
Abstract
Quantum walks exhibit many unique characteristics compared to classical random walks. In the classical setting, self-avoiding random walks have been studied as a variation on the usual classical random walk. Here the walker has memory of its previous locations and preferentially avoids stepping back to locations where it has previously resided. Classical self-avoiding random walks have found numerous algorithmic applications, most notably in the modelling of protein folding. We consider the analogous problem in the quantum setting – a quantum walk in one dimension with tunable levels of self-avoidance. We complement a quantum walk with a memory register that records where the walker has previously resided. The walker is then able to avoid returning back to previously visited sites or apply more general memory conditioned operations to control the walk. We characterise this walk by examining the variance of the walker's distribution against time, the standard metric for quantifying how quantum or classical a walk is. We parameterise the strength of the memory recording and the strength of the memory back-action on the walker and investigate their effect on the dynamics of the walk. We find that by manipulating these parameters, which dictate the degree of self-avoidance, the walk can be made to reproduce ideal quantum or classical random walk statistics, or a plethora of more elaborate diffusive phenomena. In some parameter regimes we observe a close correspondence between classical self-avoiding random walks and the quantum self-avoiding walk.
Similar content being viewed by others
Introduction
Quantum walks1,2,3,4, the quantum equivalent of classical random walks, have been studied extensively for their applications in quantum information processing5. Here a walker (a particle such as a photon) resides at a vertex (e.g. an optical mode) in a graph and is allowed to ‘hop’ along the edges in the graph to reach other vertices. In the classical random walk this process takes place randomly, whereas in the quantum case the walker coherently enters a superposition across different vertices. Numerous elementary optical demonstrations of quantum walks have been performed6,7,8,9,10,11,12,13,14, experimentally confirming the unique behaviour of quantum walks compared to classical random walks and providing an alternate route towards optical quantum information processing15,16.
In this paper we consider one-dimensional quantum walks, where the walker has memory of its previous location history and the coin operator is a function of the memory. This can be used, for example, to preferentially avoid previously visited vertices or implement more elaborate conditional coins, allowing for tunable degrees of self-avoidance in the evolution of the walk. Self-avoiding walks have been studied extensively in the classical case17,18,19,20,21,22, having been applied to applications such as protein folding and percolation theory.
Previous authors have considered quantum walks complemented by memory, where the memory is of previous coin values23,24,25,26. Here, however, we consider the case where the memory is of previous positions rather than of previous coins.
Self-avoiding quantum walks may find applications in situations where ordinary quantum walks have been applied, but where we explicitly wish to avoid re-exploring previously visited sites. While classical self-avoiding walks have been applied to modelling protein folding27, long-chain polymers28 and molecular conformation, perhaps quantum self-avoiding walks may be applied to modelling the analogous problems in the quantum context.
In our model each vertex in the graph is complimented by a qubit, which marks whether the site has previously been visited. As the walker walks it leaves a record on the site at which it is presently located. The coin, which determines the subsequent step direction, is biased to avoid walking onto previously marked sites. We will see that due to the unitarity of our model, we cannot maintain a permanent record of where the walker has been and the walker has some chance of revisiting previously visited sites.
We find that self-avoiding quantum walks exhibit diverse diffusive characteristics, ranging from ideal classical to ideal quantum walk dynamics and a plethora of more elaborate behaviours. In particular, we find that there is good agreement between the partially avoiding quantum walk and a corresponding partially avoiding classical walk in one-dimension. In the limit of maximum self-avoidance, the walk can exhibit significantly faster rate of spread than an ordinary quantum walk.
Classical self-avoiding random walks
Self-avoiding classical random walks17,18,19,20 are a variation on the standard classical walk, where the walker is unable to revisit any sites it has previously visited. A one dimensional, classical, completely self-avoiding walk is trivial; once the first step has been taken by the walker, every step thereafter has only one possibility. The variance of the walker will always be zero, as after the initial step there is only one possible location for the walker to be at any given step. Self-avoiding random walks become less trivial and more useful in two and three dimensions, but they also become exceedingly difficult to analyse in higher dimensions.
Self-avoiding walks have the property that they explore a graph more rapidly, since evolution time is not wasted re-exploring already visited sites. Self-avoiding classical random walks are particularly useful in two and three dimensions as they find applications in modelling solvents and polymers28, protein folding27, molecular conformation, percolation lattices and drug discovery. When using classical random walks to model the proliferation of forest fires or the propagation of liquids through a porous material – two archetypal applications for classical random walks – we wish to determine whether a route through a graph exists. Thus, there is no benefit in exploring vertices that have previously been explored and a self-avoiding walk will be far more efficient.
Partially self-avoiding classical walks in one dimension have been studied previously and we review a standard model for one of these in Section below and find good comparison with the partial avoiding quantum walk.
Quantum walks
A (discrete-time) quantum walk is a bipartite system comprising position and coin degrees of freedom, with Hilbert space  . The position parameter specifies the location (vertex) of the walker in the graph, whilst the coin parameter specifies the direction the walker is heading. On a one-dimensional graph the state of the quantum walker at time t is of the form |ψ(t)〉 = Σx, c αx, c(t)|x, c〉, where
. The position parameter specifies the location (vertex) of the walker in the graph, whilst the coin parameter specifies the direction the walker is heading. On a one-dimensional graph the state of the quantum walker at time t is of the form |ψ(t)〉 = Σx, c αx, c(t)|x, c〉, where  is the discrete position of the walker and c = ±1 is the direction of the walker (left or right respectively).
is the discrete position of the walker and c = ±1 is the direction of the walker (left or right respectively).
The evolution of the walk is specified by unitary  and
and  operators, which have the actions
operators, which have the actions  and
and  respectively, where U is the unitary coin matrix. Thus the coin operator coherently manipulates the direction of the walker, leaving the position unchanged, whilst the step operator uses the coin parameter to update the location of the walker, leaving the coin unchanged. The evolution of the walk over t time steps proceeds as
respectively, where U is the unitary coin matrix. Thus the coin operator coherently manipulates the direction of the walker, leaving the position unchanged, whilst the step operator uses the coin parameter to update the location of the walker, leaving the coin unchanged. The evolution of the walk over t time steps proceeds as  .
.
One of the interesting features of the quantum walk is that it exhibits a quadratically faster rate of spread (measured using variance) compared to the classical random walk. The variance is defined as, σ2(t) = Σxpx(t) · (x − µ(t))2, µ(t) = Σxpx(t) · x, where px(t) is the total probability of finding the walker at location x at time t, given by summing over the coin degree of freedom, px(t) = Σc|αx, c(t)|2, effectively tracing out the coin.
Quantum self-avoiding walks
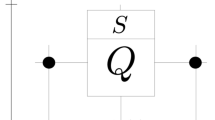
We fashion our self-avoiding quantum walk with three components: (1) we record the current position of the walker into the local quantum memory. This is performed using a ‘memory update operator’; (2) we perform the usual coin operator, where the bias of the coin is determined by the state of the memory registers at the current location of the walker; (3) the usual step operator is applied, which results in the walker's movement being a function of whether the site has previously been visited. This allows, for example, the walker to reverse direction upon reaching a previously visited site. An illustration of the components in the self-avoiding quantum walk are shown in Fig. 1.

Illustration of the different subsystems in the self-avoiding quantum walk.
The walker resides on a linear graph structure with a two-level memory qubit associated with each vertex, indicating whether the site has been previously visited.
Recording the current position — To model the self-avoiding quantum walk whereby the walker has memory of its previous location history and avoids positions where it has previously resided, we complement the walker by a sequence of qubits – one for each site in the lattice – where the qubits indicate whether the walker has previously visited the respective site. In this case the state of the system at time t is of the form,

where qi = {0, 1} is the qubit associated with site i and there are N sites. Initially qi = 0 µ i, indicating that none of the sites have been visited. Evidently, the size of the Hilbert space grows exponentially with the size of the lattice ( ), in contrast to linear growth for an ordinary quantum walk (
), in contrast to linear growth for an ordinary quantum walk ( ). This limits our numerical investigations to relatively small evolution times.
). This limits our numerical investigations to relatively small evolution times.
We introduce a memory update operator, which updates the memory qubits as a function of the walker's position. We have chosen to implement the memory update operator unitarily, which implies that the memory is reversible and temporary and that the record will evaporate after a second visit to the respective site. A permanent memory recording would require a Lindblad model, which would introduce decoherence into the system. Taking our memory recording to be unitary we fix it to be of the form,

a Pauli X rotation applied to the xth qubit. Now θM determines the strength of the action of the position on the memory. In the extreme case where θM = π/2, if the walker has not previously visited site x, the memory update operator flips the respective qubit to mark that this position has now been visited. Of course, a second visit to the site will flip the qubit again, marking that the site has not been visited. Note that this latter property is unavoidable if the evolution is to remain unitary. If θM = 0 the position has no effect on the memory and the memory only couples with position via the coin operator.
Biasing the coin according to neighbouring memory registers — The coin operator is defined analogously to the usual quantum walk coin operator,

where  is a 2 × 2 coin matrix that depends on the state of the qubit at location x, qx. This operator coherently manipulates the coin degree of freedom locally, whilst leaving the position and memory qubits unchanged. The choice of coin matrix is a function of the local memory qubit – when qx = 0 we let
is a 2 × 2 coin matrix that depends on the state of the qubit at location x, qx. This operator coherently manipulates the coin degree of freedom locally, whilst leaving the position and memory qubits unchanged. The choice of coin matrix is a function of the local memory qubit – when qx = 0 we let  (a usual balanced walk with equal amplitudes of stepping in either direction) and when qx = 1 we let
(a usual balanced walk with equal amplitudes of stepping in either direction) and when qx = 1 we let  . Here, R(θ) is a general Pauli X rotation,
. Here, R(θ) is a general Pauli X rotation,

Thus, θ = 0 implements an identity gate, θ = π/2 implements a full bit-flip and θ = π/4 implements a balanced step. Our memory will have the effect that if the xth qubit is set (indicating that we previously visited location x) then the coin operator implements a partially reflecting mirror on the walker's dynamics, with strength determined by θB. This mirror is located at spatial location x and the reflectivity (r) is determined by θB (when θB = 0, r = 0 and when θB = π/2, r = 1). Thus, the parameter θB controls how strong the effect of memory on the coin is. The probability of being reflected at a site where the memory is set is given by r = |sin θB|2, otherwise it is given by r = |sin θC|2.
Propagating the walker — The step operator is defined in the usual way – it updates the position as a function of the coin parameter,

The step operator affects only the position, leaving the coin and memory systems unchanged.
Combined evolution — The total evolution now progresses as,

where a single step begins with memory recording, followed by the coin operator and finally the step operator.
Our formalism differs from that presented in Ref. 29, where no memory was required to ensure self-avoidance. Rather, the coin matrix was chosen so as to guarantee there is always zero amplitude in the reverse direction. This is the so-called ‘non-reversing quantum walk’. However, such a formalism is constrained by the fact that one is unable to tune between different memory strengths, making our formalism much more versatile, as we will see in the next section.
Whilst the presented formalism is in the context of a one-dimensional walk, it could be trivially generalised to higher dimensions, by expanding the position space. However, we will not perform simulations in this context as the complexity of simulations grows exponentially with the number of discrete position states.
Results
To characterise the self-avoiding walk we will again consider the variance of the position probability distribution against time. We compute the variance, where now px(t) is obtained by summing over the coin and memory degrees of freedom,

effectively tracing out the coin and memory subsystems.
In the purely classical case σ2(t) ∝ t and in the quantum case σ2(t) ∝ t2. In our quantum walk with memory we anticipate more elaborate dynamics, which we will now explore and characterise.
In Fig. 2(centre) we plot the variance of the self-avoiding quantum walk against varying memory recording (θM) and coin back-action (θB) when evolved 7 steps. In all cases the regular coin is fixed as a balanced coin, θC = π/4. Here we have employed the symmetrised input state,

which guarantees symmetric position probability distributions in the case of the standard unbiased quantum walk.

Final variance (t = 7) of the self-avoiding quantum walk with symmetrised input state (Eq. 8), against memory recording strength (θM) and coin back-action strength (θB), and, as insets, some of the corresponding quantum walks (showing the full time evolution of the variance and probability distribution). (e) In the limit of θM = π/2 and θB = π/4 we observe ideal classical random walk statistics, since the memory is maximally entangled with the walker, yielding a balanced π/4 walk with decoherence upon tracing out the memory subsystem. (c) In the opposing limit of θM = 0 and irrespective of θB we observe ideal quantum walk statistics, since now the memory does not couple with the walker, yielding a uniform π/4 walk without decoherence. The memory never changes, remaining at its initial value. (a) Variance is maximised when θM = π/2 and θB = 0, for which the coin will always be the identity coin, yielding two outward straight line trajectories. (d) When θM = π/2 and θB = π/2 the dispersion is restricted since the walker is switching between a balanced π/4 coin and a bit-flip coin at alternate steps.
Each point in the plot in Fig. 2(centre) corresponds to the final variance of an entire quantum walk with given choices of coin back-action and memory recording. To understand these dynamics, the insets illustrate the complete quantum walk evolution dynamics corresponding to some individual points in the plot.
We observe that the variance is maximal when the memory has maximum recording strength (θM = π/2) and the coin has identity back-action (θB = 0), as shown in Fig. 2(a). Because the memory recording strength is maximal, the memory qubit corresponding to the initial location is set. Then, because the qubit is set, the identity coin will be applied, which propagates the walker outwards. At the next step the same process applies, marking the current site and propagating the walker outwards. Thus, the two terms in the symmetrised input state shoot off in straight line paths in opposite directions, yielding maximum quadratic variance against time. Fitting to a second order polynomial,

the second order coefficient of the aforementioned maximum variance walk is k2 = 1, compared to k2 = 0.27 for the ideal quantum walk, reflecting the significantly faster rate of spread of the θM = π/2, θB = 0 self-avoiding quantum walk compared to the normal ideal quantum walk.
Intuitively, the maximum variance in this case appears to be a result of the choice of symmetrised input state. We expect that if we instead adopt an unsymmetrised input state,

there will be only a single straight line trajectory in one direction, yielding zero variance. This is confirmed in Fig. 3. Thus, we see that the variance of the self-avoiding quantum walk is highly dependent on the initial choice of input state and can in fact swap us between maximal and zero variance. Fig. 4 illustrates the variance of an unsymmeterised input state across all parameter regimes.

Evolution of the self-avoiding quantum walk for θM = π/2, θB = 0, with symmetrised (left) and unsymmetrised (right) input states (Eqs. 8 and 10 respectively).
This illustrates the high sensitivity of the dispersion to the initial state, as the former exhibits the maximum possible variance, whereas the latter exhibits zero variance.

Variance of the self-avoiding quantum walk with unsymmetrised input state (Eq.
10). Contrast the different dynamics with Fig. 2 where a symmetrised input state was employed. In particular, note the drastically different variance at θM = π/2, θB = 0 compared to the symmetrised case – the maxima in the symmetrised plot corresponds to the minima of the unsymmetrised plot. Note the different viewing angle than Fig. 2.
In the intermediate case of 0 < θB < π/2, the coin creates a superposition, yielding lower variance than Fig. 2(a).
In the case of θM = π/4 and θB = π/4 we observe statistics that are qualitatively very classical (Fig. 2(b)). This is because now the coin is a π/4 rotation irrespective of the memory (recall that θC = π/4 also), yielding a balanced walk, regardless of history. But simultaneously the memory register is highly entangled with the position degree of freedom, which, upon being traced out, yields decoherence, which can cause a transition from a quantum to a classical walk. This transition was nicely experimentally demonstrated by Broome et al.8 in the optical context.
If we increase the memory recording strength to θM = π/2, whilst retaining θB = π/4, the walker is maximally entangling with the memory, yielding complete decoherence upon tracing out the memory. Thus, in this instance we observe the binomial distribution and linear variance associated with the ideal classical walk (Fig. 2(e)).
When θM = 0 there is no memory recording and so no entanglement between the memory and the walker. The memory stays permanently fixed at its initial value and thus the coin is always the θC = π/4 coin, yielding a balanced quantum walk, irrespective of θB (Fig. 2(c)). Thus, when θB = π/4, the memory recording strength can tune us between a perfect classical walk (θM = π/2) and a perfect quantum walk (θM = 0).
In the limiting case of maximum coin back-action (θB = π/2) and maximum memory recording strength (θM = π/2), the walker resists outward diffusion, yielding a distribution more localised around the origin (Fig. 2(d)). This is because as the walker visits sites the respective memory qubit is completely flipped, toggling between marking the site as visited or not visited. When visited, the walker will incur a full bit-flip, sending the walker back whence it came. Otherwise a balanced coin is implemented and the walker spreads equally in both directions. Thus, on alternate steps the walker either completely flips direction or spreads evenly in both directions, resulting in reduced outward diffusion compared to a normal balanced walk.
An interesting feature of Fig. 2(centre) is to note that σ2(θB, θC, θM) is not monotonically related to θB and θM. For low values of θB we see that σ2 increases monotonically with θM, whereas for large θB it decreases with θM. Similarly, for large θM, σ2 decreases monotonically with θB, whereas for small θM it increases with θM. However, the non-monotonic nature of σ2 may be due to the small values of t that we are able to simulate. In the case of unsymmetrised input states (Fig. 4) the dynamics are even more complex.
Evidently, different parameter regimes for θB, θC and θM yield different couplings between the different subsystems when acted upon by the coin, step and memory operators. The couplings are illustrated in Fig. 5. The coin operator will couple all three subsystems, provided that θC ≠ θB. The step operator will always couple the coin and position subsystems, irrespective of θB, θC and θM. And the memory operator will couple the position and memory subsystems provided that θM ≠ 0.

Illustration of the couplings between the position, coin and memory subsystems, depending on αB, θC and θM.
The coin operator couples all three subsystems, provided that θC ≠ θB. The memory operator couples the position and memory subsystems, provided that θM ≠ 0. The step operator couples the position and coin subsystems, irrespective of the parameters.
Comparison with classical self-avoiding random walks
In the classical case, self-avoiding random walks can be constructed in a variety of ways. For example, a classical random walk could be completely self-avoiding, in the sense that it may never return to a visited site. More generally, a metric could be defined, which specifies the probability with which a walker may return to a previously visited site. In Refs. 17,18 such a metric is defined as,

where qi is the probability of stepping to site i, ni is the number of times site i has been previously visited, g ≥ 0 is the strength of the self-avoidance (g = 0 is an ordinary classical random walk, g = ∞ is a completely self-avoiding walk and 0 < g < ∞ is a weakly self-avoiding walk) and j sums over the nearest neighbours of the current vertex. Thus, the probability of returning to a given site is weighted exponentially with the number of times the respective site has been visited. Using this formalism one can tune between a regular non-self-avoiding classical random walk, a weakly self-avoiding random walk, or a completely self-avoiding random walk. A generic characteristic of such a self-avoiding classical random walk is that as g increases the walker is more likely to be found further away from the origin.
The self-avoidance metric given in Eq. 11 biases how likely the walker is to revisit a site given its prior visitation history and the strength of the self-avoidance, g. However, this bias requires the total number of previous visits to each site. To compare with our quantum self-avoiding walk we restrict to the case where θM = π/2. Then the memory is marked and then unmarked at subsequent visits, i.e. the bias effectively depends on the number of visits modulo 2. Therefore, we modify Eq. 11 to count modulo 2, such that,

Alternately, one could achieve a situation more analogous to Eq. 11 by replacing the qubits in the self-avoiding quantum walk with qu-d-its and letting the memory recording implement qi → (qi + 1) mod d, thus giving us the ability to record up to d instances of previous visits. However we will not explore this option given the computational intractability.
As discussed earlier, in the quantum case when θM = π/2 we have maximum coupling between the walker and the memory, yielding a decoherence effect. Thus, we expect the comparison between the classical self-avoiding random walk and the quantum self-avoiding walk to be closest in the regime where θM = π/2.
Recall that in the classical limit σ2(t) ∝ t, whereas in the quantum limit θ2(t) ∝ t2. Thus, to characterize the classical self-avoiding random walk we fit the variance to σ2(t) = tβ. In Fig. 6 (top) we plot the exponent β against the self-avoidance strength g for a classical self-avoiding random walk. Contrast this with Fig. 6 (bottom), where we plot the analogous situation for the quantum self-avoiding walk with θM = π/2 while varying θB, corresponding to the classical regime of maximum coupling with the memory. Now θB takes the role of the self-avoidance strength. In the limit of θB = π/4 we observe an ideal classical random walk with β = 1, which corresponds to Fig. 2(e). In the opposing limit of θB = 0 we observe maximum dispersion and β = 2, corresponding to Fig. 2(a). Thus, within this region we observe a correspondence between g (in the classical case) and θB (in the quantum case). Specifically, g = 0 corresponds to θB = π/4 and  corresponds to θB = 0. In these two limits the self-avoiding classical random walk exhibits dynamics close to the respective self-avoiding quantum walk (Figs. 2(e) and (a) respectively). In both cases β exhibits a monotonic relationship to the self-avoidance strength, ranging between β = 1 (linear spread) and β = 2 (ballistic, quadratic spread).
corresponds to θB = 0. In these two limits the self-avoiding classical random walk exhibits dynamics close to the respective self-avoiding quantum walk (Figs. 2(e) and (a) respectively). In both cases β exhibits a monotonic relationship to the self-avoidance strength, ranging between β = 1 (linear spread) and β = 2 (ballistic, quadratic spread).

Exponent of a σ2(t) = tβ fit of the variance against time for a self-avoiding walk.
β = 1 corresponds to linear variance against time, whereas β = 2 corresponds to quadratic variance against time (ballistic spread). (top) A classical self-avoiding random walk with self-avoidance function given by Eq. 12, where g is the self-avoidance strength. The fitting is calculated over 200 time steps and 1000 repetitions. When g = 0 we reduce to a normal balanced classical random walk, which exhibits linear spread and thus β = 1 (analogous to Fig. 2(e)). As the self-avoidance strength increases, we approach a perfectly self-avoiding random walk, exhibiting maximum quadratic dispersion and β = 2 (analogous to Fig. 2(a)). (bottom) The same fit for a quantum self-avoiding walk where θC = π/4 and θM = π/2. This is the classical regime of maximum coupling between the walker and the memory. Now θB takes the role of the self-avoidance strength.
Conclusion
We have considered a one-dimensional quantum walk with tunable degrees of self-avoidance. Here the walker is complemented by a memory register that records the previous position history and the coin operator is a function of the memory, allowing the walker to preferentially avoid previously visited sites.
Similar behaviour could be modelled using the formalism of Ref. 26, where the walker has memory of past coin values rather than past position values. In that formalism the walker's movement may be an arbitrary unitary function of the walker's history, allowing arbitrary dynamics to be implemented.
Whilst we have focused on one-dimensional walks, the formalism may be easily generalized to higher dimensions. But in that instance numerical simulation faces the obstacle that computational complexity grows exponentially with the number of positions.
We have defined our self-avoiding walk such that the walker's direction is made a function of whether the present site has been previously visited. A possibility we have not explored is where the coin is a function of whether the neighbour in the direction of movement has been visited, but such rules often are difficult to implement in a unitary fashion. A variation where the walker's movements depends on both neighbours, though not consistent with our formalism, can be made unitary and constitutes a type of quantum cellular automata.
With appropriate choices of conditional coins and recording strengths, the walk can be made to exhibit zero dispersion or maximal dispersion, which is highly dependent on the symmetrisation of the input state. The walker can be made to reproduce ideal quantum or classical statistics, or to exhibit richer, more diverse diffusive characteristics, which can be manipulated with the strength of the memory recording (θM) and back-action (θB). In the regime of maximum memory recording strength, we observe a close correspondence between the quantum and classical self-avoiding walks, where the coin back-action takes the role of the self-avoidance strength.
The rich diffusive characteristics of the quantum self-avoiding walk may be applicable to modelling a broader range of diffusive phenomenon than ordinary quantum walks and may lend themselves to novel quantum information processing applications such as applications in quantum simulation.
References
Aharonov, Y., Davidovich, L. & Zagury, N. Quantum random walks. Phys. Rev. A 48, 1687 (1993).
Aharonov, D., Ambainis, A., Kempe, J. & Vazirani, U. Quantum walks on graphs. STOC '01 Proceedings of the 33rd ACM symposium on Theory of computing 50 (2001).
Kempe, J. Quantum random walks - an introductory overview. Cont. Phys. 44, 307 (2003).
Venegas-Andraca, S. E. Quantum walks: a comprehensive review. Quant. Inf. Proc. 5, 1015 (2012).
Nielsen, M. A. & Chuang, I. L. Quantum Computation and Quantum Information (Cambridge University Press, Cambridge, 2000).
Perets, H. B. et al. Realization of quantum walks with negligible decoherence in waveguide lattices. Phys. Rev. Lett. 100, 170506 (2008).
Schreiber, A. et al. Photons walking the line: A quantum walk with adjustable coin operations. Phys. Rev. Lett. 104, 050502 (2010).
Broome, M. A. et al. Discrete single-photon quantum walks with tunable decoherence. Phys. Rev. Lett. 104, 153602 (2010).
Peruzzo, A. et al. Quantum walks of correlated particles. Science 329, 1500 (2010).
Schreiber, A. et al. Decoherence and disorder in quantum walks: From ballistic spread to localization. Phys. Rev. Lett. 106, 180403 (2011).
Matthews, J. C. F. et al. Simulating quantum statistics with entangled photons: a continuous transition from bosons to fermions. Sci. Rep. 3, 1539 (2013).
Owens, J. O. et al. Two-photon quantum walks in an elliptical direct-write waveguide array. New. J. Phys. 13, 075003 (2011).
Schreiber, A. et al. A 2d quantum walk simulation of two-particle dynamics. Science 336, 55 (2012).
Sansoni, L. et al. Two-particle bosonic-fermionic quantum walk via integrated photonics. Phys. Rev. Lett. 108, 010502 (2012).
Knill, E., Laflamme, R. & Milburn, G. A scheme for efficient quantum computation with linear optics. Nature (London) 409, 46 (2001).
Kok, P. & Lovett, B. W. Introduction to Optical Quantum Information Processing (Cambridge Press., 2010).
Amit, D. J., Parisi, G. & Peliti, L. Asymptotic behaviour of the ‘true’ self-avoiding walk. Phys. Rev. B 27, 1635 (1983).
Byrnes, C. & Guttmann, A. J. On self-repelling walks. J. Phys. A: Math. Gen. 17, 3335 (1984).
Schulz, B. M., Trimper, S. & Schulz, M. Feedback-controlled diffusion: From self-trapping to true self-avoiding walks. Phys. Lett. A 339, 224 (2005).
Tóth, B. & Vetö, B. Continuous time ‘true’ self-avoiding random walk on z (2010). arXiv:0909.3863.
Slade, G. The self-avoiding walk: A brief survey. Surveys in stochastic processes, European Mathematical Society, Zurich (eds. J. Blath, P. Imkeller, S. Roelly) 181 (2011).
Madras, N. & Slade, G. The self-avoiding walk (Springer (New York) 2013).
Brun, T. A., Carteret, H. A. & Ambainis, A. Quantum walks driven by many coins. Phys. Rev. A 67, 052317 (2003).
Flitney, A. P., Abbott, D. & Johnson, N. F. Quantum walks with history dependence. J. Phys. A: Math. Gen. 37, 7581 (2004).
McGettrick, M. One dimensional quantum walks with memory. Quant. Inf. Comp. 10, 0509 (2010).
Rohde, P. P., Brennen, G. K. & Gilchrist, A. Quantum walks with memory - goldfish, elephants and wise old men. Phys. Rev. A 87, 052302 (2013).
Bahi, J. M., Bienia, W., Cete, N. & Guyeux, C. Is protein folding problem really a np-complete one? first investigations (2013). arXiv:1306.1372.
Flory, P. J. The configuration of a real polymer chain. J. Chem. Phys. 17, 303 (1949).
Barr, K. et al. Self-avoiding quantum walks (2013). arXiv:1303.1966.
Acknowledgements
This research was conducted by the Australian Research Council Centre of Excellence for Engineered Quantum Systems (Project number CE110001013).
Author information
Authors and Affiliations
Contributions
J.T. provided the central idea, which was further developed by all authors. E.C. and P.P.R. developed the numerical codes and performed the analysis. All authors contributed to interpreting the data and writing the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. The images in this article are included in the article's Creative Commons license, unless indicated otherwise in the image credit; if the image is not included under the Creative Commons license, users will need to obtain permission from the license holder in order to reproduce the image. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/3.0/
About this article

Cite this article
Camilleri, E., Rohde, P. & Twamley, J. Quantum walks with tuneable self-avoidance in one dimension. Sci Rep 4, 4791 (2014). https://doi.org/10.1038/srep04791
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep04791
This article is cited by
-
Collider events on a quantum computer
Journal of High Energy Physics (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
