
Abstract
Within plant populations, space-restricted gene movement, together with environmental heterogeneity, can result in a spatial variation in gene frequencies. In biennial plants, inter-annual flowering migrants can homogenize gene frequencies between consecutive cohorts. However, the actual impact of these migrants on spatial genetic variation remains unexplored. Here, we used 10 nuclear microsatellite and one plastid genetic marker to characterize the spatial genetic structure within two consecutive cohorts in a population of the biennial plant Erysimum mediohispanicum (Brassicaceae). We explored the maintenance of this structure between consecutive flowering cohorts at different levels of complexity, and investigated landscape effects on gene flow. We found that cohorts were not genetically differentiated and showed a spatial genetic structure defined by a negative genetic-spatial correlation at fine scale that varied in intensity with compass directions. This spatial genetic structure was maintained when comparing plants from different cohorts. Additionally, genotypes were consistently associated with environmental factors such as light availability and soil composition, but to a lesser extent compared with the spatial autocorrelation. We conclude that inter-annual migrants, in combination with limited seed dispersal and environmental heterogeneity, play a major role in shaping and maintaining the spatial genetic structure among cohorts in this biennial plant.
Similar content being viewed by others

Introduction
Spatial Genetic Structure (SGS) is the non-random spatial distribution of genotypes, a pattern occurring in most plant populations1. It results from an equilibrium among space-restricted gene movement, genetic drift and local selection2,3. SGS is most of the times the result of isolation by distance (IBD)2, in which local mating or short-distance seed dispersal generates a pattern such that kinship among individuals decreases with distance. The scale at which these processes act varies among species1, and recently, several studies have demonstrated that it can also happen at very fine scales4,5,6,7. The extent and strength of SGS depends on seed and pollen dispersal strategies as well as on mating system1,8,9. Moreover, dispersal can be directionally biased, resulting in differences in IBD intensity at different spatial directions10,11,12,13 that promote spatial asymmetric SGS, a pattern also occurring at fine-scales5. This spatial asymmetry usually responds to environmental heterogeneity10,11. At-site variability in ecological conditions can create differences in habitat suitability and, therefore, affect genetic connectivity via seed or pollen dispersal12,14. Regarding the latter, an increasing number of studies are analysing environmental heterogeneity to understand fine-scale SGS and its effects on population dynamics and evolution.
Studies dealing with the temporal scale of SGS have been mostly aimed at disentangling how demography affects SGS by comparing among age-classes15,16,17,18. In perennials, age-classes coexist in the same spatio-temporal context, implying that individuals initially from different cohorts classes may interbreed. In contrast, in strict biennials, i.e., those plants completing their life cycle in two years, individuals plants from consecutive cohorts are reproductively isolated because they do not overlap in their flowering year19. However, this presumption is far from reality because only a few species are strictly biennial20,21,22. Several processes promote variation in biennial life span, permitting the existence of inter-annual migrants that bridge years (‘facultative biennials’)23,24. These inter-annual migrants favour gene flow between cohorts, leading to homogenisation of their allelic frequencies25. However, little is known regarding how inter-annual migrants affect the similarities in SGS among cohorts of a biennial, particularly for small plant populations where temporal changes in population size could dramatically vary their genetic composition26. We think that the spatial location at which inter-annual migrants arrive to the next cohort may affect SGS. Particularly, in plants presenting limited seed dispersal, the localized arrival of inter-annual migrants may have predictable effects on the SGS, equalizing the spatial variation in allelic frequencies between consecutive cohorts and balancing population size fluctuations.
We have studied two consecutive cohorts of the biennial plant Erysimum mediohispanicum (Brassicaceae) to explore fine-scale SGS and to investigate the temporal maintenance of SGS between cohorts. E. mediohispanicum is endemic to the Iberian Peninsula27, where a highly diverse assemblage of pollinators visits their flowers. Although slightly self-compatible, this species needs pollinators for a complete seed set28, whose dispersal occurs at very short distances due to its barochorous dispersal strategy29. Populations of this species are patchily distributed and formed by tens to several hundreds of individuals30. These populations vary largely in size due to climate fluctuations, especially linked to drought years.
We have analysed the temporal maintenance of SGS between cohorts of E. mediohispanicum using 10 nuclear microsatellite and one plastid DNA marker. We also assess to what extent spatial environmental variation shapes the observed SGS. We first explore if cohorts were genetically differentiated, followed by characterization and comparison of SGS between cohorts at different levels: (1) by using spatial principal component analysis (sPCA) to assess global genetic structure; (2) by testing for isotropic SGS using kinship-distance distograms; (3) by using bearing correlograms to visualize SGS asymmetry (anisotropy). Finally, we assess associations among the spatial variation in genotypes and environmental factors using autoregressive spatial models.
Results
Genetic characterization
We successfully characterized 200 sampled individuals (100 per cohort, Fig. 1). The highest proportion of missing data (3%) was found in the locus E3 in 2011. Allelic richness was 11.7, ranging between four and 22 per locus (Table 1). Most loci were at Hardy-Weinberg equilibrium, with only one locus in 2010 and two in 2011 presenting a deficit of heterozygotes. The analysis of the plastid trnL-trnF spacer yielded five haplotypes with an uneven occurrence across the population, with 95.5% of individuals bearing one of the two most frequent haplotypes.

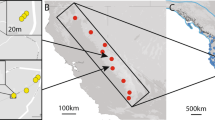
Spatial location of the marked plants.
Tree canopy is represented with green circles to evidence the fine-scale environmental heterogeneity. Scale is in meters.
Inter-annual genetic structure
All loci exhibited extremely low values of the genetic variance component related to inter-annual differences (FST < 0.006, p > 0.05 for all loci), similar to what we found for the multilocus value (FST < 0.001, p = 0.226). These low values were consistent with the lack of significance found after an AMOVA (σ2 = 0; p = 0.765). Moreover, the proportion of inferred migrants between cohorts was high (0.272).
Spatial variation of allele frequencies
Tests for spatial structure indicated the existence of global spatial structures within cohorts (max(t) = 0.019 for both cohorts, p = 0.016 and 0.036 for 2010 and 2011 respectively), but no local structures, e.g., genetic differentiation among close neighbours, (max(t) = 0.020 for both cohorts, p = 0.460 and 0.126 for 2010 and 2011). The sPCA analyses showed that most of the data structure was explained by the first three principal components (PC) in 2010 and by the first two in 2011 (Figure S1.A). The eigenvalues of these PCs were 0.045, 0.030 and 0.025 in 2010, and 0.040 and 0.027 in 2011, with the remaining eigenvalues showing lower values (Figure S1.B). For environment-genotype association studies, we retained the first two PCs, as these stand out in terms of genetic variance and spatial autocorrelation (Figure S1.A). The global structure represented by the first PC (PC1) from the sPCA, revealed similar spatial genetic patterns for both cohorts, extending as a cline along the X-axis of our study plot (Fig. 2), while the second (PC2) did not revealed a clear spatial pattern (Figure S2.B).

Spatial representation of the first vector from the sPCA for both cohorts and light availability (DSF).
Individuals tend to be surrounded by other individuals with similar score values, indicating local aggregation of related genotypes. Scores are represented with solid black squared symbols when positive and empty when negative. Square size is relative to the score value.
Isotropic spatial genetic structure
Kinship-distance distograms performed using nuclear markers showed positive significant values only at short distances (<2.5 m; Fig. 3A). The significant positive values for the first distance class (0.063 ± 0.013 in 2010; 0.071 ± 0.020 in 2011) and the negative slope of the relationship between kinship and the natural logarithm of spatial distance (−0.011 for both cohorts) lead to the same significant value of intensity of SGS (Sp = 0.012 ± 0.001; Table 2). The analysis of the plastid haplotypes showed similar results, with positive and significant values below 0.5 and 1 m in 2010 and 2011 respectively, in addition to occasional significant values at further distances (Fig. 3B). The F1 and Sp coefficients depicting SGS intensity showed significant values for both cohorts (F1 = 0.467 and 0.627; Sp = 0.207 and 0.019 in 2010 and 2011 respectively; p < 0.05).

Isotropic distograms.
For nuclear (A) and plastid (B) markers, the average kinship at each distance class are plotted with differing symbols depending on the comparison: orange squares (2010), blue diamonds (2011) and black circles (comparisons between cohorts). Filled symbols denote significance of the value when compared with the null hypothesis of no isolation by distance. Grey filled areas represents 95% confidence intervals for the null hypothesis of no spatial structure in the between-cohort comparisons.
We found similar patterns for the isotropic SGS between cohorts. When plotting the kinship coefficients of plants belonging to different cohorts against distance we observed that the pattern was maintained for both types of marker. We obtained significant positive values of average kinship coefficient below 1.5 m for the nuclear markers (Fig. 3A) and below 2 m for the plastid marker (Fig. 3B). Moreover, there were non-significant between-cohort differences in F1 and Sp (Table 2).
Anisotropic spatial genetic structure
The correlation between kinship and spatial distance varied with compass directions for each cohort and marker, indicating the occurrence of anisotropy in SGS (Fig. 4). This variation coincided between cohorts such that there was congruence in the bearing angles with the strongest and weakest SGS for each marker. For the nuclear markers, both cohorts presented the strongest correlation along the X-axis of the study plot (r = −0.050, θs = 90° in 2010; r = −0.059, θs = 87° in 2011; Table 3; Fig. 4A), and the weakest correlation at relatively close angles (r = −0.036, θw = 154° in 2010; r = −0.007, θw = 171° in 2011). Plastid markers showed the same bearing angle with the strongest correlation (θs = 56°, r = −0.112 and −0.051 in 2010 and 2011; Table 3; Fig. 4B) similar to the bearing angle with the weakest correlation (θw = 146°, r = 0.033 and 0.013 in 2010 and 2011 respectively).

Bearing correlograms.
For a series of bearing angles from 0 to 180° due the Y-axis of the plot, the Mantel correlation coefficient between genetic similarity and transformed distance matrix is plotted for both cohorts and for the nuclear (A) and plastidial (B) markers. Orange squares denote values for the cohort in 2010; blue diamonds values for the cohort in 2011. Significance after permutation is represented with filled symbols.
For the nuclear markers the strength of the correlation at θs showed the same values (Sp = 0.013 in 2010 and 2011), while at θw these were different (Sp = 0.020 and −0.007). The plastid marker showed differing values of strength at both angles (θs: Sp = 0.107 and 0.032; θw: Sp = 0.058 and −0.011).
Environment-genotype correlations
The lagged autoregressive models performed on PC1 and PC2 presented low values of Moran’s I index in the residuals (<0.099), indicating a good performance of these models (Supplementary Table S1), while ρ, the parameter associated with the inherent spatial autocorrelation term, was the most important parameter with values consistently above 0.8 (Table 4). The averaged parameters from the selected models indicated some environment-genotype associations. Light availability (DSF) was strongly associated in both cohorts with PC1 (w+ = 1 and 0.585 for 2010 and 2011; Table 4; Fig. 2) and in a lesser extent with PC2. Anions were strongly associated with PC1 in 2011 (w+ = 0.681; Figure S2.A) and PC2 in 2010 (w+ = 0.479), whereas cations had the strongest effect on PC2 both years (w+ = 0.721 and 0.438 for 2010 and 2011 ; Figure S2.B).
Discussion
We did not find genetic differentiation between two consecutive cohorts of the biennial plant E. mediohispanicum, a result indicating that these cohorts belong to the same gene pool and behave cohesively. Furthermore, fine scale SGS was congruent between cohorts, indicating recurrent seed dispersal limitation among years. Additionally, we found an association between the microenviroment and the spatial genetic variation. Below, we discuss the SGS found within the studied population and the causes that may be inducing it. We end by discussing how the absence of genetic differentiation and the maintenance of the SGS may be driven by inter-annual migrants between cohorts.
The spatial distribution of genotypes deviated each studied cohort from what it is expected under a random distribution of alleles, indicating the existence of SGS. Particularly, the genotypes were more similar at short distances, fitting a pattern of solation by distance even at this fine spatial scale. These results are supported by the global structure found using the sPCA and by the Mantel correlograms for both plastid and nuclear markers. This pattern emerges from restricted gene flow driven by the local dispersal of seeds or pollen, whose contributions to the final SGS may differ31. Limited seed dispersal promotes siblings to germinate and establish locally, creating aggregations of relatives and therefore structuring genotypes at the fine-scale6,7. This is likely to have happened in our study population because the distances at which the significant positive correlation vanished (<1–2.5 meters) are consistent with the reported distances of seed dispersal in E. mediohispanicum (0–0.38 m)29. However, limited seed dispersal may not be acting alone. The congruent SGS pattern showed by the nuclear and plastidial markers suggest that pollinators moving pollen at long distances are not blurring the SGS. In addition, we think that the spatial aggregation of individuals (Figure S3) together with the prevalence of floral visitors that tend to forage at short distances32,33, may facilitate mating events among nearby relatives, causing biparental inbreeding, and reinforcing the observed SGS. Nevertheless, even under random mating, SGS can occur as a byproduct of limited seed dispersal8,15, and therefore further analyses are needed to disentangle the relative role of pollen and seeds dispersal as drivers of the observed pattern.
We found asymmetry in SGS for both cohorts, indicating directionally biased gene flow. Kinship-distance correlation varied periodically along the spatial directions, revealing higher resistances to gene flow at 90 and 87° due the Y-axis of the plot (Fig. 4). Directionally biased gene flow has been related to spatial gradients on environmental factors13, and has been reported in plant species where topography or environmental factors reinforce SGS in particular directions10,11,13,34. If these gradients are maintained over years, the predominance of gene flow along some axes may leave their signature in the SGS. However, we did not identify any environmental gradients because the analysed environmental factors showed a marked patchy heterogeneity. Several factors acting locally could produce the observed SGS asymmetry. For example, the non-random movement of pollinators driven by preferences for plant traits, or micro-environmental factors, may produce heterogeneous patterns of gene flow12. These environmental factors could also affect seed germination and seedling establishment, contributing to directionally biased SGS35. Additionally, directional genetic flow from other populations could contribute to the observed pattern, but at the present we have no evidences for this to be considered as an important factor shaping SGS asymmetry.
Site-specific ecological conditions mediate genetic connectivity36. In our study, the spatial variation in allele frequencies showed by the PC1 matched the spatial variation in understory light availability (Fig. 2). This pattern could be produced by light modulating the suitability of spaces for seed germination and seedling establishment37, and therefore contributing to a kind of fine-scale isolation-by-environment38. In addition, this pattern could be reinforced by the influence of light on the identity and behaviour of the pollinators visiting the plants39. Under this scenario, plants sharing the same light conditions would be visited by similar pollinators and therefore may exhibit higher genetic connectivity. This hypothesis, however, needs to be tested by further analyses of paternity on the offspring to relate pollen flow with understory light conditions and pollinators.
We also found that SGS was associated with some soil variables. Effects of soil heterogeneity on the pattern of genetic variation have been reported in several plant species. For example, Segarra-Moragues et al.35 have recently shown significant genetic differentiation between rosemary plants (Rosmarinus officinalis) growing in siliceous vs. calcareous soils. In our case, the observed fine-scale soil-SGS association could be caused by the differential performance (establishment, survival, growth) of some genotypes in slightly different edaphic conditions. However, it is noteworthy to highlight the high values of ρ (>0.867) in our models, indicating that, at this scale, spatially limited dispersion prevails over these site-specific environmental factors. In this sense, more evidence is necessary to disentangle the importance of the genotype-environment interactions in shaping SGS at this fine scale.
Prudence is cautioned in interpreting spatially lagged regressions because little is known about their performance when applied to landscape genetic analyses40. However, we are confident of our results for a number of reasons. It has been shown that these models are robust to type I errors41,42 and do not fail when using sPCA principal components as response variables40,43. In addition, ρ was consistently high in our models, and the residuals showed little to no spatial autocorrelation (Table S1), indicating that these models accounted adequately for the spatial autocorrelation. Nevertheless we are aware that the associations found here have to be interpreted cautiously when inferring the causal mechanisms leading to these environment-genotype associations.
Plants flowering in different years did not differ in their allelic frequencies, indicating that the two studied cohorts belong to the same gene pool. This is confirmed by the low values of FST and the non-significance of the AMOVA. In small populations of biennial plants, such as E. mediohispanicum, recurring and catastrophic declines of population size could conduce to genetic differentiation even among cohorts, since these fluctuations in population size are expected to produce intense genetic drift in small populations26. But even in the case of large demographic events, the occurrence of gene flow between cohorts may counterbalance genetic differentiation. Gene flow is surely due to the high amount of inter-annual migrants, up to 17% according to our Bayesass estimates, a high value when compared to most studies using this same algorithm44. Several factors may promote between-cohort gene flow via different pathways in E. mediohispanicum (Figure S4). Seed dormancy can be activated by unfavourable weather conditions45 and leads to mating between the descendants of different cohorts25. In addition, the arrival of inter-annual migrants can take other different paths. Firstly, via the repeated flowering of some individuals in the oncoming year. This could be caused by delayed reproduction or via a reduced reproductive success during a year followed by subsequent resource allocation, permitting a new reproductive event in the following year46. In our study species, several factors such as herbivory47 or pollen limitation48 may trigger the existence of this type of inter-annual migrants. Additionally, delayed or precocious flowering can occur as a response to climatic suitability to plant growth46, a likely candidate factor considering the climatic unpredictability of Mediterranean ecosystems49. Whatever the reasons, our results demonstrate that inter-annual migrants prevent the genetic differentiation among cohorts, contributing to population cohesion.
Between-cohort gene flow, besides homogenizing allelic frequencies, also reinforced SGS. Firstly, kinship-distance correlations showed a similar pattern within and between cohorts, with the same significant positive values spanning up to 1.5 and 2 m for nuclear and plastid markers respectively. Along with this, SGS intensity did not differ significantly between cohorts, emphasizing the similarities in isotropic SGS. These findings confirm that plants growing nearby are genetically more similar independently of whether they belong to the same flowering cohort or not. In addition, SGSs were similar in their spatial asymmetry, with coinciding bearing angles for the strongest and weakest correlations. The maintenance of the SGS between cohorts is likely due to the limited dispersal of seeds. The integration of all individual seed shadows determines the starting template for the spatial genetic patterns of future flowering plants16,50. Therefore, an inter-annual migrant stands as a representative of this spatial template in the new cohort. From this localized migration spot, the oncoming processes of gene flow through pollination and seed dispersal will spread the migrant genes in the new cohort similarly to what would occur in its parental cohort. In this sense, the environmental factors will similarly favour or restrict gene flow in some directions, and therefore migrant alleles will flow asymmetrically. These recurrent migration events will, in the long term, match the spatial genetic variation among cohorts, leading to the observed congruence in SGS. Furthermore, between-populations migration could also contribute to produce the observed SGS. However, biased and recurrent migration, probably mediated by long-distance pollination events, would be needed to explain the observed pattern. As these pollination events do not contribute to the plastidial SGS, the importance of recurrent spatial migration in the temporal maintenance of the SGS is, at least, doubtful.
We have demonstrated the existence of congruent fine-scale spatial genetic variation in two consecutive cohorts of a natural population of the biennial plant E. mediohispanicum. This SGS was consistently associated with environmental factors, such as light availability and soil composition. More importantly, there was always a strong spatial autocorrelation in SGS, suggesting that SGS was mostly caused by the spatial pattern of limited seed dispersal in distance rather than by any environment-genotype association. The two studied cohorts had homogenized allelic frequencies, indicating the absence of genetic isolation and the existence of inter-annual migrants. These migrants, due to spatial limited seed dispersal exhibited by E. mediohispanicum, imprint a spatially localized genetic signature on the new cohort, which ultimately results in a between-cohort matching of SGS.
Materials and Methods
Sampling design
In years 2010 and 2011 we set up a 20 × 20 m plot delimiting a population of E. mediohispanicum situated at 1723 m.a.s.l. at the Sierra Nevada Protected Area (SE Spain; 37° 8.07′ N 3° 21.71′ W). Each year we randomly selected 100 flowering plants and mapped their spatial location at the centimetre level (Fig. 1). These plants represented ~ 85% of the total individuals comprising a reproductive cohort. We characterized light and soil conditions for each individual plant. Light availability, measured as Direct Site Factor (DSF), was derived from hemispherical photographs taken at the ground level using a Nikon coolpix 4500 and subsequently analysed by applying the Hemiview software (Delta-T Devices, Cambridge, UK). Soil was characterized by means of cations (Na+, K+ and Mg2+) and anions (total nitrogen and phosphorous), and moisture content at field capacity as a reliable measure of the soil’s ability to retain water (see Supplementary Information S1). To decrease variable dimensionality we ran a PCA over cations and anions independently. We found two components explaining cation variability: the first (cations 1) explaining 58% and was associated to Mg2+ and K+ and the second (cations 2) explaining 33% and was associated to Na+ (Figure S5). Anions were synthesised in a variable explaining 70% of the variability and equally associated to nitrogen and phosphorous.
Genetic characterization
We genotyped each plant using nuclear and plastid molecular markers. We isolated DNA using the GenElute Plant Genomic DNA Miniprep Kit (Sigma-Aldrich) on 60 mg of plant material previously crunched in liquid nitrogen.
We amplified the plastidial trnL-trnF spacer (~1300 bp) using the tabC and tabF primers (see Abdelaziz et al.51 and Supplementary Information S2). PCR products were mixed with 0.15 volumes of 3 M sodium acetate, pH 4.6, and 3 volumes 95% (v/v) ethanol and subsequently precipitated after centrifuging at 4 °C. Amplicons were then sent to Macrogen (Geumchun-gu, Seoul, Korea) for sequencing in both directions, using the respective PCR primers. Chromatograms were reviewed and contigs were produced using Geneious v.752 (Biomatters, http://www.geneious.com/). Sequences were uploaded to Genbank (accession numbers KX641272 to KX641276).
From each plant we amplified 10 unlinked nuclear microsatellites loci (SSR) described in Muñoz-Pajares et al.53 (Supplementary Information S2). We additionally genotyped 500 offspring in order to detect and correct genotyping errors (e.g., allele dropout or null alleles) in the parental plant genotypes. Electropherograms were analysed and genotypes called using PeakScanner v.2 (Applied Biosystems) and exhaustive eye-inspection. We characterized each microsatellite locus within cohorts by computing observed and expected heterozygosity, number of alleles, and inbreeding coefficient. For this later we tested if deviated significantly from zero using 999 bootstrap replicates. We tested for Hardy-Weinberg equilibrium using an exact test based on Monte Carlo permutations for each locus and for all loci together. These tests were performed using the ‘pegas’54 and ‘diveRsity’55 packages in the open source software R v. 3.2.2.
Inter-annual genetic structure
We evaluated the amount of genetic differentiation between cohorts using Wright’s FST statistic. The significance of this statistic was obtained by comparing with a null distribution obtained after 500 random permutations of genotypes. We also performed an AMOVA between cohorts using Chord’s distances among genotypes56. Moreover, we used Bayesass v.1.357 to infer rates of recent inter-annual migrants. This software uses Markov chain Monte Carlo techniques to estimate the posterior probabilities of recent individual immigrants. We ran three independent MCMC runs for 107 iterations with a thinning of 2000 and a burn-in of the first 10% of the iterations. Delta parameters of allele frequency, migration, and inbreeding were set as 0.15.
Spatial variation of allele frequencies
We checked for the occurrence of fine-scale SGS within each cohort by conducting a spatial principal component analysis (sPCA)58 on the nuclear markers. This multivariate ordination technique tests for the existence of global structures (such as spatial clines) or local structures (genetic differences between neighbours). sPCA integrates principal component analysis and Moran’s autocorrelation index to reduce the multidimensional nature of genotype data into a set of highly informative orthogonal vectors that differentiate spatial patterns of genetic variation. To accomplish this analysis, a connection network depicting spatial weights among individuals has to be previously defined. We used the inverse of the spatial distances among pairs so that all plants were considered neighbours while accounting for the spatial cost distance. With the resulting sPCA principal components, we assessed spatial structures by representing the scores of the two main vectors in space. We only used the two first components (PC1 and PC2) to reduce the burden of the computation to the most informative sPCA principal components. We evaluated the significance of global and local structures using the test proposed by Jombart et al.58.
Isotropic spatial genetic structure
We explored the extent and intensity of SGS to evaluate if relatives were spatially clumped as a result of isolation by distance. For each cohort and for each nuclear (SSR) and plastid marker, we calculated Nason’s kinship coefficients59, which are standardized to a population’s allele frequencies and are highly robust to HWE deviations1. When calculating this coefficient using the plastid marker, we treated haplotypes as alleles from a haploid organism. To explore the spatial extent of SGS we calculated the average kinship coefficient for a set of distance classes (FD) spanning 0.5 meters, and plotted them against distance60. We subsequently measured the intensity of SGS by calculating two gene dispersal parameters: F1, the average kinship coefficient for the first distance class (<0.5 meters), and the Sp coefficient1, defined as -bF/(1-F1), where bF is the slope of the regression of kinship coefficients on the natural logarithm of the spatial distance among individuals within an optimized range of distances. The range of distances for which bF is calculated is related to the average parent-offspring distance and its approximation follows an iterative procedure1 implemented in the software SPAGeDi 1.5a61. Standard errors for all parameters were calculated jackknifing over SSR loci1,9, except in the case of cpDNA haplotypes, where only a marker was available. For SSR Sp, and each SSR FD we obtained a null distribution of expected values under the hypothesis of no SGS by permuting genotypes among individuals 9999 times, and compared them with the observed values to obtain a significance value.
We investigated the maintenance of the isotropic SGS between cohorts by plotting kinship coefficients against spatial distance as explained before, but restricting the comparisons to individuals belonging to different cohorts. Then, we compared the intensity of the SGS between cohorts by a t-test using the average and standard errors obtained by jackknifing over loci. We also calculated bF, F1 and Sp dispersal parameters restricting the comparisons to individuals belonging to different cohorts.
Anisotropic spatial genetic structure
We explored the anisotropy of SGS by testing whether its strength varied in different spatial directions using Rosenberg’s62 bearing correlogram, an analysis that uses a Mantel test to correlate a genetic similarity matrix with a transformed distance matrix for a set of spatial directions, measured as the angles formed with the Y-axis (θ). For a given direction, the transformed distance matrix is obtained by first calculating the natural logarithm of the original distance matrix, followed by weighting its values by the squared cosine of the clockwise bearing angle depicted by each pair of individuals and the fixed spatial direction. For this analysis we used the obtained kinship matrix and a set of 128 equidistant bearing angles. The significance of the correlations was obtained using a permutation test (999 permutations). Through this analysis we were able to find the bearing angle denoting the strongest (θs, minimal Mantel correlation) and weakest SGS directions (θw, maximal Mantel correlation). Next, we calculated the strength of SGS at θs and θw for each cohort. To perform this, and to augment the number of paired kinship coefficients, we included the plants inside a range of 30° around θs and θw10. For each cohort and θs and θw, we computed Sp and F1 and obtained their significance as explained before. These analyses were performed using SPAGeDi 1.5a61 and personalized scripts in R (Supplementary Information S3). As the temporal maintenance of anisotropy is determined by the congruence and strength of θs and θw between cohorts, we therefore compared the gene dispersal parameters Sp and F1 by means of a t-test.
Environment-genotype correlations
We evaluated the contribution of environmental factors to the spatial genotypic variation beyond isolation by distance. We used lagged simultaneous autoregressive models using the first two components of the sPCA as response variables43. These models assume the inherent spatial autocorrelation occurring in the response variable and are fairly robust to type I errors41,42. The models take the form:

In this equation, the typical ordinary least squares regression (Gi = βX + ε) is modified by adding a term (ρWijGj) which controls for the inherent spatial autocorrelation which is assumed to occur in the response variable. The PC scores of all other individuals (Gj) are weighted by the parameter ρ, which accounts for the lack of independence among individuals, and by the cost-distance-weighting matrix (Wij). We computed Wij using the inverse spatial distances among individuals because it approximately emulates a spatial autocorrelation under IBD40,43. By using site-based measures we were able to determine the environmental factors associated with genetic structure63.
From all possible combinations of models we selected those with ΔAIC < 2 from the best model. Following, we model-averaged parameter estimates and calculated their relative importance following Burnham and Anderson64. Moreover, the selected models were checked for remaining autocorrelation in residuals by using a Moran’s I test. Model performances and selection were calculated using the R packages ‘spdep’65 and ‘AICcmodavg’66.
Additional Information
How to cite this article: Valverde, J. et al. Inter-annual maintenance of the fine-scale genetic structure in a biennial plant. Sci. Rep. 6, 37712; doi: 10.1038/srep37712 (2016).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Vekemans, X. & Hardy, O. J. New insights from fine-scale spatial genetic structure analyses in plant populations. Mol. Ecol. 13, 921–935 (2004).
Wright, S. Isolation by Distance. Genetics 28, 114–138 (1943).
Epperson, B. K. Recent advances in correlation analysis of spatial patterns of genetic variation. Evol. Biol. 27, 95–155 (1993).
Hardy, O. J. et al. Fine-scale genetic structure and gene dispersal in Centaurea corymbosa (Asteraceae). II. Correlated paternity within and among sibships. Genetics 168, 1601–1614 (2004).
Rouger, R. & Jump, A. S. Fine-scale spatial genetic structure across a strong environmental gradient in the saltmarsh plant Puccinellia maritima. Evol. Ecol. 29, 609–623 (2015).
Lara-Romero, C. et al. Individual spatial aggregation correlates with between-population variation in fine-scale genetic structure of Silene ciliata (Caryophyllaceae). Heredity (Edinb) 116, 417–423 (2016).
Volis, S., Zaretsky, M. & Shulgina, I. Fine-scale spatial genetic structure in a predominantly selfing plant: role of seed and pollen dispersal. Heredity (Edinb) 105, 384–393 (2010).
Hamrick, J. L., Murawski, D. A. & Nason, J. D. The influence of seed dispersal mechanisms on the genetic structure of tropical tree populations. Vegetatio 107/108, 281–297 (1993).
Hardy, O. J. et al. Fine-scale genetic structure and gene dispersal inferences in 10 neotropical tree species. Mol. Ecol. 15, 559–571 (2006).
Born, C., Le Roux, P. C., Spohr, C., McGeoch, M. A. & van Vuuren, B. J. Plant dispersal in the sub-Antarctic inferred from anisotropic genetic structure. Mol. Ecol. 21, 184–194 (2011).
Rhodes, M. K., Fant, J. B. & Skogen, K. A. Local topography shapes fine-scale spatial genetic structure in the Arkansas Valley evening primrose, Oenothera harringtonii (Onagraceae). J. Hered. 4, 1–10 (2014).
DiLeo, M. F. et al. The gravity of pollination: integrating at-site features into spatial analysis of contemporary pollen movement. Mol. Ecol. 23, 3973–3982 (2014).
Wang, Z.-F. et al. Pollen and seed flow under different predominant winds in wind-pollinated and wind-dispersed species Engelhardia roxburghiana. Tree Genet. Genomes 12, 19 (2016).
Holderegger, R., Buehler, D., Gugerli, F. & Manel, S. Landscape genetics of plants. Trends Plant Sci. 15, 675–683 (2010).
Kalisz, S., Nason, J. D., Hanzawa, F. M. & Tonsor, S. J. Spatial population genetic structure in Trillium grandiflorum: the roles of dispersal, mating, history, and selection. Evolution. 55, 1560–1568 (2001).
Jones, F. A. & Hubbell, S. P. Demographic spatial genetic structure of the Neotropical tree, Jacaranda copaia. Mol. Ecol. 15, 3205–3217 (2006).
Zhou, H. P. & Chen, J. Spatial genetic structure in an understorey dioecious fig species: The roles of seed rain, seed and pollen-mediated gene flow, and local selection. J. Ecol. 98, 1168–1177 (2010).
Berens, D. G. et al. Fine-scale spatial genetic dynamics over the life cycle of the tropical tree Prunus africana. Heredity (Edinb). 113, 401–407 (2014).
Kelly, D. Demography of short-lived plants in chalk grassland. I. Life cycle variation in annuals and strict biennials. J. Ecol. 77, 747–769 (1989).
Hart, R. Why are biennials so few? Am. Nat. 111, 792–799 (1977).
Silvertown, J. Death of the elusive biennial. Nature 310, 271 (1984).
Klinkhamer, P. G. L., de Jong, T. J. & Meelis, E. Delay of flowering in the ‘biennial’ Cirsium vulgare: size effects and devernalization. Oikos 49, 303–308 (1987).
de Jong, T. J., Klinkhamer, P. G. L. & Metz, J. A. J. Selection for biennial life histories in plants. Vegetatio 70, 149–156 (1987).
de Jong, T. J. & Klinkhamer, P. G. L. Population ecology of the biennials Cirsum vulgare and Cynoglossum officinale. J. Ecol. 76, 366–382 (1988).
Königer, J., Rebernig, C. a., Brabec, J., Kiehl, K. & Greimler, J. Spatial and temporal determinants of genetic structure in Gentianella bohemica. Ecol. Evol. 2, 636–648 (2012).
Ellstrand, N. C. & Elam, D. R. Population genetic consequences of small population size: Implications for plant conservation. Annu. Rev. Ecol. Syst. 24, 217–242 (1993).
Nieto-Feliner, G. In Flora Iberica vol. 4 (ed. Castroviejo, S. ) (Consejo Superior de Investigaciones Científicas, 2003). at http://www.floraiberica.es/eng/PHP/direcciones_todas2.php?autor=Nieto+Feliner,+G.
Gómez, J. M. et al. Association between floral traits and rewards in Erysimum mediohispanicum (Brassicaceae). Ann. Bot. 101, 1413–1420 (2008).
Gómez, J. M. Dispersal-mediated selection on plant height in an autochorously dispersed herb. Plant Syst. Evol. 268, 119–130 (2007).
Gómez, J. M. & Perfectti, F. Evolution of Complex Traits: The Case of Erysimum Corolla Shape. Int. J. Plant Sci. 171, 987–998 (2010).
Freeland, J. R., Biss, P. & Silvertown, J. Contrasting patterns of pollen and seed flow influence the spatial genetic structure of sweet vernal grass (Anthoxanthum odoratum) populations. J. Hered. 103, 28–35 (2012).
Pérez-Collazos, E., Segarra-Moragues, J. G., Villar, L. & Catalán, P. Ant pollination promotes spatial genetic structure in the long-lived plant Borderea pyrenaica (Dioscoreaceae). Biol. J. Linn. Soc. 116, 144–155 (2015).
Valverde, J., Gómez, J. M. & Perfectti, F. The temporal dimension in individual-based plant pollination networks. Oikos 125, 468–479 (2016).
Austerlitz, F., Dutech, C., Smouse, P. E., Davis, F. & Sork, V. L. Estimating anisotropic pollen dispersal: a case study in Quercus lobata. Heredity (Edinb). 99, 193–204 (2007).
Segarra-Moragues, J. G., Carrión Marco, Y., Castellanos, M. C., Molina, M. J. & García-Fayos, P. Ecological and historical determinants of population genetic structure and diversity in the Mediterranean shrub Rosmarinus officinalis. Bot. J. Linn. Soc. 180, 50–63 (2016).
Dyer, R. J. & Sork, V. L. Pollen pool heterogeneity in shortleaf pine, Pinus echinata Mill. Mol. Ecol. 10, 859–866 (2001).
Isselstein, J., Tallowin, J. R. B. & Smith, R. E. N. Factors affecting seed germination and seedling establishment of fen-meadow species. Restor. Ecol. 10, 173–184 (2002).
Wang, I. J. & Bradburd, G. S. Isolation by environment. Molecular Ecology 23, 5649–5662 (2014).
Herrera, C. M. Microclimate and individual variation in pollinators: flowering plants are more than their flowers. Ecology 76, 1516–1524 (1995).
Kierepka, E. M. & Latch, E. K. Fine-scale landscape genetics of the American badger (Taxidea taxus): disentangling landscape effects and sampling artifacts in a poorly understood species. Heredity (Edinb). 116, 33–43 (2016).
Kissling, W. D. & Carl, G. Spatial autocorrelation and the selection of simultaneous autoregressive models. Glob. Ecol. Biogeogr. 17, 59–71 (2007).
Beale, C. M., Lennon, J. J., Yearsley, J. M., Brewer, M. J. & Elston, D. A. Regression analysis of spatial data. Ecol. Lett. 13, 246–264 (2010).
Robinson, S. J., Samuel, M. D., Lopez, D. L. & Shelton, P. The walk is never random: Subtle landscape effects shape gene flow in a continuous white-tailed deer population in the Midwestern United States. Mol. Ecol. 21, 4190–4205 (2012).
Meirmans, P. G. Nonconvergence in Bayesian estimation of migration rates. Mol. Ecol. Resour. 14, 726–733 (2014).
Baskin, C. C. & Baskin, J. M. In Seeds: Ecology, biogeography, and, evolution of dormancy and germination 37–77 (Elsevier Inc.), doi: 10.1016/B978-0-12-416677-6.00003-2 (2014).
Klinkhamer, P. G. L., de Jong, T. J. & Meelis, E. Life-history variation and the control of flowering in short-lived monocarps. Oikos 49, 309–314 (1987).
Gómez, J. M. Herbivory Reduces the Strength of Pollinator-Mediated Selection in the Mediterranean Herb. Am. Nat. 162, 242–256 (2003).
Gómez, J. M., Abdelaziz, M., Lorite, J., Jesús Muñoz-Pajares, a. & Perfectti, F. Changes in pollinator fauna cause spatial variation in pollen limitation. J. Ecol. 98, 1243–1252 (2010).
Gómez, J. M., Valladares, F. & Puerta-Piñeiro, C. Differences between structural and functional environmental heterogeneity caused by seed dispersal. Funct. Ecol. 18, 787–792 (2004).
Shimono, A., Ueno, S., Tsumura, Y. & Washitani, I. Spatial genetic structure links between soil seed banks and above-ground populations of Primula modesta in subalpine grassland. J. Ecol. 94, 77–86 (2006).
Abdelaziz, M. et al. Using complementary techniques to distinguish cryptic species: a new Erysimum (Brassicaceae) species from North Africa. Am. J. Bot. 98, 1049–1060 (2011).
Kearse, M. et al. Geneious Basic: an integrated and extendable desktop software platform for the organization and analysis of sequence data. Bioinformatics 28, 1647–1649 (2012).
Muñoz-Pajares, A. J. et al. Characterization of microsatellite loci in Erysimum mediohispanicum (Brassicaceae) and cross-amplification in related species. Am. J. Bot. 98, e287–e289 (2011).
Paradis, E. pegas: an R package for population genetics with an integrated-modular approach. Bioinformatics 26, 419–420 (2010).
Keenan, K., McGinnity, P., Cross, T. F., Crozier, W. W. & Prodöhl, P. A. diveRsity: An R package for the estimation and exploration of population genetics parameters and their associated errors. Methods Ecol. Evol. 4, 782–788 (2013).
Excoffier, L. & Smouse, P. E. Analysis of Molecular Variance Inferred From Metric Distances Among DNA Haplotypes: Application. Genetics 131, 479–491 (1992).
Wilson, G. A. & Rannala, B. Bayesian inference of recent migration rates using multilocus genotypes. Genetics 163, 1177–1191 (2003).
Jombart, T., Devillard, S., Dufour, A.-B. & Pontier, D. Revealing cryptic spatial patterns in genetic variability by a new multivariate method. Heredity (Edinb). 101, 92–103 (2008).
Loiselle, B. A., Sork, V. L., Nason, J. & Graham, C. Spatial genetic structure of a tropical understory shrub, Psychotria officinalis (Rubiaceae). Am. J. Bot. 82, 1420–1425 (1995).
Hardy, O. J. & Vekemans, X. Isolation by distance in a continuous population: reconciliation between spatial autocorrelation analysis and population genetics models. Heredity (Edinb). 83, 145–154 (1999).
Hardy, O. J. & Vekemans, X. spagedi: a versatile computer program to analyse spatial genetic structure at the individual or population levels. Mol. Ecol. Notes 2, 618–620 (2002).
Rosenberg, M. S. The bearing correlogram: a new method of analyzing directional spatial autocorrelation. Geogr. Anal. 32, 267–278 (2000).
Jombart, T., Pontier, D. & Dufour, A.-B. Genetic markers in the playground of multivariate analysis. Heredity (Edinb). 102, 330–341 (2009).
Burnham, K. P. & Anderson, D. R. Model selection and multimodel inference: a practical information-theoretic approach. (Springer-Verlag, 2002). at http://www.springer.com/us/book/9780387953649.
Bivand, R. et al. spdep: spatial dependence: weighting schemes, statistics and models. spdep R package version 0.5-56. (2011). at http://cran.r-project.org/package=spdep.
Mazerolle, M. J. AICcmodavg: model selection and multimodel inference based on (Q)AIC(c). R package version 2.0-4. (2016). at http://cran.r-project.org/package=AICcmodavg.
Acknowledgements
We are grateful to Belén Herrador and José María Corral for help and advice on DNA extraction and genotyping. We thank M. Abdelaziz for discussion on the previous version on this work and Susana Hitos for helping with soil analyses. M. Berbel, A. L. Caravantes and J. Lorite helped with data collection. P. Jordano provided us the photographic equipment used to take the hemispherical photographs. Our work in the study area was approved by the Sierra Nevada Natural and National Park headquarters. Grants from the Spanish Ministerio de Economia y Competitividad (CGL2009-07015, CGL2012–34736, CGL2013-47558-P), including EU-FEDER funds, and Plan Andaluz de Investigación (P11-RNM-7676) supported this study. JV was supported by a fellowship (BES-2010-030067) from MINECO. CG was supported by the FCT Investigador Programme and co-funded by the European Program COMPETE: FCOMP-01-0124-FEDER-019772 and FCT-ANR/BIA-BIC/0010/2013.
Author information
Authors and Affiliations
Contributions
J.V., J.M.G. and F.P. performed fieldwork and wrote the manuscript. J.V. performed lab-work and analysed the results with the contribution of F.P. and C.G., M.N.J. performed soil analyses. T.F.S. provided laboratory facilities and SSR guidance. All authors reviewed the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Valverde, J., Gómez, J., García, C. et al. Inter-annual maintenance of the fine-scale genetic structure in a biennial plant. Sci Rep 6, 37712 (2016). https://doi.org/10.1038/srep37712
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep37712
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
