
Abstract
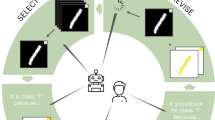
Deep neural networks have demonstrated excellent performances in many real-world applications. Unfortunately, they may show Clever Hans-like behaviour (making use of confounding factors within datasets) to achieve high performance. In this work we introduce the novel learning setting of explanatory interactive learning and illustrate its benefits on a plant phenotyping research task. Explanatory interactive learning adds the scientist into the training loop, who interactively revises the original model by providing feedback on its explanations. Our experimental results demonstrate that explanatory interactive learning can help to avoid Clever Hans moments in machine learning and encourages (or discourages, if appropriate) trust in the underlying model.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others
Data availability
The ML benchmark Fashion-MNIST is available at https://github.com/zalandoresearch/fashion-mnist. The PASCAL VOC2007 dataset is available at http://host.robots.ox.ac.uk/pascal/VOC/voc2007/. The RGB and HS data that support the findings of this study are available in the code repository https://doi.org/10.24433/CO.4559958.v1 (ref. 68). The user study is available at https://github.com/ml-research/xil/tree/master/Trust_Study.
Code availability
The code and a fully runnable capsule to reproduce the figures and results of this article, including pre-trained models, can be found at https://doi.org/10.24433/CO.4559958.v1 (ref. 68).
References
Guidotti, R. et al. A survey of methods for explaining black box models. ACM Comput. Surv. 51, 1–42 (2018).
Gilpin, L. H. et al. Explaining explanations: an overview of interpretability of machine learning. In 2018 IEEE International Conference on Data Science and Advanced Analytics (DSAA) 80–89 (IEEE, 2018).
Lapuschkin, S. et al. Unmasking clever hans predictors and assessing what machines really learn. Nature Commun. 10, 1096 (2019).
Ross, A. S., Hughes, M. C. & Doshi-Velez, F. Right for the right reasons: training differentiable models by constraining their explanations. In Proceedings of International Joint Conference on Artificial Intelligence 2662–2670 (ICJAI, 2017).
Simpson, J. A. Psychological foundations of trust. Curr. Dir. Psychol. Sci. 16, 264–268 (2007).
Hoffman, R. R., Johnson, M., Bradshaw, J. M. & Underbrink, A. Trust in automation. IEEE Intell. Syst. 28, 84–88 (2013).
Bucilua, C., Caruana, R. & Niculescu-Mizil, A. Model compression. In Proc. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 535–541 (ACM, 2006).
Ribeiro, M. T., Singh, S. & Guestrin, C. Why should I trust you? Explaining the predictions of any classifier. In Proc. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 1135–1144 (ACM, 2016).
Lundberg, S. & Lee, S. An unexpected unity among methods for interpreting model predictions. Preprint at http://arxiv.org/abs/1611.07478 (2016).
Settles, B. Closing the loop: fast, interactive semi-supervised annotation with queries on features and instances. In Proc. Conference on Empirical Methods in Natural Language Processing 1467–1478 (Association for Computational Linguistics, 2011).
Shivaswamy, P. & Joachims, T. Coactive learning. J. Artif. Intell. Res. 53, 1–40 (2015).
Kulesza, T. et al. Principles of explanatory debugging to personalize interactive machine learning. In Proc. International Conference on Intelligent User Interfaces 126–137 (ACM, 2015).
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J. & Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC 2007) Results (Pascal Network, 2017); http://host.robots.ox.ac.uk/pascal/VOC/voc2007/
Lin, T., et al. Microsoft COCO: common objects in context. In Proc. European Conference on Computer Vision 740–755 (2014).
Herbert, F. P., Kersting, K. & Jäkel, F. Why should I trust in AI? Master’s thesis (Technical Univ. Darmstadt, 2019).
Teso, S. & Kersting, K. Explanatory interactive machine learning. In Proc. AAAI/ACM Conference on AI, Ethics, and Society (AAAI, 2019).
Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 1, 206–215 (2019).
Judah, K. et al. Active imitation learning via reduction to IID active learning. In AAAI Fall Symposium Series (AAAI, 2012).
Cakmak, M. et al. Mixed-initiative active learning. In ICML 2011 Workshop on Combining Learning Strategies to Reduce Label Cost (ACM, 2011).
Selvaraju, R. R. et al. Grad-cam: visual explanations from deep networks via gradient-based localization. In Proc. IEEE International Conference on Computer Vision 618–626 (IEEE, 2017).
Selvaraju, R. R. et al. Taking a hint: leveraging explanations to make vision and language models more grounded. In Proc. IEEE International Conference on Computer Vision 2591–2600 (IEEE, 2019).
Xiao, H., Rasul, K. & Vollgraf, R., Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. Preprint at http://arxiv.org/abs/1708.07747 (2017).
Maaten, Lvd & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008).
Körber, M., Theoretical considerations and development of a questionnaire to measure trust in automation. In Congress of the International Ergonomics Association 13–30 (Springer, 2018).
Jordan, M. I. & Mitchell, T. M. Machine learning: trends, perspectives, and prospects. Science 349, 255–260 (2015).
Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 521, 452–459 (2015).
Silver, D. et al. Mastering the game of go without human knowledge. Nature 550, 354–359 (2017).
Zech, J. R. et al. Confounding variables can degrade generalization performance of radiological deep learning models. Preprint at http://arxiv.org/abs/1807.00431 (2018).
Badgeley, M. A. et al. Deep learning predicts hip fracture using confounding patient and healthcare variables. npj Digit. Med. 2, 31 (2019).
Chaibub Neto, E. et al. A permutation approach to assess confounding in machine learning applications for digital health. In Proc. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 54–64 (ACM, 2019).
Adebayo, J. et al. Sanity checks for saliency maps. In Proc. Advances in Neural Information Processing Systems 9505–9515 (NeurIPS, 2018).
Chen, C. et al. This looks like that: deep learning for interpretable image recognition. In Proc. Advances in Neural Information Processing Systems (eds Wallach, H. M. et al.) 8928–8939 (Curran Associates, 2019).
Dombrowski, A. et al. Explanations can be manipulated and geometry is to blame. In Proc. Advances in Neural Information Processing Systems (eds Wallach, H. M. et al.) 13567–13578 (Curran Associates, 2019).
Odom, P. & Natarajan, S. Human-guided learning for probabilistic logic models. Front. Robot. AI 5, 56 (2018).
Narayanan, M. et al. How do humans understand explanations from machine learning systems? An evaluation of the human-interpretability of explanation. Preprint at http://arxiv.org/abs/1802.00682 (2018).
Kanehira, A. & Harada, T. Learning to explain with complemental examples. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 8603–8611 (IEEE, 2019).
Huk Park, D. et al. Multimodal explanations: justifying decisions and pointing to the evidence. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 8779–8788 (IEEE, 2018).
Settles, B. in Synthesis Lectures on Artificial Intelligence and Machine Learning Vol. 6 1–114 (Morgan & Claypool, 2012).
Hanneke, S. et al. Theory of disagreement-based active learning. Found. Trends Mach. Learn. 7, 131–309 (2014).
Roy, N. et al. Toward optimal active learning through Monte Carlo estimation of error reduction. In International Conference for Machine Learning 441–448 (ICML, 2001).
Castro, R. M. et al. Upper and lower error bounds for active learning. In Proc. Conference on Communication, Control and Computing 1 (Univ. Illinois, 2007).
Balcan, M.-F. et al. The true sample complexity of active learning. Mach. Learn. 80, 111–139 (2010).
Tong, S. & Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2, 45–66 (2001).
Krause, A. et al. Nonmyopic active learning of gaussian processes: an exploration–exploitation approach. In Proc. International Conference on Machine Learning 449–456 (ACM, 2007).
Gal, Y. et al. Deep bayesian active learning with image data. In Proc. International Conference on Machine learning 1183–1192 (ICML, 2017).
Schnabel, T., et al. Short-term satisfaction and long-term coverage: understanding how users tolerate algorithmic exploration. In Proc. ACM International Conference on Web Search and Data Mining 513–521 (ACM, 2018).
Bastani, O., Kim, C. & Bastani, H. Interpreting blackbox models via model extraction. Preprint at http://arxiv.org/abs/1705.08504 (2017).
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A. & Torralba, A. Learning deep features for discriminative localization. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 2921–2929 (IEEE, 2016).
Cortes, C. et al. Support-vector networks. Mach. Learn. 20, 273–297 (1995).
Anders, C. J. et al. Analyzing imagenet with spectral relevance analysis: towards ImageNet un-Hans’ed. Preprint at http://arxiv.org/abs/1912.11425 (2019).
Zaidan, O. et al. Using ‘annotator rationales’ to improve machine learning for text categorization. In Proc. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 260–267 (Association for Computational Linguistics, 2007).
Small, K. et al. The constrained weight space SVM: learning with ranked features. In Proc. International Conference on Machine Learning 865–872 (Omnipress, 2011).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proc. International Conference on Learning Representations (ICLR, 2015).
Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. In Proc. International Conference on Learning Representations (ICLR, 2015).
Lau, E. High-throughput phenotyping of rice growth traits. Nat. Rev. Genet. 15, 778–778 (2014).
de Souza, N. High-throughput phenotyping. Nat. Methods 7, 36 (2009).
Tardieu, F., Cabrera-Bosquet, L., Pridmore, T. & Bennett, M. Plant phenomics, from sensors to knowledge. Curr. Biol. 27, R770–R783 (2017).
Pound, M. P. et al. Deep machine learning provides state-of-the-art performance in image-based plant phenotyping. GigaScience 6, gix083 (2017).
Mochida, K. et al. Computer vision-based phenotyping for improvement of plant productivity: a machine learning perspective. GigaScience 8, giy153 (2018).
Mahlein, A.-K. et al. Quantitative and qualitative phenotyping of disease resistance of crops by hyperspectral sensors: seamless interlocking of phytopathology, sensors, and machine learning is needed! Curr. Opin. Plant Biol. 50, 156–162 (2019).
Meier, U. et al. Phenological growth stages of sugar beet (Beta vulgaris l. ssp.) codification and description according to the general BBCH scale (with figures). Nachr. Dtsch. Pflanzenschutzd. 45, 37–41 (1993).
Hooker, S., Erhan, D., Kindermans, P. & Kim, B. A benchmark for interpretability methods in deep neural networks. In Proc. Advances in Neural Information Processing Systems 9734–9745 (Curran Associates, 2019).
Deng, J. et al. ImageNet: a large-scale hierarchical image database. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (IEEE, 2009).
Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 17, 395–416 (2007).
Abdel-Karim, B. M., Pfeuffer, N., Rohde, G. & Hinz, O. How and what can humans learn from being in the loop? Künst. Intell. 34, 199–207 (2020).
Erion, G. G., Janizek, J. D., Sturmfels, P., Lundberg, S. & Lee, S. Learning explainable models using attribution priors. Preprint at http://arxiv.org/abs/1906.10670 (2019).
Liu, F. & Avci, B. Incorporating priors with feature attribution on text classification. In Proc. 57th Annual Meeting of the Association for Computational Linguistics 6274–6283 (Association for Computational Linguistics, 2019).
Schramowski, P., Stammer, W., Teso, S. & Herbert, F. Making Deep Neural Networks Right for the Right Scientific Reasons by Interacting with their Explanations (CodeOcean, accessed 3 August 2020); https://doi.org/10.24433/CO.4559958.v1
Acknowledgements
S.T. and K.K. thank A. Vergari, A. Passerini, S. Kolb, J. Bekker, X. Shao and P. Morettin for very useful feedback on the conference version of this article. Furthermore, we thank F. Jäkel for support and supervision on the user study, C. Turan for providing the figure sketches and U. Steiner and S. Paulus for very useful feedback. P.S., A.K.M., A.B. and K.K. acknowledge the support by BMEL funds of the German Federal Ministry of Food and Agriculture (BMEL) based on a decision of the Parliament of the Federal Republic of Germany via the Federal Office for Agriculture and Food (BLE) under the innovation support programme, project DePhenSe (FKZ 2818204715). W.S. and K.K. were also supported by BMEL/BLE funds under the innovation support programme, project AuDiSens (FKZ 28151NA187). S.T. acknowledges the supported by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme, grant agreement no. 694980 SYNTH: Synthesising Inductive Data Models. X.S. and K.K. also acknowledge the support by the German Science Foundation project CAML (KE1686/3-1) as part of the SPP 1999 (RATIO). A.K.M. was partially funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy—EXC 2070 – 390732324
Author information
Authors and Affiliations
Contributions
P.S., W.S., S.T. and K.K. designed the study. S.T. and K.K. designed and published the preliminary version of this manuscript16. P.S., W.S., X.S., S.T. and K.K. developed extensions of the basic XIL methods. P.S., W.S., A.B., A.K.M. and K.K. interpreted the data and drafted the manuscript. A.B. and P.S. designed the phenotyping dataset. A.B. and H.G.L. carried out the phenotyping dataset measuring. P.S., W.S. and A.B. did the biological analysis. F.H. performed and analysed the user study. A.K.M. and K.K. directed the research and gave initial input. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
H.S. is employed by LemnaTec GmbH.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Examples of XIL on MSCOCO 2014 dataset.
The left column a, presents the original images, the middle column b, presents the explanations (GRAD-CAM) after training without user feedback (default), the right column c, presents the explanations after training with user feedback (XIL) using the MSE loss between user and model explanations. Also here, light regions represent relevant regions for the model’s decision, dark regions represent irrelevant regions. As user annotations we use the complete class segmentation to illustrate that XIL can also aid in improving the explanations for non-confounded data. See the Supplementary Information for more details. Due to license issues the presented images are alternatives to the original dataset.
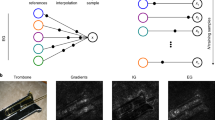
Extended Data Fig. 2 Example of explanations along the spatial and spectral dimensions.
GRAD-CAMS of a hyperspectral sample with spatial and spectral explanations of a corrected network. Leftmost image shows the sample followed by the corresponding spatial activations maps mapped to four different hyperspectral areas. The areas are 380-537 nm,538-695 nm, 696-853 nm and 854-1010 nm.
Extended Data Fig. 3 Mathematical intuition for the counterexample strategy, exemplified for linear classifiers.
Two data features are shown, ϕ1 and ϕ2, of which only the first is truly relevant. a, The positive example xi is not enough to disambiguate between the red and green classifiers. b, Counterexamples xi,ℓ are obtained by randomizing the irrelevant feature while keeping the label of xi. The counterexamples approximate a (local) orthogonality constraint. c, The red classifier is inconsistent with the counterexamples and eliminated. See the Methods section Explanatory Interactive Learning with counterexamples for details. (Best viewed in colour).
Supplementary information
Supplementary information
Supplementary Figs. 1–20, Table 1, discussion and user study example forms.
Rights and permissions
About this article

Cite this article
Schramowski, P., Stammer, W., Teso, S. et al. Making deep neural networks right for the right scientific reasons by interacting with their explanations. Nat Mach Intell 2, 476–486 (2020). https://doi.org/10.1038/s42256-020-0212-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s42256-020-0212-3
This article is cited by
-
Navigating the landscape of concept-supported XAI: Challenges, innovations, and future directions
Multimedia Tools and Applications (2024)
-
From attribution maps to human-understandable explanations through Concept Relevance Propagation
Nature Machine Intelligence (2023)
-
A typology for exploring the mitigation of shortcut behaviour
Nature Machine Intelligence (2023)
