
Abstract
Mass antigen testing has been proposed as a possible cost-effective tool to contain the COVID-19 pandemic. We test the impact of a voluntary mass testing campaign implemented in the Italian region of South Tyrol on the spread of the virus in the following months. We do so by using an innovative empirical approach which embeds a semi-parametric growth model—where COVID-19 transmission dynamics are allowed to vary across regions and to be impacted by the implementation of the mass testing campaign—into a synthetic control framework which creates an appropriate control group of other Italian regions. Our results suggest that mass testing campaigns are useful instruments for mitigating the pandemic.
Similar content being viewed by others


Introduction
A wide variety of interventions have been used in an attempt to stop the spread of COVID-19 across the globe (i.e. lockdown, quarantines, business closures, mobility restrictions, school closures)1,2. Many of these are also the main candidate policies for stopping the spread of other large-scale epidemic outbreaks, such as Ebola. One particularly low-cost intervention that has been tried in a few locations is mass testing of a population in order to identify asymptomatic carriers3,4. Theoretical work suggests that mass testing could reduce daily infections by up to 30 percent5, while a study on the impact of a mass testing campaign undertaken in Slovakia in late 2020 finds that it temporarily decreased the growth of COVID-19 by 70 percent6. Importantly, many countries worldwide offer open public testing indicating that frequent mass testing is a feasible intervention7.
In this paper, we test the impact of a voluntary mass testing campaign implemented in the Italian region of South Tyrol on the spread of the virus in the following months. We do so by using an innovative empirical approach which embeds a semi-parametric growth model into a synthetic control framework. Specifically, we first use the synthetic control approach to create a control group which is a weighted-average of other Italian regions that best follow the dynamics of COVID-19 transmission in South Tyrol prior to the mass testing campaign8,9. We use this approach because it uses the data to derive the optimal control region for South Tyrol. Although this method was previously used to evaluate the impact of masks and other non-pharmaceutical interventions on the spread of COVID-1910,11, these papers use a traditional synthetic control framework which does not account for the underlying growth dynamics of an epidemic like COVID-19. We then estimate on appropriately weighted data a semi-parametric growth model where COVID-19 transmission dynamics (i.e. growth rates) are allowed to vary across regions and to be impacted by the implementation of the mass testing campaign. Importantly, this approach is in the spirit of difference-in-difference models which compare changes in outcomes over time in a treated location to changes in outcomes over time in otherwise similar control locations and hence can isolate the impact of the mass testing campaign from national level policies regarding freedom of movement, business and school closures, hygienic measures, etc, as none of these other policies changed specifically at the same time as the testing campaign in South Tyrol12.
This approach has a number of benefits over what has so far been done in the literature that attempts to estimate the impact of public health interventions on the spread of COVID-19, as well as on other contagious diseases. Specifically, previous papers use either full parametric models13,14,15,16 or traditional synthetic control or difference-in-difference models2,10,11,17,18,19,20,21. While fully parametric models based on biological growth theory have proved very useful for assessing the dynamics of disease outbreaks, their overly rigid a-priori parametric assumptions do not allow them to fit the typical variation in short- and medium-run dynamics seen in the spread of COVID-19. On the other hand, traditional difference-in-difference and synthetic control models, by assuming that treatment and control regions would follow parallel trends in a counterfactual reality without any intervention, are potentially biased because growth dynamics in different regions will depend on the prior contagion rate.
Although there is a rich literature on estimating model-free growth curves in other fields, the use of non-parametric or semi-parametric approaches has not been sufficiently explored in the context of health policy analysis. Exceptions include15 which fits a flexible growth model curve to reported positive COVID-19 cases and22 which specifies dependence of the parameters in the Richards growth model on covariates to assess country-level risk factors due to COVID-19 within a hierarchical Bayesian framework. However, neither of these papers estimate the impact of a particular policy intervention. We show that the estimated impact of the mass test campaign in South Tyrol is sensitive to how one models COVID-19 transmission dynamics and flexible models better fit the data and generate more robust estimates of the impact of the mass testing campaign. Furthermore, our approach has the added benefit that it generates estimates of the disease proliferation rate both with and without intervention, thus gaining insight on the transmission pathways.
Overall, we find that the mass test campaign in South Tyrol decreased the growth rate of COVID-19 by 45% (95% confidence interval: 38-53%). This corresponds to a reduction in the total additional cases of 17%, 22%, 26% and 51% within seven, ten, twenty and forty days from the intervention date, respectively. Importantly, this large impact was achieved even though the campaign was entirely voluntary with no incentives to participate. In Slovakia, individuals who did not participate were required to quarantine for ten days, hence it was not entirely a voluntary test. Our results are in line with the predictions made in5 based on an epidemiological model. We find a smaller impact than6 reports for the mass testing campaign in Slovakia; however, the Slovakian intervention featured a multiple round campaign in addition to concurrent interventions, including a one-week lockdown. In line with our findings,23 uses a different approach to analyze the impact of the Slovakia campaign and finds that infections were reduced by about 25-30% in the two weeks after individuals in some districts were tested a second time.
The mass test
The population of South Tyrol was invited to take part in a mass testing campaign in late November 2020 using rapid antigen tests, which involve a nasal and throat swab. Authorities set up around 300 testing centers, where professional health care workers carried out the tests, with the support of volunteers from the civil protection agency, the voluntary fire services and other organizations for handling the logistics and the administration. All residents were invited to participate, with the exception of children below the age of five, people with COVID-19 symptoms, those on sick leave, those who had tested positive and isolated in the last three months, and those who had recently tested positive or were in quarantine or self-isolating. People with a prior appointment for a PCR (Polymerase Chain Reaction) test, those regularly tested for work reasons, and individuals in social care were also not tested.
Testing centers generally operated from 8am to 6pm from Friday, 20 November to Sunday, 22 November. During this period, people could show up at any of the centers throughout the region. In some municipalities, it was possible to register online and some published suggested centers and time slots based on the address of residence. It was also possible to be tested at some pharmacies and general practitioners in the period 18 to 25 November. People only needed a valid ID and a European Health Insurance card. They filled in a form with an email address, where they would receive, generally within a day, an encrypted file with the outcome, and a mobile number, where they would receive an SMS with the code to open the file. In case of a negative result, people were advised to continue following prevention measures like social distancing and mask wearing. In case of a positive result, people had to isolate for 10 days if asymptomatic and contact their doctor if they developed symptoms.
Participation in the mass testing was voluntary and encouraged by a massive communication campaign, providing information (with material available also in Albanian, Arabic, English, French and Urdu, as well as in simple language for kids), as well as endorsements by public figures. The goal was to identify asymptomatic cases in the population and hence reduce virus transmission. The headline of the campaign was “Together against coronavirus”, using appeals like “Let’s break the infection wave together and pave the way towards a gradual return to normality!”. In the end, 72 percent of eligible residents volunteered to be tested24. In comparison, 83 percent of the eligible population in Slovakia decided to be tested when the alternative was to quarantine for 10 days.
Methods
Semi-parametric growth model
To analyze the dynamics of the COVID-19 epidemic over time, we develop a flexible semi-parametric growth curve approach and combine it with a synthetic control approach for picking the optimal control regions for our analysis. Let \(x_t\) denote the cumulative size of the detected infected population at time t. In classic parametric growth curve analysis, the dynamics of \(x_t\) is represented by the derivative of \(x_t\), which is often assumed to have the form
where \(\rho\) is the intrinsic growth rate determining the time scale of the epidemic process, \(p \in [0,1]\) is the “deceleration of growth” parameter capturing different growth profiles and g is a smooth non-increasing function of \(x_t\) possibly depending on other model parameters.
A number of well-known growth models can be recovered from Eq. (1) depending on the choice of g; although the literature is too vast to be covered here, we provide a few examples. A basic model is the exponential growth (EG) model corresponding to \(g(x_t)= 1\). The EG model assumes that an epidemic continues to grow following the same process as in the past with the growth path completely specified by p: constant incidence (\(p=0\)), sub-exponential growth (\(0<p<1\)) and exponential growth (\(p=1\)); see, e.g.13. Although this may be useful for representing the early stages of an epidemic, it is an upper bound scenario since outbreaks often slow down and reach saturation capacity after initial exponential growth. One popular extension is the generalized logistic growth (GLG) model \(g(x_t) = 1 - x_t/k\), where k represents the total size of the epidemic, i.e. the asymptotic number of infections over the whole epidemics13. A slightly more flexible model is the generalized Richards growth (GRG) model \(g(x_t) = 1 - (x_t/k)^a\), where the parameter a allows for deviations from the S-shaped dynamics of the classical GLG13,25.
Despite the wide range of parametric growth models available, none of these rigid apriori specifications do a good job at fitting the rich dynamics observed in real COVID-19 data, which potentially leads to biased inferences. Instead, we estimate a more flexible model, referred to as a semi-parametric growth (SPG) model, that includes additional flexibility in two dimensions.
We first add flexibility by estimating the function g in the following semi-parametric specification:
where the \(\eta _j\)s are unknown coefficients and the \(b_j(x_t)\) are given basis functions, such as basis spline functions. The basis expansion \(h(x_t) = \sum _{j=1}^q \eta _{j} b_j(x_t)\) allows us to approximate an arbitrary smooth function, provided that q is large enough. Overall, this specification requires fewer assumptions about the data and fits the data better in situations where the true outbreak trajectory is hard to specify in advance, as is the case for the Italian COVID-19 data.
We also allow the growth rate parameter \(\rho\) to depend on other explanatory variables. Since our main inferential interest is to assess the impact of the policy treatment on pre- and post-treatment growth differences, we assume the growth rate follows a log-linear difference-in-differences type of specification:
where \(\texttt {Int}_t\) is a dummy variable for the policy intervention taking value 0 up to the intervention date and 1 afterwards, \(\texttt {Reg}_i\) is a dummy variable taking value 1 for the geographical region exposed to treatment (South Tyrol) and 0 otherwise, and \(\mathbf {z}_{it}\) is a \(q\times 1\) vector of additional controls (discussed in “Statistical inference” section) that capture differences over time and across regions that are potentially related to COVID-19 growth dynamics. The overall vector describing the growth parameters is denoted by \(\theta = (\alpha , \beta , \gamma , \delta , \varvec{\xi }^\top )\).
Our main inferential interest is in the coefficient \(\delta\) for the interaction between the intervention and the geographical area. This parameter measures the effect of the policy intervention and is identified in a similar way as in a traditional difference-in-differences model by comparing the change over time in the growth rate of COVID-19 infections (\(\rho _{it}\)) from before the mass testing campaign to after the campaign in South Tyrol to the same change over time in the control regions (Synthetic South Tyrol, defined in “Defining the control group” section), for a given \(g(x_t)\). Note that the spline function, \(g(x_t)\), is identifiable separately from \(\delta\) since it is assumed to be unaffected by the intervention. In particular, \(g(x_t)\) is assumed to be fixed in the sense that it only depends on the stock of cases, x, not on the region nor on the time relative to the intervention. This means that, similar to an intercept in a simple linear model, \(g(x_t)\) is estimated using the entire sample and may be interpreted as the baseline growth pattern independent of the intervention.
We also assess the impact of the policy intervention by examining the variations of the transmission growth rate. From Eq. (3), the relative change in the growth rate can be computed as \(\Delta \rho _i(\theta ) = [\rho _{i1}(\theta ) - \rho _{i0}(\theta )]/\rho _{i0}(\theta ) = \exp \left\{ \beta + \delta \ \texttt {Reg}_i \right\} - 1\). Therefore, the relative change in the treatment and control groups are \(\Delta \rho _1 = \exp \{ \beta + \delta \} - 1\) and \(\Delta \rho _0 = \exp \{ \beta \} - 1\), respectively.
Statistical inference
Let \(Y_{it}\) denote new COVID-19 cases observed in region i at time t. We follow15 and estimate the model parameters by assigning to each \(Y_{it}\) an appropriate statistical distribution with mean \(E[Y_{it}] = \partial x_{it}/\partial t = \rho _{it}(\theta ) x_{it}^p g(x_{t})\), where \(x_{it}\) is the cumulative number of cases observed in region i at time t and \(\rho _{it}(\theta )\) is a region- and time- specific growth rate parameter. For \(Y_{it}\) we consider both the Poisson and negative binomial (NB) distributions, which are appropriate models for count data. Using a log-link function to relate the expected new cases to other predictors, the working statistical model for inference can be written as
\(i=0,1\) and \(t=1,\dots , T\), where \(\rho _{it}(\theta )\) is the time- and region-specific growth rate defined in Eq. (3) and the function h is defined in Eq. (2).
We estimate two specifications of each model, a first that has no additional control variables (\(z_{it}\)) and a second that includes (unreported) controls (+Ctrl) that could impact short term (daily) movements of the outbreak trajectory, specifically i) the difference since the previous day in the number of new tests carried out, ii) day of the week fixed effects, iii) interactions between the number of new tests and day of the week fixed effects, and (iv) and an index measure of non-pharmaceutical interventions active in each region taken from12.
Thus, overall we estimate four SPG models: Pois, Pois + Ctrl, NBin, and NBin + Ctrl. For each SPG model, we report chi-squared statistics for the non-parametric component of our model corresponding to the null hypothesis \(H_0: h(x) = 0\). For all the considered models, we compute the adjusted R-squared and the explained deviance statistic, as well as the Akaike information criterion (AIC) and Bayesian information criterion (BIC) for model selection. The deviance for a model is defined as twice the difference between the log-likelihood function of the fitted model and that of the saturated model, i.e. the model that fits exactly the data by taking one parameter for each observation. The explained deviance is computed as \((D_0-D_1)/D_0\), where \(D_1\) is the deviance for the model being estimated and \(D_0\) is the deviance for the model without predictors26.
Equation (4) represents a generalized additive model (GAM); e.g., see27,28 for an introduction on GAMs. Estimates for the growth rate parameters \({{\widehat{\theta }}}= ({{\widehat{\alpha }}}, {{\widehat{\beta }}}, {{\widehat{\gamma }}}, \widehat{\delta }, {{{\widehat{\varvec{\xi }}}}}^\top )\), growth deceleration \({\widehat{p}}\) and for the smooth function \({\widehat{h}}(\cdot )\) are obtained by running a penalized likelihood estimator with penalty depending on a smoothing parameter for the non-parametric part of the model. We use thin-plate radial basis spline functions for the terms \(b_i(x_{t})\) and smoothing parameter tuned via maximum likelihood estimation.
Estimates are obtained using the function gam in the R package mgcv29. See28 and references therein for details on the estimation procedure and implementation. Approximate variances and covariances for the estimated parameters are extracted using the function vcov.gam in the R package mgcv. An estimate of \(\widehat{\Delta \rho _i}\), the relative growth change due to intervention, is obtained by plugging-in the parameter estimates \({{\widehat{\beta }}}\) and \({{\widehat{\delta }}}\) into the expression \(\Delta \rho _i(\theta )\). Since the parameter estimates are asymptotically normal, the standard errors for \({{\widehat{\Delta }}} \rho _i\) can be derived using the Delta method (e.g., see30), obtaining \(SE(\widehat{\Delta \rho _0}) = \exp \{ {{\widehat{\beta }}} \} \times SE({{\widehat{\beta }}})\) and \(SE(\widehat{\Delta \rho _1}) = \exp \{ {{\widehat{\beta }}} + {{\widehat{\delta }}}\} \times \sqrt{SE({{\widehat{\beta }}})^2 + SE({{\widehat{\delta }}})^2 + {\widehat{Cov}}({{\widehat{\beta }}}, {{\widehat{\delta }}})}\), where \(SE({{\widehat{\beta }}})\) and \(SE({{\widehat{\delta }}})\) are the standard errors for \({{\widehat{\beta }}}\) and \(\widehat{\delta }\) and \({\widehat{Cov}}({{\widehat{\beta }}}, {{\widehat{\delta }}})\) is an estimate of the covariance between \({{\widehat{\beta }}}\) and \({{\widehat{\delta }}}\).
Defining the control group
As there is no obvious a priori control group, in order to evaluate the effect of the screening intervention in South Tyrol, we constructed an optimal control group (Synthetic South Tyrol) using the synthetic control methodology of8. This method constructs a weighted combination of data from the control group to approximate the behavior of the intervention group in terms of pre-intervention characteristics. While this is not necessary for estimating the impact of the intervention using a semi-parametric growth model, having a control group that is similar in terms of COVID-19 dynamics as South Tyrol should lead to a more accurate estimate. We find that this is, in fact, the case. In unreported results, we estimate our main model with each region of Italy given equal weight. This model does not fit the data as well as when we construct an optimal control group.
Suppose we observe new cases \(Y_{it}\) in regions \(i= 1,\dots , N+1\) at times \(t= 1, \dots ,T\) and assume intervention occurs at time \(T_0+1\) so that \(1,\dots , T_0\) are pre-intervention periods. Without loss of generality, the first region (\(i=1\)) represents South Tyrol, which is exposed to the intervention, so we have N remaining donor regions contributing to the synthetic control (in our case, the other 20 Italian regions or autonomous provinces in the donor pool). Let \(\mathbf {w}= (w_1, \dots , w_N)^\top\) be a \((N\times 1)\) vector of weights such that \(\sum _{i=1}^N w_i= 1\) and \(w_i \ge 0\) for all \(i=1, \dots , N\), where \(w_i\) denotes the weight of region i in the synthetic South Tyrol. Let \(\mathbf {u}_i=(x_{i1}, \dots , x_{iT_0}, z_{i1}, \dots , z_{iT_0} )^\top\) be a \((2T_0\times 1)\) vector containing pre-treatment values for cumulative number of cases (\(x_{it}\)) and number of tests (\(z_{it}\)) for region i. Thus, the vector \(\mathbf {u}_1\) contains pre-treatment values for South Tyrol and the \((2T_0 \times N)\) matrix \(\mathbf {U}_0=(\mathbf {u}_2, \dots , \mathbf {u}_{N+1})\) with columns \(\mathbf {u}_2, \dots , \mathbf {u}_{N+1}\) contains pre-treatment values for all the remaining donor regions.
The synthetic control method selects the vector of weights \(\widehat{{\textbf {w}}}\) that determines the best control region by solving the following quadratic optimization problem:
where \(\mathbf {V}\) is a \(2T_0 \times 2T_0\) symmetric and positive semidefinite matrix to allow different weights to the variables in \(\mathbf {U}_0\) depending on their predictive power on the outcome. To stress dependence on \(\mathbf {V}\), we use the notation \({{\widehat{{{\textbf {w}}}}}} = {{\widehat{{{\textbf {w}}}}}}(\mathbf {V})\) for the solution to (5). To select \(\mathbf {V}\), we minimize the mean squared prediction error (MSPE) of the outcome variable over pre-intervention periods as described in31 and9. Specifically, if \(\mathbf {Y}_1\) is the \((T_0 \times 1)\) vector with the values of the outcome variable (new cases) for South Tyrol and \(\mathbf {Y}_0\) is the \((T_0 \times N)\) analogous matrix for the control units, then \(\mathbf {V}\) is selected by minimizing the \(\text {MSPE}(\mathbf {V})= \Vert \mathbf {Y}_1 - \mathbf {Y}_0 {{\widehat{\mathbf {w}}}}(\mathbf {V}) \Vert ^2\) over all positive definite and diagonal matrices \(\mathbf {V}\).
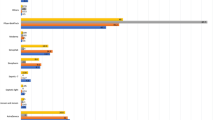
The above procedure is implemented in the function synth of the R package Synth which uses the Nelder-Mead and BFGS algorithms as default options, and then picks the solution with the lowest MSPE32. Figure 1 shows the estimated synthetic control weights for the 20 donor regions. The regions Valle d’Aosta, Friuli Venezia Giulia and Veneto are by far the major contributors in the synthetic control with percent weights equal to 71.0%, 20.0% and 7.5%, respectively. Valle d’Aosta is, like South Tyrol, a small mountain region in the North of Italy, but is not contiguous with South Tyrol. To assess the goodness-of-fit of this selection, we computed the R-squared type statistic \(R^2 = 1 - \Vert \mathbf {Y}_1 - \mathbf {Y}_0 {{\widehat{\mathbf {w}}}} \Vert ^2/ \Vert \mathbf {Y}_1 - {\bar{\mathbf {Y}}} \Vert ^2 = 0.871\), with \({\bar{\mathbf {Y}}}_1\) denoting the arithmetic average of the elements of vector \(\mathbf {Y}_1\). Moreover, we found a Pearson correlation coefficient between \(\mathbf {Y}_1\) and \(\mathbf {Y}_0 {{\widehat{\mathbf {w}}}}\) equal to 0.936. Both the \(R^2\) statistic and correlation coefficient show a very good match between South Tyrol and the synthetic control region in the pre-intervention period.
The weights generated by this procedure are then used to estimate the model described in “Semi-parametric growth model” section. This is different than the standard synthetic control approach which would directly compare outcomes for the treated group to that of the synthetic control group or examine changes in outcomes from the pre-treatment period in a standard difference-in-differences framework. Our approach is more flexible as it only assumes that the general underlying growth function is the same in each region and then identifies the impact of the mass testing campaign by looking at how the actual COVID-19 growth rate changes before/after the intervention relative to changes over the same time period in a weighted sample of regions with the same dynamics prior to the intervention.
Data description
The analysis in this paper focuses on the second COVID-19 outbreak wave that occurred in Italy in late 2020. We use daily data on cumulative cases and number of tests from 1 September 2020 to 31 December 2020 on 19 Italian regions and 2 autonomous provinces. The autonomous province of Bozen/Bolzano—South Tyrol is the intervention group of our study as it was the only Italian territory that implemented mass screening in this time period. Residents of South Tyrol were invited to take a COVID-19 antigen rapid tests from Friday, 20 November through Sunday, 22 November; see “The mass test” section for details. 361,781 out of 500,607 (72.3 percent) eligible residents volunteered to take a test.
Results
Table 1 shows the estimates for the semi-parametric growth models (SPGs) described in “Statistical inference” section using Poisson (Pois) and negative binomial (NBin) response functions. Each model includes an indicator for being in the treatment region (Reg), an indicator for being in the time-period after the mass-testing intervention (Int), and interaction between the two, and an intrinsic growth parameter (p). For comparison purposes, Table 1 also shows in the lower part analogous setups for pure exponential growth models obtained by setting \(h(x_{it})=0\) in the semi-parametric models. Based on both AIC and BIC model selection criteria, the best fitting model is NBin+Ctrl (negative binomial response with additional controls), which has an adjusted R-squared of 88.9% and percent of explained deviance of 93.9%. Overall, all the SPG models fit the data well with adjusted R-squared always exceeding 80%. The standard EG models perform worse in terms of the goodness-of-fit metrics and for all the combinations of response distribution and predictors compared to the SPG models. The appropriateness of the semi-parametric models is also confirmed by the statistically significant chi-squared statistics for the non-parametric function h in all considered cases.
Figure 2 plots the estimated number of new cases \({\widehat{y}}_{it}\) over time along with the actual observed data for both South Tyrol and the synthetic control region. The plots show the results from the Poisson and negative binomial models with and without the included additional short-term controls. Regardless of whether additional controls are included, the fitted models show a sizable and sudden decrease in the estimated new cases after the mass testing campaign. The models with additional covariates fit the short- and long-term data trajectories for both control and treatment regions remarkably well.
In each of the SPG models, we find that the difference-in-differences interaction Int\(\times\)Reg, which indicates the impact of the mass testing campaign on COVID-19 growth in South Tyrol, is negative and highly significant. The estimated coefficient from our preferred SPG model NBin+Ctrl is -0.542 which implies a decrease of the growth rate of \(45.4\%\) (with 95% confidence interval 38.0-52.8%). These results are robust to both the response function used and whether controls are included, with the estimated decrease in growth rate in these alternative specifications ranging from 45% to 51%. If instead one uses standard EG models, the estimated impacts are generally smaller, are less robust to model choice, and are less precisely estimated.
We next run a placebo test to gauge the possibility that our estimated impact of the mass testing campaign occurs by chance. We do this by matching each of the other 20 regions of Italy to synthetic versions of themselves and then estimating the SPG model (NBin + Ctrl) assuming there was an intervention at the same time as the real intervention in South Tyrol. Figure 3 compares the estimated impact in South Tyrol with the distribution of the estimates for the other regions. Further, we examine the distribution of the estimated interaction effect \({{\widehat{\delta }}}\) across placebo models. The estimated effect for the model with South Tyrol as treatment region is \({{\widehat{\delta }}} =-0.512\) while a 95% confidence interval based on the estimates for the other regions is \([-0.312, 0.160]\). The estimate for South Tyrol clearly stands out, with none of the other regions having large changes in transmission rates around the time of the intervention.
Finally, to evaluate the overall impact of the mass testing campaign, we compute the number of cases in South Tyrol over time by calculating the predicted number of cases that would have occurred each day after the intervention if the post-intervention transmission growth rate has not been reduced. Based on the estimates from our preferred model (SPG NBin+Ctrl), there were 2,115, 2,816, 4,962 and 9,560 fewer cumulative COVID-19 cases in South Tyrol compared to a scenario of unmitigated growth 7, 10, 20 and 40 days after the intervention, respectively. This corresponds to an overall reduction in cases of 17%, 22%, 26% and 51%.
Our findings are in line with the predictions by5 which uses a SEIR dynamic ordinary differential equations model to predict outbreak dynamics under various contagion scenarios. When they consider the scenario where 75% of the population is tested—which is close to the 72% observed in South Tyrol—the predicted reduction in prevalence in the population within 10 days of mass testing is between 10% and 30%, where we estimate a reduction of 22% under the same time horizon.
Conclusions
In this paper, we employ an innovative empirical approach to study the impact of mass testing on COVID-19. In particular, we combine a synthetic control methodology to define a control group and a semi-parametric growth model to model the epidemiological developments. We show that using a semi-parametric approach rather than more standard parametric exponential growth models makes a difference in the evaluation of the impact on COVID-19 growth of the mass testing that took place in the Italian region of South-Tyrol in November 2020.
In our preferred specification, we find that mass testing reduced the growth rate of COVID-19 by about 45%. This suggests that mass testing can be an useful tool to contain the pandemic. Importantly, the mass testing campaign in South Tyrol was entirely voluntary and still managed to attract 72 percent of eligible residents to participate. This likely occurred because it was underlined that participating would help reduce the spread of COVID-19 and it could potentially lead to fewer restrictions in other dimensions. In many countries, public testing is openly available, suggesting that supply constraints are less and less binding. We find that a more organized approach to testing can make a big difference in reducing the spread of COVID-19.

Synthetic control weights used to construct the synthetic control region

Fitted semi-parametric growth models against actual data on new cases for South Tyrol and synthetic control. The first and second row correspond, respectively, to Poisson (Pois) and negative binomial (NBin) models for new cases. The first column corresponds to models without short-term control factors, while the second column shows models with the additional controls included (+Ctrl)

Differences between new cases in treatment and synthetic control regions over time, obtained by running the synthetic control method for each of the 21 Italian regions. The solid line corresponds to South Tyrol, the dashed line represents point-wise average difference for the remaining regions, the shaded area represents points within 1.96 standard deviations from the point-wise average difference
Data availability
The datasets generated and/or analysed during the current study are available in the Italian Civil Protection Department online repository, https://github.com/pcm-dpc/COVID-19.
References
Haug, N. et al. Ranking the effectiveness of worldwide Covid-19 government interventions. Nat. Hum. Behav. 4(12), 1303–1312 (2020).
Tian, H. et al. An investigation of transmission control measures during the first 50 days of the Covid-19 epidemic in China. Science 368(6491), 638–642 (2020).
Holt, E. Slovakia to test all adults for SARS-COV-2. The Lancet 396(10260), 1386–1387 (2020).
Atkeson, A., Droste, M. C., Mina, M. J., & Stock, J. Economic benefits of covid-19 screening tests with a vaccine rollout. medRxiv (2021).
Bosetti, P., Tran Kiem, C., Yazdanpanah, Y., Fontanet, A., Lina, B., Colizza, V., & Cauchemez, S. Impact of mass testing during an epidemic rebound of SARS-COV-2: A modelling study. medRxiv (2020).
Pavelka, M. et al.The Impact of Population-Wide Rapid Antigen Testing on SARS-COV-2 prevalence in Slovakia (Science, 2021).
Hasell, J. et al. A cross-country database of Covid-19 testing. Sci. Data 7(1), 345 (2020).
Abadie, A., Diamond, A. & Hainmueller, J. Synthetic control methods for comparative case studies: Estimating the effect of california’s tobacco control program. J. Am. Stat. Assoc.105(490), 493–505 (2010).
Abadie, A. & Gardeazabal, J. The economic costs of conflict: A case study of the Basque country. Am. Econ. Rev. 93(1), 113–132 (2003).
Mitze, T., Kosfeld, R., Rode, J. & Wälde, K. Face masks considerably reduce Covid-19 cases in Germany. Proc. Natl. Acad. Sci. 117(51), 32293–32301 (2020).
Cho, S.-W.S. Quantifying the impact of nonpharmaceutical interventions during the COVID-19 outbreak: The case of Sweden. Economet. J. 23(3), 323–344 (2020).
Conteduca, F. P. & Borin, A. A new dataset for local and national Covid-19-related restrictions in Italy. Italian Econ. J., 1–36 (2022).
Wu, K., Darcet, D., Wang, Q. & Sornette, D. Generalized logistic growth modeling of the covid-19 outbreak: Comparing the dynamics in the 29 provinces in China and in the rest of the world. Nonlinear Dyn. 101(3), 1561–1581 (2020).
Aviv-Sharon, E. & Aharoni, A. Generalized logistic growth modeling of the covid-19 pandemic in Asia. Infect. Dis. Model. 5, 502–509 (2020).
Chénangnon, F. T., Lokonon, B. E. & Kakaï, R. G. On the use of growth models to understand epidemic outbreaks with application to covid-19 data. PLoS ONE 15(10), e0240578 (2020).
Pelinovsky, E., Kurkin, A., Kurkina, O., Kokoulina, M. & Epifanova, A. Logistic equation and Covid-19. Chaos Solitons Fractals 140, 110241 (2020).
Hsiang, S. et al. The effect of large-scale anti-contagion policies on the Covid-19 pandemic. Nature 584(7820), 262–267 (2020).
Mangrum, D. & Niekamp, P. Jue insight: College student travel contributed to local covid-19 spread. J. Urban Econ., 103311 (2020).
Alexander, A., Martin, H., & Lackner, M. Mass gatherings contributed to early Covid-19 spread: Evidence from us sports. Technical report, Working paper (2020).
Dave, D., Friedson, A. I., Matsuzawa, K. & Sabia, J. J. When do shelter-in-place orders fight Covid-19 best? Policy heterogeneity across states and adoption time. Econ. Inq. 59(1), 29–52 (2021).
Singh, S., Shaikh, M., Hauck, K., & Miraldo, M. Impacts of introducing and lifting nonpharmaceutical interventions on Covid-19 daily growth rate and compliance in the United States. Proc. Natl. Acad. Sci., 118(12) (2021).
Lee, S. Y., Lei, B., & Mallick, B. K. Estimation of covid-19 spread curves integrating global data and borrowing information (2020). arXiv preprintarXiv:2005.00662.
Kahanec, M., Lafférs, L., & Schmidpeter, B. The impact of repeated mass antigen testing for covid-19 on the prevalence of the disease. Technical Report 4 (2021).
Stillman, S. & Tonin, M. Communities and testing for Covid-19. Eur. J. Health Econ., 1–9 (2022).
Chowell, G. Fitting dynamic models to epidemic outbreaks with quantified uncertainty: A primer for parameter uncertainty, identifiability, and forecasts. Infect. Dis. Model. 2(3), 379–398 (2017).
Wood, S. N., Pya, N. & Säfken, B. Smoothing parameter and model selection for general smooth models. J. Am. Stat. Assoc. 111(516), 1548–1563 (2016).
Hastie, T. J. & Tibshirani, R. J. Generalized Additive Models Vol. 43 (CRC Press, Boca Raton, 1990).
Wood, S. N. Generalized Additive Models: An Introduction with R (CRC Press, Boca Raton, 2017).
Wood, S. & Wood, M. S. Package ‘mgcv’. R package version1, 29 (2015).
Van der Vaart, A. W. Asymptotic Statistics Vol. 3 (Cambridge University Press, Cambridge, 2000).
Abadie, A. & Diamond, A., Hainmueller, J. (2010):“Synthetic control methods for comparative case studies: Estimating the effect of california’s tobacco control program”. J. Am. Stat. Assoc.105(490), 493–505 (2014).
Abadie, A., Diamond, A. & Hainmueller, J. Synth: An r package for synthetic control methods in comparative case studies. J. Stat. Softw. Articles 42(13), 1–17 (2011).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ferrari, D., Stillman, S. & Tonin, M. Assessing the impact of COVID-19 mass testing in South Tyrol using a semi-parametric growth model. Sci Rep 12, 17952 (2022). https://doi.org/10.1038/s41598-022-21292-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-21292-3
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
