
Abstract
The analysis of the public interest as reflected by Internet queries has become a highly valuable tool in many fields. The Google Trends platform, providing timely and informative data, has become increasingly popular in health and medical studies. This study explores whether Internet search frequencies for the keyword “headache” have been increasing after the COVID-19 pandemic outbreak, which could signal an increased incidence of the health problem. Weekly search volume data for 5 years spanning February 2017 to February 2022 were sourced from Google Trends. Six statistical and machine-learning methods were implemented on training and testing sets via pre-set automated forecasting algorithms. Holt-Winters has been identified as overperforming in predicting web query trends through several accuracy measures and the DM test for forecasting superiority and has been employed for producing the baseline level in the estimation of excess query level over the first pandemic wave. Findings indicate that the COVID-19 pandemic resulted in an increased global incidence of headache (as proxied by related web queries) in the first 6 months after its outbreak, with an excess occurrence of 4.53% globally. However, the study also concludes that the increasing trend in headache incidence at the world level would have continued in the absence of the pandemic, but it has been accelerated by the pandemic event. Results further show mixed correlations at the country-level between COVID-19 infection rates and population web-search behavior, suggesting that the increased headache incidence is caused by pandemic-related factors (i.e. increased stress and mental health problems), rather than a direct effect of coronavirus infections. Other noteworthy findings entail that in the Philippines, the term "headache" was the most frequently searched term in the period spanning February 2020 to February 2022, indicating that headache occurrences are a significant aspect that defines population health at the country level. High relative interest is also detected in Kenya and South Africa after the pandemic outbreak. Additionally, research findings indicate that the relative interest has decreased in some countries (i.e. US, Canada, and Australia), whereas it has increased in others (i.e. India and Pakistan) after the pandemic outbreak. We conclude that observing Internet search habits can provide timely information for policymakers on collective health trends, as opposed to ex-post statistics, and can furthermore yield valuable information for the pain management drug market key players about aggregate consumer behavior.
Similar content being viewed by others


Introduction
The Coronavirus Disease 2019 (COVID-19) pandemic is being dubbed a Black-Swan event 1, with significant socio-economic consequences2,3,4,5, and of high impact on physical and psychological health6,7,8. It is thus widely recognized that COVID-19 has affected health and wellbeing globally, and its impact is multi-faceted9,10.
With the pandemic moving into its third year, an accurate assessment of its effects from various perspectives and on different geographies is paramount for estimating the magnitude of the pandemic's impact and most importantly for extracting valuable lessons and informing policy. However, relevant statistics are not published or are published with significant delay, which raises significant challenges for scientific researchers to deliver timely studies11.
It would be informative and instructive for policymakers and key players in the global pain management drug market to know whether the pandemic caused an increased occurrence of various pain, although such information is either undetectable, received too late, or both. Suggestions that people are suffering more from headaches in the aftermath of the COVID-19 outbreak have appeared in scientific journals and newspapers12,13, Business14, Atlantic15). Furthermore, quarantine imposed during previous pandemics (i,e. SARS, and Ebola) has been linked to various negative psychological impacts, which could in turn trigger headaches and migraine16,17. Consequently, one could reasonably link the COVID-19 pandemic with higher headache incidence. However, an increased occurrence of headache can be attributed both to the direct effect of the virus18, or to various collateral pandemic-related factors, including increased concern for personal safety, increased mental health problems, such as anxiety and depression caused by quarantine and lockdown, and resulting from negative socioeconomic outcomes of measures imposed worldwide4,19,20.
This assessment is important from at least two perspectives: (1) for policymakers, it provides relevant evidence that helps to accurately assess the impact and consequences of COVID-19; additionally, it informs whether excess occurrences of headache unrelated to direct exposure to the virus could have contributed to straining the health care system over a tumultuous period, thus extracting valuable lessons; (2) for the global pain management drug market players, it provides valuable data on aggregate consumer behavior over distinct geographical regions.
To our knowledge, however, this evaluation has not been accomplished and the topic remains under-investigated, mainly due to the unavailability of official statistics.
To address such challenges, monitoring the health-seeking behavior in the form of public interest reflected by web search queries has emerged as an important tool for early detection of health problems occurrences over certain periods and geographies21. Health facilities and insurance firms could potentially report relevant data to highlight incidences of headaches occurring during the pandemic. However, these data are not readily available, and for many countries are never reported. Additionally, even if ultimately reported, these data would only be of service for ex-post research. Furthermore, health facilities provided limited services during the pandemic22. Although telemedicine (i.e. the provision of health services to patients in a remote location by using telecommunication technology23, and virtual health care emerged as promising alternatives to the classical health-service provision model during the COVID-19 Pandemic24 by overcoming the risk of in-person exposure25, it is a reasonable assumption that not everyone suffering from headaches sought treatment through health facilities (including by using telehealth) and the insurance system. Thus, given the above considerations, the web search volume queries emerge as the best source of relevant information capable of capturing variations in headache occurrences during the COVID-19 pandemic.
Google has been the absolute leader search engine provider for the past decades, holding a market share of 86.19% as of December 202126,27. Furthermore, the Internet has become an increasingly important source of health information28, with over a billion health-related queries passing through Google daily, which accounts for an estimated 7% of Google's daily searches as of 201930. Consequently, Google Trends has been increasingly used over the last decade in the health and medical research21,31. Moreover, it is further estimated that the pandemic has increased Internet searches for health information in 2020 compared to 2019 (Statistics Netherlands (CBS)32).
Thus, this study sources Google Trends data to extract relevant information for variation in a public health variable (i.e. headache occurrence) at the world level that could not have been otherwise detected. Of note, this study uses “worldwide” web query index data as per the terminology employed by the Google Trends platform, although the term might be misleading due to some noteworthy exceptions (i.e., countries where Google is not active and/or Google Trends data is not available, such as China, the Russian Federation, and most of the African countries). Later in the study, Fig. 3 reflects all countries for which query data is available/unavailable and thus have been included in/excluded from this study. In this respect, the research builds on previous studies that have acknowledged the usefulness of web search data for predicting influenza occurrence, detecting strong correlations between web searches for a health problem, and retrospective surveillance data on that particular health problem reported by official statistics28,33; Ginsberg et al., 2009. These studies formed the foundations for the so-called infodemiology (or information epidemiology), a method for studying epidemiology-related data that provides faster access to information compared to standard epidemiological studies and can also uncover otherwise undetectable information34,35,36,37,38.
Furthermore, it has been acknowledged that the volume of search queries reflected in Google Trends data is an important predictor of private consumption and retail sales39,40,41. Thus, it is a reasonable assumption that an increase in web searches for a health problem reflects an increase in its occurrence rate that would result in increased private consumption of related medicine.
The main contributions of this paper are threefold:(1) we propose a reliable approach for web query volume forecasting that embeds a pool of relevant statistical and machine-learning forecasting models; (2) we provide a quantitative assessment of excess headache occurrences in the aftermath of the COVID-19 pandemic’s outbreak; and (3) we explore whether the positive link between the pandemic outbreak and increased incidence of headache is a direct consequence of infection or is due to other pandemic-related factors.
Hence, Google Trends query volumes related to the search term “headache” and six statistical and machine-learning predictive models fitted through automated forecasting algorithms are used to estimate headache occurrences in the 6 months following February 2020 and compute excess headache after the pandemic outbreak at the end of January 2020. In this context, COVID-19 excess headaches refer to increases in headaches over what would “normally” have been expected. The “normal” evolution of headache occurrences is projected by the best-perfuming predictive model, which is identified to be Holt-Winters. The best in-sample fit and most importantly, out-of-sample forecasting performance is firstly assured through several accuracy measures and the DM test for forecasting superiority. We find that Holt-Winters is capable of capturing most of the characteristics of the series and producing the most accurate estimations on out-of-same data. Thus, forecasts issued through HW are employed as proxies for the normal evolution of headache web searches. The actual registered values are subsequently compared to the projected “normal” values and excess headache incidence caused by the pandemic is estimated. Results indicate that the pandemic has resulted in excess headaches that would not have occurred in the absence of the pandemic. The countries most affected by headache over the COVID-19 pandemic, as proxied by web searches over the 6 months spanning February 2020–July 2020 are the Philippines, Kenya, and South Africa, whereas before the pandemic most web queries for the keyword were submitted in the Philippines, South Africa, and the US. The study thus concludes that the increasing trend in headache incidence at the world level would have continued in the absence of the pandemic, but that COVID-19 has contributed to its acceleration, causing an excess occurrence in headache (as proxied by web query interest) of 4.53% globally. At the country level, findings show mixed correlations between coronavirus cases and web-searches for the term “headache, which is indicative of a causal relationship running from other pandemic-related factors (i.e. increased stress, anxiety, depression, etc.) to the increased headache incidence. We thus conclude that increased headache occurrence after the COVID-19 outbreak is a result of pandemic-related factors, rather than a consequence of the coronavirus disease.
The remainder of the study is organized as follows. "Previous literature" performs a review of the extant literature. "Data" presents the data employed in the empirical investigation and discusses its historical trends. "Method" illustrates the implemented method. "Results" contains the empirical results and performs robustness checks. "Discussion" discusses the main research findings, and finally, "Conclusion" concludes the study.
Previous literature
Some aspects that have allowed for timely COVID-19 related research, owing to data availability, are the excess in mortality and hospitalization rates caused by the COVID-19 pandemic, as well as the connection between previous health conditions, such as obesity, and the risk of infection, hospitalization, and death from the novel coronavirus42. In this context, COVID-19 excess mortality or hospitalizations refer to mortality/hospitalizations that would not have occurred in the absence of the pandemic43. In particular, excess mortality is defined as the surge of all-cause mortality over the level that would have been expected based on historic trends44. Consequently, an increasing strand of literature estimates excess death rates43,45,46,47,48,49,50,51,52,53,54, etc.) or assesses and predicts the spread of COVID-19 as reflected in hospitalization rates55 during the ongoing global health crisis. Specifically, previous studies compare actual death rates reported in different countries to those that would have been expected without the black-swan event occurring. This further implies the need for accurate proxies for the level of the variable of interest under “normal” conditions. One approach is to evaluate the excess of deaths compared to the same period in the previous year or an average over recent years (among others 11,56). Stang et al.53 employ weekly observations and estimate the mean number of deaths corresponding to the 2016–2019 period to estimate expected weekly numbers for 2020. Modig et al.57 also use weekly observations for Sweden to identify the baseline level as the average weekly death counts between 2015 and 2019, and subsequently estimate excess mortality by subtracting the baseline level from the observed weekly counts from 2020.
However, this is inconsistent with data that presents strong trends and seasonality. Consequently, another approach has been proposed to correct this inconsistency. This consists in producing estimates for what would have occurred during “normal’ circumstances by using historical data for the variable of interest and employing univariate forecasting models to predict its evolution for the calendar period corresponding to the COVID-19 pandemic. The estimated trend thus proxies for the “normal” evolution of the variable in the absence of the pandemic and is used as a baseline in computing excess (or abnormal) evolutions. Previous studies most often employ the ETS model58, the ARIMA model59,60, the TBATS model61, and the artificial neural network (ANN) models62. Some authors estimate multiple models in an attempt to improve inference and forecasting ability. For example, Borrego–Morell et al.45 use three statistical methods (i.e. GLM, ETS, and ARIMA) to model the historical evolution and produce estimates of excess mortality rates in Brazil and Spain, and identify ARIMA as overperforming in out-of-sample prediction. The model is then employed to produce estimates for the baseline level with which actual reported rates are compared and excess rates of deaths computed. Perone55 estimates ARIMA, ETS, NNAR, TBATS in an attempt to forecast the number of patients hospitalized with mild symptoms and the number of patients hospitalized in the intensive care units (ICU) in Italy, and identifies the best single models as NNAR and ARIMA, while also showing that model combinations generally outperform single models by providing more accurate predictions. Scortichini et al.63 estimate a two-stage time-series model, where first a quasi-Poisson time-series regression model with smooth spline functions for time variables and observed predictors is estimated at the province level, and subsequently, the estimates are pooled using a mixed-effects multivariate meta-analysis. Morciano et al.64 use data on the number of deaths in all residential and nursing homes in England and apply a Poisson regression model to the pre-pandemic data to forecast the “normal” death count, which is subsequently used as the baseline level in estimating excess deaths. Next, Dahal et al.65 first fit Serfling regression models and then employed the generalized logistic growth model to forecast the total excess deaths caused by the COVID-19 pandemic in Mexico. More recently, Talkhi et al.66 estimate nine statistical and machine-learning models and conclude that a neural network model (i.e. the multilayer perceptron) and the Holt-Winters model both present the lowest error in forecasting deaths in Iran.
In this study, we implement a similar multi-model approach to explore an outstanding question, specifically the excess headache that has affected the world population over the COVID-19 pandemic period and investigate any potential shift in the population interest before and during the first wave of the COVID-19 pandemic. To produce the baseline level for headache incidence over the testing period, six statistical and machine-learning models (i.e. ETS, HW, ARIMA, STS, TBATS, and NNAR) are estimated through automated forecasting algorithms.
Data
Google Trends is an online platform that displays the popularity of a search term in a given region over a given period. It offers a time series index of the volume of Google queries submitted in a particular geography. The index reports the query weight or share, expressed as the overall query volume for a particular search term within a geographic region divided by the total number of searches in that region over the period under consideration. Subsequently, the result is scaled on a range of 0–100. Consequently, the maximum query share of a search term for a particular period is normalized to be 100, reflecting the moment at which the search reached the highest popularity. In other words, when the query index is 100, then the ratio of searches for the specific term to the total number of total searches completed in the region is at its greatest point in the specified period. Consequently, the term with the highest interest score is the most frequently searched query within the specified geographical region and period. This is particularly important for extracting the relevancy of web searches in a constantly changing environment.
Consequently, the platform provides a useful tool to measure the popularity of a certain search term among a targeted audience, which can detect health problems early on. In this study, we extract the volume of Google queries for the term “headache” for 5-year period spanning February 15, 2017–February 15, 2022 at the world level. For increased accuracy of results, we have decided toward a smaller, discriminative trend analysis with "terms" as opposed to “topics,” which allows using more targeted, thus more relevant, search queries. It should be mentioned that although headache should be envisioned within a biopsychosocial framework, with biological, psychological, and social/environmental drivers67, the search term within the Google Trends platform mainly refers to headache as a symptom associated with physical pain, which is confirmed by the most related queries (as attested subsequently by Fig. 2). This would further imply that people turn to the Internet to search for the term mostly when dealing with the physical symptoms of the health condition.
The final data series contains 261 weekly observations. To investigate potential differences in query trends after the pandemic outbreak, we subsequently split the data into two sub-samples corresponding to the pre-COVID-19 period and the COVID-19 period, respectively. The starting point of the pandemic is set on to be the week spanning January 27th, 2020–February 2nd, 2020, when two main events occurred on the pandemic’s timeline: on January 31st, 2020, the World Health Organization declared the coronavirus outbreak a Public Health Emergency of International Concern and on February 2nd, 2020 the US implemented new travel policies in response to the novel coronavirus disease68,69. Consequently, the week of February 3, 2020–February 9, 2020, is the first week in the pandemic subsample or window.
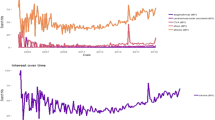
Figure 1 reflects that web searches for the keyword “headache” have steadily increased over the last 5 years at the world level. However, the increasing trend has accelerated over the first 3 months of 2020, with the peak popularity of the term reached on the second and third weeks in March 2020 (i.e. the weeks ending on March 15, 2020, and March 22, 2020, respectively). After April 2020, a slightly declining trend in web searches for “headache” emerged, but the overall interest remained higher in comparison to its pre-pandemic levels. The lower part of the chart offers a zoomed view over the first quarter of 2020, highlighting the acceleration of the increasing trend in February 2020 and its peak reached by mid-March 2020.

Search volume index for the keyword “headache” (February 2017–February 2022, worldwide) (above); zoom in at the period spanning January to May 2020 (below), reflecting the peak popularity of the term reached on the second and third weeks in March 2020.
A deeper look at most related queries in the pre-pandemic and pandemic periods (Fig. 2a,b) indicates a shift from the related term “headache symptoms” before 2020 to “covid headache” during the pandemic period.

Most related queries to the search term “headache”: Pre-pandemic period (February 2017–January 2020) (A); pandemic period (February 2020–February 2022) (B).
Furthermore, analyzing the search interest for the term “headache” at the country level (Fig. 3a,b), we notice that before the pandemic outbreak the highest query shares are encountered in the Philippines (94), followed by South Africa (92) and the US (89). On the other hand, during the COVID-19 pandemic, the highest query shares are reported in the Philippines (100), Kenya (94), and South Africa (89). There is also heterogeneity in population search behavior at the country level. The relative interest for the key term has decreased after the COVID-19 pandemic outbreak in some countries compared to the pre-pandemic period (i.e. from 89 to 79 in the US, from 69 to 60 in Canada, and from 69 to 64 in Australia), whereas it has increased in others (i.e. from 82 to 86 in the UK, from 32 to 39 in India, and from 42 to 45 in Pakistan).

Source: Authors’ representation, created with the “tmap” package (https://cran.r-project.org/web/packages/tmap/vignettes/tmap-getstarted.html) in RStudio 2021.9.1.372.
Web search interest (Google Trends) for term “headache” at country level: Pre-pandemic period (February 2017–January 2020) (A); pandemic period (February 2020–Febraury 2022) (B).
Method
To capture most of the characteristics of the time series and thus avoid unreliable forecasts, we employ an array of linear and nonlinear statistical and machine-learning techniques, including Holt-Winters (HW), Exponential Smoothing State Space Model (ETS), Autoregressive integrated moving average (ARIMA), Structural Time Series (STS), Exponential Smoothing State Space Model with Box-Cox Transformation, ARMA Errors, Trend, and Seasonal Components (TBATS), and the neural network autoregression (NNAR). This approach, with the automated implementation of the methods through pre-set automated forecasting algorithms, allows minimizing the risk of model misspecification. Subsequently, the superior model in terms of out-of-sample predictive ability as indicated by several scaled and scale-free model accuracy metrics (i.e. MAE, MAPE, MASE, RMSE, Theil’s U, ACF1) is used to produce forecasts that act as proxies for the evolution of the index of web-queries for the term “headache” during “normal” conditions, or for what could have been expected in the absence of the pandemic.
Data splitting
To implement the method, the series is split into two subsamples, corresponding to a training period in which the in-sample fit of alternative predictive models is assessed and a testing period (also called a lead-time) in which the best-fit models on the training set are assessed for out-of-sample forecasting ability. We ensure that the two datasets (i.e., the training and testing windows) cover only the pre-pandemic period and, hence, the testing interval does not span into the pandemic timeframe so that any potential shift of data characteristics produced after the outbreak of the COVID-19 pandemic does not affect the out-of-sample accuracy of the alternative predictive models. Moreover, this approach permits to produce forecasts that act as proxies for the evolution of the index of web-queries for the term “headache” during “normal” conditions, or for what could have been expected in the absence of the pandemic. Hence, in the first step, the first 123 weekly observations are employed in-sample for model training and validation, while the data spanning from week 124 to week 155 (i.e., 32 weekly observations ending in January 2020) is used to assess the predictive models' out-of-sample forecasting accuracy. The best forecasting model over this (pre-pandemic) test period is subsequently employed to issue forecasts that cover the first months of the pandemic period spanning February 2020–July 2020 (i.e., a forecasting horizon of 25 weeks). By implementing this forecasting strategy, we thus obtain the most accurate estimates available for the expected volume of web queries for the period spanning February 2020 to July 2020 (i.e., the baseline level) based on weekly historical data from February 2017 to January 2020. Real web-search volume is further compared to forecasted values, resulting in estimations of excess web queries for the term “headache”. The length of the forecasting horizon is carefully chosen to assure, on one hand, that it is smaller than the testing window70 and, on the other hand, to mitigate the risk of losing forecasting accuracy that is inherently related to longer forecasts. As per Breitung and Knuppel71, longer-term forecasts possibly do not provide any information beyond that contained in the long-run mean of the target variable. Hence, we argue that stretching the forecasting horizon over a longer timeframe would affect the accuracy of the predictive model. Moreover, this approach carries the additional advantage of making the current results directly comparable to previous COVID-19 impact studies.
Excess query
Excess web-queries are thus computed as the level of unanticipated web searches for the keyword in a week, relative to a “baseline” that represents expected web queries in the absence of the pandemic. Equation (1) depicts the calculation:
where \(E_{{S_{h} }}\) is the observed level of web-queries index for the term “headache” at time h and \(\hat{E}_{{S_{h} }}\) is the expected level of web-queries for the respective keyword at h under normal conditions. An alternative approach employs averages of past observations over a recent period to stand for the baseline level. However, this method would underestimate expectations for data with trend or seasonality, as in this case, and would thus overestimate excess queries. Consequently, a better approach is to employ a reliable forecasting model to predict the level of web-queries over the period of interest.
Models
We estimate six widely used models for univariate time series forecasting (ETS, HW, ARIMA, STS, TBATS, and NNAR), identify the best in-sample fit and the best out-of-sample forecasting ability, and subsequently employ the over-performing model to obtain reliable estimates of the expected web queries for 25 weeks spanning from February 2020 to July 2020 based on weekly historical data from February 2017 to January 2020.
R software is employed to implement all methods and carry out estimations.
-
The Holt-Winters Forecasting Model (HW), originally presented in Holt72 and Winters73 contains an exponential component (Et) and a trend component (Tt), such that:
$$E_{t} = wY_{t} + (1 - w)(E_{t - 1} + T_{t - 1} ),0 < w < 1$$(2)and
$$T_{t} = v(E_{t} - E_{t - 1} ) + (1 - v)T_{t - 1} ,0 < v < 1$$(3)
Then, the k-step-ahead forecast is given by:
HW is automatically estimated through the “HoltWinters” function in the “stats” package in R software74. The function performs HW filtering, and automatically finds parameters for the best in-sample HW model by minimizing the squared prediction error.
-
Exponential Smoothing State Space Model (ETS) contains three components: the trend (T), seasonal (S), and error (E), and the trend is its turn a combination of a level term (l) and a growth term (b). The trend and seasonal components may be none (N), additive (A), additive damped (Ad), multiplicative (M), or multiplicative damped (Md)75. The final model takes the form of a three-character string (Z,Z,Z), where the first letter represents the error assumption of the state-space model, the second stands for the trend type, whereas the third letter identifies the season type55. ETS is implemented through the “ets” function in R’s “forecast” package76,77, which automatically selects the error, type, and season. Then, the optimal ETS parameters corrected are found via the Akaike information criterion (AICc).
-
Autoregressive integrated moving average (ARIMA) models, proposed by Box and Jenkins78, are one of the most commonly used statistical methods for linear time series forecasting. A seasonal model ARIMA (p,q,d)(P,Q,D)s is written as in Eq. (5) following the terminology in Hyndman and Athanasopoulos70:
$$\begin{aligned} & (1 - \varphi_{1} B - \cdots - \varphi_{p} B^{p} )(1 - \Phi_{1} B^{s} - \cdots - \Phi_{P} B^{sP} )(1 - B)^{d} (1 - B^{s} )^{D} Y_{t} \\ & \quad = (1 - \theta_{1} B - \cdots - \theta_{q} B^{q} )(1 - \Theta_{1} B^{s} - \cdots - \Theta_{P} B^{sQ} )\varepsilon_{t} \\ \end{aligned}$$(5)where s is the seasonal period, the lowercase and the capital letters represent nonseasonal and seasonal parameters, and \(\varepsilon_{t}\) is a random variable with mean zero and the standard deviation \(\sigma\).
ARIMA is estimated through the “auto.arima” function within the “forecast” package in the R software. The function can decide whether the data used to train the model needs a seasonal differencing, and estimates unit root tests, together with the minimization of the AICc and MLE to identify parameters through a step-wise approach.
-
Exponential Smoothing State Space Model with Box-Cox Transformation, ARMA Errors, Trend, and Seasonal Components (TBATS) models have been introduced by De Livera et al.79. A TBAT model is written as TBATS(ω, p, q, φ, {m1, k1}, {m2, k2}, …,{mT, kT}), where ω is the Box-Cox transformation, k is the number of harmonics used for the seasonal trait, and φ is the dampening parameter. For automated estimation, the function “tbats” from the “forecast” package is used to select optimal model parameters by AIC.
-
Structural Time Series (STS) method80 asserts a time series is composed of four main stochastic components driven by mutually uncorrelated disturbances81.
A generalized expression of the decomposition of a time series is given by:
where \(\mu_{t}\) is the trend, \(\psi\) is the cycle, \(\gamma_{t}\) is the seasonal and \(\varepsilon_{t}\) is the irregular white noise component. STS is automatically estimated by employing the function “StructTS” in the “stats” package, and finding parameters through maximum likelihood.
-
Artificial neural networks (ANNs) are recognized as capable of modeling complex real-world systems owing to their capability to consider non-linearity82. An ANN is composed of its basic processing elements (nodes), the connections between nodes, and the activation function83. With time-series data, past own values are often used as inputs in an ANN structure, thus developing a neural network autoregression (NNAR) model84, as depicted in Fig. 4.
For seasonal data, NNAR models can be described as NNAR (p,P,k)m, where m is the seasonal period, p are nonseasonal lagged inputs for the linear AR process, P are seasonal lags for the AR process, and k represents the number of nodes in the hidden layer. In equation form, the NNAR model reflected in Fig. 4 is given by:
where Y is the output vector of predicted values, f is the activation function, and H = {weight matrix [(p*k)] * input vector} + bias vector (B)85.

The architecture of a feed-forward neural network autoregression model (NNAR) with p lagged inputs, k nodes in the hidden layer and the activation function f.
The NNAR model is fitted through the “nnetar” function within the “forecast” package in R, by making 25 repetitions and minimizing AIC to automatically identify parameters p and P. The number of nodes in the hidden layer is given by k = (p + P + 1)/2.
Evaluation metrics
Several forecasting accuracy metrics are estimated to explore the forecasting performance of the six models, as follows:
-
$${\text{Mean absolute error}}:MAE = \sqrt {\frac{1}{N}\sum\nolimits_{i = 1}^{N} {|y_{i} - \hat{y}_{l} |} }$$(8)
-
$${\text{Root mean squared error}}:RMSE = \sqrt {\frac{1}{N}\sum\nolimits_{i = 1}^{N} {(y_{i} - \hat{y}_{l} )^{2} } }$$(9)
-
$${\text{Mean absolute percentage error}}:MAPE = mean(|p_{t} |)$$(10)
where \(p_{t} = \frac{{100e_{t} }}{{y_{t} }}\)
-
Mean absolute percentage error:
$${\text{MASE}} = {\text{mean}}(|q_{j} |)$$(11)where qj is independent of the scale of the data and is defined as:\(q_{j} = \frac{{e_{t} }}{{\frac{1}{N - 1}\sum\nolimits_{i = 2}^{N} | y_{t} - y_{t - 1} |}}\) for non-seasonal series and as: \(q_{j} = \frac{{e_{t} }}{{\frac{1}{N - m}\sum\nolimits_{i = m + 1}^{N} | y_{t} - y_{t - m} |}}\) for seasonal time series.
-
Theil’s U statistic:
$$Theil^{\prime}s\;U = \frac{{RMSE_{1} }}{{RMSE_{2} }},$$(12)where RMSE1 refers to the RMSE metric estimated for the main model and RMSE2 represents the RMSE of the naïve method that always predicts the last observation.
-
Lag 1 Autocorrelation of Error:
$$ACF1 = \frac{{\hat{\gamma }(1)}}{{\hat{\gamma }(0)}}$$(13)where \(\gamma\) is the sample autocovariance function.
For all metrics, the forecast error is given by:
where {y1,…,yT} is the training window, {yT + 1,yT + 2,…,yN} is the test window, and N the length of the time series.
More details can be retrieved from Hyndman and Koehler86 and Hyndman and Athanasopoulos70.
Test for superior predictive ability (SPA)
The test proposed by Diebold and Mariano87 and its version further extended by Harvey et al.88 has been extensively used in the literature to test the null hypothesis of equal forecast accuracy between two competing models89, Diebold90,91. The DM test statistic is suitable for forecast errors that are contemporaneously correlated, serially correlated or are non-normally distributed92.
The loss associated with forecast i is considered to be a function of the forecast error, eit, which is denoted by g(eit), and which is usually the square or absolute value of eit. Furthermore, the loss differential between the two forecasts is calculated as follows:
and the null hypothesis is:
The DM test is estimated through the “dm.test” function included in R’s “forecast” package.
Integrated sequential steps for automated forecasting
The following steps are taken to implement the six models in the R environment using automated forecasting algorithms:

Results
Table 1 reflects the accuracy measures for the out-of-sample forecasting ability of the six models over the testing period. Results indicate that Holt-Winters and NNAR can provide the best forecast for web-queries, thus over-performing within the universe of six competing models when predicting the level of the web search index over the testing period. Theil’s U statistic is also sub-unitary for the two models, implying that all issued predictions are superior to the naïve method. The other predictive models show significantly higher accuracy measures, indicating that none has been able to satisfactorily capture the evolution of web-queries. Furthermore, the DM test confirms (p value = 0.046) that HW is over-performing within the pool of concurrent models and its forecasting superiority is statistically significant. At the opposite end, ARIMA produces the highest forecast errors for the web-queries series.
Consequently, HW emerges as the optimal choice when a decision should be made toward relying on a single predictive model.
We next employ the HW model to produce the expected values web-queries over the next 6 months corresponding to February-July 2020, when the pandemic started spreading globally. These values are extracted from actual web-search levels produced over the period to arrive at the excess level of queries for the term “headache”. Table 2 centralizes the estimation results.
We notice that HW predicted a continuation of the increasing trends in web queries for the term “headache”, indicating that the COVID-19 has accelerated, but not caused, the number of headache occurrences as reflected in web search interest. Estimates indicate an excess level for the web search volume index of 29 over the March 2020–July 2020 period. From March 8, 2020, to April 26, 2020, very high levels of excess web searches for the term "headache" are encountered, but the excess is lost in the following months. This indicates that the pandemic took its main toll on population well-being in the third and fourth months of 2020.
Figure 5 reflects the predictions issued by the HW model for web queries for the term “headache” over the period spanning February 2020 to July 2020 (blue line), along with the real volume number of web searches for the same term, assumed to reflect headache occurrences at world level.

Historical trends and forecasted values for web queries for the term “headache”.
Discussion
Our research endeavor relies on the works of Polgreen et al.28, Ginsberg et al. (2009), Carneiro and Mylonakis33, among others, and acknowledges that the Internet is an important source of health information, and web search interest (health-seeking behavior in the form of online queries), is a reliable proxy for a health problem occurrence.
Furthermore, our study is motivated by previous research34,34,35,36,38 highlighting that infodemiology can provide faster access to information and is capable to reveal otherwise undetectable information, assisting to improving early detection and formulating effective public health strategies.
Our results indicate, based on Google Trends-query analysis, that headache (as proxied by related web- query volume) would have risen between February 2020 and July 2020 even in the absence of the COVID-19 pandemic. Thus, estimates indicate a “normal” expected growth in headache searches of 15.49% over the 6 months. This prediction is consistent with a rising trend in interest for all pain-related topics, as found by36.
However, the actual level of web queries for the term “headache” far exceeded projections (i.e. a 20.59% increase over February 2020–July 2020), indicating that the global health crisis and subsequent measures imposed by governments to contain the spread of the novel coronavirus have affected wellbeing and accelerated headache occurrences worldwide. Our estimations indicate excess headache occurrences of 4.53% relative to expected levels in the absence of the pandemic, or during normal conditions, reinforcing that the COVID-19 has had a significant impact on various aspects of population health. This conforms to Szilagyi et al.21, confirming an increased incidence of pain after the outbreak of the COVID-19 pandemic, based on the assumption that Internet searches are a surrogate for the public interest. Findings thus indicate that people are suffering more from headaches in the aftermath of the COVID-19 outbreak, as suggested by previous studies13 and media sources (Business14, Atlantic, 2021).
However, caution should be exercised when interpreting these results.
On one hand, an increase in the frequency of searches for the term “headache” could in part reflect COVID-19-related symptoms. Headache has been recognized and reported early on as a symptom of coronavirus disease18, which could explain the increasing activity on this query.
However, besides the COVID-19 infection, various factors could have also contributed to increased headache incidence over the pandemic period, including anxiety and concern for personal safety, disagreement on optimal treatment, and the lack of viable vaccination options during the first year of the pandemic, the quarantine and lockdown measures imposed to tackle the pandemic, and the negative socioeconomic implications4,19,20. Studies that explore the effect of quarantine on population health and wellbeing during previous pandemics16,17 bring evidence that supports the latter interpretation.
Consequently, it may seem hard to attribute the increased incidence of headaches to a direct effect of the virus or the other pandemic-related factors. Nonetheless, exploring the shift in the population interest at the country level can shed light on this issue. Hence, mixed correlations are encountered between coronavirus cases and Internet searches for the term “headache. In the US, Canada, Australia, and South Africa, the frequency of web queries decreased after the COVID-19 outbreak, despite the countries reporting high coronavirus infection rates relative to population number. In contrast, in other countries (i.e. UK, India, and Pakistan) the frequency of headache-related searches increased. Hence, the population of the US and UK, two of the most impacted countries worldwide26,27 and with similar reported rates of COVID-19 cases (per million population) shows distinct web search behavior. This further supports the argument that the increased web queries are an indication that the increased headache incidence after the COVID-19 outbreak is a result of pandemic-related factors, rather than a consequence of the coronavirus disease.
Moreover, we argue that the results would still have merits in the absence of a clear identification of the driving factors for increased headache incidence. Hence, research findings remain informative for policymakers, assisting in the formulation of specific strategies and for key players in the pain management drug market, providing valuable information for decision-making and business management. The piece that explains the positive link between web searches for a health problem, health problem occurrence, and ultimately private consumption is that the vast majority (i.e. 80%) of Internet users trust the health-related information acquired from web sources93.
Conclusions
The Coronavirus Disease 2019 (COVID-19) pandemic has had a complex, multifaceted, global impact on population health and well-being. However, many aspects of the COVID-19’s impact remain hard or impossible to detect and assess due to the absence or lateness of reported statistics. Hence, there is an increasing strand of literature that estimates excess deaths and hospitalizations during the ongoing global health crisis, although other aspects remain significantly under-investigated. The effect of the pandemic on headache incidence at the world level and in particular countries is one of these outstanding research questions.
In this study, we propose a solution based on assumptions drawn from infodemiology (or information epidemiology), to shed light on the link between the pandemic and headache occurrences at a global level and for specific countries, and to detect any shift in historical trends.
The analysis of Internet-submitted queries has become a highly valuable tool in many fields for early detection of shifts in population interest for specific notions, which in turn could reflect health problems or interest in particular products and services. Google has been the absolute leader search engine provider for the past decades, whereas the Internet has become an increasingly important source of health information for the population worldwide with over a billion health-related queries passing through Google daily as of 2019. Furthermore, there is a recognized strong correlation between web searches for a particular health problem and retrospective surveillance data reported by official statistics, a link that is explained by the acknowledged trust in health-related information acquired from web sources. As a result, the Google Trends platform has become increasingly popular in health and medical studies over the previous decade, providing timely and informative data. Furthermore, the COVID-19 pandemic has increased the volume of Internet searches for health information, further increasing the relevancy and utility of Web-based analysis of search queries.
However, excess headache occurring during the pandemic remains an outstanding research topic, with suggestions indicating increased occurrence, but a quantitative assessment of COVID-19's impact and the investigation of causal relationships are yet to be accomplished.
This study tackles this issue by analyzing the Google search activity of headache-related expressions at the world level and investigating any potential shift in the population interest before and during the first wave of the COVID-19 pandemic. Based on previous findings, this can be indicative of an increased incidence of headache, which in turn has important implications for policymakers and market players, influencing decision-making processes.
Our study thus contributes to extending information epidemiology research and the overall literature concerned with assessing the impact and consequences of COVID-19, by assessing excess headache occurrence after the pandemic outbreak and uncovering causalities through exploring potential shifts in population health-seeking behavior. Moreover, considering the positive link between web queries and ultimate private consumption, identification of the overperforming forecasting method for web-search data contributes to bettering information about future aggregate consumer behavior and improving sales forecasting for the global pain management drug market.
Results indicate that web searches for the keyword “headache” sharply increased globally in the early months of the pandemic, and significantly surpassed the projections based on historic trends. Findings confirm that the COVID-19 pandemic has resulted in an excess occurrence of headaches worldwide that would not have occurred in the absence of the pandemic. Estimations additionally highlight that the increasing trend would have continued in the absence of the pandemic, but COVID-19 has accelerated it. Lastly, research results indicate mixed correlations at the country-level between infection rates and search behavior, suggesting that the increased headache incidence is caused by pandemic-related factors, rather than being a direct effect of the virus.
We argue that Google Trends can be an effective way to analyze trends in public health variables, providing the first indication of health issues even for self-medicated cases that wouldn’t otherwise appear in official statistics. The method employed in this study offers the advantage of generalizability, and can further be employed to explore potential increasing trends in occurrences of other health issues, physical or mental (i.e. diverse pain, depression, anxiety disorders, sleep disorders, suicidal behavior, etc.). Furthermore, the findings are important for extracting valuable information that can assist policymakers in efficiently managing potential future COVID-19 waves or future pandemic events. As such, based on the realistic hypothesis that online searches are a proxy for population interest, detecting an increased search for various medical conditions and/or symptoms after the breakout of a pandemic event would provide relevant and timely information on the symptomatology timeline, as well as on the spread of the condition, that would not otherwise be detected or would be reflected by official health statistics with a significant delay. Moreover, relevant insight into the geographical distribution of increased incidences (as proxied by the web search interest) can inform policymakers and health authorities on the presence of specific health problems of the local population and thus can contribute to the issuance of targeted, more effective policies and strategies.
References
Mishra, P. K. COVID-19, Black Swan events and the future of disaster risk management in India. Progress Disaster Sci. 8, 100137 (2020).
Döhring, B., Hristov, A., Maier, C., Roeger, W. & Thum-Thysen, A. COVID-19 acceleration in digitalisation, aggregate productivity growth and the functional income distribution. IEEP 18(3), 571–604 (2021).
Martin, A., Markhvida, M., Hallegatte, S. & Walsh, B. Socio-economic impacts of COVID-19 on household consumption and poverty. Econ. Disasters Clim. Change 4(3), 453–479 (2020).
Nicola, M. et al. The socio-economic implications of the coronavirus pandemic (COVID-19): A review. Int. J. Surg. 78, 185–193 (2020).
Onyeaka, H., Anumudu, C. K., Al-Sharify, Z. T., Egele-Godswill, E. & Mbaegbu, P. COVID-19 pandemic: A review of the global lockdown and its far-reaching effects. Sci. Prog. 104(2), 00368504211019854 (2021).
Lima, C. K. T. et al. The emotional impact of Coronavirus 2019-nCoV (new Coronavirus disease). Psychiatry Res. 287, 112915 (2020).
Nurunnabi, M., Almusharraf, N. & Aldeghaither, D. Mental health and well-being during the COVID-19 pandemic in higher education: Evidence from G20 countries. J. Public Health Res. 9(Suppl 1), 25 (2020).
Varma, P., Junge, M., Meaklim, H. & Jackson, M. L. Younger people are more vulnerable to stress, anxiety and depression during COVID-19 pandemic: A global cross-sectional survey. Prog. Neuropsychopharmacol. Biol. Psychiatry 109, 110236 (2021).
Hossain, M. M. et al. Epidemiology of mental health problems in COVID-19: a review. F1000Research 9, 25 (2020).
Wu, B. Social isolation and loneliness among older adults in the context of COVID-19: a global challenge. Glob. Health Res. Policy 5(1), 1–3 (2020).
Leon, D. A. et al. COVID-19: a need for real-time monitoring of weekly excess deaths. Lancet 395(10234), e81 (2020).
Bolay, H., Gül, A. & Baykan, B. COVID-19 is a real headache!. Headache J. Head Face Pain 60(7), 1415–1421 (2020).
Chew, N. W. et al. A multinational, multicentre study on the psychological outcomes and associated physical symptoms amongst healthcare workers during COVID-19 outbreak. Brain Behav. Immun. 88, 559–565 (2020).
Business Wire (2020). Global Migraine Drugs Market (2020 to 2024)—Insights and Forecast with Potential Impact of COVID-19—ResearchAndMarkets.com. https://www.businesswire.com/news/home/20200922005802/en/Global-Migraine-Drugs-Market-2020-to-2024---Insights-and-Forecast-with-Potential-Impact-of-COVID-19---ResearchAndMarkets.com. Accessed 14 Feb 2022.
The Atlantic, 2021. https://www.theatlantic.com/health/archive/2021/01/quarantine-giving-you-headaches-back-pain-and-more/617672/. Accessed 15 Feb 2022.
Brooks, S. K. et al. The psychological impact of quarantine and how to reduce it: rapid review of the evidence. Lancet 395, 912–920. https://doi.org/10.1016/S0140-6736(20)30460-8 (2020).
Hawryluck, L. et al. SARS control and psychological effects of quarantine, Toronto. Canada. Emerg Infect Dis. 10, 1206–1212. https://doi.org/10.3201/eid1007.030703 (2004).
Poncet-Megemont, L. et al. High prevalence of headaches during COVID-19 infection: a retrospective cohort study. Headache J. Head Face Pain 60(10), 2578–2582 (2020).
Alkhamees, A. A., Alrashed, S. A., Alzunaydi, A. A., Almohimeed, A. S. & Aljohani, M. S. The psychological impact of COVID-19 pandemic on the general population of Saudi Arabia. Compr. Psychiatry 102, 152192 (2020).
Holmes, E. A. et al. Multidisciplinary research priorities for the COVID-19 pandemic: a call for action for mental health science. Lancet Psychiatry 7(6), 547–560. https://doi.org/10.1016/S2215-0366(20)30168- (2020).
Szilagyi, I. S. et al. Google trends for pain search terms in the world’s most populated regions before and after the first recorded COVID-19 case: Infodemiological study. J. Med. Internet Res. 23(4), e27214 (2021).
Xiao, H. et al. The impact of the COVID-19 pandemic on health services utilization in China: time-series analyses for 2016–2020. Lancet Region. Health-Western Pac. 9, 100122 (2021).
Bahl, S. et al. Telemedicine technologies for confronting COVID-19 pandemic: a review. J. Ind. Integrat. Manage. 5(04), 547–561 (2020).
Haleem, A., Javaid, M., Singh, R. P. & Suman, R. Telemedicine for healthcare: Capabilities, features, barriers, and applications. Sens. Int. 2, 100117 (2021).
Charman, S. J. et al. Insights into heart failure hospitalizations, management, and services during and beyond COVID-19. ESC Heart Failure 8(1), 175–182 (2021).
Statista, 2022. Global market share of search engines 2010–2021. https://www.statista.com/statistics/216573/worldwide-market-share-of-search-engines/. Accessed 10 Feb 2022.
Statista, 2022. Rate of COVID-19 cases in the most impacted countries worldwide as of February 7 2022. https://www.statista.com/statistics/1174594/covid19-case-rate-select-countries-worldwide/. Accessed 18 Feb 2022.
Polgreen, P. M., Chen, Y., Pennock, D. M., Nelson, F. D. & Weinstein, R. A. Using internet searches for influenza surveillance. Clin. Infect. Dis. 47(11), 1443–1448 (2008).
Ginsberg, J. et al. Detecting influenza epidemics using search engine query data. Nature 457(7232), 1012–1014 (2009).
Becker’s Hospital Review, 2019, Google receives more than 1 billion health questions every day. https://www.beckershospitalreview.com/healthcare-information-technology/google-receives-more-than-1-billion-health-questions-every-day.html. Accessed 7 Feb 2022.
Nuti, S. V. et al. The use of google trends in health care research: a systematic review. PLoS One 9(10), e109583 (2014).
Statistics Netherlands (CBS), 2021, More online searches for health and lifestyle information. https://www.cbs.nl/en-gb/news/2021/04/more-online-searches-for-health-and-lifestyle-information. Accessed 7 Feb 2022.
Carneiro, H. A. & Mylonakis, E. Google trends: a web-based tool for real-time surveillance of disease outbreaks. Clin. Infect. Dis. 49(10), 1557–1564 (2009).
Bernardo, T. M. et al. Scoping review on search queries and social media for disease surveillance: a chronology of innovation. J. Med. Internet Res. 15(7), e2740 (2013).
Eysenbach, G. Infodemiology and infoveillance: tracking online health information and cyberbehavior for public health. Am. J. Prev. Med. 40(5), S154–S158 (2011).
Kamiński, M., Łoniewski, I. & Marlicz, W. “Dr Google, I am in Pain”—Global internet searches associated with pain: a retrospective analysis of google trends data. Int. J. Environ. Res. Public Health 17(3), 954 (2020).
Mavragani, A. Infodemiology and infoveillance: scoping review. J. Med. Internet Res. 22(4), e16206 (2020).
Mavragani, A. & Ochoa, G. Google Trends in infodemiology and infoveillance: methodology framework. JMIR Public Health Surveill. 5(2), e13439 (2019).
Carrière-Swallow, Y. & Labbé, F. Nowcasting with Google Trends in an emerging market. J. Forecast. 32(4), 289–298 (2013).
Choi, H. & Varian, H. Predicting the present with Google Trends. Econ. Record 88, 2–9 (2012).
Vosen, S. & Schmidt, T. Forecasting private consumption: survey-based indicators vs. Google trends. J. Forecast. 30(6), 565–578 (2011).
De Siqueira, J. V. V. et al. Impact of obesity on hospitalizations and mortality, due to COVID-19: A systematic review. Obes. Res. Clin. Pract. 14(5), 398–403 (2020).
Stokes, A. C. et al. COVID-19 and excess mortality in the United States: A county-level analysis. PLoS Med. 18(5), e1003571 (2021).
Karlinsky, A. & Kobak, D. Tracking excess mortality across countries during the COVID-19 pandemic with the World Mortality Dataset. Elife 10, e69336 (2021).
Borrego-Morell, J. A., Huertas, E. J. & Torrado, N. On the effect of COVID-19 pandemic in the excess of human mortality. The case of Brazil and Spain. PLoS One 16(9), e0255909 (2021).
Böttcher, L., D’Orsogna, M. R. & Chou, T. Using excess deaths and testing statistics to determine COVID-19 mortalities. Eur. J. Epidemiol. 36(5), 545–558 (2021).
Davies, B. et al. Community factors and excess mortality in first wave of the COVID-19 pandemic in England. Nat. Commun. 12(1), 1–9 (2021).
Michelozzi, P. et al. Temporal dynamics in total excess mortality and COVID-19 deaths in Italian cities. BMC Public Health 20(1), 1–8 (2020).
Nogueira, P. J., de Araújo Nobre, M., Nicola, P. J., Furtado, C. & Carneiro, A. V. Excess mortality estimation during the COVID-19 pandemic: preliminary data from Portugal. Acta Med. Port. 33(6), 376–383 (2020).
Rivera, R., Rosenbaum, J. E. & Quispe, W. Excess mortality in the United States during the first three months of the COVID-19 pandemic. Epidemiol. Infect. 148, 25 (2020).
Rossen, L. M., Branum, A. M., Ahmad, F. B., Sutton, P. & Anderson, R. N. Excess deaths associated with COVID-19, by age and race and ethnicity—United States, January 26–October 3, 2020. Morb. Mortal. Wkly Rep. 69(42), 1522 (2020).
Shiels, M. S. et al. Racial and ethnic disparities in excess deaths during the COVID-19 pandemic, March to December 2020. Ann. Intern. Med. 174(12), 1693–1699 (2021).
Stang, A. et al. Excess mortality due to COVID-19 in Germany. J. Infect. 81(5), 797–801 (2020).
Vandoros, S. Excess mortality during the Covid-19 pandemic: Early evidence from England and Wales. Soc. Sci. Med. 258, 113101 (2020).
Perone, G. Comparison of ARIMA, ETS, NNAR, TBATS and hybrid models to forecast the second wave of COVID-19 hospitalizations in Italy. Eur. J. Health Econ. https://doi.org/10.1007/s10198-021-01347-4 (2021).
Krieger, N., Chen, J. T. & Waterman, P. D. Excess mortality in men and women in Massachusetts during the COVID-19 pandemic. Lancet 395(10240), 1829 (2020).
Modig, K., Ahlbom, A. & Ebeling, M. Excess mortality from COVID-19: weekly excess death rates by age and sex for Sweden and its most affected region. Eur. J. Pub. Health 31(1), 17–22 (2021).
Cao, J., Jiang, X. & Zhao, B. Mathematical modeling and epidemic prediction of COVID-19 and its significance to epidemic prevention and control measures. Journal of Biomedical Research & Innovation 1(1), 1–19 (2020).
Alzahrani, S. I., Aljamaan, I. A. & Al-Fakih, E. A. Forecasting the spread of the COVID-19 pandemic in Saudi Arabia using ARIMA prediction model under current public health interventions. J. Infect. Public Health 13(7), 914–919 (2020).
Ceylan, Z. Estimation of COVID-19 prevalence in Italy, Spain, and France. Sci. Total Environ. 729, 138817 (2020).
Sardar, T., Nadim, S. S., Rana, S. & Chattopadhyay, J. Assessment of lockdown effect in some states and overall India: A predictive mathematical study on COVID-19 outbreak. Chaos Solitons Fractals 139, 110078 (2020).
Wieczorek, M., Siłka, J. & Woźniak, M. Neural network powered COVID-19 spread forecasting model. Chaos Solitons Fractals 140, 110203 (2020).
Scortichini, M. et al. Excess mortality during the COVID-19 outbreak in Italy: a two-stage interrupted time-series analysis. Int. J. Epidemiol. 49(6), 1909–1917 (2020).
Morciano, M., Stokes, J., Kontopantelis, E., Hall, I. & Turner, A. J. Excess mortality for care home residents during the first 23 weeks of the COVID-19 pandemic in England: a national cohort study. BMC Med. 19(1), 1–11 (2021).
Dahal, S., Banda, J. M., Bento, A. I., Mizumoto, K. & Chowell, G. Characterizing all-cause excess mortality patterns during COVID-19 pandemic in Mexico. BMC Infect. Dis. 21(1), 1–10 (2021).
Talkhi, N., Fatemi, N. A., Ataei, Z. & Nooghabi, M. J. Modeling and forecasting number of confirmed and death caused COVID-19 in IRAN: A comparison of time series forecasting methods. Biomed. Signal Process. Control 66, 102494 (2021).
Nicholson, R. A., Houle, T. T., Rhudy, J. L. & Norton, P. J. Psychological risk factors in headache: CME. Headache J. Head Face Pain 47(3), 413–426 (2007).
Centers for disease Control and Prevention (CDC), (2021), CDC Museum COVID-19 Timeline. https://www.cdc.gov/museum/timeline/covid19.html. Accessed 30 Jan 2022.
The American Journal of Managed Care, AJMC (2021) A Timeline of COVID-19 Developments in 2020. https://www.ajmc.com/view/a-timeline-of-covid19-developments-in-2020. Accessed 16 Feb 2022.
Hyndman, R. J. & Athanasopoulos, G. (2018) Forecasting: principles and practice, 2nd ed. OTexts, Melbourne, Australia. Section 3.4 "Evaluating forecast accuracy". https://otexts.com/fpp2/accuracy.html.
Breitung, J. & Knüppel, M. How far can we forecast? Statistical tests of the predictive content. J. Appl. Economet. 36(4), 369–392 (2021).
Holt, C. C. Forecasting seasonals and trends by exponentially weighted moving averages. ONR Res. Memor. 52, 25 (1959).
Winters, P. R. Forecasting sales by exponentially weighted moving averages. Manage. Sci. 6, 324–342 (1960).
R Core Team (2012). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0. http://www.R-project.org/.
Yang, D. et al. Forecasting of global horizontal irradiance by exponential smoothing, using decompositions. Energy 81, 111–119 (2015).
Hyndman, R., et al. (2022). forecast: Forecasting functions for time series and linear models. R package version 8.16. https://pkg.robjhyndman.com/forecast/.
Hyndman, R. J. & Khandakar, Y. Automatic time series forecasting: the forecast package for R. J. Stat. Softw. 26(3), 1–22. https://doi.org/10.18637/jss.v027.i03 (2008).
Box, G. & Jenkins, G. Time Series Analysis: Forecasting and Control (Holden-Day, 1970).
De Livera, A. M., Hyndman, R. J. & Snyder, R. D. Forecasting time series with complex seasonal patterns using exponential smoothing. J. Am. Stat. Assoc. 106(496), 1513–1527 (2011).
Harvey, A. C. Forecasting Analysis of Time Series Models and the Kalman Filter (Cambridge University Press, 1989).
Kapombe, C. M. & Colyer, D. A structural time series analysis of US broiler exports. Agric. Econ. 21(3), 295–307 (1999).
Pasini, A. Artificial neural networks for small dataset analysis. J. Thorac. Dis. 7(5), 953 (2015).
Allende, H., Moraga, C. & Salas, R. Artificial neural networks in time series forecasting: A comparative analysis. Kybernetika 38(6), 685–707 (2002).
Munim, Z. H., Shakil, M. H. & Alon, I. Next-day bitcoin price forecast. J. Risk Financ. Manage. 12(2), 103 (2019).
Tudor, C. & Sova, R. Benchmarking GHG emissions forecasting models for global climate policy. Electronics 10(24), 3149 (2021).
Hyndman, R. J. & Koehler, A. B. Another look at measures of forecast accuracy. Int. J. Forecast. 22(4), 679–688 (2006).
Diebold, F. X. & Mariano, R. S. Comparing predictive accuracy. J. Bus. Econ. Stat. 13, 253–263 (1995).
Harvey, D., Leybourne, S. & Newbold, P. Testing the equality of prediction mean squared errors. Int. J. Forecast. 13(2), 281–291 (1997).
Hering, A. S. & Genton, M. G. Comparing spatial predictions. Technometrics 590(4), 414–425 (2011).
Diebold, F. X. Comparing predictive accuracy, twenty years later: A personal perspective on the use and abuse of Diebold–Mariano tests. J. Bus. Econ. Stat. 33(1), 1–1 (2015).
Gilleland, E. & Roux, G. A new approach to testing forecast predictive accuracy. Meteorol. Appl. 22(3), 534–543 (2015).
Coroneo, L. & Iacone, F. Comparing predictive accuracy in small samples using fixed-smoothing asymptotics. J. Appl. Economet. 35(4), 391–409 (2020).
Beck, F. et al. Use of the internet as a health information resource among French young adults: results from a nationally representative survey. J. Med. Internet Res. 16(5), e2934 (2014).
Author information
Authors and Affiliations
Contributions
C.T. and R.S. pre-processed the data, eastablishd the methods, developed the software, and reviewed the manuscript. C.T. wrote the main manuscript text.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tudor, C., Sova, R. Infodemiological study on the impact of the COVID-19 pandemic on increased headache incidences at the world level. Sci Rep 12, 10253 (2022). https://doi.org/10.1038/s41598-022-13663-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-13663-7
This article is cited by
-
Exploring the Feasibility of a Cancer Awareness Program for High School Students in a Brazilian School: A Pilot Study
Journal of Cancer Education (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
