
Abstract
The fasting blood glucose (FBG) values extracted from electronic medical records (EMR) are assumed valid in existing research, which may cause diagnostic bias due to misclassification of fasting status. We proposed a machine learning (ML) algorithm to predict the fasting status of blood samples. This cross-sectional study was conducted using the EMR of a medical center from 2003 to 2018 and a total of 2,196,833 ontological FBGs from the outpatient service were enrolled. The theoretical true fasting status are identified by comparing the values of ontological FBG with average glucose levels derived from concomitant tested HbA1c based on multi-criteria. In addition to multiple logistic regression, we extracted 67 features to predict the fasting status by eXtreme Gradient Boosting (XGBoost). The discrimination and calibration of the prediction models were also assessed. Real-world performance was gauged by the prevalence of ineffective glucose measurement (IGM). Of the 784,340 ontologically labeled fasting samples, 77.1% were considered theoretical FBGs. The median (IQR) glucose and HbA1c level of ontological and theoretical fasting samples in patients without diabetes mellitus (DM) were 94.0 (87.0, 102.0) mg/dL and 5.6 (5.4, 5.9)%, and 92.0 (86.0, 99.0) mg/dL and 5.6 (5.4, 5.9)%, respectively. The XGBoost showed comparable calibration and AUROC of 0.887 than that of 0.868 in multiple logistic regression in the parsimonious approach and identified important predictors of glucose level, home-to-hospital distance, age, and concomitantly serum creatinine and lipid testing. The prevalence of IGM dropped from 27.8% based on ontological FBGs to 0.48% by using algorithm-verified FBGs. The proposed ML algorithm or multiple logistic regression model aids in verification of the fasting status.
Similar content being viewed by others
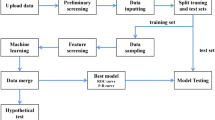

Introduction
With the universal implementation of electronic medical records (EMRs), researchers have actively leveraged real-world EMR data in diabetes research and management in clinical practice1. The development of algorithms to identify patients with prediabetes and diabetes mellitus (DM) with high validity has become increasingly fundamental in improving the patients’ quality of care and preventing complications associated with DM. In current clinical practice, the phenotypes of DM are defined by various combinations of the different components of the EMR, such as diagnostic codes, medication data, and laboratory values related to glucose homeostasis2. Thus, current diagnostic algorithms have yielded significant variation in the validity for identification of DM2. In recent years, several studies have indicated that machine learning (ML) algorithms may better identify diabetic status in EMRs for cohort establishment3,4. Other studies applied ML techniques to predict DM or undiagnosed DM based on clinical information5,6,7,8. Systematic reviews reported that most ML studies used the supervised learning approach and a comparison of the approaches indicated that support vector machine (SVM) was the most widely used algorithm9,10. Deep learning (DL) models such as artificial neural networks (ANNs) and deep neural networks (DNNs) have been applied and reported in some studies showing superior performance than conventional ML approaches in predicting DM-related phenotypes11,12. However, these studies usually assumed that fasting blood glucose (FBG) values are valid if labeled as such by the clinical laboratory, which may lead to potential overestimation of fasting status13. As demonstrated in a survey conducted by Tseng et al., only approximately half of the patients reported to have adequately fasted before phlebotomy at a large academically affiliated hospital13. Another study surveyed around 150 outpatients and stated that 40% did not fast before going to the hospital for laboratory blood work14. Both studies pointed out that documentation of fasting state before phlebotomy was often non-existent as these data are not routinely collected by healthcare providers or the laboratory team and recorded in the EMR. Similarly, information regarding whether patients had been given instructions to fast before phlebotomy was also not recorded13,14. Despite the importance of the fasting status in patients undergoing phlebotomy, there has been relatively few research conducted in the current literature to verify the fasting status of patients before blood work. The lack of knowledge of the fasting state of patients presents a challenge for healthcare providers in determining whether patients had truly fasted before laboratory blood testing and may prohibit them from interpreting the results in accordance with diabetes screening guidelines, resulting in missed diagnoses of prediabetes and type 2 diabetes.
Misclassification of fasting status negatively influences the clinical accuracy of conventional or ML models in screening DM or predicting the risk of DM15. Verification of fasting blood samples is therefore a significant challenge in analyzing real-world EMR data for epidemiological research, particularly when the disease diagnostic criteria are based on fasting blood samples. The current reference standard for confirmation of the fasting status relies on self-reported information from the patients during phlebotomy, which may be influenced by recall and awareness biases. To the best of our knowledge, no studies have used EMR data to investigate the discordance between prescribed and actual fasting status based on the distribution of BG and concomitant HbA1c values. Using a large clinical data repository of more than 2.75 million patient records from a tertiary medical center in central Taiwan, we systematically evaluated the distribution of BG values. We used the HbA1c-estimated average glucose level to define fasting status, followed by the development of prediction models using ML.
Materials and methods
Study data source and sample selection
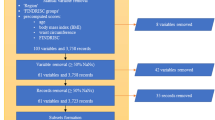
The China Medical University Hospital (CMUH) Clinical Research Data Repository (CRDR) carefully validated the EMRs of 2,873,887 patients who had sought care at CMUH between January 1, 2003, and December 31, 2018. The methodologic details have been published elsewhere16,17,18,19. Of the 2,873,887 patients, 945,792 underwent glucose measurements using sera samples from inpatient and outpatient services. The sample selection flow is summarized in Fig. 1. All methods in this study were performed in accordance with the relevant guidelines/regulations. This study protocol was approved by the Big Data Center of China Medical University Hospital and the Research Ethical Committee/Institutional Review Board of China Medical University Hospital (CMUH105-REC3-068) and the need to obtain informed consent for the present study was waived by the Research Ethical Committee of China Medical University Hospital.

Sample selection process from ontological glucose ante cibum (AC) to theoretical fasting classification, followed by splitting of the dataset into training and testing datasets.
Sociodemographic and clinical variables
The covariables of interest were obtained from the CRDR, including patient demographics, specifically age and sex, and body mass index, which was calculated as the weight in kilograms divided by the height in square meters. The presence of hypertension or type 2 DM was captured based on associated ICD-9/-10 codes or the use of glucose-lowering medications or antihypertensive agents. A history of cardiovascular disease was also documented if the patients had a record of coronary artery disease, myocardial infarction, stroke or congestive heart failure in EMRs based on International Classification of Diseases (ICD) 9th and 10th edition codes. All other coexisting comorbidities were also captured based on ICD-9/-10 codes from the repository or EMR data. Additional provider- or patient-level factors such as medication records, health care provider specialty, and biochemical measures were obtained from repository data or the EMRs within a 1-year window prior to enrollment into the study cohort.
Another patient-level factor that we included was the distance from the patients’ home to the hospital as we hypothesized that fasting status might be associated with the travel time to the healthcare facility. Currently, no studies have investigated the association of distance between healthcare facilities and homes and fasting status. However, a few studies have provided evidence that increasing travel distance to the primary care provider may affect and decrease glycemic control20,21,22.Therefore, we calculated the straight-line distance between hospital to home as it is the most common method for this type of calculation23. The home-to-hospital distance was calculated in two steps. First, a geocoding application programming interface developed by Google Maps was used to transform the map coordinates of the entire study population’s home addresses and locations. The distance between the homes and the hospital was calculated using the geographic information system (ArcGIS version 10; ESRI, Redlands, CA, USA).
Determination of glucose and HbA1c levels
Blood glucose levels were determined by the central laboratory using the Beckman Oxygen electrode (glucose oxidase method) with a Beckman Synchron® LX20 and Beckman UniCel® DxC 800 (Beckman Coulter Inc., Brea, CA, USA) from January 1, 2003, to September 30, 2007, and from October 1, 2007, to December 31, 2018, respectively. The level of HbA1c was measured using boronate affinity and high-performance liquid chromatography (HPLC) methods with the Primus CLC385 analyzer from January 1, 2003, to June 30, 2008, cation exchange HPLC methods with the Tosoh HLC-723 G7 (Tosoh Corporation, Tokyo, Japan) from July 31, 2008, to December 31, 2013, and boronate affinity and HPLC methods with the Trinity Biotech Premier Hb9210 from January 1, 2014, to December 31, 2018.
From the CMUH-CRDR laboratory database, we selected the glucose measurements specified as fasting glucose (AC, ante cibum), postprandial glucose (PC, post cibum), and random glucose. We excluded data recorded as nonnumerical values, values higher than 1000 mg/dL, or zero values. All glucose measurements could also be classified as inpatient, outpatient clinic, and emergency department services. Only measurements obtained in the outpatient setting were included in the final analysis. The HbA1c-derived averaged glucose level (ACaverage) was defined based on Nathan et al.’s formula as a theoretical upper limit of fasting glucose24.
Data conditioning steps to determine ontological fasting glucose
To investigate the “true” ontological fasting status on blood glucose measurements, we filtered glucose measurements that were highly likely nonfasting in the outpatient setting to derive ontological fasting glucose (AContological) as follows. Glucose measurements were reclassified as non-AContological if:
-
1.
the data were labeled as post cibum glucose or random glucose,
-
2.
the glucose measurement included additional descriptions/labels such as “one-touch”, “bedside check”, or “PC” or contained descriptions indicating active food intake before phlebotomy, regardless of the laboratory test prescribed (e.g., fasting glucose),
-
3.
patients had multiple fasting glucose measurements on the same day; only the first measurement was considered as non-AContological.
Definition of theoretical fasting status
Three criteria were used to define the theoretical fasting status (ACtheoretical) of patients who underwent concomitant AContological and HbA1c measurements on the same day: (1) an AContological < 100 md/dL in patients without DM with HbA1c < 5.5%; (2) an AContological < ACaverage − 1 standard deviation of AContological glucose in patients without DM with an HbA1c between 5.5 and 6.4%; and (3) an AContological < ACaverage in patients with DM. Once the patients' glucose AC was defined as ACtheoretical, the corresponding blood samples were defined as fasting samples. Otherwise, they were considered nonfasting samples. These criteria are based on the physiological profiling of glucose and insulin variation over 24 h in individuals with and without diabetes25,26. The A1c-derived estimated average glucose (ACaverage) summarizes the daily glucose variation over the past 90 days, depicting an averaged value between the lowest and the highest glucose level in this time window among patients with a stable metabolic state. Therefore, if truly obtained in the fasting status, the glucose level should be theoretically less than the level of ACaverage27. To verify the validity of our proposed criteria, we used the glucose AC from 4519 patients who provided morning fasting samples before the procedure of pan-endoscopy in CRDR as the true fasting glucose AC and only 314 measurements (6.95%) were misclassified as nonfasting based on our criteria.
Statistical analysis
The clinical characteristics of patients with a theoretical fasting sample and those with a theoretical nonfasting sample were compared. The probability densities of glucose levels between fasting and nonfasting status were examined based on the diabetic status. We also assessed whether the levels of fasting glucose differed if the glucose measurements were taken at the same time with lipid profiles. Conventional logistic regression and ML were applied to develop a tool for predicting whether the glucose measurements were fasting measures. We tested model discrimination and calibration using area under the receiver operating characteristic (AUROC) statistics and calibration curves.
Machine learning approach and evaluation
To use ML for predicting whether the blood samples were obtained in the fasting state, a balanced dataset was curated to obtain a 1:1 ratio of AContological and ACtheoretical, which was composed of 93,958 patients (Fig. 1). Patients within this balanced dataset were separated into training and testing sets at an 80/20 proportion while maintaining a 1:1 ratio of AContological and ACtheoretical. The demographic, clinical, and biochemical information of the patients, such as age, ICD-9 or -10 codes, medication histories, and laboratory test results, was then extracted from the CMUH-CRDR. We applied logistic regression and eXtreme Gradient Boosting model (XGBoost), a scalable end-to-end tree boosting model proposed by Chen and Guestrin28, to evaluate the performance of predicting fasting status. We additionally experimented with two efficient algorithms, CatBoost and ensemble models with H2O AutoML, to better handle the categorical variables and explore the predictive performance using multiple learning algorithms29,30. The objective function of this binary classification problem was to minimize binary entropy loss; the hyperparameters of our XGBoost model were determined using the Tree of Parzen Estimators (TPE) method31. Taking the implementation of XGBoost in Python as an example, the finalized hyperparameters were set as tree depth = 8, learning rate = 0.1, gamma = 0.5, minimum sum of instance weight = 7, number of estimators = 300, and the remaining parameters were set using the default setting. Detailed parameter ranges for grid search were summarized in Supplementary Table 1. To implement ensemble models with H2O AutoML in Python, we stacked various algorithms, such as XGBoost, Random Forest, and Gradient Boosting Machines. The model output of XGBoost, CatBoost, or Ensemble models was the probability of ACtheoretical. The performance quantification of each ML algorithm was evaluated in terms of AUROC, accuracy, precision, recall, and F1 score using a fivefold cross-validation scheme. We used the bootstrapping method with 2000 repetitions to statistically test the difference between the paired AUROCs32. Finally, we compared the proportion of glucose AC ≥ 126 mg/dL calculated with or without the ML algorithm to classify the fasting status. We also classified glucose AC ≥ 126 mg/dL, regardless of ontological or predicted fasting samples, which did not lead to the diagnosis of diabetes over the study periods as ineffective glucose measurements (IGM). All statistical analyses were performed using SAS version 9.4 (SAS Institute Inc., Cary, NC, USA), R version 3.5.1 (R Foundation for Statistical Computing, Vienna, Austria), and Python version 3.7.3 under a Linux operating system. The Python package version was 1.5.2 for XGBoost, 1.0.4 for CatBoost, and 3.36.0.2 for H2O AutoML. The two-sided statistical significance level of α was set at 0.05.
Ethical approval
The study was approved by the Research Ethical Committee/Institutional Review Board of China Medical University Hospital (CMUH105-REC3-068).
Results
Distribution of glucose level by fasting and diabetic status
A total of 359,402 AContological data points were included in the final analysis, with a mean sample age of 59.7 ± 14.6 years. Approximately half of the sample population were female (46.1%). When restricting to only the patients’ first sample in the CRDR (n = 93,958), the average age was 54.4 ± 15.5 years, and 45.9% of these patients were female. Of these 93,958 patients, 29.2% had been diagnosed with DM at the first AContological. Blood glucose measurements considered to be collected during fasting state were observed in younger non-DM patients but not among younger patients with DM. Nonfasting samples were more likely to be provided by male patients, regardless of their diabetic status. Moreover, samples were more likely to be fasting measures if the lipid profiles of the patients were concomitantly examined. Statistical differences were observed for the majority of the biochemical measures between fasting and nonfasting samples. Specifically, levels of triglyceride demonstrated clinically significantly different results (> 15 mg/dL) between fasting and nonfasting samples, regardless of the diabetic status (Table 1).
The peak of the density curves of AContological with and without same-day HbA1c measures was similar at approximately 100 mg/dL. However, the width of the distribution of AContological with HbA1c measures was wider than those without the HbA1c measures (Fig. 2A). Peaks of the density curves of ACtheoretical and nonfasting AContological were separated with a peak value slightly lower than 100 and slightly above 126 mg/dL, respectively (Fig. 2B). Among patients without DM, a peak shift to the left to < 126 mg/dL was noted in the nonfasting samples compared with the entire sample with concomitant HbA1c (Fig. 2C). By contrast, among patients with DM, the peak of the fasting samples shifted right to approximately 126 mg/dL (right-shifting; Fig. 2D). Figure 3 shows the scatter plots of AContological and HbA1c based on diabetic status and highlights the distribution of ACtheoretical.

Density plots of ontological glucose AC in selected samples as follows: (A) entire samples stratified by the availability of HbA1c measured on the same day; (B) samples with HbA1c measured on the same day, stratified by theoretical fasting and nonfasting status; (C) the entire samples with A1c measured on the same day, stratified by fasting and nonfasting status in patients without DM; (D) the entire samples with HbA1c measured on the same day, stratified by fasting and nonfasting status in patients with DM. The dark blue dashed line shows the glucose value at 100 mg/dL, and the red dashed line shows the glucose value at 126 mg/dL.

Scatter plot of HbA1c and fasting glucose levels. The figure is divided into four quadrants (a, b, c, and d) according to the diagnostic criteria of the American Diabetes Association (ADA) by diabetic status.
Factors associated with nonfasting status
The entire dataset consisted of 67 attributes (Supplementary Table 2) and details of relevant missingness are provided in Supplementary Table 3. In multiple logistic regression, age, male sex, distance from the home to the hospital, the timing of blood sampling, and the cumulative frequency of outpatient visits 1 year prior to the blood sampling were associated with a higher probability of being in a nonfasted state. Patients with a history of DM, hypertension or coronary artery disease, statin medication, and concomitant lipid and glucose testing were significantly associated with the fasting status. Comparing the odds of nonfasting status among patients who visited the Health Management Center, those who were ordered glucose measurement in the departments of metabolism and endocrinology, general medicine, and nephrology were twice as likely to be in a nonfasted state (Table 2). In addition, patients who underwent concomitant glucose and lipid testing were more likely to follow the fasting instruction, with the odds ratio of being in a nonfasted state of 0.78 (95% CI 0.76–0.80).
Machine learning performance in fasting status identification
We conducted experiments on feature selection by building XGBoost models with the top 10, 25, 35, 45 features and found that using all 67 features generated the most accurate result. Compared with the predictive performance of multiple logistic regression for nonfasting status in the testing dataset, XGBoost with full features showed better sensitivity (77.8% vs. 76.1%), accuracy (80.9% vs. 78.5%), and F1 score (81.6% vs. 78.0%; Table 3). The top 45 scoring variables are summarized in Fig. 4. The level of the AContological, the distance from home to the hospital, age, height, and the level of serum creatinine were the most important features. When we used 14 features of the parsimonious model (model 2 in Table 2) in the XGBoost algorithm, the predictive performance was statistically better than that of the predictive model derived from multiple logistic regression. By contrast, the precision of the conventional logistic regression model was marginally better than the ML-based models (Table 3). The AUROC and calibration performance of our proposed ML methods were generally better than those of the multiple logistic regression model (AUROC 0.887 vs. 0.868, p < 0.001; Fig. 5). In the sensitivity analysis of other ML algorithms, the predictive performance was consistent with the original XGBoost (Table 3). However, the overall predictive performance difference between ML-based and conventional logistic regression models was not clinically relevant. The performance of different ML methods in the training dataset is provided in Supplementary Table 4.

Top-ranked 45 features identified using the proposed XGBoost algorithm. SCr serum creatinine, ALT alanine transaminase, AST aspartate aminotransferase, BUN blood urea nitrogen, RBC red blood cell counts.

Discrimination statistics (A) and calibration plots (B) for multivariable logistic regression model and the parsimonious machine learning models in the testing dataset.
Impact on the prevalence of ineffective glucose measurements
On average, the prevalence of glucose measurement ≥ 126 mg/dL dropped from 14.2 to 10.1% by applying algorithm-verified FBGs over the years, and this difference was constant throughout the study period (Table 4). The prevalence of IGM dropped from 27.8% based on AContological ≥ 126 mg/dL to 0.48% by using algorithm-verified FBGs ≥ 126 mg/dL. The difference consistently ranged between 25.9 and 28.5% from 2003 to 2018 (Table 4).
Discussion
Our findings support that fasting status can be well predicted in real-world settings by using parsimonious computation models based on ML or conventional statistical approaches in clinical practice. Using the ML model, we found that 78.0% of the 604,639 blood samples could be theoretically classified as fasting samples when we defined the fasting status as AContological less than ACaverage. The most important features to predict fasting status were the levels of AContological, distance from the home to the hospital, age, height, and concomitant testing of serum creatinine. XGBoost yielded statistically better performance in predicting fasting status than conventional logistic regression modeling did, with an AUC of 0.892 and an F1 score of 80.5%. The prevalence of IGM decreased from 6.44 to 0.06% among those without DM history. This change is noteworthy, as the prevalence of DM was 16.6% regardless of the fasting status and 11.8% when patients with nonfasting status verified by ML algorithms were excluded from the sample. ML algorithms, such as XGBoost, may be particularly useful as their robustness to missing data, can address one of the most pervasive barriers of real-world data analysis.
In clinical practice and diabetes research, it is common to assume that AContological is from a fasting sample in EMR33. Our results suggest that implementing fasting status verification algorithms based on a ML or conventional statistical approach is essential for an automated diabetes screening algorithm to better predict DM, which may help the regional and national diabetes screening policy and improve care management. There is no standardized method to assess whether patients have truly fasted before phlebotomy is performed. When patients were asked about their fasting status prior to phlebotomy in a survey study, only 50% reported having actually fasted13. As there is no objective biomarker to verify fasting status, the current reference standard merely relies on patients’ self-reports which are inevitably affected by recall bias. Thus, the self-report data pose persistent challenges to assessing the epidemiology of DM13. From the perspective of point-of-care testing, it is likely that the current literature has overestimated the prevalence and incidence of prediabetes and DM based on the EMR data, particularly the so-called “undiagnosed prediabetes or diabetes.” Information bias, specifically misclassification bias, caused by treating nonfasting glucose as fasting glucose, underestimates the effects of glucose on health outcomes. The findings of a recent study, in which six diabetes phenotyping methods in EMR were compared, suggested that solely using abnormal glucose values would overestimate the number of prevalent DM cases by approximately 1.5 times34. This magnitude of overestimation cannot be entirely explained by analytical variation in glucose measurement; therefore, overestimation of actual fasting status should be considered and thoroughly investigated35.
Our results showed that lipid profiles, except triglyceride level, were not affected by fasting status. Especially among patients without DM, levels of fasting TCHO, LDL-C, and HDL-C were counterintuitively higher than those from the nonfasting samples. This finding supports the trends of using nonfasting lipid profiles to facilitate risk assessment of atherosclerotic cardiovascular disease and assures the feasibility of our algorithm in classifying fasting status by comparing the difference between AContological and ACaverage. Our ML approach in identifying fasting status can serve as a complementary tool to the questionnaire-based survey and enable clinicians to provide personalized instructions for fasting to patients based on their prior fasting records, thereby increasing the accuracy of the true fasting rate improving the precision in identifying DM and monitoring its control. We also observed some major contributing factors in predicting fasting status, such as distance from the home to the hospital, age, and serum creatinine level, which can provide another perspective in understanding the adherence behavior of staying in a fasting state. Furthermore, our proposed fasting status prediction algorithm helps enhance the validity of an automated diabetes phenotyping algorithm. In the entire population of CMUH-CRDR, we found that the prevalence trend of diabetes mellitus based on algorithm-verified FBGs was 11.8% lower than that based on AContological (23.1%), and the corresponding trend of prevalent prediabetes based on algorithm-verified FBGs was also 24.1% lower than that based on AContological (40.2%). Although the difference was not radical, the absolute misclassified number from DM to nondiabetes can be significant, depending on the population size. Indeed, due to the increasing interest and use of digital health tools to detect abnormal blood glucose levels, misclassification of nonfasting glucose measures as fasting may lead to potential overdiagnosis and treatment of patients without DM.
The concept of IGM is worthy of broader discussion as it stands for a measurement of FBG that did not change the clinical course of glucose metabolism even when the level was greater than 126 mg/dL among patients without a history of DM. Several reasons could help explain this observation, such as clinician knowledge of the nonfasting status or a missed interpretation of the result. Nonetheless, a potential consequence of IGM is missing the detection of diabetes, leading to complications and increased healthcare utilization in the long run. Failing to obtain a truly FBG may be problematic for diabetes screening. Our proposed algorithms drastically reduced the proportion of IGM, supporting their use in the real-world care flow to trigger actionable screening of diabetes. These algorithms also help generate a warning upon detecting the discrepancy between AContological and algorithm-verified nonfasting glucose, which could serve as a checkpoint and reminder in the automatically digital phenotyping process for DM screening. Future research on clinical effectiveness and automatic fasting status prediction implementation in the flow of digital diabetic phenotyping systems is necessary to strengthen the public health impact.
The present study has several limitations. First, the actual fasting status of the patients was not available. However, it is challenging, if not impossible, to obtain the actual fasting status. We assumed that AContological should be less than ACaverage in the fasting status among outpatients with stable dietary habits and a steady level of carbohydrate metabolism. In the crude analysis, we found that patients from the Health Management Center were more likely to be in the fasting state before phlebotomy. This observance corresponds to our clinical experience, where patients who were relatively healthy and willing to attend health checkups typically have a higher motivation to provide fasting samples. Specifically, patients who undergo health checkups usually receive detailed instructions for fasting36. Furthermore, over 93% of FBGs obtained from patients prepared for a pan-endoscopy were accurately classified as ACtheoretical. Second, the algorithm was developed in a tertiary hospital under universal health care coverage; thus, it may not be generalizable to other settings. Further research with additional data from different populations is required to train and solidify our proposed algorithm. More importantly, integrating our algorithm into the clinical workflow is critical to verify its performance in the real-world setting.
Conclusions
To the best of our knowledge, this is the first attempt at using a ML approach to evaluate the reliability of fasting samples in a large tertiary hospital. Only 65.3% of ontologically AC samples could be classified as algorithm-verified fasting status. Despite its moderate performance in predicting the fasting status among outpatients, our algorithms provide an innovative approach to clean medical data and facilitate true fasting BG detection. Notably, this study has introduced an essential step towards establishing automated phenotyping in EMR for effective diabetic screening and more accurate estimation of the global and local epidemiology of DM.
Data availability
Restrictions apply to the availability of some or all data generated or analyzed during this study to preserve patient confidentiality or because they were used under license. The corresponding author will on request detail the restrictions and any conditions under which access to some data may be provided.
References
Cebul, R. D., Love, T. E., Jain, A. K. & Hebert, C. J. Electronic health records and quality of diabetes care. N. Engl. J. Med. 365, 825–833 (2011).
Spratt, S. E. et al. Assessing electronic health record phenotypes against gold-standard diagnostic criteria for diabetes mellitus. J. Am. Med. Inform. Assoc. 24, e121–e128 (2017).
Adjah, E. S. O., Montvida, O., Agbeve, J. & Paul, S. K. Data mining approach to identify disease cohorts from primary care electronic medical records: A case of diabetes mellitus. Open Bioinform. J. 10, 16–27 (2017).
Zheng, T. et al. A machine learning-based framework to identify type 2 diabetes through electronic health records. Int. J. Med. Inform. 97, 120–127 (2017).
Zou, Q. et al. Predicting diabetes mellitus with machine learning techniques. Front. Genet. 9, 515 (2018).
Kopitar, L., Kocbek, P., Cilar, L., Sheikh, A. & Stiglic, G. Early detection of type 2 diabetes mellitus using machine learning-based prediction models. Sci. Rep. 10, 11981 (2020).
Lai, H., Huang, H., Keshavjee, K., Guergachi, A. & Gao, X. Predictive models for diabetes mellitus using machine learning techniques. BMC Endocr. Disord. 19, 101 (2019).
Anderson, A. E. et al. Electronic health record phenotyping improves detection and screening of type 2 diabetes in the general United States population: A cross-sectional, unselected, retrospective study. J. Biomed. Inform. 60, 162–168 (2016).
Kavakiotis, I. et al. Machine learning and data mining methods in diabetes research. Comput. Struct. Biotechnol. J. 15, 104–116 (2017).
Sharma, T. & Shah, M. A comprehensive review of machine learning techniques on diabetes detection. Vis. Comput. Ind. Biomed. Art 4, 30 (2021).
Chaki, J., Thillai Ganesh, S., Cidham, S. K. & Ananda Theertan, S. Machine learning and artificial intelligence based Diabetes Mellitus detection and self-management: A systematic review. J. King Saud Univ. Comput. Inf. Sci. (2020).
Zhu, T., Li, K., Herrero, P. & Georgiou, P. Deep learning for diabetes: A systematic review. IEEE J. Biomed. Health Inform. 25, 2744–2757 (2021).
Tseng, E., Segal, J. B. & Maruthur, N. M. Fasting status of patients undergoing ambulatory laboratory testing. Diabetes Care 42, e133–e134 (2019).
Kackov, S., Simundic, A. M. & Gatti-Drnic, A. Are patients well informed about the fasting requirements for laboratory blood testing?. Biochem. Med. (Zagreb) 23, 326–331 (2013).
Herzig, K., Just, S. & Zeller, A. It's not a bug, it's a feature: How misclassification impacts bug prediction. 2013 35th International Conference on Software Engineering (ICSE), 392–401 (2013).
Chiang, H. Y. et al. Electronic medical record-based deep data cleaning and phenotyping improve the diagnostic validity and mortality assessment of infective endocarditis: Medical big data initiative of CMUH. Biomedicine (Taipei) 11, 59–67 (2021).
Shen, W. C. et al. Risk of all-cause mortality, cardiovascular disease mortality, and cancer mortality in patients with bullous pemphigoid. JAMA Dermatol. 158, 167–175 (2022).
Chiang, H. Y. et al. Association between preoperative blood glucose level and hospital length of stay for patients undergoing appendectomy or laparoscopic cholecystectomy. Diabetes Care 44, 107–115 (2021).
Kao, P. Y., Yeh, H. C., Hsia, Y. F., Hsiao, Y. L., Wang, J. S., Chang, D. R. et al. Paradoxical mortality of high estimated glomerular filtration rate reversed by 24-h urine creatinine excretion rate adjustment: Sarcopenia matters. J. Cachexia Sarcopenia Muscle (2022).
Strauss, K., MacLean, C., Troy, A. & Littenberg, B. Driving distance as a barrier to glycemic control in diabetes. J. Gen. Intern. Med. 21, 378–380 (2006).
Smith, J. J., Berman, M. D., Hiratsuka, V. Y. & Frazier, R. R. The effect of regular primary care utilization on long-term glycemic and blood pressure control in adults with diabetes. J. Am. Board Fam. Med. 28, 28–37 (2015).
Zgibor, J. C. et al. The association between driving distance and glycemic control in rural areas. J. Diabetes Sci. Technol. 5, 494–500 (2011).
Kelly, C., Hulme, C., Farragher, T. & Clarke, G. Are differences in travel time or distance to healthcare for adults in global north countries associated with an impact on health outcomes? A systematic review. BMJ Open 6, e013059 (2016).
Nathan, D. M. et al. Translating the A1C assay into estimated average glucose values. Diabetes Care 31, 1473–1478 (2008).
Bhatnagar, S., Srivastava, D., Jayadev, M. S. & Dubey, A. K. Molecular variants and derivatives of insulin for improved glycemic control in diabetes. Prog. Biophys. Mol. Biol. 91, 199–228 (2006).
American Diabetes Association. 2. Classification and diagnosis of diabetes: Standards of medical care in diabetes-2021. Diabetes Care 44, S15–S33 (2021).
Diseases. NIoDaDaK. The A1C Test and Diabetes (U.S. Department of Health and Human Services, 2018).
Chen, T. & Guestrin, C. XGBoost: A scalable tree boosting system. Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2016).
Veronika Dorogush, A., Ershov, V. & Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv:1810.11363 (2018).
LeDell, E. H2O AutoML: Scalable Automatic Machine Learning (2020).
Bergstra, J., Yamins, D. & Cox, D. D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. Proceedings of the 30th International Conference on International Conference on Machine Learning Vol. 28, I-115–I-23 (JMLR.org, 2013).
Robin, X. et al. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 12, 77 (2011).
Schmittdiel, J. A. et al. Novel use and utility of integrated electronic health records to assess rates of prediabetes recognition and treatment: Brief report from an integrated electronic health records pilot study. Diabetes Care 37, 565–568 (2014).
Upadhyaya, S. G. et al. Automated diabetes case identification using electronic health record data at a tertiary care facility. Mayo Clin. Proc. Innov. Qual. Outcomes 1, 100–110 (2017).
Sacks, D. B. et al. Guidelines and recommendations for laboratory analysis in the diagnosis and management of diabetes mellitus. Diabetes Care 34, e61–e99 (2011).
DeWaters, A. L., Mejia, D., Thomas, J., Elwood, B. & Bowen, M. E. Patient preparation for outpatient blood work and the impact of surreptitious fasting on diagnoses of diabetes and prediabetes. Mayo Clin. Proc. Innov. Qual. Outcomes 4, 349–356 (2020).
Acknowledgements
We appreciate the data exploration, statistical analysis, manuscript preparation, and the support of the iHi Clinical Research Platform from the Big Data Center of CMUH. We would like to thank the Health and Welfare Data Science Center (HWDC), Ministry of Health Welfare, and Health Data Science Center, China Medical University Hospital for providing administrative, technical, and funding support.
Funding
This study was supported by the Ministry of Science and Technology of Taiwan (grant number: 108-2314-B-039-038-MY3, 110-2314-B-039-013, and 110-2321-B-468-001) and by the China Medical Universiy Hospital (grant number: DMR-111-207 and DMR-111-206).
Author information
Authors and Affiliations
Contributions
S.N.C., H.Y.C., and C.C.K. designed the study; C.C.L., C.M.C., P.S.C., and C.H.S. analyzed the data and made the figures; M.Y.W. and S.H.C. performed the machine learning analysis; all authors had input into and approved the statistical analysis plan. Y.L.H., C.T.H., H.Y.C., E.K.K., and C.C.K. drafted and revised the paper; all authors approved the final version of the manuscript. C.C.K. is the guarantor of this work and, as such, had full access to all the data in the study and take responsibility for the integrity of the data and the accuracy of the data analysis.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chang, SN., Hsiao, YL., Lin, CC. et al. Application of machine learning methods for the prediction of true fasting status in patients performing blood tests. Sci Rep 12, 11929 (2022). https://doi.org/10.1038/s41598-022-15161-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-15161-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
