
Abstract
MS1 full scan based quantification is one of the most popular approaches for large-scale proteome quantification. Typically only three different samples can be differentially labeled and quantified in a single experiment. Here we present a two stages stable isotope labeling strategy which allows six different protein samples (six-plex) to be reliably labeled and simultaneously quantified at MS1 level. Briefly in the first stage, isotope lysine-d0 (K0) and lysine-d4 (K4) are in vivo incorporated into different protein samples during cell culture. Then in the second stage, three of K0 and K4 labeled protein samples are digested by lysine C and in vitro labeled with light (2CH3), medium (2CD2H) and heavy (213CD3) dimethyl groups, respectively. We demonstrated that this six-plex isotope labeling strategy could successfully investigate the dynamics of protein turnover in a high throughput manner.
Similar content being viewed by others


Introduction
Large scale proteome identification and quantification can be readily performed using liquid chromatography coupling with tandem mass spectrometry (LC-MS/MS). Thousands of proteins can be identified and quantified from complex biological samples in one experiment1,2. Proteome quantification on a global scale is essential to profile protein expression changes under different biological conditions3. Both in vivo metabolic isotope labeling and in vitro chemical isotope labeling have been widely utilized for accurate proteome quantification. Stable Isotope Labeling by Amino acids in Cell culture (SILAC) is performed by in vivo metabolic labeling at protein level during cell culture4, while dimethylation isotope labeling and isobaric labeling strategies, such as iTRAQ and Tandem Mass Tag (TMT), label digested peptides in vitro5,6. Currently, the isobaric labeling strategies can quantify as many as eight protein samples in parallel in one LC-MS/MS experiment7. Furthermore, 18-plex isotope labeling can be achieved by combining SILAC and iTRAQ8. However, ratio distortion is a common effect for iTRAQ due to protein quantification interference, which will compromise the proteome quantification accuracy9,10. In contrast, SILAC and dimethylation labeling quantification approaches rely on MS1 full scan and can generally each quantify up to three protein samples in one experiment8.
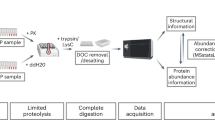
We developed a six-plex stable isotope labeling strategy by combing SILAC and dimethylation isotope labeling. Briefly, isotope differentiated lysine-d0 (K0) and lysine-d4 (K4) are in vivo incorporated into proteins during cell culture. Then, three of K0 and K4 labeled protein samples are in vitro labeled with light (2CH3), medium (2CD2H) and heavy (213CD3) dimethyl groups, respectively (Supplementary Information (SI), Fig. S1). As only peptides with lysine can be labeled by this six-plex isotope labeling approach (Table S1), lysine C is used as the digestion enzyme to ensure the digested peptides containing lysine amino acids. Thus, six protein samples can be isotopically labeled and simultaneously quantified in a single experiment. The mass difference between the nearest isotopic forms is 4 Da (Fig. S1 and Table S1), which is essential to limit isotopic cluster overlap in the MS spectra. Home-developed software Quant-ArMone was used for proteome quantification by using six-plex isotope labeling strategy (Fig. 1 and Fig. S2) and the quantification accuracy was demonstrated. Finally, this six-plex isotope labeling strategy was applied to investigate the dynamics of protein turnover and the 50% turnover time of 1365 proteins were successfully obtained.

Schematic diagram for processing the datasets of six-plex isotope labeling and protein turnover analyses.
All acquired raw files were converted to *.mgf files using DTASupercharge (v2.0a7), followed with database searching with Mascot Version 2.3.0 (Matrix Science). Then, Quant-ArMone was used to determine the position of the identified peptide in its belonged six-plex isotopic forms and the corresponding precursor masses and charge of six-plex in MS1 can be calculated and used for feature detection. Isotope Pattern Calculator was implemented to calculate the relative intensities of isotope peaks for deconvolution. In a MS1 scan, one label form with at least three isotope peaks will be seen as a significant signal and peak hill over the retention time range present in over five consecutive scan was used for quantification. In protein turnover analyses, relative isotope abundance (RIA) K4/(K0 + K4) for each time point was calculated. The six-plex XICs in one experiment represent three time points and three RIA can be calculated.
Results
Quant-ArMone software for the proteome quantification of MS1 results
Currently, no software is available for the quantitative analysis of six-plex datasets. Therefore, we developed a new software for quantitative proteomics called Quant-ArMone (Fig. 1 and Fig. S2). This proteome quantification software builds upon the previous proteomics data processing platform termed ArMone11. A detail description of the algorithms at the core of Quant-ArMone is provided in the methods section. We firstly tested whether Quant-ArMone is comparable to other quantification software. In particular, Quant-ArMone was compared with MSQuant, which is widely used for proteome quantification analyses based on stable isotope labeling12. Briefly, 25 μg of tryptic digests of proteins extracted from mouse brain were labeled using light (2CH3) and heavy (213CD3) dimethylation labeling reagents, respectively. As well, 100 μg of the tryptic digests was labeled with medium (2CD2H) labeling reagent. Then, the three samples were combined and analyzed by strong cation exchange-reversed phase (SCX-RP) online two-dimensional (2D) LC-MS/MS system. Mascot was used to identify peptides and proteins present in the samples. Then, MSQuant and Quant-ArMone were both used to quantify the proteins identified by Mascot. Respectively, 930 and 916 distinct proteins were quantified using MSQuant and Quant-ArMone and 895 (97%) proteins were quantified by both software. The log2 ratio distribution profiles obtained by these two quantification software were both symmetrically distributed around the theoretically values (Fig. S3) and the quantification accuracy was comparable. Overall, Quant-ArMone provides similar quantitative results to the established MSQuant software in three-plex MS1 quantification. However, Quant-ArMone is the only software that can handle six-plex MS1 quantification currently.
Performance of proteome quantification by the Six-plex isotope labeling strategy
Two types of replicate analyses were performed to evaluate the performance of the six-plex quantification strategy. In the first type of replicate analysis, HeLa cells were fully labeled with medium containing K0 or K4 amino acids in two plates. 15 μg of identical protein samples extracted from K0 or K4 labeled Hela cells were digested and labeled with light, medium, or heavy dimethyl groups, respectively. Then, these six protein samples were equally mixed together and analyzed by SCX-RP 2D LC-MS/MS system. Protein identification was performed by Mascot whereas six-plex proteome quantification was performed by Quant-ArMone (Fig. 1 and Fig. S2). Finally, 5306 unique peptides were positively identified, among which 3786 (71%) unique peptides were successfully quantified for all of the six protein samples, corresponding to 1239 distinct protein groups. Accurate quantification was achieved across all of the six isotopic forms with ~96% of peptides and proteins without significant changes (within the range of [0.5, 2] relative ratio) (SI S2). Furthermore, log2 ratio distributions of peptides and proteins are both normally and symmetrically distribute around the theoretic values (Fig. 2a and b). Therefore, all of the six protein samples come from two different cell lines (K0 and K4 labeled) can be accurately quantified by using Quant-ArMone.

Log2 ratios distribution of (a, c) unique peptides and (b, d) distinct proteins obtained by quantitative proteome analysis of six HeLa cell samples in one SCX-RP 2D LC-MS/MS analysis using six-plex isotope labeling strategy.
Lysine C was used as digestion enzyme. (a, b) six HeLa cell samples (from two culture plates) were mixed with 1:1:1:1:1:1 ratio, most of the Log2 ratios are closed to 0; (c, d) six HeLa cell samples (from six culture plates) were mixed with 1:2:3:6:1:2 ratio. All the distributions for peptides and proteins are normal and symmetric around the theoretical ratios.
In the second type of replicate analysis, three HeLa cell cultures were separately labeled with medium containing K0 amino acids and three others labeled with K4 amino acids for a total of six plates. The remaining processing steps are the same as described above except the six protein samples are mixed with 1:2:3:6:1:2 ratio before analysis. After data processing, 4552 (73%) unique peptides were successfully quantified from 6246 identified peptides for all of the six protein samples, corresponding to 1388 distinct protein groups. Accurate quantification results were also obtained across all of the six biological replicate samples with ~93% of the Log2 ratios of both peptides and proteins are within one fold change from theoretical ratios (Fig. 2c and d, SI S3). Therefore, high throughput and high accurate proteome quantification can be achieved in both technological and biological replicate analyses by the six-plex labeling strategy.
High-throughput protein turnover analysis by the six-plex isotope labeling strategy
The steady state levels of proteins are maintained through a balance between protein synthesis and degradation. Disturbances in this balance are often related to abnormal physiological and pathological status, such as cancer13. Investigating the dynamics of protein synthesis and degradation, as well as the protein turnover time can enhance our understanding of biological processes14. Pulsed SILAC labeling strategy has been extensively applied to study the dynamics of protein turnover in different biological systems15,16,17. Usually, more than five time points are necessary to measure protein turnover dynamics. Unfortunately, the current pulsed SILAC approach is time consuming as each time point requires a quantitative proteome analysis. In contrast, our six-plex isotope labeling strategy can be used to obtain protein turnover dynamics by doing only two experiments to monitor six time points (Fig. 3), which greatly simplifies the processes protein turnover analysis. Here, this approach is exemplified for the study of protein turnover dynamics in HeLa cells across six time points (Table S2). Briefly, six plates of HeLa cells cultures in K4 SILAC were transferred into K0 SILAC for different length of time as described in methods section (Fig. S4). Decreases over time in the signals for the K4 SILAC labeled peptides are related to protein degradation whereas increases in the K0 SILAC labeled peptides are related to new protein syntheses (Fig. 3). Protein turnover dynamics were measured for 4878 unique peptides from 1365 distinct proteins observed in at least three time points (Fig. 4a and SI S4). As well, the 50% turnover time, defined as the time point at which the intensities of the K4 and K0 are equal, was calculated for each of the 1365 proteins (SI S4). The average 50% turnover time for all the proteins is ~20 hrs and 91% of the proteins are within the range from 10 to 30 hrs (Fig. 4a). The 50% turnover time of 822 proteins in our study were also obtained in previous reports by using conventional double pulsed SILAC strategy16,17 and the coefficient of variations (CVs) of 655 proteins (80%) are ≤−0.3 in these two analyses (SI S5). Therefore, the protein turnover results obtained by the six-plex isotope labeling strategy are consistent to conventional SILAC strategy. However, protein samples at three time points can be simultaneously quantified in just one experiment in our six-plex strategy, in contrast to separate quantification experiment is needed for each time point in conventional strategy.

Schematic diagram for investigating the dynamics of protein synthesis and degradation by using six-plex isotope labeling strategy.
As both SILAC and dimethylation isotope labeling methods were feasibly combined in the six-plex isotope labeling strategy, pulsed SILAC samples in three time points could be labeled with light, medium and heavy dimethyl groups and compared in one experiment. And six times points could be feasibly monitored in two LC-MS/MS experiments.

(a) the distribution of 50% turnover time for the 1365 detected proteins; (b) the turnover fitting curves for five multicopy maintenance (MCM) proteins and three histones. Red: fitting curves for proteins; Grey: fitting curves for peptides.
Discussion
We have developed a six-plex strategy for quantitative proteomics. As well, we have developed a software called Quant-ArMone for the quantitative analysis of the six-plex datasets. Quant-ArMone appears to be as performant as conventional algorithms such as MSQuant for the quantitative analysis of proteomic results. Furthermore, Quant-ArMone is the only software capable of handling the six-plex datasets. When six identical protein samples were used to investigate the performance of this six-plex strategy, ~96% of the peptides and proteins were accurately quantified among the six protein samples with relative ratios in the range from 0.5 to 2. The quantification accuracy of this six-plex labeling strategy is comparable to conventional dimethylation and SILAC strategies as described in our previous works (Fig. S3 and Fig. S6)18,19. More complex biological replicate protein samples with a short dynamic range were further exemplified and high quantification accuracy were still achieved (Fig. 2 a–d).
The six-plex labeling strategy and Quant-ArMone were used to study protein turnover dynamics in HeLa cells over a 48 hours period. The bulk of the proteins had a 50% turnover time of ~20 hrs. Interestingly, the multicopy maintenance (MCM) proteins initially thought to be only involved in DNA replications are also involved in gene expression regulation, damage response and chromatin remodeling. Although their levels are not expected to change during the cell cycle, they are known to be polyubiquitinated and to be degraded by the proteasome. We obtained 50% turnover values of ~15 hrs for six members of the MCM protein family, indicating faster than average protein turnover, especially MCM7 exhibited a 50% turnover time ~10 hrs (Fig. 4 b–f, Fig. S7 and SI S4)20. This is likely a reflection of the need to rapidly degrade MCM proteins following their involvement in chromosomal processes. Furthermore, although some of the histones were reported as long-lived proteins in rat brain, the 50% turnover values of the 22 detected histone proteins are all closed to 21 hrs in Hela cells (Fig. 4 g–i and SI S4), which might be due to the relatively rapid turnover of cancer cell lines14,21.
In summary, a six-plex stable isotope labeling strategy was successfully developed and six different protein samples can be differentially labeled and quantified at MS1 level in a single experiment. Because all of the quantification information is obtained from a single MS1 scan, variations due to LC separation, ionization and MS detection can be reduced. Finally, the six-plex isotope labeling strategy was successfully applied to investigate the dynamics of protein turnover in Hela cells. We believe that the six-plex labeling strategy can be applied to different types of high-throughput proteome quantification analyses.
Methods
Cell culture, harvest and lysis
To investigate the dynamics of protein synthesis and degradation, six plates of Hela cells were cultured in lysine-depleted 1640 medium supplemented with heavy lysine-d4 (K4) and 10% dialyzed fetal bovine serum (FBS) and were incubated at 37°C in a humidified atmosphere of 5% CO2. After six doublings, the “heavy” medium was removed and the cells were quickly washed twice with sterile PBS. The cells were then incubated in normal 1640 medium containing light Lysine-d0 (K0) for 0, 3, 6, 12, 24 and 48 hrs (Fig. S4). Then the cells were washed with ice-cold PBS, pelleted by centrifugation. And the same amount (1 × 107 cells) of harvested Hela cells at each time point were resuspended in lysis buffer (50 mM Tris-HCl, pH 8.2 + 8 M urea + protease inhibitor cocktail, pH 8.2) and sonicated three times for 30 s (200 W) with at least 1 min on ice between two pulses. The cell lysate was centrifugated at 25 000 g and the supernatant was kept for following preparation.
For six-plex isotope labeling strategy testing, Hela cells were cultured in lysine-depleted 1640 medium supplemented with either K0 or K4 in two or six plates. After six doublings, the “light” and “heavy” labeled cells were harvested and lysised, respectively, as described above.
Protein sample preparation and dimethylation isotope labeling
The proteins within the supernatant were precipitated by chloroform/methanol precipitation. After washing with methanol, the pellets were resuspended in 1 mL denaturing buffer containing 50 mM TEAB (pH 8.1) and 8 M urea and the protein concentration was determined by Bradford assay. The protein samples were reduced by DTT at 37°C for 2 hrs and alkylated by iodoacetamide in dark at room temperature for 40 min. Then, the sample solution was diluted to 1 M urea by using 50 mM TEAB (pH 8.1) and lysine C was added with weight ratio of enzyme to protein at 1/50 and incubated at 37°C overnight. 100 μg of the protein digest was loaded onto a 100 mg homemade C18 solid phase extraction (SPE) column and labeled by 5 mL of light (0.2% CH2O and 30 mM NaBH3CN), medium (0.2% CD2O and 30 mM NaBH3CN), or heavy (0.2% 13CD2O and 30 mM NaBD3CN) dimethylation reagents6. After a wash with 1 mL 0.1% formic acid (FA) aqueous solution, the isotopic labeled peptides were eluted from the C18 SPE column using 1 mL 80% ACN. Then, the comparative samples were mixed together with specific ratio and lyophilized (Fig. S1).
Online two-dimensional LC-MS/MS analysis
The lyophilized sample was re-dissolved into 0.1% FA solution and loaded onto a 200 μm i.d. × 7 cm strong cation exchanged (SCX) monolithic column for online multidimensional analysis22. 0.1% formic acid in water (solvent A) and 0.1% formic acid in ACN (solvent B) were used for RP gradient separation and the RP binary gradient was set as follows: from 1–10% solvent B 5 min, from 10–35% solvent B 150 min, from 35–90% solvent B 5 min, after flush with 90% solvent B for 8 min the system was equilibrated by solvent A for 12 min. Then, a series of salt steps elution were applied to fractionate the SCX monolith trapped peptides to the separation column. The NH4AC (pH 2.7) salt steps were as follows: 50, 100, 150, 200, 250, 300, 350, 400, 500 and 1000 mM (for protein synthesis and degradation analysis, two more fractions 450 and 700 mM were added). Each salt step lasted 8 min (the final one 10 min) with a flow rate 300 nL/min, followed with a RP binary gradient separation and MS detection as described above.
The LTQ-OrbiTrap XL (Thermo, San Jose, CA) was used for MS detection. The temperature of the ion transfer capillary was 200°C, the electrospray voltage was +1.8 kV and the normalized collision energy was 35%. The MS full scan was acquired from m/z 400 to 2000 in OrbiTrap with a resolution of 60,000 in centroid mode and the MS/MS scan was acquired in LTQ linear ion trap. All MS and MS/MS spectra were acquired in the data dependent analysis (DDA) mode, in which the 6 most intense ions with MS scan were selected for MS/MS scan by collision induced dissociation (CID). Preview mode was enabled to exclude the precursors with unknown or +1 charge. The automatic gain control (AGC) and maximum ion injection time were set to 1 × 106 and 500 ms and 1 × 104 and 50 ms for MS and MS/MS scan, respectively. The dynamic exclusion function was: repeat count 1, repeat duration 60 s and exclusion duration 180 s.
Data processing
All acquired raw files were converted to *.mgf files using DTASupercharge (v2.0a7). Then the *.mgf files were searched against a recently released NCBI human protein database (10 March 2013, 35922 entries) downloaded from ftp://ftp.ncbi.nih.gov/refseq/H_sapiens/mRNA_Prot/human.protein.faa.gz, using Mascot Version 2.3.0 (Matrix Science) in decoy searching mode to evaluate the false discovery rate (FDR). Cysteine residues were searched as static modification of +57.0215 Da, methionine residues as variable modification of +15.9949 Da. All of the isotope labeled peptides amino termini and lysine residues were set as variable modification as Dimethyl: +28.0313 Da, Dimethyl:2H(4): +32.0564 Da and Dimethyl:2H(6)13C(2): 36.0757 Da for both K and N-term; and DimethylK4: +32.0564 Da, Dimethyl:2H(4)K4: +36.0815 Da and Dimetyl:2H(6)13C(2)K4: 40.1008 Da for K only. Peptides were searched using fully tryptic cleavage constraints and up to two missed cleavages sites were allowed for tryptic digestion. The mass tolerances were 10 ppm for parent masses and 0.8 Da for fragment masses.
A well-establish application termed Percolator was used to validate the search results23. The stand alone tool of Mascot Percolator (version 2.00)24 and Percolator (version 2.04) were downloaded from http://www.sanger.ac.uk/resources/software/mascotpercolator/. Automatic decoy database search in mascot was performed, so the generated result file (.dat) contains the entire target and decoy matches. The program was executed with “java -Xm × 1024 m -cp MascotPercolator.jar cli.MascotPercolator -rankdelta 1 -target filepath -decoy filepath -out filepath”, where the “-target” and “-decoy” shared the same path of the .dat file. Result files were generated contain a log file, a target peptide list and a decoy peptide list and for each item in the peptide lists a q-value was reported. In this work the identified peptides with q-value < 0.05 were reserved for quantitative analysis.
Since this is a novel six-plex isotope labeling strategy, there is no appropriate software solution at present. Therefore, we developed a new quantitative analysis platform termed Quant-ArMone to fulfill this requirement (Fig. 1 and Fig. S2). In addition to the basic function of isotope labeling based quantification, protein turnover analysis related features were also contained. This software is free for academic use and can be downloaded at http://www.bioanalysis.dicp.ac.cn/proteomics/software/Quant-ArMone.html.
Quant-ArMone mainly deals with MS data obtained by high resolution mass spectrometer, such as LTQ Orbitrap. The supported spectra data formats were .mzXML and .mzData. In theory, peptide contains lysine residues may display a six-plex XIC (extracted ion chromatogram) in our labeling strategy. According to the isotope labels in an identified peptide, we can determine the position of this peptide in its belonged six-plex. Then the corresponding precursor masses and charge of six-plex can be calculated and used for feature detection. The molecular mass difference between the nearest isotopic forms is 4 Da for peptides with one lysine amino acid, which means that regardless of the charge state of the precursor ions the 5th isotope peak of a isotopic form will be overlapped with the monoisotopic peak of the next near isotopic cluster. Therefore for each isotopic label form the first four peaks were used for calculated the intensity. The influence of overlapped isotope clusters was also considered. A software tool named Isotope Pattern Calculator (IPC) download from http://omics.pnl.gov/software/IPC.php was used to calculate the relative intensities of isotope peaks and the overlapped portion were deducted25. In a MS1 scan one label form with at least three isotope peaks will be seen as a significant signal and peak hill over the retention time range present in over five consecutive scan was used for quantification. First the centroid of chromatographic peak will be determined by looking for local maximum and then the peak will extend to intensity drop to zero or local minima on both sides. Only one local intensity maximum was retained in a peptide's elution profile. If a plurality of local maxima were detected, the peak covered more retention time points of identified MS2 scans will be selected. The total intensity of this peak was used to calculate the peptide ratio. Typically chromatographic shifts between isotopologues will not be large, but different peptide ions overlapped in m/z in adjacent retention time will increase the deviation. Therefore if the distance between two centroids of peaks is greater than the peak widths, this quantification is probably not precise and will be discarded. From our limited experience this method shows favorable simplicity, effectiveness and robustness. Normalization of ratios can be selected to correct the errors of loading amount of protein samples. Results of multiple salt gradients in a same experiment will be combined. Protein ratio can be obtained according to the median estimate of its peptide ratios (Fig. 1 and Fig. S2).
In protein turnover analysis relative isotope abundance (RIA) was needed, which is generally obtained as the ratio of degradative peptide to the total amount of degradative and synthetic peptide. In this experiment the six-plex XIC represent three time points and the corresponding RIA: K4/(K0 + K4) for each time point can be calculated (Figure 1). For the dynamic analysis of protein turnover, four integrate quantitative results were obtained (0 h, 3 h, 6 h; 0 h, 3 h, 48 h; 6 h 12 h, 24 h; 12 h, 24 h, 48 h, Table S2), each of which contained information of three time point and general every time point had a technology replication. The RIA of protein was calculated as the median of all the peptide RIAs. Only protein detected in three or more time point were used for further analyses. In theory, the RIA at each time point will fit to an exponential function26:

The fitting curve for every protein was calculated to match to this function. The RIA0 and RIA∞ represent the RIA at t = 0 and t = ∞ and kloss is a constant rate of degradation. When the calculated RIA∞ was less than 0, it was set as 0. If the correlation coefficient was less than 0.8, the ratio point with max offset was discarded and recalculated. Then fittings with correlation coefficient less than 0.8 were discarded. Finally the corresponding 50% turnover time and kloss were obtained (Fig. 1 and SI S4).
The fitting curves for all detected proteins (SI S6) can be obtained at http://www.bioanalysis.dicp.ac.cn/proteomics/software/Quant-ArMone.html.
References
Nilsson, T. et al. Mass spectrometry in high-throughput proteomics: ready for the big time. Nat. Methods 7, 681–685 (2010).
Ning, Z., Zhou, H., Wang, F., Abu-Farha, M. & Figeys, D. Analytical aspects of proteomics: 2009–2010. Anal. Chem. 83, 4407–4426 (2011).
Ong, S.-E. & Mann, M. Mass spectrometry-based proteomics turns quantitative. Nat. Chem. Biol. 1, 252–262 (2005).
Ong, S. E. et al. Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics. Mol. Cell. Proteomics 1, 376–386 (2002).
Ross, P. L. et al. Multiplexed protein quantitation in Saccharomyces cerevisiae using amine-reactive isobaric tagging reagents. Mol. Cell. Proteomics 3, 1154–1169 (2004).
Boersema, P. J., Raijmakers, R., Lemeer, S., Mohammed, S. & Heck, A. J. R. Multiplex peptide stable isotope dimethyl labeling for quantitative proteomics. Nat. Protocols 4, 484–494 (2009).
Werner, T. et al. High-Resolution Enabled TMT 8-plexing. Anal. Chem. 84, 7188–7194 (2012).
Dephoure, N. & Gygi, S. P. Hyperplexing: a method for higher-order multiplexed quantitative proteomics provides a map of the dynamic response to rapamycin in yeast. Sci. Signal. 5, rs2 (2012).
Wenger, C. D. et al. Gas-phase purification enables accurate, multiplexed proteome quantification with isobaric tagging. Nat. Methods 8, 933–935 (2011).
Ting, L., Rad, R., Gygi, S. P. & Haas, W. MS3 eliminates ratio distortion in isobaric multiplexed quantitative proteomics. Nat. Methods 8, 937–940 (2011).
Jiang, X., Ye, M., Cheng, K. & Zou, H. ArMone: a software suite specially designed for processing and analysis of phosphoproteome data. J. Proteome Res. 9, 2743–2751 (2010).
Mortensen, P. et al. MSQuant, an open source platform for mass spectrometry-based quantitative proteomics. J. Proteome Res. 9, 393–403 (2010).
Eden, E. et al. Proteome half-life dynamics in living human cells. Science 331, 764–768 (2011).
Savas, J. N., Toyama, B. H., Xu, T., Yates, J. R., 3rd & Hetzer, M. W. Extremely long-lived nuclear pore proteins in the rat brain. Science 335, 942 (2012).
Doherty, M. K. & Whitfield, P. D. Proteomics moves from expression to turnover: update and future perspective. Expert. Rev. Proteomics 8, 325–334 (2011).
Boisvert, F. M. et al. A quantitative spatial proteomics analysis of proteome turnover in human cells. Mol. Cell. Proteomics 11, M111 011429 (2012).
Ahmad, Y., Boisvert, F. M., Lundberg, E., Uhlen, M. & Lamond, A. I. Systematic analysis of protein pools, isoforms and modifications affecting turnover and subcellular localization. Mol. Cell. Proteomics 11, M111 013680 (2012).
Wang, F. et al. A Fully Automated System with Online Sample Loading, Isotope Dimethyl Labeling and Multidimensional Separation for High-Throughput Quantitative Proteome Analysis. Anal. Chem. 82, 3007–3015 (2010).
Wang, F. et al. Combination of online enzyme digestion with stable isotope labeling for high-throughput quantitative proteome analysis. Proteomics 12, 3129–3137 (2012).
Meierhofer, D., Wang, X., Huang, L. & Kaiser, P. Quantitative analysis of global ubiquitination in HeLa cells by mass spectrometry. J. Proteome Res. 7, 4566–4576 (2008).
Cambridge, S. B. et al. Systems-wide proteomic analysis in mammalian cells reveals conserved, functional protein turnover. J. Proteome Res. 10, 5275–5284 (2011).
Wang, F., Dong, J., Jiang, X., Ye, M. & Zou, H. Capillary trap column with strong cation-exchange monolith for automated shotgun proteome analysis. Anal. Chem. 79, 6599–6606 (2007).
Kall, L., Canterbury, J. D., Weston, J., Noble, W. S. & MacCoss, M. J. Semi-supervised learning for peptide identification from shotgun proteomics datasets. Nat. Methods 4, 923–925 (2007).
Brosch, M., Yu, L., Hubbard, T. & Choudhary, J. Accurate and sensitive peptide identification with Mascot Percolator. J. Proteome Res. 8, 3176–3181 (2009).
Cappadona, S. et al. Deconvolution of overlapping isotopic clusters improves quantification of stable isotope-labeled peptides. J. Proteomics 74, 2204–2209 (2011).
Pratt, J. M. et al. Dynamics of protein turnover, a missing dimension in proteomics. Mol. Cell. Proteomics 1, 579–591 (2002).
Acknowledgements
The authors wish to thank Dr. D. Figeys and Dr. R. Tian for editing the manuscript. HZ would like to acknowledge the financial supports from the China State Key Basic Research Program Grant (2013CB-911203, 2012CB-910601 and 2012CB-910101), the Creative Research Group Project by NSFC (21021004), the Analytical Method Innovation Program of MOST (2012IM030900) and FW would like acknowledge the financial support from “Hundred Talent Young Scientist Program” by DICP.
Author information
Authors and Affiliations
Contributions
H.Z. and F.W. designed the study. F.W. performed most of the experiments of dimethylation labeling and LC-MS/MS experiments. K.C. developed proteome quantification software and analyzed the datasets. X.W. cultured all the cell lines and performed pulsed SILAC labeling. H.Q. and R.C. participated in isotope labeling of protein samples. J.L. participated in LC-MS/MS analysis. F.W. and H.Z. wrote the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Supplementary Information
Supplementary Information S1
Supplementary Information
Supplementary Datasets
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/
About this article
Cite this article
Wang, F., Cheng, K., Wei, X. et al. A six-plex proteome quantification strategy reveals the dynamics of protein turnover. Sci Rep 3, 1827 (2013). https://doi.org/10.1038/srep01827
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep01827
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
