
Abstract
Networks in nature are often formed within a spatial domain in a dynamical manner, gaining links and nodes as they develop over time. Motivated by the growth and development of neuronal networks, we propose a class of spatially-based growing network models and investigate the resulting statistical network properties as a function of the dimension and topology of the space in which the networks are embedded. In particular, we consider two models in which nodes are placed one by one in random locations in space, with each such placement followed by configuration relaxation toward uniform node density and connection of the new node with spatially nearby nodes. We find that such growth processes naturally result in networks with small-world features, including a short characteristic path length and nonzero clustering. We find no qualitative differences in these properties for two different topologies and we suggest that results for these properties may not depend strongly on the topology of the embedding space. The results do depend strongly on dimension and higher-dimensional spaces result in shorter path lengths but less clustering.
Similar content being viewed by others


Introduction
One fascinating property of many real-world networks is that they are often “small worlds” in the sense that they are sparsely connected, but nonetheless have both short average path length and high clustering1,2,3. The shortest path length between two nodes is the smallest number of links in the path connecting that pair of nodes and the average path length is the average of this value over all node pairs in the network. It is regarded as short if it grows very slowly with network size. To quantify the clustering of an undirected network, we use the clustering coefficient, which is defined as three times the number of triangles in the network divided by the number of link pairs that share a common node4. In networks with high clustering, if two nodes are both neighbors of a third node, they are also likely to be connected to one another. A variety of real-world networks exhibit the small-world property and this has fundamental consequences for dynamical processes such as spread of information or disease2.
Networks with spatial constraints typically have short-range edges and it is thus relevant that both the original Watts-Strogatz small-world model2 and many real networks with the small-world property are embedded in physical space. (Here and throughout, we will use the terms “distance” or “spatial distance” to refer to physical distances in such spaces, reserving the terms “length” and “path length” for the number of hops between two nodes along network edges.) For example, the Internet, a network of routers connected via cables, is essentially embedded on the two-dimensional surface of the Earth and tends to have mostly local links, presumably due to the cost of wiring5. This has led many researchers to consider network models with spatial embedding6,7,8,9,10,11,12,13,14,15. Work on this topic has shown that small-world properties are found in a variety of spatially embedded networks, including social networks and transportation networks2,16.
Two other key aspects of many real-world networks are that they grow with time (new nodes are added) and that nodes may move in space. For example, new people may join social networks with time and friendships typically form between people who live near one another, but people may also move to new locations. Although some studies have considered dynamically growing networks, they frequently assume that nodes remain fixed in their initial positions7,9,10 or consider growing networks that are not embedded in space17,18.
One case of particular interest is networks of neurons, which grow both in number of neurons and in physical size during the development of an organism. It has been proposed that networks of cortical neurons are small worlds, based on experimental results that identify connections between different functional areas of the brain (i.e., macroscopic groups of physically contiguous neurons with similar behavior)2,19,20. These findings have recently been contested by improved experimental techniques that show that the network of connections between functional areas is very dense21,22. However, it is still an open question whether the full, microscopic network of connections between neurons is small-world. Here, we study models that may have some important features in common with newly forming networks of neurons (the addition of new nodes, local edge formation and approximately uniform density over time). We find that these features lead naturally to small-world networks, although it remains to be seen whether these features, or the small-world property, are shared by complete microscopic neuronal networks.
In Ref. 6, Ozik et al. considered a model which incorporated both a growing number of nodes and node movement. In this model, nodes are placed randomly on the circumference of a circle, but undergo small displacements to maintain a constant density over time. Each node initially forms links only to its nearest neighbors, but, due to growth, these links can subsequently be “stretched” in the sense that they bypass many nodes along the circumference of the circle. Due to the emergence of these long-range links, this model also generates networks with the small-world property, but in this case it is a consequence of the growth process, rather than the spontaneous formation of long-range edges. However, since the physical properties of typical spatial systems typically depend on the dimension of the embedding space, the main limitation of Ref. 6 is that only a one-dimensional space (the circle) is treated. Thus, in this paper, we generalize the model of Ref. 6 by introducing and analyzing a class of growing undirected network models that have spatially constrained nodes able to move about in an embedding space of arbitrary dimension. (We note that, for real applications, dimensions two and three are commonly most relevant.)
Methods
The Circle Network Model
In Ref. 6, the authors presented a model, henceforth referred to as the Circle Network Model, which considers an undirected network which initially has m + 1 uniformly separated, all-to-all connected nodes on the circumference of a circle. It has been shown that this growth model leads to a small-world network with an exponentially decaying degree distribution6. At each discrete growth step the network is grown according to the following rules:
-
1
A new node is placed at a randomly selected point on the circumference of the circle.
-
2
The new node is linked to its m nearest neighbors (m is even in Ref. 6).
-
3
Preserving node positional ordering, the nodes are repositioned to make the nearest-neighbor distances uniform.
-
4
Steps (1–3) are repeated until the network has N nodes.
This procedure may be imagined as a toy model for the formation of a neuronal tissue in the following way. Step 1 corresponds to the division of an existing cell (since the existing cells are distributed approximately uniformly). Step 2 is the simplest possible model of the formation of local edges by the new neuron21. As the tissue grows, neurons will be gradually pushed apart, but remain at an approximately uniform density, corresponding to Step 3. Note that, as mentioned above, the main limitation of this model is that the space (a circle) is one-dimensional.
We define a network growth procedure to yield the small-world property if, as N → ∞, (i) the average degree 〈k〉 of a node approaches a finite value; (ii) the characteristic graph path length ℓ, the average value of the smallest number of links in a path joining a pair of randomly chosen nodes, does not grow with N faster than logN, as in an Erdös-Rényi random network4,23; and (iii) the clustering coefficient C, the fraction of connected network triples which are also triangles, approaches a nonzero constant with increasing N. (In6 an alternate definition of the clustering coefficient was used. Specifically, the local clustering Ci of each node i is  , where qi is the number of links between the ki neighbors of node i and the global network clustering is the average of Ci over i.) The circle network model exhibits all three properties.
, where qi is the number of links between the ki neighbors of node i and the global network clustering is the average of Ci over i.) The circle network model exhibits all three properties.
Degree distribution
The degree distribution H(k) is the probability that a randomly selected node has k network connections. For large N, the degree distribution of the circle network model approaches

for k ≥ m and H(k) = 0 for k < m6. Since the number of new links added each time a new node is added is m, Eq. (1) yields the result that the average node degree 〈k〉 is 2m, satisfying the criterion (i) for the small-world property.
Characteristic path length
In the circle network model, simulation results show that ℓ ~ logN, satisfying criterion (ii). This may be explained intuitively by noting that as new nodes are added, they push apart the older connected nodes, increasing the spatial distance traversed by older edges. These older links dramatically decrease the shortest path length between any given pair of nodes.
Clustering coefficient
For the circle network model, it was shown that the clustering coefficient approaches a constant, positive, m-dependent value as N → ∞, satisfying criterion (iii).
Generalizing the Circle Network Model
Like the Watts-Strogatz model, the circle network model may be described as a one-dimensional ring model in which connections are initially formed with m nearest neighbors. However, in the circle network model, long-distance edges do not form spontaneously, but are a natural result of the dynamics of network growth. Moreover, the circle network model naturally raises the question of whether networks grown in higher-dimensional spaces exhibit similar properties. A primary goal of this article is to address this question.
In what follows, we introduce two models that generalize the model of Ref. 6 to higher dimensionality and then present our results from analysis of these models. Our main results are as follows.
-
i
The coupling of network growth with local spatial attachment leads to small-world networks independent of the dimension of the underlying space.
-
ii
The nodal degree distribution (Fig. 1) and age-degree relationship (Fig. 2) are independent of dimension as in (i).
Figure 1 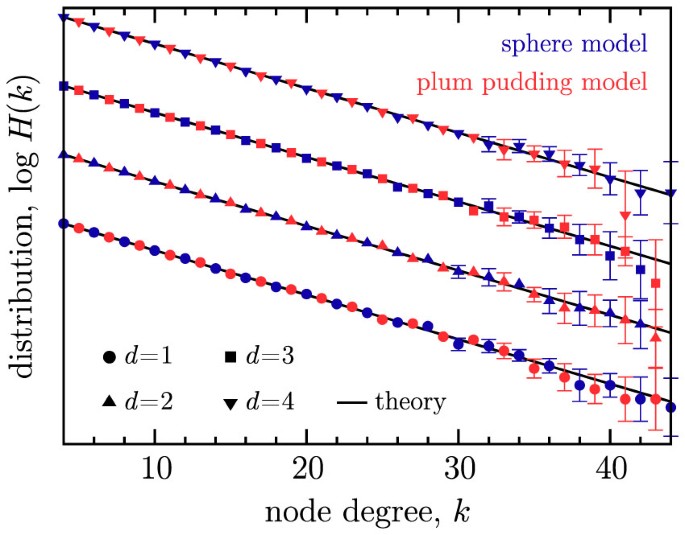
The logarithm of the degree distribution, log(H (k)), versus degree k, for the sphere network model (blue markers) and the plum pudding model (red markers), using N = 104 and m = 4.
Data are shown for d = 1 (circles), d = 2 (triangles), d = 3 (squares) and d = 4 (inverted triangles). Since all four cases have nearly identical results, an arbitrary linear offset has been used to separate data for visualization. Error bars are shown when they exceed the point size. Solid black lines correspond to the theoretical prediction of Eq. (1).
Figure 2 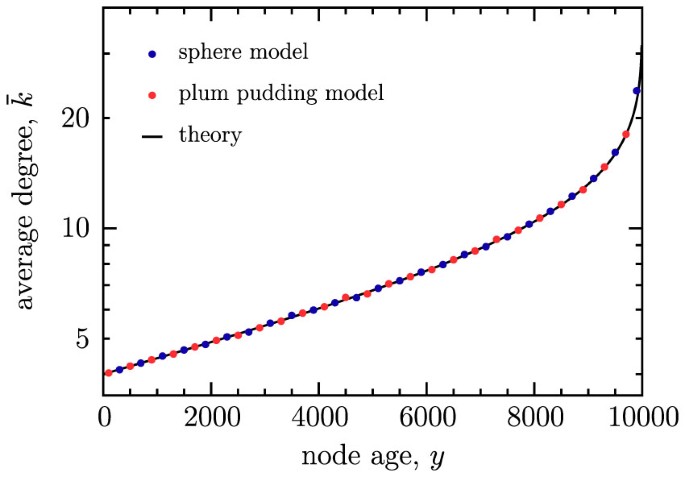
The mean degree
 of a node of age y in a network with N nodes on semilogarithmic axes.
of a node of age y in a network with N nodes on semilogarithmic axes.Data are shown for the sphere network model (blue) and plum pudding model (red), both with d = 2, m = 4 and N = 104. Errors are smaller than the point size. The solid black line is the theoretical prediction given by Eq. (6).
-
iii
The path length ℓ scales as logN with a coefficient that decreases with dimension (Fig. 3) for fixed average degree.
Figure 3 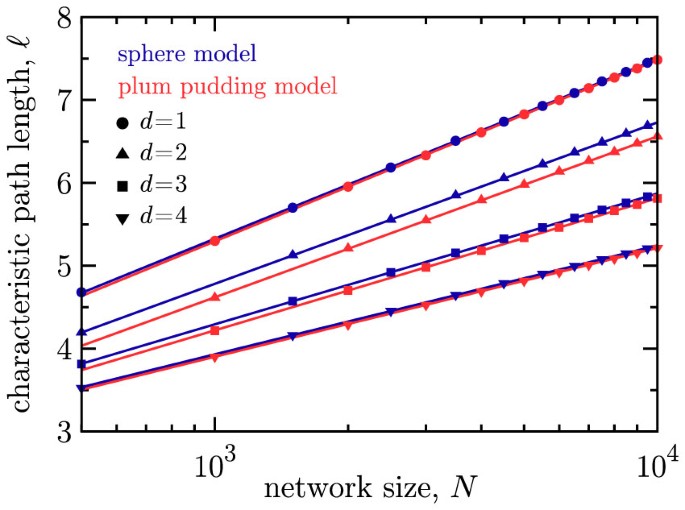
The characteristic graph path length (ℓ) versus network size N on semilogarithmic axes for the sphere model (blue markers) and the plum pudding model (red markers).
The path length shows the desired scaling, ℓ ~ logN. Results are shown for d = 1 (circles), 2 (triangles), 3 (squares) and 4 (inverted triangles), all using m = 4. Errors are smaller than the point size. In general, the average shortest path is shorter for higher dimensions d in both models.
-
iv
The clustering coefficient C approaches a finite asymptotic value with increasing N (Fig. 4) and this asymptotic value decreases with increasing dimension d of the embedding space.
Figure 4 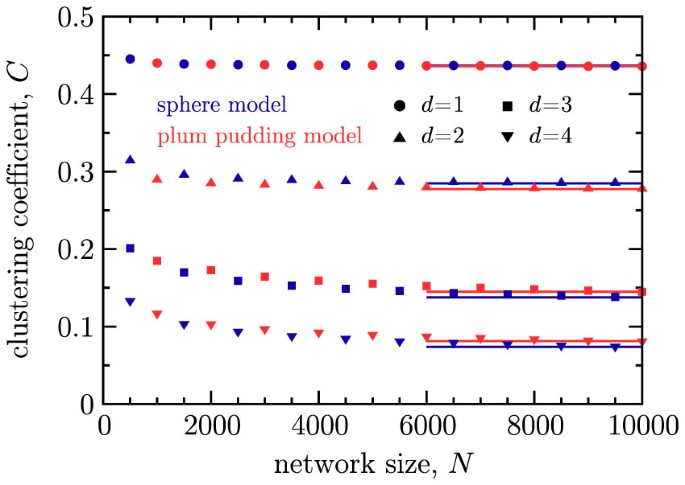
Clustering coefficient C versus network size N for the sphere network model (blue markers) and plum pudding model (red markers), both with m = 4.
Results are shown for d = 1 (circles), 2 (triangles), 3 (squares) and 4 (inverted triangles). Errors are smaller than the point size. Horizontal lines are drawn through the last data point in each series.
-
v
All of our results are very similar for both models, which have different topologies (a unit sphere and a unit ball).


 of a node of age y in a network with N nodes on semilogarithmic axes.
of a node of age y in a network with N nodes on semilogarithmic axes.

The Sphere Network Model
One natural generalization of embedding nodes on the one-dimensional circumference of a circle is to embed them on the two-dimensional surface of a sphere, or more generally on the d-dimensional surface of a hypersphere (in a space of dimension d + 1). The case d = 1 corresponds to the circle network model. However, although it is trivial to arrange N points along the circumference of a circle with uniform spacing, the analogous procedure is less well-defined on higher dimensional surfaces. One way to generalize the arrangement procedure is to consider nodes to act like point charges and to move them to a minimum electrostatic energy equilibrium configuration. The problem of finding the equilibrium configuration of point charges on the surface of a sphere dates back to 1904, when J. J. Thomson introduced his model of the atom and the problem of obtaining such an equilibrium is sometimes referred to as the “Thomson problem”24. A related “generalized Thomson problem” assumes that the force between “charges” is proportional to r−α, where r is the spatial distance between charges, with α not necessarily equal to the Coulomb value, α = d25. In order to facilitate comparisons with our second model below, we use the value α = d − 1 in simulations.
Using the generalized Thomson problem as a guide, we develop a generalization of the circle network model, which we call the Sphere Network Model, as follows. We model the nodes as point charges confined to a unit spherical surface of dimension d. We successively add a new node onto the surface at random with uniform probability density per unit area and then add links to connect it to its m nearest neighbors in terms of spatial distance. Next we relax the node positions to minimize the potential energy of the configuration using a gradient descent procedure,


where xi is the (d + 1)-dimensional position vector of node i, |xi| = 1 for all i and P [·] denotes projection onto the d-dimensional surface of the sphere. We note that, as new nodes are added, this procedure tends to yield a local energy minimum, as opposed to the global minimum (but for some applications, such as modeling biological network growth, the identification of local rather global minima might be viewed as more appropriate). Note that, for large N, the repulsive interaction ensures that the points are distributed approximately uniformly on the surface of the sphere.
The Plum Pudding Network Model
The sphere network model described above has the topological feature that the spatial embedding region does not have any boundary, which allows us to find a nearly-uniform distribution of nodes by imagining them to be identical charges with repulsive interactions. We have also tested another model with a different topology having a boundary and using a different mechanism to encourage uniform distribution of nodes. We call this second model the Plum Pudding Network Model after Thomson's famous model of the atom24.
We again model our nodes as a collection of negative point charges in d dimensions. The growth procedure is similar to the previous models; we place new nodes randomly in our volume and connect them to their m nearest neighbors, where here we define nearest to be the spatial distance between the nodes. Now, however, we regard the nodes as free to move in a unit radius, d-dimensional ball. (For d = 1, the unit ball is the interval −1 ≤ x ≤ 1; for d = 2, it is the region enclosed by the unit circle.) We assume that the ball contains a uniform background positive charge density such that the total background charge in the sphere is equal and opposite to that of the N network nodes. As in the sphere model, after adding a node with uniform probability density within the unit d-dimensional ball, we relax the charge configuration to a local energy minimum. Here, the relaxation is described by

where xi is a d-dimensional position vector with respect to the center of the ball, Fi is as in Eq. (3) and the term Nxi is due to the positive charge density.
Note that, in order to apply Gauss's law for the background charge, we have assumed a force law proportional to r−(d−1). When N is large, the nodes will be approximately uniformly distributed in the ball in order to cancel the uniform positive background charge. Although any repulsive force law can, in principle, be used for the sphere model, we chose to use the same force law for the sphere model in order to facilitate comparisons of the results between the two models. In what follows, we will compare cases of the sphere model and plum pudding model for which the dimension d of the space occupied by the nodes is the same and we keep α = d − 1 the same for both cases.
Results
Degree Distribution
The distribution of node degrees can be derived analytically, does not depend on dimension and is the same for the sphere and plum pudding models. This can be derived from the fact that, for large N, the probability that a newly added node will form an edge to any particular existing node is m/N for all nodes. This is because existing nodes are distributed approximately uniformly and new nodes are placed randomly according to a uniform probability distribution. Here we show that for each considered model, we produce the same master equation governing the evolution of the degree distribution as that found for the circle model6. This master equation is not specific to the spatial structure of the network and appears, in various forms, in other network models, such as the Deterministic Uniform Random Tree of Ref. 26.
We define  to be the number of nodes with degree k at growth step N (i.e., when the system has N nodes). When a node is added to the network it is initially connected to its m nearest neighbors, so upon creation, k = m for each node, meaning that
to be the number of nodes with degree k at growth step N (i.e., when the system has N nodes). When a node is added to the network it is initially connected to its m nearest neighbors, so upon creation, k = m for each node, meaning that  for k < m. Since each existing node is equally likely to be chosen to be connected to the new node, there is an m/N probability that any given node will have its degree incremented by 1. Averaging
for k < m. Since each existing node is equally likely to be chosen to be connected to the new node, there is an m/N probability that any given node will have its degree incremented by 1. Averaging  over all possible random node placements, we obtain a master equation for the evolution of G(k, N), the average of
over all possible random node placements, we obtain a master equation for the evolution of G(k, N), the average of  over all possible randomly grown networks,
over all possible randomly grown networks,

where δkm is the Kronecker delta function. The first term on the right is the expected number of nodes with degree k at growth step N. The second term is the expected number of nodes with degree k at growth step N that are promoted to degree k + 1. The third term is the expected number of nodes with degree k − 1 at growth step N that are promoted to degree k. The last term on the right is the new node with degree m.
It was shown by Ozik et al.6 that this master equation leads to an exponentially decaying degree distribution with an asymptotically N invariant form H(k) = limN→∞G(k, N)/N given by Eq. (1) for k ≥ m and H(k) = 0 for k < m. Interestingly, this degree distribution comes only from the growth process and the uniform probability of attaching new links to existing nodes. As seen in Fig. 1, for m = 4, N = 104, with d = 1, 2, 3, or 4, Eq. (1) is well satisfied by numerical simulations of both models.
Intuitively, we expect that older nodes in each model will accumulate more edges and become network hubs. The relationship between degree and age is also straightforward to investigate in this model. Here, we reproduce an expression for the expected degree  of a node that has existed for y growth steps, given that the network size is N (y < N)27. Each node connects to its m nearest neighbors upon creation and the probability of incrementing the degree of the node is m/N when the size of the network is N. Thus we obtain
of a node that has existed for y growth steps, given that the network size is N (y < N)27. Each node connects to its m nearest neighbors upon creation and the probability of incrementing the degree of the node is m/N when the size of the network is N. Thus we obtain

Once again, since this derivation uses only the assumption that each node has an equal chance each growth step to have its degree incremented, the result holds for both of the models discussed here. This represents a specific example of the fact that in dynamically growing networks, older nodes are preferentially connected to subsequent nodes, as discussed in Ref. 18. Numerical simulations in Fig. 2 demonstrate that Eq. (6) is satisfied for both models. For simplicity, results are only presented for d = 2, but Eq. (6) has no dependence on the embedding space and thus holds for other dimensions as well.
Path Length and Clustering Coefficient
For the sphere and plum pudding network models, we find numerically that the average shortest path length ℓ scales logarithmically with the network size N, that is, ℓ ~ logN. See Fig. 3. The scaling ℓ ~ logN is expected because as the network grows in size, the older nodes are pushed apart by the repulsive force, thus leaving bridges across the network that span a significant distance. These long range links serve to connect spatially separated regions of highly interconnected nodes, dramatically reducing the shortest path length between any two nodes in the network6. At each growth step only local connections are made, but due to the dynamic nature of the nodes' spatial positions, each growth step can make existing links longer in physical space, thus building bridges across the network.
We see from Fig. 3 that, for given values of N and m, the characteristic path length decreases with d and is shorter than that of the corresponding one-dimensional case (the original circle network model). One possible explanation for this is that in a higher dimensional space, it is easier to separate existing nodes by placing a new node, because nodes can move around one another, making it easier for short-range links to be stretched into shortcuts as the network grows. This is in contrast to the circle network model, in which each node is forever locked between its two original spatial neighbors until a new node is placed directly between them.
For both models, we also find that the clustering coefficient C is nonzero for large N, but depends on the dimension of the embedding space. Results for the clustering coefficient C versus the number of nodes N with d = 1, 2, 3 and 4, using m = 4, are displayed in Fig. 4. Horizontal lines are drawn through the last point in each series. For the values of d shown, we see that as N increases, there is an initial decrease of C for N < 1, 000, but the N variation appears to effectively cease with increasing N. These results are consistent with an N → ∞ asymptotic value close to the value at N = 10; 000. Assuming this to be the case, values for the large-N clustering in the sphere model are given as follows: for d = 1, C ≈ 0.44; for d = 2, C ≈ 0.28; for d = 3, C ≈ 0.14; and for d = 4, C ≈ 0.07. Values for the plum pudding model are similar. Higher dimensional cases that we have examined (d = 5–9) follow the same pattern. More specifically, we find that for a given value of m, the clustering coefficient decays algebraically with dimension,  . In Fig. 5, we show that β4 = 1.88 for the sphere model, while for larger values of m we find βm decreases, but remains positive.
. In Fig. 5, we show that β4 = 1.88 for the sphere model, while for larger values of m we find βm decreases, but remains positive.

Asymptotic clustering coefficient C versus dimension of embedding space d for the sphere network model (blue) and plum pudding model (red) on logarithmic axes with m = 4.
Solid black lines are given by C ∝ d−β, where β was obtained from a least-squares fit to the data for d ≥ 2. The resulting value of β was 1.88 for the sphere model and 1.81 for the plum pudding model.
Thus we find that both the sphere and plum pudding network models lead to networks exhibiting the small-world property and their behaviors are similar. Based on these examples, we suggest that spatial topology may not to be of great importance to the small-world properties of the resulting network. We conjecture that node addition, local edge formation and relaxation towards uniform density are typically sufficient for the occurrence of the small-world property (although we acknowledge that there may be counterexamples in unusual cases). On the other hand, although the degree distribution does not depend on dimension, an important result is that other network properties such as the clustering coefficient show a relatively strong dependence on dimensionality (Figs. 3–5).
It is worth noting that the d = 1 case of the plum pudding model does not reduce to the circle network model, but the two nonetheless show similar behavior, because they differ only at the boundary x = ±1. In both models, the relative spatial ordering of nodes is preserved and the equilibrium case has perfectly uniform inter-nodal spacing, as opposed to models with d ≥ 2, in which the concept of linear ordering is absent. In addition, when d ≥ 2 in both the sphere and plum pudding models, exact, global regular-lattice positioning is not possible. For example, for  charges on a sphere with d = 2, it is known that the equilibrium positioning on much of the area of the sphere is locally similar to a triangular lattice, but the sphere's curvature leads to point and line defects in the lattice25. Thus a natural question is whether the d = 1 cases might have special properties in common that deviate from those for d ≥ 2. It can be seen in Fig. 5 that one such property is that both d = 1 cases do not follow the same scaling trend in clustering that we find for higher dimensions.
charges on a sphere with d = 2, it is known that the equilibrium positioning on much of the area of the sphere is locally similar to a triangular lattice, but the sphere's curvature leads to point and line defects in the lattice25. Thus a natural question is whether the d = 1 cases might have special properties in common that deviate from those for d ≥ 2. It can be seen in Fig. 5 that one such property is that both d = 1 cases do not follow the same scaling trend in clustering that we find for higher dimensions.
Discussion
We have explored two models which generate networks with small-world features through local spatial attachment and growth, without direct formation of long-distance links. By allowing nodes to move in space, the initially formed local links can become long-range, thus providing a mechanism for how small-world networks can emerge from a growing collection of dynamically interacting and locally constrained vertices. Both models show similar behavior for the degree distribution, characteristic path length and clustering coefficient. The qualitative similarity between the networks generated by the two models indicates that the small-world features are determined by spatial attachment and growth, and, in these cases, is not affected by the topological features of the embedding space. However, the quantitative values of measures characterizing these features can depend on dimension; higher-dimensional spaces yield shorter path lengths but less clustering.
These findings may offer insight into the origin of small-world features in growing networks, possibly including networks of neurons. In some systems, network growth may be an appropriate mechanism for the emergence of small-world features. We also speculate that similar ideas may explain the small-world property in other types of networks. For example, in some transportation networks such as the Indian railroad network16, nodes are not distributed uniformly, but there is an incentive for spacing nodes apart and some of the same results may follow. It is also possible that these ideas could be applied to some non-spatial networks, such as the world wide web28, by replacing the physical space used in our model with a more abstract space of content (i.e., the location of a node represents the topic or purpose of a website and websites link to other websites which have similar content).
We hope these findings will generate renewed interest in spatial networks with dynamically located nodes and in the role that growth plays in the development of important network features.
References
Milgram, S. The small world problem. Psych. Today 1, 61 (1967).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440 (1998).
Newman, M. E. J. The structure and function of complex networks. SIAM Rev. 45, 167 (2003).
Newman, M. E. J. Random graphs with clustering. Phys. Rev. Lett. 103, 058701 (2009).
Lakhina, A., Byers, J. W., Crovella, M. & Matta, I. On the geographic location of internet resources. IEEE J. Sel. Areas Commun. 21, 934 (2003).
Ozik, J., Hunt, B. R. & Ott, E. Growing networks with geographical attachment preference: Emergence of small worlds. Phys. Rev. E 69, 026108 (2004).
Przulj, N., Kuchaiev, O., Stevanovic, A. & Hayes, W. Geometric evolutionary dynamics of protein interaction networks. Pac. Symp. Biocomput. 2009, 178 (2010).
Herrmann, C., Barthélemy, M. & Provero, P. Connectivity distribution of spatial networks. Phys. Rev. E 68, 026128 (2003).
Bullock, S., Barnett, L. & Di Paolo, E. A. Spatial embedding and the structure of complex networks. Complexity 16, 20 (2010).
Guan, Z.-H. & Wu, Z.-P. The physical position neighbourhood evolving network model. Physica A 387, 314 (2008).
Zhang, Z.-Z., Rong, L.-L. & Comellas, F. Evolving small-world networks with geographical attachment preference. J. Phys. A 39, 3253 (2006).
Zhang, Z., Zhou, S., Shen, Z. & Guan, J. From regular to growing small-world networks. Physica A 385, 765 (2007).
Bassett, D. S. et al. Efficient physical embedding of topologically complex information processing networks in brains and computer circuits. PLoS Comp. Biol. 6, e1000748 (2010).
Barthélemy, M. Crossover from scale-free to spatial networks. Europhys. Lett. 63, 915 (2003).
Vázquez, A., Flammini, A., Maritan, A. & Vespignani, A. Modeling of protein interaction networks. ComPlexUs 1, 38 (2002).
Sen, P., Dasgupta, S., Chatterjee, A., Sreeram, P. A., Mukherjee, G. & Manna, S. S. Small-world properties of the Indian railway network. Phys. Rev. E 67, 036106 (2003).
Davidsen, J., Ebel, H. & Bornholdt, S. Emergence of a small world from local interactions. Phys. Rev. Lett. 88, 128701 (2002).
Callaway, D. S., Hopcroft, J. E., Kleinberg, J. M., Newman, M. E. J. & Strogatz, S. H. Are randomly grown graphs really random? Phys. Rev. E 64, 041902 (2001).
Sporns, O. & Zwi, J. D. The small world of the cerebral cortex. Neuroinformatics 2, 145 (2004).
Bassett, D. S. & Bullmore, E. Small-world brain networks. Neuroscientist 12, 512 (2006).
Markov, N. T. et al. Cortical high-density counterstream architectures. Science 342, 1238406 (2013).
Oh, S. W. et al. A mesoscale connectome of the mouse brain. Nature 508, 207 (2014).
Newman, M. E. J., Strogatz, S. H. & Watts, D. J. Random graphs with arbitrary degree distributions and their applications. Phys. Rev. E 64, 026118 (2001).
Thomson, J. J. On the structure of the atom: an investigation of the stability and periods of oscillation of a number of corpuscles arranged at equal intervals around the circumference of a circle; with application of the results to the theory of atomic structure. Philos. Mag. 7, 237 (1904).
Bowick, M., Cacciuto, A., Nelson, D. R. & Travesset, A. Crystalline order on a sphere and the generalized Thomson problem. Phys. Rev. Lett. 89, 185502 (2002).
Zhang, Z., Zhou, S., Qi, Y. & Guan, J. Topologies and Laplacian spectra of a deterministic uniform recursive tree. Eur. Phys. J. B 63, 507 (2008).
Jackson, M. O. Social and Economic Networks (Princeton University Press, 2010).
Adamic, L. A. The small world web. Research and Advanced Technology for Digital Libraries 443–452 (Springer, 1999).
Acknowledgements
This work was supported by the National Science Foundation under grant number PHY-1156454, by the Army Research Office under grant W911NF-12-1-0101 and by The University of Maryland: Mpowering the State initiative through the Center for Health-related Informatics and Bioimaging.
Author information
Authors and Affiliations
Contributions
All authors (A. Z., A. G., S. S., M. H., T. M. A., M. G. and E. O.) posed research questions, contributed to analytical results and analyzed numerical results. A. Z. and A. G. performed all numerical simulations. S. S. prepared the figures. A. Z., S. S., M. G. and E. O. wrote the main text of the manuscript. All authors reviewed the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. The images or other third party material in this article are included in the article's Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder in order to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/4.0/
About this article

Cite this article
Zitin, A., Gorowara, A., Squires, S. et al. Spatially embedded growing small-world networks. Sci Rep 4, 7047 (2014). https://doi.org/10.1038/srep07047
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep07047
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
