
Abstract
The complexity of business decision-making has increased over the years. It is essential for managers to gain a confident understanding of their business environments in order to make successful decisions. With the growth of opinion-rich web resources such as social media, discussion forums, review sites, news corpora, and blogs available on the internet, product and service reviews have become an essential source of information. In a data-driven world, they will improve services and operational insights to achieve real business benefits and help enterprises remain competitive. Despite the prevalence of textual data, few studies have demonstrated the effectiveness of real-time text mining and reporting tools in firms and organizations. To address this aspect of decision-making, we have developed and evaluated an unsupervised learning system to automatically extract and classify topics and their emotion score in text streams. Data were collected from commercial websites, open-access databases, and social networks to train the model. In the experiment, the polarity score was quantified at four different levels: word, sentence, paragraph, and the entire text using Latent Dirichlet Allocation (LDA). Using subjective data mining, we demonstrate how to extract, summarize, and track various aspects of information from the Web and help traditional information retrieval (IR) systems to capture more information. An opinion tracking system presented by our model extracts subjective information, classifies them, and tracks opinions by utilizing location, time, and reviewers’ positions. Using the online-offline data collection technique, we can update the library topic in real-time to provide users with a market opinion tracker. For marketing or economic research, this approach may be useful. In the experiment, the new model is applied to a case study to demonstrate how the business process improves.
Similar content being viewed by others


Introduction
As information continues to grow, firms are changing their strategies to grow their market share. Managers and leaders formulate their strategies based on all the competitive tactics and operational measures. Developing sustained leadership requires understanding all external and internal information (news, media, and social networks), listening to the internal context (internal surveys, career websites, and social networks), analyzing and summarizing information, and communicating the results effectively (Zhang et al., 2019). The emergence of social media has given online users a place for expressing and sharing their thoughts and opinions on different topics and events. In the market and e-commerce, understanding the role of social media, news, and customer reviews is becoming increasingly critical (Quach et al., 2020). Companies and service providers monitor user responses to their products and services on social media platforms such as Twitter, LinkedIn, Facebook, YouTube videos, and news sites.
Discussions about current issues, complaints, and sentiments on the Internet are an excellent source of information. Developing knowledge from extracted data (mostly unstructured) has been shown to have a significant effect on sales and consumer decision-making (Shen et al., 2019). Unlike structured data, unstructured texts, audios, and videos are complex and difficult to analyze. Salloum et al. (2018) have demonstrated the importance of developing existing, efficient, and appropriate methods for mining heterogeneous datasets. Businesses and service providers often lack the knowledge and time to determine if their choice of competing products from numerous websites is the right one. Hertrich et al. (2020) and Jang et al. (2016) offered an approach to identifying metaphors and topics at the sentence-level by targeting sentences, surrounding contexts, emotions, and cognitive words. The proposed model showed a significant improvement in detecting metaphors with over-classification.
However, recent cognitive neuroscience studies dispute the idea that explanatory and communicative practices can be explained purely in terms of mental structures without reference to emotional factors. Qualitative content analysis is commonly used in sociology to analyze interview transcripts, online news, open-ended survey responses, newspapers, and social media text, whereas quantitative and combined text analysis techniques are less common. Lauter (2022) and Ignatow (2016) believe that there is a lack of social science research on the benefits of analyzing large corpora of text with artificial intelligence. In addition, applying linguistic theories to the problem of modeling intersubjective information construction has proven insufficient. Lakoff (2012) argues that formal language models are highly artificial and do not address emotions or perceptions. Language is fundamentally influenced by embodied cognition, which is problematic. Kobayashi et al. (2018) and Zhang et al. (2019) described how text mining can allow the testing of existing or new research questions with rich, context-rich, and ecologically valid data.
To collect and analyze these volumes of heterogeneous, largely unstructured data, multiscale modeling and automation are necessary. Additionally, that modeling will help reduce uncertainty about information, products, and services. In order to accomplish this task, data must be classified automatically in real-time as positive, negative, or neutral. The characteristics and irregular structure of social media content have posed some challenges to Natural Language Processing (NLP). In this study, we attempted to address some of these issues, including presenting a competitive intelligence (CI) process that integrates information from a strategic perspective to monitor the market environment and to predict customer behavior. An in-depth analysis of previous work on online text mining for market prediction has been conducted, providing an insight into today’s cutting-edge research and future directions.
The following contributions are made as a result of the work:
-
1.
We have provided a brief overview of the relevant economic and information technology concepts. We have also provided an explanation of their relationship with the solutions to the problem that are currently being proposed.
-
2.
In order to be able to study cutting-edge research for this project, we reviewed recent significant published literature.
-
3.
An online data collection and classification method is described, along with the reasons why it can be used to create business intelligence (BI) analysis for strategic decision-making by detecting and extracting subjective information from human-generated comments, feedback, and suggestions.
-
4.
Here, we present our findings as well as the proposed feature engineering process, outlining how data have been transformed into knowledge.
-
5.
Lastly, we conclude by discussing our findings and potential future research directions.
Literature review
Background
Information can be extracted from text using statistical analysis, computational linguistics, and machine-learning techniques. The human-generated text can be converted into meaningful information and summaries to support businesses in making evidence-based decisions (Zhang et al., 2019; Salloum et al., 2018). Despite the fact that web archives contain a wealth of information and knowledge resources (Costa et al., 2017), their increasing number of texts and increasing level of noise make them difficult to analyze and extract information (Zhang et al., 2019; Gajzler, 2010). Shen et al. (2019) merged machine learning and natural language processing in order to predict return the on investment (ROI). Their model accurately predicted the relationship between script features and movie success with 90% accuracy.
Human behavioral coding
It is possible to combine automatic sentiment analysis with human coding. For purposes of demonstrating the effectiveness of human coding, Bail (2012) examined media discourses and civil society organizations related to Islam after September 2001. From large text collections of sentiment human coding, we can capture behavioral, cultural, and contextual nuances. We cannot accomplish this through manual categorization followed by training the algorithm to categorize the remaining documents using supervised learning techniques (Idalski Carcon et al., 2019). The method must construct a training set and a learning model in which well-defined relationships between categories and features validate the outputs and classify the remaining documents. It was explained by Grimmer and Stewart (2013) how supervised methods are used to determine the labels of documents. First, they create a training set based on features and categories in the training set, and then they apply the learning method to infer the labels for the test set (Grimmer and Stewart, 2013). Using supervised learning models, researchers can construct conceptually coherent models, measure the models’ performance, and then utilize statistical methods to validate their predictions. There have been several scientific applications of supervised learning methods to sentiment analysis, including those presented by Nakov et al. (2019), Soleymani et al. (2017), and Cambria (2016).
Behavioral-economics
According to cognitive and behavioral economists, price is not a measure of costs of production, but rather it is a measure of perceived value. In spite of this, the media are not only focused on reporting on the status of the market, but are also able to actively affect market dynamics through their coverage (Wisniewski and Lambe, 2013; Robertson et al., 2006). Individuals interpret information differently, and market participants are affected by cognitive biases such as overconfidence, overreaction, representative bias, and information bias (Friesen and Weller, 2006). Research on behavioral finance and investor sentiment suggests that investors’ behavior can be influenced by whether they feel optimistic (bullish) or pessimistic (bearish) about future market valuations (Shankar et al., 2019; Bollen et al 2011).
Social network text mining techniques
Greco and Polli (2020) and Cui et al. (2011) examine Twitter text mining by analyzing emotional tokens. They explained how emotion tokens could be extracted from the message, plotted different polarities, and then the algorithm classified those emotions as negative, positive, and neutral. Kowshalya and Valarmathi (2018) found that Cui et al. (2011)‘s approach was insufficient in terms of sentiment analysis, lacked emotional representation, and required more time. Hasan et al. (2019) claimed their algorithm, which utilizes the sliding window kappa statistic for constantly changing data streams, classified real-time tweet streams, and performed sentiment analysis. Normally, a real-time Twitter stream is unbalanced, but the study utilized balanced data, not a stream in real-time.
According to Wang et al. (2022), real social networks are highly heterogeneous and sophisticated. In many practical problems, it is unrealistic to assume that individual contributions are distributed uniformly. It is the key leader who promotes consensus among members of an organization or a decision-maker. Therefore, their followers respond to their decision. A leader-follower consensus system is used by Xiao et al. (2020) to investigate how key leaders drive network segregation. However, previous studies have failed to take into account the heterogeneous nature of real networks.
Ye and Wu (2010) demonstrate how to identify popular tweets by considering different social influences and their effects, such as stability, correlations, and assessments. However, the polarity of the influence was not explained. Araque et al. (2019) demonstrate how supervised learning algorithms can be used to determine or change sentiment-related attributes when lexicons are generated from scratch. Nagy and Stamberger (2012) analyzed informative messages delivered by crowds during disasters and crises using classification-driven methods, while Montejo-Dridi and Recupero (2019) utilized social media frames to extract meaningful sentiment analysis features in order to generate more accurate sentiment analysis models. Montejo-Raez et al. (2012) presented an unsupervised method of determining polarity. This method is based on a random walk algorithm. SentiWordNet’s polarity score is summed and the results are compared to the performance of Support Vector Machine (SVM).
Ortega et al. (2013) implemented a multilayer model with three stages: preprocessing, polarity detection based on SentiWordNet and WordNet, and rule-based classification. Bravo-Marquez et al. (2013) demonstrated how to improve classification accuracy by combining techniques for opinion strength, emotion, and polarity prediction. Furthermore, Natarajan et al. (2020) used a collaborative filtering model for predicting sentiment on Twitter as a solution for a data sparsity problem. To support multilingual datasets, Liu et al. (2019) applied minimal linguistic processing to sentiment analysis. Despite the advantages and limitations of the techniques mentioned above, a comprehensive model can overcome these limitations.
Polarity mining
The terms emotion mining, sentiment mining, attitude mining, and subjectivity mining refer to methods for extracting and analyzing opinions expressed in text reviews, which are usually unstructured and heterogeneous for products, organizations, individuals, and events. The information can be utilized by search engines to synthesize and analyze product reputations (Nithyashree and Nirmala, 2020; Rambocas and Pacheco, 2018; Kunal et al., 2018; Penubaka, 2018; Mini, 2017). The majority of web blogs, discussion forums, and newspaper columns containing many opinions do not provide systematic organization of information based on such opinions. Furthermore, some review sites may not provide star ratings or scale ratings, and some users may misunderstand what a rating means. There are three levels of sentiment analysis: document-level, sentence-level, and aspect-level. A document’s polarity score is explained by document-level techniques. In contrast to document-level techniques, sentence-level techniques distinguish subjective sentences from objective ones and assign each a polarity score. Polarities are calculated by using aspect-based techniques. In aspect-based techniques, all sentiments in a document are identified, as well as the aspects of the entity that each sentiment refers to. Client reviews generally contain opinions concerning various aspects of a product or service. This method allows the vendor to acquire valuable information from several aspects of that specific product or service that would otherwise be lost if the sentiment were only categorized in terms of polarity (Salloum et al., 2018). To avoid further complexity in polarity mining, it is also necessary to remove any noise from the raw data, including page numbers, URLs, and messed-up tables. Both consumers and businesses can benefit from polarity mining. Polarity mining enables consumers to make better decisions regarding what products and services to purchase as well as businesses and organizations to make more informed strategic decisions. Polarity Mining can be divided into supervised and unsupervised techniques. In the supervised method, polarity mining is treated as a classification problem, while in the knowledge-rich unsupervised method, it is based on external knowledge resources beyond the raw data. Unlike supervised approaches, unsupervised approaches extract words or phrases from the text that express semantic orientation, and then determine the polarities of these words or phrases. The polarity of a text is determined by aggregating the polarities of individual words or phrases.
Liebrecht et al. (2019) demonstrated the different effects of positive and negative messages. In a study of online consumer reviews, Purnawirawan et al. (2015) analyzed online consumer reviews and found that consumers who read neutral reviews are more likely to be negative than those who read positive reviews. Despite these concerns, there has not been enough research done on how negative reviews can be shifted into positive ones over time.
Methodology: algorithms and problem formulation
To train a classic machine-learning model for product recommendation, most research combines similarity and sentiment scores over certain features. Based on the frequency of keywords that are mined in the other models, opinions are retrieved as words, phrases, or entire documents (Fig. 1) (Da’u et al., 2020; Kobayashi et al., 2018; Jang et al., 2016; Purnawirawan et al., 2015; Montejo-Raez et al., 2012; Lakof, 2012).

Data collected by an automated data-processing system can be used to solve problems and guide decision-making.
The real-time decision-support model we propose combines cognitive intelligence with NLP concepts. It also provides business decision-makers with a better awareness of destructive subjects by turning online resources and social media into real-time productivity, and it purifies unstructured text data into subjective knowledge. The proposed cognitive-based decision-support algorithm is represented in section “Proposed algorithm”.
Moreover, in this experiment, the proposed algorithm has been collecting data from all online sources for more than 2 years, while updating the data-lake every month. This case study proposes a model capable of understanding data types, performing optimal feature engineering to eliminate data redundancy by finding highly correlated features at an early stage, and then transforming those features into tables. Analysts and end users can learn from extracted topics, apply that learning, and monitor improvements in real-time as textual data is continuously gathered through the analytics algorithm.
Methodology for collecting and preprocessing text
Modeling a business involves defining the data collection process and determining the most relevant data sources. Data sources may include news websites, blogs and forums, official websites, corporate documents (such as reports, internal surveys, and earnings calls transcripts), personal text (such as chats, emails, SMS messages, and tweets), as well as open-ended survey responses. By using web APIs (application programming interfaces) or scraping (such as automatic extraction of web page content), text data are collected from websites.
The next step to improving data quality and validity is segmenting texts and cleaning text data. Keep only relevant text elements (Indurkhya et al., 2010) and remove unimportant characters (such as extra spaces and formatting tags), text segmentation, lowercase conversion, and word stemming. Prepositions and conjunctions (such as all, and, the, of, for) contribute minimally to the meaning of the text. It unifies semantically similar terms (for example, “acceptance,” “accepting,” and “accepted” become “accept”). These techniques also reduce the vocabulary size.
To convert the text into a matrix format, the text needs to be transformed into mathematical structures, where rows represent documents and columns represent variables (features). The matrix is referred to as the ‘document-by-term matrix’, and its values correspond to the “weights” of the words in the document (Venkatraman et al., 2020). In terms of categorizing or classifying documents, the frequency of words alone does not provide very useful information (Kobayashi et al., 2018). To avoid the inclusion of words that have little discriminatory power, each word can be assigned a weight based on its specificity to a few documents within a corpus (Lan et al., 2008). The raw frequency of a word is usually multiplied by the inverse document frequency (IDF), allowing the importance and specificity of a word to be taken into account simultaneously (Zhu et al., 2019).
Text mining for service experience
Cognitive decision-support systems (CDSS) have been recognized as an essential component of the research and development of BI. Management can make better decisions by utilizing cognitive processes, such as intelligence and perception, as well as leveraging experience to the fullest extent possible. Situation awareness (SA) and mental models are two of these cognitive factors that are considered vital for making an informed decision. This is especially true in dynamic, ill-structured decision situations with uncertainties, time constraints, and high stakes involved. In this study, we propose a model for generating BI through the use of human-generated reviews and news. Its success depends directly on the model’s ability to detect and extract subjective information from human-written reviews and news articles. Prior to making a recommendation, this model evaluates the texts and their features for richness.
Proposed algorithm
Our primary goal is to develop a model for an online intelligence decision-support system that combines artificial intelligence, text mining, and competitive intelligence in an effort to assist business leaders in improving their businesses by analyzing opinions, surveys, and feedback from customers. Several classic text mining and information extraction studies have been taken into account in this study, integrating machine learning and multiscale modeling and making some recommendations for practical applications (Giordano et al., 2021; Ren et al., 2021; Alber et al., 2019; Kumar et al., 2019; Dong et al., 2016).
To give readers a better understanding of how the algorithm works, Fig. 2 shows the pseudocode version. This algorithm uses textual data as input. The data pipeline automatically identifies the most relevant data sources and preprocess text corpora. A customized text cleaning process is undertaken by keeping only relevant text elements and removing unimportant characters, lemmatization, and segmenting the text into words, sentences, and paragraphs. The classification phase involves assigning the appropriate topics to each review, validating the topic, and calculating sentiment scores for the review, each paragraph of the review, and each sentence of the review. In the next step, the algorithm calculates the most accurate sentiment score for the topic. Finally, return the top-N topics with a weighted sentiment score for each class.

Separate sentiment scores are assigned to paragraphed and sentence topics. In the end, the topic is given a weighted sentiment.
In order to assign an accurate sentiment score to extracted topics from the corpus, the algorithm aggregates topic modeling and sentiment scores at the service level. At the review level, distinct sentiment scores are assigned to paragraphed and sentence topics. The last step is to assign a weighted sentiment to the topic (see section “Text to structured data”).
Results and discussion
Datasets
We were primarily focused on news and reviews of online business services. The data had been collected for over 2 years. By combining text mining and natural language processing with advanced feature engineering in the early stages, we can determine the reviewer’s location (city, state, and country), occupation, and length of employment, which enables us to create customized features such as employment-location and location-topics. In social media applications and websites, full-text, date and time of entry, number of likes and shares, and impressions are all retrieved. For news, it extracts the full-text, publication date, and the source. Statistical information about the dataset is shown in Table 1.
Collect textual data
The collection of diverse and large amounts of relevant data is an essential component of decision-support systems (Roh et al., 2019). However, ideal datasets that reflect all subtypes of the study condition are expensive and often impractical to obtain (Farzaneh et al., 2021). This model integrates online and offline data. This textual data is collected automatically from external sources as well as internal sources such as emails, surveys, quarterly reports, earnings calls, and internal multimedia.
Text to structured data
Text may be processed in a variety of formats, including JSON, XML, PDF, MS Word, and HTML. By developing advanced feature engineering techniques and integrating them with NLP techniques, we were able to achieve the highest level of data granularity for our competitive intelligence analysis. A combination of named entity recognition (NER), n-grams, and part-of-speech tagging techniques has been used to extract names and locations. This algorithm continuously proceeds to data preparation and information processing. To further enrich the dataset, a polarity score has also been added.
Ti (Fig. 4) indicates how frequently each topic is associated with positive, negative, or neutral sentiment based on the opinions expressed in reviews of the whole corpus. At the review level, they are combined with the sentiment scores (S) to generate a case of topics and modified sentiment scores. After text cleaning, W would be the set of words as a full sentence in each document:
The score is calculated as follows:
Transforming information into knowledge
Topic modeling techniques can be used when dealing with large-scale documents and interpreting latent topics. In terms of performance, the LDA model is known to be the most successful (Jeong et al., 2019). LDA is known as a generative probabilistic model. Using machine learning, the system can determine the meaning of words from large corpora of text in any discipline without making a critical assumption about their meaning (Blei et al., 2003). Amado et al. (2018) presented the results of marketing research using LDA-based topic modeling in order to analyze trends in large datasets, while Nie et al. (2017) demonstrated the results of design research utilizing LDA-based topic modeling. LDA models divide the corpus into partitions based on topics. The LDA model then uses the TF-IDF values as input from the documents and the number of topics specified by the user. It determines the probability that a document is associated with a topic, resulting in a new vector space model of LDA topics (Fig. 3) (Carrera-Trejo et al., 2015).

In the LDA, each document is represented based on its probability of belonging to a topic. Probability distributions are generated based on n-grams (or syntactic n-grams) of the corpus. Topics determine the number of partitions in LDA.
In our experiment, we considered two types of features: Bi-gram features and LDA topic modeling. Using simplified NLP and statistical techniques (Dong et al., 2016), from reviews as {R1, R2, ..., RN}, we were able to extract modified collocations such as adjectives followed by nouns (AN), or nouns followed by nouns (NN), such as Service Delivery (Fig. 4).

A successful learning and generalization process requires the right feature set. The predictability of a classifier decreases as it adds more dimensions or features to the training dataset (it is known as the Curse of Dimensionality). The training dataset is always a finite set of samples with discrete values, while the prediction space may be infinite and continuous in all dimensions. Adding features also incurs a cost. Highly correlated features provide only limited benefit to a classifier, but they require a lot of training and persistence time. Since machine learning requires a great deal of CPU, memory, and elapsed time, limiting the number of features that can be implemented makes a great deal of sense.
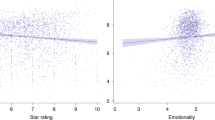
Figure 5 illustrates a strong correlation between the modified sentiment score and the weighted scores assigned to reviews by the reviewers. Moreover, the location of the reviewer and the source of the review (such as social networks and news websites) are highly correlated.

Dark blue squares indicate that properties on the x and y axes are more correlated. When both features are added to the training data, higher correlation leads to a possible negative impact on the classification model.
Classification results
Classification reports are generated to determine whether the model is capable of accurately determining which topics are classified as true or false. A benchmark for future quality assurance has been created by periodically evaluating the model’s output with human supervision separately. The model will be able to calculate precise accuracy scores from the classification in the future. Tables 2 and 3 provide precision, recall, F-1 score, and number of observations for the top ten positive and negative topics, respectively. Development and evaluation of models should be based on a range of criteria in addition to high predictive accuracy. This advocacy of benchmarking does not mean that researchers should overlook other criteria. The performance of some models can be acceptable despite failing basic validity tests (Myung and Pitt, 2018). Furthermore, an increased emphasis on benchmarking may potentially help undermine the tendency that complex models are dismissed out of hand because of their complexity. Subjective factors play an important role in this process.
Compound sentiment
Tables 4 and 5 present the weighted average sentiment score for the top 10 positive and negative topics. Both tables have the same topics, indicating that this is the most common weakness and strength after review.
From the data collected between January 2017 and March 2018, the top 10 topics for both positive and negative issues were identified. A live modeling process has been conducted for topics since March 2018. In Figs. 6 and 7, we show the number of negative and positive topics and their trends in each category before and after using the model (red dotted line). Starting from January 2017, there have only been topics with their sentiment scores across both categories. However, as of March 2018, the model has presented the accuracy scores for the topics to decision-makers for further consideration. Over time, negative topics have decreased while positive topics have increased. According to cognitive psychology research, negative effects of words are perceived more strongly than positive ones (Alves et al., 2017). Research suggests that negative words are given more attention, evoke more emotions, influence behavior, and are stored better and longer in the memory (Alves et al., 2017; Lagerwerf et al., 2015). This means that the negativity effect would moderate more slowly than the positive one, as shown in Fig. 6.

Topics have been modeled live since March 2018. The graph illustrates the number of negative topics in each category and their trends before and after the model was employed.

In March 2018, a live modeling process was initiated for topics. Using the model, it shows the number of positive topics and their trends in each category prior to and following the application of the model.
Conclusions and future work
An end-to-end operational decision automation goes beyond decision modeling and implementing decision logic. This helps organizations deliver significant value to their shareholders and measure performance on the basis of their business values and key performance indicators (KPIs). Multiscale modeling was used in this study for the purpose of proving how subjective information extraction can improve short-term and long-term business and service decisions. Despite extensive research in this area, there is a need to link scholars’ findings with industry requirements. Prior studies have demonstrated that the strength of the corpus can be measured by individual words. In the study, recent research in text mining, natural language processing, and competitive intelligence was analyzed as a way to increase the return on investment. Normal sentiment analysis involves adding up the sentiment scores associated with each of the words in the wordlist (De Rijke et al., 2013). This study found that it is more beneficial to investigate the effects of positive and negative topics in the text corpus, in the form of N-grams (two-word compound expressions) rather than referring to the meaning of single words, and assigning a modified weighted sentiment score. Combinations of words can impact the perception of a corpus and the strength of an evaluation. Our studies confirm this theory.
Models are often evaluated by quantitative criteria such as model plausibility, explanatory adequacy, or faithfulness to existing literature (Myung and Pitt, 2018). Although this is an open question, it is important to know how these criteria should be applied to intelligent modeling. In general, we prefer a configuration in which qualitative constraints should not be considered in benchmark-based evaluation (i.e., model scores should not be based upon a subjective evaluation of theoretical elegance by a panel of judges).
Through the development of opinion mining and cognitive intelligence, topic modeling and modified sentiment analysis will be combined with advanced machine-learning techniques. Therefore, business owners will be able to discern each reviewer’s opinion separately, and understand the message they are trying to convey. It can also be used for crowdsourcing during a run of an experiment in order to monitor both short- and long-term outcomes to modify and improve it. Through the conversion of textual resources and social media into social productivity, it can have a positive impact on business operations.
In future research, the effectiveness of the proposed model needs to be re-evaluated over an extended period of time. Videos and voice recordings obtained from YouTube, Tiktok, and call centers provide rich sources of emotional information. This could increase the model’s reliability and open up new possibilities for discussion.
Data availability
Data generated and analyzed in this study are limitedly available upon reasonable request from the corresponding author.
References
Alber M, Buganza Tepole A, Cannon WR, De S, Dura-Bernal S, Garikipati K, Kuhl E (2019) Integrating machine learning and multiscale modeling—perspectives, challenges, and opportunities in the biological, biomedical, and behavioral sciences. NPJ Digit Med 2(1):1–11
Alves H, Koch A, Unkelbach C (2017) Why good is more alike than bad: Processing implications. Trend Cogn Sci 21(2):69–79
Amado A, Cortez P, Rita P, Moro S (2018) Research trends on Big Data in Marketing: a text mining and topic modeling based literature analysis. Eur Res Manage Bus Econ 24(1):1–7
Araque O, Zhu G, Iglesias CA (2019) A semantic similarity-based perspective of affect lexicons for sentiment analysis. Knowl Based Syst 165:346–359
Bail CA (2012) The fringe effect: Civil society organizations and the evolution of media discourse about Islam since the September 11th attacks. Am Sociol Rev 77(6):855–879
Blei DM, Ng AY, Jordan MI (2003) Latent dirichlet allocation. J Mach Learn Res 3(Jan):993–1022
Bollen J, Mao H, Pepe A (2011) Modeling public mood and emotion: Twitter sentiment and socio-economic phenomena. In Proceedings of the international AAAI conference on web and social media 5(1)pp 450–453
Bravo-Marquez F, Mendoza M, Poblete B (2013) Combining strengths, emotions and polarities for boosting Twitter sentiment analysis. In: Proceedings of the Second International Workshop on Issues of Sentiment Discovery and Opinion Mining. ACM.org, pp 1–9
Cambria E (2016) Affective computing and sentiment analysis. IEEE Intell Syst 31(2):102–107
Carrera-Trejo JV, Sidorov G, Miranda-Jiménez S, Moreno Ibarra M, Cadena, Martínez R (2015) Latent Dirichlet Allocation complement in the vector space model for multi-label text classification. Int J Comb Optim Probl Inform 6(1):7–19
Costa M, Gomes D, Silva MJ (2017) The evolution of web archiving. Int J Digit Libr 18(3):191–205
Cui A, Zhang M, Liu Y, Ma S (2011) Emotion tokens: Bridging the gap among multilingual twitter sentiment analysis. In Asia information retrieval symposium. Springer, Berlin, Heidelberg, pp. 238–249
Da’u A, Salim N, Rabiu I, Osman A (2020) Recommendation system exploiting aspect-based opinion mining with deep learning method. Inf Sci 512:1279–1292
De Rijke M, Jijkoun V, Laan F, Weerkamp W, Ackermans P, Geleijnse G (2013) Generating, refining and using sentiment lexicons. In Essential speech and language technology for dutch. pp 359–377
Dong R, O’Mahony MP, Schaal M, McCarthy K, Smyth B (2016) Combining similarity and sentiment in opinion mining for product recommendation. J Intell Inf Syst 46(2):285–312
Dridi A, Recupero DR (2019) Leveraging semantics for sentiment polarity detection in social media. Int J Mach Learn Cybernet 10(8):2045–2055
Farzaneh N, Williamson CA, Gryak J, Najarian K (2021) A hierarchical expert-guided machine learning framework for clinical decision support systems: an application to traumatic brain injury prognostication. NPJ Digit Med 4(1):1–9
Friesen G, Weller PA (2006) Quantifying cognitive biases in analyst earnings forecasts. J Financ Mark 9(4):333–365
Gajzler M (2010) Text and data mining techniques in aspect of knowledge acquisition for decision support system in construction industry. Technol Econ Dev Econ 2:219–232
Giordano V, Chiarello FCervelli E,(2021) Defining definition: a text mining approach to define innovative technological fields. https://arxiv.org/abs/2106.04210
Greco F, Polli A (2020) Emotional text mining: customer profiling in brand management. Int J Inf Manag 51:101934
Grimmer J, Stewart BM (2013) Text as data: the promise and pitfalls of automatic content analysis methods for political texts. Polit Anal 21(3):267–297
Hasan M, Rundensteiner E, Agu E (2019) Automatic emotion detection in text streams by analyzing twitter data. Int J Data Sci Analyt 7(1):35–51
Hertrich I, Dietrich S, Ackermann H (2020) The margins of the language network in the brain. Front Commun 5:519955
Idalski Carcon A, Hasan M, Alexander GL, Dong M, Eggly S, Brogan Hartlieb K, Kotov A (2019) Developing machine learning models for behavioral coding. J Pediat Psychol 44(3):289–299
Ignatow G (2016) Theoretical foundations for digital text analysis. J Theory Soc Behav 46(1):104–120
Indurkhya N, Damerau F J, D Palmer D (2010) Text Preprocessing. Handbook of Natural Language Processing, Second Edition. Chapman et Hall/CRC 9
Jang H, Jo Y, Shen Q, Miller M, Moon S, Rose C (2016) Metaphor detection with topic transition, emotion and cognition in context. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (vol. 1: Long Papers). ACL Anthology, pp 216–225
Jeong B, Yoon J, Lee JM (2019) Social media mining for product planning: a product opportunity mining approach based on topic modeling and sentiment analysis. Int J Inf Manag 48:280–290
Kobayashi VB, Mol ST, Berkers HA, Kismihok G, Den Hartog DN (2018) Text classification for organizational researchers: a tutorial. Organ Res Methods 21(3):766–799
Kobayashi VB, Mol ST, Berkers HA, Kismihók G, Den Hartog DN (2018) Text mining in organizational research. Organ Res Methods 21(3):733–765
Kowshalya AM, Valarmathi ML (2018) Evaluating twitter data to discover user’s perception about social internet of things. Wirel Pers Commun 101(2):649–659
Kumar V, Rajan B, Venkatesan R, Lecinski J (2019) Understanding the role of artificial intelligence in personalized engagement marketing. Calif Manag Rev 61(4):135–155
Kunal S, Saha A, Varma A, Tiwari V (2018) Textual dissection of live Twitter reviews using naive Bayes. Procedia Comput Sci 132:307–313
Lagerwerf L, Boeynaems A, van Egmond-Brussee C, Burgers C (2015) Immediate attention for public speech: differential effects of rhetorical schemes and valence framing in political radio speeches. J Lang Soc Psychol 34(3):273–299
Lakoff G (2012) Explaining embodied cognition results. Top Cogn Sci 4(4):773–785
Lan M, Tan CL, Su J, Lu Y (2008) Supervised and traditional term weighting methods for automatic text categorization. IEEE Trans Pattern Anal Mach Intell 31(4):721–735
Lauter K (2022) Private AI: machine learning on encrypted data. In Recent Advances in Industrial and Applied Mathematics. Springer Cham pp 97–113
Liebrecht C, Hustinx L, van Mulken M (2019) The relative power of negativity: The influence of language intensity on perceived strength. J Lang Soc Psychol 38(2):170–193
Liu Y, Fu Y, Wang Y, Cui Y, Zhang Z (2019) Mixed word representation and minimal Bi-GRU model for sentiment analysis. In 2019 Twelfth International Conference on Ubi-Media Computing IEEE (Ubi-Media). IEEE. pp 30–35
Mini U (2017) Opinion mining for monitoring social media communications for brand promotion. Int J Adv Res Comput Sci 8:3
Montejo-Ráez A, Martínez-Cámara E, Martin-Valdivia MT, López LAU (2012) Random walk weighting over sentiwordnet for sentiment polarity detection on twitter. In Proceedings of the 3rd Workshop in Computational Approaches to Subjectivity and Sentiment Analysis. ACL Anthology, pp 3–10
Myung JI, Pitt MA (2018) Model comparison in psychology. In Stevens’ handbook of experimental psychology and cognitive neuroscience. John Wiley & Sons (vol 5). pp 1–34
Nagy A, Stamberger JA (2012) Crowd sentiment detection during disasters and crises. ISCRAM
Nakov P, Ritter A, Rosenthal S, Sebastiani F, Stoyanov V (2019) SemEval-2016 task 4: sentiment analysis in Twitter. https://arxiv.org/abs/1912.01973
Natarajan S, Vairavasundaram S, Natarajan S, Gandomi AH (2020) Resolving data sparsity and cold start problem in collaborative filtering recommender system using linked open data. Exp Syst Appl 149:113248
Nie W, Li X, Liu A, Su Y (2017) 3D object retrieval based on Spatial+ LDA model. Multimedia Tools and Applications. Springer, 76(3):4091–4104
Nithyashree T, Nirmala MB (2020) Analysis of the Data from the Twitter account using Machine Learning. In 2020 5th International Conference on Communication and Electronics Systems IEEE. (ICCES). IEEE. pp 989–993
Ortega R, Fonseca A, Montoyo A (2013) SSA-UO: unsupervised Twitter sentiment analysis. In Second joint conference on lexical and computational semantics (*SEM) (vol 2). ACL Anthology, pp 501–507
Penubaka P (2018) Feature Based summarization system for E-Commerce BAsed Products by Using Customers’ reviews. In 2018 IADS International Conference on Computing, Communications & Data Engineering (CCODE). SSRN, pp 7–8
Purnawirawan N, De Pelsmacker P, Dens N (2015) The impact of managerial responses to online reviews on consumers’ perceived trust and attitude. In Advances in advertising research. Springer Gabler, Wiesbaden. pp 63–74
Quach S, Shao W, Ross M, Thaichon P (2020) Customer participation in firm-initiated activities via social media: understanding the role of experiential value. Aust Market J (AMJ). https://doi.org/10.1016/j.ausmj.2020.05.006
Rambocas M, Pacheco B G (2018) Online sentiment analysis in marketing research: a review. J Res Interact Market 12:146–163
Ren J, Xia F, Chen X, Liu J, Hou M, Shehzad A, Kong X (2021) Matching algorithms: fundamentals, applications and challenges. IEEE Trans Emerg Topic Comput Intell. 5(3):332–350
Robertson C, Geva S, Wolff R (2006) What types of events provide the strongest evidence that the stock market is affected by company specific news. In Proceedings of the Fifth Australasian Data Mining Conference. Australian Computer Society pp 145–154
Roh Y, Heo G, Whang S E (2019) A survey on data collection for machine learning: a big data-ai integration perspective. IEEE Transactions on Knowledge and Data Engineering. IEEE
Salloum S A, Al-Emran M, Monem A A, Shaalan K (2018) Using text mining techniques for extracting information from research articles. In Intelligent natural language processing: trends and applications. Springer, Cham. pp 373–397
Shankar K, Ilayaraja M, Deepalakshmi P, Ramkumar S, Kumar K S, Lakshmanaprabu S K, Maseleno A (2019) 5 Opinion mining analysis of e-commerce sites using fuzzy clustering with whale optimization techniques. In Expert Systems in Finance: Smart Financial Applications in Big Data Environments, 67. Routledge
Shen XL, Li YJ, Sun Y, Chen Z, Wang F (2019) Understanding the role of technology attractiveness in promoting social commerce engagement: moderating effect of personal interest. Inf Manag 56(2):294–305
Soleymani M, Garcia D, Jou B, Schuller B, Chang SF, Pantic M (2017) A survey of multimodal sentiment analysis. Image Vis Comput 65:3–14
Venkatraman S, Surendiran B, Kumar PAR (2020) Spam e-mail classification for the Internet of Things environment using semantic similarity approach. J Supercomput 76(2):756–776
Wang W, Feng Y, Chen S, Xu W, Zhuo X, Li HJ, Perc M (2022) Segregation dynamics driven by network leaders. N J Phys 24(5):053007
Wisniewski T P, Lambe B (2013) The role of media in the credit crunch: The case of the banking sector. J Econ Behav Organ 85:163–175
Xiao Y, Zhang N, Lou W, Hou YT (2020) A survey of distributed consensus protocols for blockchain networks. IEEE Commun Surv Tutor 22(2):1432–1465
Ye S, Wu SF (2010) Measuring message propagation and social influence on Twitter.com. In International conference on social informatics. Springer, Berlin, Heidelberg. pp 216–231
Zhang T, Moody M, Nelon JP, Boyer DM, Smith DH, Visser RD (2019) Using natural language processing to accelerate deep analysis of open-ended survey data. In 2019 Southeast Con, IEEE. pp 1–3
Zhu Z, Liang J, Li D, Yu H, Liu G (2019) Hot topic detection based on a refined TF-IDF algorithm. IEEE Access 7:26996–27007
Acknowledgements
The authors have done an individual study on this subject over the past 4 years. This research received no external funding.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies requiring ethical approval.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sigari, S., Gandomi, A.H. Analyzing the past, improving the future: a multiscale opinion tracking model for optimizing business performance. Humanit Soc Sci Commun 9, 341 (2022). https://doi.org/10.1057/s41599-022-01325-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-022-01325-y
This article is cited by
-
Optimizing Sentiment Analysis: A Cognitive Approach with Negation Handling via Mathematical Modelling
Cognitive Computation (2023)
