
Abstract
Non-volatile computing-in-memory (nvCIM) could improve the energy efficiency of edge devices for artificial intelligence applications. The basic functionality of nvCIM has recently been demonstrated using small-capacity memristor crossbar arrays combined with peripheral readout circuits made from discrete components. However, the advantages of the approach in terms of energy efficiency and operating speeds, as well as its robustness against device variability and sneak currents, have yet to be demonstrated experimentally. Here, we report a fully integrated memristive nvCIM structure that offers high energy efficiency and low latency for Boolean logic and multiply-and-accumulation (MAC) operations. We fabricate a 1 Mb resistive random-access memory (ReRAM) nvCIM macro that integrates a one-transistor–one-resistor ReRAM array with control and readout circuits on the same chip using an established 65 nm foundry complementary metal–oxide–semiconductor (CMOS) process. The approach offers an access time of 4.9 ns for three-input Boolean logic operations, a MAC computing time of 14.8 ns and an energy efficiency of 16.95 tera operations per second per watt. Applied to a deep neural network using a split binary-input ternary-weighted model, the system can achieve an inference accuracy of 98.8% on the MNIST dataset.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others
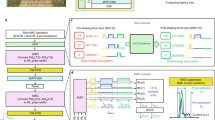

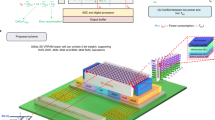
Data availability
The data that support the plots within this paper and other findings of this study are available from the corresponding author upon reasonable request.
Code availability
The code that supports the experimental platforms and proposed nvCIM test chip and SBITW network is available from the corresponding author upon reasonable request.
References
Price, M. et al. A scalable speech recognizer with deep-neural-network acoustic models and voice-activated power gating. In Proceedings of IEEE International Solid-State Circuits Conference (ISSCC) 244–245 (IEEE, 2017).
Shin, D. et al. DNPU: An 8.1TOPS/W reconfigurable CNN-RNN processor for general-purpose deep neural networks. In Proceedings of IEEE International Solid-State Circuits Conference (ISSCC) 240–241 (IEEE, 2017).
Chen, Y.-H., Krishna, T., Emer, J. S. & Sze, V. Eyeriss: an energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid State Circuits 52, 127–138 (2017).
Sze, V., Chen, Y.-H., Yang, T.-J. & Emer, J. S. Efficient processing of deep neural networks: a tutorial and survey. Proc. IEEE 105, 2295–2329 (2017).
Xu, A. et al. Scaling for edge inference of deep neural networks. Nat. Electron. 1, 216–222 (2018).
Ventra, M. D. & Pershin, V. The parallel approach. Nat. Phys. 9, 200–202 (2013).
Wong, H.-S. P. & Salahuddin, S. Memory leads the way to better computing. Nat. Nanotechnol. 10, 191–194 (2015).
Yang, J. J., Strukov, D. B. & Stewart, D. R. Memristive devices for computing. Nat. Nanotechnol. 8, 13–24 (2013).
Zidan, M.-A., Strachan, J.-P. & Lu, W.-D. The future of electronics based on memristive systems. Nat. Electron. 1, 22–29 (2018).
Ielmini, D. & Wong, H.-S. P. In-memory computing with resistive switching devices. Nat. Electron. 1, 333–343 (2018).
Chi, P. et al. PRIME: a novel processing-in-memory architecture for neural network computation in ReRAM-based main memory. ACM SIGARCH Comput. Archit. News 44, 27–39 (2016).
Li, S. et al. Pinatubo: A processing in non-volatile memory architecture for bulk bitwise operations. In Proceedings of the 53rd Annual Design Automation Conference 170 (ACM, 2016).
Su, F. et al. A 462GOPs/J RRAM-based nonvolatile intelligent processor for energy harvesting IoE system featuring nonvolatile logics and processing-in-memory. In Proceedings of Symposium on VLSI Circuits T260–T261 (2017).
Chen, W.-H. et al. A 16 Mb dual-mode ReRAM macro with sub-14 ns computing-in-memory and memory functions enabled by self-write termination scheme. In Technical Digest of the International Electron Devices Meeting (IEDM) 28.2.1–28.2.4 (IEEE, 2017).
Chen, W.-H. et al. A 65 nm 1 Mb nonvolatile computing-in-memory ReRAM macro with sub-16 ns multiply-and-accumulate for binary DNN AI edge processor. In IEEE International Solid-State Circuits Conference (ISSCC) Digest of Technical Papers 494–495 (2018).
Xue, C.-X. et al. A 1Mb multibit ReRAM computing-in-memory macro with 14.6ns parallel MAC computing time for CNN-based AI edge processors. In IEEE International Solid-State Circuits Conference (ISSCC) Dig. Tech. Papers 388–389 (2019).
Dou, C. et al. Nonvolatile circuits–devices interaction for memory, logic and artificial intelligence. In Symposium on VLSI Circuits Digest of Technical Papers 171–172 (IEEE, 2018).
Ney, A., Pampuch, C., Koch, R. & Ploog, K. H. Programmable computing with a single magnetoresistive element. Nature 425, 485–487 (2003).
Borghetti, J. et al. ‘Memristive’ switches enable ‘stateful’ logic operations via material implication. Nature 464, 873–876 (2010).
Li, H. et al. Hyperdimensional computing with 3D VRRAM in-memory kernels: device-architecture co-design for energy-efficient, error-resilient language recognition. In Technical Digest of the International Electron Devices Meeting (IEDM) 16.1.1–16.1.4 (IEEE, 2016).
Chen, B. et al. Efficient in-memory computing architecture based on crossbar arrays. In Technical Digest of the International Electron Devices Meeting (IEDM) 16.5.1–16.5.4 (IEEE, 2015).
Prezioso, M. et al. Training and operation of an integrated neuromorphic network based on metal–oxide memristors. Nature 521, 61–64 (2015).
Yao, P. et al. Face classification using electronic synapses. Nat. Commun. 8, 15199 (2017).
Sheridan, P. M. et al. Sparse coding with memristor networks. Nat. Nanotechnol. 12, 784–789 (2017).
Li, C. et al. Analogue signal and image processing with large memristor crossbars. Nat. Electron. 1, 52–59 (2018).
Wang, Z. et al. Fully memristive neural networks for pattern classification with unsupervised learning. Nat. Electron. 1, 137–145 (2018).
Ambrogio, S. et al. Equivalent-accuracy accelerated neural-network training using analogue memory. Nature 558, 60–67 (2018).
He, K. et al. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 770–778 (IEEE, 2016).
Huang, G. et al, Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 4700–4708 (IEEE, 2017).
Deamen, J. et al. Specification for the Advanced Encryption Standard (AES) 197 (FIPS, 2001).
Mathew, S. et al. 340 mV–1.1 V, 289 Gbps/W, 2090-gate nanoAES hardware accelerator with area-optimized encrypt/decrypt GF(24)2 polynomials in 22 nm tri-gate CMOS. IEEE J. Solid State Circuits 50, 1048–1058 (2015).
Xie, M. et al. Securing emerging nonvolatile main memory with fast and energy-efficient AES in-memory implementation. IEEE Trans. VLSI Syst. 20, 2443–2455 (2018).
Rastegari, M. et al. XNOR-Net: ImageNet classification using binary convolutional neural networks. Preprint at https://arxiv.org/abs/1603.05279 (2016).
Hubara, I. et al. Binarized neural networks: training neural networks with weights and activations constrained to +1 or –1. Preprint at https://arxiv.org/abs/1602.02830 (2016).
Tseng, Y.-H. et al. High density and ultra small cell size of contact ReRAM (CR-RAM) in 90 nm CMOS logic technology and circuits. In Technical Digest of the International Electron Devices Meeting (IEDM) 1–4 (IEEE, 2009).
Cheng, H. Y. et al. An ultra high endurance and thermally stable selector based on TeAsGeSiSe chalcogenides compatible with BEOL IC integration for cross-point PCM. In Technical Digest of the International Electron Devices Meeting (IEDM) 2.2.1–2.2.4 (IEEE, 2017).
Chen, A. A highly efficient and scalable model for crossbar arrays with nonlinear selectors. In Technical Digest of the International Electron Devices Meeting (IEDM) 37.2.1–37.2.4 (IEEE, 2018).
Chou, C.-C. et al. An N40 256K×44 embedded RRAM macro with SL-precharge SA and low-voltage current limiter to improve read and write performance, In International Solid-State Circuits Conference (ISSCC) Digest of Technical Papers 478–479 (IEEE, 2018).
Fackenthal, R. et al. A 16 Gb ReRAM with 200 MB/s write and 1 GB/s read in 27 nm technology. In International Solid-State Circuits Conference (ISSCC) Digest of Technical Papers 338–339 (IEEE, 2014).
Chung, S.-W. et al. 4 Gbit density STT-MRAM using perpendicular MTJ realized with compact cell structure. In Technical Digest of the International Electron Devices Meeting (IEDM) 27.1.1–27.1.4 (IEEE, 2016).
Rho, K. et al. A 4 Gb LPDDR2 STT-MRAM with compact 9F2 1T1MTJ cell and hierarchical bitline architecture. International Solid-State Circuits Conference (ISSCC) Digest of Technical Papers 396–397 (IEEE, 2017).
Kraus, R. Analysis and reduction of sense-amplifier offset. IEEE J. Solid State Circuits 24, 1028–1033 (1989).
Courbariaux, M. et al. Binarynet: training deep neural networks with weights and activations constrained to +1 or –1. Preprint at https://arxiv.org/abs/1602.02830 (2016).
Rastegari, M. et al. XNORNet: ImageNet classification using binary convolutional neural networks. In Proceedings of European Conference on Computer Vision (ECCV) 525–542 (Springer, 2016).
Liu, R. et al. Parallelizing SRAM arrays with customized bit-cell for binary neural networks. Proceedings of the 55th Annual Design Automation Conference 21 (ACM, 2018).
Khwa, W.-S. et al. A 65 nm 4 kb algorithm-dependent computing-in memory SRAM Unit-Macro with 2.3 ns and 55.8 TOPS/W fully parallel product-sum operation for binary DNN edge processors. In International Solid-State Circuits Conferences (ISSCC) Digest of Technical Papers 496–498 (IEEE, 2018).
Chang, M.-F. et al. An offset-tolerant fast-random-read current-sampling-based sense amplifier for small-cell-current nonvolatile memory. IEEE J. Solid State Circuits 48, 864–877 (2013).
Lecun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Acknowledgements
The authors acknowledge support from NVM-DTP of TSMC, TSMC-JDP and MOST-Taiwan.
Author information
Authors and Affiliations
Contributions
W.-H.C., K.-X.L. and W.-Y.L. developed the concept of this work, designed the circuits and the chip. W.-H.C. and C.D. performed the electrical analysis and measurements of the nvCIM macro. J.-H.H. and J.-H.W. built the MNIST demonstration system with input from R.-S.L. Y.-C.K. and C.-J.L. designed the contact RRAM devices. P.-Y.L., W.-C.W. and W.-H.C. conceived the neural network algorithm and CIM chip design, with input from C.-C.H., K.-T.T., M.-S.H. and M.-F.C. W.-H.C. and C.D. wrote the manuscript, with input from J.J.Y. and M.-F.C. All authors discussed the results and gave approval for the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary Figs. 1–11, Tables 1–3 and Notes 1–7
Rights and permissions
About this article

Cite this article
Chen, WH., Dou, C., Li, KX. et al. CMOS-integrated memristive non-volatile computing-in-memory for AI edge processors. Nat Electron 2, 420–428 (2019). https://doi.org/10.1038/s41928-019-0288-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41928-019-0288-0
This article is cited by
-
Hardware implementation of memristor-based artificial neural networks
Nature Communications (2024)
-
Parallel in-memory wireless computing
Nature Electronics (2023)
-
An in-memory computing architecture based on a duplex two-dimensional material structure for in situ machine learning
Nature Nanotechnology (2023)
-
A full spectrum of computing-in-memory technologies
Nature Electronics (2023)
-
Passive frustrated nanomagnet reservoir computing
Communications Physics (2023)
