
Abstract
Human culture is the result of a unique cumulative evolutionary process. Despite the importance of culture for our species the social transmission mechanisms underlying this process are still not fully understood. In particular, the role of language—another unique human behaviour—in social transmission is under-explored. In this first direct, systematic comparison of demonstration vs. language-based social learning, we ran transmission chains of participants (6- to 8-year-old children and adults from Cyprus) who attempted to extract a reward from a puzzle box after either watching a model demonstrate an action sequence or after listening to verbal instructions describing the action sequence. The initial seeded sequences included causally relevant and irrelevant actions allowing us to measure transmission fidelity and the accumulation of beneficial modifications through the lens of a subtractive ratchet effect. Overall, we found that, compared to demonstration, verbal instruction specifically enhanced the faithful transmission of causally irrelevant actions (overimitation) in children, but not in adults. Cumulative cultural evolution requires the faithful transmission of sophisticated, complex behaviour whose function may not be obvious. This indicates that, by supporting the retention of actions that appear to lack a causal function specifically by children, language may play a supportive role in cumulative cultural evolution.
Similar content being viewed by others

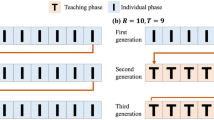
Introduction
Social transmission and cumulative cultural evolution
Human culture—our set of socially transmitted behaviours, skills, institutions, beliefs and values—is the unique product of cumulative cultural evolution (Boyd and Richerson, 1996). Legare and colleagues emphasise the ‘dual engines’ of cumulative transmission, namely imitation and innovation. The former—high fidelity copying—allows the faithful transmission of a vast array of cultural traits from generation to generation thereby eliminating the costs of individual learning by trial and error whereas the later—innovation—enables cultural adaptation to new environments through the generation of novel solutions (Legare and Nielsen, 2015; Legare and Harris, 2016). The capacity for cumulative change is believed to be underpinned by the ‘ratchet effect’ (Tomasello, 1999), a unidirectional mechanism that allows the faithful retention of beneficial modifications to a cultural trait to accumulate to yield products of such sophistication that no single individual or generation could accomplish on their own (Tomasello et al., 1993).
Recently, Tennie et al. (2014) expanded on earlier definitions of the ratchet effect to propose that the ratchet could operate additively or subtractively. In the case of an additive ratchet, improvements accumulate over generations, and cultural traits become increasingly complex, whilst in the case of a subtractive ratchet the loss of causally unnecessary (Flynn, 2008; McGuigan and Graham, 2010) or inefficient actions (Tennie et al., 2014) increases efficiency over generations. The additive ratchet effect requires faithful social transmission (Tomasello, 1994; 1999; Tennie et al., 2009), that can be supported by social learning strategies that include imitation, in which both the goal and the actions that are causally relevant to achieve it are copied (Tomasello, 1990; Whiten and Ham, 1992; Meltzoff, 2007; Tennie et al., 2009) and overimitation, in which actions that are not causally relevant to the goal are copied. In contrast, the subtractive ratchet effect does not necessarily require high fidelity copying. It may be indicative of imitation if both the goal and causally relevant actions are copied, however, the loss of causally irrelevant actions or increase in efficiency may be more indicative of emulation, a social transmission strategy in which the goal is copied, but the observed actions employed to achieve it are not. Thus, it would appear that, unlike imitation and overimitation, emulation may not support cumulative cultural evolution (Horner and Whiten, 2005).
The importance of cumulative cultural evolution for the success of the human species, coupled with the potential uniqueness of cumulative culture in the animal kingdom (see Whiten, 2021 for a review), has over the past few decades generated a plethora of studies that have explored both the phylogeny and ontogeny of different social learning mechanisms (most often imitation and emulation). Key to such explorations has been the implementation of tasks incorporating a two-action structure. Two-action tasks, initially known as artificial fruits, are often in the form of puzzle boxes, and are specifically designed to allow for the dissection of different social learning mechanisms by incorporating two different techniques to open the box (to extract a reward) using the same part of the apparatus (e.g., the model has viewed either pushing or pulling a bolt). Such studies have revealed that young children and adults are often very faithful imitators, more often copying the precise action technique used by the model to open the puzzle than our closest primate cousins who are more often emulative.
In their original conception, two-action tasks contained only actions that were causally relevant to achieving the task goal (e.g., extraction of a food reward). However, in 2005 Horner and Whiten, in addition to the standard casually relevant actions, incorporated actions into the demonstration that were causally irrelevant to reward retrieval. The somewhat surprising finding was that young human children, but not chimpanzees, copied the causally irrelevant actions with high levels of fidelity, a tendency that later became known as overimitation (Lyons et al., 2007). Subsequent studies have explored this overimitative tendency using a variety of tasks, age groups, and cultures (see Hoehl et al., 2019 for a recent review), with the vast majority revealing that overimitation is present in both adults and children across world cultures (Nielsen and Tomaselli, 2010; Nielsen et al., 2014; for an exception in Aka children, see also Berl and Hewlett, 2015; Clegg and Legare, 2016). Interestingly, although overimitation is evident across the lifespan studies have shown that the tendency to overimitate increases with age, with older children copying causally irrelevant actions more than younger children (McGuigan et al., 2007) and adults more than children (McGuigan et al., 2011; McGuigan, 2012). This suggests that overimitation may be a powerful driver of cumulative cultural evolution by allowing for the high-fidelity transmission of causally opaque actions, an opacity that is a key feature of many cultural traits.
Alongside the development of tasks that tease apart different social learning mechanisms has come the inception of experimental methods that can be used to explore cumulative cultural evolution in the laboratory. One such experimental paradigm that has been commonly used to study the cumulative effects of social learning is the transmission chain method. Transmission chains mimic the structure of the child’s game ‘Telephone’, where information initially generated by one individual is passed from one individual to another along a chain. In social learning studies, the actions produced by the individual at the beginning of the chain are typically seeded by the experimenter, with subsequent individuals first observing, and then modelling the actions for the next individual in the chain. The output at the end of the chain thus reflects the changes introduced and retained by multiple generations of one or more individuals. Studies employing the transmission chain method have revealed cumulative cultural evolution of actions in both children (Flynn, 2008; Flynn and Whiten, 2008; Horner et al., 2006; McGuigan and Graham, 2010; McGuigan, 2012) and adults (Tennie et al., 2014; Motamedi et al., 2019). Here we adopted this previously successful methodology to examine the role that demonstration and verbal instruction play in the cumulative cultural evolution of a sequence involving both causally relevant and causally irrelevant actions.
The importance of language and demonstration in social transmission
In the section above we outlined the importance of high fidelity copying for cumulative cultural evolution. Language is an important channel for social learning and cultural transmission (Tomasello et al., 1993; Legare, 2017; Laland, 2017) that has been somewhat neglected in previous studies. In the context of social learning, language has strong connections with teaching, normativity and intentionality. Specifically, language enhances and extends teaching, and may even have evolved as an adaptation to support efficient and economical teaching (Laland, 2017). Furthermore, imitation and teaching are often proposed to be the two main social learning mechanisms that enable cumulative cultural evolution (Boyd and Richerson, 1996; Tomasello, 1999; Tomasello et al., 1993). Verbal information, especially when it is about abstract, non-observable, opaque concepts, can be made more credible by confirmatory actions (Henrich, 2009). Conversely, verbal instructions often elicit normativity (Casler et al., 2009; Rakoczy et al., 2008), the belief that it is somehow obligatory to copy behaviour faithfully (Keupp et al., 2013). Previous studies have shown that children not only display normative behaviour after receiving verbal instructions but also after watching an adult model perform an action in a markedly intentional way (Schmidt et al., 2011). As language is an ostensive signal that indicates the intention to communicate (Grice, 1989), it also favours normativity indirectly, by signalling intentionality. Therefore language, by supporting teaching, normative beliefs and intentionality, can promote faithful cultural transmission, in particular of opaque cultural traits, and thus support cumulative cultural evolution.
Taken together the studies outlined above suggest that both language and demonstration have the potential to act as effective transmission mechanisms. However, we currently know very little as to whether, and in what circumstances, these mechanisms may be useful. Previous studies have shown that language plays a key role in the transmission of knowledge, beliefs, attitudes, and values (e.g., Levinson, 2003; Jarvis and Pavlenko, 2008; Rhodes et al., 2012). However, for the transmission of observed behaviour, modelling or demonstrating appears to achieve more faithful transmission than verbally conveyed information. In studies involving children, Harper and Sanders (1975) found that 14- to 18-month-old infants did not eat a novel food item after an adult pointed at it saying “something to eat”, but they did eat the novel food item if they saw the adult eat it first. Similarly, school-age children were more prone to displaying sharing and aggressive behaviour after an adult model demonstrated the actions than after the adult engaged in verbal preaching for (or against) them (Bryan and Walbek, 1970; Grusec and Skubiski, 1979; Bryan et al., 1971; Rushton, 1975).
A similar preference for modeled information has also been found with respect to adults, who were more likely to adopt novel public goods such as solar power when the community organizers, in addition to promoting them verbally, adopted them themselves (Kraft-Todd et al., 2018). Further studies involving adults have shown that demonstration also leads to more copying than verbal instruction in tasks involving the adoption of action techniques. In a dart-throwing task, participants were given either a demonstration or verbal instructions of one of several possible techniques. Those in the demonstration condition reproduced the technique given to them and performed it better than those in the verbal instruction condition (Al-Abood et al., 2001). Similarly, in a clinical trial, the demonstration was found to be more effective than written information (a leaflet) for promoting the adoption of a tooth-brushing technique among the general population (Schlueter et al., 2010).
Several recent studies have explored the role of language and action demonstration specifically within the context of cumulative cultural evolution. Dean et al. (2012) presented groups of 3- and 4-year-old children with a puzzle box in which increasingly desirable rewards could be obtained by solving sequential problems. Some of the children who had previously solved the task spontaneously provided verbal instructions for other children, and those learners who received instructions outperformed those who did not. Dean et al. (2012) therefore linked language (among other factors) to cumulative improvement on the task. However, the relative benefit of verbal instruction versus demonstration appears to be more variable in populations of adults. Caldwell and Millen (2009) asked chains of adult participants to construct paper aeroplanes that would fly as far as possible. The authors systematically manipulated the opportunities for participants to imitate (participants saw how the models made the aeroplanes, as well as the finished product), emulate (participants saw the finished aeroplanes, but did not witness how they were made), and receive teaching (which included gesture and a verbal component). The results showed that performance improved as the chains progressed to a similar extent in all conditions, suggesting that all information provided was equally as beneficial. Prior familiarity with the aeroplane construction task may however have confounded the results. In another transmission chain study, Zwirner and Thornton (2015) presented adult participants with some everyday materials to construct baskets that could carry as much rice as possible. The authors found that verbal teaching was not essential for cumulative improvement, although its presence resulted in more robust baskets than when participants only observed others’ actions (imitation) or only observed the finished product (emulation).
The relative importance of verbal instruction and demonstration has also been explored in a series of recent studies using experimental stone-tool manufacturing tasks. Putt et al. (2014) had participants learn how to make bifaces and found that adding verbal instructions to the demonstration of an action sequence increased copying fidelity—the reproduction of the instructor’s exact actions—but it made no significant difference in terms of skill—how well participants learned the target behaviour. In the demonstration-only group, individual actions were more efficient. In Ohnuma et al. (1997) study, participants’ production of Levallois stone tools did not differ between a demonstration-plus-verbal-instruction and a demonstration-only group. In contrast to those studies, in Morgan et al.’s (2015) comparison of five transmission mode conditions (involving demonstration, gestural communication and verbal communication) in a flint flake manufacture task, participants in the ‘verbal teaching’ condition performed significantly better than in most other conditions and slightly better than participants in the ‘gestural teaching’ condition.
In the studies of the cumulative cultural evolution of skills and action sequences reviewed above, the verbal and teaching conditions often involved face-to-face interaction, during which participants engaged in both verbal and gestural interaction (Dean et al., 2012; Caldwell and Millen, 2009; Zwirner and Thornton, 2015). Although Morgan et al. (2015) included distinct gestural and verbal teaching conditions, both provided verbal input in addition to observation. Therefore, the independent influence that verbal instruction and demonstration have on transmission fidelity has yet to be determined and is a gap that the current study aimed to address.
The current study
The aim of the current study was to directly compare for what is, to the best of our knowledge, the first time, how two transmission modes—verbal instruction and demonstration—affected transmission fidelity and the cumulative cultural evolution of an action sequence seeded with both causally relevant and causally irrelevant actions. Chains of participants were presented with a reward extraction task, allowing us to manipulate transmission mode (verbal instruction or demonstration), participant age (children or adults), and the causal relevance of actions in the demonstration (causally relevant or causally irrelevant). Of interest was both the fidelity of action transmission as well as the fate of the causally relevant and irrelevant actions along the chains. Specifically, it was predicted that:
-
1.
Transmission fidelity would be greater under demonstration than verbal instruction conditions.
-
2.
Higher levels of overimitation (i.e., greater reproduction of causally irrelevant actions) would be witnessed under the demonstration than verbal instruction conditions.
-
3.
A cumulative (subtractive) loss of irrelevant actions, but not of relevant actions, would occur over generations.
-
4.
A more pronounced loss of irrelevant actions would occur over generations of children than adults.
Methods
Ethical approval was obtained from Heriot-Watt University’s School of Social Sciences Ethics Committee and was pre-registered with the Open Science Foundation (https://osf.io/wdjqp/?view_only=20dcfb94b6fc45889ec7db3824f8de58). Informed consent was gathered from parents of all participating children and from participating adults before testing.
Participants
Seventy adults (31 females; age range 19–32 years, M = 22.94 years, SD = 3.11 years) were recruited and tested in public locations in Cyprus. Sixty of the adult participants were allocated to the social learning condition and subsequently divided into 20 chains (three participants per chain). The mean age of the participants in each chain was approximately equal, and the male–female ratio was similar across chains. The remaining 10 participants were allocated to the asocial learning condition. No compensation was given to the adults for participating in the study.
Seventy children (30 females; age range 6–8 years, M = 6.72 years, SD = 0.76 years) were recruited and tested in summer school and playgrounds in Cyprus. This sample size was equivalent to that used in previous and similar studies (Kumpfer et al., 2002; Patil et al., 2014; Neely et al., 2016; Rice and Grusec, 1975, Bryan et al., 1971). Sixty of the children were allocated to the social learning condition and subsequently divided into 20 chains (three participants per chain). The mean age and the gender ratio of the participants were similar across chains. The remaining 10 participants were allocated to the asocial learning condition. The children received stickers as compensation for their participation.
Two additional participants—one adult and one 9-year-old, both male native Greek Cypriot speakers—were recruited to act as the ‘seeds’ used to record the visual and auditory stimuli.
Materials
The apparatus presented to all participants was an adaptation of the opaque box used in previous studies with children and adults (McGuigan et al., 2007; McGuigan and Whiten, 2009; McGuigan and Graham, 2010). For the purposes of the current study, the bolts on the top of the original box were not used (see Fig. 1). The box contained a reward housed within a tube inside the box. The reward could only be extracted by opening a small door on the front of the box and interesting a rod inside. One end of the rod had a magnet attached (coloured red), and the other end of the rod had Velcro attached (coloured blue). The reward was a metal ball wrapped in Velcro, allowing it to be retrieved using either end of the rod. The reward could not be obtained using a finger.

The only way to access the reward is through the door at the front.
Design
Participants in the social learning condition were organised into linear transmission chains, each comprising three generations. Each participant represented one generation (see Fig. 2). We opted to include three generations as previous studies have shown that the majority of effects occur within the first few generations. We had a total of 40 chains: 20 comprised of child participants and 20 of adult participants. The input to each generation was the (video or audio) recorded output of the preceding generation. Generation 0 (the ‘seeded’ participant) provided the initial input for all the chains in the relevant transmission modality condition and age group. The participants in the asocial learning groups attempted the task individually.

All chains in the same transmission and participant age condition received input from the same Generation 0 or ‘seeded’ participant.
Procedure
Initial action sequences
The transmission chains were initiated with one of two sequences produced by the ‘seeded’ participant. Each sequence contained two causally relevant actions (Rel), which were necessary for retrieving the reward, and two causally irrelevant (Irrel) actions, that were not necessary for reward retrieval. Following the two-action approach (Dawson and Foss, 1965; Whiten et al., 2016; McGuigan et al., 2007, 2011; McGuigan and Graham, 2010) a different sequence of actions was the input for half of the chains in each condition, resulting in a total of four causally relevant actions and four causally irrelevant actions across the study (see Table 1). The four causally relevant actions were used in previous studies using the same apparatus (McGuigan et al., 2007, 2011; McGuigan and Graham, 2010), whereas the four causally irrelevant actions were designed specifically for this study. The irrelevant actions were within the capability of the age of the participants tested and took approximately the same amount of time to perform as the relevant actions.
Seeds
The adult and child seeds were trained by the experimenter to produce the initial action sequences (see Table 1). Their demonstrations (for the Demonstration condition) were video recorded, and the spoken descriptions of their actions (for the Verbal Instruction condition) were audio-recorded in separate sessions. We opted to use recorded information, in line with similar studies (McGuigan et al., 2007; Wood et al., 2012), for consistency of presentation.
Social learning conditions
Demonstration condition
Each participant was asked to take a seat at a table directly facing the laptop and the puzzle box. The experimenter told them: “Inside the box there is a ball. The goal is to take the ball out of the box. Before you try, I will show you a video of another participant who took the ball out. The video will play three times. Then, you can try, too”. The video-recorded actions performed by the previous participant in the chain (or, for generation 1, by the seed) were presented three times on the laptop with the volume muted. Following the task demonstrations, the experimenter invited the participant to “have a go”. Their actions were video recorded. Participants were allowed to interact with the box for a maximum of five minutes, or until they retrieved the reward successfully, if this was less than five minutes, or until they became frustrated or refused to continue. All participants were successful in retrieving the reward within the time allocated. While the participants were carrying out the task, the experimenter did not interfere.
Verbal instruction condition
Each participant was asked to take a seat at a table directly facing the laptop and the puzzle box before being told: “Inside the box, there is a ball. The goal is to take the ball out of the box. Before you try, I will play for you the [voice] recording of another participant who took the ball out. The recording will play three times. Then, you can try, too”. The audio-recorded verbal instructions from the previous participant in the chain (or, for generation 1, by the seed) were then played three times on a laptop (mp3 player). Then the experimenter invited the participant to have a go, and their actions were video recorded. After the participant finished, the experimenter gave the following instructions: “I will play for you a video of yourself on my laptop and I want you to watch carefully what you do. Every few seconds, I will pause it. Each time I pause the video, I would like you to tell me what you do in it” and asked if the participant had any questions. After making sure her instructions were clear, the experimenter played the video for the participant pausing after every action and the participant described the action to the microphone. All participants were able to describe their sequence action by action. The experimenter did not guide them as to in which format they should give their descriptions (some of them took a first-person perspective and others a second-person perspective). Their descriptions of their actions were audio-recorded, and they were used as the audio input for the next participant in the chain. Participants were allowed to interact with the box undisturbed until they retrieved the reward successfully, or after five minutes, as above. Also as above, all participants were successful and the experimenter did not interfere while they were carrying out the task.
Asocial learning condition
Participants in the asocial learning condition interacted with the box individually, without having previously viewed a model or having received any verbal instruction. The aim of this condition was to establish what actions the participants (both children and adults) would perform on the box spontaneously, allowing us to confirm that the irrelevant actions contained in the seeded demonstration (see Table 1) truly constituted overimitationFootnote 1. Participants in this condition were told: “There is a reward in this box. Can you take it out?”. All of the participants retrieved the reward and all were video recorded whilst interacting with the box.
In all conditions, after each participant finished the task, they were thanked and debriefed. In addition, they were asked, for some of the actions they performed, why they performed it the way they did: “Why did you do x?”.
Data coding and variables
The video recordings of participants were coded by the first author. Co-author MT coded random samples (10%) of the video data for reliability regarding the variables below. Cohen’s κ (Landis and Koch, 1977) revealed near-perfect inter-coder agreement, κ = 0.838 (p < 0.000), 95% CI (0.799, 0.877).
Asocial learning condition: Each action that the participants produced was coded as causally relevant if it contributed to extracting the reward or as causally irrelevant if it did not contribute.
Social learning conditions: For coding and analysis purposes, our units (rows in our database) were action types in a participant’s input and/or output. If an action type was present in a participant’s input or output, the type was included in the coding as a new row. Action tokens allocated to an action type included exact replicas, slight modifications and variations in the number of times an action is produced (e.g., swiping the rod on the hand 3 or 4 or more times were counted as the same action type).
For each action type witnessed and/or produced by a participant, we coded: Participant ID; Participant Age group; Chain; Generation; Action type; whether the action was present in the participant’s input or not; whether the action was produced by the participant or not; transmission mode condition (Demonstration or Verbal instruction); and causal relevance (whether the action contributed to extracting the reward or not). From this information, we extracted three outcome variables, action retention and action emulation (to capture fidelity) and improvements in efficiency (or loss of irrelevant actions).
-
(i)
Action retention: This binary variable reflects whether an action present in a participant’s input was also present in their output (retention = 1) or not (retention = 0). Actions that were produced by participants but were not present in their input were not considered for the analysis of this variable (they were counted as instances of emulation, see next paragraph). For the purposes of action retention, the variable Generation was not taken into account; rather, for each action in any participant’s input, we coded whether they retained it in their output or not.
-
(ii)
Action emulation: This variable counts the number of actions present in a participants’ output that were not present in their input. Generation was not taken into account with respect to emulation.
-
(iii)
Improvement in efficiency: This binary variable captures the specific loss of irrelevant variants over generations. We coded, for each action produced by participants at each generation (regardless of whether it had been retained from their input or emulated) whether it was relevant or irrelevant. By comparing over generations, we could see how many relevant and irrelevant actions were lost. Actions that were in participants’ input, but were not retained, were not included in the analysis of this variable. Irrelevant action loss improves efficiency because it decreases the number of actions required to extract the reward without detracting from goal success.
Analyses
To test differences between the asocial and social groups we ran chi-squared tests on the number of actions produced under each condition.
We also used chi-squared tests to check for effects of Transmission condition, action Relevance and participant Age on number of actions emulated.
Effects on action retention and improvement of efficiency were tested using estimate mixed effects logistic regression models with lme4 package (Bates et al., 2015) in R (R Core Team, 2012) (see SM.9 for R code). Given the presence of multiple manipulated variables and the relatively few specific predictions in this study, most of our analyses were exploratory and involved interactions between predictors. For that reason we present interactive models (see additive model for action Retention in SM.10).
For Retention, we modelled whether each action observed was retained as a Bernoulli variable. The probability of retention was a function of a baseline retention probability and effects of three binary predictors: transmission mode, participant age and action relevance, with additional random effects for each participant and each action. A logit link function was used to transform the linear predictor into a probability.
For Improvement in Efficiency, we modelled whether each action produced was relevant as a Bernoulli variable. The probability of being relevant was a function of a baseline relevance probability and effects of generation (G1, G2, or G3), transmission mode and participant age (the last two being binary predictors) with additional random effects for each participant and each chain. A logit link function was used to transform the linear predictor into a probability.
Results
Asocial vs. social learning
Participants produced significantly fewer actions in the asocial learning condition than in the experimental conditions (Table 2). Actions produced under asocial and social learning are in SM.1 and SM.2, respectively. Participants in the asocial condition produced very few irrelevant actions in the asocial condition (SM.2), indicating that these actions do not tend to emerge spontaneously.
Action retention
Table 3 shows the results of the interactive regression model (see SM.3 for numbers of actions observed, retained, lost and emulated by participants at each Generation and SM.4 for more details on the model).
We found significant effects of action Relevance (Fig. 3A) and participant age (Fig. 3B), as well as a significant interaction between Transmission condition and participant Age (Fig. 3C) on action Retention.

Panel A compares conditions of action Relevance and panel B, conditions of participant Age. Panel C illustrates the interaction between participant Age and Transmission.
We also found a significant 3-way interaction between Transmission mode, action Relevance and participant Age on action Retention. Figure 4 shows the estimated marginal means of action Retention for each condition combination and Table 4 shows the significant pairwise contrasts.

Transmission mode (distinguished by colour for additional clarity), participant Age and action Relevance are shown.
Analysis of action Retention did not support Prediction 1 (more transmission fidelity under Demonstration than Verbal instruction), as there was no main effect of Transmission condition, and none of the Demonstration-Verbal contrasts in matching conditions of participant Age and action Relevance were significant (see Table 4). Consequently, the more specific Prediction 2 (more Retention of Irrelevant actions under Demonstration than under Verbal instruction) was not supported either. A closer examination of the significant three-way interaction (see Fig. 4) revealed that Retention of actions was higher under Demonstration (blue in Fig. 4) than Verbal instruction (in red) in three out of four combinations of Age and Relevance. However, the pattern was reversed for Children’s over-imitation (retention of Irrelevant actions), which was higher under Verbal instruction than Demonstration.
Emulation
At each generation, 20%, 35%, and 19%, respectively, of action tokens produced by participants were emulated (not present in their input). A total of 89 action tokens (31 types) were produced by emulation. The most common types were the alternative methods to open the door or extract the reward (Fig. 5).

For each of the four causally relevant actions in participants’ input, arrows show the extent to which participants imitated, and therefore retained them in their output (arrow to itself) or emulated, and therefore performed the alternative action (see Table 1) for the same function (arrow to the other action). E.g., of the 40 participants who saw or heard action ‘slide the door open’ (action B), 21 retained it in their output and 19 emulated and ‘lifted the door open’ instead (Action A). See also SM.3 for the fate of all action types.
Chi-squared tests only revealed a significant effect of Transmission condition on Emulation (χ²(1) = 4.67, p < 0.05), with more Emulated actions in the Verbal Instruction (N = 57) than the Demonstration condition (N = 32) (more details in SM.6). This partially supported Prediction 1 (more transmission fidelity, interpreted here as less emulation, under Demonstration than Verbal instruction).
Improvement in efficiency
Table 5 shows the results of the regressions for improvement in efficiency, the specific decrease of irrelevant actions over generations (see SM.7 for full details).
We found a significant three-way interaction effect between Generation, Transmission mode and participant Age on action Relevance. The estimated marginal means shown in Fig. 6 represent differences in how Relevant and Irrelevant actions change over generations (see associated pairwise comparisons in SM.8).

All pairwise contrasts are in SM.8.
All values in Fig. 6 are positive because Irrelevant actions disappear faster than Relevant actions in all cases, supporting Prediction 3 (a cumulative loss of irrelevant, but not relevant, actions, over generations, illustrated in Fig. 7). While in the Demonstration condition there is no difference between Children and Adults, in the Verbal condition Adults lose significantly more irrelevant actions over generations than Children. In addition, Children lose significantly more actions over generations under Demonstration than under Verbal transmission. This means that our data show no support for Prediction 4 (a more pronounced loss of irrelevant actions over generations in children than adults) under Demonstration. In fact, we observed the opposite pattern in the Verbal condition.

The specific decrease of Irrelevant actions (Improvement in Efficiency) is shown.
Discussion
The main objective of the current study was to directly test for what is, to our knowledge, the first time, the effects of transmission modality on the cultural transmission of a sequence containing both causally relevant (related to imitation) and causally irrelevant components (related to overimitation). Specifically, using a transmission chain design we compared verbal transmission (without co-occurring gestures or other visual cues) with visual demonstration (the transmission modality used in most previous studies of social learning) in chains of 6- to 8-year-old children and adults. This design allowed us to quantify the extent to which participants reproduced the actions in their input, how many emulated actions they introduced, and the (subtractive) cumulative evolution of the action sequences over generations. The design also allowed us to analyse interactions, and therefore illuminate our understanding of the relationships between transmission modality, action relevance, and participant age.
The influence of demonstration versus verbal instruction
We first predicted that the participant’s output would show greater fidelity to the input provided by the previous generation under demonstration than verbal instruction conditions. This prediction was found to be only partially supported. The results show that there was no difference in the levels of action retention between the two transmission conditions. However there were more emulated actions (new actions in the output that were not present in the input) under verbal instruction than under demonstration conditions. The higher emulation rates under verbal instruction may be a consequence of language underspecification (e.g., Frisson, 2009). For an instrumental task such as extracting a reward from a box, verbal signals convey a less detailed, more ambiguous message than visual demonstration. Comprehension of verbal instructions is shaped by the listener’s prior knowledge and by the context. Suppose a participant hears ‘swipe the rod three times on the side of the box’. To carry out the instruction, they have to access their own meaning for swipe, rod, three, etc. While some verbal signals are unambiguous for most speakers (e.g., three times) others, such as swipe, can be interpreted in multiple ways (e.g., swipe upwards, from left to right, holding the rod with two fingers, etc.). In contrast, the demonstration provides a level of detail that significantly narrows down interpretation.
Alternatively, the higher number of emulated actions under verbal instruction could be due to the visual absence of the model in our audio recorded instructions (but see discussion of limitations below). This potential problem could be eliminated in future studies by presenting video input in both conditions; in one the model demonstrates and in the other narrates the action sequence.
The absence of a difference in action retention between the verbal and the demonstration conditions is at odds with studies showing that observable cultural traits such as prosocial and antisocial behaviour (Bryan et al., 1971), the adoption of novel social goods (Kraft-Todd et al., 2018), learning a new tooth-brushing technique (Schlueter et al., 2010) or eating a novel food item (Harper and Sanders, 1975) were more faithfully transmitted when they were demonstrated than when they were verbally praised or extolled. Past studies using technological tasks like ours suggest that adding verbal instruction to demonstration increased action reproduction fidelity (Putt et al., 2014). Our study focused on the independent contribution of verbal instruction to the faithful transmission of instrumental actions. We find that by itself, verbal instruction supports equal or less faithful transmission than demonstration alone.
The influence of transmission modality on overimitation
With respect to the specific retention of causally irrelevant actions we predicted that higher levels of overimitation would be witnessed under demonstration than verbal instruction conditions. However, this prediction was not supported by the results, with participants reproducing the causally irrelevant actions equally often under both transmission modalities. We did, however, find significant interactions between transmission condition, age, and action relevance, findings that are discussed more fully below.
Were causally irrelevant actions subtractively eliminated along chains?
As well as predicting that transmission modality would influence the reproduction of causally irrelevant actions, we also predicted that we would see a subtractive loss of irrelevant actions over generations. This prediction was upheld as the number of irrelevant actions reproduced decreased as the chains progressed, resulting in an overall increase in task efficiency. Although the levels of overimitation decreased across chains, in many of the chains causally irrelevant actions persisted into the later generations. That many of the irrelevant actions were retained contributes to the established body of evidence suggesting that the tendency to overimitate is powerful in humans. Importantly, the actions of the participants in the asocial learning condition included very few causal irrelevancies (see SM.1), indicating that they were much more likely to produce manifestly superfluous actions in the context of social learning than asocial learning.
Are adults more likely to retain irrelevant actions than children?
Our final prediction was that we would see a more pronounced loss of irrelevant actions in children than in adults. While there were no differences between children and adults in the demonstration condition, we found the opposite effect under verbal instruction. In this latter condition adults cumulatively lost more irrelevant actions than children over generations, or, conversely, children were more overimitative (retained more irrelevant actions) than adults. This somewhat surprising finding could be explained by the nature of irrelevant actions employed. The previous studies, from which the current task was adapted, and that prompted us to predict more overimitation in adults (McGuigan et al., 2011; McGuigan, 2012), included causally irrelevant actions that required manipulation of bolts that were positioned on the top of the box. These bolt manipulations, although causally irrelevant, may have been perceived as more instrumental in comparison to our irrelevant actions (swiping the rod on the hand or on the box, tapping the box three times), that may have been perceived as playful or as conventional social rituals, which are overimitated by children to a higher degree than irrelevant actions perceived as instrumental (Clegg and Legare, 2017; Nielsen et al., 2012). This suggests that the age effect witnessed could be due to children’s willingness and/or adults’ unwillingness to copy actions perceived as playful or ritual.
Exploring the interactions between transmission modality, age and action relevance
In our initial analysis we found, counter to predictions of greater fidelity following a task demonstration, that the fidelity of the participants’ output did not vary according to transmission modality. However, an exploratory inspection of the interaction effects revealed that fidelity was greater in the demonstration conditions than the verbal instruction conditions in both adults (with respect to both causally relevant and causally irrelevant actions), and children (causally relevant actions only). Interestingly, the exception was the reproduction of causally irrelevant actions by children, which was higher under verbal instruction than demonstration conditions. Thus, when presented with causally relevant actions, all participants irrespective of their age tended to imitate more faithfully when they saw the actions visually demonstrated than when the actions were verbally described. When presented with causally irrelevant actions, adults did the same, they copied more what they saw than what they were told about. However, children behaved in the opposite way—they copied more of the causally irrelevant actions they were told about than of those they saw (i.e., they overimitated more in the verbal instruction than the demonstration condition).
The interaction involving subtractive cumulative evolution offers an additional perspective on these age differences. Under demonstration conditions, adults and children behave similarly: both age groups lose some, but not all, causally irrelevant actions. Under verbal instruction, however, the age groups behave very differently. While adults cumulatively lose 87% of causally irrelevant actions by the end of generation 3, children cumulatively lose only 61%. It, therefore, appears that, under verbal instruction (but not under demonstration), children overimitate (retain causally irrelevant actions) much more frequently than adults. This analysis provides a more nuanced interpretation of the results for our unsupported second prediction (greater retention of irrelevant actions, or overimitation, under demonstration than verbal instruction conditions). For children only, we find the opposite, namely significantly more overimitation under verbal instruction than demonstration conditions.
The two interactions together suggest that, when it comes to imitation of causally relevant instrumental actions, participants of any age are more likely to ignore, forget or misunderstand (or perhaps be creative about) verbal information, relative to visually demonstrated information. The same is the case with causally irrelevant actions in adults. But, in stark contrast, when it comes to children, verbal transmission actually increases transmission fidelity. This might be due to qualitative differences between the verbal instructions produced by children and adults. Children’s utterances could be less complex or more straightforward than adults’, and they could facilitate the production of causally irrelevant actions. Or children’s language might be more goal-oriented, and therefore more suited to instructions about causally relevant actions. But if that were the case, we would not have the distinction between causally relevant and irrelevant actions; instead, we would expect children’s retention of actions to be higher in all verbal instruction conditions—for both relevant and irrelevant actions. Despite that, we checked whether the differences in children’s and adults’ speech affected their likelihood of retaining an action in the verbal instruction condition. We transcribed children’s and adults’ descriptions of the same sequences of actions and compared their narrative styles: which verbs and nouns they used and in what numbers, in which person the verbs were, the length of the descriptions and the number and length of their pauses. We did not find any substantial differences that might account for increased retention in children, suggesting that it was the mode of transmission that affected differential retention in children and adults.
The country in which the experiment took place could also have contributed to age related differences in overimitation. Cross-cultural differences can affect children’s overimitation (Berl and Hewlett, 2015; Clegg and Legare, 2016), and the primary education system in Cyprus, more teacher-centred than other western systems (Papanastasiou, 2002), could have biased our child participants to be more compliant with verbal instructions. In Cyprus, teachers traditionally provide instructions and teach children to follow them from a young age. Many of our adult participants were either current students or recent graduates of European universities, where they were most probably exposed to more student-centred educational systems. We cannot, however, from the results of our study, ascertain what accounts for the developmental decrease in overimitation under verbal instruction: Did Cypriot adults overimitate less or did Cypriot children overimitate more? Studies of language-mediated social transmission with children and adults from countries with different educational styles could shed more light on this question and, by extension, on the effects of the educational system on social learning and cultural evolution.
Another plausible explanation for the high levels of overimitation in children is connected to relationships between language, instrumental tasks, pedagogy and normativity. The insights above regarding differential transmission of instrumental and other types of action suggest that verbal transmission specifically enhances transmission fidelity for playful, conventional or ritualistic actions in children. Overimitation in children has been related to a psychological tendency to participate in rituals—conventional, normative causally opaque action sequences—which, in turn, facilitate social affiliation (Wen et al., 2016). Overimitation has also been related to normativity, which in turn may promote cooperation (Rakoczy et al., 2009). Children tend to assume that socially learned actions are normative to the extent that they denounce others who perform modified versions of the actions. They display normative behaviour after watching adult models perform an action in a markedly intentional way (Schmidt et al., 2011) and after receiving verbal, normative instructions (Casler et al., 2009; Rakoczy et al., 2008), which constitute teaching (Schmidt et al., 2010). Therefore, the reason why children overimitate more under verbal instruction may be because language suggests teaching, elicits normativity and maintains rituals.
Coevolution of language and social transmission fidelity?
If the above hypotheses were supported, it might speak to the question of language origins, suggesting that language coevolved with social transmission fidelity. Cumulative cultural evolution results in cultural traits that could not have been invented by a single individual, and these are passed on from generation to generation (Tomasello, 1990; Tennie et al., 2009). Such traits are often complex and opaque such that their causal relevance is not immediately obvious to the learner. By promoting overimitation, language increases the transmission fidelity of opaque behaviours in children. Tamariz (2019) argues that an essential mechanism of cumulative cultural evolution is the replication of actions, regardless of whether their function is understood or not, by naïve learners (see also Schleihauf and Hoehl, 2020). Regarding the naivety of participants, Putt et al. (2014) found more precise reproduction of stone-tool-making actions when verbal instruction was added to the demonstration. Their adult participants, like our children, were naïve to their task. Our adult participants were arguably less naïve to the reward-extraction task than the children. Additionally, children are more capable of magical thinking and entertaining supernatural beliefs (Woolley, 1997; Subbotsky, 2004), which could make them more naïve and less biased when faced with causally irrelevant actions. Adults, in contrast, will more readily see the causally irrelevant actions for what they are and, under a rational efficiency bias, will be less likely to copy them. Therefore, both in Putt et al. (2014) and our study, language increased transmission fidelity specifically by naïve participants. We propose that language, by enhancing normativity and signalling intentionality, selectively increases blanket copying (McGuigan et al., 2011) or action replication (Tamariz, 2019) by naïve learners, and thus it promotes not only overimitation, but also the reproduction of the precise structure, or style, of causally relevant actions. All of this supports cumulative cultural evolution which—we should add to close the circle—in turn increases human fitness (Mesoudi and Thornton, 2018).
Limitations
One possible limitation of the current study lies in a potential confound between transmission condition and sensory modality. In experimental tasks that present visual and auditory information simultaneously, children attend more readily to auditory stimuli, while adults show visual dominance (Robinson and Sloutsky, 2004), suggesting that adults are more visually oriented, and children are more auditorily oriented. The shift seems to occur around 9 years of age (Nava and Pavani, 2012). If sensory orientation was the only reason for differences between demonstration-visual and verbal-auditory conditions, we would not expect differences in retention and loss of specific types of actions. However, in our verbal condition, retention and loss by children was very different for causally relevant and irrelevant actions, which suggests sensory modality is not the main explanation of the results of this study. An additional potential limitation in our design is the age of the models, which is confounded with participant age: children are exposed to video and audio input produced by children, while adults are exposed to input produced by adults. Children copy relevant actions to the same extent when demonstrated by other children or by adults (Hanna and Meltzoff, 1993; McGuigan et al., 2007; Flynn and Whiten, 2008). Both children and adults copy more irrelevant actions demonstrated by an adult model than by a child model (McGuigan et al., 2011, Wood et al., 2012). This indicates that retention of irrelevant actions (overimitation) may be inflated in our adult participants. Correcting for this would return lower retention values for adult-irrelevant conditions, but this would not alter the implications of our results, including the specific reversed effect of transmission condition on overimitation in children. Finally, it could be argued that our Verbal Instruction condition was unrealistic, as verbal instruction of actions in the absence of concurrent demonstration is very infrequent. This would additionally suggest that our inferences regarding coevolutionary dynamics are unwarranted. The interaction we found between age, transmission modality and action causal relevance, however, points to a facilitatory role of language on the adoption of cultural traits. As suggested above, perhaps the role of language in the evolution of culture is more related to teaching and the transmission of norms to children, but it is also, perhaps incidentally, apparent for actions.
Future directions
The age differences in our results suggest that the normative function of language may change over the lifetime. Future language- and demonstration-mediated social transmission studies with participants of different ages, from early childhood through adolescence and adulthood to old age, would not only tell us when and how these changes happen, but also explore the contribution of individuals at different life stages to social transmission, which would in turn inform models of cultural evolutionary dynamics in populations with different age distributions.
Experiments have investigated the effects of verbal transmission on attitudes (e.g., Harper and Sanders, 1975; Bryan et al., 1971) and instrumental actions (e.g., Onhuma et al., 1997; Morgan et al., 2015). Cultural traditions, however, are hugely diverse, and transmission and innovation operate differently across cultural domains (Tamariz et al., 2016). We do not know whether our findings apply to other cultural traits. Extensions of the current study may help reveal how transmission fidelity in children and adults operates under verbal- and demonstration-based transmission for a variety of cultural traditions.
Conclusion
In conclusion, this study has shed light on how language shapes the operation of the dual engines of cultural evolution—copying and innovation (Legare and Nielsen, 2015). Under verbal instruction, children overimitate more than adults—the first experimental instance in which this is the case—suggesting developmental changes for language-mediated social transmission. Importantly, our exploratory analysis found that compared to demonstration, verbal instruction generally reduces transmission fidelity, except in the case of overimitation in children, which is facilitated by verbal transmission. The evolutionary consequences of increased overimitation in children at the population level and in the long term include higher retention of opaque actions over generations. This suggests that language, possibly as the mediator of teaching and normativity, plays a crucial role in supporting the type of high-fidelity social transmission that is required for cumulative cultural evolution.
Data availability
The datasets generated during and/or analysed during the current study are available in the Zenodo repository: https://zenodo.org/record/4444854#.YALWy0EYA2w, https://doi.org/10.5281/zenodo.4444854.
Notes
At the pre-registration stage, this study intended to include an additional independent variable, namely action familiarity. One half of the causally irrelevant actions at generation 0 were intended to be ‘familiar’ to the participants and the other half to be ‘unfamiliar’. However, we found that participants in the asocial learning condition spontaneously performed the ‘unfamiliar’ actions. This invalidated our criterion to distinguish familiar and unfamiliar actions and, as a consequence, the variable familiarity is not included in this report.
References
Al-Abood SA, Davids K, Bennett SJ (2001) Specificity of task constraints and effects of visual demonstrations and verbal instructions in directing learners’ search during skill acquisition. J Motor Behav 33:295–305
Bates D, Maechler M, Bolker B, Walker S (2015) Fitting linear mixed-effects models using lme4. J Stat Softw 67:1–48
Berl REW, Hewlett BS (2015) Cultural variation in the use of overimitation by the Aka and Ngandu of the Congo Basin. PLoS ONE 10(3):e0120180. https://doi.org/10.1371/journal.pone.0120180
Boyd R, Richerson P (1996) Why culture is common, but cultural evolution is rare. Proc Br Acad 88:77–94
Bryan JH, Walbek NH (1970) The impact of words and deeds concerning altruism upon children. Child Dev 41:747–757
Bryan JH, Redfield J, Mader S (1971) Words and deeds about altruism and the subsequent reinforcement power of the model. Proc Br Acad 42:1501–1508. https://doi.org/10.2307/1127914
Caldwell C, Millen A (2009) Social learning mechanisms and cumulative cultural evolution: is imitation necessary? Psychol Sci 20:1478–1483. https://doi.org/10.1111/j.1467-9280.2009.02469.x
Casler K, Terziyan T, Greene K (2009) Toddlers view artifact function normatively. Cognitive Dev 24:240–247. https://doi.org/10.1016/j.cogdev.2009.03.005
Clegg J, Legare C (2016) A cross-cultural comparison of children’s imitative flexibility. Dev Psychol 52:1435–1444. https://doi.org/10.1037/dev0000131
Clegg J, Legare C (2017) Parents scaffold flexible imitation during early childhood. J Exp Child Psychol 153:1–14. https://doi.org/10.1016/j.jecp.2016.08.004
Dawson B, Foss B (1965) Observational learning in budgerigars. Anim Behav 13:470–474. https://doi.org/10.1016/0003-3472(65)90108-9
Dean L, Kendal R, Schapiro S et al. (2012) Identification of the social and cognitive processes underlying human cumulative culture. Science 335:1114–1118. https://doi.org/10.1126/science.1213969
Flynn E (2008) Investigating children as cultural magnets: do young children transmit redundant information along diffusion chains? Philos Trans R SOC B 363:3541–3551. https://doi.org/10.1098/rstb.2008.0136
Flynn E, Whiten A (2008) Cultural transmission of tool use in young children: a diffusion chain study. Soc Dev 17:699–718. https://doi.org/10.1111/j.1467-9507.2007.00453.x
Frisson S (2009) Semantic underspecification in language processing. Lang Ling Compass 3:111–127. https://doi.org/10.1111/j.1749-818x.2008.00104.x
Grice HP (1989) Studies in the way of words. Harvard University Press, Cambridge
Grusec JE, Skubiski SL (1979) Model nurturance, demand characteristics of the modeling experiment and altruism. J Pers Soc Psychol 14:3S2–359
Hanna E, Meltzoff AN (1993) Peer imitation by toddlers in laboratory, home, and day-care contexts: implications for social learning and memory. Dev Psychol 29:701–710. https://doi.org/10.1037/0012-1649.29.4.701
Harper LV, Sanders KM (1975) The effect of adults’ eating on young children’s acceptance of unfamiliar foods. J Exp Child Psychol 20:206–214. https://doi.org/10.1016/0022-0965(75)90098-3
Henrich J (2009) The evolution of costly displays, cooperation and religion: credibility enhancing displays and their implications for cultural evolution. Evol Hum Behav 30:244–260. https://doi.org/10.1016/j.evolhumbehav.2009.03.005
Hoehl S, Keupp S, Schleihauf H et al. (2019) ‘Over-imitation’: a review and appraisal of a decade of research. Dev Rev 51:90–108. https://doi.org/10.1016/j.dr.2018.12.002
Horner V, Whiten A (2005) Causal knowledge and imitation/emulation switching in chimpanzees (Pan troglodytes) and children (Homo sapiens). Anim Cogn 8:164–181. https://doi.org/10.1007/s10071-004-0239-6
Horner V, Whiten A, Flynn E, de Waal FBM (2006) Faithful replication of foraging techniques along cultural transmission chains by chimpanzees and children. Proc Natl Acad Sci USA 103:13878–13883. https://doi.org/10.1073/pnas.0606015103
Jarvis S, Pavlenko A (2008) Crosslinguistic influence in language and cognition. Routledge
Keupp S, Behne T, Rakoczy H (2013) Why do children overimitate? Normativity is crucial. J Exp Child Psychol 116:392–406. https://doi.org/10.1016/j.jecp.2013.07.002
Kraft-Todd GT, Bollinger B, Gillingham K, Lamp S, Rand DG (2018) Credibility-enhancing displays promote the provision of non-normative public goods. Nature 563:245–248. https://doi.org/10.1038/s41586-018-0647-4
Kumpfer KL, Alvarado R, Tait C, Turner C (2002) Effectiveness of school-based family and children’s skills training for substance abuse prevention among 6-8-year-old rural children. Psychol Addict Behav 16:S65. https://doi.org/10.1037/0893-164X.16.4S.S65
Laland KN (2017) Darwin’s unfinished symphony. Princeton University Press, Princeton
Landis J, Koch G (1977) The measurement of observer agreement for categorical data. Biometrics 33:159–174. https://doi.org/10.2307/2529310
Legare CH (2017) Cumulative cultural learning: development and diversity. Proc Natl Acad Sci USA 114:7877–7883. https://doi.org/10.1073/pnas.1620743114
Legare C, Harris P (2016) The ontogeny of cultural learning. Child Dev 87:633–642. https://doi.org/10.1111/cdev.12542
Legare C, Nielsen M (2015) Imitation and innovation: the dual engines of cultural learning. Trends Cogn Sci 19:688–699. https://doi.org/10.1016/j.tics.2015.08.005
Levinson SC (2003) Space in language and cognition. Cambridge University Press
Lyons D, Young A, Keil F (2007) The hidden structure of overimitation. Proc Natl Acad Sci USA 104:19751–19756. https://doi.org/10.1073/pnas.0704452104
McGuigan N (2012) The role of transmission biases in the cultural diffusion of irrelevant actions. J Comp Psychol 126:150–160. https://doi.org/10.1037/a0025525
McGuigan N, Whiten A, Flynn E, Horner V (2007) Imitation of causally opaque versus causally transparent tool use by 3- and 5-year-old children. Cogn Dev 22:353–364. https://doi.org/10.1016/j.cogdev.2007.01.001
McGuigan N, Graham M (2010) Cultural transmission of irrelevant tool actions in diffusion chains of 3- and 5-year-old children. Eur J Dev Psychol 7:561–577. https://doi.org/10.1080/17405620902858125
McGuigan N, Whiten A (2009) Emulation and “overemulation” in the social learning of causally opaque versus causally transparent tool use by 23- and 30-month-olds. J Exp Child Psychol 104:367–381. https://doi.org/10.1016/j.jecp.2009.07.001
McGuigan N, Makinson J, Whiten A (2011) From over-imitation to super-copying: Adults imitate causally irrelevant aspects of tool use with higher fidelity than young children. Br J Psychol 102:1–18. https://doi.org/10.1348/000712610x493115
Meltzoff AN (2007) Infants’ causal learning: Intervention, observation, imitation. In: Gopnik A, Schulz L (ed) Causal learning: psychology, philosophy, and computation. Oxford University Press, Oxford
Mesoudi A, Thornton A (2018) What is cumulative cultural evolution? Proc R Soc B 285:20180712. https://doi.org/10.1098/rspb.2018.0712
Morgan T, Uomini N, Rendell L et al. (2015) Experimental evidence for the co-evolution of hominin tool-making teaching and language. Nat Commun 6:1–8. https://doi.org/10.1038/ncomms7029
Motamedi Y, Schouwstra M, Culbertson J, Smith K, Kirby S (2019) Evolving artificial sign languages in the lab: from improvised gesture to systematic sign. Cognition 192:103964. https://doi.org/10.1016/j.cognition.2019.05.001
Nava E, Pavani F (2012) Changes in sensory dominance during childhood: converging evidence from the colavita effect and the sound-induced flash illusion. Child Dev 84:604–616. https://doi.org/10.1111/j.1467-8624.2012.01856.x
Neely RJ, Green JL, Sciberras E et al. (2016) Relationship between executive functioning and symptoms of attention-deficit/hyperactivity disorder and autism spectrum disorder in 6–8 year old children. J Autism Dev Disord 46:3270–3280. https://doi.org/10.1007/s10803-016-2874-6
Nielsen M, Tomaselli K (2010) Overimitation in Kalahari Bushman children and the origins of human cultural cognition. Psychol Sci 21:729–736. https://doi.org/10.1177/0956797610368808
Nielsen M, Cucchiaro J, Mohamedally J (2012) When the transmission of culture is child’s play. PLoS ONE 7:e34066. https://doi.org/10.1371/journal.pone.0034066
Nielsen M, Mushin I, Tomaselli K, Whiten A (2014) Where culture takes hold: “overimitation” and its flexible deployment in western, aboriginal, and bushmen children. Child Dev 85:21269–2184. https://doi.org/10.1111/cdev.12265
Ohnuma K, Aoki K, Akazawa A (1997) Transmission of tool-making through verbal and non-verbal communication: preliminary experiments in levallois flake production. Anthropol Sci 105:159–168. https://doi.org/10.1537/ase.105.159
Papanastasiou C (2002) TIMSS study in Cyprus: patterns of achievements in mathematics and science. Stud Educ Eval 28:223–233. https://doi.org/10.1016/s0191-491x(02)80004-9
Patil SP, Patil PB, Kashetty MV (2014) Effectiveness of different tooth brushing techniques on the removal of dental plaque in 6–8 year old children of Gulbarga. J Int Soc Prevent Communit Dent 4:113. https://doi.org/10.4103/2231-0762.138305
Putt S, Woods A, Franciscus R (2014) The role of verbal interaction during experimental bifacial stone tool manufacture. Lithic Technol 39:96–112. https://doi.org/10.1179/0197726114z.00000000036
Rakoczy H, Warneken F, Tomasello M (2008) The sources of normativity: young children’s awareness of the normative structure of games. Dev Psychol 44:875–881. https://doi.org/10.1037/0012-1649.44.3.875
Rakoczy H, Warneken F, Tomasello M (2009) Young children’s selective learning of rule games from reliable and unreliable models. Cogn Dev 24:61–69. https://doi.org/10.1016/j.cogdev.2008.07.004
R Core Team (2012) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria
Rice ME, Grusec JE (1975) Saying and doing: effects on observer performance. J Pers Soc Psychol 32:584–593. https://doi.org/10.1037/0022-3514.32.4.584
Rhodes M, Leslie S-J, Tworek CM (2012) Cultural transmission of social essentialism. Proc Natl Acad Sci USA 109:13526–13531. https://doi.org/10.1073/pnas.1208951109
Robinson CW, Sloutsky VM (2004) Auditory dominance and its change in the course of development. Child Dev 75:1387–1401. https://doi.org/10.1111/j.1467-8624.2004.00747.x
Rushton JP (1975) Generosity in children: Immediate and long-term effects of modeling, preaching, and moral judgement. J J Pers Soc Psychol 31:459–466
Schleihauf H, Hoehl S (2020) A dual-process perspective on over-imitation. Dev Rev 55:00896. https://doi.org/10.1016/j.dr.2020.100896
Schlueter N, Klimek J, Saleschke G, Ganss C (2010) Adoption of a toothbrushing technique: a controlled, randomised clinical trial. Clin Oral Investig 14:99–106
Schmidt MFH, Rakoczy H, Tomasello M (2011) Young children attribute normativity to novel actions without pedagogy or normative language. Dev Sci 14(3):530–539. https://doi.org/10.1111/j.1467-7687.2010.01000.x
Subbotsky E (2004) Magical thinking in judgments of causation: Can anomalous phenomena affect ontological causal beliefs in children and adults? Br J Dev Psychol 22:123–152. https://doi.org/10.1348/026151004772901140
Tamariz M (2019) Replication and emergence in cultural transmission. Phys Life Rev 30:47–71. https://doi.org/10.1016/j.plrev.2019.04.004
Tamariz M, Kirby S, Carr J (2016) Cultural evolution across domains: language, technology and art. In: Papafragou A, Grodner D, Mirman D, Trueswell JC (ed), Proceedings of the 38th annual conference of the cognitive science society. pp. 2759–2764
Tennie C, Call J, Tomasello M (2009) Ratcheting up the ratchet: on the evolution of cumulative culture. Philos Trans R Soc B 364:2405–2415. https://doi.org/10.1098/rstb.2009.0052
Tennie C, Walter V, Gampe A et al. (2014) Limitations to the cultural ratchet effect in young children. J Exp Child Psychol 126:152–160. https://doi.org/10.1016/j.jecp.2014.04.006
Tomasello M (1990) Cultural transmission in the tool use and communicatory signaling of chimpanzees? In: Parker S, Gibson K (ed) “Language” and intelligence in monkeys and apes. Cambridge University Press, Cambridge
Tomasello M (1994) The question of chimpanzee culture. In: Wrangham R, McGrew W, de Waal F, Heltne P (ed) Chimpanzee cultures. Harvard University Press, Cambridge, pp. 301–317
Tomasello M (1999) The cultural origins of human cognition. Harvard University Press, Cambridge
Tomasello M, Kruger A, Ratner H (1993) Cultural learning. Behav Brain Sci 16:495–511. https://doi.org/10.1017/s0140525x0003123x
Wen N, Herrmann P, Legare C (2016) Ritual increases children’s affiliation with in-group members. Evol Hum Behav 37:54–60. https://doi.org/10.1016/j.evolhumbehav.2015.08.002
Whiten A (2021) The burgeoning reach of animal culture. Science 372:eabe6514. https://doi.org/10.1126/science.abe6514
Whiten A, Ham R (1992) On the nature and evolution of imitation in the animal kingdom: reappraisal of a century of research. In: Slater PJB, Rosenblatt JS, Beer C, Milinski M (ed) Advances in the study of behavior. Academic Press, New York, pp, 239–283
Whiten A, Allan G, Devlin S et al. (2016) Social learning in the real-world: ‘over-imitation’ occurs in both children and adults unaware of participation in an experiment and independently of social interaction. PLOS ONE 11:e0159920. https://doi.org/10.1371/journal.pone.0159920
Wood L, Kendal R, Flynn E (2012) Context-dependent model-based biases in cultural transmission: children’s imitation is affected by model age over model knowledge state. Evol Hum Behav 33:387–394. https://doi.org/10.1016/j.evolhumbehav.2011.11.010
Woolley J (1997) Thinking about fantasy: are children fundamentally different thinkers and believers from adults? Child Dev 68:991–1011. https://doi.org/10.2307/1132282
Zwirner E, Thornton A (2015) Cognitive requirements of cumulative culture: teaching is useful but not essential. Sci Rep 5:1–8. https://doi.org/10.1038/srep16781
Acknowledgements
A.P. was supported by a PhD fellowship granted by the School of Social Sciences of Heriot-Watt University. We are grateful to Carmen Saldaña and Sean Roberts for their comments on our statistical analyses.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Papa, A., Cristea, M., McGuigan, N. et al. Effects of verbal instruction vs. modelling on imitation and overimitation. Humanit Soc Sci Commun 8, 239 (2021). https://doi.org/10.1057/s41599-021-00925-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-021-00925-4
