
Abstract
The indeterminacy of quantum mechanics was originally presented by Heisenberg through the tradeoff between the measuring error of the observable A and the consequential disturbance to the value of another observable B. This tradeoff now has become a popular interpretation of the uncertainty principle. However, the historic idea has never been exactly formulated previously and is recently called into question. A theory built upon operational and state-relevant definitions of error and disturbance is called for to rigorously reexamine the relationship. Here by putting forward such natural definitions, we demonstrate both theoretically and experimentally that there is no tradeoff if the outcome of measuring B is more uncertain than that of A. Otherwise, the tradeoff will be switched on and well characterized by the Jensen-Shannon divergence. Our results reveal the hidden effect of the uncertain nature possessed by the measured state, and conclude that the state-relevant relation between error and disturbance is not almosteverywhere a tradeoff as people usually believe.
Similar content being viewed by others

Introduction
Quantum uncertainty is conventionally explained through two sequential quantum measurements1,2, the error of the first and its disturbance to the precision of the second are qualitatively claimed to have an essential tradeoff. The core effect in the relation between error and disturbance is the intrinsic back action of quantum measurements, as Dirac wrote “a measurement always causes the system to jump into an eigenstate of the dynamical variable that is being measured  ”3. Heisenberg only gave an intuitive and informal argument of the probable error-disturbance tradeoff. The famous uncertainty inequalities, Kennard’s4 ΔxΔp ≥ ħ/2 (Δ is the standard deviation), Robertson’s5
”3. Heisenberg only gave an intuitive and informal argument of the probable error-disturbance tradeoff. The famous uncertainty inequalities, Kennard’s4 ΔxΔp ≥ ħ/2 (Δ is the standard deviation), Robertson’s5  and Maassen-Uffink’s6,7,8,9 entropic inequality all focus on limitations of legal states, but do not cover the characteristic back-action of quantum measurements.
and Maassen-Uffink’s6,7,8,9 entropic inequality all focus on limitations of legal states, but do not cover the characteristic back-action of quantum measurements.
To close the discrepancy between mathematical inequalities and physical interpretations, Ozawa firstly quantified the error and the disturbance, and analyzed their relationship. He proposed an inequality10:

and claimed the incorrectness of the Heisenberg-type tradeoff εAηB ≥ |〈ψ|[A, B]|ψ〉|/2. There in, the error term, εA, is defined as the root mean squared of the difference between the observable really measured and A, the observable we aimed at. The disturbance to B, ηB, is defined in a similar manner. We shall not repeat the expressions of εA and ηB but emphasize that they are defined as being state-relevant, i.e., they are defined for each specific input state |ψ〉.
The mathematical correctness of Eq. (1) has been verified extensively in qubit experiments11,12,13,14,15,16. However, its physical exactness was questioned is triggering a heated debate on the error-disturbance tradeoff17,18,19,20,21,22,23,24,25,26,27. The εA and ηB defined by Ozawa were criticized for violating the operational requirements for exact and faithful definitions of error and disturbance, which are explicitly suggested in ref. 27. They require
-
error to be nonzero if the outcome distribution produced in an actual measurement of A deviates from that predicted by Born’s rule;
-
disturbance to be nonzero if the back-action introduced by the actual measurement alters the original distribution with respect to B.
These requirements emphasize the probabilistic feature of quantum mechanics, and further imply that 〈ψ|[A, B]|ψ〉 should be excluded to appear alone on the right hand side of the inequalities that describe the tradeoff27. This conclusion sharply conflicts with Eq. (1) and leaves an open problem as what can be there.
Meanwhile, Busch, Lahti and Werner (BLW) developed theories to support Heisenberg-type relations24,25. In their inequalities, the relevance to states is erased by searching the extreme case over all possible inputs. The relevance to input state has not been well taken into account26. These theories behave like benchmarking the quality of the measurement device. Unlike those state-relevant formalisms, they cannot describe the tradeoff in each particular experiment.
In spite of the intricate features, we notice the presence of ΔA and ΔB, characters of the quantum uncertainty, in Eq. (1). It inspires us to ask the question: does the quantum uncertainty possessed by the quantum state with respect to A and B play some hidden but intrinsic role in the error-disturbance tradeoff? Meanwhile, those state-irrelevant inequalities hint that the state-relevant relation may not be a pure tradeoff. In this paper, we will propose a state-relevant formalism of the error-disturbance relation with definitions of the error and the disturbance that obey the operational requirements. We demonstrate both theoretically and experimentally that a condition controlled by quantum uncertainty determines the existence of the error-disturbance tradeoff. We also give an inequality for the case where the tradeoff does exist.
Results
Error and disturbance
Suppose we measure observable A on a quantum system in state |ψ〉 with an imperfect real-life device. In the process, the employed device (together with the environment) selects a preferred pointer basis in the system’s Hilbert space28. As a result, the entire state evolves to be  , where indexes s and a label the system and the apparatus (also the environment), and
, where indexes s and a label the system and the apparatus (also the environment), and  . The apparatus bridges the quantum system and the classical world we stay in. It returns an outcome from the set
. The apparatus bridges the quantum system and the classical world we stay in. It returns an outcome from the set  . Repetitive measurements generate the distribution
. Repetitive measurements generate the distribution  with
with  . By the logic of quantum mechanics, what we learn from quantum measurements is just this distribution. However, due to kinds of imperfections,
. By the logic of quantum mechanics, what we learn from quantum measurements is just this distribution. However, due to kinds of imperfections,  is hard to be exactly the eigenstates of A, {|ai〉}. This mismatch, i.e., the error, is therefore embodied in the difference between P′ and
is hard to be exactly the eigenstates of A, {|ai〉}. This mismatch, i.e., the error, is therefore embodied in the difference between P′ and  , the distribution predicted theoretically by Born’s rule. Thus, we define the error, Errψ(A), to be specified below, to quantify the difference between P and P′ (see Fig. 1).
, the distribution predicted theoretically by Born’s rule. Thus, we define the error, Errψ(A), to be specified below, to quantify the difference between P and P′ (see Fig. 1).

Boxes with dashed frames stand for the ideal measurements with the outcomes given by Born’s rule. The other box stands for the real-life apparatus which produces the distribution P′. Error is defined by the divergence between P and P′. The difference between Q and  witnesses the disturbance caused by the inevitable back-action by the first measurement. Thus we define the disturbance by comparing Q and
witnesses the disturbance caused by the inevitable back-action by the first measurement. Thus we define the disturbance by comparing Q and  .
.
By the notation “|ψ〉” and the specified process of measurements, we have assumed that the problem in consideration associates with pure-state systems and the projective measurements that are maximally informative29. In fact, all the quantum measurements can be modeled by tracing back to projective measurements performed on a complete system described by a pure state. The concepts of mixed states and positive-operator valued measurements (POVM) emerge by statistically ignoring some sub-systems and losing some classical information. We will discuss them at the end and here focus on the most underlying structure.
Now we define the disturbance. Statistically, the back-action of the real-life measurement maps the original state |ψ〉 to  . This is the disturbance. When referring to observable B, it means that the original distribution determined by Born’s rule,
. This is the disturbance. When referring to observable B, it means that the original distribution determined by Born’s rule,  with
with  , is disturbed to
, is disturbed to  . Therein, {|bj〉} are eigenstates of B. If
. Therein, {|bj〉} are eigenstates of B. If  , the disturbance to the quantum state induced by the real-life measurement of A cannot be perceived from observing B. So we define the disturbance to B, Disψ(B), by the divergence between
, the disturbance to the quantum state induced by the real-life measurement of A cannot be perceived from observing B. So we define the disturbance to B, Disψ(B), by the divergence between  and Q.
and Q.
It can be seen that our definitions satisfy the operational requirements introduced above in a minimal way. That is, our definitions satisfy no additional requirements other than the operational requirements. Furthermore, the operational definitions will offer us a direct experimental implementation as illustrated in Fig. 2. With these preparations, we can now give one of the main results.

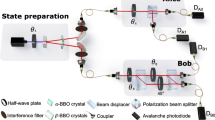
Here part (a) and part (b) show the setup for ideal measurement of A = σz and B = σx respectively. Part c shows the sequential measurements of A (imprecise) and B. The groups of half-wave plate and quarter-wave plate positioned behind the PBS (in the box with dashed frame) rotate |H〉, |V〉 to the eigenstates of  , the observable actually measured in the imprecise measurement. A polarizer is used to prepare the initial state of the photons. Finally, the photons are sent to fiber-coupled single-photon avalanche photodiode detectors.
, the observable actually measured in the imprecise measurement. A polarizer is used to prepare the initial state of the photons. Finally, the photons are sent to fiber-coupled single-photon avalanche photodiode detectors.
Quantum uncertainty and error-disturbance tradeoff
We find that a criterion for which quantum uncertainty completely determines the existence of the state-relevant error-disturbance tradeoff.
Theorem 1. For any d-dimensional pure state |ψ〉, there exists projective measurements such that Errψ(A) and Disψ(B) vanish simultaneously, i.e., there is no tradeoff between the error of measuring A and the consequential disturbance to B, if and only if  .
.
 , read P majorizes Q, means that if sorting the elements from large to small, i.e.,
, read P majorizes Q, means that if sorting the elements from large to small, i.e.,  and
and  , then
, then  for
for  30. That means the occurrence probability of a top-k high-probability outcome in the ideal measurement of A is no less than that of B, for all possible values of k. Thus, majorization gives a rigorous criterion for the partial order of certainty or uncertainty. Moreover,
30. That means the occurrence probability of a top-k high-probability outcome in the ideal measurement of A is no less than that of B, for all possible values of k. Thus, majorization gives a rigorous criterion for the partial order of certainty or uncertainty. Moreover,  leads to H(P) ≤ H(Q), where
leads to H(P) ≤ H(Q), where  is the Shannon entropy. As widely accepted, larger Shannon entropy means more uncertainty. So Theorem-1 concludes that, if the outcome of measuring A is more certain than the outcome of measuring B, there will be no state-relevant error-disturbance tradeoff; otherwise, the tradeoff will be switched on and a positive lower bound of Errψ(A) + Disψ(B) is expected.
is the Shannon entropy. As widely accepted, larger Shannon entropy means more uncertainty. So Theorem-1 concludes that, if the outcome of measuring A is more certain than the outcome of measuring B, there will be no state-relevant error-disturbance tradeoff; otherwise, the tradeoff will be switched on and a positive lower bound of Errψ(A) + Disψ(B) is expected.
The necessary part of Theorem 1 can be derived from a historic mathematical theorem31. The necessary part says if P and Q are generated in sequential measurements, P must majorize Q. That is, measurement is a way of extracting information thus the entropy is generally increasing. The sufficient part is more technic and we leave the proof in Methods. Our proof sets up an algorithm to find generally 2d−1 different realizations of  to close the tradeoff. There are two known extreme examples where there is no tradeoff. One is the case where |ψ〉 is an eigenstate of A. Another case is the zero-noise and zero-disturbance (ZNZD) states defined in ref. 27. In the first example of eigenstates, P = {1, 0, … 0}; for ZNZD states, P and Q are both the uniform distribution
to close the tradeoff. There are two known extreme examples where there is no tradeoff. One is the case where |ψ〉 is an eigenstate of A. Another case is the zero-noise and zero-disturbance (ZNZD) states defined in ref. 27. In the first example of eigenstates, P = {1, 0, … 0}; for ZNZD states, P and Q are both the uniform distribution  . So P majorizes Q in both cases. Here by revealing the effect of quantum uncertainty behind the scene, Theorem 1 links these isolated point-like examples together and extends the no tradeoff conclusion to extensive situations.
. So P majorizes Q in both cases. Here by revealing the effect of quantum uncertainty behind the scene, Theorem 1 links these isolated point-like examples together and extends the no tradeoff conclusion to extensive situations.
Theorem 1 does not conflict with the common sense that non-commuting observables are impossible to be precisely measured simultaneously with a state-independent strategy, because the vanishing tradeoff between error and disturbance implied by Theorem 1 is conditioned on the input state. An inverse question may be interested: given the real life measurements along  , how many input states share the merits of zero-error and zero-disturbance? We leave it to the Discussion.
, how many input states share the merits of zero-error and zero-disturbance? We leave it to the Discussion.
Quantification of the tradeoff
If  , the error-disturbance tradeoff is switched on. To describe the tradeoff, we shall quantify Errψ(A) and Disψ(B). Based on the above analysis, we can quantify them using any non-negative functional D(·, ·) that vanishes only when the associated two probability distributions are identical. The relative entropy
, the error-disturbance tradeoff is switched on. To describe the tradeoff, we shall quantify Errψ(A) and Disψ(B). Based on the above analysis, we can quantify them using any non-negative functional D(·, ·) that vanishes only when the associated two probability distributions are identical. The relative entropy  , a central concept in information theory with wide applications, is one such example. Explicitly, we quantify the error and the disturbance as
, a central concept in information theory with wide applications, is one such example. Explicitly, we quantify the error and the disturbance as

These information-theoretical definitions are independent of the unessential eigenvalues of the relevant ovservables, like the entropic uncertainty relation6,7. This is different from the Wasserstein 2-deviation used in the works of BLW. In the following, we give the result for 2-dimensional cases at first.
Theorem 2. When d = 2 and  , let us label the outcomes so that p1 ≥ p2 and q1 ≥ q2 and quantify error and disturbance by the relative entropy as Errψ(A) = D(P ‖ P′) and
, let us label the outcomes so that p1 ≥ p2 and q1 ≥ q2 and quantify error and disturbance by the relative entropy as Errψ(A) = D(P ‖ P′) and  . Then we have
. Then we have

where the Jensen-Shannon divergence,  (H is the Shannon entropy),
(H is the Shannon entropy),  is the distribution
is the distribution  .
.
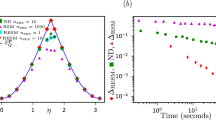
In Fig. 3, we illustrate both DJS(P, Q) and the exact bound obtained by numerical calculations. DJS(P, Q) is shown to be a valid lower bound which can be very close to the exact one. Theorem-2 answers the open question asked in ref. 27 of what can serve on the right hand side of the state-relevant inequality. The Jensen-Shannon divergence is also a distance function of probability distributions that has been applied in bioinformatics, machine learning and social science32. Interestingly, the well-known Holevo’s bound33, the upper bound to the accessible information of a quantum state, is its quantum generalization.

In part (a) the red line is the exact lower bound of Errψ(A) + Disψ(B) which we obtain via numerical methods. The blue line is the lower bound given by DJS(P, Q) in Theorem 2, it can be very close to the exact bound given in the red line. In part (b) as a function of ϕ, Errψ(A) + Disψ(B) is always higher than the bound given by  . The point marked by light blue dashed rectangle reaches the minima value of 0.304 that is obtained numerically, it is identical to the point marked in part (a). The error bars indicate the standard deviation including both systematical (±1° rotation of each plate) and statistical errors (Poissonian distribution).
. The point marked by light blue dashed rectangle reaches the minima value of 0.304 that is obtained numerically, it is identical to the point marked in part (a). The error bars indicate the standard deviation including both systematical (±1° rotation of each plate) and statistical errors (Poissonian distribution).
Next we shall give the strategy for constructing the inequalities, and then generalize Theorem 2 to the case of higher dimensions.
Strategy for the lower bound
As coordinates, all pairs  as defined above compose a set we call
as defined above compose a set we call  . We can release the specified definitions to view P′ and
. We can release the specified definitions to view P′ and  as free distributions. Then the pairs
as free distributions. Then the pairs  compose a 2(d − 1)-dimensional sub-manifold
compose a 2(d − 1)-dimensional sub-manifold  of the 2d-dimensional Euclid space (
of the 2d-dimensional Euclid space ( and
and  ). The exact bound of Errψ(A) + Disψ(B) is the minima of
). The exact bound of Errψ(A) + Disψ(B) is the minima of  over
over  . An analytical solution seems complicated to approach and shapes terrible because of the involved geometry of
. An analytical solution seems complicated to approach and shapes terrible because of the involved geometry of  embedding in
embedding in  . Instead, we define the set of pairs satisfying
. Instead, we define the set of pairs satisfying  as
as  . According to Horn’s theorem30, we have
. According to Horn’s theorem30, we have  and thus
and thus  by logic. Moreover, the point
by logic. Moreover, the point  is the unique extreme point of Errψ(A) + Disψ(B) in
is the unique extreme point of Errψ(A) + Disψ(B) in  such that its minima value over
such that its minima value over  must be obtained at the surface of
must be obtained at the surface of  . This surface consists of many faces, especially those defined by majorization. The geometry of
. This surface consists of many faces, especially those defined by majorization. The geometry of  is much simpler and analytical solution becomes reachable. So the strategy is to find the minima over
is much simpler and analytical solution becomes reachable. So the strategy is to find the minima over  . An illustration of this strategy for the case d = 2 is given in Fig. 4. The strategy also works for many other quantifications of the difference between probability distributions, aside from relative entropy.
. An illustration of this strategy for the case d = 2 is given in Fig. 4. The strategy also works for many other quantifications of the difference between probability distributions, aside from relative entropy.
 and
and  in
in  when d = 2.
when d = 2.
 is parameterized by
is parameterized by  and thus illustrated by the [0, 1] × [0, 1] square. We fix the labeling of eigenstates of A and B such that p1 ≥ p2 and q1 ≥ q2.
and thus illustrated by the [0, 1] × [0, 1] square. We fix the labeling of eigenstates of A and B such that p1 ≥ p2 and q1 ≥ q2.  is the pink region, it is a subset of
is the pink region, it is a subset of  that is contained in the yellow region. When the relative entropy is used to characterize the distance of probability distributions, it is sufficient to consider only the component with
that is contained in the yellow region. When the relative entropy is used to characterize the distance of probability distributions, it is sufficient to consider only the component with  and
and  . (a,b) show the details of that component when
. (a,b) show the details of that component when  and (p1, q1) equals to (0.727, 0.978) and (0.681, 0.882), respectively. The lower bound DJS(P, Q) is obtained on the blue points, which locate on the surface of
and (p1, q1) equals to (0.727, 0.978) and (0.681, 0.882), respectively. The lower bound DJS(P, Q) is obtained on the blue points, which locate on the surface of  . The line-chart illustrates the exact lower bound (red) of Errψ(A) + Disψ(B) and lower bound DJS(P, Q) (blue) determined by Theorem-2, when A = σz, B = σx, and
. The line-chart illustrates the exact lower bound (red) of Errψ(A) + Disψ(B) and lower bound DJS(P, Q) (blue) determined by Theorem-2, when A = σz, B = σx, and  with
with  such that
such that  . Here,
. Here,  and
and  .
.
Physically speaking, the strategy is equivalent to replacing the ideal measurements of B (in the part of sequential measurements in Fig. 1) with an imprecise apparatus performing projective measurements in a random basis denoted by  . Now
. Now  should be redefined as
should be redefined as  . With the help of Horn’s theorem30, the exact lower bound of
. With the help of Horn’s theorem30, the exact lower bound of  is just the minima of the original Errψ(A) + Disψ(B) over
is just the minima of the original Errψ(A) + Disψ(B) over  .
.
On the way to the bound, a new concept emerges as a natural extension of majorization.
Majorization by sections
If  , we cannot conclude that P is more certain than Q in the global sense. However if only certain outcomes are considered, things will be different. Let us relabel the eigenstates so that
, we cannot conclude that P is more certain than Q in the global sense. However if only certain outcomes are considered, things will be different. Let us relabel the eigenstates so that  and
and  , then cut the subscript string 1 ~ d into short sections
, then cut the subscript string 1 ~ d into short sections  ,
,  . For each section, say the t-th one, we find the probabilities according to the subscripts in this section and take their sum
. For each section, say the t-th one, we find the probabilities according to the subscripts in this section and take their sum  and
and  (j0 = 1, jk+1 = d). Then we say P majorizes Q by sections if the relation
(j0 = 1, jk+1 = d). Then we say P majorizes Q by sections if the relation

holds for all the short sections. (If some zero-valued probabilities vanish the denominator, take the limit from infinitesimal positive factors). Equation (4) says that P is relatively more certain than Q in each section. We use  to denote this relation where the index
to denote this relation where the index  labels this particular partition of the subscript string. In addition,
labels this particular partition of the subscript string. In addition,  and
and  are two distributions coarse-grained from P and Q by this partition.
are two distributions coarse-grained from P and Q by this partition.
Next, let us find all the coarsest partitions under which P majorizes Q by sections. We say a partition is coarser than another if the latter can be obtained from the former by additional cutting such as cutting (2 ~ 9) into (2 ~ 4) (5 ~ 9). (“ Coarser” defined in such a way is a partial order, we cannot say (1 ~ 5) (5 ~ 9) is coarser than (1 ~ 4) (4 ~ 7) (7 ~ 9)). Let us denote the set of all the coarsest partitions upon which P majorizes Q by sections as  . None of
. None of  can be obtained by further cutting from another section in it.
can be obtained by further cutting from another section in it.  is never an empty set since P will always majorize Q by sections for the finest partition where each short section consists of only one subscript. Then according to each partition in
is never an empty set since P will always majorize Q by sections for the finest partition where each short section consists of only one subscript. Then according to each partition in  (say, the one labeled by
(say, the one labeled by  ), we coarsen P and Q to obtain distributions
), we coarsen P and Q to obtain distributions  and
and  in the way given above. With these preparations, now we can present our tradeoff relation.
in the way given above. With these preparations, now we can present our tradeoff relation.
Theorem 3. Label the outcomes such that  and
and  . Then if
. Then if  , Errψ(A) = D(P ‖ P′) and
, Errψ(A) = D(P ‖ P′) and  , there is a tradeoff relation
, there is a tradeoff relation

where  is the Jensen-Shannon divergence. Moreover, DJS(P, Q) serves as the lower bound if
is the Jensen-Shannon divergence. Moreover, DJS(P, Q) serves as the lower bound if  and
and  for any possible partition
for any possible partition  .
.
Experiment
Being based on operational definitions, our theory can be experimentally tested in a straightforward manner. To compare, the reported experimental tests of Ozawa’s inequality (qubit cases) require the three state method or the technology of weak measurement11,12,13,14,15,16. These experimental configurations are out of the original physical picture thus not so direct34.
For single-photon experiments, a weak coherent state measured by single photon detectors is a good approximation to a true single-photon source35. Thus, as a photon source, we used a pulsed laser (with 788-nm central wavelength, 120-fs pulse width and 76-MHz repetition rate; Coherent Verdi-18/Mira-900F) and highly attenuate its mean photon number to ~0.004 at each pulse. For measurements, we can measure σz by two single-photon detectors after the polarizing beam splitter (PBS, extinction ratio >500), which transmits horizontal and reflects vertical polarizations (Fig. 2a). The σx measurement, which corresponds to the polarization measurement in the ±45° linear polarization basis, could be realized by inserting a half-wave plate (HWP) rotated at 22.5° before the PBS (Fig. 2b). The real-life measurements of A are actually measuring observables  , the direction
, the direction  is a unit vector. They are realized by a PBS which performs σz measurement, and groups of HWP and quarter-wave plate (QWP) that implement unitary rotations between the basis {|H〉, |V〉} and the eigenbasis of
is a unit vector. They are realized by a PBS which performs σz measurement, and groups of HWP and quarter-wave plate (QWP) that implement unitary rotations between the basis {|H〉, |V〉} and the eigenbasis of  (Fig. 2c). The ratio of the counts of D1 + D1’ and the total counts determines
(Fig. 2c). The ratio of the counts of D1 + D1’ and the total counts determines  , and
, and  is determined by the ratio of the counts of D1’ + D2 and the total counts. The distributions P′ and
is determined by the ratio of the counts of D1’ + D2 and the total counts. The distributions P′ and  are thus obtained.
are thus obtained.
In the experiment, a polarizer was used to prepare the photons in the state  with
with  . Therein, |H〉 and |V〉, the horizontal and vertical polarization states, are viewed as the eigenstates of σz, i.e., σz|H〉 = |H〉 and σz|V〉 = −|V〉. We calculated the optimal directions
. Therein, |H〉 and |V〉, the horizontal and vertical polarization states, are viewed as the eigenstates of σz, i.e., σz|H〉 = |H〉 and σz|V〉 = −|V〉. We calculated the optimal directions  so that the measurements of
so that the measurements of  could reach the minimal sum of Errψ(A) and Disψ(B), where
could reach the minimal sum of Errψ(A) and Disψ(B), where  . These directions are used to carry out the imprecise measurements of A of which the experimental results are illustrated in Fig. 3a. Theoretically, we have
. These directions are used to carry out the imprecise measurements of A of which the experimental results are illustrated in Fig. 3a. Theoretically, we have  when
when  and
and  when
when  . So there is no tradeoff in the first half θ-range by Theorem 1 and Theorem 2 covers the rest. Experimental results show great agreements with the predictions of the two theorems (see Fig. 3a, where the closeness of DJS(P, Q) is illustrated by comparing with the exact bound obtained by numerical calculations). The validity of the bound given by Theorem 2 is also tested with a randomly chosen state with parameter θ = 5/12π(75°). The real-life measurements of A are implemented by the measurements of
. So there is no tradeoff in the first half θ-range by Theorem 1 and Theorem 2 covers the rest. Experimental results show great agreements with the predictions of the two theorems (see Fig. 3a, where the closeness of DJS(P, Q) is illustrated by comparing with the exact bound obtained by numerical calculations). The validity of the bound given by Theorem 2 is also tested with a randomly chosen state with parameter θ = 5/12π(75°). The real-life measurements of A are implemented by the measurements of  . Thus Errψ(A) + Disψ(B) varies as a function of ϕ. As shown in Fig. 3b, experimental data clearly supports the theory.
. Thus Errψ(A) + Disψ(B) varies as a function of ϕ. As shown in Fig. 3b, experimental data clearly supports the theory.
Discussion
If we focus on a sub-system of a pure-state system, mixed input states must be taken into account. Now actually classical uncertainty is involved in. We show in the Methods that Theorem 2 and Theorem 3 are valid for all the mixed input states, and Theorem 1 is robust to depolarization noise, i.e., valid for at least the ensembles described by  with 0 ≤ η ≤ 1), as well as for all qubit states, pure or mixed. The validity of Theorem 1 in more general situations is still an open question. Additionally, we considered only projective measurements. The more general POVMs are realized from projective measurements on the enlarged systems. Correlation between the measured system and the ancillary established in the implementation of POVM, and the consequent information flow between them make the problem more complicated27. The state-dependent relation between error and disturbance thus still have rich structures to be discovered.
with 0 ≤ η ≤ 1), as well as for all qubit states, pure or mixed. The validity of Theorem 1 in more general situations is still an open question. Additionally, we considered only projective measurements. The more general POVMs are realized from projective measurements on the enlarged systems. Correlation between the measured system and the ancillary established in the implementation of POVM, and the consequent information flow between them make the problem more complicated27. The state-dependent relation between error and disturbance thus still have rich structures to be discovered.
For some state |ψ〉, if  we can find
we can find  so that Errψ(A) = Disψ(B) = 0. While, given this
so that Errψ(A) = Disψ(B) = 0. While, given this  , how many input states, mixed or pure, ensure zero-error and zero-disturbance? The d-dimensional quantum state ρ can be parameterized using a vector
, how many input states, mixed or pure, ensure zero-error and zero-disturbance? The d-dimensional quantum state ρ can be parameterized using a vector  so that
so that

where the generators of the Lie-algebra of group SU (d),  , satisfy tr(λiλj) = 2δij.
, satisfy tr(λiλj) = 2δij.  should satisfy some conditions to make ρ positive.
should satisfy some conditions to make ρ positive.  , |ai〉 and |bj〉 can also be represented in the same way (by
, |ai〉 and |bj〉 can also be represented in the same way (by  ,
,  , and
, and  , respectively). Then zero-error and zero-disturbance, i.e.,
, respectively). Then zero-error and zero-disturbance, i.e.,  and
and  , are described by
, are described by

This series contains 2(d − 1) independent equations while  has d2 − 1 coordinates. Therefore, the solution set of
has d2 − 1 coordinates. Therefore, the solution set of  has at most (d − 1)2 dimensions, and includes at least |ψ〉 and the mixed states
has at most (d − 1)2 dimensions, and includes at least |ψ〉 and the mixed states  .
.
To conclude, we have revealed the hidden effect of quantum uncertainty on the error-disturbance tradeoff. Our results also shed new light on overcoming problems engendered by the back-action of quantum measurements in fields such as quantum control, quantum metrology and measurement-based quantum information protocols36. We hope this work can inspire more research on quantum uncertainty and measurement.
Methods
Proof of theorem 1. The proposition that error and disturbance can be zero simultaneously is equivalent to the proposition that there is a unitary matrix which satisfies the following two conditions simultaneously:

Here we just need to show sufficiency. For B, we have the freedom to define the phases of its eigenstates  so that the state |ψ〉 can be written as
so that the state |ψ〉 can be written as

Then if  satisfies the above two condition, we have
satisfies the above two condition, we have

Then we will prove the existence of such a unitary with the premise  by mathematical induction. (Horn’s theorem states that the first condition has solutions if and only if
by mathematical induction. (Horn’s theorem states that the first condition has solutions if and only if  ). First, when d = 2, if
). First, when d = 2, if  (for convenience, we assume p1 > p2, the case p1 = p2 is trivial), the following unitary results
(for convenience, we assume p1 > p2, the case p1 = p2 is trivial), the following unitary results

Actually, we will get a second solution by taking −ϕ, −θ1 and −θ2 in the above matrix. Here, we do not require the normalization that  . Then we assume the validity of the cases where the dimension equals to d − 1.
. Then we assume the validity of the cases where the dimension equals to d − 1.
For d-dimensional cases, the first condition can be written as

where we use Diag to denote the diagonal matrix and  means a matrix whose diagonal elements are
means a matrix whose diagonal elements are  .
.
For convenience, we assume that  and q1 is the largest one in Q. There exists a subscript j such that
and q1 is the largest one in Q. There exists a subscript j such that

Then we have

For the first, majorization is valid since  . For the second majorization, when 2 ≤ k ≤ j − 1, since
. For the second majorization, when 2 ≤ k ≤ j − 1, since  , we have
, we have  ; when j ≤ k ≤ d − 1, we have
; when j ≤ k ≤ d − 1, we have  . Since
. Since  , the second majorization must be valid.
, the second majorization must be valid.
Then we have a unitary U1 that acts only on the subspace belonging to p1, pj, such that it changes the diagonal elements p1, pj to q1, p1 + pj − q1 and maps vector  . Next, according to our induction assumption, we have another unitary U2 acting on the subspace belonging to p2,
. Next, according to our induction assumption, we have another unitary U2 acting on the subspace belonging to p2,  that changes Diag
that changes Diag  to
to  and maps vector
and maps vector  to
to  . Then U1U2 is the unitary we want for the d-dimensional cases.
. Then U1U2 is the unitary we want for the d-dimensional cases.
Since we have two solutions when d = 2, it can be seen from the induction that generally 2d−1 solutions can be found.
Proof of Theorems 2 and 3. Theorem 2 is covered by Theorem 3, thus we give only the proof of the latter. For convenience, we make use of the freedom of relabeling to assume that  and the same applies for distributions Q. Then P′ and
and the same applies for distributions Q. Then P′ and  , which are also labeled by such an order, will give
, which are also labeled by such an order, will give  the smallest value.
the smallest value.
Lemma. If the probability distributions P and Q are sorted by the order that  and
and  , then among all ways of labeling the probabilities in P′ and
, then among all ways of labeling the probabilities in P′ and  , the one satisfying
, the one satisfying  and
and  gives the minima to
gives the minima to  . The proof is omitted here.
. The proof is omitted here.
Without loss of generality, we assume that elements in P and Q are all positive. For possible problems caused by zero elements, we can take the limit from infinitesimal positive factors. Consider the geometric surface of  in manifold
in manifold  . First, it is composed by (d!)2 symmetric components due to permutation. The above lemma tells us that we only need to consider the single component on which P′ and
. First, it is composed by (d!)2 symmetric components due to permutation. The above lemma tells us that we only need to consider the single component on which P′ and  are labeled in decreasing order. Such a component looks like a polytope with many faces and we only need to take the faces associated with the definition of majorization into account. (Faces associated with equations like
are labeled in decreasing order. Such a component looks like a polytope with many faces and we only need to take the faces associated with the definition of majorization into account. (Faces associated with equations like  or
or  points on them will give infinite value to the sum of error and disturbance, thus we do not need to care about them; other faces of the component associated with the decreasing order of labeling are not faces of
points on them will give infinite value to the sum of error and disturbance, thus we do not need to care about them; other faces of the component associated with the decreasing order of labeling are not faces of  ). Consider the following equations
). Consider the following equations

Now we use n to denote the dimension of the manifold, i.e., n = 2(d − 1). An (n − j)-dimension surfaces of  is produced by j equations of the above equation string, accompanied with the restriction that
is produced by j equations of the above equation string, accompanied with the restriction that  .
.
Now let us consider the minimum value on an (n − k)-dimension surface (j ranges from 1 to d − 1). The j equations cut the subscript string 1 ~ d into k + 1 sections that the sum of  and the sum of
and the sum of  within each subscript-section are equal. We use St to denote the different sections and define notations
within each subscript-section are equal. We use St to denote the different sections and define notations

do the same for the distributions P, Q and  . Then we use the Lagrange multiplier method to search for the extreme value:
. Then we use the Lagrange multiplier method to search for the extreme value:

where the equivalence in each section has already implies that  . Simple calculation shows that the minima is obtained on the point
. Simple calculation shows that the minima is obtained on the point

if the subscript “i” is in the t-th section where λp = 2 and  . To write down the minimum value, we define two distributions obtained from P, Q by coarse graining:
. To write down the minimum value, we define two distributions obtained from P, Q by coarse graining:

and an average of the two,  with elements
with elements  . Then the minimum value obtained from Eq. (18) is given by the Jensen-Shannon divergence,
. Then the minimum value obtained from Eq. (18) is given by the Jensen-Shannon divergence,  .
.
Now we have to check whether this point is located on the (n − j)-surface of  , i.e., whether
, i.e., whether  given by Eq. (18) satisfies the requirement that
given by Eq. (18) satisfies the requirement that  . Since
. Since  ,
,  if and only if P and Q satisfy the condition that within any section, such as St. After re-normalizing
if and only if P and Q satisfy the condition that within any section, such as St. After re-normalizing  and
and  to a common factor we must have
to a common factor we must have  in each section. More rigorously, suppose that section St has subscripts
in each section. More rigorously, suppose that section St has subscripts  , then
, then  if and only if Eq. (4) is valid for all these sections. This is the conception of “majorization by sections” introduced above.
if and only if Eq. (4) is valid for all these sections. This is the conception of “majorization by sections” introduced above.
If the above condition is not satisfied, the point defined by Eq. (18) locates outside of  so we should consider the edges of the (n − j)-dimensional surface, i.e., we should add another equation in Eq. (15) and study the (n − j − 1)-dimensional case. If the above condition is satisfied, a finer partition, i.e., adding extra equations in Eq. (15), will not bring a lower value.
so we should consider the edges of the (n − j)-dimensional surface, i.e., we should add another equation in Eq. (15) and study the (n − j − 1)-dimensional case. If the above condition is satisfied, a finer partition, i.e., adding extra equations in Eq. (15), will not bring a lower value.
So we have to find the family of all the coarsest partitions of the subscript string (anyone in this family is not a refinement of another one in it) under which P majorizes Q by sections. Then we calculate the Jensen-Shannon divergence corresponding to the partitions and the minimum is just the minimum over  . With the notations
. With the notations  , the above analysis leads to Theorem 3.
, the above analysis leads to Theorem 3.
One may wonder whether the solution given by Eq. (18) follows the order  and
and  . Actually, we do not need to care. This is because
. Actually, we do not need to care. This is because  ensures
ensures  such that the solution is in
such that the solution is in  . Thus all the values derived from
. Thus all the values derived from  can be reached in
can be reached in  , and meanwhile the real minima over
, and meanwhile the real minima over  must link with one partition in
must link with one partition in  . So the minimizing over
. So the minimizing over  will always give the minima we want.
will always give the minima we want.
The second part of Theorem 3, which gives the sufficient condition for the situations when DJS(P, Q) serves as the lower bound, can be checked straightforwardly. Theorem 2 is covered in this case.
Generalization to mixed input states
Mixed states emerge by statistically ignoring some sub-systems and losing some classical information, i.e., including classical uncertainty in the scenario. Theorem 3, inequality for the tradeoff, is still valid because the relation  holds for mixed input states. Actually one can do more analysis in
holds for mixed input states. Actually one can do more analysis in  to get a tighter bound, since P′ is also majorized by the string of eigenvalues of the input ρ. Other versions of Theorem 3 could be derived with other metrics of distance between probability distributions. The relative entropy could be infinity. One with finite upper bound can be utilized if someone wanted to derive a BLW-type theory from ours.
to get a tighter bound, since P′ is also majorized by the string of eigenvalues of the input ρ. Other versions of Theorem 3 could be derived with other metrics of distance between probability distributions. The relative entropy could be infinity. One with finite upper bound can be utilized if someone wanted to derive a BLW-type theory from ours.
As to Theorem 1, let us give it another proof for qubits. The density matrix of the input state, A, B and the observable of the real-life measurement OA, can be represented by four vectors  ,
,  ,
,  and
and  in Bloch sphere. The probability distributions have one to one correspondence with the inner products such as
in Bloch sphere. The probability distributions have one to one correspondence with the inner products such as  and
and  . They can be assumed to be positive due to the freedom of relabeling the eigenstates of A and B. Suppose the angle between
. They can be assumed to be positive due to the freedom of relabeling the eigenstates of A and B. Suppose the angle between  and
and  is θa and the angle between
is θa and the angle between  and
and  is θb. Now
is θb. Now  implies that θa ≤ θb.
implies that θa ≤ θb.  can be obtained by rotating
can be obtained by rotating  around
around  such that P′ = P. Thus the angle
such that P′ = P. Thus the angle  between
between  and
and  will range from θb − θa to θa + θb. Then there must be a case where we have
will range from θb − θa to θa + θb. Then there must be a case where we have  , which then leads to
, which then leads to  . It can be seen from the proof that what important is not the norm of
. It can be seen from the proof that what important is not the norm of  , but rather its direction and the inter-angles between the vectors representing |ψ〉,
, but rather its direction and the inter-angles between the vectors representing |ψ〉,  and |bj〉.
and |bj〉.
For higher dimensions, projectors of pure states can also be represented by coherent vectors as

We have proved Theorem 1 for pure states. Drawing an analogy with the qubit case, we conclude that Theorem 1 is valid for mixed states in the form of  , which have parallel but shorter coherent vectors compared with |ψ〉. In other words, Theorem 1 is robust under depolarization de-coherence. The validity of Theorem 1 for more general mixed states is still open.
, which have parallel but shorter coherent vectors compared with |ψ〉. In other words, Theorem 1 is robust under depolarization de-coherence. The validity of Theorem 1 for more general mixed states is still open.
Additional Information
How to cite this article: Zhang, Y.-X. et al. Quantum uncertainty switches on or off the error-disturbance tradeoff. Sci. Rep. 6, 26798; doi: 10.1038/srep26798 (2016).
References
Heisenberg, W. Über den anschaulichen inhalt der quantentheoretischen kinematik und mechanik. Z. Phys. 43, 172–198 (1927).
Feynman, R. P., Leighton, R. B. & Sands, M. L. The Feynman Lectures on Physics (Addison-Wesley, 1966).
Dirac, P. A. M. The Principle of Quantum Mechanics (Oxford University Press, 1930).
Kennard, E. H. Zur Quantenmechanik einfacher bewegungstypen. Z. Phys. 44, 326–352 (1927).
Robertson, H. P. The uncertainty principle. Phys. Rev. 34, 163–164 (1929).
Deutsch, D. Uncertainty in quantum measurements. Phys. Rev. Lett. 50, 631 (1983).
Maassen, H. & Uffink, J. B. M. Generalized entropic uncertainty relations. Phys. Rev. Lett. 60, 1103 (1988).
Wu, S., Yu, S. & Mølmer, K. Entropic uncertainty relation for mutually unbiased bases. Phys. Rev. A 79, 022104 (2009).
Liu, S., Mu, L.-Z. & Fan, H. Entropic uncertainty relations for multiple measurements. Phys. Rev. A 91, 042133 (2015).
Ozawa, M. Universally valid reformulation of the Heisenberg uncertainty principle on noise and disturbance in measurement. Phys. Rev. A 67, 042105 (2003).
Rozema, L. A. et al. Violation of Heisenberg’s measurement-disturbance relationship by weak measurements. Phys. Rev. Lett. 109, 100404 (2012).
Erhart, J. et al. Experimental demonstration of a universally valid error-disturbance uncertainty relation in spin measurements. Nat. Phys. 8, 185–189 (2012).
Ringbauer, M. et al. Experimental joint quantum measurements with minimum uncertainty. Phys. Rev. Lett. 112, 020401 (2014).
Kaneda, F., Baek, S.-Y., Ozawa, M. & Edamatsu, K. Experimental test of error-disturbance uncertainty relations by weak measurement. Phys. Rev. Lett. 112, 020402 (2014).
Baek, S.-Y., Kaneda, F., Ozawa, M. & Edamatsu, K. Experimental violation and reformulation of the Heisenberg’s error-disturbance. Sci. Rep. 3, 2221 (2013).
Sulyok, G. et al. Violation of Heisenberg’s error-disturbance uncertainty relation in neutron-spin measurements. Phys. Rev. A 88, 022110 (2013).
Ozawa, M. Disproving heisenberg’s error-disturbance relation. arXiv: 1308.3540 [quant-ph].
Rozema, L. A., Mahler, D. H., Hayat, A. & Steinberg, A. M. A note on different definitions of moment disturbance. arXiv: 1307.3604 [quant-ph].
Dressel, J. & Nori, F. Certainty in Heisenberg’s uncertainty principle: revisting definitions for estimation errors and disturbance. Phys. Rev. A 89, 022106 (2014).
Branciard, C. Error-tradeoff and error-disturbance relations for incompatible quantum measurements. Proc. Natl. Acad. Sci. USA 110, 6742 (2013).
Coles, P. J. & Furrer, F. Entropic formulation of heisenberg error-disturbance relation. arXiv: 1311. 7637 [quant-ph].
Busch, P., Lahti, P. & Werner, R. F. Measurement uncertainty-reply to critics. arXiv: 1402.3102 [quant-ph].
Busch, P., Lahti, P. & Werner, R. F. Noise operators and measures of RMS errors and disturbance in quantum mechanics. arXiv: 1312.4393 [quant-ph].
Busch, P., Lahti, P. & Werner, R. F. Heisenberg uncertainty for qubit measurements. Phys. Rev. A 89, 012129 (2014).
Busch, P., Lahti, P. & Werner, R. F. Proof of Heisenberg’s error-disturbance relation. Phys. Rev. Lett. 111, 160405 (2013).
Buscemi, F., Hall, M. J. W., Ozawa, M. & Wilde, M. M. Noise and disturbance in quantum measurements: an information-theoretic approach. Phys. Rev. Lett. 112, 050401 (2014).
Korzekwa, K., Jennings, D. & Rudolph, T. Operational constraints on state-dependent formulations of quantum error-disturbance trade-off relations. Phys. Rev. A 89, 052108 (2014);
Zurek, W. H. Pointer basis of quantum apparatus: into what mixture does the wave packet collapse? Phys. Rev. D 24, 1516 (1981).
Girolami, D., Tufarelli, T. & Adesso, G. Characterizing nonclassical correlations via local quantum uncertainty. Phys. Rev. Lett. 110, 240402 (2012).
Marshall, A. W., Ingram, O. & Arnold, B. C. Inequalities: Theory of Majorization and Its Applications, 2nd Edition, Springer Series in Statistics (Springer, New York, 2011).
Hardy, G. H., Littlewood, J. E. & Polya, G. Some simple inequalities satisfied by convex functions. Messenger Math. 58, 145–152 (1929).
Endres, D. M. & Schindelin, J. E. A new metric for probability distributions. IEEE Trans. Inf. Theory 49, 1858–1860 (2003).
Holevo, A. S. Information theoretical aspects of quantum measurements. Prob. Inf. Transmission USSR 9, 177–183 (1973).
Busch, P. & Stevens, N. Direct tests of measurement uncertainty relations: what it takes. Phys. Rev. Lett. 114, 070402 (2015).
Kok, P. & Lovett, B. W. Introduction to Optical Quantum Information Processing (Cambridge Univ. Press, 2010).
Wiseman, H. M. & Milburn, G. J. Quantum Measurements and Control (Cambridge Univ. Press, 2009).
Acknowledgements
We thank Zhihao Ma, Yutaka Shikano for discussions. This work was supported by the National Natural Science Foundation of China (Grants Nos 11305118, 11275181 and 61125502), the National Fundamental Research Program of China (Grant No. 2011CB921300), and the CAS.
Author information
Authors and Affiliations
Contributions
Y.-X.Z., Z.-E.S., X.Z., S.W. and Z.-B.C. designed the research, discussed the results and analyzed the data. Y.-X.Z. and X.Z. proved the theorems and did the theoretical analysis, Z.-E.S. and Y.-X.Z. performed the experiments and analyzed the experimental data. Y.-X.Z., S.W. and Z.-B.C. wrote the manuscript. All the authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Zhang, YX., Su, ZE., Zhu, X. et al. Quantum uncertainty switches on or off the error-disturbance tradeoff. Sci Rep 6, 26798 (2016). https://doi.org/10.1038/srep26798
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep26798
This article is cited by
-
Error tradeoff uncertainty relations for three observables
Quantum Information Processing (2024)
-
Disturbance-Disturbance uncertainty relation: The statistical distinguishability of quantum states determines disturbance
Scientific Reports (2018)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
