b = 1200 s/mm2) and 1 non-diffusion weighted volume (b = 0). We used the Automated Anatomical Labelling (AAL) template to parcellate the entire brain into 90 cortical and subcortical (45 each hemisphere) as well as 26 cerebellar regions (cerebellum and vermis)58. The parcellation was conducted in the diffusion MRI native space. We estimated the connectivity probability by applying probabilistic tractography at the voxel level using a sampling of 5000 streamline fibres per voxel. The connectivity probability between region i to j was defined by the proportion of fibres passing through voxels in i that reach voxels in j59. Because of the dependence of tractography on the seeding location, the probability from i to j is not necessarily equivalent to that from j to i. However, these two probabilities were highly correlated, we therefore defined the undirected connectivity probability Pij between regions i and j by averaging these two probabilities. We implemented the calculation of regional connectivity probability using in-house Perl scripts. Regional connectivity was normalised using the regions’ volume expressed in number of voxels.
The 21 networks so constructed were all composed of N = 116 brain regions and a number of links ranging from L = 1110 undirected links for the sparsest case (density ρ = 0.17) to L = 1614 for the densest (ρ = 0.24). These networks are individually used for the results in Fig. 3. In order to derive an average connectome, used in the results of Fig. 2, we performed an iterative procedure which automatically prunes outlier links (data-points falling out of 1.5 times the inter-quartile range). For each link between regions i and j outlier values of Cij are identified among the initial 21 measures available for the link (one per subject) as those values out of the 1.5 inter-quartile range (IQR). If outliers are identified we remove them from the dataset and search again for outliers. The procedure stops when no further outliers are identified. This method allows to clean the data without having to set an arbitrary threshold for the minimally accepted prevalence of the link across subjects. The average network contains approximately the same number of links as the individual matrices. Defining the average connectivity by computing the simple mean across the 21 Cij matrices (a usual approach in the literature) leads to an average connectivity matrix that contains more than twice the links in the matrices for individual subjects. For consistency with the datasets of the cats and the macaque monkeys, we show in the paper the results for the subnetworks formed only by the N = 76 cortical regions (38 per hemisphere) and ignoring all subcortical areas. We found qualitatively the same results in the cortical subnetwork and in the full-brain network, with the only difference that the cerebellum and the vermis form a very densely interconnected community that synchronises easily.
Human functional connectivity
Data were collected at CFIN, Aarhus University, Denmark, from 16 healthy right-handed participants (11 men and 5 women, mean age: 24.75 ± 2.54). All participants were recruited through the online recruitment system at Aarhus University excluding anyone with psychiatric or neurological disorders (or a history thereof). The study was approved by the internal research board at CFIN, Aarhus University, Denmark. Ethics approval was granted by the Research Ethics Committee of the Central Denmark Region (De Videnskabsetiske Komitér for Region Midtjylland). Written informed consent was obtained from all participants prior to participation.
The MRI data (structural MRI and rs-fMRI) were collected in one session on a 3 T Siemens Skyra scanner at CFIN, Aarhus University, Denmark. The parameters for the structural MRI T1 scan were as follows: voxel size of 1 mm3; reconstructed matrix size 256 × 256; echo time (TE) of 3.8 ms and repetition time (TR) of 2300 ms. The resting-state fMRI data were collected using whole-brain echo planar images (EPI) with TR = 3030 ms, TE = 27 ms, flip angle = 90°, reconstructed matrix size = 96 × 96, voxel size 2 × 2 mm with slice thickness of 2.6 mm and a bandwidth of 1795 Hz/Px. Approximately seven minutes of resting state data were collected per subject.
We used the automated anatomical labelling (AAL) template to parcellate the entire brain into 116 regions58. The linear registration tool from the FSL toolbox (www.fmrib.ox.ac.uk/fsl, FMRIB, Oxford)60 was used to co-register the EPI image to the T1-weighted structural image. The T1-weighted image was co-registered to the T1 template of ICBM152 in MNI space61. The resulting transformations were concatenated and inverted and further applied to warp the AAL template58 from MNI space to the EPI native space, where interpolation using nearest-neighbour method ensured that the discrete labelling values were preserved. Thus the brain parcellations were conducted in each individual’s native space.
Data preprocessing of the functional fMRI data was carried out using MELODIC (Multivariate Exploratory Linear Decomposition into Independent Components) Version 3.1462, part of FSL (FMRIB’s Software Library, www.fmrib.ox.ac.uk/fsl). We used the default parameters of this imaging pre-processing pipeline on all participants: motion correction using MCFLIRT60; non-brain removal using BET63; spatial smoothing using a Gaussian kernel of FWHM 5 mm; grand-mean intensity normalisation of the entire 4D dataset by a single multiplicative factor and high pass temporal filtering (Gaussian-weighted least-squares straight line fitting, with sigma = 50.0s). We used tools from FSL to extract and average the time courses from all voxels within each AAL cluster. We then used Matlab (The MathWorks Inc.) to compute the pairwise Pearson correlation between all 116 regions, applying Fisher’s transform to the r-values to get the z-values for the final 116 × 116 FC-fMRI matrix.
Community detection
After application of data mining methods the corticocortical network of the cat network was found to be organised into 4 distinguishable clusters which closely follow functional subdivisions: visual, auditory, somatosensory-motor and frontolimbic29,53. For the other three real datasets we investigated their modular structure using Radatools (http://deim.urv.cat/~sergio.gomez/radatools.php), a software that allows to detect graph communities by alternating different methods. We run the community detection such that it would first perform a coarse grained identification of the communities using Newman and Girvan’s method16 and then a method by Gómez and Arenas named ‘Tabu Search’18 was applied. Final optimisation of the partitions was performed by a reposition method.
The neural network of the C. elegans was partitioned into four modules of size 8, 64, 92 and 111 neurones respectively with modularity q = 0.417. The corticocortical network of the macaque monkey was divided into three modules of 4, 38 and 47 cortical areas with q = 0.402. The average human corticocortical connectome was divided into three modules of sizes 20, 26 and 30 with modularity q = 0.33. In two of the modules there is a dominance of one cortical hemisphere while the third module contains left and right areas in similar numbers.
Surrogates and synthetic network models
The network analysis, the generation of network models and the randomisation of networks has been performed using GAlib, a library for graph analysis in Python (https://github.com/gorkazl/pyGAlib). The network generation and rewiring functions are located in the submodule gamodels.py.
Random graphs
Random graphs were generated following the G(N, L) model that seeds links between randomly chosen pairs of nodes in an initially empty graph of N nodes until L links have been placed. Random graphs were produced using the function RandomGraph.
Scale-free networks
Random graphs with scale-free degree distribution were generated following the method in ref. 64. The nodes are ranked as i = 1, 2, …, N and they are assigned a weight  . To place the links, two nodes i and j are chosen at random with probabilities p(i) and p(j) respectively and they become connected if they were not already linked. The procedure is repeated until the desired number of links are reached. Scale-free networks generated using this preferential attachment rule achieve, on the limit of large and sparse networks, a degree distribution p(k) ∝ e−γ with γ = (1 + α)/α > 2. Tuning α in the range [0, 1) scale-free networks with exponent γ ∈ [2, ∞) are generated. Here, we set α = 0.5 to achieve scale-free networks with γ = 3.0. The exponent in individual network realisations fluctuated between 2.6 and 3.4. The function ScaleFreeGraph generates scale-free networks with desired size N, number of links L and exponent γ.
. To place the links, two nodes i and j are chosen at random with probabilities p(i) and p(j) respectively and they become connected if they were not already linked. The procedure is repeated until the desired number of links are reached. Scale-free networks generated using this preferential attachment rule achieve, on the limit of large and sparse networks, a degree distribution p(k) ∝ e−γ with γ = (1 + α)/α > 2. Tuning α in the range [0, 1) scale-free networks with exponent γ ∈ [2, ∞) are generated. Here, we set α = 0.5 to achieve scale-free networks with γ = 3.0. The exponent in individual network realisations fluctuated between 2.6 and 3.4. The function ScaleFreeGraph generates scale-free networks with desired size N, number of links L and exponent γ.
Rewired networks
Given a real network it is often desirable to compare it with equivalent random graphs which have the same degree distribution as the original network. A common procedure is to iteratively choose two links at random, e.g. (i, j) and (i′, j′), and to switch them such that (i, j′) and (i′, j) are the new links. The method is usually attributed to Maslov & Sneppen65 but it had been proposed by several authors before refs 66, 67, 68, 69, 70. The function RewireNetwork returns rewired versions of a given input network. In order to guarantee the convergence of the algorithm into the subspace of maximally random graphs, the link-switching step is repeated for 10 × L iterations, where L is the number of links.
Modular and nested-hierarchical networks
Random modular networks were generated, as the random graphs, choosing two nodes at random and connecting them if they were not previously linked. The difference lies on choosing the two nodes either from the same module or from two different modules. The nested hierarchical model with random connectivity2 is an extension of this procedure such that modules are subdivided into further modules. The function HMRandomGraph generates both modular and nested hierarchical networks depending on the input parameters.
Nested-hierarchical networks with centralised connectivity
While in the nested hierarchical random model the connections between the modules are shed at random, in neural and brain networks inter-module connections and communication paths tend to be centralised through the hubs19. We here propose a model of hierarchical and modular networks that combines both features. For that we modify the nested hierarchical model to replace the random connectivity between modules by a preferential attachment rule. We start by creating the 16 random graphs of 16 nodes each and mean degree κ3 = 13 of the deepest level. Then, the nodes of each submodule are ranked as i = 1, 2, …, N3 = 16 and they are assigned a weight  . To place the inter-modular links, two nodes i and j are chosen at random from two different modules with probability p(i) and p(j) respectively, and they become connected if they were not already linked. The procedure is repeated at each hierarchical level until the mean degree of inter-modular links are κ2 = 6 and κ1 = 5 as we had in the nested random hierarchical networks. Scale-free networks generated using this preferential attachment rule achieve, on the limit of large and sparse networks, a degree distribution p(k) ∝ e−γ with γ = (1 + α)/α > 264. Tuning α in the range [0, 1) scale-free networks with exponent γ ∈ [2, ∞) are generated. The inter-modular links at the second level are planted using γ2 = 2.0 and the links between the four major modules at first level are placed with γ1 = 1.7. The function HMCentralisedGraph generates nested-modular hierarchical networks with the inter-modular links centralised, seeding the inter-modular links at each level with a preferential attachment rule of desired exponent γ.
. To place the inter-modular links, two nodes i and j are chosen at random from two different modules with probability p(i) and p(j) respectively, and they become connected if they were not already linked. The procedure is repeated at each hierarchical level until the mean degree of inter-modular links are κ2 = 6 and κ1 = 5 as we had in the nested random hierarchical networks. Scale-free networks generated using this preferential attachment rule achieve, on the limit of large and sparse networks, a degree distribution p(k) ∝ e−γ with γ = (1 + α)/α > 264. Tuning α in the range [0, 1) scale-free networks with exponent γ ∈ [2, ∞) are generated. The inter-modular links at the second level are planted using γ2 = 2.0 and the links between the four major modules at first level are placed with γ1 = 1.7. The function HMCentralisedGraph generates nested-modular hierarchical networks with the inter-modular links centralised, seeding the inter-modular links at each level with a preferential attachment rule of desired exponent γ.
Modularity preserving random graphs
Given a network with a partition of its N nodes into n communities we generated graphs with the same modularity but randomly connected. Therefore we first counted in the original network the number of links Lrs between any two communities r, s = 1, 2, …, n. So, Lrr are the number of internal links within the community r and Lrs are the number of links between nodes in community r and community s. Then, the generation procedure is the same as for the random modular networks but considering the specific number of links to be planted in each case. The resulting random networks have the same modularity q as the original network for the given partition. Modularity preserving random graphs were generated using the function ModularityPreservingGraph.
Ravasz-Barabási networks
The Ravasz-Barabási model is composed of a ring of N0 − 1 nodes connected to their first neighbours surrounding a central hub. To generate subsequent hierarchical levels every node becomes the central node of a copy of the original motif. Finally, the central nodes are connected to all the non-hub nodes in the lower hierarchical levels of the branch they belong to. The function RavaszBarabasiGraph creates Ravasz-Barabási networks with desired size N0 in the original motif and desired number of hierarchical levels.
Mapping functional connectivity from anatomical connectomes
The collective dynamics of coupled systems depend on many factors such as the topology of the network (the structural connectome), the model chosen for the local node dynamics (e.g., Kuramoto oscillators, neural-mass models or spiking neurones) and the coupling function between them which determines how information is passed from one node to its neighbours. The purpose of the present paper is to investigate the influence of the connection topology while discarding as much as possible other influences. For that we propose a simple mapping to analytically estimate the functional connectivity out of a structural connectome. This is accomplished by considering a diffusive model with non-linear (exponential) decay of information transmission at longer paths. The convenience of this mapping for the present purposes are twofold. First, it avoids internal parameters. The only free parameter controlling the collective behaviour is the strength of the connections. Second, it allows to analytically estimate the functional connectivity without the need to run otherwise time-consuming simulations.
In order to illustrate the nonlinear mapping we here propose, let us first revisit a widely used linear stochastic model. Given a network of N neural populations represented by the binary adjacency matrix A with Aij = 1 if node i sends a projection to node j and Aij = 0 otherwise, the firing rate ri of each population can be expressed following a generic rate equations, often also referred as the Wilson-Cowan model:

where α is the inverse of the relaxation time, Θ(·) is a positive sigmoidal function, g the coupling strength, Ii an external input and ηi a noise term. Under the assumption of weak coupling the fluctuations xi of the firing rates ri around their mean can be linearised as:

where ξi is now a Gaussian white noise with zero mean and unit variance, and σ its variance. This is also known as an Ornstein-Uhlenbeck stochastic process. Given the column vectors xT = (x1, x2, …, xN) and ξT = (ξ1, ξ2, …, ξN), the system can be rewritten in matrix form as:

The transpose of the adjacency matrix AT is important when the network is directed such that the dynamics of population i is determined by its inputs, not by its outputs. The covariance of this multivariate Gaussian system can be analytically estimated9,71 by averaging over the states produced by an ensemble of noise vectors ξ. Defining Q = (1 − g/αAT)−1, the covariance matrix is thus

As stated above, the Gaussian diffusion process in Eq. (3) is a linear approximation of the fluctuations in Eq. (2) that is valid only for weakly coupled networks. Because the linear equation lacks of the sigmoidal function Θ(·) which delimits the amplitude of the inputs received by a neural population, its solution diverges to infinity when g/α equals any of the eigenvalues of the adjacency matrix A3. In order to compare networks of different size and density, the coupling strength shall be normalised such that  where λmax is the largest eigenvalue of A. For directed networks λmax is replaced by the largest norm of A’s complex eigenvalues. In this case the matrix Q is defined for all
where λmax is the largest eigenvalue of A. For directed networks λmax is replaced by the largest norm of A’s complex eigenvalues. In this case the matrix Q is defined for all  and the solutions of Equations (3) and (4) converge. The α parameter, which is usually regarded as an important parameter that controls re-entrant self-activations of the neural population plays here a rather irrelevant role. It only re-scales the coupling, shifting the strength at which the network diverges but it does not change the functional form of the solutions. Hence, we will consider α = 1. We will also consider that g is the normalised coupling such that the system converges for g ∈ [0, 1).
and the solutions of Equations (3) and (4) converge. The α parameter, which is usually regarded as an important parameter that controls re-entrant self-activations of the neural population plays here a rather irrelevant role. It only re-scales the coupling, shifting the strength at which the network diverges but it does not change the functional form of the solutions. Hence, we will consider α = 1. We will also consider that g is the normalised coupling such that the system converges for g ∈ [0, 1).
We now explain the solution of the Gaussian diffusion model in terms of the graph properties of the underlying structural connectivity. Therefore we note that the matrix Q can be represented as the following series expansion:

It is well-known that in a network the total number of paths of length l between two nodes is given by the powers of the adjacency matrix Al. This includes paths with internal recurrent loops. From this point of view we realise that Qji represents the total influence exerted by node j over node i, accumulated over all possible paths of all lengths. The relation between the structural and the functional connectivities is thus translated to understanding how the state of one node propagates to all others along the intricate organisation of paths within the complex network. Previous work in this direction has shown that the capacity of neural random networks to display oscillatory behaviour depends on the distribution of cycles (re-entrant paths)72, reflected by a sudden change of the network’s topology when super-cycles are formed from merging of isolated loops.
From its series expansion we realise that the linear Gaussian diffusion model assumes that paths of any length are equally influential. The series only converge when the coupling is small enough such that the powers of gl decrease faster than the growth in the number of paths of length l represented by Al. In neural systems this scenario is rather unrealistic since information fed into the system decays rapidly due to the stochasticity of synaptic transmission and to the interaction between excitatory and inhibitory neurones in local circuits. That is, information does not perpetually propagate along the network and signals attenuate over longer processing paths. Empirical evidence from resting-state functional magnetic resonance has shown that, in general, the functional connections between regions with direct structural connections are stronger, but significant functional connections can also occur between regions without a direct connection73. While direct structural connections seem to play a major causal role in shaping the resting-state functional connectivity, the flow of information over alternative processing paths cannot be neglected. It is thus more natural to assume that shorter processing paths are more relevant than longer ones. Mathematically, the general problem is to find a set of coefficients {cl} for which the series  converge for any adjacency matrix and coupling strength. Although the solution to this problem is not unique, a satisfactory solution is motivated by the measure of communicability in networks74,75. Communicability is a generalisation of the path-length on graphs to consider a general flow of information that favours short paths over longer paths without ignoring them. There is also indications that the communicability is the Green’s function of the network dynamics in case of diffusion processes, that is, the solution for the propagation of a single, infinitesimal perturbation.
converge for any adjacency matrix and coupling strength. Although the solution to this problem is not unique, a satisfactory solution is motivated by the measure of communicability in networks74,75. Communicability is a generalisation of the path-length on graphs to consider a general flow of information that favours short paths over longer paths without ignoring them. There is also indications that the communicability is the Green’s function of the network dynamics in case of diffusion processes, that is, the solution for the propagation of a single, infinitesimal perturbation.
The communicability between two nodes i and j is defined as the exponential of the adjacency matrix (eA)ij. This can itself be decomposed into a series with coefficients cl = 1/l! and hence, we re-define the influence matrix Q in Eq. (6) as:

From a physical point of view this represents the diffusion of local perturbations along the network with nonlinear (faster) decay for longer paths75 and it has the advantage of being free of the divergence problem of the linear Gaussian propagator. In a network nodes interact only locally with their direct neighbours, however, local perturbations propagate and can be “sensed” by other nodes giving rise to correlations also between distant nodes. The intensity of that correlation is thus determined by two critical factors: (i) the structure of the paths along which the perturbation propagates and (ii) the attenuation that the perturbation experiences along the way. When g is weak, perturbations quickly decay giving rise to local correlations only around the perturbed node. As g grows perturbations propagate deeper inside the network giving raise to stronger correlations.
Following the argumentation above, we will compute the covariance matrices as in Eq. (5) but replacing the propagator kernel Q by Qexp in Eq. (7). Such a modification still keeps the simplicity and elegance of the original linear Gaussian process, but captures the physically plausible effects of convergence in the dynamical process. As shown in the Supplementary Information the results obtained with this simple mapping are consistent with those obtained after simulations of the networks using widely applied models for generic oscillatory and neural dynamics, e.g. Kuramoto oscillators and Neural-Masses.
A final note, because the coupling required to reach global synchrony depends on the size and the density of the network, the interesting range of g at which the transition happens is different in every case. For convenience and for illustrative reasons we normalise the adjacency matrix by its largest real eigenvalue λmax before the calculation of Qexp. We observed that this normalisation aligns the transition to synchrony for most networks to happen in the range g ∈ [0, 10).
Additional Information
How to cite this article: Zamora-López, G. et al. Functional complexity emerging from anatomical constraints in the brain: the significance of network modularity and rich-clubs. Sci. Rep. 6, 38424; doi: 10.1038/srep38424 (2016).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Ravasz, E. & Barabási, A.-L. Hierarchical organization in complex networks. Phys. Rev. E 67, 026112 (2003).
Arenas, A., Díaz-Guilera, A. & Pérez-Vicente, C. Synchronization reveals topological scales in complex networks. Phys. Rev. Lett. 96, 114102 (2006).
Zamora-López, G., Zhou, C. S. & Kurths, J. Cortical hubs form a module for multisensory integration on top of the hierarchy of cortical networks. Front. Neuroinform. 4, 1 (2010).
van den Heuvel, M. & Sporns, O. Rich-club organization of the human connectome. J. Neurosci. 31, 15775–15786 (2011).
Varshney, L. A., Chen, B. L., Paniagua, E., Hall, D. H. & Chklovskii, D. B. Structural properties of the caenorhabditis elegans neuronal network. Plos Comput. Biol. 7, e1001066 (2011).
Damasio, A. R. The brain binds entities and events by multiregional activation from convergence zones. Neural Comp. 1, 123–132 (1989).
Fuster, J. M. Cortex and Mind: unifying cognition (Oxford University Press, New York, 2003).
Sporns, O. & Tononi, G. M. Classes of network connectivity and dynamics. Complexity 7(1), 28–38 (2001).
Tononi, G., Sporns, O. & Edelman, G. M. A measure for brain complexity: relating functional segregation and integration in the nervous system. Proc. Nat. Acad. Sci. 91, 5033–5037 (1994).
Zhao, M., Zhou, C., Lü, J. & Lai, C. Competition between intra-community and inter-community synchronization and relevance in brain cortical networks. Phys Rev. E 84, 016109 (2011).
Adjari Rad, A. et al. Topological measure locating the effective crossover between segregation and integration in a modular network. Phys. Rev. Lett. 108, 228701 (2012).
Nematzadeh, A., Ferrara, E., Flammini, A. & Ahn, Y.-Y. Optimal network modularity for information diffusionusion. Phys. Rev. Lett. 113, 088701 (2014).
Zhao, M., Zhou, C., Chen, Y., Hu, B. & Wang, B.-H. Complexity versus modularity and heterogeneity in oscillatory networks: Combining segregation and integration in neural systems. Phys Rev. E 82, 046225 (2010).
Zhou, C. S. & Kurths, J. Hierarchical synchronization in networks of oscillators with heterogeneous degrees. Chaos 16, 015104 (2006).
Pereira, T. Hub synchronization in scale-free networks. Phys. Rev. E 82, 036201 (2010).
Newman, M. E. J. & Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 69, 026113 (2004).
Ravasz, E., Somear, A. L., Mongru, D. A., Oltvai, Z. N. & Barabási, A.-L. Hierarchical organization of modularity in metabolic networks. Science 297, 1551–1555 (2002).
Arenas, A., Fernández, A. & Gómez, S. Analysis of the structure of complex networks at different resolution levels. New J. Phys. 10, 05039 (2008).
Zamora-López, G., Zhou, C. S. & Kurths, J. Graph analysis of cortical networks reveals complex anatomical communication substrate. Chaos 19, 015117 (2009).
Zamora-López, G., Zhou, C. & Kurths, J. Exploring brain function from anatomical connectivity. Front. Neurosci. 5, 83 (2011).
Senden, M., Deco, G., de Reus, M., Goebel, R. & van den Heuvel, M. Rich club organization supports a diverse set of functional network configurations. NeuroImage 96, 174–178 (2014).
Betzel, R. et al. Synchronization dynamics and evidence for a repertoire of network states in resting EEG. Front. Comput. Neurosci. 6, 74 (2012).
Deco, G., Hagmann, P., Hudetz, A. & Tononi, G. Modeling resting-state functional networks when the cortex falls asleep: Local and global changes. Cereb. Cortex 24, 3180–3194 (2013).
Hudetz, A., Humphries, C. & Binder, J. Spin-glass model predicts metastable brain states that diminish in anesthesia. Front. Syst. Neurosci. 8, 234 (2014).
Hudetz, A., Liu, X. & Pillay, S. Dynamic repertoire of intrinsic brain states is reduced in propofol-induced unconsciousness. Brain Connectivity 0, 1–13 (2014).
McIntosh, A., Kovacevic, N. & Itier, R. Increased brain signal variability accompanies lower behavioral variability in development. Plos Comput. Biol. 4, e1000106 (2008).
Baars, B. A Cognitive Theory of Consciousness (Cambridge University Press, 1988).
Hilgetag, C. C., Burns, G. A. P. C., O’neill, M. A., Scannell, J. W. & Young, M. P. Anatomical connectivity defines the organization of clusters of cortical areas in the macaque monkey and the cat. Phil. Trans. R. Soc. Lond. B 355, 91–110 (2000).
Hilgetag, C. C. & Kaiser, M. Clustered organisation of cortical connectivity. Neuroinf. 2, 353–360 (2004).
Dehaene, S., Kerszberg, M. & Changeux, J.-P. A neuronal model of a global workspace in effortful cognitive task. Proc. Nat. Acad. Sci. 95, 14529–14534 (1998).
Dehaene, S., Sergent, C. & Changeux, J.-P. A neuronal network model linking subjective reports and objective physiological data during conscious perception. Proc. Nat. Acad. Sci. 100, 8520–8525 (2003).
Shanahan, M. Embodiment and the inner life: Cognition and consciousness in the space of possible minds (Oxford University Press, 2010).
Zamora-López, G. Linking structure and function of complex cortical networks. Ph.D. thesis, University of Potsdam, Potsdam (2009).
Sporns, O. Network attributes for segregation and integration in the human brain. Curr. Opi. Neurobiol. 23, 162–171 (2013).
Bartolero, M., Thomas Yeo, B. & D’Esposito, M. The modular and integrative functional architecture of the human brain. Proc. Nat. Acad. Sci. 112, E6798–E6807 (2015).
Deco, G., Tononi, G., Boly, M. & Kringelbach, M. Rethinking segregation and integration: contributions of whole-brain modelling. Nat. Rev. Neurosci. 16, 430–439 (2015).
Mišić, B. et al. Cooperative and competitive spreading dynamics on the human connectome. Neuron 86, 1518–1529 (2015).
Avena-Koenigsberger, A. et al. Using pareto optimality to explore the topology of the human connectome. Phil. Trans. R. Soc. B 369, 20130530 (2014).
Koch, C., Massimini, M., Boly, M. & Tononi, G. Neural correlates of consciousness: progress and problems. Nat. Rev. Neurosci. 17, 307–321 (2016).
Tononi, G., Boly, M., Massimini, M. & Koch, C. Integrated information theory: from consciousness to its physical substrate. Nat. Rev. Neurosci. 17, 450–461 (2016).
Wackerbauer, R., Witt, A., Atmanspacher, H., Kurths, J. & Scheingraber, H. A comparative classification of complexity measures. Chaos, solitons & Fractals 4, 133–173 (1994).
Galán, R. On how network architecture determines the dominant patterns of spontaneous neural activity. Plos One 3, e2148 (2008).
Fox, M. & Greicius, M. Clinical applications of resting state functional connectivity. Front. Syst. Neurosci. 4, 19 (2010).
Fornito, A., Zalesky, A. & Breakspear, M. Graph analysis of the human connectome: Promise, progress, and pitfalls. NeuroImage 80, 426–444 (2013).
Papo, D., Zanin, M., Pineda-Pardo, J., Boccaletti, S. & Buldú, J. Functional brain networks: great expectations, hard times and the big leap forward. Phil. Trans. R. Soc. B 369, 20130525 (2014).
Kaiser, M. & Hilgetag, C. C. Modelling the development of cortical systems networks. Neurocomputing 58–60, 297–302 (2004).
Kaiser, M. & Hilgetag, C.-C. Spatial growth of real-world networks. Phys Rev. E 69, 036103 (2004).
Kaiser, M. & Hilgetag, C. C. Nonoptimal component placement, but short processing paths, due to long-distance projections in neural systems. Plos Comp. Biol. 2(7), e95 (2006).
Chen, Y., Wang, S., Hilgetag, C.-C. & Zhou, C. Trade-off between multiple constraints enables simultaneous formation of modules and hubs in neural systems. Plos Comp. Biol. 9, e1002937 (2013).
Samu, D., Seth, A. & Nowotny, T. Influence of wiring cost on the large-scale architecture of human cortical connectivity. Plos Comp. Biol. 10, e1003557 (2014).
Lim, S. & Kaiser, M. Developmental time windows for axon growth influence neuronal network topology. Biol. Cybern. 109, 275–286 (2015).
Klimm, F., Borge-Holthoefer, J., Wessel, N., Kurths, J. & Zamora-López, G. Individual node’s contribution to the mesoscale of complex networks. New J. Phys. 16, 125006 (2014).
Scannell, J. W. & Young, M. P. The connectional organization of neural systems in the cat cerebral cortex. Curr. Biol. 3(4), 191–200 (1993).
Scannell, J. W., Blakemore, C. & Young, M. P. Analysis of connectivity in the cat cerebral cortex. J. Neurosci. 15(2), 1463–1483 (1995).
Kötter, R. Online retrieval, processing, and visualization of primate connectivity data from the cocomac database. Neuroinformatics 2, 127–144 (2004).
Cabral, J., Hugues, E., Kringelbach, M. L. & Deco, G. Modeling the outcome of structural disconnection on resting-state functional connectivity. NeuroImage 62, 1342–1353 (2012).
van Hartevelt, T. et al. Neural plasticity in human brain connectivity: The effects of long term deep brain stimulation of the subthalamic nucleus in parkinson’s disease. Plos One 9, e86496 (2014).
Tzourio-Mazoyera, N. et al. Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage 1 (2002).
Behrens, T., Berg, H., Jbabdi, S., Rushworth, M. & Woolrich, M. Probabilistic diffusion tractography with multiple fibre orientations: What can we gain? Neuroimage 34 (2007).
Jenkinson, M., Bannister, P., Brady, M. & Smith, S. Improved optimization for the robust and accurate linear registration and motion correction of brain images. NeuroImage 17, 825–841 (2002).
Collins, D., Neelin, P., Peters, T. & Evans, A. Automatic 3D intersubject registration of MR volumetric data in standardized Talairach space. J. Computer Assisted Tomography 18, 192–205 (1994).
Beckmann, C. & Smith, S. Probabilistic independent component analysis for functional magnetic resonance imaging. IEEE Trans. Med. Imaging 23, 137–152 (2004).
Smith, S. Fast robust automated brain extraction. Human Brain Mapping 17, 143–155 (2002).
Goh, K.-I., Kahng, B. & Kim, D. Universal behaviour of load distribution in scale-free networks. Phys. Rev. Lett. 87, 27 (2001).
Maslov, S. & Sneppen, K. Specificity and stability in topology of protein networks. Science 296, 910–913 (2002).
Katz, L. & Powell, J. H. Probability distributions of random variables associated with a structure of the sample space of sociometric investigations. Ann. Math. Stat. 28, 442–448 (1957).
Holland, P. W. & Leinhardt, S. Sociological Methodology, chap. The statistical analysis of local structure in social networks, 1–45 (Jossey-Bass, San Francisco, 1977).
Rao, A. R. & Bandyopadhyay, S. A Markov chain Monte Carlo method for generating random (0, 1)-matrices with given marginals. Sankhya A 58, 225–242 (1996).
Kannan, R., Tetali, P. & Vempala, S. Simple Markov-chain algorithms for generating bipartite graphs and tournaments. Random Structures and Algorithms 14, 293–308 (1999).
Roberts, J. M. Simple methods for simulating sociomatrices with given marginal totals. Social Networks 22, 273–283 (2000).
Papoulis, A. Probability, random variables and stochastic processes (McGraw-Hill, New York, 1991).
beim Graben, P. & Kurths, J. Simulating global properties of electroencephalograms with minimal random neural networks. Neurocomputing 71, 999–1007 (2008).
Goñi, J. et al. Resting-brain functional connectivity predicted by analytic measures of network communication. Proc. Nat. Acad. Sci. 111, 833–838 (2014).
Estrada, E. & Hatano, N. Communicability in complex networks. Phys Rev. E 77, 036111 (2008).
Estrada, E., Hatano, N. & Benzi, M. The physics of communicability in complex networks. Phys. Reps. 514, 89–119 (2012).
Acknowledgements
The authors thank Mario Senden for discussions and early revision of the manuscript. This work has been supported by (G.Z.L.) the European Union Seventh Framework Programme FP7/2007–2013 under grant agreement number PIEF-GA-2012-331800, the German Federal Ministry of Education and Research (Bernstein Center II, grant no. 01GQ1001A), and the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 720270 (HBP SGA1). Y.C. and C.S.Z. were supported by the Hong Kong Baptist University (HKBU) Strategic Development Fund, the Hong Kong Research Grant Council (GRF12302914), HKBU FRG2/14-15/025 and the National Natural Science Foundation of China (No. 11275027). G.D. is supported by the European Research Council Advanced Grant: DYSTRUCTURE (295129) and by the Spanish Research Project PSI2013-42091-P; and M.L.K. by the European Research Council Consolidator Grant: CAREGIVING (615539).
Author information
Authors and Affiliations
Contributions
G.Z.-L., Y.C., C.S.Z. and G.D. conceived and designed the study. G.Z.-L. and Y.C. performed numerical simulations and analysed data. M.L.K. conducted human DTI and fMRI experiments and analysed data. G.Z.-L. wrote the first version of the manuscript and coordinated subsequent versions. All authors significantly contributed and agreed to the final version.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Zamora-López, G., Chen, Y., Deco, G. et al. Functional complexity emerging from anatomical constraints in the brain: the significance of network modularity and rich-clubs. Sci Rep 6, 38424 (2016). https://doi.org/10.1038/srep38424
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep38424
This article is cited by
-
Functional and structural reorganization in brain tumors: a machine learning approach using desynchronized functional oscillations
Communications Biology (2024)
-
A low dimensional embedding of brain dynamics enhances diagnostic accuracy and behavioral prediction in stroke
Scientific Reports (2023)
-
Structural determinants of dynamic fluctuations between segregation and integration on the human connectome
Communications Biology (2020)
-
Altered Neocortical Dynamics in a Mouse Model of Williams–Beuren Syndrome
Molecular Neurobiology (2020)
-
Spontaneous electromagnetic induction promotes the formation of economical neuronal network structure via self-organization process
Scientific Reports (2019)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
