
Abstract
Cannabis Use Disorder (CUD) has been linked to a complex set of neuro-behavioral risk factors. While many studies have revealed sex and gender differences, the relative importance of these risk factors by sex and gender has not been described. We used an “explainable” machine learning approach that combined decision trees [gradient tree boosting, XGBoost] with factor ranking tools [SHapley’s Additive exPlanations (SHAP)] to investigate sex and gender differences in CUD. We confirmed that previously identified environmental, personality, mental health, neurocognitive, and brain factors highly contributed to the classification of cannabis use levels and diagnostic status. Risk factors with larger effect sizes in men included personality (high openness), mental health (high externalizing, high childhood conduct disorder, high fear somaticism), neurocognitive (impulsive delay discounting, slow working memory performance) and brain (low hippocampal volume) factors. Conversely, risk factors with larger effect sizes in women included environmental (low education level, low instrumental support) factors. In summary, environmental factors contributed more strongly to CUD in women, whereas individual factors had a larger importance in men.
Similar content being viewed by others

Introduction
Cannabis is the most commonly used illicit drug in the United States, with an estimated 8.2% of the population reporting cannabis use in the past month1. Of those who endorsed past-year use, an estimated 30.6% met criteria for Cannabis Use Disorder (CUD)2. Although men have historically reported a greater prevalence of cannabis use relative to women, this gender gap is narrowing3,4,5,6. Moreover, research shows that women progress to CUD more quickly than men7,8. While the observed broad differences in use patterns thus suggest that different factors may be underlying CUD in women versus men, little is known about which factors drive these differences9,10. Here we examine both neurobiological (e.g., sex-specific) risk factors as well as environmental (e.g., gender-specific) risk factors that are difficult to parse in humans11. We will refer to the differences between men and women in this study as sex/gender differences to more accurately reflect this complexity.
The factors underlying cannabis use and dependence are complex and likely include neurobiological, individual-level (e.g., personality, cognitive), and environmental risk factors. These factors have, until now, often only been investigated in a fragmented way, with researchers focusing on a small number of factors in each study or focusing on a single domain of interest. However, the recent availability of large public datasets with broad phenotyping, such as the Human Connectome Project (HCP), and the emergence of machine learning approaches and ranking tools for evaluating the importance of a large number of factors and their relative contributions12, make it possible to shift toward an analysis of the patterns of factors underlying CUD.
Prominent neurobiological theories of addiction have traditionally focused on the importance of reward- and approach-related behavior, with newer theories integrating cognitive and affective factors as important additional functional domains13,14,15,16. However, even “multi-mechanistic” addiction models are limited, such as the Koob–Volkow model13 that discusses three main mechanisms involved in addiction: incentive salience/habit formation (reward/approach-related behavior), negative affect, and executive function. Only very few addiction theories have moved beyond this triadic-mechanism framework [e.g. see “vulnerabilities in decision making”17 as an example], and even less empirical work has been done using a multi-domain data-driven approach [e.g., see “An Integrated Multimodal Model of Alcohol Use Disorder”18 as an example]. However, separate empirical investigations strongly suggest the involvement of a myriad of different factors.
Individual risk factors that have been shown to predict high likelihood of cannabis abuse and dependence include sex/gender19, general cognitive ability [IQ/working memory20,21,22], childhood mental health disorders [(depression, externalizing/conduct disorder)19,23,24,25,26,27,28], trauma history26,29,30 and stressful life events/low socioeconomic status23. Cannabis users have further been characterized to have personality traits of high openness/extraversion and low agreeableness/conscientiousness, while neuroticism has not been linked to cannabis abuse31,32,33. Increased openness in particular appears to discriminate cannabis users from other drug users33. The triadic neurobiological models of cannabis addiction are supported by evidence on increased reward/approach-related behavior [e.g., increased sensation seeking34 & delay discounting35,36], a role of increased negative affect [e.g. increased prevalence of depression2,19,23] and deficits in executive function, specifically deficits in memory/working memory performance and processing speed deficits that predict risk for chronic cannabis use20,21,22,37,38. Neuroimaging studies corroborate these theories by demonstrating an upregulation of brain regions involved in reward/approach-related behavior [e.g., salience/reward network16,39] and structural changes in valuation networks [e.g., orbitofrontal cortex40,41], as well as changes in brain structures supporting memory function [e.g., reduced hippocampal volume40; altered memory network function39]. Finally, reduced educational attainment and lower socioeconomic status have been shown to co-occur with chronic cannabis use42,43,44. Specifically, longitudinal studies have concluded that common risk factors [e.g., lack of support in family/peer/school environment45 and mental health issues43] cause both substance use and lower educational attainment/socioeconomic status.
Although sex/gender differences in use patterns in CUD are increasingly well established, it is unclear which neurobiological, individual-level (e.g., personality, cognitive) and environmental mechanisms drive these differences. Preclinical models of cannabis use and dependence suggest that neurobiological factors may contribute to these sex/gender differences. Female rodents metabolize ∆9-tetrahydrocannabinol (THC) at a faster rate than males46,47. Behaviorally, female rodents also demonstrate more cannabis withdrawal symptoms48, higher rates of cannabinoid reinstatement after abstinence49, and higher rates of self-administration relative to males50. Further, while sex/gender differences have not been studied comprehensively in adults to date9, a machine-learning analysis of the predictors of initiation of cannabis use in adolescence found distinct neurobiological, individual-level and environmental risk factor profiles in boys versus girls10. Specifically, individual level factors such as sensation/novelty seeking were predictive of cannabis use onset in boys, whereas factors that are more closely linked to the environment, such as verbal IQ, sexual relationships and parent personality, were predictive in girls10. Finally, gendered environmental experiences may also influence CUD. For example, women with substance use disorders are more likely to experience a lack of social support and increased isolation relative to men9,11. The endocannabinoid system is essential in regulating stress51,52. Stressful environmental factors (e.g., lack of social support) may contribute to cannabis use and dependence in a sex/gender-specific way through altered endocannabinoid signaling. Therefore, in this study, we comprehensively examine sex/gender differences in the relative contribution of neurobiological, individual, and environmental risk factors to high cannabis use levels and CUD to fill this gap in the literature.
To evaluate the relative importance of a wide variety of factors associated with high cannabis use levels and cannabis dependence as well as potential sex/gender differences in a well-described community sample (HCP39; N = 1204), we employed state-of-the-art machine learning methods [XGBoost (eXtreme Gradient Boosting)53, a tree-based ensemble machine learning algorithm] in combination with a ranking tool [SHapley’s Additive exPlanations (SHAP)12] to assign relative importance (i.e., SHAP values) to each of the associated factors. Decision and boosted tree-based machine learning methods are powerful tools for identifying associated factors in psychiatric research due to their non-parametric nature (resilience to non-normal data distributions) and their tolerance for multicollinear and missing data54. However, when used on their own, it is difficult to interpret the relative importance of each of the factors involved. We therefore employed SHAP, an extension of methodology originally developed for consistent credit attribution in cooperative game theory55, to provide a reliable and consistent ranking of the unique relative importance of each factor12. In addition to providing a ranking for the unique and additive importance of all identified factors, SHAP allows for examining interactions between factors in a model56, such as sex/gender-related interactions. In summary, the current study is an exploratory, data-driven analysis that leverages state-of-the-art machine learning algorithms to model the complex factors underlying chronic cannabis use and their relative importance by sex/gender.
Methods
Participants
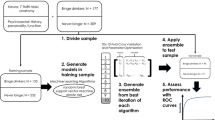
We analyzed data from the final HCP data release [N = 1204, aged 22–35, 54% female; https://db.humanconnectome.org/data/projects/HCP_1200; HCP preprocessing pipeline (4.1)]. The data was collected in 2012–2015 at Washington University in St. Louis, Missouri, United States. All subject recruitment procedures and informed consent forms, including consent to share de-identified data, were approved by the Washington University Institutional Review Board (IRB) in accordance with the Declaration of Helsinki. For the present study, after permission was obtained from the HCP to use the Open Access and Restricted Access data for the present study (see Data Availability Statement below), a protocol filed with the University of Minnesota Institutional Review Board (IRB) met criteria for exemption. In this community sample, 9% of participants met the DSM-IV criteria for cannabis dependence (n = 109, 26% female; note that cannabis abuse was not assessed). The HCP study sample had a similar racial and socioeconomic status distribution as reported in the 2010 United States Census (Census United States 2010: 72% White, 13% Black/African–American, 6% Asian/Nat. Hawaiian/ Other Pacific Islander, 9% other; median income (25–34 year olds) = $49,445; mean education years (25–34 year olds) = 13.8 years). See Table 1 for detailed demographic information. See Supplementary Fig. 1 for an overview of the analysis flow.
Outcome variables
Our primary outcome measures of interest were (1) lifetime level of cannabis use and (2) lifetime diagnosis of cannabis dependence, which were assessed using a structured interview (the Semi-Structured Assessment for the Genetics of Alcoholism [SSAGA]57). Level of cannabis use was assessed by the reported number of lifetime uses (categories: 0, 1–5, 6–10, 11–100, 101–999, 1000 + lifetime uses). For our analysis, we merged two categories, such that we had five different levels of cannabis use on a logarithmic scale (0, 1 + , 10 + . 100 + , 1000 + lifetime uses). Classification analyses were conducted for each outcome respectively, i.e., we classified escalation of cannabis use and dependence (1 + uses, 10 + uses, 100 + uses, 1000 + uses, and DSM-IV dependence). Each analysis classified a binary outcome using the entire sample; that is, we classified individuals who used cannabis 1 + times from those who did not, classified individuals who used cannabis 10 + times from those who used cannabis < 10 times, and so on. The smallest number of cases for considering sex/gender interaction effects were hence found in the 1000 + model (cases: N = 31 women, N = 77 men), and in the model with cannabis dependence diagnosis as an outcome (cases: N = 28 women, N = 81 men).
Phenotypic models
The HCP dataset contains a wide array of self-report, diagnostic and behavioral measures assessing domains of cognition, emotion, social function, psychiatric dysfunction, and personality58. To examine as broad a phenotypic space as possible, this study used all available behavioral, self-report, and interview-based measures in the HCP database (including all in-scanner task behavior variables). We generally included both summary scores and subscale/item-level scores, because the machine learning method we used (detailed below) explicitly allows for correlated factors during model fitting53. This allows for a direct comparison of the contribution of summary scores versus subscale/item-level scores to the classification. For a complete list of all included phenotypic variables (273 in total), see Supplementary Table 1.
Freesurfer (structural MRI) models
For our structural Magnetic Resonance Imaging (MRI) or “Freesurfer” model, we used the Freesurfer data provided by HCP59,60. These summary data included Freesurfer-generated volume estimates for 44 regions and surface area and cortical thickness estimates for 68 regions. We did not correct these measures for total brain volume, to avoid introducing artificial sex/gender differences due to overcorrection61, but did include 19 summary measures including total gray matter volume, white matter volume, and brain segmentation volume as additional factors in the model (199 factors total).
Resting-state global and local efficiency models
We used the resting-state functional MRI (rsfMRI) data as preprocessed by HCP59 in the volumetric data format. Using the Brain Connectivity Toolbox48, we conducted a graph theory analysis to extract measures of nodal global and local efficiency [connectivity of a brain region with the rest of the network (global) or with the network within a small neighborhood (local)] from 638 similarly sized brain regions [whole-brain, excluding cerebellum;62,63 sub-parcellation of the Automated Anatomical Labeling atlas (AAL)64]. For each participant, a 638-by-638 matrix of Fisher’s z-transformed Pearson correlations was computed, representing the normalized bivariate correlation of each brain region with each other region. This correlation matrix was binarized at a proportional cost (to improve stability of measures over absolute thresholds)65 of 0.15 (which is in the middle of the optimal range of 0.01–0.30)66, to represent the strongest 15% of positive connections. We characterized the intrinsic properties of the obtained connectivity graphs by computing nodal global and local efficiency for all 638 brain regions67, and then averaging both graph theory measures within each larger AAL region (90 factors).
Resting-state network connectivity models
We used the resting-state grayordinate (CIFTI) functional data provided by HCP, to compute within and between functional connectivity for a set of brain networks68,69,70,71. We first parcellated the whole brain into 718 parcels using the Cole-Anticevic parcellation72,73. We calculated the pairwise Pearson correlations between each pair of parcels in the brain, normalized the obtained correlations using Fisher’s z-transform, and averaged the parcel-to-parcel correlation values both within and between networks (78 factors in total).
Task fMRI models
All task fMRI (tfMRI) data were preprocessed by HCP using the same steps as for the rsfMRI data59. We used the provided task fMRI task activation Contrast Of Parameter Estimates (COPE) maps (generated by FSL’s FEAT) that were acquired during seven behavioral tasks, described in58. These tasks included (1) an N-Back task, (2) a gambling task, (3) a motor mapping task, (4) a language-math task, (5) a social cognition task, (6) a relational-processing task, and (7) an emotion-processing task. We selected 12 COPE maps that represented the main task effects of interest for each task: (1) N-Back task: 2back-0back contrast, (2) gambling task: response to punishments and rewards, (3) motor mapping task: response to left/right foot, left/right hand and tongue movements, (4) language-math task: story-math contrast, (5) social cognition task: social-random contrast, (6) relational-processing task: relational-match contrast, and (7) emotion-processing task: negative faces-shapes contrast. To define activation clusters, we employed the cifti-find-clusters command in Connectome Workbench v1.4.2 (https://www.humanconnectome.org/software/get-connectome-workbench) to find clusters of significantly activated voxels for each of the selected contrast maps, using the full sample (N = 889 with task fMRI). We chose a cutoff of Cohen’s d > 0.8 to select only clusters with large effect sizes and reduce the number of factors entering our final model. Then, for individual participants, we extracted the mean beta weight within each cluster of selected voxels. The task fMRI model contained 448 factors. For a complete list of all included fMRI task contrasts (12 in total), see Supplementary Table 2.
Classification analysis using gradient tree boosting
To classify each outcome variable of interest, we used a nonparametric classification approach called gradient tree boosting. Gradient tree boosting machines are fit to the gradient of the loss function at every iteration, building up a series of simple models using gradient descent in function space. Specifically, we used the recently developed XGBoost53, a fast and scalable state-of-the-art gradient tree boosting system. We chose gradient tree boosting because this class of methods is stable and requires a much smaller sample size to produce reliable effect estimates74, compared to previous methods such as support vector machines (SVM)75. Specifically, simulations demonstrated that XGBoost was able to achieve a prediction accuracy of 0.90, detecting the top 27 relevant features out of ~ 2000 features reliably in a biological benchmarking dataset (N = 865) with as little as N = 20 for the training sample74. Comparative simulations using the identical benchmarking dataset further demonstrated a ~ 12-fold reduction in the needed training sample size with XGBoost as compared to SVM (e.g. with XGBoost N = 20 achieves > 0.90 accuracy, while N = 250 with SVM)74,75. Also, while class imbalance has been shown to lower the performance of XGBoost, comparative simulations demonstrated that performance was acceptable up to a 17:1 ratio for class imbalance in the population76. Another advantage of XGBoost is its ability to deal with the presence of missing values in the data through sparsity-aware split finding, capturing trends in missing values by the model53. It is therefore not necessary to use an imputation for missing values53. Finally, the feature ranking tool that we applied (see for details below) had been initially applied to XGBoost, which outperformed other machine learning models such as SVM, Lasso penalized linear logistic regression, or an unsupervised Parzen window method77.
Nested k-fold cross-validation was used to tune hyperparameters (inner loop) and evaluate classification performance (outer loop), generating an unbiased estimate of the model performance78. We used k = 5, therefore evaluating 5 models using an 80–20 train-test split in both inner and outer loops. Bentéjac and colleagues79 performed a comprehensive evaluation of parametrization tuning for XGBoost. They compared the XGBoost default parameter values with different tuning approaches and concluded that tuned models performed significantly better79. They then proposed new (optimized) default values for (a) learning rate [suggested values: 0.05, 0.1], (b) maximum tree depth [suggested value: 100 (unlimited)], and (c) subsampling [suggested value: 0.75]79. These proposed values are conservative (reducing the risk of model overfitting) for learning rate and subsampling, but non-conservative for maximum tree depth. We therefore chose to center our grid search around their proposed values for learning rate and subsampling, but used more conservative (smaller) values for maximum tree depth than proposed. Overall, we hence chose a conservative approach, aimed at preventing model overfitting. We considered the Cartesian product of the following hyperparameters: learning rate = {0.01, 0.02, 0.05, 0.1, 0.2}, max tree depth = {4, 6, 8, 10, 12}, and subsampling size = {0.6, 0.8, 1}. During the inner loop of the nested cross-validation, we conducted a grid search to determine the best combination of the above hyperparameters. The performance of the best model selected from the inner loop was evaluated in the outer loop, resulting in 5 performance estimates. The overall best performing set of hyperparameters for each outcome is reported in the Supplementary Table 3. We additionally used an early stopping parameter of 30 rounds, thus preventing overfitting when the model loss function fails to improve (therefore number of trees was not included in the hyperparameter grid). Since the HCP dataset contains many related participants, our cross-validation scheme always assigned family members to the same group (train or test) for every fold, therefore ensuring that test performance was not inflated by allowing the model to be trained and then tested on a related subject.
We quantified the performance of each model by using the Area Under the Curve of the Receiver Operating Characteristic Curve (AUC-ROCC), which describes how well the model can distinguish between classes. The AUC-ROCC ranges from 0 to 1; higher AUC-ROCCs indicate better predictive performance. An AUC-ROCC of 0.5 indicates random prediction for a binary outcome.
Factor importance ranking using SHapley Additive exPlanations
Advanced machine learning methods such as gradient boosting machines are capable of making highly accurate predictions, but often these predictions come at the expense of interpretability. That is, traditional classification approaches do not allow for an interpretation of the relative importance of the factors involved, as they only evaluate the predictive performance of the entire model. To evaluate the unique relative importance of each model factor (referred to as “features” in machine learning research), we used SHAP (SHapley Additive exPlanations), proposed by12, as a feature ranking tool. SHAP provides an explanation model that computes the unique and additive importance of each model feature (predictive factor) in determining the final classification result. SHAP is based on the concept of Shapley Values, originally described in55 as a consistent method to allocate credit to a set of team members for a cooperative outcome. In this case, rather than the consortium consisting of a team of players working toward a common goal, the consortium consists of the set of features (factors) which work toward the common goal of producing the classification output of the model. The impact of each feature on the output of the model is defined as the change in model output when the feature is known, as opposed to unknown. Shapley values are the only currently available feature ranking tool that obeys a specific set of properties [local accuracy, consistency, and missingness12], which are considered desirable in explaining the output of a machine learning classification model. In combination with gradient-boosting machines such as XGBoost, this method is both robust to outliers and flexible77. An in-depth explanation of the properties of SHAP is beyond the scope of the current paper; for a full explanation of the properties of SHAP, the reasons these properties are desirable, and the equations used to derive the feature importance rankings, please see12 and56.
Using SHAP to investigate sex/gender effects in cannabis use and dependence
Critical to our current investigation, SHAP is also able to leverage the assumption of feature additivity to compute interaction effects between sets of two factors in the model56. SHAP values can provide a rich alternative to traditional partial dependence plots80. While partial dependence plots only allow for an interpretation of how the output of a model depends on the interaction between two factors, SHAP dependence plots allow for interpreting interaction effects while accounting for both lower- and higher-order interaction effects of all factors in the model. In this study, we leveraged this to investigate sex/gender differences in model factors, as sex/gender was a strong predictor of cannabis outcomes in all models.
Results
Classification performance
Cross-validated AUC-ROCCs of the six unimodal models we considered returned a wide range of performance indices (Fig. 1a). The phenotypic model had an average AUC-ROCC of 0.70 over all five outcome measures, and produced the best performance in classifying 1000 + cannabis uses (AUC-ROCC = 0.74). Of the brain models, the best performance was obtained by the Freesurfer (structural MRI) model (average AUC-ROCC = 0.58) and the global efficiency model (average AUC-ROCC = 0.57). The other brain models all performed similarly to each other, and were not considered further (AUC-ROCC range 0.52–0.53).

Area under the Curve of the Receiver Operating Characteristic Curve (AUC-ROCC) was used to quantify the classification performance of (a): Six unimodal models, and (b): Two additional multimodal models that combined the factors of the phenotypic model with the factors of the two best performing brain models. The phenotypic model performed better than any of the other unimodal models, and the inclusion of the two best sets of brain factors (Freesurfer & global efficiency) did not appreciably improve the performance of the phenotypic model. Error bars correspond to ± 1 Standard Error.
To determine if performance of the phenotypic model could be improved by adding factors from the most informative brain modalities, we then tested two bimodal models (phenotypic + Freesurfer, phenotypic + global efficiency; Fig. 1b). For both of the combined models, the average AUC-ROCC over all five outcomes was 0.71. The best performance of the combined models (phenotypic + Freesurfer, phenotypic + global efficiency) was obtained in classifying 1000 + cannabis uses (AUC-ROCC = 0.74 & 0.80, respectively). The results indicate that while the inclusion of brain data did not appreciably change the overall classification accuracy, specific brain factors (e.g. hippocampus volume, median rank = 4) were among the highest ranked predictors in these bimodal models.
SHAP factor importance ranking
To determine which factors drove the performance of the best performing classification models, we used SHAP to estimate the relative importance of all factors (e.g., see the factors contributing to dependence in Fig. 2; see other models in Supplementary Figs. 2–9). To determine which factors consistently classified increased cannabis use levels and dependence, we computed the median rank of each factor across all models (see Supplementary Table 4). The consistent highly ranked factors across models (median rank ≤ 20, the default cutoff for highly ranked features in SHAP models) included a broad range of factors, such as sex/gender, environmental factors (income, education level), personality measures (openness), mental health measures (externalizing, childhood conduct disorder, aggression), neurocognitive measures (working memory, verbal IQ) and brain measures (hippocampal, brainstem and CSF volume; frontal pole thickness; insula, operculum and occipital resting-state connectivity) (Supplementary Table 4).

SHAP ranking for factors contributing to the two bimodal models (a: phenotypic + Freesurfer, b: phenotypic + global efficiency) classifying cannabis dependence. Higher positive SHAP values on the x-axis indicate that the observed factor pushed the classification closer towards cannabis dependence, whereas more negative SHAP values indicate that the factor pushed the classification away from cannabis dependence. Factors are ranked in order of the average (absolute) SHAP value, which indicates the importance of a factor. Individual data points (dots) represent the model output for each individual in the sample. The position of a dot on the x-axis represents the impact of the observed factor on the model output for the individual. The color of the individual dots represent the value of the observed measurements, with blue indicating lower and red higher values (e.g. red indicates high openness or high education level in these plots). As an example, in both plots high (red dots) observed “Openness to Experience” and low (blue dots) education levels pushed the model prediction closer towards cannabis dependence. That is, high “Openness to Experience” and lower education levels make it more likely that the model would categorize a given individual as cannabis-dependent relative to not dependent.
SHAP sex/gender interaction analysis
Since sex/gender was a top ranked factor (ranked 4th across all phenotypic + Freesurfer and phenotypic + Global models, Supplementary Table 4), we examined interaction effects to identify sex/gender-specific factors that contribute to classifying cannabis dependence. We focused on the models predicting cannabis dependence and use levels of 1000 + lifetime uses as the most clinically relevant outcomes. We report all interaction effects with a SHAP interaction value of at least 0.1 (the sum of all SHAP values per model is 1), in order to discuss only interaction effects with meaningful effect sizes. When comparing effect sizes, we considered values <|0.1| as small, <|0.3| as moderate, <|0.5| as large and >|0.5| as very large effect sizes.
SHAP sex/gender interactions in models predicting cannabis dependence
The bimodal models (phenotypic + Freesurfer; phenotypic + global) classifying cannabis dependence indicated sex/gender interaction effects for environmental factors (education level), personality measures (openness), mental health factors (childhood conduct disorder, fear somaticism), neurocognitive measures (delay discounting, working memory) and brain measures (hippocampal volume, postcentral thickness, superior temporal area) (Figs. 3, 4). Men as compared to women were more often classified as cannabis-dependent based on personality (high openness), mental health (high childhood conduct disorder, high fear somaticism), neurocognitive (impulsive delay discounting, slow working memory performance) and brain factors (low hippocampal volume, high postcentral thickness). In contrast, women were more often classified as dependent based on environmental (lower education level) and brain factors (smaller superior temporal area). Effect sizes for the main effects were often very large ( >|0.5|) for behavioral effects, and large ( >|0.3|) for brain effects (see Figs. 3, 4: column “main effects present”), while the sex/gender interaction effects had small to moderate effect sizes (Figs. 3, 4: column “main effects removed”). Overall, the direction of effects was therefore the same in men and women, but the sex/gender interaction effects indicated that the observed effects were much stronger in either men or women.

Several factors in the phenotypic + Freesurfer model classifying cannabis dependence showed sex/gender interaction effects. As in previous figures, each dot indicates an individual. Dots are colored according to sex/gender (red = women, blue = men). The left columns (“Dependence plots”) show individuals colored according to sex/gender, with main effects intact; the right columns (“Interaction plots”) again show the same individuals, but with main effects removed for improved visualization of the sex/gender interaction effects. The x-axis of the plots indicates the observed measurement value of each factor, and the y-axis of each plot indicates the SHAP value (where a higher SHAP value pushed the model closer towards dependence, and lower values pushed the model away from dependence). The magnitude of the SHAP values are standardized in the model and can therefore be interpreted as effect sizes.
SHAP sex/gender interactions in models predicting heavy cannabis use
The 1000 + lifetime uses model demonstrated sex/gender interaction effects for environmental factors (instrumental support), personality measures (openness), mental health factors (externalizing) and brain measures (precentral efficiency) (see Fig. 4 for sex/gender interactions in the phenotypic + global model; the phenotyopic + Freesurfer model showed no sex/gender interaction effects > 0.1 ). Men as compared to women were more often classified as heavy cannabis users (+ 1000 uses) based on personality (high openness), mental health (high externalizing) and brain factors (low global efficiency of the precentral cortex). In contrast, women were more often classified as heavy cannabis users based on environmental factors (low instrumental support). Similarly as in the Cannabis Dependence models, the sex/gender interaction effects did not influence the directions of the effects but rather modulated the effect sizes such that the observed effects were much stronger in either men or women.

Several factors in the phenotypic + Global Efficiency model classifying cannabis dependence (left) and classifying heavy cannabis use (1000 + uses; right) showed sex/gender interaction effects. As in previous figures, each dot indicates an individual. Dots are colored according to sex/gender (red = women, blue = men). The left columns (“Dependence plots”) show individuals colored according to sex/gender, with main effects intact; the right columns (“Interaction plots”) again show the same individuals, but with main effects removed for improved visualization of sex/gender interaction effects. The x-axis of the plots indicates the observed measurement value of each factor, and the y-axis of each plot indicates the SHAP value (where a higher SHAP value pushed the model closer towards dependence, and lower values pushed the model away from dependence). The magnitude of the SHAP values are standardized in the model and can therefore be interpreted as effect sizes.
Discussion
The current study used a machine learning approach to describe the complex factors underlying high cannabis use levels and dependence and their relative importance by sex/gender in a community sample of young adults in the United States. While a number of recent reviews have recognized the potential for machine learning methods in psychiatric research81,82,83,84,85,86, this is the first study to date to use such an approach in adults with CUD, although machine learning methods have been applied to examine adolescent cannabis use10. Therefore, it is also the first study to date to comprehensively study sex/gender differences in CUD in adults. Since conventional machine learning methods obtain increased predictive power at the cost of interpretability77,83,87, we paired our classification models [(XGBoost)53] with Shapley Additive eXplanations [(SHAP)12] to generate “explainable” machine learning models. This enables the ranking of factors (or “features”) according to their unique and additive importance in classifying an outcome.
Overall, the classification models achieved high accuracy, which in itself was remarkable since the used dataset was not designed to assess substance use and dependence [see Rawls and colleagues18 for a more in-depth discussion of the assessments and how they relate to addiction]. The current results further confirmed that a small number of factors, of the more than one thousand included in the analyses, consistently provided a unique and additive contribution to the classification performance, beyond other factors in the model. The identified factors included environmental, personality, mental health, neurocognitive and brain measures, demonstrating the complexity of the factors involved in CUD. Overall, the current results confirm the importance of multi-domain investigations into the factors underlying drug addiction, as in our previous empirical investigation of multi-domain factors in substance use disorders18.
Many factors that have been well described in the literature on CUD were replicated in this study, though we demonstrated here systematic sex/gender interaction effects for many factors for the first time. The environmental factors that most consistently contributed highly to model classification performance were income and education level. Previous longitudinal research further suggests that reduced educational attainment and lower socioeconomic status co-occur with (but do not directly cause) chronic cannabis abuse and dependence42,43,44,45. These current results further replicate previous work that has linked the personality trait openness to high cannabis use levels and dependence, suggesting that high openness is a predictor specifically for cannabis as a primary drug of choice31,32,33. Additionally, the current results also confirm an important role of externalizing mental health disorders, aggression, and a history of child conduct disorder, which have all been identified as risk factors for cannabis abuse and dependence in longitudinal research24,25,26,27,28. Notably, while our results provide additional support for an important role of externalizing disorders [e.g.26,27,28], we could not confirm a link between cannabis abuse or dependence and internalizing disorders, as had been reported by some other studies [e.g.19,23]. Further, in the current study, working memory and verbal IQ measures were among the most highly ranked neurocognitive factors, both of which have consistently been associated with CUD and shown to be risk factors for (not consequences of) cannabis abuse and dependence20,21,22,37,38. Finally, brain measures that were consistently highly ranked included hippocampal volume, an important structure of the brain’s memory system39,88,89, as well as brainstem volume, frontal pole thickness, insula, operculum and occipital resting-state connectivity, all of which are part of the reward, salience and visual brain networks that are most densely innervated by dopaminergic receptors90. These results converge with previous studies and systematic reviews that have demonstrated that CUD is characterized by changes in the brain’s memory system39,40,91, the reward and salience networks39,41, and the occipital lobe92,93. These results also demonstrate changes in the brain’s reward/approach-related system, a domain that was not captured well by the behavioral assessments or neuroimaging tasks used in this study [see Rawls and colleagues18 for a more in-depth discussion]. Thus, the current evidence supports the triadic models of cannabis addiction by indicating changes in the brain’s reward/approach system, deficits in executive function, specifically in working memory function and verbal IQ, and a role of negative affect, specifically of externalizing symptoms and aggression.
The analysis of sex/gender interaction effects revealed complex sex/gender differences in the multi-domain factors underlying cannabis abuse and dependence. Environmental factors such as educational attainment and instrumental support (the latter was not among the highest ranked factors overall) were factors that primarily contributed to model prediction accuracy in women. In stark contrast to this finding, ‘classic’ personality, mental health, and neurocognitive factors that have often been linked to chronic cannabis use and dependence in previous studies were primarily driving effects in men. In particular, the ‘male-dominated’ factors included the personality trait openness, a history of conduct disorder, externalizing symptoms, and working memory performance. For brain factors, there were both ‘female-dominated’ factors, such as a smaller right superior temporal area (which was not among the highest ranked overall factors), and ‘male-dominated’ factors, such as low hippocampal volume, higher postcentral thickness and lower global efficiency of the precentral gyrus in the somatosensory-motor system. A smaller right superior temporal regions, the ‘female-dominated’ brain factor, has been previously observed in adolescent cannabis users94, and is assumed to underlie social perception95, consistent with the greater importance of environmental factors such as social support in women. Reduced hippocampal volume, a ‘male-dominated’ brain factor, is probably the most commonly reported brain structural abnormality in CUD96, and may be linked to ‘male-dominated’ impaired working memory performance97. Increased postcentral cortical thickness, another ‘male-dominated’ brain factor, has been shown to correlate with earlier age of onset of cannabis use in young adults98, and may be a marker of altered somatosensory processing as a consequence of cannabis use99. Finally, abnormalities in precentral gyrus function, the third ‘male-dominated’ brain factor that we identified, has been previously observed in young adults with cannabis use98,100, and are assumed to play a role in response inhibition of motor impulses (e.g. lack of self-regulation as evidenced by increased externalizing symptoms in men)98. Taken together, these results suggest that environmental factors (educational attainment, instrumental support) and their associated brain correlates play a larger role in women, and the ‘classic’ individual factors that have been most often linked to cannabis addiction and their associated brain correlates, contribute more strongly to CUD in men.
A limitation of the current study is the relatively small number of women included in some of the models. However, the current results provide compelling initial evidence for sex/gender differences in the multifactorial factors underlying CUD in adults, which had not been previously investigated using a multi-domain approach. Strikingly, these results closely mirror previous findings from a machine learning analysis that investigated predictors of onset of cannabis use in adolescence. Spechler and colleagues (2019) found that individual level factors such as sensation/novelty seeking were predictive of cannabis use onset in boys, whereas factors that are more closely linked to the environment, such as verbal IQ, sexual relationships and parent personality, were predictive in girls10. These findings also fit with our recent review and empirical data demonstrating a much greater importance of social support as a protective factor preventing the escalation of alcohol use in adolescence and maintenance of alcohol misuse in adulthood particularly in girls and women, as compared to boys and men101. We are only aware of one previous study on sex/gender differences in CUD in adults102. This study specifically investigated sex/gender differences in the role of social support and found a stronger protective relationship of social support in women as compared to men102. Additionally, our results extend previous findings on cannabis use in adolescence that suggest a stronger influence of environmental factors in girls as compared to boys103,104,105,106. A twin study found that the overall contribution of environmental factors for predicting cannabis use levels, as compared to individual predictive factors, was larger in adolescent girls versus boys103. Similarly, a longitudinal study described that environmental influences such as attending public (versus private) schools, academic performance, living in a single-parent family, spending time in bars/discos and drug use among friends had a stronger influence on cannabis use levels in adolescent girls as compared to boys104. The same study found that individual factors such as prior history of smoking/alcohol consumption and antisocial behavior were stronger predictors in adolescent boys104. Furthermore, one study demonstrated that a protective family environment had a stronger influence on cannabis use onset in adolescent girls as compared to boys105, and that higher life satisfaction was a stronger protective factor against frequent cannabis use among adolescent girls than boys106. Overall, the resemblance of the general pattern of a stronger influence of environmental versus individual factors in girls and women is striking and warrants further investigation.
Conclusion
Our data-driven investigation of the factors linked to CUD in young adults in the United States revealed a small number of environmental, personality, mental health, neurocognitive and brain factors that were consistently linked to high cannabis use levels and dependence. The importance of these factors in classifying high use levels and dependence varied by sex/gender. Environmental factors contributed more strongly to CUD in women, whereas individual factors, such as personality, mental health and neurocognitive factors, had a larger importance in men. The current findings therefore warrant further investigations into sex/gender differences in young adults with CUD, and suggest the importance of understanding how these differences may inform the development of sex/gender-specific treatment approaches for addiction medicine.
Data availability
All data used in the present study are available for download from the Human Connectome Project (www.humanconnectome.org). Users must agree to data use terms for the HCP before being allowed access to the data and ConnectomeDB, details are provided at https://www.humanconnectome.org/study/hcp-young-adult/data-use-terms. The HCP has implemented a two-tiered plan for data sharing, with different provisions for handling Open Access data and Restricted data (e.g., data related to substance use). See https://www.humanconnectome.org/study/hcp-young-adult/document/restricted-data-usage for more details. Users must also consult with their local IRB or Ethics Committee (EC) before utilizing the HCP data to ensure that IRB or EC approval is not needed before beginning research with the HCP data. If needed, and upon request, the HCP will provide a certificate to users confirming acceptance of the HCP Open and Restricted Access Data Use Terms. See https://www.humanconnectome.org/study/hcp-young-adult/data-use-terms.
Code availability
The code for preprocessing the data and all computational models are available on https://github.com/explainable-cannabis/explainable-cannabis-paper.
References
SAMSHA. Key Substance Use and Mental Health Indicators in the United States: Results from the 2018 National Survey on Drug Use and Health 82 (2018).
Hasin, D. S. et al. Prevalence of marijuana use disorders in the United States between 2001–2002 and 2012–2013. JAMA Psychiat. 72(12), 1235–1242 (2015).
Chapman, C. et al. Evidence for sex convergence in prevalence of cannabis use: A systematic review and meta-regression. J. Stud. Alcohol Drugs. 78(3), 344–352 (2017).
Nia, A. B., Mann, C., Kaur, H. & Ranganathan, M. Cannabis use: Neurobiological, behavioral, and sex/gender considerations. Curr. Behav. Neurosci. Rep. 5(4), 271–280 (2018).
Substance Abuse and Mental Health Services Administration. Results from the 2006 National Survey on Drug Use and Health: National Findings 282 (2007).
Center for Behavioral Health Statistics and Quality. 2017 National Survey on Drug Use and Health: Detailed Tables 2871 (Substance Abuse and Mental Health Services Administration, 2017).
Khan, S. S. et al. Gender differences in cannabis use disorders: Results from the national epidemiologic survey of alcohol and related conditions. Drug Alcohol Depend. 130, 101–108 (2013).
Hernandez-Avila, C. A., Rounsaville, B. J. & Kranzler, H. R. Opioid-, cannabis- and alcohol-dependent women show more rapid progression to substance abuse treatment. Drug Alcohol Depend. 74(3), 265–272 (2004).
Greaves, L. & Hemsing, N. Sex and gender interactions on the use and impact of recreational cannabis. Int. J. Environ. Res. Public Health. 17(2), E509 (2020).
Spechler, P. A. et al. The initiation of cannabis use in adolescence is predicted by sex-specific psychosocial and neurobiological features. Eur. J. Neurosci. 50(3), 2346–2356 (2019).
Becker, J. B., McClellan, M. L. & Reed, B. G. Sex differences, gender and addiction. J. Neurosci. Res. 95(1–2), 136–147 (2017).
Lundberg, S. M. & Lee, S. I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 30, 4765–4774 (2017).
Koob, G. F. & Volkow, N. D. Neurobiology of addiction: A neurocircuitry analysis. Lancet Psychiatry 3(8), 760–773 (2016).
Bickel, W. K. et al. 21st century neurobehavioral theories of decision making in addiction: Review and evaluation. Pharmacol. Biochem. Behav. 164, 4–21 (2018).
Yücel, M. et al. A transdiagnostic dimensional approach towards a neuropsychological assessment for addiction: An international Delphi consensus study. Addiction 114(6), 1095–1109 (2019).
Zilverstand, A. & Goldstein, R. Z. Chapter 3—Dual models of drug addiction: the impaired response inhibition and salience attribution model. In Cognition and Addiction (ed. Verdejo-Garcia, A.) 17–23 (Academic Press, 2020).
Redish, A. D., Jensen, S. & Johnson, A. A unified framework for addiction: Vulnerabilities in the decision process. Behav. Brain Sci. 31(4), 415–487 (2008).
Rawls, E., Kummerfeld, E. & Zilverstand, A. An integrated multimodal model of alcohol use disorder generated by data-driven causal discovery analysis. Commun. Biol. 4(1), 1–12 (2021).
Meier, M. H. et al. Which adolescents develop persistent substance dependence in adulthood? Using population-representative longitudinal data to inform universal risk assessment. Psychol. Med. 46(4), 877–889 (2016).
Khurana, A., Romer, D., Betancourt, L. M. & Hurt, H. Working memory ability and early drug use progression as predictors of adolescent substance use disorders. Addict. Abingt. Engl. 112(7), 1220–1228 (2017).
Wilson, S., Malone, S. M., Venables, N. C., McGue, M. & Iacono, W. G. Multimodal indicators of risk for and consequences of substance use disorders: Executive functions and trait disconstraint assessed from preadolescence into early adulthood. Int. J. Psychophysiol. Off. J. Int. Organ. Psychophysiol. https://doi.org/10.1016/j.ijpsycho.2019.12.007 (2019).
Meier, M. H. et al. Associations between adolescent cannabis use and neuropsychological decline: A longitudinal co-twin control study. Addict. Abingt. Engl. 113(2), 257–265 (2018).
Schlossarek, S., Kempkensteffen, J., Reimer, J. & Verthein, U. Psychosocial determinants of cannabis dependence: A systematic review of the literature. Eur. Addict. Res. 22(3), 131–144 (2016).
Defoe, I. N., Khurana, A., Betancourt, L., Hurt, H. & Romer, D. Disentangling longitudinal relations between youth cannabis use, peer cannabis use, and conduct problems: Developmental cascading links to cannabis use disorder. Addiction 114(3), 485–493 (2019).
Pingault, J. B. et al. Childhood trajectories of inattention, hyperactivity and oppositional behaviors and prediction of substance abuse/dependence: A 15-year longitudinal population-based study. Mol. Psychiatry. 18(7), 806–812 (2013).
Oshri, A., Rogosch, F. A., Burnette, M. L. & Cicchetti, D. Developmental pathways to adolescent cannabis abuse and dependence: Child maltreatment, emerging personality, and internalizing versus externalizing psychopathology. Psychol. Addict. Behav. 25(4), 634–644 (2011).
Griffith-Lendering, M. F. H., Huijbregts, S. C. J., Mooijaart, A., Vollebergh, W. A. M. & Swaab, H. Cannabis use and development of externalizing and internalizing behaviour problems in early adolescence: A TRAILS study. Drug Alcohol Depend. 116(1), 11–17 (2011).
Farmer, R. F. et al. Internalizing and externalizing psychopathology as predictors of cannabis use disorder onset during adolescence and early adulthood. Psychol. Addict. Behav. 29(3), 541 (2015).
Proctor, L. J. et al. Child maltreatment and age of alcohol and marijuana initiation in high-risk youth. Addict. Behav. 75, 64–69 (2017).
Mills, R., Kisely, S., Alati, R., Strathearn, L. & Najman, J. M. Child maltreatment and cannabis use in young adulthood: A birth cohort study. Addiction 112(3), 494–501 (2017).
Fridberg, D. J., Vollmer, J. M., O’Donnell, B. F. & Skosnik, P. D. Cannabis users differ from non-users on measures of personality and schizotypy. Psychiatry Res. 186(1), 46–52 (2011).
Ketcherside, A., Jeon-Slaughter, H., Baine, J. L. & Filbey, F. M. Discriminability of personality profiles in isolated and co-morbid marijuana and nicotine users. Psychiatry Res. 238, 356–362 (2016).
Terracciano, A., Löckenhoff, C. E., Crum, R. M., Bienvenu, O. J. & Costa, P. T. Five-Factor Model personality profiles of drug users. BMC Psychiatry 8(1), 22 (2008).
Creemers, H. E. et al. Predicting onset of cannabis use in early adolescence: The interrelation between high-intensity pleasure and disruptive behavior. The TRAILS Study. J. Stud. Alcohol Drugs. 70(6), 850–858 (2009).
Amlung, M., Vedelago, L., Acker, J., Balodis, I. & MacKillop, J. Steep delay discounting and addictive behavior: a meta-analysis of continuous associations. Addict. Abingt. Engl. 112(1), 51–62 (2017).
Strickland, J. C., Lee, D. C., Vandrey, R. & Johnson, M. W. A systematic review and meta-analysis of delay discounting and cannabis use. Exp. Clin. Psychopharmacol. https://doi.org/10.1037/pha0000378 (2020).
Meier, M. H. et al. Persistent cannabis users show neuropsychological decline from childhood to midlife. Proc. Natl. Acad. Sci. 109(40), E2657–E2664 (2012).
Gonzalez, R., Pacheco-Colón, I., Duperrouzel, J. C. & Hawes, S. W. Does cannabis use cause declines in neuropsychological functioning? A review of longitudinal studies. J. Int. Neuropsychol. Soc. JINS 23(9–10), 893–902 (2017).
Zilverstand, A., Huang, A. S., Alia-Klein, N. & Goldstein, R. Z. Neuroimaging impaired response inhibition and salience attribution in human drug addiction: A systematic review. Neuron 98(5), 886–903 (2018).
Lorenzetti, V., Chye, Y., Silva, P., Solowij, N. & Roberts, C. A. Does regular cannabis use affect neuroanatomy? An updated systematic review and meta-analysis of structural neuroimaging studies. Eur. Arch. Psychiatry Clin. Neurosci. 269(1), 59–71 (2019).
Batalla, A. et al. Structural and functional imaging studies in chronic cannabis users: A systematic review of adolescent and adult findings. PLoS ONE 8(2), e55821 (2013).
Maggs, J. L. et al. Predicting young adult degree attainment by late adolescent marijuana use. J. Adolesc. Health Off. Publ. Soc. Adolesc. Med. 57(2), 205–211 (2015).
Danielsson, A. K., Falkstedt, D., Hemmingsson, T., Allebeck, P. & Agardh, E. Cannabis use among Swedish men in adolescence and the risk of adverse life course outcomes: Results from a 20 year-follow-up study. Addict. Abingt. Engl. 110(11), 1794–1802 (2015).
Green, K. M., Doherty, E. E. & Ensminger, M. E. Long-term consequences of adolescent cannabis use: Examining intermediary processes. Am. J. Drug Alcohol Abuse. 43(5), 567–575 (2017).
Verweij, K. J. H., Huizink, A. C., Agrawal, A., Martin, N. G. & Lynskey, M. T. Is the relationship between early-onset cannabis use and educational attainment causal or due to common liability?. Drug Alcohol Depend. 133(2), 580–586 (2013).
Wiley, J. L. & Burston, J. J. Sex differences in Δ9-tetrahydrocannabinol metabolism and in vivo pharmacology following acute and repeated dosing in adolescent rats. Neurosci. Lett. 576, 51–55 (2014).
Narimatsu, S., Watanabe, K., Yamamoto, I. & Yoshimura, H. Sex difference in the oxidative metabolism of delta 9-tetrahydrocannabinol in the rat. Biochem. Pharmacol. 41(8), 1187–1194 (1991).
Harte-Hargrove, L. C. & Dow-Edwards, D. L. Withdrawal from THC during adolescence: Sex differences in locomotor activity and anxiety. Behav. Brain Res. 231(1), 48–59 (2012).
Fattore, L., Spano, M., Altea, S., Fadda, P. & Fratta, W. Drug- and cue-induced reinstatement of cannabinoid-seeking behaviour in male and female rats: Influence of ovarian hormones. Br. J. Pharmacol. 160(3), 724–735 (2010).
Fattore, L. et al. Cannabinoid self-administration in rats: Sex differences and the influence of ovarian function. Br. J. Pharmacol. 152(5), 795–804 (2007).
Hill, M. N. et al. Endogenous cannabinoid signaling is essential for stress adaptation. Proc. Natl. Acad. Sci. U.S.A. 107(20), 9406–9411 (2010).
Hillard, C. J., Beatka, M. & Sarvaideo, J. Endocannabinoid signaling and the hypothalamic-pituitary-adrenal axis. Compr. Physiol. 7(1), 1–15 (2016).
Chen, T. & Guestrin, C. XGBoost: A scalable tree boosting system, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery, 785–794 (2016) [cited 2020 Sept 8]. (KDD ’16). https://doi.org/10.1145/2939672.2939785
Song, Y. Y. & Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry. 27(2), 130–135 (2015).
Shapley, L. S. A value for N-person games. In Contributions to the Theory of Games 2nd edn (ed. Kuhn, H. W.) 307–317 (Princeton University Press, 1953).
Lundberg SM, Erion GG, Lee SI. Consistent Individualized Feature Attribution for Tree Ensembles. arXiv (2019).
Hesselbrock, M., Easton, C., Bucholz, K. K., Schuckit, M. & Hesselbrock, V. A validity study of the SSAGA-a comparison with the SCAN. Addiction 94(9), 1361–1370 (1999).
Barch, D. M. et al. Function in the human connectome: Task-fMRI and individual differences in behavior. Neuroimage 80, 169–189 (2013).
Glasser, M. F. et al. The minimal preprocessing pipelines for the Human Connectome Project. Neuroimage 80, 105–124 (2013).
Uğurbil, K. et al. Pushing spatial and temporal resolution for functional and diffusion MRI in the Human Connectome Project. Neuroimage 80, 80–104 (2013).
Perlaki, G. et al. Are there any gender differences in the hippocampus volume after head-size correction? A volumetric and voxel-based morphometric study. Neurosci. Lett. 570, 119–123 (2014).
Zalesky, A., Fornito, A. & Bullmore, E. Network-based statistic: Identifying differences in brain networks. Neuroimage 53(4), 1197–1207 (2010).
Crossley, N. A. et al. Cognitive relevance of the community structure of the human brain functional coactivation network. Proc. Natl. Acad. Sci. 110(28), 11583–11588 (2013).
Tzourio-Mazoyer, N. et al. Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage 15(1), 273–289 (2002).
Garrison, K. A., Scheinost, D., Finn, E. S., Shen, X. & Constable, R. T. The (in)stability of functional brain network measures across thresholds. Neuroimage 118, 651–661 (2015).
Bullmore, E. & Bassett, D. S. Brain graphs: Graphical models of the human brain connectome. Annu. Rev. Clin. Psychol. 7, 113–140 (2011).
Achard, S. & Bullmore, E. Efficiency and cost of economical brain functional networks. PLOS Comput. Biol. 3(2), e17 (2007).
Hagler, D. J. et al. Image processing and analysis methods for the Adolescent Brain Cognitive Development Study. Neuroimage 202, 116091 (2019).
Mamah, D., Barch, D. M. & Repovš, G. Resting state functional connectivity of five neural networks in bipolar disorder and schizophrenia. J. Affect. Disord. 150(2), 601–609 (2013).
Repovš, G. & Barch, D. M. Working memory related brain network connectivity in individuals with schizophrenia and their siblings. Front. Hum. Neurosci. https://doi.org/10.3389/fnhum.2012.00137/abstract (2012).
Van Dijk, K. R. A. et al. Intrinsic functional connectivity as a tool for human connectomics: Theory, properties, and optimization. J. Neurophysiol. 103(1), 297–321 (2010).
Ji, J. L. et al. Mapping the human brain’s cortical-subcortical functional network organization. Neuroimage 185, 35–57 (2019).
Glasser, M. F. et al. A multi-modal parcellation of human cerebral cortex. Nature 536(7615), 171–178 (2016).
Floares, A. G. et al. The smallest sample size for the desired diagnosis accuracy. Int. J. Oncol. Cancer Ther. 2, 13–19 (2017).
Mukherjee, S. et al. Estimating dataset size requirements for classifying DNA microarray data. J. Comput. Biol. 10(2), 119–142 (2003).
Wang, C., Deng, C. & Wang, S. Imbalance-XGBoost: Leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost. Pattern Recognit. Lett. 136, 190–197 (2020).
Lundberg, S. M. et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2(10), 749–760 (2018).
Duda, R. O., Hart, P. E. & Stork, D. G. Pattern Classification 679 (John Wiley & Sons, 2012).
Bentéjac, C., Csörgő, A. & Martínez-Muñoz, G. A comparative analysis of XGBoost. Artif. Intell. Rev. 54(3), 1937–1967 (2021).
Friedman, J. H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 29(5), 1189–1232 (2001).
Janssen, R. J., Mourão-Miranda, J. & Schnack, H. G. Making individual prognoses in psychiatry using neuroimaging and machine learning. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 3(9), 798–808 (2018).
Bzdok, D. & Meyer-Lindenberg, A. Machine learning for precision psychiatry: Opportunities and challenges. Biol. Psychiatry Cogn. Neurosci. Neuroimaging. 3(3), 223–230 (2018).
Dwyer, D. B., Falkai, P. & Koutsouleris, N. Machine learning approaches for clinical psychology and psychiatry. Annu. Rev. Clin. Psychol. 14(1), 91–118 (2018).
Iniesta, R., Stahl, D. & McGuffin, P. Machine learning, statistical learning and the future of biological research in psychiatry. Psychol. Med. 46(12), 2455–2465 (2016).
Cearns, M., Hahn, T. & Baune, B. T. Recommendations and future directions for supervised machine learning in psychiatry. Transl. Psychiatry. 9(1), 1–12 (2019).
Rutledge, R. B., Chekroud, A. M. & Huys, Q. J. Machine learning and big data in psychiatry: toward clinical applications. Curr. Opin. Neurobiol. 55, 152–159 (2019).
Chandler, C., Foltz, P. W. & Elvevåg, B. Using machine learning in psychiatry: The need to establish a framework that nurtures trustworthiness. Schizophr. Bull. 46(1), 11–14 (2020).
Ritchey, M., Libby, L. A. & Ranganath, C. Chapter 3—Cortico-hippocampal systems involved in memory and cognition: The PMAT framework. In Progress in Brain Research (eds O’Mara, S. & Tsanov, M.) 45–64 (Elsevier, 2015) (The Connected Hippocampus; vol. 219).
Doll, B. B., Shohamy, D. & Daw, N. D. Multiple memory systems as substrates for multiple decision systems. Neurobiol. Learn. Mem. 117, 4–13 (2015).
Palomero-Gallagher, N., Vogt, B. A., Schleicher, A., Mayberg, H. S. & Zilles, K. Receptor architecture of human cingulate cortex: Evaluation of the four-region neurobiological model. Hum. Brain. Mapp. 30(8), 2336–2355 (2009).
Manza, P., Tomasi, D. & Volkow, N. D. Subcortical local functional hyperconnectivity in cannabis dependence. Biol. Psychiatry Cogn. Neurosci. Neuroimaging. 3(3), 285–293 (2018).
Wu, Y. F. & Yang, B. Gray matter changes in chronic heavy cannabis users: A voxel-level study using multivariate pattern analysis approach. NeuroReport 31(17), 1236–1241 (2020).
Cheng, H. et al. Resting state functional magnetic resonance imaging reveals distinct brain activity in heavy cannabis users—A multi-voxel pattern analysis. J. Psychopharmacol. Oxf. Engl. 28(11), 1030–1040 (2014).
Lopez-Larson, M. P. et al. Altered prefrontal and insular cortical thickness in adolescent marijuana users. Behav. Brain Res. 220(1), 164–172 (2011).
Pitcher, D. & Ungerleider, L. G. Evidence for a third visual pathway specialized for social perception. Trends Cogn. Sci. 25(2), 100–110 (2021).
Navarri, X. et al. How do substance use disorders compare to other psychiatric conditions on structural brain abnormalities? A cross-disorder meta-analytic comparison using the ENIGMA consortium findings. Hum. Brain Mapp. 43(1), 399–413 (2022).
Leszczynski, M. How does hippocampus contribute to working memory processing?. Front. Hum. Neurosci. 5, 168 (2011).
Lisdahl, K. M. et al. The impact of ADHD persistence, recent cannabis use, and age of regular cannabis use onset on subcortical volume and cortical thickness in young adults. Drug Alcohol Depend. 161, 135–146 (2016).
Hagenmuller, F. et al. Early somatosensory processing in individuals at risk for developing psychoses. Front. Behav. Neurosci. 8, 308 (2014).
Çolak, Ç., Çelik, Z. Ç., Zorlu, N., Kitiı, Ö. & Yüncü, Z. cortical thickness and subcortical volumes in adolescent synthetic cannabinoid users with or without ADHD: A preliminary study. Arch. Neuropsychiatr. 56(3), 167–172 (2019).
Maxwell, A. M., Harrison, K., Rawls, E. & Zilverstand, A. Gender differences in the psychosocial determinants underlying the onset and maintenance of alcohol use disorder. Front. Neurosci. https://doi.org/10.3389/fnins.2022.808776/full (2022).
Kahle, E. M., Veliz, P., McCabe, S. E. & Boyd, C. J. Functional and structural social support, substance use and sexual orientation from a nationally representative sample of US adults. Addict. Abingt. Engl. 115(3), 546–558 (2020).
Miles, D. R., van den Bree, M. B. M. & Pickens, R. W. Sex differences in shared genetic and environmental influences between conduct disorder symptoms and marijuana use in adolescents. Am. J. Med. Genet. 114(2), 159–168 (2002).
Guxens, M., Nebot, M. & Ariza, C. Age and sex differences in factors associated with the onset of cannabis use: A cohort study. Drug Alcohol Depend. 88(2–3), 234–243 (2007).
Rusby, J. C., Light, J. M., Crowley, R. & Westling, E. Influence of parent-youth relationship, parental monitoring, and parent substance use on adolescent substance use onset. J. Fam. Psychol. JFP J. Div. Fam. Psychol. Am. Psychol. Assoc. Div. 32(3), 310–320 (2018).
Farhat, T., Simons-Morton, B. & Luk, J. W. Psychosocial correlates of adolescent marijuana use: variations by status of marijuana use. Addict. Behav. 36(4), 404–407 (2011).
Acknowledgements
Data were provided by the Human Connectome Project, WU-Minn Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University. ER was supported by a postdoctoral training grant from the National Institutes of Mental Health (NIMH; T32 MH115866). GD was supported by a predoctoral training grant from the National Institute on Drug Abuse (NIDA; T32 DA007234). AMM was supported by a predoctoral training grant from the National Institute of Neurological Disorders and Stroke (NINDS; T32 NS105604-04). SM and EK received support for this work from the National Center for Advancing Translational Sciences of the National Institutes of Health Award Number (NCATS; UL1TR000114).
Author information
Authors and Affiliations
Contributions
G.N.: conceptualization, data curation, formal analysis, software, visualization, writing—review and editing; E.R.: conceptualization, data curation, visualization, writing—original draft; S.M.: conceptualization, methodology, software, writing—review and editing; EK: conceptualization, methodology, writing—review and editing; A.M.M.: conceptualization, writing—review and editing; L.R.B.: conceptualization, writing—review and editing; G.D.: conceptualization, writing—review and editing; A.Z.: conceptualization, funding acquisition, methodology, project administration, resources, supervision, visualization, writing—review and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Niklason, G.R., Rawls, E., Ma, S. et al. Explainable machine learning analysis reveals sex and gender differences in the phenotypic and neurobiological markers of Cannabis Use Disorder. Sci Rep 12, 15624 (2022). https://doi.org/10.1038/s41598-022-19804-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-19804-2
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
