
Abstract
We describe a spatially contiguous, temporally consistent high-resolution gridded daily meteorological dataset for northwestern North America. This >4 million km2 region has high topographic relief, seasonal snowpack, permafrost and glaciers, crosses multiple jurisdictional boundaries and contains the entire Yukon, Mackenzie, Saskatchewan, Fraser and Columbia drainages. We interpolate daily station data to 1/16° spatial resolution using a high-resolution monthly 1971–2000 climatology as a predictor in a thin-plate spline interpolating algorithm. Only temporally consistent climate stations with at least 40 years of record are included. Our approach is designed to produce a dataset well suited for driving hydrological models and training statistical downscaling schemes. We compare our results to two commonly used datasets and show improved performance for climate means, extremes and variability. When used to drive a hydrologic model, our dataset also outperforms these datasets for runoff ratios and streamflow trends in several, high elevation, sub-basins of the Fraser River.
Design Type(s) | modeling and simulation objective • process-based data transformation objective |
Measurement Type(s) | climate |
Technology Type(s) | digital curation |
Factor Type(s) | temporal_interval |
Sample Characteristic(s) | Canada • contiguous United States of America • State of Alaska • climate system |
Machine-accessible metadata file describing the reported data (ISA-Tab format)
Similar content being viewed by others

Background & Summary
Climate datasets suitable for trend and extremes analysis enable investigation of the unique challenges facing hydrology today. Temporally consistent datasets better facilitate statistical downscaling and hydrologic modelling by reducing spurious statistical relationships1,2. Long-term records are more likely to include observed extreme events that can be used to test modelling frameworks3–5 and are better suited to carry out detection and attribution analysis6. Currently a long-term, spatially contiguous and temporally consistent gridded meteorological dataset does not exist for northwestern North America (NWNA), 40°N to 72°N and 169°W to 101°W, a region that contains five major drainage basins, the Yukon, Mackenzie, Saskatchewan, Fraser and Columbia. These watersheds have substantial topographic complexity and highly variable climates, which are known to be affected by climate change7,8.
To maximize spatial coverage, most gridded meteorological datasets have been based on numerous, often not homogenized, stations of variable record lengths that drop in and out over the timeframe of the dataset9,10. These datasets are subject to inhomogeneities that can affect trends or the statistics associated with extremes. Some have attempted to make adjustments so that trends in the gridded dataset match those of long-term stations11, while others include a disclaimer stating the data are not intended for use in trend analysis12. Homogenized, or temporally consistent, station networks exist in Canada and the US although with a low station density. Hence, they have not been the foundation of the gridded datasets more commonly used with hydrologic modelling or statistical downscaling.
The mountains of western NA provide the majority of the source water to the region’s major rivers13. To account for the lack of climate stations at high elevations, interpolation methods often include elevation as a predictor and sometimes include an additional bias correction against a gridded climatology10,14. For example, elevation was used as a predictor with the Australian National University Spline (ANUSPLIN) algorithm15 to create one of the most commonly used gridded meteorological datasets in Canada16, which we refer to as NRCANmet. However, this dataset has known deficiencies for high elevation precipitation17,18. One study in New Zealand19 showed that using a high-resolution climate normal as a predictor with the spline algorithm, in place of elevation, improved the interpolation of precipitation. Several high-resolution climatologies in NWNA were recently updated to incorporate information from more climate stations20,21. One, in British Columbia, was also adjusted against snow course measurements and glacier coverage20.
We describe the development of a new, temporally consistent gridded daily meteorological dataset for NWNA covering 1945 through 2012. We refer to this dataset as PCIC meteorology for NWNA, or PNWNAmet. We interpolate a set of long-term homogenized stations with the thin plate spline algorithm using a high resolution, high station density climatology as a predictor. The following will provide a detailed description of the methodology used to create this dataset and its technical evaluation, which includes four main components. First, precipitation, and minimum and maximum temperature from our gridded meteorological dataset and two others commonly used in hydrologic modelling in regions of NWNA, are evaluated with standardize performance measures against an independent climate network for climatology, extremes and variability. Second, their climatologies are compared spatially over NWNA and their climate variability compared temporally by major basin. Third, differences in the water balance between the three datasets is evaluated using observed streamflow through assessment of runoff/precipitation ratios. Fourth, the streamflows simulated by a (calibrated) hydrologic model when driven with the three datasets are evaluated relative to observed streamflow through assessment of streamflow trends.
Methods
Primary Data – Stations and Reanalyses
Daily minimum temperature, maximum temperature, and precipitation station records for western Canada were obtained from the second generation of Environment and Climate Change Canada’s (ECCC) Adjusted and Homogenized Canadian Climate Data (AHCCD)22–24, a homogenized subset of ECCC’s Historical Climate Data (HCD). Corresponding daily data from the conterminous United States was obtained from the United States Historical Climatology Network-Daily (USHCN-Daily), a stable, long-record subset of the US Cooperative Observer Program (COOP) network only available in the conterminous US25. Daily data (not homogenized) in Alaska were obtained from the Global Historical Climatology Network-Daily (GHCN-Daily)26.
To maximize temporal consistency in the dataset, selected stations had to have at least 40 years of complete record (<10% missing days within a year) over the 1945–2012 period. To supplement areas with sparse observations along the periphery of the domain, specifically around the western and northern coasts of Alaska, daily outputs from the 20th Century Reanalysis V2 (20CR2)27 were used as virtual stations. This was the only reanalysis spanning the desired period of 1945-2012 for PNWNAmet. Excluding the 20CR2 series, a median of 389 temperature stations (minimum of 322 and maximum of 422) were reported each year; for precipitation, the median number of reporting stations was 442 (minimum of 262 and maximum of 476). Maximum station density in PNWNAmet is given in Fig. 1. Station density is highest in the conterminous United States and southern Canada, decreases with increasing latitude and is lowest in northern Canada, Alaska and northeastern British Columbia.

The location of the 20CR, meteorological and ARDA stations, domains of the PNWNAmet, NRCANmet and PBCmet gridded meteorological dataset, sub-regions, and sub-basins of the Thompson (itself a sub-basin of the Fraser River basin; see inset).
Scaling Data – ClimateWNA v5.10
The high-resolution climatology predictor in the thin plate spline interpolation algorithm was derived from ClimateWNA, which is a tool that produces a scale-free, smooth at the boundaries, gridded climatology from a mosaic of disparate climatology products28–30. The individual climatologies used, which were the latest available for the provinces, territories and states within NWNA circa 2014, are described in Table 1.
The climatologies were extracted from ClimateWNA to a target resolution of 0.0625° (~6 km) using bilinear interpolation with an elevation adjustment. Elevation was derived from the GEMTED2010 digital elevation model (DEM)31, clipped to match the ocean/land boundary. This DEM was selected for its global availability, including areas north of 60°N. Within ClimateWNA all 1961–1990 climatologies were temporally adjusted to the 1971–2000 reference period using anomalies obtained from the CRU ts3.21 dataset28,32. Spatial discontinuities between individual climatologies were removed using a gradient merge with a 50-km overlap. This consists of assigning equal weight (50%) to the two overlapping products at the centre of the overlap, then gradually reducing the weights to 0 and 100% at the edges28. The result is a single 0.0625°, spatially homogeneous, 1971–2000 monthly precipitation, minimum temperature and maximum temperature climatology that crosses several jurisdictional boundaries.
Interpolation – Thin Plate Spline
PNWNAmet was created using the trivariate thin plate spline interpolation method, as implemented by Nychka et al.33, which is similar to the method used in Canada’s NRCANmet dataset16,34. As with NRCANmet, minimum temperature, maximum temperature and binary precipitation occurrence and square-root transformed precipitation amounts were interpolated separately on each day, combined, and transformed back to original units. Specifically, values at grid points where the interpolated occurrence exceeded a value of 0.5 were set equal to the interpolated precipitation amount; otherwise, values were set to zero. Instances of maximum temperature less than minimum temperature are possible, and values were simply switched in those cases.
In contrast with NRCANmet, PNWNAmet uses ClimateWNA v5.10 monthly climate normals rather than elevation as the third predictor variable. The rationale is that temporal homogeneity in PNWNAmet is obtained via the use of a relatively small, but fixed number of long record, temporally consistent, daily stations. Additional spatial information is then derived from the underlying climatology. Although the source climatology likely uses the same stations as PNWNAmet, the individual climatologies in Table 1 are constructed from a much larger number of stations, including proxies based on glacier or snow measurements20,21. Those climatologies based on the Parameter Regression on Independent Slopes Model (PRISM) also account for additional mechanisms such as temperature inversions and coastal influences. Relying on a mosaic of disparate climatology products is expected to introduce some spatial inconsistency in the final interpolated meteorological fields. However, we feel that any residual spatial inconsistency in the merged ClimateWNA is insignificant compared to any errors that may occur due the interpolation process itself.
In general, thin plate splines are not scale invariant because three covariates, in this case, latitude, longitude and a climate normal appear in a nonlinear term in the interpolation equation. Two estimates of generalization error were used to select optimal scale factors for the climate normal predictor: (1) the generalized cross-validation error, which is calculated as part of the thin plate spline algorithm, and (2) errors based on 10 withheld stations. The 10 stations are drawn from a pool of 50 used by Hutchinson et al.15 to evaluate NRCANmet across Canada, but restricted to the BC part of the PNWNAmet domain. Minimum and maximum temperature (in °C) and precipitation (in mm) climate normal predictors were scaled by factors of 1/20 and 1/300, respectively. See Boer et al.35 for full equations and an explanation of how the scaling factors are used. After interpolation, the raw daily minimum temperature, maximum temperature and precipitation surfaces were rescaled so that their climatological monthly means matched the 1971–2000 ClimateWNA v5.10 normals following Hunter and Meetemeyer36.
The source data used for PNWNAmet is primarily based on observations collected at fixed times, based on a climate day that does not coincide with the calendar day (i.e. observation times are offset from midnight local time). Offset observations times can result in biases in reported daily maximum and minimum temperature37. Changes in the observing day over time also confounds climatic trends38 and compiling stations with different observation times can distort areal patterns. Precipitation measurement errors can also affect precipitation trends39. We attempt to minimize these effects in the PNWNAmet via the careful selection of source data. For the Canadian AHCCD stations, temperature and precipitation are homogenized to remove any temporal inconsistencies and step changes22,23, which are primarily due to station relocations and changes in observing practices41. Daily minimum temperature data are further corrected to account for network-wide observation time changes that occurred in 1961 at synoptic stations23. In addition, the precipitation data have been corrected for gauge undercatch, evaporation and wetting losses22. Although not explicitly homogenized, the USHCN-Daily data are a sub-set of mostly COOP stations that have been selected using several criteria, but primarily based on the degree to which a station maintained a constant observing time40. The USHCN-Daily station data was also subject to a number of additional quality assurance checks. Outside the conterminous US, we used GHCN-Daily data, which, although subject to some additional quality assurance26, has not undergone any selection or corrections for observation time inconsistencies. Although efforts have been made to select the best available data, the source data are still subject to inconsistencies between observing times within and between networks, which will introduce uncertainties in the resulting interpolated surfaces.
Data Records
The resulting 1945–2012 Northwestern North America (NWNA) gridded meteorological dataset, PNWNAmet, contains daily precipitation, minimum temperature and maximum temperature gridded to a spatial resolution of 0.0625°. This dataset described is freely available from figshare (Data Citation 1). The data records are stored as four separate variables in a single netCDF file. A duplicate of the dataset is also archived at the Pacific Climate Impacts Consortium’s public and persistent data portal at http://tools.pacificclimate.org/dataportal/gridded_observations/map/.
Technical Validation
We tested gridded PNWNAmet results and two gridded meteorological datasets commonly used with statistical downscaling and hydrologic modelling in the NWNA region, NRCANmet and PBCmet, against historical station observations from the Agricultural and Rural Development Act (ARDA) network. The ARDA network operated between 1965 and 1991 (https://www.pacificclimate.org/data/bc-station-data) and was only available in BC (Fig. 1). The ARDA station records are sufficiently long to be useful for calculating error statistics, but were not used in any of three gridded meteorological datasets (PNWNAmet, NRCANmet or PBCmet) or the ClimateWNA v5.10 normals. In total, 76 ARDA stations with more than 5 years of data were identified. Stations dropped in and out over the 1965 to 1991 period (not shown). Of these, 20 stations were located at high elevation (>1000 m), which makes the ARDA network particularly well suited for verification in the mountainous regions of BC.
Notable features of the previously mentioned NRCANmet dataset include its use of elevation as the third predictor in the thin plate spline algorithm and source data from ECCC HCD15. Furthermore, stations have frequently been added or subtracted over time, peaking in the 1970s with a general decrease towards present15. The number of stations active across Canada between 1950 and 2011 ranges from 2000 to 3000 for precipitation and 1500 to 3000 for air temperature41. NRCANmet is gridded to a slightly coarser spatial resolution of 0.0833333°.
The PBCmet dataset was generated for BC at a spatial resolution of 0.0625° for 1950–2004 following the methods of Maurer et al.14. Station data were obtained from multiple national and provincial networks, each with a varying range of quality control and temporal availability. Maximum station density in PBCmet occurred in the 1990s when local networks, such as those available from BC Hydro, the BC Ministry of Forests and BC Ministry of Environment snow pillows, came on line or expanded. The maximum number of stations included 1400 for precipitation and 1130 for temperature42. Gridded fields were generated by superimposing interpolated daily station anomalies (relative to their own climatologies) on to a PRISM 1961–1990 monthly climatology. In this fashion, although not acting as a formal covariate (as in PNWNAmet), high-resolution climatology is used to directly influence the spatial structure of the gridded daily fields. Daily anomalies were interpolated using a modified version of the SYMAP algorithm43, where a cosine distance function is used in conjunction with a flexible search radius that starts at 50 km and increases until four stations are found (to a maximum radius of 100 km)44.The resulting gridded surfaces were then temporally adjusted against homogenized Canadian and US monthly datasets in an attempt to remove artefacts introduced by using a temporally varying station mix11,45.
Source data for all the products derives predominantly from national networks with similar quality standards, such as ECCC HCD and AHCCD, COOP, USHCN-daily and GHCN-daily, although PBCmet also uses source data from BC provincial sources including BC Hydro (BCH), and the Automated Snow Pillow (ASP) and Fire Weather (FWN) networks, which may have less stringent quality control. The primary differences in source data between PNWNAmet and the remaining datasets is the absence of short record stations in PNWNAmet, the use of homogenized data in PNWNAmet, and fixed versus varying station mix.
Evaluation against Station Observations
Values of mean error (bias), root mean squared error (RMSE), and mean absolute error (MAE) for the three datasets versus the ARDA network are shown in Fig. 2. For precipitation, NRCANmet exhibits a large negative, or dry, bias. Its bias is greatest in fall, followed by winter, then spring, similar to what was found in previous studies17,18. PBCmet and PNWNAmet have smaller magnitude precipitation bias than NRCANmet, both being positive. PBCmet shows the lowest magnitude precipitation bias in all seasons except summer. The PNWNAmet dataset has the largest precipitation MAE values of the three datasets, but comparable RMSE values. Given that RMSE puts higher weight on large errors, this suggests poorer performance for low to moderate precipitation intensities for PNWNAmet. Annual bias in maximum temperature is highest for PNWNAmet, whereas it is greatest for PBCmet in minimum temperature. The dataset with the largest temperature bias varies by season for minimum and maximum temperature, although bias in minimum temperature is substantially greater in winter with NRCANmet and in fall with PBCmet. RMSE and MAE are consistently highest for PBCmet annually and for all seasons suggesting a more systematic problem with temperature in this dataset.

Bias, RMSE and MAE in PNWNAmet (red), NRCANmet (blue) and PBCmet (orange) versus the ARDA network for precipitation (pr), maximum temperature (tasmax) and minimum temperature (tasmin) by season and annually.
It would seem plausible to attribute the large negative bias in NRCANmet, particularly in winter, to the effects of gauge undercatch and loss of trace precipitation, which are known to affect the source data39,46. However, if gauge undercatch and trace precipitation strongly affect interpolation accuracy then one would expect PBCmet and NRCANmet to display a similar precipitation bias to ARDA (as both use the same uncorrected source precipitation data). As PBCmet also uses data from additional networks, such as snow pillow sites, found at higher elevations, the effect of precipitation undercatch should dominate this data set even more so than NRCANmet. To the contrary, the similar positive sign and magnitude of the bias between ARDA and both PNWNAmet (using corrected data) and PBCmet (using raw data) suggests that data quality is not the main reason for differences in interpolation bias between NRCANmet and PNWNAmet. We infer instead that interpolation methodology dominates precipitation bias, wherein climatology is a superior predictor for precipitation than elevation (PNWNAmet/PBCmet versus NRCANmet). As all three datasets display similar accuracy for temperature, it is apparent that either elevation or climatology can be used as suitable predictors for temperature.
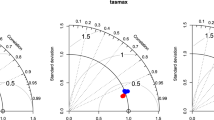
To evaluate differences in extremes for these datasets, Fig. 3 displays observed (ARDA stations) versus modelled (gridded meteorological datasets) values of nine annual climate indices. Various statistics comparing modelled and ARDA are summarized in Table 2. A dry bias is evident for NRCANmet with the precipitation indices: annual maximum 5-day precipitation (RX5DAY), simple daily wet-day precipitation intensity index (SDII), number of days with precipitation ≥10 mm (R10MM), number of days with precipitation ≥1 mm (R01MM), number of consecutive dry days (CDD), annual total of precipitation from days with precipitation exceeding the 95th percentile (R95PTOT), and annual total precipitation (PRCPTOT). PNWNAmet shows a positive bias in the number of wet days (R01MM), which may stem from the low station density. Large deviations from observed values are noted for PBCmet with the temperature indices: the number of icing days where the maximum temperature <0 deg. C (ID) and mean diurnal temperature range (DTR).

ARDA stations (X-axis) versus modelled (gridded meteorological datasets) values (Y-axis) of nine annual climate indices RX5DAY, SDII, ID, R10MM, R01MM, CDD, R95PTOT, PRCPTOT and DTR.
Finally, to assess performance in terms of seasonality and longer-term trends in the datasets, a comparison of cumulative departures of the series from their climatological mean values is made using the distributions of MAE skill scores (MEASS) over the ARDA network for each dataset and variable(Fig. 4), where MAESS = 1-MAEd/MAEclim, and MAEd is the MAE of the modelled cumulative departure series relative to the observed cumulative departure series and MAEclim is the same for a simple model consisting of the climatological mean value. MAESS values can range from -Inf to +1, with values greater than 0 indicating skill relative to the naive model. Based on the median and range of MAE skill score the PNWNAmet dataset better resolves the timing of increasing/decreasing periods in the observed series than the NRCANmet and PBCmet datasets, for precipitation and minimum temperature, while PBCmet is slightly better for maximum temperature. PBCmet is particularly weak in minimum temperatures with the lowest median and negative scores. NRCANmet struggles in precipitation. These results reinforce that the methodology for creating the PNWNAmet datasets maintains the timing and magnitude of events found in the observations better than NRCANmet and PBCmet, which rely on a temporally varying station mix.

MAE skill scores of cumulative departure series for the gridded meteorological datasets (PNWNAmet, NRCANmet AND PBCmet) versus the observed ARDA stations over British Columbia.
Spatial Comparison – PNWNAmet versus NRCANmet
Mean annual precipitation, mean annual minimum daily temperature and mean annual maximum daily temperature over 1950 to 2004 are compared between NRCANmet and PNWNAmet over their overlapping region. The dry bias in NRCANmet hinted at by the station comparison in the previous section is shown to be more widespread by the spatial comparison in Fig. 5. The advantage of using climatology as a predictor over elevation for interpolating precipitation is apparent when we see that differences between NRCANmet-PNWNAmet are most pronounced in mountainous regions (Coast and Rocky Mountains and Yukon) and smallest in areas of flat topography (Canadian plains and northern tundra). One notable exception is on Victoria Island, part of the Canadian Arctic Archipelago, where precipitation in NRCANmet is greater than PNWNAmet by up to 76%. Using a hydrologic model Eum et al.46, found NRCANmet too dry at high elevations. NRCANmet had lower precipitation amounts than other datasets they compared with17,18.

Percent difference in mean annual precipitation for NRCANmet minus PNWNAmet.
NRCANmet is cooler than PNWNAmet in western Canada and warmer in eastern Canada for the long-term average of daily minimum temperature (not shown). NRCANmet is cooler than PNWNAmet in the northwest portion of the region, including northern BC and the Yukon (not shown). Unlike precipitation, temperature differences between NRCANmet and PNWNAmet do not show any spatial coherence with topography.
Climate Variability
The three gridded meteorological datasets are compared for variability in mean annual precipitation and mean average daily temperature for the ten regions shown in Fig. 1. PNWNAmet is available in all regions, NRCANmet covers all of Canada and PBCmet is only available in British Columbia (BC). Two additional observational datasets are included for precipitation, the Global Precipitation Climatology Centre (GPCC) full data monthly version 201847 and the Variability Analyses of Surface Climate Observations (VASClimO)48. Both datasets have global coverage with a spatial resolution of 0.5°. GPCC is a 110-year dataset (1901–2010) recommended for water balance studies, validation of remote sensing based rainfall estimations and verification of numerical models. VASClimO is a 50-Year dataset (1951–2000), which is suitable for climate variability and trend studies. Values are plotted as anomalies from the respective means of the 1950 to 2004 period with loess smoothing (with an 11-year span), except VASClimO, which is available only up to 2000.
Although the broad patterns of inter-annual precipitation variability are similar for all five datasets, notable discrepancies are apparent (Fig. 6). Agreement can be quite poor between all datasets during the early part of the record (prior to 1970), particularly in southeastern BC and northern Canada. In certain regions, specifically coastal and southeastern BC and in northern Canada, NRCANmet exhibits a markedly different temporal evolution than the remaining data sets. The precipitation variability in PNWNAmet tends to match the global observational data sets quite well, except early in the record of the aforementioned regions.

Variability in annual precipitation (pr) and temperature (tas) for 10-year filtered PNWNAmet, NRCANmet, PBCmet, GPCC and VASClimO by region.
Correspondence of inter-annual variability among the three datasets is much better for temperature than for precipitation. All three datasets also exhibit similar positive trends in annual temperature for all regions, although NRCANmet has a stronger trend than either PBCmet or PNWNAmet in coastal and northeastern BC. Differences between PBCmet and PNWNAmet are, for the most part, indistinguishable.
Water Balance
To assess basin-wide precipitation accuracy in the gridded climate datasets, we compare precipitation to observed discharge from streamflow gauges. Streamflow integrates precipitation over the drainage area with losses to evapotranspiration, gains due to glacier melt and potential source or sink effects of groundwater. By converting streamflow at the gauge to depth of runoff (R) over a basin, it can be compared to average precipitation (P) over the basin, using the ratio R/P as a surrogate for water balance. R/P values of one or greater would signal that observed runoff is greater than interpolated precipitation, while values of 0.2 or less would suggests strong evaporation rates not likely at these elevations and latitudes49,50.
The Thompson above Spence’s Bridge (THOMS) is a major tributary to the Fraser River basin (Fig. 1). It is an ideal setting to investigate the three gridded meteorological datasets for water balance because of its high elevations, unregulated flow, Water Survey of Canada (WSC) observed streamflow records and glacier mass balance data. The THOMS’ drainage area is 55,400 km2 and its elevation ranges from 238 m to 3046 m (Table 3). The majority of WSC stations in the THOMS have data available from 1959 to 2013, with the exception of South Thompson River at Chase (STHOM) that starts in 1972. The overlapping period of record for the WSC gauges and three gridded meteorological datasets is 1972 to 2004. Thus, an R/P analysis is conducted over 1971–2000, a standard climate normal period.
Streamflow rates (m3s−1) were converted to mean annual runoff depth for each sub-basin (mm). A recent study by Beedle et al.51 looked at 33 glaciers in the Cariboo Mountains, located partially in the headwaters of the THOMS, and found that all glaciers receded during the 1952–2005 period. Rates of retreat and thinning accelerated after 1985. However, glacier cover still remained in this area circa 200551,52. Glacier thinning rates over 1985–1999 were used to adjust average annual runoff53. Only in the North Thompson did glacier melt contribute a notable volume to streamflow. Adjusted average annual runoff depth was divided by average annual precipitation depth to give R/P ratios over 1971–2000.
R/P ratios are highest with NRCANmet versus the other gridded meteorological datasets in all sub-basins (Table 4). R/P is greater than one with NRCANmet for the NTHMB despite adjustment of mean annual runoff (R) to account for contributions from glacier melt, while R/P ratios are less than 0.75 for PNWNAmet and PBCmet. R/P ratios in NRCANmet are especially high in the high elevation, headwater catchments of CLEAS, NTHMB and NTHMM. Mean annual precipitation (P) values are lowest for the NRCANmet dataset in all sub-basins. These results confirm the dry bias in NRCANmet at high elevations detected by previous studies17,18. Conversely, mean annual R/P values derived from PNWNAmet and PBCmet, with values ranging from 0.53 to 0.73, are considered reasonable for this climate and latitude49.
Hydro-Climatic Trends – Temporal Consistency
Trends in climate data play a major role in determining trends in simulated streamflow. Observed streamflow records can be used as an independent check against modelled streamflow, which in turn assesses trends in the gridded meteorological datasets used to drive the hydrologic model. To check the temporal consistency of the three datasets we continue to use the THOMS as a test basin. The Variable Infiltration Capacity (VIC) hydrologic model54,55, commonly applied in this region5,56,57, was used to simulate historical streamflow. Simulations were run using VIC version 4.0.7 in water balance mode at a daily timestep (the snow sub-model operated in energy-balance mode at a 3-hour timestep). The computational grid used a spatial resolution of 0.0625° with 500-m elevation bands (with a maximum of five bands per cell) to represent sub-grid topographic variability. The MT-CLIM package in VIC was used to estimate required unobserved variables (such as daily shortwave radiation, longwave radiation, and humidity) and for aggregating daily variables to sub-daily (as required by the snow sub-model)58. Wind speed, which is a required input to VIC, was added to the forcing data and was sourced from either NCEP/NCAR Reanalysis 159 (PBCmet and NRCANmet) or NOAA-CIRES 20th Century Reanalysis v2c27.
Prior to assessing trend, the VIC hydrologic model was calibrated specifically to each gridded meteorological dataset (NRCANmet, PBCmet and PNWNAmet), while keeping all other parameter fields (vegetation, soil, and elevation) constant. Calibration employed the automated NSGA-II elitist multi-objective genetic algorithm60 to optimize a set of five standard runoff generation parameters61,62. Over the calibration period (1991–2000) NRCANmet consistently has the largest volume bias (VB) and poorest Nash-Sutcliffe (NSE) and Log NSE coefficients of efficiency performance of the three datasets (not shown). Similar results were obtained for the validation period (1971–1990; Table 5). Large negative streamflow biases with the NRCANmet forcing dataset arise from its negative precipitation bias, which was demonstrated earlier versus the ARDA network (Fig. 2) and via high R/P ratios (Table 4). However, all datasets under predict streamflow volumes, which highlights the difficulty in estimating precipitation in these high elevations areas based on predominately low elevation stations, even when corrected against high-resolution climatologies as with PNWNAmet. Nevertheless, NSE and LNSE scores in all sub-basins, under all three datasets, are sufficiently strong63 to proceed with analysing trends in simulated streamflow.
Trends in mean annual streamflow from the calibrated VIC hydrologic model as driven by the NRCANmet, PBCmet and PNWNAmet gridded meteorological datasets are compared to those for observed streamflow over 1959 to 2004 using the iterative pre-whitening procedure proposed by Zhang et al.64–66. Trends in annual streamflow are dominated by trends in summer freshet runoff; hence, we omit any seasonal analysis and focus solely on annual streamflow. Streamflow simulated by driving the VIC hydrologic model with the PBCmet has a strong and significant/positive trend, while the observed shows a mild and always non-significant/negative trend for three of five sub-basins, CLEAS, NTHMB and NTHMM (Fig. 7). Additionally, the confidence intervals for the PBCmet trend do not overlap with those for observations in these sub-basins. However, the confidence bounds for trends in streamflow driven by NRCANmet and PNWNAmet do overlap with those for observed in all sub-basins. Thus, some characteristic of the PBCmet dataset is making it unsuitable for use with simulating streamflow trends for the three higher elevation sub-basins.

Circles show trend, filled circles indicate statistically significant trends at a 5% significance level and lines show the range between the upper and lower confidence bounds of the trend.
Trends in annual precipitation, minimum and maximum temperature, and diurnal temperature range were computed on daily data from each gridded meteorological dataset averaged by sub-basin. Similar to streamflow, trends were assessed using the an iterative pre-whitening procedure to correct for autocorrelation64–66. These trends are summarized in Table 6. Over the 46 years of analysis, significant increasing trends in mean annual daily precipitation were found in CLEAS, NTHMB and NTHMM only with the PBCmet dataset, while in the STHOM and THOMS only NRCANmet trends were significant. Maximum daily average temperature has increased for all datasets, but trends are significant for the PBCmet dataset only in all sub-basins except STHOM. Maximum temperature trends were highest in magnitude for PBCmet for all sub-basins and lowest in PNWNAmet in all sub-basins, but STHOM. Trends in minimum daily temperature are positive and significant for all three datasets and in all sub-basins. In most cases, minimum temperature trends are also larger in magnitude than are those for the corresponding trend in maximum temperature. As a result, the daily temperature range has been decreasing in most case, although trends are only significant for PNWNAmet.
Trends in annual VIC-simulated values of solar radiation, evapotranspiration and snow accumulation as driven by PBCmet, NRCANmet and PNWNAmet are also summarized in Table 6. Solar radiation exhibits a negative trend for all data sets in all basins. This result is generally consistent with the trends observed for diurnal temperature range, which is used as a covariate for atmospheric transmissivity. However, the variation in trend magnitude between basins and data sets does not correspond strictly to changes in temperature range, as it is affected also by trends in precipitation (which is used as a proxy for cloudiness, such that increasing precipitation would also result in decreasing solar radiation). Evapotranspiration trends are uniformly positive for all data sets and basins and changes are of similar magnitude but mostly insignificant. The magnitude of the evapotranspiration trend is generally the same as the corresponding precipitation trend, except in those instances where the precipitation change is significant and precipitation is increasing at a faster rate than evapotranspiration (e.g. PBCmet for CLEAS, NTHM and NTHM and NRCANmet for STHOM and THOMS). Given the sensitivity of snow accumulation to changes in both temperature and precipitation, simulated March snow water equivalent, which is a surrogate for peak annual accumulation, unsurprisingly shows mixed trends. Large increases occur with PBCmet for CLEAS, NTHMB and NTHMM, but a large decrease occurs for STHOM. PNWNAmet consistently produces decreasing snow water equivalent (or no change for NTHMB), and NRCANmet produces a range of positive and negative changes.
Changes in precipitation (and corresponding trends in snow accumulation) seem to explain the large positive trends in streamflow generated by PBCmet in CLEAS, NTHM, and NTHMB and the negative change produced for STHOM. Large positive precipitation trends, that are much larger than corresponding ET trends, result in increased snow accumulation and discharge (CLEAS, NTHMB and NTHMM). For PBCmet in the STHOM, the trend in ET is positive whereas there is no trend in precipitation, and discharge decreases. For the remaining data sets and basins, any increase in precipitation is partially offset by increasing evapotranspiration and the resulting trends in annual streamflow are statistically insignificant. In these cases, changes in SWE are also generally small and insignificant.
The streamflow trend results for PBCmet indicate that the temporal correction was either ineffective in removing, or possibly exacerbated, the effect of a temporal varying mix of station density and networks. For the PBCmet and NRCANmet datasets, where stations drop in and out over time, the effect of low station density could be more pronounced for the first 20-year period (1958–1977) when the station density was lowest in BC67.
Usage Notes
The PNWNAmet dataset performs comparably well to two gridded meteorological datasets for standardize performance measures against an independent climate network for climatology, extremes and variability. However, it potentially has a greater number of wet days than other gridded meteorological datasets commonly used in the NWNA climate region, which could be due to the lower stations density of this product. It performs better than other datasets in terms of resolving the timing of periods of increasing/decreasing precipitation and minimum temperature in the observed series than the NRCANmet and PBCmet datasets, while PBCmet performs slightly better for maximum temperature. Based on a comparison between PNWNAmet and NRCANmet climatologies, PNWNAmet likely better resolves spatial patterns of precipitation. Furthermore, PNWNAmet better matches decadal scale climate variability of two gridded precipitation products by major drainage basin. Based on a study in the Thompson (a major Fraser River tributary) where all three gridded observational datasets are available, the PNWNAmet and PBCmet datasets are hydrologically consistent based on runoff over precipitation (R/P) ratios where runoff is obtained from observed streamflow. NRCANmet R/P ratios are too high, even exceeding one in one sub-basin. When a hydrologic model is driven with these datasets, the PBCmet driven simulated streamflow results in trends almost opposite from observed in many sub-basins, while NRCANmet and PNWNAmet driven trends are within the confidence bounds of observed.
The temporal and spatial continuity of the PNWNAmet dataset over the Canada/US border at the 49th parallel and from the Yukon into Alaska makes this new dataset ideal for transboundary studies. It also extends far enough east to support hydrologic modelling and statistical downscaling in five major North American drainages, the Yukon, Mackenzie, Saskatchewan, Fraser and Columbia. PNWNAmet appears robust for use with statistical downscaling and hydrological modelling for climatology, trends and extremes over a relatively long-term record (1945–2012). However, where the number of precipitation days is a key determining factor in a physical response of a system, to evaporation or snowmelt, for example, users should be aware of its potential to overestimate the number of days with precipitation. Additionally, in-depth analysis of PNWNAmet has only been conducted for a fraction of its region of availability. Further work is needed to assess PNWNAmet over its entire domain.
Additional information
How to cite this article: Werner, A. T. et al. A long-term, temporally consistent, gridded daily meteorological dataset for northwest North America. Sci. Data. 6:180299 doi: 10.1038/sdata.2018.299 (2019).
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
References
Elsner, M. M. et al. How does the choice of distributed meteorological data affect hydrologic model calibration and streamflow simulations? J. Hydrometeorol. 15, 1384–1403 (2014).
Werner, A. T. & Cannon, A. J. Hydrologic extremes – an intercomparison of multiple gridded statistical downscaling methods. Hydrol. Earth Syst. Sci. 20, 1483–1508 (2016).
Curry, C. L. & Zwiers, F. W. Examining controls on peak annual streamflow and floods in the Fraser River Basin of British Columbia. Hydrol. Earth Syst. Sci. 22, 2285–2309 (2017).
Islam, S. U. & Déry, S. J. Evaluating uncertainties in modelling the snow hydrology of the Fraser River Basin, British Columbia, Canada. Hydrol. Earth Syst. Sci. 21, 1827–1847 (2017).
Shrestha, R. R., Cannon, A. J., Schnorbus, M. A. & Zwiers, F. W. Projecting future nonstationary extreme streamflow for the Fraser River, Canada. Clim. Change 145, 298–303 (2017).
Najafi, M. R., Zwiers, F. & Gillett, N. Attribution of the Observed Spring Snowpack Decline in British Columbia to Anthropogenic Climate Change. J. Clim. 30, 4113–4130 (2017).
DeBeer, C. M., Wheater, H. S., Carey, S. K. & Chun, K. P. Recent climatic, cryospheric, and hydrological changes over the interior of western Canada: a review and synthesis. Hydrol. Earth Syst. Sci. 20, 1573–1598 (2016).
Elsner, M. M. et al. Implications of 21st century climate change for the hydrology of Washington State. Clim. Change 102, 225–260 (2010).
Hopkinson, R. F., Hutchinson, M. F., McKenney, D. W., Milewska, E. J. & Papadopol, P. Optimizing input data for gridding climate normals for Canada. J. Appl. Meteorol. Climatol. 51, 1508–1518 (2012).
Schnorbus, M. A ., Bennett, K. E ., Werner, A. T . & Berland, A. J. Hydrologic Impacts of Climate Change in the Peace, Campbell and Columbia Watersheds, British Columbia, Canada. (Pacific Climate Impacts Consortium, University of Victoria, 2011).
Hamlet, A. F. & Lettenmaier, D. P. Production of temporally consistent gridded precipitation and temperature fields for the continental United States. J. Hydrometeorol. 6, 330–336 (2005).
Livneh, B. et al. A spatially comprehensive, hydrometeorological data set for Mexico, the U.S., and Southern Canada 1950–2013. Sci. Data 2, 150042 (2015).
Stewart, I. T., Cayan, D. R. & Dettinger, M. D. Changes in snowmelt runoff timing in western North America under a ‘Business as Usual’ climate change scenario. Clim. Change 62, 217–232 (2004).
Maurer, E. P., Wood, A. W., Adam, J. C., Lettenmaier, D. P. & Nijssen, B. A long-term hydrologically based dataset of land surface fluxes and states for the conterminous United States. J Clim. 15, 3237–3251 (2002).
Hutchinson, M. F. et al. Development and testing of Canada-wide interpolated spatial models of daily minimum–maximum temperature and precipitation for 1961–2003. J. Appl. Meteorol. Climatol. 48, 725–741 (2009).
McKenney, D. W. et al. Customized spatial climate models for North America. Bull. Am. Meteorol. Soc. 92, 1611–1622 (2011).
Eum, H.-I., Dibike, Y., Prowse, T. & Bonsal, B. Inter-comparison of high-resolution gridded climate data sets and their implication on hydrological model simulation over the Athabasca Watershed, Canada. Hydrol. Process. 28, 4250–4271 (2014).
Wong, J. S., Razavi, S., Bonsal, B. R., Wheater, H. S. & Asong, Z. E. Inter-comparison of daily precipitation products for large-scale hydro-climatic applications over Canada. Hydrol. Earth Syst. Sci. 21, 2163–2185 (2017).
Tait, A., Henderson, R., Turner, R. & Zheng, X. Thin plate smoothing spline interpolation of daily rainfall for New Zealand using a climatological rainfall surface. Int. J. Climatol. 26, 2097–2115 (2006).
Anslow, F. S. Climate Analysis and Monitoring - Research Plan: 2015–2019. (Pacific Climate Impacts Consortium, 2015).
Daly, C. et al. Physiographically sensitive mapping of climatological temperature and precipitation across the conterminous United States. Int. J. Climatol. 28, 2031–2064 (2008).
Mekis, É. & Vincent, L. A. An overview of the second generation adjusted daily precipitation dataset for trend analysis in Canada. Atmosphere-Ocean 49, 163–177 (2011).
Vincent, L. A. et al. A second generation of homogenized Canadian monthly surface air temperature for climate trend analysis. J. Geophys. Res. Atmospheres 117, D18110 (2012).
Vincent, L. A., Zhang, X., Bonsal, B. R. & Hogg, W. D. Homogenzation of daily temperatures over Canada. J. Clim. 15, 1322–1334 (2002).
Williams, C. N., Vose, R. S., Easterling, D. R. & Menne, M. J. United States Historical Climatology Network Daily Temperature, Precipitation, and Snow Data. (Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory, Oak Ridge, Tennessee, 2006).
Menne, M. J., Durre, I., Vose, R. S., Gleason, B. E. & Houston, T. G. An overview of the Global Historical Climatology Network-Daily database. J. Atmospheric Ocean. Technol. 29, 897–910 (2012).
Compo, G. P. et al. The Twentieth Century Reanalysis project. Q. J. R. Meteorol. Soc. 137, 1–28 (2011).
Wang, T., Hamann, A., Spittlehouse, D. & Carroll, C. Locally Downscaled and Spatially Customizable Climate Data for Historical and Future Periods for North America. PLOS ONE 11, e0156720 (2016).
Wang, T., Hamann, A., Spittlehouse, D. L. & Murdock, T. Q. ClimateWNA—high-resolution spatial climate data for western North America. J. Appl. Meteorol. Climatol. 51, 16–29 (2011).
Wang, T., Hamann, A., Spittlehouse, D. L. & Aitken, S. N. Development of scale-free climate data for Western Canada for use in resource management. Int. J. Climatol. 26, 383–397 (2006).
Danielson, J. J. & Gesch, D. B. Global multi-resolution terrain elevation data 2010 (GMTED2010) U.S. Geological Survey Open-File Report 2011–1073, 26p. (2011).
Jones, P. D. & Harriss, I. C. CRU TS3.21: Climatic Research Unit (CRU) Time-Series (TS) Version 3.21 of high resolution gridded data of month-by-month variation in climate (Jan. 1901–Dec. 2012) NERC British Atmospheric Data Centre https://doi.org/10.5285/D0E1585D-3417-485F-87AE-4FCECF10A992 (2013).
Nychka, D., Furrer, R., Paige, J. & Sain, S. fields: Tools for Spatial Data. (2017).
Hutchinson, M. F. Interpolating mean rainfall using thin plate smoothing splines. Int. J. Geogr. Inf. Syst. 9, 385–403 (1995).
Boer, E. P. J., de Beurs, K. M. & Hartkamp, A. D. Kriging and thin plate splines for mapping climate variables. Int. J. Appl. Earth Obs. Geoinformation 3, 146–154 (2001).
Hunter, R. D. & Meentemeyer, R. K. Climatologically aided mapping of daily precipitation and temperature. J. Appl. Meteorol. 44, 1501–1510 (2005).
Janis, M. J. Observation-time-dependent biases and departures for daily minimum and maximum Air temperatures. J. Appl. Meteorol. 1988-2005 41, 588–603 (2002).
Menne, M. J., Williams, C. N. & Vose, R. S. The U.S. Historical Climatology Network Monthly Temperature Data, Version 2. Bull. Am. Meteorol. Soc. 90, 993–1008 (2009).
Mekis, E. & Hogg, W. D. Rehabilitation and analysis of Canadian daily precipitation time series. Atmosphere-Ocean 37, 53–85 (1999).
Menne, M. J., Williams, C. N. Jr. & Vose, R. S. United States Historical Climatology Network Daily Temperature, Precipitation, and Snow Data. (Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory, 2015).
Hopkinson, R. F. et al. Impact of aligning climatological day on gridding daily maximum–minimum temperature and precipitation over Canada. J. Appl. Meteorol. Climatol. 50, 1654–1665 (2011).
Bennett, K. E. VIC Hydrologic Forcing Data. 26. (Pacific Climate Impacts Consortium, University of Victoria, 2010).
Shepard, D. S. In Spatial Statistics and Models (eds. Gaille, G. L. & Willmott, C. J. ) Computer Mapping: the SYMAP Interpolation Algorithm (Reidel, 1984).
Widmann, M. & Bretherton, C. S. Validation of mesoscale precipitation in the NCEP Reanalysis using a new gridcell dataset for the northwestern United States. J. Clim. 13, 1936–1950 (2000).
Schnorbus, M., Werner, A. & Bennett, K. Impacts of climate change in three hydrologic regimes in British Columbia, Canada. Hydrol. Process. 28, 1170–1189 (2014).
Eum, H.-I., Yonas, D. & Prowse, T. Uncertainty in modelling the hydrologic responses of a large watershed: a case study of the Athabasca River basin, Canada. Hydrol. Process. 28, 4272–4293 (2014).
Becker, A. et al. A description of the global land-surface precipitation data products of the Global Precipitation Climatology Centre with sample applications including centennial (trend) analysis from 1901–present. Earth Syst. Sci. Data 5, 71–99 (2013).
Beck, C., Grieser, J. & Rudolf, B. A New Monthly Precipitation Climatology for the Global Land Areas for the Period 1951 to 2000. 181–190 (German Weather Service, 2005).
Haddeland, I. et al. Multimodel estimate of the global terrestrial water balance: setup and first results. J. Hydrometeorol. 12, 869–884 (2011).
Kumar, S. et al. Terrestrial contribution to the heterogeneity in hydrological changes under global warming. Water Resour. Res. 52, 3127–3142 (2016).
Beedle, M. J., Menounos, B. & Wheate, R. Glacier change in the Cariboo Mountains, British Columbia, Canada (1952–2005). The Cryosphere 9, 65–80 (2015).
Pfeffer, W. T. et al. The Randolph Glacier Inventory: a globally complete inventory of glaciers. J. Glaciol. 60, 537–552 (2014).
Schiefer, E., Menounos, B. & Wheate, R. Recent volume loss of British Columbian glaciers, Canada. Geophys Res. Lett. 34, L16503 (2007).
Liang, X., Wood, E. F. & Lettenmaier, D. P. Surface soil moisture parameterization of the VIC-2L model: Evaluation and modification. Glob. Planet. Change 13, 195–206 (1996).
Liang, X., Lettenmaier, D. P., Wood, E. F. & Burges, S. J. A simple hydrologically based model of land surface water and energy fluxes for general circulation models. J. Geophys. Res. Atmospheres 99, 14415–14428 (1994).
Shrestha, R. R., Peters, D. L. & Schnorbus, M. A. Evaluating the ability of a hydrologic model to replicate hydro-ecologically relevant indicators. Hydrol. Process. 28, 4294–4310 (2014).
Shrestha, R. R., Schnorbus, M. A., Werner, A. T. & Berland, A. J. Modelling spatial and temporal variability of hydrologic impacts of climate change in the Fraser River basin, British Columbia, Canada. Hydrol. Process. 26, 1840–1860 (2012).
Bohn, T. J. et al. Global evaluation of MTCLIM and related algorithms for forcing of ecological and hydrological models. Agric. For. Meteorol. 176, 38–49 (2013).
Kalnay, E. et al. The NCEP/NCAR 40-year reanalysis project. Bull. Am. Meteorol. Soc. 77, 437–471 (1996).
Deb, K., Pratap, A., Agarwal, S. & Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6, 182–197 (2002).
Demaria, E. M., Nijssen, B. & Wagener, T. Monte Carlo sensitivity analysis of land surface parameters using the Variable Infiltration Capacity model. J. Geophys. Res. Atmospheres 112, D11113 (2007).
Shrestha, R. R., Schnorbus, M. A. & Peters, D. L. Assessment of a hydrologic model’s reliability in simulating flow regime alterations in a changing climate. Hydrol. Process. 30, 2628–2643 (2016).
Singh, V. P. Computer Models of Watershed Hydrology. (Water Resources Pubns, 1995).
Bürger, G. On trend detection. Hydrol. Process. 31, 4039–4042 (2017).
Zhang, X., Vincent, L. A., Hogg, W. D. & Niitsoo, A. Temperature and precipitation trends in Canada during the 20th Century. Atmosphere-Ocean 38, 395–429 (2000).
Zhang, X. & Zwiers, F. W. Comment on “Applicability of prewhitening to eliminate the influence of serial correlation on the Mann-Kendall test” by Sheng Yue and Chun Yuan Wang. Water Resour. Res. 40, W03805 (2004).
Stahl, K., Moore, R. D., Floyer, J. A., Asplin, M. G. & McKendry, I. G. Comparison of approaches for spatial interpolation of daily air temperature in a large region with complex topography and highly variable station density. Agric. For. Meteorol. 139, 224–236 (2006).
Data Citations
Werner, A. T. et al. figshare https://doi.org/10.6084/m9.figshare.c.3965337 (2018)
Acknowledgements
Lee Zeman, Rod Glover and James Hiebert of the Pacific Climate Impacts Consortium’s computational support group are gratefully acknowledged for creating the data portal that hosts the evaluated datasets.
Author information
Authors and Affiliations
Contributions
A.T.W. wrote this article, produced figures and conducted the trend analysis. R.S. researched and produced the high-resolution climatology, calibrated the VIC hydrologic model, ran all VIC simulations, and was the impetus for earlier drafts of this manuscript. A.J.C. developed and implemented the high-resolution climatology predictor thin plate spline methodology and analysed the three gridded meteorological datasets against the ARDA observed stations. M.S. developed earlier drafts of this manuscript and provided valuable revisions and feedback that helped shape this version. F.Z. provided edits and comments that were pivotal in bringing this manuscript to its current form. G.D. analysed the climate variability of temperature and precipitation of the three datasets in the five watersheds in the NWNA region. F.A. provided helpful feedback on this manuscript and valuable discussion on PRSIM and ClimateWNA.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
ISA-Tab metadata
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files made available in this article.
About this article

Cite this article
Werner, A., Schnorbus, M., Shrestha, R. et al. A long-term, temporally consistent, gridded daily meteorological dataset for northwestern North America. Sci Data 6, 180299 (2019). https://doi.org/10.1038/sdata.2018.299
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/sdata.2018.299
