
Abstract
Dynamic metabolomics studies can provide a systematic view of the metabolic trajectory during disease development and drug treatment and reveal the nature of biological processes at metabolic level. To extract important information in a systematic time dimension rather than at isolated time points, a weighted method based on the means and variations along the time points was proposed and first applied to previously published rat model data. The method was subsequently extended and applied to prospective metabolomics data analysis of hepatocellular carcinoma (HCC). Permutation was employed for noise filtering and false discovery rate (FDR) was used for parameter optimization during the feature selection. Long-term elevated serum bile acids were identified as risk factors for HCC development.
Similar content being viewed by others


Introduction
Metabolomics is increasingly applied to studies of pathogenesis and biomarker identification1,2. Metabolomics aims to comprehensively monitor alterations at the metabolic level in response to endogenous or exogenous stimuli3 and link metabolic disruptions to biological mechanisms4. Because metabolism is a dynamic process, it is very important to monitor the dynamic responses of metabolites in response to disease development and drug administration. Coupled with systematic metabolomics investigations, time-series5,6 studies are increasingly recognized as advantageous in disease pathogenesis research, early diagnosis, personalized medicine and the elucidation of complex life processes.
Optional data processing methods for complex metabolomics time-course data are rare6. Most of algorithms were proposed for large sets of time-series data, while the number of time points in a metabolomics time-series study is often less than ten7. Short time series, together with large variables and small samples (characteristics of metabolomics data), render many classic data analysis methods unsuitable for metabolomics dynamic studies6,8.
Time-series data are frequently analyzed by static methods that do not consider their dynamic nature6. For example, three-dimensional data have been analyzed by means of PCA and PLS-DA, etc.9,10,11,12,13,14, without taking advantage of time information. Parallel factor analysis15 (PARAFAC) can resolve data with three or more dimensions and it can treat samples, features and time16 together to analyze overall metabolic trends. However, PARAFAC is a time-consuming process17 and the number of principal components chosen greatly influences the identification of physiologically relevant features18. Clustering algorithms are also applied to analyze time-series data19,20,21,22,23,24 to group the features according to their dynamic changes. Methods have been proposed to define important features by simulating the variable distribution or evaluating the smoothness of the variables at each time point25,26. To model short time series in metabolomics25, each observed time series is assumed to be a smooth random curve inferred by a functional data analysis approach. Berk et al.7 described a statistical framework for estimating time-varying metabolic data and used a functional test statistic to detect differences between groups. Trend analysis of time-series data27 is a method for untargeted metabolic feature discovery that employs two univariate methods: autocorrelation as a measure of the smoothness of non-random behavior and curve-fitting to analyze the compounds. Although these methods are compatible with short time-series datasets, each observed time series is assumed as a smooth random curve. However, when dealing with detailed time-series data where specific time points must be treated differently, corresponding data processing methods are needed.
Hepatocellular carcinoma (HCC) is one of the most lethal cancers28,29 and its incidence and mortality rates continue to increase30. However, the mechanism of hepatocarcinogenesis remains obscure because of the complicated interactions of multiple factors and individual genetic variations, impeding early clinical intervention before the development of HCC. Relatively effective treatments are available when HCC is diagnosed early. HCC patients often have a history of chronic liver diseases, leading to the introduction of screening programs among high-risk populations31, such as those infected with hepatitis virus B (HBV) in Qidong, China (a high-incidence area of HCC due to the high prevalence of HBV infection), who undergo HCC screening every half year. In addition, a sample library has been established in Qidong for HCC pathogenesis and early diagnosis studies32,33,34.
In this study, a weighted relative difference accumulation algorithm (wRDA) and its extended form were proposed. The wRDA method was first used to treat our previously published rat model data and its extended form was further applied to a prospective cohort study of HCC patients with the aim of revealing earlier HCC diagnosis biomarkers and metabolic dysregulations contributing to hepatocarcinogenesis.
Results
The application of the wRDA to metabolomics data from the rat HCC model
The proposed wRDA was first applied to our previously published data for a rat HCC model induced by diethylnitrosamine (DEN) administration35. In that study35, 52 differential metabolites were identified, of which three, taurocholic acid (TCA), lysophosphoethanolamine 16:0 (LPE 16:0) and lysophosphatidylcholine 22:5 (LPC 22:5), were defined as “marker metabolites” for distinguishing the different stages of chemical hepatocarcinogenesis. LPE 16:0 and TCA were more discriminative between the disease group and control group, whereas LPC 22:5 was more discriminative between the HCC and non-HCC samples.
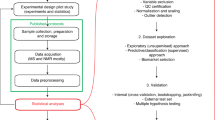
Parallel to our previous feature-defining process, a two-level data analysis procedure employing the wRDA (Fig. 1) was performed to select meaningful features to discriminate between the models and control and between HCC and non-HCC samples. In the first level, 152 ion features were removed by means of permutation, leaving 1092 features with a false discovery rate (FDR) of 0 to constitute feature subset 1. Then, Support Vector Machine36 (SVM) was conducted based on the top 20 features (Fig. 2A) ranked by the wRDA. Five fold cross validation was conducted 50 times. The average accuracy rate was 98.85% ± 0.66%, demonstrating that the top ranked variables have a strong ability to distinguish disease samples from controls. These metabolic features include two bile acids (TCA and tauroursodeoxycholic acid (TUDCA)), LPCs and LPEs with different acyl chains and unsaturation levels. These results indicate a disturbance of lipid metabolism in DEN-induced liver disease.

Flow chart of the analysis of the rat metabolomics data.

Top 20 features ranked by wRDA for discriminating liver diseases from healthy control (A) and HCC from non-HCC stages (B).
Redundant ions from the same compound are deleted. LPC: lysophosphatidylcholine, TCA: taurocholic acid, TUDCA: tauroursodeoxycholic acid, LPE: lysophosphatidylethanolamine.
In the second level, the features in feature subset 1 were analyzed again to calculate their ability to characterize the metabolic status of the three different liver diseases. Using the top 20 ranked variables (Fig. 2B), the average accuracy rate of the SVM classifier for discriminating HCC and non-HCC samples was 93.12% ± 1.92%, demonstrating that informative features can be defined by weighting the time points according to their importance (here the importance of the time points was decided according to prior knowledge). The combinations of these features can denote disease progression towards HCC.
To investigate the discrimination abilities of the top ranked 20 features defined by wRDA to distinguish the liver diseases from the controls, their receiver operator characteristic curves are further drawn with their area under curves (AUCs) calculated. Among 15 features (after deleting the redundant ions from the same metabolite), three features TUDCA, feature with m/z of 636.3415 and LPE 22:6 are found to have higher AUCs of 0.97, 0.97 and 0.96, respectively (Fig. S1) than that of TCA (0.94). And 12 features have larger AUCs than that of LPE 16:0 (0.88) except for LPC 20:4 and feature with m/z of 545.6404 (0.81 and 0.79, respectively). TUDCA, feature with m/z of 636.3415 and LPE 22:6 were not included in 52 differential metabolites defined by VIP > 2 in the analysis of PLS-DA in our previous work35. The Pearson correlation coefficients of TUDCA and feature with m/z of 636.3415 with TCA are 0.71 and 0.94, respectively. LPE 22:6 also has a high Pearson correlation coefficient with LPE 16:0 (0.80). For discriminating HCC from non-HCC, LPC 22:5 has the largest AUC (0.87). Because the top ranked features are related to bile acid and lipid metabolism disturbance which was discussed in our previous paper35, here further explanation is omitted. Collectively, the metabolic features derived from the rat model metabolomics data demonstrate the excellent performance of the wRDA in feature-ranking and demonstrate its potential in analyzing time-series metabolomics data.
The application of w2RDA in HCC prospective metabolomics data analysis
In this prospective cohort study, samples of 5 time points from 11 HCC cases were collected during screening over 3.5 years. The study aimed to identify prospective features of HCC, but the biological events in the other time points before HCC occurrence are unknown. Moreover, in contrast to animal model samples, the collection times of samples from patients in the same stage were not uniform. Therefore, parameter k was introduced into the wRDA to reduce the influence of sample storage time. The settings of ωi for each time point and kj for each sampling time affect the measurement of the features. To define the most suitable settings for ω and k, linear function, exponential function and proportional function were tested with different changing factors (equal weights were included as a special case of linear function). For n top-ranked features, the lowest FDR was adopted to evaluate the settings of k and ω. As shown in Table 1, when ω was an exponential function, the minimum values of the lowest FDR were obtained for each k's function setting. When k was also an exponential function, the minimum FDR values in each column were derived for the vast majority of different function settings of ω for n decreasing from 50 to 30. Furthermore, 194 k-ω pairs were derived from different functions and their corresponding changing factors, resulting in a low FDR of less than 5% (including 192 k-ω pairs with the lowest FDR equaling 0 at n = 30 and 2 k-ω pairs with the lowest FDR equaling 2.86% at n = 35). Among the 194 k-ω pairs, the probability of both ω and k being exponential was the highest (25.26%). Therefore, exponential function is more suitable for k and ω than other functions.
When k and ω were fixed as exponential functions, the lowest FDR was 0% at n = 30 and there were 47 paired values of changing factors for k and ω (Table S1). To minimize the weight differences among the sampling points, the smallest changing factor of k was chosen, qk = 0.5. Once k was selected, the smallest changing factor of ω was defined as qω = 0.6.
Under the optimized settings for k and ω, the features were ranked according to their w2RDA scores. The top 30 ranked variables (Table 2) were chosen as the most important metabolic features related to HCC development.
The most important variables were bile acids, with the exception of dihydroxyandrostenone sulfate and LPE 18:2. The serum concentrations of the primary bile acids cholic acid (CA) and chenodeoxycholic acid (CDCA) were significantly higher in the HCC group than in the control group (at T0) when malignant hepatic tumors were identified. Four other bile acids, the secondary bile acids deoxycholic acid (DCA) and taurodeoxycholic acid (TDCA) and the sulfated bile acids glycodeoxycholate sulfate (GDCAS) and glycochenodeoxycholate sulfate (GCDCAS), were also elevated in HCC sera compared to controls. When the serum levels of bile acids were compared over the entire monitoring time period, most were significantly elevated in patients in which HCC occurred compared to individuals that were hepatitis B surface antigen positive (HBsAg+), with the exception of hyodeoxycholic acid (HDCA) (Table 2). The relative serum levels of bile acids at each time point are shown in Fig. 3.

Relative content of serum bile acids in the HCC group compared to the HBsAg+ control group at paired time points.
T0: the stage at which patients were initially diagnosed with HCC. Serum samples collected every 6 months prior to T0 at T1 (half a year ago), T2 (one year ago), T3 (one and a half years ago), T4 (two years ago) were then identified. Abbreviations are the same as in Table 2. * indicates significance (p < 0.05).
Discussion
HCC usually develops from chronic liver diseases and a long time is required for the formation of malignant hepatic tumors. The mechanism underlying the occurrence and development of HCC remains to be elucidated.
Bile acids are synthesized in the liver and their functions are not limited to facilitating the absorption of lipids and lipid-soluble nutrients37,38 but also include acting as signaling molecules to regulate glucose and lipid metabolism39,40 and apoptosis41. Bile acids are detergents and are cytotoxic and their concentrations are tightly regulated under normal physiological conditions42,43. We previously demonstrated that glycocholic acid (GCA) and glycochenodeoxycholic acid (GCDCA) are elevated in hepatitis, cirrhosis and HCC accompanied by cirrhosis44. The serum levels of seven bile acids were quantitatively measured and compared among HCC patients without liver cirrhosis and hepatitis, HCC patients with liver cirrhosis and hepatitis, benign liver tumor patients with liver cirrhosis and hepatitis and healthy controls and elevated serum GCDCA, GCA and TCA levels and decreased serum CDCA levels were correlated with liver cirrhosis and hepatitis45. We previously demonstrated that conjugated GCA, GCDCA, TCA and taurochenodeoxycholic acid (TCDCA) are potential biomarkers of liver cirrhosis46.
Fasting serum levels of primary bile acids47 can be affected by enterohepatic circulation48, leading to intra-individual variations. Thus, multiple time points of circulating bile acids were compared together within the monitoring period instead of at a single time point. This comparison revealed that all bile acids except HDCA were significantly higher in HCC patients than in HBsAg+ controls. The more hydrophobic secondary bile acids DCA and lithocholic acid (LCA) have been reported to increase HCC risk49,50.
Activation of the YAP pathway was recently shown to be responsible for bile acid-dependent tumor promotion51. The development of spontaneous liver tumors in a Fxr-/- Shp-/- double-knockout (DKO) mouse model was employed in the study to produce chronically elevated bile acid levels, which enabled the study of the mechanism of hepatic malignant tumor promotion by long-term high circulating levels of the bile acids CA and CDCA in mice51. Compared to the HBsAg+ control group, serum CA, CDCA and DCA levels were slightly elevated in the HCC group during the two-year monitoring period and their glycine- and taurine-conjugated forms were elevated to a greater extent. Thus, the increased serum levels of bile acids may be due to leakage from damaged hepatic cells or the alteration of bile acid transfer protein activity52 rather than upregulation of bile acid synthesis. When more bile acids enter the blood, they may further intensify hepatic injury because of their cytotoxic nature and may simultaneously act as signaling molecules to promote hepatic tumor formation.
No differences in levels of ursodeoxycholic acid (UDCA), which has been reported to have protective effects53,54, were observed in HCC patients and HBsAg+ controls during the two years before or at HCC diagnosis, whereas levels of its taurine-conjugated form were slightly elevated in HCC patients. The sulfated bile acids GDCAS and GCDCAS were elevated in HCC patients during the two years prior to diagnosis. Sulfotransferase-2A1, which has been reported to be underexpressed in HCC tumor cells55, catalyzes the sulfation of bile acids for their elimination and detoxification56. Sulfotransferase activities have been reported to decrease with the severity of liver disease from steatosis to cirrhosis57. The long-term increase in sulfated bile acids in HCC patients may be due to their increased availability for sulfation rather than enhanced SULT2A1 activity.
Because chronic hepatitis and cirrhosis are typically precursors of HCC, in combination with the above evidence that bile acids promote hepatic tumor formation, it is reasonable to speculate that long-term high circulating bile acids are potential high-risk factors for HCC. TCA is elevated since week 6 in model rats treated with DEN compared to controls35. The 13 bile acids mentioned above were extracted from the DEN-induced rat HCC model data acquired in positive mode, which revealed that the 10 bile acids (CA, CDCA, DCA, GCA, GCDCA, glycodeoxycholic acid (GDCA), TCA, TCDCA, TDCA and tauroursodeoxycholic acid (TUDCA)) detected were elevated in sera in the model group compared to the control group since week 6 (Supplementary Fig. S2), coincident with the appearance of hepatic cell injury due to DEN treatment. It has been reported that 40% of HCC patients infected with HBV from Qidong have high exposures to aflatoxin B158. Although the mechanism of HCC pathogenesis may vary greatly because of different etiological agents, the common long-term elevated serum bile acids were observed before HCC occurrence. Collectively, it can be speculated that the elevated levels of circulating bile acids in chronic liver disease may play an important role in the process of malignant hepatic tumor formation in both humans infected with HBV and DEN-treated rats.
In this article, to identify discriminative metabolites that may reflect dynamic biochemical developments, a wRDA method based on the weighted mean and variance analysis along the time points was proposed. Rather than screening differentially expressed variables at isolated time points as in static methods, the wRDA can investigate variables comprehensively along all time points in feature selection. Moreover, weighting the time points emphasizes the influence of relevant, important time points by setting relatively larger corresponding weights and vice versa. Thus, high efficiency can be achieved in identifying the key differences between two groups along the entire time course.
The application of the wRDA to the rat metabolomics data demonstrated that it is an effective method for defining metabolic features that may be related to disease status. In the prospective cohort study, continuously high serum bile acid levels within a two-year monitoring time period were identified as risk factors for HCC development. The weights of the time points can be decided based on prior knowledge or optimized by the lowest FDR. Other functions and changing factors for weighting can be simulated and other optimization standards can be introduced in further studies. Collectively, our proposed method, by analyzing the weighted relative difference accumulation along the time dimension, effectively defines the features of dynamic metabolism related to disease development.
Methods
wRDA and its application to the rat liver disease model
wRDA
When analyzing the metabolomics time course data of two different groups, for simplicity, let C denote the control group and M denote the model group. Let Ti denote a time point, 0 ≤ i < N, where N is the number of the time points.
In bioinformatic data analysis, the method used to measure the discriminative ability of a feature among different groups is a key consideration. SAM59 scores the “relative difference” of a gene over repeated measurements according to the mean and the standard deviation. Based on the idea of “relative difference”, the wRDA considers the variations of the means along the time points to dynamically study the biological process and screen biomarkers that reflect differences between the two groups and characterize the development of the model group. A variable with a higher wRDA score is more discriminative between the two groups. The detailed principles of the wRDA are outlined as follows:
In metabolomics time-series studies, metabolites are measured at each time point. Because differences in metabolite levels in the two groups may occur in a process, the accumulation of distance between the mean values of a given feature f at all time points, D(f), reflects the discriminative ability of feature f:

where μC,f(i) and μM,f(i) are the mean values of feature f at time point i in the C and M groups, respectively and ωi represents the weight of time point i. Different time points may play different roles in the development of differences between the two groups, resulting in different weight settings. In particular, some time points may occur at typical stages for biological events and hence merit greater attention and relatively large weights.
Furthermore, the standard deviation is applied to enable a fair comparison among the discriminative abilities of features. Let

where σC,f(i) and σM,f(i) are the standard deviations of feature f at time point i in the C and M groups, respectively. Hence the “weighted relative difference accumulation” of a feature f between the C and M groups over all time points is calculated as wRDA(f):

ε is a small positive value introduced to moderate or regularize the wRDA score and potentially reduces the relative impact of small variances. In this study, ε was set to 0.005.
Data source for the rat liver disease model
Metabolomics dynamic data for the rat liver disease model35 were employed using the model obtained from the Shanghai Experimental Animal Centre. Serum samples were collected from two groups, control rats and rats with liver disease induced by DEN, every two weeks from week 6 to week 20. A total of 8 monitoring time points were obtained. In this animal model, the serial progression of hepatocarcinogenesis includes three disease stages: the inflammation stage (week 6–week 8), the cirrhosis stage (week 12–week 14) and the HCC stage (week 18–week 20). All samples at each time point were collected synchronously in this animal experiment.
The application of the wRDA to the rat liver disease model
The wRDA was first applied to the metabolomics data of the rat liver disease model. First, features whose values equaled zero in more than 20% of the samples60 at each time point were removed, leaving 1289 features. Then, outlier correction was conducted (a sample for feature f is an outlier if its value is beyond the range μ(f) ± 2σ(f), where μ(f) is the mean value of f and σ(f) is the standard deviation of f in the corresponding group13). Assuming that the feature followed a prior distribution, the outlier was replaced by a random selected sample value following this distribution.
To select the features reflecting the different developments between the two groups and define the features discriminating HCC samples from non-HCC samples, the wRDA was applied at two levels (Fig. 1).
(1) In the first level, to study the dynamic differences between the liver disease group and the control group, equal values of 1/8 were assigned to ω at all time points. The features defined together reflect the entire liver disease status of the model group from week 6 to week 20. Permutation was conducted 200 times to filter noise and non-informative features.
(2) At the second level, the wRDA was applied again to measure the variables in feature subset 1 (Fig. 1) and the weights (ω) of three time points, week 6, week 12 and week 18, which were defined as the typical stages of hepatitis, cirrhosis and liver cancer, were set to 0.3, 0.3 and 0.4, respectively. The stage at which liver malignant tumors occur is the most important and merits greater attention, as reflected by a larger weight. The weights (ω) of the other time points were set to zero. The weight adjustment allowed the most informative features characterizing the three different liver diseases to be targeted, particularly those capable of distinguishing HCC from non-HCC.
w2RDA and its application in the HCC prospective cohort study
w2RDA
In epidemiological screening, people with high risk are checked at certain time intervals. One time point may lie in the onset stage of a disease or a malignant tumor and other time points may be a certain time interval before or after the key biological event. However, not all patients with a disease or a malignant tumor were spot at a uniform screening period and thus samples at each disease stage may be collected at different sampling times. To measure the features more accurately, a weight k for different sampling times was introduced:


where pi is the number of the sampling times at time point i; μC,f(i, j) and μM,f(i, j) are the average levels of feature f at the sampling time j of the ith time point in the C and M groups, respectively; and kj is the weight of the jth sampling time. The extended standard deviation by considering the sampling time differences at each time point is defined as follows:

where σC,f(i.j) and σM,f(i,j) are the standard deviations of feature f at the sampling time j of the ith time point in the C and M groups, respectively.
HCC prospective cohort study and data collection
Serum specimens were obtained from a prospective cohort in Qidong, Jiangsu Province, China. From May 2009 to October 2012, residents of the Qidong area were invited for a health examination as part of the HCC screening study. Table 3 shows the baseline characteristics of the enrolled HCC and HbsAg+ control subjects. Each participant underwent serological hepatitis tests (HBsAg, hepatitis B e antigen (HBeAg), anti-hepatitis C virus (HCV)), abdominal ultrasonography (US), serum alpha-fetoprotein (AFP) and alanine aminotransferase (ALT) tests at approximately six-month intervals. If an individual had abnormal results from US or higher AFP levels (greater than 20 ng/mL), then intensive surveillance by computed tomography (CT), magnetic resonance imaging (MRI), and/or hepatic angiography were employed to identify the space-occupying lesion. In total, 11 HCC cases were identified in a 3.5-year screening period. Their serum samples at the time of HCC diagnosis and samples within the 2 years preceding the initial HCC diagnosis were selected for analysis. Another 22 HBsAg+ individuals were taken as a positive controls with matched age, sex, sample collection time points and storage conditions (−20°C). The details of serum sample preparation, liquid chromatography-mass spectrometry (LC-MS)-based metabolic profiling and data preprocessing are available in the supplementary material.
The application of the w2RDA in the HCC prospective cohort study
For simplicity, the HCC and HBsAg+ control groups are also denoted as M and C, respectively. T0j, T1j, T2j, T3j and T4j (Fig. 4) are used to mark each stage (time points). T0j represents the stage when HCC was diagnosed, whereas T1j, T2j, T3j and T4j represent the stages 0.5, 1, 1.5 and 2 years before T0j, respectively. HCC patients were identified from the participants at four screening periods in this study; thus there are four sampling times for each stage (Fig. 4). Taking the T0j stage as an example, patients were diagnosed with liver cancer in May 2011, Nov. 2011, May 2012 and Oct. 2012. The corresponding serum samples at 6 months, 12 months, 18 months and 24 months prior to HCC diagnosis were then collected. The longest time interval of the samples at each stage from different sampling times was 1.5 years. Therefore, the w2RDA was applied to further consider the possible influence of different sampling times.

Sampling for HCC and HBsAg+ control groups from May 2009 to October 2012.
T0: the stage at which patients were initially diagnosed with HCC. Serum samples were collected every 6 months prior to T0 at T1j (half a year ago), T2j (one year ago), T3j (one and a half years ago) and T4j (two years ago).
The aim of the Qidong cohort study was to identify prospective features related to the occurrence of HCC. The settings of the weights ω and k could affect the feature measurement of w2RDA. T0j is the onset stage of HCC and therefore is the most important. The closer the other time points are to T0j, the more similar their metabolic characteristics are to those of HCC. Hence, for ω (and k), three different setting methods were tested: a linear function, a proportional function and an exponential function. FDR59,61 was adopted to evaluate the results under different weight settings. For the linear function ωi = 1.0 + (N-i-1)q, 0 ≤ i < N, q is a parameter factor. When q = 0, all time points have the same weight. For the proportional function ωi = (1.0 + q)(N-i-1), 0 ≤ i < N. Many metabolomics experiments use natural exponential functions to estimate time-varying profiles6; in this case, ωi = e (N-i−1)q, 0 ≤ i < N. In the latter two functions, q is also a changing factor. In the Qidong cohort study, to consider the influences of all the monitoring time points on metabolism, the differences of ωi should not be too large. q was restricted from 0.1 to 1.0 and was tested with a step increment of 0.1. In addition, T0j is the most important stage when malignant hepatic tumors are discovered and thus its weight should be larger than those of the others. Similarly, the weight k was also tested using a linear function, proportional function and exponential function. The sample with the shortest storage time should have the greatest weight.
References
Kim, K. et al. Urine Metabolomic Analysis Identifies Potential Biomarkers and Pathogenic Pathways in Kidney Cancer. Omics 15, 293–303 (2011).
Caudle, W. M., Bammler, T. K., Lin, Y., Pan, S. & Zhang, J. Using 'omics' to define pathogenesis and biomarkers of Parkinson's disease. Expert Rev. Neurother 10, 925–942 (2010).
Nicholson, J. K., Connelly, J., Lindon, J. C. & Holmes, E. Metabonomics: a platform for studying drug toxicity and gene function. Nat. Rev. Drug Discov. 1, 153–161 (2002).
Patti, G. J., Yanes, O. & Siuzdak, G. Innovation: Metabolomics: the apogee of the omics trilogy. Nat. Rev. Mol. Cell Biol. 13, 263–269 (2012).
Fu, T.-c. A review on time series data mining. Eng. Appl. Artif. Intell. 24, 164–181 (2011).
Smilde, A. et al. Dynamic metabolomic data analysis: a tutorial review. Metabolomics 6, 3–17 (2010).
Berk, M., Ebbels, T. & Montana, G. A statistical framework for biomarker discovery in metabolomic time course data. Bioinformatics 27, 1979–1985 (2011).
Ghandhi, S. A., Sinha, A., Markatou, M. & Amundson, S. A. Time-series clustering of gene expression in irradiated and bystander fibroblasts: an application of FBPA clustering. BMC Genomics, 10.1186/1471-2164-12-2 (2011).
Spegel, P. et al. Time-resolved metabolomics analysis of beta-cells implicates the pentose phosphate pathway in the control of insulin release. Biochem. J. 450, 595–605 (2013).
Rantalainen, M. et al. Piecewise multivariate modelling of sequential metabolic profiling data. BMC bioinformatics 9 10.1186/1471-2105-9-105 (2008).
Keun, H. C. et al. Geometric trajectory analysis of metabolic responses to toxicity can define treatment specific profiles. Chem. Res. Toxicol. 17, 579–587 (2004).
de Haan, J. R. et al. Interpretation of ANOVA models for microarray data using PCA. Bioinformatics 23, 184–190 (2007).
Sun, X. & Weckwerth, W. COVAIN: a toolbox for uni-and multivariate statistics, time-series and correlation network analysis and inverse estimation of the differential Jacobian from metabolomics covariance data. Metabolomics 8, 81–93 (2012).
Pan, L. et al. An optimized procedure for metabonomic analysis of rat liver tissue using gas chromatography/time-of-flight mass spectrometry. J. Pharm. Biomed. Anal. 52, 589–596 (2010).
Harshman, R. A. & Lundy, M. E. PARAFAC: Parallel factor analysis. Computational Statistics & Data Analysis 18, 39–72 (1994).
Rubingh, C. M. et al. Analyzing Longitudinal Microbial Metabolomics Data. J. Proteome Res. 8, 4319–4327 (2009).
Kiers, H. A. L. A three-step algorithm for CANDECOMP/PARAFAC analysis of large data sets with multicollinearity. J. Chemom. 12, 155–171 (1998).
Jiang, J. H., Wu, H. L., Li, Y. & Yu, R. Q. Three-way data resolution by alternating slice-wise diagonalization (ASD) method. J. Chemom. 14, 15–36 (2000).
Wang, K., Ng, S. K. & McLachlan, G. J. Clustering of time-course gene expression profiles using normal mixture models with autoregressive random effects. BMC bioinformatics 13 10.1186/1471-2105-13-300 (2012).
Inoue, L. Y. T., Neira, M., Nelson, C., Gleave, M. & Etzioni, R. Cluster-based network model for time-course gene expression data. Biostatistics 8, 507–525 (2007).
Wang, J., Liu, P., She, M. F. H., Nahavandi, S. & Kouzani, A. Biomedical time series clustering based on non-negative sparse coding and probabilistic topic model. Comput. Methods Programs Biomed. 111, 629–641 (2013).
Wu, F.-X., Zhang, W. J. & Kusalik, A. J. Dynamic model-based clustering for time-course gene expression data. J. Bioinform. Comput. Biol. 3, 821–836 (2005).
Son, Y. S. & Baek, J. A modified correlation coefficient based similarity measure for clustering time-course gene expression data. Pattern Recognit. Lett. 29, 232–242 (2008).
Ernst, J., Nau, G. J. & Bar-Joseph, Z. Clustering short time series gene expression data. Bioinformatics 21Suppl 1, i159–168 (2005).
Montana, G., Berk, M. & Ebbels, T. Modelling Short Time Series in Metabolomics: A Functional Data Analysis Approach. Adv. Exp. Med. Biol 696, 307–315 (2011).
Peters, S., Janssen, H.-G. & Vivo-Truyols, G. Untargeted metabolite discovery in kinetic data from multi-dose intervention studies. J. Chromatogr. A 1218, 3337–3344 (2011).
Peters, S., Janssen, H. G. & Vivo-Truyols, G. Trend analysis of time-series data: A novel method for untargeted metabolite discovery. Anal. Chim. Acta. 663, 98–104 (2010).
Venook, A. P., Papandreou, C., Furuse, J. & de Guevara, L. L. The incidence and epidemiology of hepatocellular carcinoma: a global and regional perspective. Oncologist 15 Suppl 4, 5–13 (2010).
Farazi, P. A. & DePinho, R. A. Hepatocellular carcinoma pathogenesis: from genes to environment. Nat. Rev. Cancer 6, 674–687 (2006).
Altekruse, S. F., McGlynn, K. A. & Reichman, M. E. Hepatocellular carcinoma incidence, mortality and survival trends in the United States from 1975 to 2005. J. Clin. Oncol. 27, 1485–1491 (2009).
Lencioni, R., Chen, X. P., Dagher, L. & Venook, A. P. Treatment of intermediate/advanced hepatocellular carcinoma in the clinic: how can outcomes be improved? Oncologist 15 Suppl 4, 42–52 (2010).
Qu, L. S. et al. Pre-S Deletion and Complex Mutations of Hepatitis B Virus Related to Young Age Hepatocellular Carcinoma in Qidong, China. Plos One 8, e59583 (2013).
Munoz, A. et al. Predictive power of hepatitis B 1762(T)/1764(A) mutations in plasma for hepatocellular carcinoma risk in Qidong, China. Carcinogenesis 32, 860–865 (2011).
Jackson, P. E. et al. Prospective detection of codon 249 mutations in plasma of hepatocellular carcinoma patients. Carcinogenesis 24, 1657–1663 (2003).
Tan, Y. et al. Metabolomics study of stepwise hepatocarcinogenesis from the model rats to patients: potential biomarkers effective for small hepatocellular carcinoma diagnosis. Mol. Cell. Proteomics. 11, M111. 010694 (2012).
Cortes, C. & Vapnik, V. Support vector machine. Machine learning 20, 273–297 (1995).
Hofmann, A. F. Bile acids, cholesterol, gallstone calcification and the enterohepatic circulation of bilirubin. Gastroenterology 116, 1276–1277 (1999).
Russell, D. W. The enzymes, regulation and genetics of bile acid synthesis. Annu. Rev. Biochem. 72, 137–174 (2003).
Hylemon, P. B. et al. Bile acids as regulatory molecules. J. Lipid Res. 50, 1509–1520 (2009).
Li, T. & Chiang, J. Y. Bile Acid signaling in liver metabolism and diseases. J. Lipids. 2012, 754067 (2012).
Amaral, J. D., Viana, R. J., Ramalho, R. M., Steer, C. J. & Rodrigues, C. M. Bile acids: regulation of apoptosis by ursodeoxycholic acid. J. Lipid Res. 50, 1721–1734 (2009).
Kim, I. et al. Differential regulation of bile acid homeostasis by the farnesoid X receptor in liver and intestine. J. Lipid Res. 48, 2664–2672 (2007).
Goodwin, B. et al. A regulatory cascade of the nuclear receptors FXR, SHP-1 and LRH-1 represses bile acid biosynthesis. Mol. cell 6, 517–526 (2000).
Zhou, L. N. et al. Serum metabolomics reveals the deregulation of fatty acids metabolism in hepatocellular carcinoma and chronic liver diseases. Anal. Bioanal. Chem. 403, 203–213 (2012).
Chen, T. L. et al. Serum and Urine Metabolite Profiling Reveals Potential Biomarkers of Human Hepatocellular Carcinoma. Mol. Cell. Proteomics 10, 1280–1289 (2011).
Yin, P. Y. et al. A metabonomic study of hepatitis B-induced liver cirrhosis and hepatocellular carcinoma by using RP-LC and HILIC coupled with mass spectrometry. Mol. Biosyst. 5, 868–876 (2009).
Ponz De Leon, M., Murphy, G. M. & Dowling, R. H. Physiological factors influencing serum bile acid levels. Gut 19, 32–39 (1978).
Angelin, B., Bjokhem, I. & Einarsson, K. Individual serum bile acid concentrations in normo- and hyperlipoproteinemia as determined by mass fragmentography: relation to bile acid pool size. J. Lipid Res. 19, 527–537 (1978).
Kitazawa, S. et al. Enhanced Preneoplastic Liver Lesion Development under Selection Pressure Conditions after Administration of Deoxycholic or Lithocholic Acid in the Initiation Phase in Rats. Carcinogenesis 11, 1323–1328 (1990).
Tsuda, H. et al. Positive Influence of Dietary Deoxycholic-Acid on Development of Pre-Neoplastic Lesions Initiated by N-Methyl-N-Nitrosourea in Rat-Liver. Carcinogenesis 9, 1103–1105 (1988).
Anakk, S. et al. Bile Acids Activate YAP to Promote Liver Carcinogenesis. Cell Rep. 5, 1060–1069 (2013).
Tanaka, N., Matsubara, T., Krausz, K. W., Patterson, A. D. & Gonzalez, F. J. Disruption of phospholipid and bile acid homeostasis in mice with nonalcoholic steatohepatitis. Hepatology 56, 118–129 (2012).
Takano, S. et al. A Multicenter Randomized Controlled Dose Study of Ursodeoxycholic Acid for Chronic Hepatitis-C. Hepatology 20, 558–564 (1994).
Oyama, K., Shiota, G., Ito, H., Murawaki, Y. & Kawasaki, H. Reduction of hepatocarcinogenesis by ursodeoxycholic acid in rats. Carcinogenesis 23, 885–892 (2002).
Huang, L. R., Coughtrie, M. W. H. & Hsu, H. C. Down-regulation of dehydroepiandrosterone sulfotransferase gene in human hepatocellular carcinoma. Mol. Cell Endocrinol. 231, 87–94 (2005).
Alnouti, Y. Bile Acid Sulfation: A Pathway of Bile Acid Elimination and Detoxification. Toxicol. Sci. 108, 225–246 (2009).
Yalcin, E. B. et al. Downregulation of Sulfotransferase Expression and Activity in Diseased Human Livers. Drug Metab. Dispos. 41, 1642–1650 (2013).
Ming, L. et al. Dominant role of hepatitis B virus and cofactor role of aflatoxin in hepatocarcinogenesis in Qidong, China. Hepatology 36, 1214–1220 (2002).
Tusher, V. G., Tibshirani, R. & Chu, G. Significance analysis of microarrays applied to the ionizing radiation response. Proc. Natl. Acad. Sci. U S A. 98, 5116–5121 (2001).
Smilde, A. K., van der Werf, M. J., Bijlsma, S., van der Werff-van der Vat, B. J. & Jellema, R. H. Fusion of mass spectrometry-based metabolomics data. Anal. chem. 77, 6729–6736 (2005).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Series B Stat. Methodol. 57, 289–300 (1995).
Acknowledgements
The study has been supported by the State Key Science & Technology Project for Infectious Diseases (2012ZX10002011), National Natural Science Foundation of China (21375011) and the Sino-German Center for Research Promotion (GZ 753).
Author information
Authors and Affiliations
Contributions
W.Z., L.Z. and P.Y. researched data, wrote the manuscript; J.W., J.C., X.L. and X.W. contributed to the clinical sample organization and discussion; X.L. and G.X. contributed to discussion, reviewed/edited the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Supplementary Information
Supplementary materials
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article's Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder in order to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Zhang, W., Zhou, L., Yin, P. et al. A weighted relative difference accumulation algorithm for dynamic metabolomics data: long-term elevated bile acids are risk factors for hepatocellular carcinoma. Sci Rep 5, 8984 (2015). https://doi.org/10.1038/srep08984
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep08984
This article is cited by
-
Time-dependent metabolomics uncover dynamic metabolic adaptions in MCF-7 cells exposed to bisphenol A
Frontiers of Environmental Science & Engineering (2023)
-
The role of bile acids in carcinogenesis
Cellular and Molecular Life Sciences (2022)
-
Causal effects of gallstone disease on risk of gastrointestinal cancer in Chinese
British Journal of Cancer (2021)
-
Farnesoid X receptor antagonizes Wnt/β-catenin signaling in colorectal tumorigenesis
Cell Death & Disease (2020)
-
Tsumura-Suzuki obese diabetic mice-derived hepatic tumors closely resemble human hepatocellular carcinomas in metabolism-related genes expression and bile acid accumulation
Hepatology International (2018)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
