
Abstract
Weather characteristics have been suggested by many social scientists to influence criminality. According to a recent study, climate change may cause a substantial increase in criminal activities during the twenty-first century. The additional number of crimes due to climate have been estimated by associational models, which are not optimal to quantify causal impacts of weather conditions on criminality. Using the Rubin Causal Model and crime data reported daily between 2012 and 2017, this study examines whether changes in heat index, a proxy for apparent temperature, and rainfall occurrence, influence the number of violent crimes in Boston. On average, more crimes are reported on temperate days compared to extremely cold days, and on dry days compared to rainy days. However, no significant differences in the number of crimes between extremely hot days versus less warm days could be observed. The results suggest that weather forecasts could be integrated into crime prevention programs in Boston. The weather-crime relationship should be taken into account when assessing the economic, sociological, or medical impact of climate change. Researchers and policy makers interested in the effects of environmental exposures or policy interventions on crime should consider a causal inference approach to analyze their data.
Similar content being viewed by others


Introduction
For approximately four decades, criminologists have been interested in the weather–crime relationship (Bell and Baron, 1975; Cohen and Felson, 1979; DeFronzo, 1984; Harries et al., 1984; Anderson et al., 1995; Cohn and Rotton, 1997; Mares, 2013a). Two main theories have been suggested to explain the association between heat and human behavior. First, the routine activities theory argues that pleasant weather increases outdoor activity, thus exposing more people to offenders and leaving homes unprotected until extreme heat induces people to seek shelter indoors (Cohen and Felson, 1979). Consequently, Cohn and Rotton (1997; 2000a) expect the relationship between temperature and offenders’ social contacts to be an inverted-U shaped function. In contrast, the heat-aggression theory argues that changes in temperature affect crimes by increasing irritability and anger. To test the second argument and examine the shape of the dose–response, Bell and Baron (1975; 1976) conducted human experiments and observed that, by exposing research subjects to artificially uncomfortable conditions, aggression increases along with temperature until temperature crosses the threshold from warm to unbearable, after which subjects display lower levels of aggression. Other authors argued for a positive linear relationship between temperature and aggressive behavior (Anderson et al., 1995; Bushman et al., 2005). Several empirical analyses with different study designs and different data aggregation levels (e.g., hourly, daily, weekly, annual data) provided evidence for the existence of a weather-crime relationship. We present a summary of studies that investigated the effect of heat on crimes with results supporting either of the theories in Table 1. In addition to the impact of temperature, criminologists have been interested in the impact of rainfall. A positive relationship between rain and robbery was reported (DeFronzo, 1984), although other studies did not find evidence for a relationship between precipitation and the frequency of homicide or rape (Feldman and Jarmon, 1979; Perry and Simpson, 1978; DeFronzo, 1984). According to the routine activities theorists, rainfall could either prevent property and violent crimes, or increase assaultive behavior, by increasing the likelihood of people staying inside. From a heat-aggression point of view, a cooling-effect could occur from temperatures being reduced by precipitation (Baron and Bell, 1976). Criminologists have also extensively inspected the relationship between neighborhood conditions and crimes, they generally agree on the existence of a geographic component in levels of violence and criminal behavior (Sampson, 1997). The geographic differences in the weather–crime relationship are well explained by Harries et al. (1984), and more recently by Mares (2013b), who suggest higher violence rates in disadvantaged neighborhoods when climatic conditions are warmer.
Weather conditions leading to criminal activities can affect the mental and physical health of the offender and the victim. For this reason, violent crimes are considered an important public health issue. Preventing crimes may involve not only the police and the criminal justice system, but also environmental scientists, epidemiologists, and criminologists. Over the past two decades, an increasing number of studies have associated climate with human conflicts, criminal behavior, and violence (Rotton and Cohn, 2003; Agnew, 2011; Gamble and Hess, 2012; Hsiang et al., 2013; Mares, 2013a; Ranson, 2014; Mares and Moffett, 2016; Levy et al., 2017; Tiihonen et al., 2018). Recently, Ranson (2014) predicted that 22,000 murders, 1.2 million aggravated assaults, and 2.3 million simple assaults will occur in the United States by the end of the twenty-first century, because of climate change and the resulting change in temperature and rainfall patterns. The precise estimation of the magnitude of weather effects (e.g., temperature anomalies) on violence is important for criminologists and researchers in fields related to climate change and public health (Satcher, 1995). Most studies estimate the relationship between weather variables and crimes with associational models (e.g., linear, multilevel, and time series regressions). Controlling or adjusting for confounding variables, by including them in a regression model is not optimal for addressing causality in observational studies, especially when the covariate distributions of the exposed and control groups are substantially far apart (Rubin, 2008). If the covariate distributions do not overlap in the exposed and control groups, researchers are often implicitly making strong assumptions (e.g., inappropriate linear extrapolations) that can lead to biases. Cochran and Rubin (1973); Heckman et al. (1998); and Rubin (2001) have shown that regression can estimate biased causal effects when the true relationship between the background covariates or the outcome is unknown, as well as when the means and variances of the background covariates are considerably different for the exposed and control groups.
In this manuscript, we depart from associational modeling to provide estimates of the weather–crime relationship, and use an alternative estimation and inference method that relies on the Rubin Causal Model (RCM) (Rubin, 1974). Following a multi-stage strategy, we carefully reconstruct the observational weather–crime data in such a way that mimics randomized experiments, in which we can then quantify daily effects of weather on crime (Bind and Rubin, 2017). We use the RCM coupled with a matched-sampling strategy that enables us to compare exposed and control days as if they had been randomized (Rosenbaum and Rubin, 1983). Designing the observational data carefully and independently of the outcome is required before performing the statistical analysis using the outcome. The objective is to compare apples to apples, thereby we mean, we construct groups of exposed and control days that resemble each other with respect to background covariates while blinding ourselves from the outcome of interest (i.e., daily crime rates). We focus on the weather–crime relationship in Boston because of its wide spectrum of weather conditions. In Boston, average Summer temperatures can rise up to 28 °C and it has been suggested that the number of days below 0 °C will decrease to 34 days per year by the end of the century (Research Advisory Group (BRAG), 2016). In this paper, we estimate the effects of heat index and precipitation on daily violent crime counts and provide the reader with easily interpretable interval estimates obtained with transparent assumptions. Our approach concentrates on the estimation of meteorological influences on crimes at a finite population level (i.e., the Boston area). Our goal is not to extrapolate our local findings to a more generalizable dose–response curve. However, we discuss and compare the plausibility and the effect size of our results for Boston with the weather–crime relationship in Los Angeles, a city with a smaller weather condition spectrum.
Crime data analysis with the Rubin Causal Model
Data description and analysis strategy
Weather conditions from the Boston Logan airport monitoring station were obtained from the Climate Data Online provided by the National Oceanic and Atmospheric Administration (NOAA2018). The heat index (HI) is calculated from air temperature and dew point temperature, using the U.S. National Weather Service’s formula suggested by Anderson et al. (2013). We explore the heat–crime relationship in Boston by estimating the effect of changes in heat index, and not temperature alone to incorporate not only ambient temperature, but also ambient humidity. Both the routine activities and the heat-aggression perspectives rely on how humans feel and react to heat variations. Apparent temperature was developed to measure thermal comfort (Steadman, 1994). Because the heat index is used as a proxy for apparent temperature, we believe it provides a better quantification of human discomfort.
In this study, the crime data come from crime incident reports (between July 2012 and February 2017) collected by the Boston Police Department and made available on the City of Boston Data Portal (2018). Details on the location and time of day are given for all reported crimes. In the Fall and the Summer, the daily count of violent crimes and average HI are higher than during the Winter and the Spring on average (see Table S1). It might feel counterintuitive for Fall to have higher temperatures than Spring but it is worthwhile to note that Boston is located in New England, a region that is known for its Indian Summer. Figure S1 shows that the daily violent crime counts are the highest during the Summer months (i.e., June, July, August) on average. The approach we undertake to investigate the heat–crime relationship uses binary exposures (e.g., daily cold vs. temperate HI). Therefore, we decided to classify the days by heat index class: [−18; 0 °C], (0; 24 °C], (24; 35 °C], the Negative, Mild, and High heat index class, respectively (see Fig. S2(a)). For the the estimation of the effect of precipitation vs. no precipitation no data segmentation is necessary (see Fig. S2(b)).
Our strategy is to primarily focus on daily counts of violent crimes (i.e., aggravated assaults, simple assaults, crimes involving weapons, homicides, kidnapings, manslaughters, murders, escapes, runaways, truancies, and vandalism). Secondarily, we explore aggravated assault and larceny counts in order to analyze both a violent and a property offense in the study. In addition, we use the crime locations to discuss the potential neighborhood differences in the weather–crime relationship. Our choice of background covariates is based on the literature suggesting that the weather–crime relationship can be confounded by meteorological conditions, seasons, public holidays, large events, day of the month (crime reporting can be systematically biased on the first, middle, and last day of the month), and day of the week.
Potential outcomes and notation
The data segmentation described above leads to three hypothetical randomized experiments that help to understand the effects of daily changes in heat index: we reconstruct one experiment for each heat index class. A fourth hypothetical experiment is reconstructed for the analysis of the effect of rainfall where each day will either be assigned to precipitation or no precipitation. As illustrated in Fig. S2 and Table S2, we define Zi as the heat index and Ti as the threshold of day i, i = 1, …, N. The exposure indicator Wi is equal to 1 if Zi > Ti (i is exposed), and 0 otherwise (i is control). For the first three experiments, we choose the average heat index as the threshold. For the last experiment on rain occurrence, the threshold is by definition set at 0 mm. In all four hypothetical experiments we assume that each day i is randomly assigned to the exposed group (Wi = 1) or the control group (Wi = 0) with probability 1/2.
The hypothetical randomized experiments we reconstruct are completely-randomized experiments (see Table S3). We need to assure that the Stable Unit Treatment Value Assumption (SUTVA) holds in order to frame our analysis within the Rubin Causal Model (RCM) (Rubin, 1974). Therefore, we assume that the crime count of a certain day occurring after some exposure level is independent of the exposure received on other days. Following the RCM, each day has two potential outcomes: Yi(1), the number of crimes that occurred in day i if Wi = 1 and Yi(0) otherwise. The observed number of crimes that occurred in i is denoted by \(Y_i^{{\mathrm{obs}}}\) and it is equal to Yi(0) when Wi = 0, or equal to Yi(1) when Wi = 1. The days where \(Y_i^{{\mathrm{obs}}} = Y_i(0)\) is observed are referred to as control days and the ones where \(Y_i^{{\mathrm{obs}}} = Y_i(1)\) are referred to as exposed days.
In each hypothetical experiment we assess the effect of the exposure on crimes. The unit-level exposure effect (UEE) is defined as the difference between both potential outcomes of i:
In this study, we are interested in the mean difference in daily crime counts between the exposed days and the control days. Our estimand of interest is the average exposure effect (AEE):
Within each experiment, we estimate the AEE of different exposure levels, which can be interpreted as the average number of daily violent crimes resulting from a high exposure level (e.g., temperate heat index) compared to a lower exposure level (e.g., cold heat index).
Design stages
In observational studies, meteorological exposures cannot be randomly assigned. In such situations, to address causality, Rubin (2008) suggests to undertake a design stage that attempts to reconstruct a hypothetical experiment without using the observed outcome. This strategy avoids p-value hacking and multiple testing, thereby limiting false discovery biases in the subsequent statistical analyses. The goal is to fulfill the ideal conditions of a randomized experiment, implying that the treatment assignment is unconfounded given background covariates. Unconfoundedness of the treatment assignment can often be approximately achieved using matched-sampling strategies (Rubin, 2006).
Four design stages are performed in this study, one for each hypothetical experiment, and we use a one-to-one matching strategy with caliper on the estimated propensity score to create groups of exposed and control days with similar distributions for background covariates. The aim of this strategy is to improve balance in covariate distributions, in other words, the covariate distributions of the exposed and control days are similar on average (Rosenbaum and Rubin, 1983), therefore making sure we compare apples to apples. The background covariates included in the four hypothetical experiments are the binary variables: Fall, Winter, Spring, Summer, Friday, Weekend, FirstDayMonth (i.e., first day of the month), MidDayMonth (i.e., fifteenthth day of the month), LastDayMonth (i.e., last day of the month), Snow, HolidaysFootnote 1, and EventsFootnote 2 as well as the continuous variable Wind (i.e., windspeed). In the first three experiments concentrating on the effects of different levels of heat indexes, Rain (i.e., rainfall occurrence) is an additional binary background covariate. In the last experiment, concentrating on the effect of rainfall, HeatIndex plays the role of a background covariate. The steps to follow through each design stage to reach covariate balance are: (1) to estimate the propensity score for each day i, (2) to assess the overlap in propensity score distributions, and (3) to proceed with the actual one-to-one propensity score matching. These steps can be repeated multiple times until a satisfying balance is obtained.
First, let Xi be the vector of background covariates for day i, the propensity score is defined as the probability of being an exposed day given the background covariates, ei = ei(Xi) = P(Wi = 1 | Xi). We estimate the propensity score of each day i via a logistic regression that regresses the log odds of an exposed day on the background covariates:
At every design stage, different specifications are possible for the model in Eq. (3) and we attempt to find an appropriate functional form for f(Xi, β) by comparing models with stepwise model selection by Akaike Information Criteria. The following propensity score models were selected for each hypothetical experiment:
Summer days were not present in the Negative heat index days experiment, as well as Winter days and Events in the High heat index experiment.
Second, once a propensity score is calculated for each day i, the overlap in propensity score distributions for the control and exposed days is assessed. Control days with estimated propensity score outside the range of estimated propensity scores of the exposed days are discarded, and vice versa. Let us call these days: outlying days. The idea is to have the same range of data across exposure groups to avoid extrapolating beyond the support of the data during the analysis. Table S6 presents the overlap in propensity score distribution before and after deleting the outlying days for each experiment.
Last, we proceed with the one-to-one matching strategy with caliper. To assess whether the matching is successful and that the hypothesized experiment is plausible, we examine the balance in background covariate distribution for each exposure group. Diagnostic plots, such as Love plots (Ahmed et al., 2006), of the Fig. S3(a–d) show the difference in standardized means for the background covariates before and after matching. There is no evidence against covariate imabalance when the difference is close to zero, and more likely when the distributions overlap. Figures S4–7 present a precise comparison of the empirical distribution of the background covariates before and after matching. These figures show how, in each experiment, matching enables the exposed and control background covariate distributions to become closer. Insuring covariate balance is crucial for valid estimation of the causal effects of exposures and their confidence intervals.
Analytic methods
After a design stage is conducted for the four hypothetical experiments, we analyze each sample with balanced distributions of covariates for each experiment. We are interested in several crime outcomes: daily violent crime counts, as well as aggravated assault, and larceny counts. In this study, we conduct a Bayesian analysis within the four matched-samples resulting from our design stages. We assume independent Negative-Binomial distributions for the potential outcomes of crime counts.
The Bayesian analysis estimates posterior distributions of the AEE in the finite population. This analysis method was initially proposed by Rubin (1978) and is also described by Imbens and Rubin (2015). The Bayesian inference approach is appealing in our setting because it imputes the missing potential outcomes via simulation-based computational methods instead of estimating the slope coefficient of a regression model using the observed outcomes. For each experiment, we start with specifying a negative-binomial (NB) distribution for the potential outcomes conditional on background covariates. The independence assumption avoids contaminating the imputations of exposed days’ potential outcomes by imputed values of the control days, and vice versa. As we do not have prior knowledge on the values of the parameters, we impose the weakly informative priors suggested in the rstanarm R package on the parameters (Gabry and Goodrich). We assume a half-cauchy distributed prior for the scale parameter and normally (N) distributed priors for the intercept and slope parameters of the linear predictor. The selection of background covariates was done using leave-one-out cross-validation, the loo method for rstanarm. For the four hypothetical experiments of the primary results, the missing potential outcomes follow negative-binomial distributions parametrized with ηi = log(μi) and a dispersion parameter ϕ We use the following Bayesian models for the imputation:
The distributions of the parameters ϕ, β0 and β1,..,5 are estimated twice: once for the control potential outcomes and once for the exposed potential outcomes. We estimated these distributions with 20,000 iterations and we burned 10,000, so we have 10,000 values for each parameter. After that, we can impute the missing potential outcomes among the control and exposed groups separately. For each replication (10,000), one value of \(Y_i^{{\mathrm{miss}}}\) are drawn for each day i, conditional on \(Y_i^{obs}\), the observed covariates, and the parameters. For every replication, the AEE is calculated, which gives us a distribution of the AEE and a 95% posterior interval. See Supplementary Material Section F for the models of the exploratory results.
Results
Design stages enable us to reconstruct four hypothetical randomized experiments before comparing the daily violent crime counts that occurred on days with different binary meteorological exposures (see Fig. 1). For each hypothetical experiment, we estimate the average exposure effect (AEE) on the total number of violent crimes and their corresponding 95% posterior interval (see Fig. 2 and Table S4). The more specific crimes presented in the exploratory analysis are aggravated assault and larceny (see Table S5). The spatial variation of the average daily violent crimes across zip-code areas is illustrated in the spatial description.

Daily violent crime count distributions for days with different exposure levels across the four hypothetical experiments, after propensity score matching. a Extremely cold (HI ≤ −4 °C), very cold (−4 < HI < 0 °C), cold (0 < HI ≤ 12 °C), temperate (12 < HI < 24 °C), very hot (24 < HI ≤ 27 °C), and extremely hot (27 °C < HI) days. b Dry (PRCP < 0 mm) and rainy (PRCP ≥ 0 mm) days

Primary results: Estimates of the average exposure effect of different exposure levels on daily violent crimes across the four hypothetical experiments after multiply imputing the missing potential outcomes 10,000 times
Primary results
In the Negative, Mild, and High heat index hypothetical experiments, the estimates of the AEE and their 95% posterior interval are: (1) 1.75 [0.34; 3.17], (2) 1.88 [1.10; 2.66] and (3) 2.19 [−0.36; 4.77], respectively. These results suggest that on average more violent crimes occur in Boston during very cold days (−4 < HI < 0 °C) compared to extremely cold days (HI ≤ −4 °C), and also during temperate days (12 < HI < 24 °C) compared to cold days (0 < HI ≤ 12 °C). However, we did not find enough statistical evidence to make conclusions about changes in daily violent crimes counts between extremely hot days (27 °C < HI) and hot days (24 < HI ≤ 27 °C). The hypothetical experiment focusing on the estimation of the AEE of the occurrence of rainfall suggests that compared to dry days, the average daily violent crimes count decreases by 1.37 (95% posterior interval: [−1.94; −0.79]) during rainy days. In Boston, rainy days have fewer crimes than dry days on average.
Exploratory results
The results of the Negative, Mild, and High heat index experiments suggest that, on average, 0.91 (95% interval = [0.45; 1.38]), 0.58 (95% interval = [0.30; 0.86]), and 1.31 (95% interval = [0.18; 2.41]) more aggravated assaults occur on very cold vs. extremely cold days, on temperate vs. cold days, and on extremely hot vs. very hot days, respectively. The estimated effect of rainfall on daily aggravated assault counts is −0.35 (95% interval = [−0.55; −0.14]). Larceny counts also vary between days that are extremely cold and days with temperate heat. In the High heat index and the Rainfalls experiments, there is no evidence of a trend in larceny counts when days are subject to high heat exposure or precipitation occurrence.
Spatial description
For each hypothetical experiment, we present estimated average exposure effects of different exposure levels on the total violent crime counts in Boston. However, there is spatial heterogeneity in crime counts by zip-code area (see Fig. 3). The mapping of the average daily violent crimes by zip-code area across hypothetical experiments (see Fig. 4) suggests that these variations are not homogeneous across experiments. When we compare the average daily violent crimes of days with low exposure level (upper panels) to days with a higher exposure level (lower panels), we observe for the Negative, Mild, High and Precipitation hypothetical experiments: (1) increases in Dorchester, (2) increases in Dorchester, South Boston, South End, and Fenway, (3) decreases in Roslindale, Hyde Park, Charlestown, West End, and Brighton, as well as increases in East Boston, Dorchester, and Longwood Medical area, and (4) decreases in Mattapan and Chinatown, respectively.

Mapping of the average daily violent crimes (between July 2012 and February 2017) per zip-code area in Boston

Spatial description: Mapping of the average daily violent crimes (between July 2012 and February 2017) per zip-code area for different exposure levels across the four hypothetical experiments
Discussion
Our first research focus is to investigate the temperature–violent crime relationship in Boston. We observe a significant increase in daily violent crimes when moving from extremely cold days to temperate days. However, once the heat indexes are high, we do not observe any significant changes in trends in violent crimes frequency as the heat index exposure increases (see Fig. 5). Our second research focus was to examine whether rainfall decreased daily violent crime counts. Clearly, the occurrence of rainfall tends to decrease total daily violent crimes and aggravated assaults. To illustrate and make the effect sizes reported in our study more intuitive, we calculate an absolute change in crime count had thirty cold days been temperate in the Mild heat index experiment maintaining the covariates (e.g., population, length of daylight, or police deployment) the number of days in the other experiments constant. According to our results, if 30 cold days had been temperate, 56.4 (30 × 1.88) additional violent crimes would have occurred, in Boston on average.

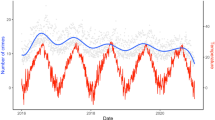
Graphical abstract: Smooth LOESS curves for the three hypothetical experiments (Negative, Mild, and High) focusing on the effects of different heat index exposure levels, fitted with the after propensity score matching samples
The results on the effects of different heat exposures on larceny counts supports the routine activities theory. Indeed, not only aggressive behavior (e.g., violent crimes), but also other criminal activities such as property crime can be affected by varying heat exposures. Furthermore, the observed spatial heterogeneity in violent crime counts suggests that neighborhood differences should also be investigated. For example, the heat-neighborhood interaction could be precisely estimated by reconstructing hypothetical experiments with two conditions, (i.e., heat and neighborhood), each with two-levels (i.e., low/high heat, Downtown/Dorchester neighborhood). Matching techniques for the hypothetical reconstruction of multiple treatment experiments with observational data are discussed in Lopez and Gutman (2017).
It is important to note that interpretation should be restricted to days that remain in the sample after matching, these are the finite population of days between 2012 and 2017 with Bostonian weather characteristics (see Table S7). The data do not provide direct information for unmatched days. Cautiousness regarding extrapolation to days with covariate values beyond values observed in the matched data is necessary. In contrast to other studies interested in the effect of weather variations on criminal or aggressive behavior (Cohn and Rotton, 1997; Rotton and Cohn, 2000a; Cohn and Rotton, 2000, 2005; Schinasi and Hamra, 2017), this study does not provide any estimation of an exposure-response curve. This is a choice we made to be able to use the Rubin Causal Model with more transparent and plausible assumptions given our observational data. Environmental scientists interested in precise causal analysis and inference should not directly model observed data but instead consider a subset of their data exhibiting covariate balance, thereby approximating a hypothetical randomized experiment, in which valid causal effects can be estimated (Rubin, 2008). Generalizing causal effects is a complicated task. Directly modeling observed data from multiple cities can lead to misleading results because the socioeconomic, cultural, and climatic conditions can vary dramatically, and therefore cannot be guaranteed to be modeled correctly. We applied the same analysis strategy to Los Angeles (LA) crime data, a city with a smaller weather spectrum (see Supplementary Material G). The analysis of the weather–crime relationship in LA reveals the existence of a stronger heat–crime relationship than Boston. The results suggest that on average, 6.15 more (95% posterior interval: [3.74; 8.54]), violent crimes occur in LA during cold/temperate days (HI ≤ 17 °C) as compared to hotter days (HI > 17 °C). Interestingly, we observe no evidence for a rain–crime relationship. These divergent results show it is not straightforward to provide estimates generalizing the crime–weather relationship. To enhance crime prevention, the identification of causal factors for crimes should be conducted at the city, or even neighborhood, levels.
As opposed to Agnew (2011); Mares (2013a); Ranson (2014); Levy et al. (2017), our research question does not assess the direct impact of climate change on crimes, but proposes an approach to estimate the effect of weather variations on daily crime counts. Our causal inference approach can be extended to estimate the effects of anomalous weather patterns (as suggested by Mares (2013a)). We believe that this work is a contribution to the field of environmental health because crimes can have adverse effects on mental or physical health. Finding environmental explanations (e.g., weather condition variations), to crime outcomes will contribute to the public health debate on this issue. The results of this study affirm that when considering the economic, sociological, or medical impact of climate change; the effects of weather variations on criminal behavior should be taken into account.
The potential outcome framework coupled with a matched-sampling strategy we present was designed to understand the effect of plausible interventions. Therefore, we believe that interesting extensions to this study should consider not only a more precise spatial understanding of the weather–crime relationship in Boston, but also analyze whether location-specific police deployment with respect to specific weather conditions has an effect on violent crime counts.
Furthermore, although our approach does not suggest any direct intervention to reduce or stop crime incidence, we suggest interventions to alert the population and increase police deployment at certain locations when certain weather conditions can be predicted. Our study confirms that weather variables can have an effect on daily violent crime counts. Environmental factors should be included in crime prediction models to obtain more accurate criminality prevention. Some research focus on investigating the relationship between weather and mental health (Hansen et al., 2008). Other studies examine the effect of environmental exposures (e.g., air pollution) on the brain and behavior-related outcomes (e.g., criminal activity and unethical behavior) (Costa et al., 2017; Lu et al., 2018). Further research should be conducted on the relationships between weather and human behavior, as well as the interaction between temperature and air pollution on neurological outcomes based on observational and experimental data.
Data availability
The datasets analyzed during the current study are available in the Dataverse repository: https://doi.org/10.7910/DVN/4UZ9D4. These were derived from the following public domain resources: https://www.ncdc.noaa.gov/cdo-web https://data.cityofboston.gov https://data.lacity.org
Change history
03 September 2019
An amendment to this paper has been published and can be accessed via a link at the top of the paper.
Notes
New Years Day, Martin Luther King Day, Washington’s Birthday, Good Friday, Memorial Day, Independence Day, Labor Day, Thanksgiving Day, Christmas
Boston Marathon, St. Patrick’s Day, Celtics’ Playoffs (basketball), Patriots’ Playoffs (superbowl)
References
Agnew R (2011) Dire forecast: A theoretical model of the impact of climate change on crime. Theor Criminol 16(1):21–42
Ahmed A, Husain A, Love TE, Gambassi G, Dell’Italia LJ, Francis GS, Gheorghiade M, Allman RM, Meleth S, Bourge RC (2006) Heart failure, chronic diuretic use, and increase in mortality and hospitalization: An observational study using propensity score methods. Eur Heart J 27(12):1431–1439
Anderson C, Bushman B (2002) Human aggression. Annu Rev Psychol 53:27–51
Anderson CA, Bushman BJ, Groom RW (1997) Hot years and serious and deadly assault: Empirical tests of the heat hypothesis. J Pers Soc Psychol 73(6):1213–1223
Anderson CA, Deuser WE, DeNeve KM (1995) Hot temperatures, hostile affect, hostile cognition, and arousal: Tests of a general model of affective aggression. Pers Soc Psychol Bull 21(5):434–448
Anderson GB, Bell ML, Peng RD (2013) Methods to calculate the heat index as an exposure metric in environmental health research. Environ Health Perspect 121(10):1111–1119
Baron RA, Bell PA (1976) Aggression and heat: The influence of ambient temperature, negative affect, and a cooling drink on physical aggression. J Pers Soc Psychol 33(3):245–255
Bell PA, Baron RA (1975) Aggression and heat: The mediating role of negative affect. J Appl Soc Psychol 6(1):18–30
Bind M-A, Rubin DB (2017) Bridging observational studies and randomized experiments by embedding the former in the latter. Stat Methods Med Res 0:1–21
Bushman BJ, Wang MC, Anderson CA (2005) Is the curve relating temperature to aggression linear or curvilinear? Assaults and temperature in Minneapolis reexamined. J Pers Soc Psychol 89(1):62–66
City of Boston Data Portal. Analyze Boston. https://data.cityofboston.gov. Accessed 20 February 2017
Cochran WG, Rubin DB (1973) Controlling bias in observational studies: A Review. Sankhyā: The Indian Journal of Statistics, Series A (1961-2002) 35(4):417–446
Cohen LE, Felson M (1979) Social change and crime rate trends: A Routine Activity Approach. Am Sociol Rev 44(4):588–608
Cohn EG, Rotton J (1997) Assault as a function of time and temperature: A moderator-variable time-series analysis. J Pers Soc Psychol 72(6):1322–1334
Cohn EG, Rotton J (2000) Weather, seasonal trends and property crimes in Minneapolis, 1987-1988. a moderator-variable time-series analysis of routine activities. J Environ Psychol 20(3):257–272
Cohn EG, Rotton J (2005) The curve is still out there: a reply to Bushman, Wang, and Anderson’s (2005) “Is the curve relating temperature to aggression linear or curvilinear?”. J Pers Soc Psychol, 89(1):67(4)
Costa LG, Cole TB, Coburn J, Chang Y-C, Dao K, Roqué PJ (2017) Neurotoxicity of traffic-related air pollution. Neurotoxicology 59:133–139
DeFronzo J (1984) Climate and crime: “Tests of an FBI Assumption”. Environ Behav 16(2):185
Feldman H, Jarmon R (1979) Factors influencing criminal behavior in Newark: A local study in forensic psychiatry. J Forensic Sci 24(1):234
Gabry J, Goodrich B, (2017). rstanarm: Bayesian applied regression modeling via Stan. R package version 2.10.0. http://mc-stan.org/.
Gamble JL, Hess JJ (2012) Temperature and violent crime in Dallas, Texas: Relationships and implications of climate change. West J Emerg Med 13(3):239–246
Hansen A, Bi P, Nitschke M, Ryan P, Pisaniello D, Tucker G (2008) The effect of heat waves on mental health in a temperate Australian city. Environ Health Perspect 116(10):1369–1375
Harries K, Stadler S, Zdorkowski T (1984) Seasonality and assault: Explorations in inter-neighborhood variation, Dallas 1980. Ann Assoc Am Geogr 74(4):590–604
Heckman JJ, Ichimura H, Todd P (1998) Matching as an econometric evaluation estimator. Rev Econ Stud 65:261–294
Hsiang SM, Burke M, Miguel E (2013) Quantifying the influence of climate on human conflict. Science 341(6151):1235367-1235367
Imbens GW, Rubin DB (2015) Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press, New York, NY, USA
Levy BS, Sidel VW, Patz JA (2017) Climate change and collective violence. Annu Rev Public Health 38:241–257
Lopez MJ, Gutman R (2017) Estimation of causal effects with multiple treatments: A review and new ideas. Statistical Science 32(3):432–454
Lu JG, Lee JJ, Gino F, Galinsky AD (2018) Polluted morality: Air pollution predicts criminal activity and unethical behavior. Psychol Sci 29(3):340–355
Mares D (2013a) Climate change and crime: monthly temperature and precipitation anomalies and crime rates in St. Louis, MO 1990–2009. Crime Law Soc Change 59(2):185–208
Mares D (2013b) Climate change and levels of violence in socially disadvantaged neighborhood groups. J Urban Health 90(4):768–783
Mares D, Moffett K (2016) Climate change and interpersonal violence: A “global” estimate and regional inequities. Clim Change 135(2):297–310
NOAA. National Oceanic and Atmospheric Administration. https://www.ncdc.noaa.gov/cdo-web/. Accessed 9 March 2017
Perry JD, Simpson ME (1978) Violent crimes in a city: “Environmental Determinants”. Environ Behav 19(1):77
Ranson M (2014) Crime, weather, and climate change. J Environ Econ Manag 67(3):274–302
Research Advisory Group (BRAG) (2016) Climate Projection Consensus. Boston
Rosenbaum PR, Rubin DB (1983) The central role of the propensity score in observational studies for causal effects. Biometrika 70(1):41–55
Rotton J, Cohn EG (2000a) Violence is a curvilinear function of temperature in Dallas: A replication. J Pers Soc Psychol 78(6):1074–1081
Rotton J, Cohn EG (2000b) Weather, disorderly conduct, and assaults: From social contact to social avoidance. Environ Behav 32(5):651–673
Rotton J, Cohn EG (2003) Global warming and U.S. crime rates. Environ Behav 35(6):802–825
Rubin DB (1974) Estimating causal effects of treatments in randomized and nonrandomized studies. J Educ Psychol 66(5):688–701
Rubin DB (1978) Bayesian inference for causal effects: The role of randomization. Ann Stat 6(1):34–58
Rubin DB (2001) Using propensity scores to help design observational studies: Application to the tobacco litigation. Health Serv Outcomes Res Methodol 2(3):169–188
Rubin DB (2006) Matched sampling for causal effects. Cambridge University Press, New York, NY, USA
Rubin DB (2008) For objective causal inference, design trumps analysis. Ann Appl Stat 2(3):808–840
Sampson RJ (1997) Neighborhoods and violent crime: A multilevel study of collective efficacy. Science 277(5328):918–928
Satcher D (1995) Violence as a public health issue. Bull N Y Acad Med 72(1):46
Schinasi LH, Hamra GB (2017) A time series analysis of associations between daily temperature and crime events in Philadelphia, Pennsylvania. J Urban Health 94(6):892–900
Steadman R (1994) Norms of apparent temperature in Australia. Aust Meteorol Mag, Canberra, Aust 43(1):1–16
Tiihonen J, Halonen P, Tiihonen L, Kautiainen H, Storvik M, Callaway J (2018) The association of ambient temperature and violent crime. Nat Sci Rep 7(1):6543–6543
Acknowledgements
Research reported in this publication was supported by the Office of the Director, National Institutes of Health under Award Number DP5OD021412 and the John Harvard Distinguished Science Fellows Program, within the FAS Division of Science of Harvard University. We thank Rachel Schweiker for proof-reading the manuscript. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Author information
Authors and Affiliations
Contributions
AJS and MACB designed the research. ML prepared the datasets, constructed the maps, and conducted the spatial discussion. AJS analyzed the data. AJS and MACB wrote and thoroughly discussed the first draft of the paper. All authors, read, revised and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sommer, A.J., Lee, M. & Bind, MA.C. Comparing apples to apples: an environmental criminology analysis of the effects of heat and rain on violent crimes in Boston. Palgrave Commun 4, 138 (2018). https://doi.org/10.1057/s41599-018-0188-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-018-0188-3
This article is cited by
-
A nationwide time-series analysis for short-term effects of ambient temperature on violent crime in South Korea
Scientific Reports (2024)
-
Heat and fraud: evaluating how room temperature influences fraud likelihood
Cognitive Research: Principles and Implications (2020)
