
Abstract
One of the most important problems that the drilling industry faces is drilling cost. Many factors affect the cost of drilling. Increasing drilling time has a significant role in increasing drilling costs. One of the solutions to reduce drilling time is to optimize the drilling rate. Drilling wells at the optimum time will reduce the time and thus reduce the cost of drilling. The drilling rate depends on different factors, some of which are controllable and some are uncontrollable. In this study, several smart models and a correlation were proposed to predict the rate of penetration (ROP) which is very important for planning a drilling operation. 5040 real data points from a field in the South of Iran have been used. The ROP was modelled using Radial Basis Function, Decision Tree (DT), Least Square Vector Machine (LSSVM), and Multilayer Perceptron (MLP). Bayesian Regularization Algorithm (BRA), Scaled Conjugate Gradient Algorithm and Levenberg–Marquardt Algorithm were employed to train MLP and Gradient Boosting (GB) was used for DT. To evaluate the accuracy of the developed models, both graphical and statistical techniques were used. The results showed that DT-GB model with an R2 of 0.977, has the best performance, followed by LSSVM and MLP-BRA with R2 of 0.971 and 0.969, respectively. Aside from that, the proposed empirical correlation has an acceptable accuracy in spite of simplicity. Moreover, sensitivity analysis illustrated that depth and pump pressure have the highest effects on ROP. In addition, the leverage approach approved that the developed DT-GB model is valid statistically and about 1% of the data are suspected or out of the applicability domain of the model.
Similar content being viewed by others

Introduction
One of the most important issues facing the oil industry, especially the drilling industry, is the costs of drilling, and has attracted much attention in recent decades. Many factors can affect the cost of drilling, the most important of which is the drilling time of the well, which can increase drilling costs several times. Therefore, reducing drilling time is one of the most significant purposes of drilling engineers1,2,3. In other words, one of the major aims of drilling optimization is to lessen the total time4. For this purpose, two ways have been proposed: choosing optimum drilling variables (e.g. picking a suitable drilling fluid type and drill-bit) and instantaneous analysis so as to optimize operational parameters such as rotary speed and weight on bit while drilling4.
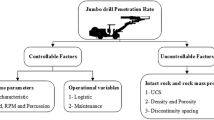
The major factor affecting drilling time is the rate of penetration (ROP)5. Hence, the precision of ROP model is critical6. Many parameters affect the drilling rate, including drilling mud properties, formation characteristics, rotary speed, and bit characteristics2,7. The main parameters that affect ROP are presented in Fig. 1. Some of these parameters are uncontrollable, such as formation characteristics, and others are controllable, such as the properties of drilling mud. Studying the effect of different parameters individually on ROP can easily be investigated, such as rock strength, revolutions per minute (RPM), and weight on bit (WOB)8. Increasing uniaxial compressive strength of formation rock causes hardening and thus decreases penetration rate8,9. The drilling parameters are also controllable factors for changing drilling rate. The type of bit and its genus10, and the fit of bit and formation are effective in increasing drilling rate. Although increasing RPM11 increases drilling rate in soft formations, it is not directly visible in hard formations and low rotational speeds can result in better drilling rates. The flow rate and characteristics of drilling mud, such as plastic viscosity (PV), mud weight (MW), and yield point (YP) determine the ability of the mud to transfer drilling cuttings to the surface. Better cutting transportation to the surface prevents the accumulation of cuttings and regrinding, and increases drilling rate. The WOB determines the degree of contact and penetration of bit into the formation which depends upon the type of rock, and can increase the drilling rate, but the WOB has a direct relation to the drilling rate to a certain extent, and then has no great impact on drilling rate12,13. Many models have been proposed to predict ROP, but they are problematic as they are obtained either in the lab or by using incomplete field data2,14. In other word, effects of the drilling variables on the ROP has not yet been understood completely15. So far, different methods have been proposed to optimize the drilling rate, but due to the fact that a large number of parameters influence the drilling rate, development of an efficient and comprehensive model is very difficult. On the other hand, the complex relationship between these parameters has led to a lack of a comprehensive model2,14.

The main factors affecting ROP.
Normally, two main approaches are used to predict ROP, including traditional models and machine learning (ML) models.
Some famous traditional correlations are as follows:
Maurer16 developed Eq. (1) for rolling cutter bits:
In the above equation, S and K are the compressive rock strength and constant of proportionality, respectively. Wo and W are the threshold bit weight and bit weight, respectively. db shows diameter of drill-bit and N denotes the rotary speed.
Another traditional model for ROP was introduced by Bingham17:
where R, W, \(d_{bit}\), and N refer to ROP (ft/hr), weight on bit (klbs), bit diameter (in), and rotary speed (rot/min), respectively. K and \(a_{5}\). are Bingham coefficients, and have different values for various formations18.
One of the most important ROP models was developed by Bourgoyne and Young19. This model is extensively employed in the industry20. Equation (3) was proposed by Bourgoyne and Young19. Eight parameters were involved in Bourgoyne and Young model19 (BYM).
where D shows the well depth, the coefficient a1to a8 are associated with the formation strength parameter, formation compaction, pore pressure, differential pressure, weight on bit exponent, rotary drilling, drill-bit tooth wear, and bit hydraulic jet impact, respectively, and t denotes the time. Afterwards, Bourgoyne et al.18 suggested an adaptation to their original ROP model:
In the above equation, the functions f1 to f8 involves the empirical coefficients a1–a8. As stated by Soares and Gray6, the main difference between Eqs. (3) and (4) is in the last function. Equation (3) uses Eckel's hydraulics Reynolds number, however in Eq. (4) a power law function of the hydraulic jet impact force was used. Although the BYM equations denote all important features of drilling, some parameters which are necessary in the model are not simply measured in real-time (e.g. drill bit wear, differential pressure)6.
A general drag bit model was introduced by Hareland and Rampersad21:
where, Nc and Av show the number of cutters and the area of rock compressed ahead of a cutter, which supposes a different formulation based on the drill-bit type, respectively. More details can be found in Soares et al. work22.
Finding the definite connection among the drilling parameters is not well realized and is very difficult15. Hence, some researches23,24,25 have been made to better comprehend the connection among the drilling parameters and how they affect the ROP. For instance, Motahhari et al.23 suggested an ROP model for polycrystalline diamond compact (PDC) bit:
In this equation, S shows confined rock strength. \(\alpha\) and y represent the coefficient of ROP model and Wf denotes wear. G presents coefficient related to bit geometry and bit-rock interactions. Deng et al.24 suggested a theoretical model for ROP. This model was developed for roller cone bit and it was validated with results that were achieved from experimental data. In this model, the rock dynamic compressive strength was used in reverse static compressive strength, which improved the accuracy of the theoretical model. Eq. (7) developed by Al-AbdulJabbar et al.25 and it is based on regression analysis:
where 16.96 is used to converted units, \({\uprho }\) shows the mud density, T denotes the torque, SSP represents the standpipe pressure, Q shows the flow rate, PV presents the plastic viscosity, UCS denotes the uniaxial compressive strength. Nonlinear regression was used to calculate the coefficients (a and b).
Equation (8) proposed by Warren:
where S shows rock strength, and \({\text{a}}\) and \({\text{c}}\) denote constant8.
Effects of other factors, such as hold down of chip26,27, bit wear28, and cutting geometry 29,30 was considered by many researchers. Eckel31 expressed that mud properties have no direct effect on ROP, while Paiaman et al.32 showed that growing the plastic viscosity and mud weight can decrease the rate of penetration. Moraveji et al.33 developed a model and illustrated that the gel strength, WOB and YP/PV ratio have remarkable effect on ROP.
Soares et al.22 showed limitations of traditional ROP mods such as model introduced by Bourgoyne et al.19. ML methods are interesting methods to predict ROP. Priority of machine learning techniques than traditional model was proved by several researchers8,34,35,36. The first work about prediction of ROP by ML was conducted by Bilgesu et al.37. The ability of the neural networks to find a complex relationship between data has led to this approach being taken to predict drilling rates. Nowadays, artificial neural networks (ANNs) are widely used in oil industry. We briefly mention few of them in the following part. Alarfaj et al.38 predicted ROP using ANNs and compared several models. They concluded that the extreme learning machine (ELM) gives the accurate results. They did not consider the effect of flow rate, RPM, MW and bit diameter in their models. Ansari et al.39 used error analysis of multivariate regression to select the best parameters to predict ROP and then used support vector regression (SVR) techniques to model ROP. Finally, committee support vector regression (CSVR) based on imperialist competitive algorithm (ICA) was employed to predict ROP. Their results showed that CSVR-ICA model can improve the result of SVR39. Hegde et al.36 conducted evaluation of two different approaches, physics-based and data-driven modeling approaches, for prediction of ROP. Their results showed that the data-driven model had better prediction than traditional models36. Soares and Gray6 studied real-time predictive capabilities of ML and analytical ROP models. Their results showed than ML models decrease the error much better than analytical ones. In addition, among analytical models, the best performance belonged to BYM6. Ashrafi et al.40 employed hybrid artificial intelligence models to predict ROP. Based on their results, particle swarm optimization-multi-layer perception (PSO-MLP) gained the best performance40. Usage of ANN for ROP prediction during drilling operation was also evaluated by Diaz et al.41. Gan et al.42 suggested a new hybrid modeling model to estimate ROP. Excellent prediction performance of their proposed model was shown in this study42. Mehrad et al.43 used mud logging and geomechanical parameters to predict ROP by hybrid algorithm. Least-square support-vector machines-cuckoo optimization algorithm (LSSVM-COA) had the best performance among used models. The difference of errors in training and testing data of the developed model by LSSVM-COA was small43.
This study is conducted to develop an empirical correlation and some smart models including least square vector machine (LSSVM), multilayer perceptron (MLP), Decision Tree (DT), and Radial Basis Function (RBF), for ROP based on a large data bank (more than 5000 data points) obtained from drilling in South fields of Iran. Gradient boosting (GB) is used for DT optimization and Bayesian Regularization Algorithm (BRA), Scaled Conjugate Gradient Algorithm (SCGA) and Levenberg-Marquardet Algorithm (LMA) are used to train MLP modes. What distinguishes this study is to consider more effective parameters in developing the models. These parameters include depth (D), weight on bit (WOB), pit total (PT), pump pressure (PP), hookload (H), surface torque (ST), rotary speed (RS), flow in (Fi), flow out (Fo), and wellhead pressure (Wp). The accuracy and validity of the proposed models are evaluated by statistical and graphical techniques. In addition, the Leverage approach is employed to check the validity of the experimental data and applicability domain of the proposed models.
Modelling
Generalized reduced gradient (GRG)
For developing an empirical correlation for ROP, we proposed a structure for the correlation and used Generalized reduced gradient (GRG) to optimize the coefficient of the correlation. The optimum structure was obtained by a trial-and-error procedure. GRG is known as one of the techniques for solving multivariable problems. This method is used to solve both nonlinear and linear problems44. In this method, variables are regulated to continue the active restrictions being satisfied once the process shifts from one point to another. Linear guess to the gradient at a specific point y is developed by GRG. Both the objective gradient and restriction are solved alongside. The objective gradient function can be denoted in the form of the gradients of restrictions. Later, the search can move in a realistic way and the search area's size is reduced. For an objective function f(y) subjected to h(y)45:
GRG can be stated as follows45:
One of the vital conditions for f(y) to be minimized is that df(y) = 0. Interested readers can achieve more details in the literature46,47,48,49.
Decision Tree (DT)
DT is known as a non-parametric supervised learning method that can be applied for both classification and regression problems. Morgan and Sonquist50 introduced Automatic Interaction Detection (AID), known as the first decision tree. Messenger and Mandell51 introduced THeta Automatic Interaction Detection (THAID), the first classification tree algorithm. THAID is a hierarchical flow chart involving branches, root nodes, internal nodes, and leaf nodes. A top node that does not have any income branch is called root node. The root node presents the entire sample space. Nodes contain one incoming branch and more outgoing edges are the internal or test nodes. Leaves or terminal nodes are nodes that show the final results. Pruning, stopping, and splitting are three main procedures for making a decision tree52. Separating the data into a number of subsets, based on testing the most noted attribute that is valid also for the training instances is accomplished in the splitting step. Various criteria such as Gini index, information gain, gain ratio, information gain, classification error, and towing could be considered for standard deviation reduction, variance reduction, and classification tree53. Figure 2 shows an instance of a decision tree that is used for both regression and classification. Data splitting is started from the root node and develops to the internal node until reaching the stopping criteria or satisfaction of the predefined homogeneity. Representing the stopping criteria can result in a lessening of the problem complexity. This approach results in avoiding overfitting. Splitting would cause a complex tree once stopping criteria are not applied. Although the training data would be fitted well, it does not occur for the test data. Usage of represented stopping criteria would be restricted to tuning the model for the best value. In order to avoid overfitting, if stopping methods do not work properly, pruning technique is applied. In pruning technique, a complete tree is made. Afterward, it is pruned to small trees which are generated by the removal of some nodes that contain less information gain or validation data.

The schematic diagram of DT.
Radial basis function (RBF) neural network
RBF and MLP are the most widely used artificial neural network (ANN) models. With these differences that the RBF model has a simpler design and its structure is fixed and consists of only three layers. It should also be noted that the categorization methods are unalike between the MLP and RBF. The data values in this method are gained based on the space of the points from the points called the center. Centers are chosen in three different ways: (a) supervised, (b) unsupervised (c) fixed. In each neuron, a transport function acts, thus, we have for f(zi) = output:
where terms \(\emptyset \left( {z_{i} } \right)\), \(w^{t}\) and \(b\) refer to transport function, transposed matrix of weights, and bias vector, respectively.
Equation (13) shows Gaussian function and generally it is the transport function in RBF models:
Other common radial functions are:
The distance of point \(z_{i}\). from center \(c_{k}\). is shown as, \(\left\| {z_{k} - c_{i} } \right\|\), thus, we have:
The number of inputs and kernels, centers, and Gaussian transport function is symbolized by, N, M, \(c_{k}\). and \(\varphi_{ik} \left( z \right)\), respectively.
According to the above statements, outputs are obtained by54,55,56,57:
The schematic of RBF model and flowchart for the proposed RBF model illustrated in Figs. 3 and 4, respectively. The spread coefficient and the maximum number of neurons in RBF are 2 and 100, respectively. In addition, Gaussian function was used as a transfer function in the present study for RBF model.

The schematic diagram of RBF.

Flowchart for the suggested RBF model72.
Multilayer perceptron (MLP)
MLP is a feed-forward ANN that can have several layers. A simple MLP model consists of at least three layers. In this case, a hidden layer connects input and output layer. The layers are composed of neurons, except for the input layer, the neurons of the other layers contain a nonlinear activation function. The number of layers and neurons in each layer could be determined by considering the number of input data and complexity of the problem. Learning this network is performed using a supervised back-propagation algorithm. Weights and bias are the parameters of each neuron. Several functions can be used as a transfer function in hidden and output neurons. Some of these functions are presented below:
In the present study, Purelin, Tansig, and Logsig are three-transfer function used for MLP model. As mentioned above, the first layer has a linear function and the others have nonlinear. For example, output of an MLP model with two hidden layers is calculated as follows:
where \(b_{1}\), \(b_{2}\), and \(b_{3}\) refer to the first and second hidden layer bias vector and output layer bias, respectively. Matrixes of the first and second hidden layer and output layer are also denoted by \(w_{1}\), \(w_{2}\), and \(w_{3}\)54,55,57,58. Schematic of a single hidden layer MLP model illustrated in Fig. 5.

The schematic diagram of MLP.
Least square support vector machine (LSSVM)
LSSVM was firstly suggested by Suykens and Vandewalle59. In LSSVM, a set of linear equations is solved; therefore, we have simplification in the learning process. Eq. (27) shows the cost function of Support Vector Machine (SVM):
Here superscript T represents the transport matrix of a variable and We shows regression weight. A variable error of the LSSVM algorithm is shown by \(Ve_{j}^{2}\) and Tu shows the tuning parameter.
Subjected to the following restriction:
By equating the Lagrange function of the LSSVM to zero and then using the following formula, model's parameter could be achieved:
By using Eq. (31), the parameters of LSSVM can be achieved. Unknown parameters in Eq. (31), are We, c, \(Ve_{j}\), and \(\alpha_{j} .\)
\(Ve_{j}\) and \(\sigma^{2}\) control the reliability of LSSVM. In this study, the amount of Tu and \(\sigma^{2}\) are 24.7959, and 2.2514, respectively.
Optimization algorithms
Levenberg–Marquardt algorithm
In order to train data in MLP model, training algorithms are used to optimize weights and bias values. Levenberg–Marquardt is one of these algorithms which is used to solve nonlinear problems. In this method, even if there is an inappropriate initial guess for weights and bias, the algorithm will be able to get the final answer. Due to having sum square form for performance function, the gradient and Hessian matrixes are determined as follows:
Here, the Jacobian matrix and network errors vector are denoted by \(J\) and \(e\).
By updating the equations, the weight values in each step are obtained as:
It should be noted that \(\eta { }\) is a constant, and due to the condition of performance function in each step, it increases or decreases60.
Bayesian regularization algorithm (BRA)
Like Levenberg–Marquardt, Bayesian regularization algorithm is also used to optimize weights and bias and minimize squares of errors. Weights are determined as follows:
in which, \(\alpha\), \(\beta\), \(E_{D}\), \(E_{w} { }\), and F(ω) are objective function parameters, sum of network errors, sum of squared network weights, and objective function, respectively. Bayes' theorem was used to determine \(\alpha\) and \(\beta\) Moreover Gaussian distribution was employed to develop both network weight and training sets. These parameters are updated and repeated procedure until convergence achieved61.
Boosting method
Schapire62 introduced boosting method which is a type of ensemble methods. In this method, some weak predictors/learners are combined to create a stronger learner. In order to correct previous learners, each weak learner is trained. One of the most popular types of Boosting is Gradient Boosting which is used in this paper.
Gradient boosting (GB)
Gradient boosting is known as one type of Boosting methods. In this type, new learners are applied to residual errors which are made by the previous learners63. The GB could be considered as a form of functional gradient decent (FGD), in which a specific loss is lessened by adding a learner at each step of gradient descent64. The algorithm of GB is as follows:
-
1.
Initialize \(g_{0} \left( y \right) = argmin_{\gamma } \mathop \sum \limits_{q = 1}^{Nu} O\left( {x_{q} ,\gamma } \right)\)
-
2.
Iteration for c = 1: C (C is number if tree learners
-
a.
Compute the negative gradient \(a_{q} = \left[ {\frac{{\partial O(x_{q} ,g\left( {y_{q} } \right)}}{{\partial g\left( {y_{q} } \right)}}} \right]_{{g = g_{c - 1} }} ,{ }q = 1,2, \ldots ,NU\)
-
b.
Set a regression free \(F_{c} \left( y \right)\) to the target \(\left\{ {a_{q} ,{ }q = 1,2, \ldots ,NU} \right\}\)
-
c.
Compute the gradient descent step size by following equation:
$$t = argmin_{\gamma } \mathop \sum \limits_{q = 1}^{Nu} O\left( {x_{q} ,g_{c - 1} \left( {y_{q} } \right) + \gamma F_{c} \left( {y_{q} } \right)} \right)$$ -
d.
Update the model as \(g_{c} \left( y \right) = g_{c - 1} \left( y \right) + tF_{c} \left( y \right)\)
-
a.
-
3.
For data test (y,?) output is \(g_{C} \left( y \right)\)
The parameters of GB used in this study are presented in Table 1.
Results and discussion
In this research, 5040 data points from South Azadgan field in Iran have been used. Table 2 shows the preprocessing of this dataset. In all the developed models, depth (D), weight on bit (WOB), pit total (PT), pump pressure (PP), hook load (H), surface torque (ST), rotary speed (RS), flow in (Fi), flow out (Fo), and wellhead pressure (Wp) were considered as inputs and ROP is regarded as output. Histogram of inputs and output are presented in Fig. 6. As shown in Fig. 6 most of data of surface torque are between 75 and 175 psi. Figure 6 showed that data of flow out and flow in are altered between 50–100% and 600–800 gal/min, respectively (Fig. 6). Hook load data varied from 75–125 k-lbs and most of them are 50 k-lbs (Fig. 6). Data of pump pressure and wellhead pressure are varied from 1000 to 2000 psi and from 0 to 10 psi, respectively (Fig. 6). Pit total data lie between 200 and 280 bbls (Fig. 6). Most of Weight on bit data are around 35 k-lbs (Fig. 6). Most of the rotary speed data in our study were from 25 to100 rpm. Maximum ROP in our data is around 25 ft/hr (Fig. 6). Figure 7 shows box plot of inputs and output data. As shown in Fig. 7, range of WOB data are lower than 50, while pit total data are higher than 200. The data of hook load varied between 50 and 100 (Fig. 7). The range of surface torque and rotary speed are less than 150 and 100, respectively. In addition, the range of flow out and wellhead pressure are less than 100 and 25, respectively (Fig. 7). As shown in Fig. 7, 25% to 75% of ROP's data are less than 50. Figure 7 shows that pump pressure is varied from 750 to more than 1500. As stated in Fig. 7, all of the flow in data are less than 1000. Figure 8 shows the relation of ROP vs. depth for our data. As shown in Fig. 8, by increasing the depth, ROP will decrease.

Histogram of inputs and output data.

Box plot of inputs and output data.

The relation between ROP and depth.
In first step, in order to estimate ROP based on input parameters, the following correlation was developed based and its coefficients were optimized by GRG:
where a1–a31 are constants which are presented in Table 3. As shown in Eq. (34), all involved parameters are available and recorded during drilling operation. Therefore, this correlation can be used to estimate ROP roughly. Although the developed correlation can give us a good sense of ROP, if we want to have a good estimation of ROP, it is recommended to use artificial intelligence (AI) which are more flexible and could solve complicated problems. In this study, AI methods namely, LSSVM, MLP, RBF, and DT were used. In order to develop AI models, first, the databank was randomly separated into two subgroups known as the training set, in which the model learns and tries to find best and optimum predictive model, and the test set, which is used to investigate the prediction capability of the developed model. Classification of data points for intelligent models and the developed correlation are as follow:
-
1.
80 percent of the data were used for training
-
2.
20 percent of the data were used for testing
LMA, BR, and SCG are the three algorithms developed for MLP model and GB is the optimization technique used for DT model.
Statistical evaluation
In order to evaluate and compare the developed models in this study, statistical analysis of errors is performed. For this purpose, the values of standard deviation (SD), average absolute percent relative error (AAPRE), coefficient of determination (R2), root mean square error (RMSE), and the average percent relative error (APRE) are computed and the results are summarized in Table 4. Equations (35)–(39) presented the formulation employed to calculate the aforementioned parameters58,65.
Two suitable statistical errors to compare the developed models are AAPRE and R2. As presented in Table 4, R2 of the developed correlation is 0.807. Then, among different MLP models, the best performance was for BRA, followed by LMA and SCGA. R2 of MLP-SCGA, MLP-LMA, and MLP-BRA were 0.944, 0.965, and 0.969, respectively. AAPRE of these models is in good agreement with the R2 results, 13.88% for MLP-BRA, 14.05% for MLP-LMA, and 18.49% for MLP-SCGA. As shown in Table 4, RBF had the worst performance among the developed models. AAPRE and R2 of this model are 21.409% and 0.937, respectively. R2 and AAPRE for LSSVM are 0.971 and 10.497%, respectively. As stated in Table 4, DT-GB had the best performance among the developed models. AAPRE for this model is 9.013% and its R2 is 0.977. Therefore, DT-GB has the best performance among the developed models, followed by LSSVM, MLP-BR, MLP-LM, MLP-SCG, and RBF.
Graphical analysis of models
Figure 9 shows the crossplots for the developed models. In these plots, the values of modeled ROP are plotted versus experimental data. The more data around the line Y = X is, the more accurate the model will be. In other words, line Y = X is a visual criterion for quick examination of model accuracy. Parameter R2 specifies how much data sets conform to the line of Y = X. In other words, as far as R2 is closer to 1, the degree of conformance of the model with the experimental data is more remarkable. Subplot (a) of Fig. 9 presents crossplots of the developed models. As shown in subplot (a), until ROP of 50, the developed correlation obtains an acceptable prediction. However, at high ROP values, scattering of data around 45o line is obvious. As shown in subplot (b) of Fig. 9, except at high ROP values, concentration of the data around the unit slope line is well for MLP-LMA. Concentration of training set around the unit slope line is better than testing set in MLP-LMA model. The same results were achieved for MLP-BRA; however, a better concentration of the data is noticed in MLP-BRA than MLP-LMA (subplot (c) of Fig. 9). However, scattering of data is obvious for MLP-SCGA (subplot (d) of Fig. 9). Scattering of the testing set is obvious and much more than the training data. In subplot (e) of Fig. 9, it can be seen that the estimations of RBF model are scattered around the Y = X line. Scattering of the testing data both at high and low ROP values is obvious. Although scattering of the test data is obvious, concentration of the training data around the Y = X line is acceptable for LSSVM (subplot (f) of Fig. 9. Subplot (g) of Fig. 9 shows that the best performance among AI models belongs to DT-GB. As shown in subplot (g) of Fig. 9, concentration of the data around 45° straight line is good.

Cross plots of the implemented intelligent models.
Error distribution of the proposed correlation and developed models is presented in Fig. 10. In each subplot, the percent relative error is plotted against rate of penetration. Subplot (a) of Fig. 10 shows that the developed correlation has reasonable prediction at low ROP values and concentration of the data points around the zero-error line is good. As shown in subplot (b) of Fig. 10, concentration of the data sets around the zero-error line is suitable. In addition, subplot (c) of Fig. 10 shows a much better concentration of the data for MLP-BRA around the zero-error line than MLP-LMA. However, concentration of the data points, which are estimated by model MLP-SCGA, around zero-error line is not as good as that of the two other MLP models (subplot (d) of Fig. 10). Statistical analysis showed that the performance of RBF is not well. Both cross plot and error distribution of RBF confirmed this finding (subplot (e) of Fig. 10). As illustrated in subplot (f) of Fig. 10, concertation of the training data around the zero-error line is satisfactory for LSSVM model, although concentration of the testing data was not well at some points. As displayed in subplot (e) of Fig. 10, the predictions of DT-GB display very appropriate concentration around the zero-error line at both high and low ROP values. The subplot (e) of Fig. 10 supports the superiority of DT-GB.

Error distribution plots of the proposed models.
Figure 11 shows comparison between experimental ROP and ROP predicted values by DT-GB model for the first 100 testing data points. As shown in Fig. 11, the best developed model in this study, DT-GB, has good predictions. Except in some data points, the predictions of DT-GB match well with the experimental ROP.

Comparison of experimental data and output of DT-GB model for the first 100 testing data points.
Figure 12 shows the comparison of statistical errors for developed models using bar chart. Each subplot of Fig. 12 confirms that the best and worst performance belong to DT-GB and RBF, respectively.

Comparison of statistical errors of the intelligent models.
3D plot of absolute relative error of DT-GB model versus different parameters including, hook load, depth, ROP, and WOB, are shown in Fig. 13. As shown in subplot (a) of Fig. 13, maximum absolute relative error is seen when WOB is around 18 k-lbs and depth is 4000 ft. In subplot (b) of Fig. 13, once ROP is 14 ft/hr, and depth is 4000 ft, maximum absolute relative error is reported. Also, at Hook load 90 k-lbs and depth of 4000 ft, the model has high error.

Absolute relative error contour versus different parameters (a) WOB and depth (b) ROP and depth (c) hook load and depth.
Figure 14 shows cumulative frequency vs. absolute relative error. Above 50% of the predicted ROP values by DT-GB models have an absolute relative error of less than 10%. 50% of the predicted ROP by LSSVM have an error less than 10%. About 50% of the predicted values by MLP-LMA and MLP-BR models have an absolute relative error of less than 10%. For MLP-SCG and RBF, about 40% and around 30% of the predicted ROP values, respectively, have an absolute relative error of less than 10%.

Cumulative frequency vs. absolute relative error of different models proposed in this study.
Sensitivity analysis
A sensitivity analysis was investigated to study the quantitative effects of all input parameters on the ROP of the developed model. Relevancy factor with directionality (r) was chosen for this purpose. The value of r and its sign show the level of effect of input on the output of model and the impact direction, respectively66. The following formula shows the definition of r:
In the above equation, \(In_{k}\) and \(OU\) show the nth input of the model and the predicted ROP, respectively. The relative effect of input variables on the ROP estimated by the proposed DT-GB model is shown in Fig. 15. As shown in Fig. 15, pit total, rotary speed, and flow in, have a positive effect on the ROP, while depth, weight on bit, pump pressure, hook load, surface torque, and wellhead pressure have negative impacts on the ROP. The highest absolute value of r belongs to depth; therefore, depth has the most important effect among the inputs on the predicted ROP value.

The relative effect of input variables on the ROP based on DT-GB model.
Applicability area of the developed model and outlier analysis
Outliers are the data that may vary from the bulk of the data. Frequently, these types of data are expected to appear in large sets of experimental data. The presence of such data can affect the accuracy and reliability of models. Hence, finding these data is necessary in the development of models67,68,69,70,71. In this study, leverage approach has been employed for determining outliers67,69,70,71. In this method, deviation of predicted valued from corresponding experimental data, was calculated. More details about this method can be found in literature67,68,69,70.
Figure 16 shows the William's plot for the predicted ROP obtained by the DT-GB model. Data of out of leverage and suspected data, presented in Fig. 16, can be found in Table 5. As shown in Fig. 16, majority of the data points are positioned in the applicability domain (− 3 ≤ R ≤ 3 and 0 ≤ hat ≤ 0.0057). Therefore, the developed model, DT-GB, has statistical validity and high reliability. A small amount of data is out of the applicability domain, which is negligible. In this plot, we have two important definitions, Good High Leverage and Bad High Leverage. Good High Leverage data are known as data that their R is located between 3 and -3 and their hat* ≤ hat. These data points are different from the bulk of data and they are out of feasibility domain of the developed model, however, they may be predicted well by developed model. If R of data are less than -3 or are more than 3, these data are known as Bad High Leverage. These data are experimentally doubtful data or outliers67,68,69,70.

William's plot for discovering the probable outliers and the feasibility domain of the developed model, DT-GB, in this study.
Conclusions
In this study, new methods were used to predict drilling rates. Since the parameters affecting the drilling rates are different, as well as the conditions vary from field to field, it is always difficult to develop a comprehensive, efficient, and precise model. The model that can accommodate more parameters, could better predict the drilling rate. Therefore, we tried to develop a correlation and smart models including MLP, RBF, LSSVM, and DT, with ten input parameters. The main findings of this study are as follows:
-
1.
The developed correlation and smart models need parameters that are accessible in field and can give fast prediction of ROP.
-
2.
All four smart models have a good prediction of drilling rates, which would increase the tendency to use smart methods to predict drilling rates.
-
3.
The best predictions belong to DT-GB model with R2 of 0.977. In addition, the LSSVM model has acceptable performance. R2 of this model was 0.969. In addition, MLP models have good performance and finally the worst performance among the developed models belongs to RBF.
-
4.
Sensitivity analysis showed that flow in, rotary speed, and pit total have positive effects on ROP, while other parameters have negative effects. Among input parameters, depth has the greatest effect on ROP.
-
5.
The leverage approach indicated that the developed DT-GB model is statistically valid and only few data points are located out of the applicability domain of the model.
Abbreviations
- RBF:
-
Radial basis function
- DT:
-
Decision tree
- MLP:
-
Multilayer perceptron
- LMA:
-
Levenberg_Marquardet algorithm
- BRA:
-
Bayesian regularization algorithm
- SCGA:
-
Scaled conjugate gradient algorithm
- GB:
-
Gradient boosting
- APRE:
-
Average percent relative error
- AAPRE:
-
Average absolute relative error
- RMSE:
-
Root mean square error
- SD:
-
Standard deviation
- ML:
-
Machine learning
- BYM:
-
Bourgoyne and Yong model
- WOB:
-
Weight on bit
- ANN:
-
Artificial neural network
- D:
-
Depth
- PT:
-
Pit total
- PP:
-
Pump pressure
- H:
-
Hookload
- ST:
-
Surface torque
- RS:
-
Rotary speed
- Fi:
-
Flow in
- Fo:
-
Flow out
- Wp:
-
Wellhead pressure
- AID:
-
Automatic interaction detection
- AI:
-
Artificial intelligence
- RPM:
-
Revolutions per minute
- UCS:
-
Uniaxial compressive strength
- PV:
-
Plastic viscosity
- MW:
-
Mud weight
- YP:
-
Yield point
- ELM:
-
Extreme learning machine
- THAID:
-
THeta Automatic Interaction Detection
- GRG:
-
Generalized reduced gradient
- LSSVM:
-
Least Square Support Vector Machine
- PDC:
-
Polycrystalline diamond compact
- SVR:
-
Support vector regression
- CSVR-ICA:
-
Committee support vector regression based on imperialist competitive algorithm
- CIT:
-
Computational intelligence techniques
- LS-SVR:
-
Least-square support vector regression
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- SVM:
-
Support vector machine
References
Bahari, M. H., Bahari, A. & Moradi, H. Intelligent drilling rate predictor. Int. J. Innov. Comput. Inf. Control. 7(2), 1511–20 (2011).
Hadi, H. A. & Engineering, P. Correlation of penetration rate with drilling parameters for an Iraqi field using mud logging data. Iraqi J. Chem. Petrol. Eng. 16(3), 35–44 (2015).
Kaiser, M. J. Technology: a survey of drilling cost and complexity estimation models. Int. J. Petrol. Sci. Technol. 1(1), 1–22 (2007).
Barbosa, L. F. F., Nascimento, A., Mathias, M. H. & de Carvalho Jr, J. A. Machine learning methods applied to drilling rate of penetration prediction and optimization: a review. J. Petrol. Sci. Eng. 183, 106332 (2019).
Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H. & Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 21(6), 1087–1092 (1953).
Soares, C. & Gray, K. Real-time predictive capabilities of analytical and machine learning rate of penetration (ROP) models. J. Petrol. Sci. Eng. 172, 934–959 (2019).
Akgun, F. Drilling rate at the technical limit. J. Petrol. Sci. Technol. 1(1), 99–119 (2007).
Bataee, M., Irawan, S. & Kamyab, M. Artificial neural network model for prediction of drilling rate of penetration and optimization of parameters. J. Jpn. Petrol. Inst. 57(2), 65–70 (2014).
Paone, J., Madson, D. Drillability Studies: Impregnated Diamond Bits. Department of the Interior, Bureau of Mines (1966).
Khosravanian, R., Sabah, M., Wood, D. A. & Shahryari, A. Weight on drill bit prediction models: Sugeno-type and Mamdani-type fuzzy inference systems compared. J. Nat. Gas Sci. Eng. 36, 280–97 (2016).
Paone, J., Bruce, W. E., Virciglio, P. R. Drillability Studies: Statistical Regression Analysis of Diamond Drilling. US Dept. of the Interior, Bureau of Mines (1966).
Ayoub, M., Shien, G., Diab, D. & Ahmed, Q. Modeling of drilling rate of penetration using adaptive neuro-fuzzy inference system. Int J Appl Eng Res 12(22), 12880–91 (2017).
Ersoy, A., Waller, M. Prediction of drill-bit performance using multi-variable linear regression analysis. In International Journal of Rock Mechanics and Mining Sciences and Geomechanics Abstracts. 6, 279A (1995).
Mendes, J. R. P., Fonseca, T. C., Serapião, A. Applying a genetic neuro-model reference adaptive controller in drilling optimization. 29–36 (2007).
Mitchell, R., Miska, S. Fundamentals of Drilling Engineering; Society of Petroleum Engineers, Inc.: Richardson, TX, USA, 2011; Chapter 4. Google Scholar.
Maurer, W. The, “perfect-cleaning” theory of rotary drilling. J. Petrol. Technol. 14(11), 1270–1274 (1962).
Bingham G. A new approach to interpreting rock drillability. Tech. Manual Reprint Oil Gas J., 93, 1965 (1965).
Bourgoyne, Jr. A. T., Millheim, K. K., Chenevert, M. E., Young, Jr F.S. Applied drilling engineering. (1991).
Bourgoyne, A. T. Jr. & Young, F. Jr. A multiple regression approach to optimal drilling and abnormal pressure detection. Soc. Petrol. Eng. J. 14(04), 371–384 (1974).
Eren, T. & Ozbayoglu, M. E. Real time optimization of drilling parameters during drilling operations (Society of Petroleum Engineers, 2010).
Hareland, G., Rampersad, P. Drag-bit model including wear. In SPE Latin America/Caribbean Petroleum Engineering Conference. Society of Petroleum Engineers; 1994.
Soares, C., Daigle, H. & Gray, K. Evaluation of PDC bit ROP models and the effect of rock strength on model coefficients. J. Nat. Gas Sci. Eng. 34, 1225–1236 (2016).
Motahhari, H. R., Hareland, G. & James, J. Improved drilling efficiency technique using integrated PDM and PDC bit parameters. J. Can. Pet. Technol. 49(10), 45–52 (2010).
Deng, Y., Chen, M., Jin, Y., Zhang, Y., Zou, D., Lu, Y., et al. Theoretical and experimental study on the penetration rate for roller cone bits based on the rock dynamic strength and drilling parameters. 36, 117–123 (2016).
Al-AbdulJabbar, A., Elkatatny, S., Mahmoud, M., Abdelgawad, K., Al-Majed, A. A robust rate of penetration model for carbonate formation. J. Energy Resour. Technol. 141(4) (2019).
Elkatatny, S. New approach to optimize the rate of penetration using artificial neural network. 1–8 (2017).
Warren, T. J. S. D. E. Penetration rate performance of roller cone bits. 2(01):9–18 (1987).
Hareland, G., Hoberock, L. Use of drilling parameters to predict in-situ stress bounds. In SPE/IADC Drilling Conference. Society of Petroleum Engineers (1993).
Hareland, G., Wu, A., Rashidi, B. A drilling rate model for roller cone bits and its application. In International Oil and Gas Conference and Exhibition in China. Society of Petroleum Engineers (2010).
Hareland G, Wu A, Rashidi B, James J. A new drilling rate model for tricone bits and its application to predict rock compressive strength. In 44th US Rock Mechanics Symposium and 5th US-Canada Rock Mechanics Symposium. American Rock Mechanics Association (2010).
Eckel JR. Microbit studies of the effect of fluid properties and hydraulics on drilling rate, ii. In Fall Meeting of the Society of Petroleum Engineers of AIME. Society of Petroleum Engineers; 1968.
Paiaman, A. M., Al-Askari, M., Salmani, B., Alanazi, B. D., Masihi, M. J. N. Effect of drilling fluid properties on rate of Penetration. 60(3), 129–34 (2009).
Moraveji, M. K., Naderi, M. Drilling rate of penetration prediction and optimization using response surface methodology and bat algorithm. 31, 829–41 (2016).
Arabjamaloei, R. & Shadizadeh, S. Modeling and optimizing rate of penetration using intelligent systems in an Iranian southern oil field (Ahwaz oil field). Pet. Sci. Technol. 29(16), 1637–1648 (2011).
Amar, K., Ibrahim, A. Rate of penetration prediction and optimization using advances in artificial neural networks, a comparative study. In 4th International Joint Conference on Computational Intelligence, 647–52 (2012).
Hegde, C., Daigle, H., Millwater, H. & Gray, K. Analysis of rate of penetration (ROP) prediction in drilling using physics-based and data-driven models. J. Petrol. Sci. Eng. 159, 295–306 (2017).
Bilgesu, H., Tetrick, L., Altmis, U., Mohaghegh, S. & Ameri, S. A new approach for the prediction of rate of penetration (ROP) values (Society of Petroleum Engineers, 1997).
AlArfaj, I., Khoukhi, A., Eren, T. Application of advanced computational intelligence to rate of penetration prediction. In Computer Modeling and Simulation (EMS), 2012 Sixth UKSim/AMSS European Symposium on. IEEE; 33–38 (2012).
Ansari, H. R., Hosseini, M. J. S. & Amirpour, M. Drilling rate of penetration prediction through committee support vector regression based on imperialist competitive algorithm. Carbonates Evaporites 32(2), 205–213 (2017).
Ashrafi, S. B., Anemangely, M., Sabah, M. & Ameri, M. J. Application of hybrid artificial neural networks for predicting rate of penetration (ROP): a case study from Marun oil field. J. Petrol. Sci. Eng. 175, 604–623 (2019).
Diaz, M. B., Kim, K. Y., Shin, H.-S. & Zhuang, L. Predicting rate of penetration during drilling of deep geothermal well in Korea using artificial neural networks and real-time data collection. J. Nat. Gas Sci. Eng. 67, 225–232 (2019).
Gan, C. et al. Prediction of drilling rate of penetration (ROP) using hybrid support vector regression: a case study on the Shennongjia area, Central China. J. Petrol. Sci. Eng. 181, 106200 (2019).
Mehrad, M., Bajolvand, M., Ramezanzadeh, A., Neycharan, J. G. Developing a new rigorous drilling rate prediction model using a machine learning technique. J. Petrol. Sci. Eng. 107338 (2020).
Gill, P. E., Murray, W., Wright, M. H. Practical Optimization. Academic Press, New York (1981).
Ameli, F., Hemmati-Sarapardeh, A., Dabir, B. & Mohammadi, A. H. Determination of asphaltene precipitation conditions during natural depletion of oil reservoirs: a robust compositional approach. Fluid Phase Equilib. 412, 235–248 (2016).
Wilde, D. J., Beightler, C. S. Foundations of Optimization (1967).
Sharma, R. & Glemmestad, B. On generalized reduced gradient method with multi-start and self-optimizing control structure for gas lift allocation optimization. J. Process Control 23(8), 1129–1140 (2013).
David, C. Y., Fagan, J. E., Foote, B. & Aly, A. A. An optimal load flow study by the generalized reduced gradient approach. Electric Power Syst. Res. 10(1), 47–53 (1986).
Abadie, J. Generalization of the Wolfe reduced gradient method to the case of nonlinear constraints. Optimization 37–47 (1969).
Morgan, J. N. & Sonquist, J. A. Problems in the analysis of survey data, and a proposal. J. Am. Stat. Assoc. 58(302), 415–434 (1963).
Messenger, R. & Mandell, L. A modal search technique for predictive nominal scale multivariate analysis. J. Am. Stat. Assoc. 67(340), 768–772 (1972).
Song, Y.-Y. & Ying, L. Decision tree methods: applications for classification and prediction. Shanghai Arch. Psychiatry 27(2), 130 (2015).
Patel N, Upadhyay S. Study of various decision tree pruning methods with their empirical comparison in WEKA. Int. J. Comput. Appl. 60(12) (2012).
Ameli, F., Hemmati-Sarapardeh, A., Schaffie, M., Husein, M. M., Shamshirband, S. J. F. Modeling interfacial tension in N 2/n-alkane systems using corresponding state theory: application to gas injection processes. 222, 779–791 (2018).
Hemmati-Sarapardeh, A., Varamesh, A., Husein, M. M., Karan, K. J. R., Reviews, S. E. On the evaluation of the viscosity of nanofluid systems: modeling and data assessment. 81, 313–329 (2018).
Karkevandi-Talkhooncheh, A., Rostami, A., Hemmati-Sarapardeh, A., Ahmadi, M., Husein, M. M., Dabir, B. J. F. Modeling minimum miscibility pressure during pure and impure CO2 flooding using hybrid of radial basis function neural network and evolutionary techniques. 220, 270–282 (2018).
Varamesh, A., Hemmati-Sarapardeh, A., Dabir, B., Mohammadi, A. H. Development of robust generalized models for estimating the normal boiling points of pure chemical compounds. 242, 59–69 (2017).
Rostami, A., Hemmati-Sarapardeh, A., Shamshirband, S. J. F. Rigorous prognostication of natural gas viscosity: smart modeling and comparative study. 222, 766–778 (2018).
Suykens, J. A. & Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 9(3), 293–300 (1999).
Hagan, M. T. & Menhaj, M. B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Networks 5(6), 989–993 (1994).
Yue, Z., Songzheng, Z., Tianshi, L. Bayesian regularization BP Neural Network model for predicting oil-gas drilling cost. In 2011 International Conference on Business Management and Electronic Information. 2. IEEE; 483–487 (2011).
Schapire, R. E. The strength of weak learnability. Mach. Learn. 5(2), 197–227 (1990).
Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning (Springer, 2009).
Friedman, J. H. Stochastic gradient boosting. Comput. Stat. Data Anal. 38(4), 367–378 (2002).
Rostami, A., Baghban, A., Mohammadi, A. H., Hemmati-Sarapardeh, A., Habibzadeh, S. J. F. Rigorous prognostication of permeability of heterogeneous carbonate oil reservoirs: smart modeling and correlation development. 236, 110–123 (2019).
Tohidi-Hosseini, S.-M., Hajirezaie, S., Hashemi-Doulatabadi, M., Hemmati-Sarapardeh, A. & Mohammadi, A. H. Toward prediction of petroleum reservoir fluids properties: a rigorous model for estimation of solution gas-oil ratio. J. Nat. Gas Sci. Eng. 29, 506–516 (2016).
Leroy, A. M., Rousseeuw, P. J. Robust regression and outlier detection. rrod (1987).
Hemmati-Sarapardeh, A., Ameli, F., Dabir, B., Ahmadi, M. & Mohammadi, A. H. On the evaluation of asphaltene precipitation titration data: Modeling and data assessment. Fluid Phase Equilib. 415, 88–100 (2016).
Goodall, C. R. 13 Computation using the QR decomposition (1993).
Gramatica, P. Principles of QSAR models validation: internal and external. QSAR Comb. Sci. 26(5), 694–701 (2007).
Mohammadi, A. H., Eslamimanesh, A., Gharagheizi, F. & Richon, D. A novel method for evaluation of asphaltene precipitation titration data. Chem. Eng. Sci. 78, 181–185 (2012).
Mehrjoo, H., Riazi, M., Amar, M. N., Hemmati-Sarapardeh, A. Modeling interfacial tension of methane-brine systems at high pressure and high salinity conditions. J. Taiwan Inst. Chem. Eng. (2020).
Author information
Authors and Affiliations
Contributions
M.R.: Investigation, Modelling, Visualization, Writing-Original Draft, H.M.: Investigation, Validation, Writing-Original Draft, R.N.: Writing-Review & Editing, Experiments, H.J.: Writing-Review & Editing, Validation, Supervision, M.S.: Writing-Review & Editing, Modelling, M.R.: Writing-Review & Editing, Validation, Supervision, M.O.: Writing-Review & Editing, Validation, Funding, A.H.-S.: Writing-Review & Editing, Methodology, Validation, Supervision, Writing-Review & Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Riazi, M., Mehrjoo, H., Nakhaei, R. et al. Modelling rate of penetration in drilling operations using RBF, MLP, LSSVM, and DT models. Sci Rep 12, 11650 (2022). https://doi.org/10.1038/s41598-022-14710-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-14710-z
This article is cited by
-
Hybrid physics-machine learning models for predicting rate of penetration in the Halahatang oil field, Tarim Basin
Scientific Reports (2024)
-
An ensemble-based machine learning solution for imbalanced multiclass dataset during lithology log generation
Scientific Reports (2023)
-
Enhancing Rock Drilling Efficiency: A Comparative Analysis of DRI Estimation Models Using the RES Approach
Indian Geotechnical Journal (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
