
Abstract
With the development of commodity economy, the emergence of fake and shoddy raisin has seriously harmed the interests of consumers and enterprises. To deal with this problem, a classification method combining near-infrared spectroscopy and pattern recognition algorithms were proposed for adulterated raisins. In this study, the experiment was performed by three kinds of raisins in Xinjiang (Hongxiangfei, Manaiti, Munage). After collecting and normalizing the spectral data, we compared the spectra of three kinds of raisins. Next the principal component analysis (PCA) was preformed to compress the dimension of the spectral data, and then classification models including support vector machine (SVM), multiscale fusion convolutional neural network (MCNN) and improved AlexNet were established to identify raisins. The accuracy of SVM, MCNN, and improved AlexNet is 100%, 92.83%, and 97.78% respectively. This study proves that near-infrared spectroscopy combined with pattern recognition is feasible for the raisin inspection.
Similar content being viewed by others

Introduction
Raisin is a kind of nutritious and diverse agricultural product, which is rich in nutrients such as sodium, iron, calcium, and dietary fiber1. Studies have found that eating raisins three times a day can significantly reduce blood sugar levels, systolic and diastolic blood pressure, thereby reducing the risk of diabetes and cardiovascular and cerebrovascular diseases in consumers2. Furthermore, compared with carbohydrate foods with the same calorie, raisins can effectively reduce cholesterol levels and have anti-inflammatory and anti-cancer effects. Therefore raisin is beneficial for promoting body and heart health and preventing many chronic diseases3. At present, raisin is widely used in food processing such as making various snacks or adding staple foods4,5,6. Due to the differences in the variety, origin, and drying process, the taste, nutritional content, and commercial value of raisins are very different7,8,9. In addition, there is a serious problem of fake raisin varieties and inferior quality in the market at present, which have a bad impact on the healthy development of the raisins market10
At present, the method for the classification of raisins mainly relies on the extraction of texture features from raisins' images. For example, Khojastehnazhand et al. used the gray horizontal run length matrix (GLRM) combined with SVM to classify 15 kinds of raisins and got 69.78% accuracy respectively11. Navab·Karimia et al. used a method based on machine vision combined with ANN and SVM to identify golden bleached raisins among a variety of raisins, and the final accuracy rate of golden bleached raisins was 92.71%12. However, the raisin' size is small and has fewer image features that can be extracted. At the same time, the photographing process is susceptible to inevitable factors such as lighting, equipment, and pixels. Therefore, this method has some limitations that restrict its wide application. To overcome the limitations of the above method, this research proposes a classification method based on near-infrared spectroscopy.
Since mature grape will form a waxy layer on the surface during the process of dehydration, the waxy layer formed by different varieties of grapes under a variety of dehydration methods will exist differences in lipids, polyphenols, and trace elements13. Therefore, raisin skin is selected as the object of study.
Near-infrared spectroscopy, as a commonly used material quantitative analysis and chemical structure detection tool, has the characteristics of low energy and very high efficiency. In addition, it also has the advantages of unlimited sample form, less dosage, and no damage to the sample14. At present, near-infrared spectroscopy has a wide range of applications in various research fields, such as medical diseases, food detection, and gem identification15,16,17,18.
Machine learning is a data analysis technique. It selects appropriate algorithms through data, automatically summarizes logic and rules, and make predictions based on the generalized model19. Deep learning algorithm which is a type of machine learning algorithm, is generally composed of one or several layers of deep neural networks20. Deep learning algorithm has been applied to research in many fields21. This research optimized the deep learning algorithm and made the model more suitable for the classification of near-infrared spectroscopy data. To improve performance, Batch normalization (BN) was added to the model in this experiment. BN is a method for optimizing neural networks. It can speed up the convergence speed of model training, make the training process more stable, and avoid gradient explosion or gradient disappearance. It also has the function of regularization22.
In this study, we used near-infrared spectroscopy combined with pattern recognition algorithms to classify three kinds of raisins: Hongxiangfei, Manaiti and Munageto. First, we collected the spectral data from the raisin pericarps and then used PCA to extract the characteristics of the spectral data of the pericarps. Finally, we constructed SVM, MCNN and improved AlexNet model for classification.
Experimental materials and methods
Sample preparations
Three kinds of raisins: HongxiangFei, Manaiti and Munage were selected in the experiment. Among them, Hongxiangfei and Munage raisins were purchased from Shangyao dry and fresh fruit specialty boutiques in Urumqi, Xinjiang, China. Manaiti raisins were purchased from Urumqi Xiyu Baza E-Commerce Co. Ltd. The origin of Hongxiangfei is Hami, and the origin of Manaiti and Munage are Turpan. The pericarps were separated from raisin. Then, the skin samples were placed in a YG747 fast constant temperature oven (Changzhou First Textile Equipment Co., Ltd.) for two hours and the temperature was set to 100 °C. Afterwards, they were packaged in ziplock bags.
Near-infrared spectroscopy measurement
The experimental measurement used a VERTEX 70 FT-IR spectrometer from Germany with a resolution of 8 cm−1; the scanning range was 4000–11,000 cm−1; OPUS 65 software was used to measure the atmospheric background data before each measurement, which scanned on zinc slenide; the atmospheric compensation parameter was CO2 compensation and the number of scans was 16 times. To reduce the influence caused by random errors such as noise of spectrometer and the difference of environmental humidity, the measurement was repeated four times for each sample and the average value was taken. In addition, to reduce the influence of electronic drift and other factors, the near-infrared spectroscopy used Rubberband baseline correction, and the number of baseline points was set to 64. In the end, Hongxiangfei obtained 59 average spectra, and Marquise and Munage each obtained 60 average spectra.
Method introduction
PCA is a data mining technique in multivariate statistics. It selects a small number of new variables to replace the original old variables without losing the main spectral information. It not only solves the difficulty of being unable to analyze due to overlapping bands but also helps in the interpretation, understanding, discrimination and clustering of measurement data23. In this study, PCA was used to reduce the dimensionality of the spectral data.
SVM is a supervised binary generalized linear classifier. The data are classified by constructing the best hyperplane. SVM is a learning algorithm for small samples. Its essence is to mine the classification information hidden in the data to the maximum in the limited samples. In addition, the non-linear problem in the original space is transformed into the linear problem in the high-dimensional space through the non-linear transformation. It not only guarantees good promotion ability, but also does not increase the algorithm complexity. SVM has been widely used in food research24. In summary, we chose SVM as the first algorithm of multivariate classification.
Convolutional Neural Network (CNN) is a deep learning structure for feature extraction, classification, and regression25. In the literature, CNN has been widely applied to food26. Combining the characteristics of spectral data, this study designed and evaluated a CNN structure for classification.
The AlexNet model is a deep convolutional neural network proposed by Alex Krizhevsky and others at the University of Toronto. AlexNet has more parameters and convolutional layers so that it is more efficient to extract features. At the same time, AlexNet uses the ReLU activation function and Dropout to reduce the risk of overfitting, which not only greatly improves the performance of the model but also improves the recognition accuracy27. We made some adjustments to AlexNet to better adapt to the spectral data28.
Method evaluation indexes
In order to evaluate the classification effect of the model accurately and comprehensively, we used three common model evaluation indexes, namely accuracy, sensitivity and recall rate.
Accuracy represents the percentage of the total sample that is predicted correctly, and the formula is as Eq. (1)
Accuracy is the simplest and most intuitive evaluation index in the classification problem, but it has obvious defects. When the proportion of different types of samples is very uneven, the larger samples have a greater impact on the accuracy. Therefore, it is not sufficient only through the accuracy to evaluate the model.
Precision represents the proportion of the number of correct pictures to the total number of positive predictions. The formula is as Eq. (2)
Recall represents the probability that a correct sample is predicted to be positive in all the correct numbers, and the formula is as Eq. (3)
Result and analysis
Spectral analysis
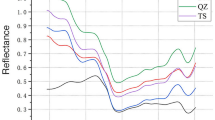
We normalized the spectral data of raisins to the [0,1] range. The resulting spectra are shown in Fig. 1. Three spectral lines represent the average near-infrared spectra of Hongxiangfei raisins, Manaiti raisins, and Munage raisins in the range of 4000 cm−1 to 11,000 cm−1, respectively. As shown in the figure, the spectra are similar but different in intensity. Hongxiangfei raisins have the highest normalized spectral intensity, Munage raisins have the lowest normalized spectral intensity, and the spectral intensity of Manaiti raisins lies between the two. According to relevant literature, different infrared absorption bands and corresponding substances are indicated in Table 126,29,30,31.

Average spectroscopy of raisin pericarps.
Spectral characteristic peaks of the three groups of samples are mainly distributed at 4323, 4763, 5160, 6896 and so on. Combined with the peak material distribution analysis, the variety types of raisins and the drying treatment methods cause the difference in lipid content in the waxy layer on the surface of the raisins32. In addition, the processing method of raisins is also the main reason for the difference in the content of brass and phenolic acid in raisins33.
Data processing results
PCA dimensionality reduction results
The variance contribution rate after PCA dimensionality reduction is shown in Fig. 2. The cumulative variance contribution rate of the first 25 principal components exceeded 99.98%34. The above results show that the 25-dimensional feature variables obtained by PCA can basically explain all the information of the original variables. So this study used the first 25 features for subsequent analysis23. After feature extraction, the data were randomly divided into training set, test set and validation set at a ratio of 6:2:2. We used SVM, MCNN and improved AlexNet for model training. To ensure the stability of the experimental results, each model was run five times. The final result was the average of five runs.

Variance contribution of the principal component.
SVM
We selected the radial basis function as the kernel function. By conducting a grid search, optimal weight facstors were determined. Grid optimization is an exhaustive search method. It loop through all the values in the range of parameters c and g and compare their accuracy to determine the best c and g. In this study, the ranges of the parameters c and g were [2–10]35. When the feature dimension is 25 dimensions, the selection results of parameters and their accuracy are shown in Fig. 3.

SVC Parameter selection result.
The best c was 0.75786 and g was 0.25. In this study, 5, 10, 15, 20, 25, 30, 35, 40 characteristics were selected to classify the raisins.
MCNN
The structure of MCNN is shown in Fig. 4. There were six hidden layers of MCNN in this experiment: three convolutional layers, a flatten layer and two fully connected layers. In order to prevent over-fitting and speed up the convergence speed, a BN layer was added before each convolutional layer36. The number and size of convolution cores in the convolution layer and the parameters of other layers are shown in Fig. 4. At the same time, two dropout layers were inserted before the two fully connected layers and the corresponding dropout rates were set to 0.5; LeakyReLU was selected as the activation function; alpha was 0.1; Adam was the optimizer; the learning rate was set to 1 × 10–5 and the training batch size was set as 64; the number of training times was set for 200 times.

The MCNN model.
The improved AlexNet
The improved AlexNet structure is shown in Fig. 5. It had five convolutional layers, a flatten layer, and three fully connected layers. The number and size of convolution cores in the convolution layer and the parameters of other layers are shown in Fig. 5. Three BN layers were added before the first three convolutional layers, and two dropout layers with dropout probabilities of 0.5 were added between the first two of the three fully connected layers; the activation function was ReLU; the learning rate was 1 × 10–7 and the batch size for training was set to 32. The training procedure were repeated 200 times. The experimental results are shown in the Table 2.

The adjusted AlexNet model.
Discussion
In this study, we used near-infrared spectroscopy combined with pattern recognition algorithms to quickly and accurately identify three kinds of raisins from different origins. We used SVM, MCNN and improved AlexNet for classification. The accuracy, precision and recall of test set and verification set are shown in Tables 2 and 3. The accuracy of the test set is shown in Fig. 6. The results show that the accuracy of the test set improves with the increase of the number of features when selecting 5, 10, 20, 25 features. When selecting 20 features, the accuracy, precision and recall of the three models are the highest, and SVM, AlexNet get 100% accuracy respectively. After that, with the increase of the number of features, the accuracy decreases slightly, but gradually tends to be stable. The accuracy of the validation set is shown in Fig. 7. The accuracy trend of the verification set is similar to that of the test set. The reason for this trend may be that the number of features is small so that the model is underfitted when selecting 5, 10 features, while when selecting 40 features, some interference information is introduced while the number of features increases, resulting in a little decrease in the accuracy of the verification set.

Test set accuracy of SVM, AlexNet and MCNN.

Validation set accuracy of SVM, AlexNet and MCNN.
By comparing the experimental results, among the three models used, SVM is more stable than AlexNet and MCNN, and the accuracy of test set and verification set is higher. The reason for the limited classification performance of AlexNet and MCNN may be the lack of data. Both AlexNet and MCNN require larger data sets to have a better generalization. In contrast, SVM requires only a small amount of data to have a good performance. Therefore, SVM is more suitable for classifying raisins than AlexNet and MCNN.
This experiment achieved better results than the results of Khojastehnazhandd et al. and Navab-Karimia et al. The possible reason is that the image processing reflects only the surface characteristics of raisins and does not allow the analysis of the internal structure of raisins. Infrared spectroscopy reflects information about chemical bonds or functional groups in the molecules of a substance, and therefore better shows the differences between different types of raisins.
Conclusion
This study verified the feasibility of near-infrared spectroscopy combined with pattern recognition algorithms for adulterated raisins. We first analyzed the near-infrared spectroscopy images of the three kinds of raisins, and there were differences in the material content of the skins of different kinds of raisins. Then, we used SVM, MCNN, and the improved AlexNet model to classify raisins and got 100% accuracy. The experimental results show that though MCNN and AlexNet achieved good prediction results, SVM had a better classification effect on the skin of raisins. This experiment overcomes the limitations of the raisin image classification method and provides a simple, accurate, and fast method for the identification of raisin varieties. This method can also be applied to the detection of other granular foods. In addition, this experiment compared the classification capabilities of traditional machine learning algorithm and deep learning algorithms on small data sets and provided a certain idea for choosing a classification model.
References
Olmo-Cunillera, A. et al. Is eating raisins healthy?. Nutrients 12(1), 54 (2020).
Fulgoni, V. L., Painter, J. & Carughi, A. Association of raisin and raisin-containing food consumption with nutrient intake and diet quality in US children: NHANES 2001–2012. Food Sci. Nutr. 6(8), 2162–2169 (2018).
Anderson, J. W., Weiter, K. M., Christian, A. L., Ritchey, M. B. & Bays, H. E. Raisins compared with other snack effects on glycemia and blood pressure: A randomized, controlled trial. Postgrad. Med. 126(1), 37–43 (2014).
Payne, T. J. Raisins in our daily bread. Cereal Foods World 50(2), 62–64 (2005).
Wei, Q., Wolf-Hall, C. & Hall, C. A. Application of raisin extracts as preservatives in liquid bread and bread systems. J. Food Sci. 74(4), M177–M184 (2009).
Payne, T. J. Raisins for health and nutrition. Cereal Foods World 48(3), 109–111 (2003).
Angulo, O., Fidelibus, M. W. & Heymann, H. Grape cultivar and drying method affect sensory characteristics and consumer preference of raisins. J. Sci. Food Agric. 87(5), 865–870 (2007).
Christensen, L. P., Bianchi, M. L., Miller, M. W., Kasimatis, A. N. & Lynn, C. D. The effects of harvest date on Thompson Seedless grapes and raisins. 2. Relationships of fruit quality factors. Am. J. Enol. Vitic. 46(4), 493–498 (1995).
Akev, K., Koyuncu, M. A. & Erbas, D. Quality of raisins under different packaging and storage conditions. J. Hortic. Sci. Biotechnol. 93(1), 107–112 (2018).
Dabeka, R. W., McKenzie, A. D. & Pepper, K. Lead contamination of raisins sold in Canada. Food Addit. Contam. 19(1), 47–54 (2002).
Khojastehnazhand, M. & Ramezani, H. Machine vision system for classification of bulk raisins using texture features. J. Food Eng. 271, 109864 (2020).
Karimi, N., Kondrood, R. R. & Alizadeh, T. An intelligent system for quality measurement of Golden Bleached raisins using two comparative machine learning algorithms. Measurement 107, 68–76 (2017).
Ramming, D. W. Water loss from fresh berries of raisin cultivars under controlled drying conditions. Am. J. Enol. Vitic. 60(2), 208–214 (2009).
Zou, Q., Fang, H., Zhang, W. & He, Y. Application of near infrared spectroscopy (NIR) for evaluating cheese quality. Spectrosc. Spectr. Anal. 31(10), 2725–2729 (2011).
Tu, Y., Liu, J. & Zhang, J. Application of near-infrared spectroscopy technology in quality control of TCM manufacturing process. Zhongguo Zhong yao za zhi = Zhongguo zhongyao zazhi = China J. Chin. Mater. Med. 36(17), 2433–2436 (2011).
Jiang, Y. & Wu, P. Y. Study of soy protein by mid-infrared spectroscopy and near-infrared spectroscopy. Prog. Chem. 21(4), 705–714 (2009).
Larsen, D. J., Von Doenhoff, L. J. & Crable, J. V. The quantitative dermination of quartz in coal dust by infrared spectroscopy. Am. Ind. Hyg. Assoc. J. 33(6), 367–372 (1972).
Li, Y.-Z., Min, S.-G. & Liu, X. Study on the methods and applications of near-infrared spectroscopy chemical pattern recognition. Spectrosc. Spectr. Anal. 27(7), 1299–1303 (2007).
Kersting, K. Machine learning and artificial intelligence: Two fellow travelers on the quest for intelligent behavior in machines. Front. Big Data 1, 6 (2018).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521(7553), 436–444 (2015).
Mu, R. H. & Zeng, X. Q. A review of deep learning research. KSII Trans. Internet Inf. Syst. 13(4), 1738–1764 (2019).
Ioffe, S. & Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning 448–456. PMLR (2015).
Li, X. L., Hu, H. Y., Xiao-Li, L. I., Xing-Yue, H. U. & Yong, H. E. A new method for identification of peach varieties by visible-infrared spectroscopy based on principal component and multiclass discriminant analysis. J. Infrared Millim. Waves 25(6), 417–420 (2006).
Osuna, E., Freund, R. & Girosi, F. J. P. C. IEEE Computer Society Conference on Computer Vision, Vision PRICSCoC, Recognition P. Training Support Vector Machines: An Application to Face Detection (2000.).
Zhu, S. S. et al. Near-infrared hyperspectral imaging combined with deep learning to identify cotton seed varieties. Molecules 24(18), 3268 (2019).
Chen, Q. S., Zhao, J. W., Fang, C. H. & Wang, D. M. Feasibility study on identification of green, black and Oolong teas using near-infrared reflectance spectroscopy based on support vector machine (SVM). Spectrochim. Acta Part A 66(3), 568–574 (2007).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. Commun. ACM 60(6), 84–90 (2017).
Schrauder, M. G. et al. Circulating micro-RNAs as potential blood-based markers for early stage breast cancer detection. PLoS ONE 7(1), e29770 (2012).
Tahir, H. E. et al. Authentication of the geographical origin of Roselle (Hibiscus sabdariffa L.) using various spectroscopies: NIR, low-field NMR and fluorescence. Food Control 114, 1072341 (2020).
Richter, B., Rurik, M., Gurk, S., Kohlbacher, O. & Fischer, M. Food monitoring: Screening of the geographical origin of white asparagus using FT-NIR and machine learning. Food Control 104, 318–325 (2019).
Tahir, H. E. et al. Authentication of the geographical origin of Roselle (Hibiscus sabdariffa L.) using various spectroscopies: NIR, low-field NMR and fluorescence. Food Control 114, 1072341 (2020).
Radler, F. The surface lipids of fresh and processed raisins. J. Sci. Food Agric. 16(11), 638–643 (1965).
Karadeniz, F., Durst, R. W. & Wrolstad, R. E. Polyphenolic composition of raisins. J. Agric. Food Chem. 48(11), 5343–5350 (2000).
Hou, W., Wang, J. F. & Liu, Y. R. Machine learning-based pattern recognition and traceability analysis of human nail spectra. Adv. Lasers Optoelectron. 1–17.
Lin, S. W., Ying, K. C., Chen, S. C. & Lee, Z. J. Particle swarm optimization for parameter determination and feature selection of support vector machines. Expert Syst. Appl. 35(4), 1817–1824 (2008).
Chen, Y. F. & Shin, H. Pedestrian detection at night in infrared images using an attention-guided encoder-decoder convolutional neural network. Appl. Sci. 10(3), 809 (2020).
Acknowledgements
This work was supported by the National Key Research and Development Program of China (2019YFC1606100 and sub-program 2019YFC1606104), the Major science and technology projects of Xinjiang Uygur Autonomous Region (2020A03001 and sub-program 2020A03001-1) and Xinjiang Uygur Autonomous Region Science and Technology Branch Project of China (2019E0282).
Author information
Authors and Affiliations
Contributions
Cheng Chen designed the project, J.G. performed the measurements, performed the statistical treatment, discussed the results and interpreted the data. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Guo, J., Chen, C., Chen, C. et al. Near-infrared spectroscopy combined with pattern recognition algorithms to quickly classify raisins. Sci Rep 12, 7928 (2022). https://doi.org/10.1038/s41598-022-12001-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-12001-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
