
Abstract
Despite the publication of great number of tools to aid decisions in COVID-19 patients, there is a lack of good instruments to predict clinical deterioration. COVID19-Osakidetza is a prospective cohort study recruiting COVID-19 patients. We collected information from baseline to discharge on: sociodemographic characteristics, comorbidities and associated medications, vital signs, treatment received and lab test results. Outcome was need for intensive ventilatory support (with at least standard high-flow oxygen face mask with a reservoir bag for at least 6 h and need for more intensive therapy afterwards or Optiflow high-flow nasal cannula or noninvasive or invasive mechanical ventilation) and/or admission to a critical care unit and/or death during hospitalization. We developed a Catboost model summarizing the findings using Shapley Additive Explanations. Performance of the model was assessed using area under the receiver operating characteristic and prediction recall curves (AUROC and AUPRC respectively) and calibrated using the Hosmer–Lemeshow test. Overall, 1568 patients were included in the derivation cohort and 956 in the (external) validation cohort. The percentages of patients who reached the composite endpoint were 23.3% vs 20% respectively. The strongest predictors of clinical deterioration were arterial blood oxygen pressure, followed by age, levels of several markers of inflammation (procalcitonin, LDH, CRP) and alterations in blood count and coagulation. Some medications, namely, ATC AO2 (antiacids) and N05 (neuroleptics) were also among the group of main predictors, together with C03 (diuretics). In the validation set, the CatBoost AUROC was 0.79, AUPRC 0.21 and Hosmer–Lemeshow test statistic 0.36. We present a machine learning-based prediction model with excellent performance properties to implement in EHRs. Our main goal was to predict progression to a score of 5 or higher on the WHO Clinical Progression Scale before patients required mechanical ventilation. Future steps are to externally validate the model in other settings and in a cohort from a different period and to apply the algorithm in clinical practice.
Registration: ClinicalTrials.gov Identifier: NCT04463706.
Similar content being viewed by others

Introduction
At 15 months after the declaration of the pandemic, there have been more than 160 M confirmed cases of coronavirus disease 2019 (COVID-19) worldwide and nearly 3.5 M in Spain1. Though vaccines have been available since December 2020, vaccination rates are uneven across countries. This fact, together with the emergence of new variants of the virus, leads to uncertainty about when global immunity will be achieved2. On the other hand, in clinical settings, physicians face patients arriving at hospitals with markedly different characteristics, probably influenced by the age groups vaccinated at each point in time and differences in virulence between strains3.
One of the main complications of COVID-19 is acute respiratory distress syndrome (ARDS). Clinical manifestations may be relatively mild in almost all patients, especially in early stages of the disease. These patients might not complain of dyspnea and have no significant increase in respiratory rate or respiratory distress4. The challenge for managers and physicians in this context is to identify patients at risk of developing severe forms of the disease with the aim of allocating resources and adequate treatments. Almost all the literature available concerning the prediction of prognosis in COVID-19 has used death5,6 or ICU transfer7,8 as the main outcome for developing models, with the aim of stratifying patients by risk of poor course. Recently, Gupta et al. have published the 4C Deterioration model for identifying patients at risk of needing ventilatory support9.
Our hypothesis is that is possible to predict clinical deterioration in hospitalized patients before the need for intensive ventilatory support. Knowledge about the characteristics of such patients must be the basis of decision support systems to improve triage systems, allowing physicians to decide advanced treatments and, thereby, avoid ICU admission.
Methods
Data collection
COVID19-Osakidetza is a sub-study within COVID19-REDISSEC (clinicaltrials.gov # NCT04463706), a prospective cohort study recruiting patients infected by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) confirmed by naso- and/or oropharyngeal swab polymerase chain reaction (PCR). We used anonymized patient level data from patients with a confirmed COVID-19 admitted to one of four public hospitals in the Basque Country. Participating hospitals serve a population of approximately 1.2 million and provide tertiary referral services to the surrounding region.
We excluded any patients admitted to these hospitals in the same period but who died in the emergency department or were, immediately or in the first 24 h of the hospital stay, admitted to a critical care unit or reached the endpoint. We also excluded patients who arrived at hospital more than 10 days after their first positive PCR test or tested positive by PCR later than 7 days after admission.
Data were internally stored and managed by the Osakidetza-Basque Public Health System. After anonymisation and removal of protected health information, the data were released in a text-delimited format for research purposes. Patient-level data were collected for the initial analyses in our study. The study protocol was approved by the Ethics Committee of the Basque Country (reference PI2020059). The Basque Country Ethics Committee (PI2020059) approved the waiver of informed consent. The study was carried out in accordance with the relevant guidelines and regulations.
We collected data on demographic variables (age, sex), comorbidities and baseline treatments. Comorbidities were assessed based on International Classification of Diseases, Tenth Revision codes that were active on the patients’ electronic health records (EHR) on arrival to the emergency department (ED). We categorized them according to whether the date of diagnosis was in the previous year or earlier. Baseline treatments were assessed based on the Anatomical, Therapeutic and Chemical/Defined Daily Dose (ATC/DDD) index in the EHR, and we categorized them into treatments prescribed in the last 6 months, between > 6 and 12 months earlier and between > 12 months and 5 years earlier (older treatments being excluded). Patients were considered to have no comorbidities or treatments if none were documented in the EHR.
Regarding hospitalization history, we collected information from the ED and up to the first 24 h after admission. This information was related to vital signs: temperature, blood pressure, respiratory and heart rate, oxygen saturation by pulse oximetry and fraction of inspired oxygen, as well as treatments prescribed (ATC/DD). We also gathered data on the most recent lab results (for tests performed up to 1 month before admission).
Our outcome was a composite endpoint defined as need for intensive ventilatory support (with at least standard high-flow oxygen face mask with a reservoir bag for at least 6 h and need for more intensive therapy afterwards or Optiflow high-flow nasal cannula or noninvasive or invasive mechanical ventilation) and/or admission to a critical care unit and/or death during hospitalization.
All the data we used were structured data.
Datasets
-
1.
Development and internal validation dataset We downloaded patient-level data for the period March 1 to April 30, 2020. We randomly split this derivation cohort, without replacement and randomly assuming a uniform distribution, to create two independent sets of patients, assigning 70% of the sample for development of the prediction model and 30% for internal validation. Data were pre-processed to address quality issues, such as allowing the elimination of repeated entries for some patients and exclusion of features with more than 25% of missing data from the list of potential predictor variables.
-
2.
Validation dataset Furthermore, a prospective validation set of patients, independent from the other datasets, referred to as the validation dataset, was composed of other patients with COVID-19 admitted from May 1 to October 7, 2020. We used this dataset as the external validation sample and it was pre-processed using the same process as that used the development and internal validation dataset. Further, the demographic and clinical data recorded for these patients were consistent with those of the patients in the development and internal validation cohorts.
In all the resulting datasets, we performed univariate analyses of the differences between patients whose condition did and did not deteriorate using Student’s t test for continuous features and the χ2 test for categorical features. We set the p value threshold for significance at 0.05 in these and other analyses in this study.
Development and validation of the predictive model
We combined the aforementioned information for machine learning analysis using the CatBoost algorithm10. Since it is a tree-based model, data normalization is not necessary and categorical variables do not need to be pre-processed.
The contribution of each feature to the model’s prediction was assessed using the Shapley Additive Explanations (SHAP) approach, which ensures high local accuracy, stability against missing data, and consistency in feature impact11. The SHAP values were calculated using https://github.com/slundberg/shap. This is a unified approach for explaining the outcome of any machine-learning model. SHAP values evaluate the importance of the output resulting from the inclusion of feature A for all combinations of features other than A. Features being shown in blue indicates that their values are less likely to predict the outcome while values of those shown in red are more likely to be predictive.
We performed four-fold cross-validation in the training set to identify the optimal hyperparameters through a random hyperparameter search and compared the training models through fourfold cross-validation area under the receiver operating curve (AUROC). We also used logistic regression implemented using the Scikit-learn library as baseline model to evaluate and compare.
Different models obtained in the development set were applied to the internal validation set and the model that performed the best based on the AUROC in this latter set was selected. We also calculated the area under precision recall curve (AUPRC) in development, internal validation and external validation sets.
We explored the calibration of models by means of a calibration plot and the Hosmer–Lemeshow Test12, which assesses whether or not the observed event rates match expected event rates in subgroups of the model population, identifying subgroups as the deciles of fitted risk values. Based on the distribution of the outcome across the predicted probability in the development and internal validation dataset, we created five risk groups, which were tested in the external validation dataset. We calculated the performance parameters for each risk group.
SAS software was used for the univariate analysis and Python to pre-process data and develop the model with the CatBoost method. Finally, the model was calibrated using R software.
Ethics approval
The study protocol was approved by the Ethics Committee of the Basque Country (reference PI2020059).
Consent for publication
The authors give their consent for publication.
Results
Data collection
For the analysis, 1568 patients were included in the derivation set, corresponding to 87% of the PCRs selected, while 956 patients were included in the validation set, corresponding to 85% of the PCRs selected. The percentages of patients who reached the composite endpoint were 23.3% vs 20.0% respectively (p value = 0.05) (Fig. 1).

Flow chart.
Datasets
There were differences between cohorts in sex and age, patients in the external validation dataset being younger (67.42 [Standard Deviation (SD):16] in the derivation dataset vs 65.75 [SD: 20], p = 0.03). There were no differences in comorbidities between cohorts except for dementia (2.36% in derivation vs 4.18 in external validation dataset, % in derivation and validation datasets respectively, p = 0.01). There were more patients taking chronic medications in the external validation dataset. We encountered statistically significant differences in all baseline medications considered except for antihypertensives and immunosuppressants. Regarding vital signs on arrival, no differences were detected except for temperature and oxygen saturation, being lower and higher respectively in the validation sample than in the development sample. We also found differences in several lab results, specifically, inflammation makers, namely, lactate dehydrogenase (LDH) and C-reactive protein (CRP), being lower in the development sample (Table 1). Suplementary Information Table S1 shows more information about differences between cohorts.
Table 2 shows the relationship between predictors and the outcome in the development and internal validation dataset and external validation dataset. Among patients who deteriorated, the percentage of males was higher in the derivation dataset (56% vs 69%, p < 0.0001), while there were no differences in the external validation dataset (p = 0.10). Deteriorated patients were older in both datasets. Further, in both datasets, cerebrovascular diseases were more frequent in deteriorated patients, as were chronic pulmonary disease, diabetes, kidney disease and cancer, and in general, they took chronic medications more frequently and had lower oxygen saturation on arrival at the ED. They also presented with higher values of CRP and LDH, lower platelet counts and higher values of mean corpuscular volume (MCV) and red blood cell distribution width (RDW) in both cohorts. Further, in these patients with a poor course, lymphocyte counts were lower in the external validation dataset, while neutrophil counts and D-dimer levels were elevated in both cohorts. Supplementary Information Table S2 shows univariate analysis.
Development and validation of the predictive model
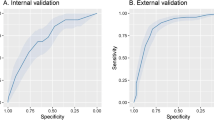
Figure 2 presents main variables in the CatBoost model. The strongest predictors of clinical deterioration were arterial blood oxygen pressure, followed by age, levels of several markers of inflammation (procalcitonin, LDH, CRP) and alterations in blood count and coagulation. Some medications, namely, ATC AO2 (antiacids) and N05 (neuroleptics) were also among this group of main predictors, together with C03 (diuretics). The predictive performance of the CatBoost model in the derivation and validation sets are shown in Fig. 3.

Main predictors in catboost model in (a) derivation-internal validation and (b) external validation datasets. PO2-A partial arterial oxygen concentration, PCR C-reactive proteine, PCT procalcitonine, Edad age, LDH lactate dehydrogenase, PLT platelets, ADE RED blood cell distribution width, CREA creatinine, Mon%A Total count of monocytes, CK creatine kinase, Dimer D dimer, EOS%A Percentage of eoshinophils, AO2_12 Antacids in the last 12 months, N05_12 neuroleptics in the last 12 months, MON#A total count of monocytes, GLU glucose, EOS#A TOTAL count of eosynophils, lin#A total count of lynphocites, Neu%A percentage of neutrophils, CO3_12 diuretics in the last 12 months.

Predictive performance of the catboost model in (a) derivation and (b) validation sets.
We used SHAP values to provide consistent and locally accurate attribution values for each feature within the prediction model. Patients who reached the endpoint obtained the lowest values for partial pressure of oxygen, platelets, lymphocytes, monocytes and eosinophils and the highest values for CRP, age, procalcitonin, urea, LDH, RDW, creatine kinase, creatinine, D-dimer and glucose. In the case of baseline treatments, which were dichotomous variables, those who took neuroleptics, antacids and/or diuretics were more likely to deteriorate than those who did not.
Calibration plots are shown in Fig. 4, the Hosmer–Lemeshow test p value being < 0.001 in the development cohort and 0.3654 in the validation cohort.

Calibration performance in (a) derivation and (b) validation sets.
We explored the distribution of the outcome across the predicted probability based on the scores from the CatBoost classifier. We considered five different cut-off points (> 0.04, > 0.13, > 0.23, > 0.47 and > 0.82) to classify patients as reaching or not reaching the endpoint based on predicted values of probability. Table 3 shows the performance parameters for each cut-off point, the lowest group being the most sensitive and the highest group the most specific. The negative predictive value ranged between 0.81 and 0.99 across the risk groups. In addition, the variable representing patients risk stratification was defined considering the cut-off points mentioned above and creating complementary risk groups.
Discussion
We have developed and validated a clinical prediction model including routinely available information recorded in the EHR. This model includes chronic treatments prescribed at baseline, lab results and vital signs on arrival at hospital and predicts poor course in patients with COVID-19 before transfer to an ICU. Therefore, it is expected that it could improve triage systems allowing earlier identification of patients who are likely to need intensive ventilatory support. These decision support systems must be feasible, and have to be continuously updated to detect variations in patients’ characteristics that make them differently vulnerable.
Deciding whether or not to intubate is a critical aspect of caring for patients seriously ill with COVID-1913. We excluded patients in which emergent intubation was required, and hence, the algorithm is designed to detect poor prognosis in patients who arrive at a hospital ward with severe COVID, requiring oxygen therapy. We believe ICU transfer is not a good outcome to consider if seeking to identify all patients who have a poor course in COVID-19 as it results in an under diagnosis of severe forms of the disease. We believe that the outcome should be a composite endpoint of ICU transfer, mortality, and need for intensive ventilatory support, corresponding to a score of 5 or more on the WHO Clinical Progression Scale14, including patients who will need standard high-flow oxygen face mask with a reservoir bag, if we want to identify the whole spectrum of patients who develop severe forms of this disease.
Izquierdo et al. have recently published a predictive model of ICU admission of patients with COVID-19 based on a sample of 10,504 patients in a region of Spain. One of the limitations of that model is that they did not include lab results or baseline treatments in their prediction model, their conclusion being that age, fever, and tachypnea were the main predictors of ICU admission8. We believe that these predictors occurred late in the presentation of the disease; in contrast, our work provides clinicians and health managers an aid to take earlier decisions.
The recently published 4C Deterioration model used a composite primary outcome of in-hospital clinical deterioration considering initiation of ventilatory support from the start of noninvasive ventilation (score of 6 on the WHO Clinical Progression Scale). We defined intensive ventilation as the need for 100% O2, including patients not candidates for mechanical ventilation but whose condition deteriorated and this is a main strength of our work. We included all data available for each patient related to the information we wanted to enter into the model: comorbidities, treatments, lab results and vital signs, without a priori definitions for each variable. The goal of Gupta et al. in proposing the 4C deterioration model was that it should be easily usable9. Our main goal was, by contrast, to achieve the greatest possible accuracy in our predictions, since we envisaged its implementation in the EHR, and depending on the pre-selected decision threshold, physicians would receive the performance parameters automatically to aid their decision-making.
We derived the model in the first months of pandemic, and therefore, differences between patients in the derivation and external validation cohorts were expected. While there were differences in sociodemographic characteristics, we did not detect differences in comorbidities except for dementia. This could be due to the availability of hospital beds beyond the first months of the pandemic, since in the first months, patients with dementia were more likely to be treated in care homes. Other differences were encountered in inflammatory markers and other lab results, values being slightly better in patients in the validation cohort than in those in the derivation cohort; nevertheless, these differences were not clinically significant.
In any case, our model was sufficiently robust to identify patients at risk of clinical deterioration under new conditions, presenting excellent performance properties in other settings/circumstances.
In the literature, there is at least moderate evidence of predictive value in COVID-19 for almost all of our main predictors (partial pressure of oxygen, age, PCT, LDH, CRP, BUN, PLT, CK, D-dimer, creatinine, and lymphocyte count)15. RDW on admission and an increase therein during hospitalization have been proposed as predictors of mortality, especially in younger patients16. We also found low levels of monocytes and eosinophils to be related to poor course17. Such variations in blood cell counts with the progression of the disease are to be expected, but we provide the probability of poor outcomes depending of the magnitude of these variations, adjusted for other characteristics of the patients and this is another strength of our work.
A recent meta-analysis indicated that patients with upper gastrointestinal diseases taking omeprazole may be more vulnerable to COVID-19, without confirmation of severe disease being associated with other drugs in the same ATC group18. Some authors have hypothesized that psychiatric patients could be protected against COVID-19 due to being on neuroleptics, but this has not been confirmed in our study19. Another possible explanation for antacids and neuroleptics being among the main predictors is that they were acting as a proxy for the overall number of drugs taken by patients. We assessed the number of drugs prescribed among the group of patients who took antacids or neuroleptics compared to that in patients who did not take these types of medications, and we found significant differences. Specifically, patients who took antacids or neuroleptics took eight drugs compared to two in the groups of patients who did not take them (data not shown). Oddy et al. identified diuretics as protectors of ICU admission and cardiac arrest as well being associated with lower oxygen requirements20, while Cabezon et al. did not find a poorer prognosis in patients who took diuretics21.
Our model presented excellent AUROCs and this indicates that the algorithm is sufficiently sensitive to identify patients at risk of needing intensive ventilatory support and acceptable AUPRC indicates that the algorithm is able to distinguish false positives. We proposed several cut-off points to aid decisions about allocation of care to patients. Another advantage of our model is that it takes into account all the comorbidities and baseline medications recorded, in a more specific way than models for predicting poor prognosis described to date9,22,23. Indeed, our machine-learning based model is designed to detect which patients in the pulmonary phase at admission are going to need ventilatory support during their hospital stay. Bardley et al. recommended focusing on features of respiratory compromise rather than circulatory collapse as almost all the predictive models do23.
A limitation of our work is the calibration performance of the model in the derivation dataset. Specifically, there is some under prediction when the observed probability of experiencing deterioration is greater than 0.5, while there is a slight over prediction when the observed probability is below 0.25. Nevertheless, the estimated and observed probabilities in the external validation dataset are very well calibrated, which indicates that the model has a good fit when applied to an external sample, although it is true that, as might be expected, the estimates in the 10 groups do not show a monotonic growth. This could be due to differences in the profile of patients across the waves of the pandemic as well as in the response of the health system and medical knowledge of the disease3. This leads us to recommend the use of dynamic models, that is, models should be continuously updated after their implementation in clinical practice to adjust them for these differences. Figure 5 outlines differences between traditional models and those based on machine-learning systems. Clinicians are provided with the result of the model automatically, and the model updates with the change in profiles of patients or changes in health system practices, such as changes in treatment protocols. Preprocessing code plus model training will be available on specific request in clinical trials.gov.

Differences between traditional development and machine-learning based prediction models.
Conclusions
In conclusion, we present a machine-learning based prediction model with excellent performance properties to be implemented in EHRs. Our main goal was to predict progression to a score of 5 or higher on the WHO Clinical Progression Scale prior to patients requiring mechanical ventilation. Future steps are to externally validate the model in other settings and in a cohort from a different time period and to apply the algorithm in clinical practice14.
Data availability
Data available on request from the authors.
Change history
12 May 2022
A Correction to this paper has been published: https://doi.org/10.1038/s41598-022-12247-9
References
Spanish Ministry of Health. Current Pandemic Situation (Spanish Ministry of Health, 2020).
Omer, S. B., Yildirim, I. & Forman, H. P. Herd Immunity and Implications for SARS-CoV-2 Control (2020).
Domingo, P. et al. Not all COVID-19 pandemic waves are alike. Clin. Microbiol. Infect. Off. Publ. Eur. Soc. Clin. Microbiol. Infect. Dis. 27, 1040 (2021).
Li, X. & Ma, X. Acute respiratory failure in COVID-19: Is it “typical” ARDS? Crit. Care 24(1), 1–5 (2020).
Chidambaram, V. et al. Factors associated with disease severity and mortality among patients with COVID-19: A systematic review and meta-analysis. PLoS ONE 15(11), e0241541. https://doi.org/10.1371/journal.pone.0241541 (2020).
Wu, G. et al. Development of a clinical decision support system for severity risk prediction and triage of COVID-19 patients at hospital admission: An International Multicentre Study. Eur. Respir. J. 56, 2001104. https://doi.org/10.1183/13993003.01104-2020 (2020).
Cheng, F.-Y. et al. Clinical medicine using machine learning to predict ICU transfer in hospitalized COVID-19 patients. J. Clin. Med. 2020, 1668 (1668).
Izquierdo, J. L., Ancochea, J., Soriano, J. B. & Soriano, J. B. Clinical characteristics and prognostic factors for intensive care unit admission of patients with COVID-19: Retrospective study using machine learning and natural language processing. J. Med. Internet Res. 22(10), e21801 (2020).
Gupta, R. K. et al. Development and validation of the ISARIC 4C deterioration model for adults hospitalised with COVID-19: A prospective cohort study. Lancet Respir. Med. 3, 349 (2021).
Barmaki, R. Multimodal assessment of teaching behavior in immersive rehearsal environment—TeachLivETM. In ICMI 2015—Proc. 2015 ACM Int. Conf. Multimodal Interact, Vol. 139, 651–655 (2015).
Rodríguez-Pérez, R. & Bajorath, J. Interpretation of machine learning models using shapley values: Application to compound potency and multi-target activity predictions. J. Comput. Aided Mol. Des. 34, 1013–1026. https://doi.org/10.1007/s10822-020-00314-0 (2020).
Hosmer, D. W. & Lemeshow, S. Applied Logistic Regression 2nd edn, 1–375 (Springer, 2000).
Berlin, D. A., Gulick, R. M. & Martinez, F. J. Severe covid-19. N. Engl. J. Med. 383, 2451–2460 (2020).
Marshall, J. C. et al. A minimal common outcome measure set for COVID-19 clinical research. Lancet Infect. Dis. 20(8), e192–e197 (2020).
Izcovich, A. et al. Prognostic factors for severity and mortality in patients infected with COVID-19: A systematic review. PLoS ONE 15(11), e0241955. https://doi.org/10.1371/journal.pone.0241955 (2020).
Foy, B. H. et al. Association of red blood cell distribution width with mortality risk in hospitalized adults with SARS-CoV-2 infection + supplemental content conclusions and relevance elevated RDW at the time of hospital admission and an increase in RDW during hospitaliza. JAMA Netw. Open 3(9), 2022058 (2020).
Ouyang, S. M. et al. Temporal changes in laboratory markers of survivors and non-survivors of adult inpatients with COVID-19. BMC Infect. Dis. 20(1), 1–10 (2020).
Fan, X. et al. Effect of acid suppressants on the risk of COVID-19: A propensity score-matched study using UK biobank. Gastroenterology 160(1), 455-458.e5 (2021).
Plaze, M. et al. Repurposing chlorpromazine to treat COVID-19: The reCoVery study. Encephale 46(3), 169–172 (2020).
Oddy, C. et al. Pharmacological Predictors of Morbidity and Mortality in COVID-19. 61(10), 1286–1300 www.icmje.org/coi_disclosure.pdf. (Accessed 1 Aug 2021).
Alberto, J. et al. Impact of the presence of heart disease, cardiovascular medications and cardiac events on outcome in COVID-19. Cardiol. J. 28(3), 360–368 (2021).
Satici, C. et al. Performance of pneumonia severity index and CURB-65 in predicting 30-day mortality in patients with COVID-19. Int. J. Infect. Dis. Off. Publ. Int. Soc. Infect. Dis. 98, 84–89 (2020).
Bradley, P., Frost, F., Tharmaratnam, K. & Wootton, D. G. Utility of established prognostic scores in COVID-19 hospital admissions: Multicentre prospective evaluation of CURB-65, NEWS2 and qSOFA. BMJ Open Respir. Res. 7(1), e000729 (2020).
Acknowledgements
We are grateful for the support of the Basque Health Service-Osakidetza and the Department of Health of the Basque Government. We also gratefully acknowledge the patients who participated in the study and the COVID-Redissec Working Group. The authors also would like to thank Ideas Need Communicating Language Services for improving the use of English in the manuscript.
Funding
This work was supported in part by grants from the Instituto de Salud Carlos III and the European Regional Development Fund COVID20/00459; the health outcomes group from Galdakao-Barrualde Health Organization; the Kronikgune Institute for Health Service Research; and the thematic network–REDISSEC (Red de Investigación en Servicios de Salud en Enfermedades Crónicas)–of the Instituto de Salud Carlos III. The funder of the study had no role in study design, data collection, analysis, management or interpretation, or writing of the report.
Author information
Authors and Affiliations
Consortia
Contributions
S.G.G. contributed to the study design, data collection, data analysis, data interpretation, writing of the original draft, review, editing and approval the final version. C.E.A., contributed to the data analysis, data interpretation, writing of the original draft, review, editing and approval the final version. I.L., contributed to the data collection, data interpretation, writing of the original draft, review, editing and approval the final version. I.B., contributed to the data analysis, data interpretation, writing of the original draft, review, editing and approval the final version. R.Q. contributed to the study design, data collection, data interpretation, writing of the original draft, review, editing and approval the final version. J.M.Q., contributed to the study design, data analysis, data interpretation, writing of the original draft, review, editing and approval the final version. A.U. contributed to the study design, data interpretation, writing of the original draft, review, editing and approval the final version. The COVID-REDISSEC Working Group contributed to the data collection, data interpretation, review, editing and approval the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained an error in Affiliation 2, which was incorrectly given as ‘Cambrian Intelligence, London, UK’. The correct affiliation is ‘Cambrian Intelligence SLU, Madrid, Spain’.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Garcia-Gutiérrez, S., Esteban-Aizpiri, C., Lafuente, I. et al. Machine learning-based model for prediction of clinical deterioration in hospitalized patients by COVID 19. Sci Rep 12, 7097 (2022). https://doi.org/10.1038/s41598-022-09771-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-09771-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
