
Abstract
Based on wind speed, direction and power data, an assessment method of wind energy potential using finite mixture statistical distributions is proposed. Considering the correlation existing and the effect between wind speed and direction, the angular-linear modeling approach is adopted to construct the joint probability density function of wind speed and direction. For modeling the distribution of wind power density and estimating model parameters of null or low wind speed and multimodal wind speed data, based on expectation–maximization algorithm, a two-component three-parameter Weibull mixture distribution is chosen as wind speed model, and a von Mises mixture distribution with nine components and six components are selected as the models of wind direction and the correlation circular variable between wind speed and direction, respectively. A comprehensive technique of model selection, which includes Akaike information criterion, Bayesian information criterion, the coefficient of determination R2 and root mean squared error, is used to select the optimal model in all candidate models. The proposed method is applied to averaged 10-min field monitoring wind data and compared with the other estimation methods and judged by the values of R2 and root mean squared error, histogram plot and wind rose diagram. The results show that the proposed method is effective and the area under study is not suitable for wide wind turbine applications, and the estimated wind energy potential would be inaccuracy without considering the influence of wind direction.
Similar content being viewed by others

Introduction
Energy consumption increases dramatically with the rapid development of society and economy. Wind energy has attracted more and more attention because of its advantages such as abundance, renewability, natural cleanness, low cost and little negative impact on the environment, and has been used as an alternative to fossil fuels1,2. Therefore, the application of wind energy has already been selected as an important measure for the sustainable development of resources and environment all over the world. Wind energy also plays an important role in national economic growth which creates more employment opportunities3,4. Before developing wind power in a certain site, including the design, arrangement and condition monitoring of wind turbine systems, it is necessary to assess the wind energy potential and wind characteristics5.
As wind energy is proportional to the cube of wind speed, this means that even a small increase in wind speed results in a large increase in wind energy, therefore, the most important factor affecting wind energy is wind speed. But wind speed is not constant, it always fluctuates with the varying of air temperature over a period of time in different geographic locations and seasons. In this case, we can take wind speed as a random variable and describe it by a probability density function (pdf). Therefore, the pdf of wind speed becomes an important basis for evaluating wind energy potential and wind stochastic characteristics6. If the frequency distribution of wind speed is comprehensively expressed by an estimated pdf, the wind power density and wind energy output of wind turbines can be evaluated, which can help us make a reasonable decision whether to build a wind farm in the observed area or not, and reduce the uncertainties and the errors of wind power output estimation7. At the same time, the accurate estimated pdf can also help us to select an optimal wind energy conversion system and evaluate the reliability of generation system. Therefore, accurate evaluation of wind speed pdf is conducive to the prediction of wind energy potential and the selection of an optimal wind energy conversion system8.
There are families or groups of parametric models and nonparametric models describing wind characteristics. The parametric models are also divided into single and mixture distribution models. At present, the most widely used single distribution models include Gamma, Raleigh, Inverse Gaussian distribution, lognormal and Weibull distribution models2,3,4,5,6,7,8,9,10,11,12,13,14, etc. Among them, the two-parameter Weibull distribution model is often recognized as an effective model and is widely used in the field of wind industry to estimate wind energy potential mainly due to its simplicity. In some cases, the probability of calms (null wind speed) or the wind speed below 2 m/s is significant, and the two-parameter Weibull distribution performs poorly for a high percentage of null wind speed. While it can be observed that the three-parameter Weibull distribution gives a better result of energy calculation when the frequency of null wind speed is higher4,13. A wind turbine can generate electricity only when wind speed exceeds the cut-in speed. So Deep et al.14 pointed out that a three-parameter Weibull distribution must be used to model wind speed data between the cut-in and cut-out wind speeds, and the location parameter can be equivalent to the cut-in wind speed. On the other hand, when a distribution of wind speed is bimodal or multimodal, a single distribution model cannot perform well. In this case, some mixture distribution models5,8,15,16,17,18,19,20,21,22,23,24, which consist of several single distribution models (called components), are used, such as the Weibull-Weibull mixture, the Gamma-Weibull mixture, the truncated Normal-Weibull mixture, etc.
Wind direction is also an important aspect affecting the wind energy when evaluating wind characteristics in a certain area. Gugliani et al.25 argued that it is futile to study wind power at a particular site when wind direction was not analyzed. Han and Chu26 also considered that the available wind resources change with the wind direction, especially in the low-speed and complex terrain areas. Therefore, the mixture model of von Mises (voM) distribution is commonly used for modelling wind direction data27,28,29,30,31,32. Besides the voM distribution, the other circular statistical distributions including the uniform distribution, wrapped-normal distribution and wrapped-Cauchy distribution, etc. are also suitable for modelling analysis of wind direction. The research results showed that a mixture of voM distributions provided a flexible model for studies of wind direction that have several modes27,28. However, compared to wind speed model, the statistical modeling of wind direction is more difficult and complex. On the other hand, wind speed and wind direction are dependent random variables, wind speed has a directional characteristic and wind direction can complement information about wind speed in analyses of wind energy potential28,29. Therefore, in the past fewer decades, several bivariate distribution models for simultaneously describing wind speed and direction, which named joint distribution models of wind speed and direction, have been proposed by different authors33,34,35,36,37,38,39,40. Carta et al.33 presented a joint distribution from two marginal distributions, a single truncated from below Normal-Weibull mixture distribution for wind speed and a finite mixture of voM distributions for wind direction. Erdem and Shi35 given a comparison of bivariate distribution models for analyzing wind speed and direction data of multiple sites in North Dakota, USA.
The methods commonly used to estimate model parameters of wind speed or wind direction are the graphical method or least square method (LSM), maximum likelihood estimate (MLE), modified maximum likelihood estimate (MMLE), empirical method (EmM), moment method (MoM), power density method (PDM), energy pattern factor method (EPFM), equivalent energy method (EEM) and copula-based approach, etc. Non-parametric model methods were also proposed in literature. These methods include the minimum cross entropy (MCE) method41, maximum entropy principle method (MEPM)42, kernel density estimation43,44,45 and root-transformed local linear regression method46, etc.
In this study, to evaluate wind energy potential, the single and mixture of two-parameter and three-parameter Weibull distributions are used as candidate models for wind speed data, and a finite mixture of voM distributions is used for wind direction data. Based on MLE, the expectation–maximization (EM)8,29,45,47 optimization algorithm is applied to estimate model parameters of mixture distributions. As Carta et al.27 pointed out that although the mixture distributions enrich the modelling and have high degrees of fits, the model complexity increases with the increasing of more number of model parameters. Therefore, we use Akaike information criterion (AIC) and Bayesian information criterion (BIC) to select the optimal model, and adopt the coefficient of determination R2 and the root mean squared error (RMSE) to evaluate the goodness-of-fit of model. The number of components in mixture model does not need to be known in advance.
Therefore, the novelty and main contributions of this work can be summarized as follows: (1) For null or low wind speed and multimodal wind speed data, we use three-parameter Weibull mixture distributions to model its pdf, the number of components in mixture model can be optimally determined using a comprehensive technique of model selection. (2) Based on the wind power curve of a specified wind tribune, the wind energy output considering the effect of wind speed and direction simultaneously can be given. The effectiveness of the proposed method is verified by a real case.
The paper is organized as follows. In “Methodology” we give some details on the modelling for wind data using the Weibull and voM distributions, including parameter estimation, model selection and validation. The assessment of wind energy potential is described in “Wind power estimation”. While in “Case study” presents some information about the observed field and the statistical description for wind speed, its direction and wind power. Results and comparison with the observation data are presented with details in “Results and discussion”. Conclusions are drawn in the final and concluding section.
Methodology
Wind speed model with Weibull distribution
When the frequency of low wind speed, especially of null wind is significant, a three-parameter Weibull distribution can be used to model this wind speed data well and a more appropriate results can be obtained. The pdf of wind speed using the three-parameter Weibull distribution is given by4,13:
where v is wind speed, η is the scale parameter (m/s), η > 0, β represents the shape parameter, β > 0, and γ is the position parameter, γ ≤ 0. When γ = 0, three-parameter Weibull distribution reduces to two-parameter Weibull distribution.
Mixture distributions are defined as linear combinations of two or several distributions. Therefore, there are more parameters needed to estimate for mixture distribution model than that of single distribution model. And parameter estimation of mixture distribution model is more complex and difficult. The MLE is one of the efficient methods to estimate model parameters.
Mixture model is a weighted sum with several single models16,17,18,19,22,23,24, therefore, a pdf of mixture distribution model for m-component three-parameter Weibull distributions can be given by
where wi is the weight coefficient of the ith component, and must satisfy the following conditions:
Given the n observed wind speed data V = [v1,v2,…,vn], the likelihood function on V can be obtained by
where Λ = [w, η, β, γ] are unknown model parameters of wind speed.
Then the log-likelihood function can be given as follows:
Due to the complexity of the log-likelihood function, the model parameters cannot be got by taking the partial derivatives of log-likelihood function with respect to each parameter and setting them equal to zero. Therefore, the log-likelihood function is maximized directly to estimate the model parameters. Unfortunately, there is no closed-form expression for computing them, it only can be numerically estimated. Therefore, a numerical method, such as EM algorithm is needed to find the maximum likelihood estimates of the parameters.
EM algorithm is an iterative method for finding maximum likelihood or maximum a posteriori estimates of model parameters for statistical distribution from a given data set. It proceeds iteratively in two steps, the expectation (E) step and maximization (M) step. In the E-step, a function for the expectation of the log-likelihood is created, and the hidden variables or missing data are estimated given the observed data and current estimator of model parameters. In the M-step, the likelihood function defined by the previous E-step is maximized to obtain new parameter estimations under the assumption that the hidden variables or missing data are known. It should be noted that the E-step and M-step in EM algorithm are performed iteratively until the algorithm converges. Initial values are required for the iterative procedure. In this study, the population is divided into m components, and the estimated parameters are assumed to have the same values with a single Weibull distribution for each component. These estimates are considered as initial values for the iterative procedure.
For an m-component mixture model, Eq. (6) is used to find the mean c1, variance c2, the coefficients of skewness c3 and kurtosis c4 of wind speed, respectively.
When the model parameters of three-parameter Weibull mixture distributions are known, based on Eq. (6), the values of c1, c2, c3 and c4 can be obtained as follows, respectively:
Wind direction model with von Mises distribution
For the assessment of wind direction, the voM distribution is used. Consider a random variable θ following the voM distribution, the corresponding pdf is27,28
where θ is wind direction in radians units, μ denotes location parameter or mean direction on the circle, 0 ≤ μ ≤ 2π, α represents concentration parameter, α ≥ 0, and I0 (α) is the modified Bessel function of the first kind of order zero, given by27,28
When wind direction has several modes or prevailing wind directions, the distribution of wind direction comprises a finite mixture of voM distributions. Thus, based on Eq. (11), the corresponding pdf of mixture distribution model can be given by
where k is the number of components and pi is the weight coefficient of the ith component that sum to one, given by
The mixture of voM distributions corresponds to the weighted sum of several voM distributions. It is thus suitable for the statistical description of multimodal datasets. Given the n observed wind direction data Θ = [θ1, θ2, …, θn], the likelihood function on Θ is given by
where Δ = [p, μ, α] are unknown model parameters of wind direction. Then the log-likelihood function is computed by the following expression:
The model parameters can also be estimated by the EM algorithm for maximum likelihood estimation29,47.
If the model parameters of the voM mixture distributions are known, the mean b1 and variance b2 can also be got as follows, respectively:
Joint distribution model of wind speed and direction
Based on Eq. (2), the corresponding cumulative distribution function (CDF) for wind speed is given as follows:
Equation (13) can also be expressed as a series of Bessel functions and given by.
where Iq (α) is the modified Bessel function of the first kind of order q, whose expression is given by
Therefore, using Eq. (20), the CDF for wind direction can be obtained as follows:
The joint angular-linear pdf of wind speed and direction is then given as33
where g(ζ) is the correlation pdf of circular variable ζ between wind speed v and direction θ, and ζ given by33
Using the above definitions, the values of ζj can be obtained for each pair of values of wind speed vj and direction θj (j = 1, 2, …, n) from a sample of size n given as33
Therefore, based on Eqs. (2), (13), (19), (22) and (24), the pdf g(ζ) of the variable ζ can also be described by a mixture of voM distributions.
Selection of optimal model
For mixture distribution model, the selection of the number of components is important. The log-likelihood cannot be directly used for selecting the number of components, since the log-likelihood value increases with the number of components. The best models of wind speed and direction are selected by two information criteria, which are named the Akaike information criterion (AIC)12,25,39,47 and Bayesian information criterion (BIC)37. The values of AIC and BIC are defined as
where l is the number of estimated parameters, n is the number of all observations, and maxlnL is the maximized log-likelihood. In this study, the number of unknown parameters l = 4 m-1 for m components three-parameter Weibull mixture wind speed model, and l = 3 m-1 for m components voM mixture wind direction model. The maxlnL can be obtained by Eqs. (5) and (16) with EM algorithm. AIC and BIC contain the penalization terms that take into account the number of model parameters and all observed values to counterbalance the maximized log-likelihood. To avoid overfitting, AIC penalizes model for its complexity only with model parameters, while BIC imposes a greater penalty for additional parameter than AIC. So, AIC and BIC give a comprehensive balance in order to find a good tradeoff between the goodness-of-fit and the complexity of the model, and avoid the risk of choosing a complex model with a poor generalization. The smaller the values of AIC and BIC are, the higher the fit accuracy of model is. Therefore, the number of components does not need to be known in advance.
Validation of model
The coefficient of determination (R2) and the root mean squared error (RMSE) are used to judge the goodness-of-fit of different mixture models to wind speed and direction data, because it quantifies the correlation between the observed and the estimated probability density according to a particular distribution.
The coefficient of determination is the square of the correlation between the estimated values and observed values, and is defined by13,16
where yj is the jth observed value, ym is the mean value of all observations, and \(\hat{y}_{j}\) is the jth estimated value, respectively. A large value of R2 indicates the proposed distribution fits the wind speed data set well in all candidate models.
Unlike the value of R2, a high RMSE value indicates a poor fit. The smaller the values of RMSE are, the better the proposed distribution function approximates the observed data. It can be given by13,16
Wind energy estimation
The density of air changes slightly with air temperature and with altitude at a potential site, supposed that air density is constant, based on a pdf f(v) of wind speed v at a height for a wind turbine, in theory, the wind power P(v) in W can be computed by10,12
where ρ is air density (kg/m3), A is the sweep area of a wind turbine rotor (m2). Therefore, the wind power density p(v) in W/m2 can be given as
Using the real wind speed values of time series wind data, the effective wind power density, denoted as pe(v) in W/m2 is estimated as follows12,22,42:
where ne is the number of effective wind speed, which lies between the cut-in wind speed vin and cut-out wind speed vout of wind turbine.
If the wind direction influence is ignored, the wind power density p(v) for a specified wind turbine can be obtained numerically by
When considering the effect of wind direction, similar to Eq. (32), the wind power density p(v,θ) at different wind speed and direction can be computed numerically by37
The power curve gives a relation between the output power Pw(v) and wind speed v, and this relation can be expressed by a polynomial function of degree u as follows48,49,50:
where Pw(v) is the output power, Pr denotes the rated power of wind turbine, vr represent the rated speed, a0 and ai are the regression constants which can be obtained using a polynomial regression method.
Based on the power curve of a specified wind tribune, the wind energy output E(v,θ) with a joint pdf of wind speed and direction within a period of time t can be calculated numerically by33
Case study
Wind speeds are continuously acquired for a significant time, usually not less than one year. Therefore, the data used in this study were collected in a period of one year (January 1, 2019 to December 31, 2019) and measured at a height of 30 m above the ground level from the Maling Mountain wind farm (34°31.4′ N and 118°45.7′ E) located in Jiangsu Province, China (see Supplementary Table S1 on line). The Maling Mountain wind farm is selected due to the fact that the histogram of wind speed indicates that the frequency of 0–2 m/s wind speed range is 8.25% for this station (see Supplementary Table S2 on line). The percentage of null wind speed or calms (0–0.2 m/s) at this wind farm is 0.50%. Wind direction data are circular because they are recorded in terms of degrees, from 0° clockwise to 360°. However, for modeling convenient, the data are converted into radian units. After removing some abnormal and unreasonable data such as the missing data by sensor fault, measurement error data and low temporal resolution data, a total of 47,084 wind data are collected. The statistical description of wind speed, its direction and wind power data for 1.8 MW wind turbine are shown in Table 1.
Results and discussion
The estimated parameters with different methods for the Weibull distribution wind speed model are shown in Table 2.
A comparison results with different methods for the Weibull distribution wind speed model are also given in Table 3. Based on the information criteria of AIC and BIC, we can see that the fit accuracy of mixture model is higher than that of single model, and the accuracy of LSE is the lowest. For single model, three-parameter model has a higher fit accuracy than that of two-parameter model. The reason is that the former considers the null wind speed. However, for mixture model, as the number of components increases, the accuracy of the model decreases. Therefore, we select two-component three-parameter Weibull mixture model as the optimal model for wind speed. This result is also confirmed by the values of RMSE and R2. Because a lower value of RMSE and a higher value of R2 indicate a better fit of the model to the data, and two-component three-parameter Weibull mixture model has the lowest value of RMSE and highest value of R2 in all candidate models. It is worth noting that in the case of multi-modal data, the fitting, modeling and analysis for a statistical distribution are more accurate than an ordinary regression analysis, a value of R2 only more than 0.7 is not sufficient28. In this study, this value is high, it is 0.9944.
The fit results of different models are given in Fig. 1. It also shows that two-component three-parameter Weibull mixture model adequately fits the frequency histogram of wind speed well than other models. The fit accuracy of three-component three-parameter Weibull mixture model and two-parameter Weibull single model with LSE method is the lowest in all models. To fit the sample histogram, the wind speed and direction intervals must be given. In this case, the bin size of wind speed and direction interval is selected as 0.5 m/s and 10° (0.1745 rad)7,21,27,29,35, which is often considered to be reasonable in wind energy analyses. The speed interval of 0.5 m/s is also close to the value of 2 km/h (approximates 0.56 m/s) used by Deep et al.14 and Gugliani et al25. They concluded that the class width of 2 km/h gives a minimum error for modelling wind speed data.

Histogram of wind speeds. The bin size of wind speed interval is 0.5 m/s. The bold dotted line of two-component three-parameter Weibull mixture distribution with EM algorithm (3-p EM, m = 2) gives the best fitting accuracy to the histogram of wind speed in all candidate distribution. Figure created using Matlab R2014a (https://www.mathworks.com).
A statistical description of wind speed data can give some useful information on wind speed, such as mean, variance, symmetry and flatness. We can also calculate them using Eqs. (7)-(10) and compare them with the statistical description in Table 1 to verify the rightness and effectiveness of our proposed method. Therefore, using Eqs. (7)-(10), the estimated values of the mean, variance, the coefficients of skewness and kurtosis for wind speed can be obtained, respectively, as follows: c1 = 4.6666, c2 = 3.2406, c3 = 0.1470 and c4 = 2.8026. Compared to the real statistical values in Table 1, we can find that the relative errors of mean and variance are small, they are only 6.30% and 2.51%, respectively, and the estimated values of c3 > 0 and c4 < 3. All these indicate that the probability distribution of wind speed has a long and light right tail than a normal distribution. This result also agrees well with two-component three-parameter Weibull mixture distribution in Fig. 1.
Table 4 is the results of estimated parameters with different components for voM wind direction model.
Table 5 is a comparison results with the different mixture models for wind direction. It can be observed that increasing the number of voM components from one to ten in the mixture distributions will increase the value of the R2 coefficient, which indicates a better fit to the data. However, when the number of components increases to ten, the value of the R2 coefficient does not increase any more, it is the same as the nine-component mixture model has. At the same time, a nine-component mixture model has the same value of RMSE as a ten-component mixture model. In this situation, how to select the best wind direction model? However, it is noticed that nine-component mixture model has lower values of AIC and BIC, so based on the information criteria of AIC and BIC, and the values of RMSE and R2, the best wind direction model would be selected using the comprehensive criteria of information and goodness-of-fit. It can be concluded that the most suitable model for wind direction at this station is a voM mixture model with nine-component distributions. Generally speaking, a voM mixture distribution with six components for the modelling of wind direction is enough, increasing the number of components of mixture distributions, the variations in value of R2 are not significant27. On the contrary, it would yield a complex model. Therefore, combining with the comprehensive criteria of model selection, an appropriate number of mixture distributions can be selected, which not only reduces the computational burden but also improves the model accuracy, and the model has a higher predictive ability.
The fit results of different models are given in Figs. 2(a) and 2(b), it also shows that nine-component mixture model fits the frequency histogram of wind direction well than other models.

Histogram of wind directions for (a) k = 1, 2, …, 5 and (b) k = 6, 7, …, 10. The bin size of wind direction interval is 10°. A voM mixture model with nine-component distributions (b green bold dash line) fits the histogram of wind direction well in all candidate model with different components. Figure created using Matlab R2014a (https://www.mathworks.com).
In Table 4, from the estimated model parameters of nine-component mixture model of wind direction, we can see that the parameters of μ, which correspond to the nine main wind directions, are 0.0010, 0.5544, 1.3416, 1.5989, 2.1458, 2.2854, 3.0405, 4.3874 and 5.6471 rad (or 0.06°, 31.77°, 76.87°, 91.61°, 122.94°, 130.94°, 174.21°, 251.38° and 323.55°), respectively. As shown in Fig. 2(b), the prevailing wind directions covering from 0° to 180°.
This result is also confirmed by the wind rose diagram shown in Fig. 3. According to the frequency of occurrence for wind direction, the nine main wind directions are classified into three kinds in descending order in this study: the first four, the middle three and the last two main wind directions. We can see that the first four prevailing wind directions are the ESE, ENE, E and NNE directions with 9.39%, 8.92%, 8.72% and 7.95% of frequency of occurrence, respectively. In Table 4, the four estimated parameters μ of nine-component mixture model are 2.1458, 1.3416, 1.5989 and 0.5544 rad, which correspond to the wind directions are 122.94°, 76.87°, 91.61° and 31.77°, respectively. This result is close to the result given by Fig. 2(b) with the ESE, ENE, E and NNE directions (112.5°, 67.5°, 90° and 22.5°). The middle three predominant directions are the SE, SSE and N directions (135°, 157.5° and 0°) with 7.74%, 7.42% and 7.40% of occurrence. This result also agrees well with the result given by the estimated parameters μ = 2.2854, 3.0405 and 0.0010 rad (130.94°, 174.21° and 0.06°) in nine-component mixture model of wind direction. The last two main wind directions are the WSW and NW directions (247.5° and 315°) with 5.11% and 4.20% frequency. Therefore, the yaw system of a wind turbine can be arranged to the ESE direction, since most of the wind blows from this direction, which will enable the wind turbine to be positioned in such a way as to maximize the captured energy.

Wind rose diagram of wind direction. The wind direction is divided into 16 different sections. In the range from the direction N clockwise to S, three are seven main wind directions with 57.54% frequency totally. The other directions show an approximately uniform dispersion.
Using Eqs. (17) and (18), the estimated mean and variance of wind direction can be given as follows: b1 = 2.8051 rad (160.72°) and b2 = 0.1052, respectively. The relative error of b1 is very small, it is only 2.99%.
The statistical association between the wind speed and wind direction is measured by the linear–circular correlation coefficient, r2, given by33,37,40
where rvc = corr(v, cosθ), rvs = corr(v, sinθ) and rcs = corr(cosθ, sinθ). The correlation coefficient between wind speed and direction should satisfy the requirement of ׀r׀ < 1/3. In this study, the value of r is small and equals to 0.1101, therefore, it can be seen that there exists a weak correlation between wind speed and direction. The absolute value of correlation coefficient is within 1/3 satisfying the condition of use for voM wind direction model. At last, the parameter estimation results for the pdf g(ξ) of circular variable ζ between the wind speed and direction using a voM mixture distribution with the different components are given in Table 6.
Table 7 is a comparison results with different components for circular variable.
From Table 7, it can be found that increasing the number of voM components from one to six in the mixture distributions will increase the value of the R2 coefficient. However, when the number of voM components increase to seven, the value of the R2 coefficient does not increase, it is the same as the six-component mixture model has. At the same time, a seven-component mixture model has the same value of RMSE as a six-component mixture model. It is also noticed that six-component mixture model has a lower value of AIC and BIC, so based on the comprehensive criteria of model selection, the most suitable model for the wind direction at this station is six-component voM mixture model.
When considering the correlation between wind speed and direction, the number of parameters of μ, which corresponds to the main wind directions, is decreased from 9 to 6. They are 0.4968, 0.9895, 1.4361, 2.1411, 4.6757 and 5.9236 rad (28.46°, 56.69°, 82.28°, 122.68°, 267.90° and 339.40°), respectively. Compared with the nine main wind directions (0.06°, 31.77°, 76.87°, 91.61°, 122.94°, 130.94°, 174.21°, 251.38° and 323.55°) without considering the correlation, we find an interesting phenomenon: the deleted three main wind directions (0.06°, 130.94° and 174.21°) are happened to be the middle three main wind directions analyzed in Table 4. A possible explanation is that the N and S directions, which correspond 0.06° and 174.21°, fall in the edge of the section of main wind directions ranging from the N direction clockwise to S direction, so the wind energy potential of these two directions is not significant than other parts of the section. On the other hand, 130.94° is approximately close to 122.94°, therefore, it is also deleted. At last, only six directions (31.77°, 76.87°, 91.61°, 122.94°, 251.38° and 323.55°) are left, and they are close to these six directions: 28.46°, 56.69°, 82.28°, 122.68°, 267.90° and 339.40°, as shown in Fig. 4. The maximum error does not exceed the value of one Sect. (22.5°).

Histogram of circular variable ξ. A voM mixture model with six-component distributions fits the histogram of circular variable well in all candidate model with different components. Figure created using Matlab R2014a (https://www.mathworks.com).
Therefore, based on Eqs. (23) and (33), the joint pdf of wind speed and direction and wind power probability density can be given in Figs. 5 and 6.

Joint probability density of wind speed and direction. Figure created using Matlab R2014a (https://www.mathworks.com).

Wind power probability density. Figure created using Matlab R2014a (https://www.mathworks.com).
The scatter plot of wind power output versus wind speed for 1.8 MW wind turbine is shown in Fig. 7, after pre-processing with a data-cleaning method, some abnormal and unreasonable data are discarded. The number and value of model parameters of power curve affect the fitting accuracy for wind power to speed data; more parameters can imply better performance, but can also mean time-consuming. Therefore, 4-parameter and 5-parameter logistic functions were compared to find the best performance49. In our study, we use a polynomial regression model to fit wind power curve because of its convenient calculating with Matlab and a high coefficient of determination 0.9932. Using a polynomial regression method to fit the data of wind power, a mathematical expression of wind power output with speed can be obtained.

Scatter plot of wind power. There are a large number of outlier data points located far from the normal power bands. These abnormal and unreasonable data include the missing data by sensor fault, measurement error data and low temporal resolution data. Figure created using Matlab R2014a (https://www.mathworks.com).
The different fitting results are shown in Table 8, based on the correlation coefficient R2, we select the eight-degree polynomial as the best model for wind power output.
The power curve of the studied wind turbine as shown in Fig. 8. The expression of wind power in W with wind speed in m/s is given as follows:

Wind power curve. The simplest data cleaning method is to delete the wind power data that lies outside the boundary. Blue zone line is wind power curve after pre-processing of raw wind power data, while red line is the fitting line for wind power data. Figure created using Matlab R2014a (https://www.mathworks.com).
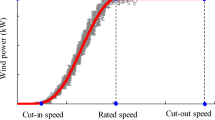
In this study, the cut-out wind speed (maximum allowable speed) and rated output power are known, they are 18.99 m/s and 1800 kW, respectively. The rated wind speed can be found by examining the power curve, i.e., the lowest wind speed, where the wind turbine first reaches its rated power, is the rated wind speed. Therefore, set Eq. (37) equals to 1.8 × 106 and 0, we can get the rated output speed, vr = 9.74 m/s, and the cut-in speed, vin = 2 m/s, respectively, as shown in Fig. 8.
To estimate the wind power output of a wind turbine, it is necessary to know wind speed and the number of hours of the year, in which the wind blows at velocity v. The period t of one year, i.e., approximates 8760 h and the air density of studied area is 1.216 kg/m3 are used. Subsequently, the estimated values of wind power density at this wind farm were calculated using Eq. (33) is 93.27 W/m2. This value is close to the reference value of wind power density of 88.14 W/m2 which is obtained using Eq. (31). It indicates that the region under study stands in class 110, which belongs to the low-wind speed wind power development area, and is generally not suitable for wide wind turbine establishment and wind farm investment. However, it would be possible to exploit the wind power applications for small scale wind turbines at this area. Based on Eq. (32), a comparison result without taking into account of wind direction is 125.78 W/m2, is also presented. It is clearly shown that the wind energy potential is overestimated without considering the effect of wind direction. Using Eq. (35), the annual energy output can also be obtained, it is 2.21 GWh.
Conclusions
In this paper, the wind energy potential of the Maling Mountain in China is studied by using the measured wind data for a period of one year at a height of 30 m. Based on EM algorithm, an assessment method of wind energy potential using finite mixture statistical distribution model is proposed, the probability density function of wind power density and the annual energy output are given for use in wind energy analyses. The suitability of the model is judged using a comprehensive technique of model selection including AIC, BIC information criteria, coefficient of determination R2 and RMSE. Field monitoring wind data are used to verify the effectiveness and validity of the proposed method by comparing it with other estimation methods in accordance with the value of R2 and RMSE, the histogram plot and wind rose diagram. Wind direction is also important for a given wind farm when the orography and wake effects are going to be studied, so the orography and wake effects will be carried on in our future research, in addition we will also use Kato Jones distribution as candidate wind direction model and compare it with von Mises distribution. The further study to extend the modelling of direction-dependent power curve for wind turbine is also needed. The main conclusions are drawn from the study as follows:
-
1.
The proposed method takes into account the effect of wind speed and direction simultaneously, the correlation existing between both variables, as well as the bimodal or multimodal distributions of them. The mixture distribution model provides a better fitting result for wind data than single distribution model, and it can therefore be used in the assessment of wind energy at a potential site and assessment result is more accuracy and close to the reality. On the other hand, three-parameter Weibull distribution considers the frequency of calm winds, it shows a good fit to wind speed data with a significant null wind speed or high percentage of low wind speed and is particularly suitable for a skewed data with a long tail in histogram plot.
-
2.
The best mixture model with the lowest AIC and BIC values is selected as the optimal model from all candidate models with a finite component number, therefore it is not necessary to know the number of components in mixture model in advance. Increasing the number of components of the mixture distributions, the variations in value of R2 are not significant. On the contrary, it might yield complex. Therefore, combining with the comprehensive technique of model selection, an appropriate number of mixture distributions can be selected, which not only reduces the computational burden but also improves the model accuracy, and the model has a higher predictive ability.
-
3.
Compared with the real wind power density of time series wind speed data, it also shown that when there exists a correlation between wind speed and its direction, the estimated results of wind energy potential is more close to the real situation when considering the influence of wind direction.
References
Ogulata, R. T. Energy sector and wind energy potential in Turkey. Renew. Sustain. Energy Rev. 7, 469–484 (2003).
Eskin, N., Artar, H. & Tolun, S. Wind energy potential of Gokceada Island in Turkey. Renew. Sustain. Energy Rev. 12, 839–851 (2008).
Philippopoulos, K., Deligiorgi, D. & Karvounis, G. Wind speed distribution modeling in the greater area of Chania Greece. Int. J. Green Energy 9, 174–193 (2012).
Wais, P. A review of Weibull functions in wind sector. Renew. Sustain. Energy Rev. 70, 1099–1107 (2017).
Kiss, P. & Janosi, I. M. Comprehensive empirical analysis of ERA-40 surface wind speed distribution over Europe. Energy Convers. Manag. 49, 2142–2151 (2008).
Aslam, M. Testing average wind speed using sampling plan for Weibull distribution under indeterminacy. Sci. Rep. 11, 7532 (2021).
Chen, H., Birkelund, Y., Anfinsen, S. N., Staupe-Delgado, R. & Yuan, F. Assessing probabilistic modelling for wind speed from numerical weather prediction model and observation in the Arctic. Sci. Rep. 11, 7613 (2021).
Hu, Q., Wang, Y., Xie, Z., Zhu, P. & Yu, D. On estimating uncertainty of wind energy with mixture of distributions. Energy 112, 935–962 (2016).
Aries, N., Boudia, S. M. & Ounis, H. Deep assessment of wind speed distribution models: A case study of four sites in Algeria. Energy Convers. Manag. 155, 78–90 (2018).
Pishgar-Komleh, S. H., Keyhani, A. & Sefeedpari, P. Wind speed and power density analysis based on Weibull and Rayleigh distributions (a case study: Firouzkooh county of Iran). Renew. Sustain. Energy Rev. 42, 313–322 (2015).
Akdag, S. A. & Dinler, A. A new method to estimate Weibull parameters for wind energy applications. Energy Convers. Manag. 50, 1761–1766 (2009).
Kantar, Y. M. & Usta, I. Analysis of the upper-truncated Weibull distribution for wind speed. Energy Convers. Manag. 96, 81–88 (2015).
Wais, P. Two and three-parameter Weibull distribution in available wind power analysis. Renew. Energy 103, 15–29 (2017).
Deep, S., Sarkar, A., Ghawat, M. & Rajak, M. K. Estimation of the wind energy potential for coastal locations in India using the Weibull model. Renew. Energy 161, 319–339 (2020).
Carta, J. A. & Mentado, D. A continuous bivariate model for wind power density and wind turbine energy output estimations. Energy Convers. Manag. 48, 420–432 (2007).
Carta, J. A. & Ramirez, P. Use of finite mixture distribution models in the analysis of wind energy in the Canarian Archipelago. Energy Convers. Manag. 48, 281–291 (2007).
Carta, J. A. & Ramirez, P. Analysis of two-component mixture Weibull statistics for estimation of wind speed distributions. Renew. Energy 32, 518–531 (2007).
Akpinar, S. & Akpinar, E. K. Estimation of wind energy potential using finite mixture distribution models. Energy Convers. Manag. 50, 877–884 (2009).
Akdag, S. A., Bagiorgas, H. S. & Mihalakakou, G. Use of two-component Weibull mixtures in the analysis of wind speed in the Eastern Mediterranean. Appl. Energy 87, 2566–2573 (2010).
Zhang, J., Chowdhury, S., Messac, A. & Castillo, L. A multivariate and multimodal wind distribution model. Renew. Energy 51, 436–447 (2013).
Ouarda, T. B. M. J. et al. Probability distributions of wind speed in the UAE. Energy Convers. Manag. 93, 414–434 (2015).
Mahbudi, S., Jamalizadeh, A. & Farnoosh, R. Use of finite mixture models with skew-t-normal Birnbaum-Saunders components in the analysis of wind speed: Case studies in Ontario Canada. Renew. Energy 162, 196–211 (2020).
Mazzeo, D., Oliveti, G. & Labonia, E. Estimation of wind speed probability density function using a mixture of two truncated normal distributions. Renew. Energy 115, 1260–1280 (2018).
Ouarda, T. B. M. J. & Charron, C. On the mixture of wind speed distribution in a Nordic region. Energy Convers. Manag. 174, 33–44 (2018).
Gugliani, G. K., Sarkar, A., Ley, C. & Mandal, S. New methods to assess wind resources in terms of wind speed, load, power and direction. Renew. Energy 129, 168–182 (2018).
Han, Q. & Chu, F. Directional wind energy assessment of China based on nonparametric copula models. Renew. Energy 164, 1334–1349 (2021).
Carta, J. A., Bueno, C. & Ramirez, P. Statistical modelling of directional wind speeds using mixtures of von Mises distributions: Case study. Energy Convers. Manag. 49, 897–907 (2008).
Masseran, N., Razali, A. M., Ibrahim, K. & Latif, M. T. Fitting a mixture of von Mises distributions in order to model data on wind direction in Peninsular Malaysia. Energy Convers. Manag. 72, 94–102 (2013).
Zou, M. et al. Evaluation of wind turbine power outputs with and without uncertainties in input wind speed and wind direction data. IET Renew. Power Gener. 14, 2801–2809 (2020).
Soukissian, T. H. Probabilistic modeling of directional and linear characteristics of wind and sea states. Ocean Eng. 91, 91–110 (2014).
Horn, J., Gregersen, E. B., Krokstad, J. R., Leira, B. J. & Amdahl, J. A new combination of conditional environmental distributions. Appl. Ocean Res. 73, 17–26 (2018).
Vanem, E., Hafver, A. & Nalvarte, G. Environmental contours for circular-linear variables based on the direct sampling method. Wind Energy 23, 563–574 (2020).
Carta, J. A., Ramirez, P. & Bueno, C. A joint probability density function of wind speed and direction for wind energy analysis. Energy Convers. Manag. 49, 1309–1320 (2008).
Carta, J. A., Ramirez, P. & Velazquez, S. A review of wind speed probability distributions used in wind energy analysis Case studies in the Canary Islands. Renew. Sustain. Energy Rev. 13, 933–955 (2009).
Erdem, E. & Shi, J. Comparison of bivariate distribution construction approaches for nalyzing wind speed and direction data. Wind Energy 14, 27–41 (2011).
Ovgor, B., Lee, S. K. & Lee, S. A method of micrositing of wind turbine on building roof-top by using joint distribution of wind speed and direction, and computational fluid dynamics. J. Mech. Sci. Technol. 26, 3981–3988 (2012).
Soukissian, T. H. & Karathanasi, F. E. On the selection of bivariate parametric models for wind data. Appl. Energy 188, 280–304 (2017).
Han, Q., Hao, Z., Hu, T. & Chu, F. Non-parametric models for joint probabilistic distributions of wind speed and direction data. Renew. Energy 126, 1032–1042 (2018).
Ye, X. W., Xi, P. S. & Nagode, M. Extension of REBMIX algorithm to von Mises parametric family for modeling joint distribution of wind speed and direction. Eng. Struct. 183, 1134–1145 (2019).
Li, H. N., Zheng, X. W. & Li, C. Copula-based joint distribution analysis of wind speed and direction. J. Eng. Mech. 145, 04019024 (2019).
Kantar, Y. M. & Usta, I. Analysis of wind speed distributions: Wind distribution function derived from minimum cross entropy principles as better alternative to Weibull function. Energy Convers. Manag. 49, 962–973 (2008).
Zhang, H., Yu, Y. J. & Liu, Z. Y. Study on the Maximum Entropy Principle applied to the annual wind speed probability distribution: A case study for observations of intertidal zone anemometer towers of Rudong in East China Sea. Appl. Energy 114, 931–938 (2014).
Miao, S. et al. A mixture kernel density model for wind speed probability distribution estimation. Energy Convers. Manag. 126, 1066–1083 (2016).
Han, Q., Ma, S., Wang, T. & Chu, F. Kernel density estimation model for wind speed probability distribution with applicability to wind energy assessment in China. Renew. Sustain. Energy Rev. 115, 109387 (2019).
Guan, J. S., Lin, J., Guan, J. J. & Mokaramian, E. A novel probabilistic short-term wind energy forecasting model based on an improved kernel density estimation. Int. J. Hydrog. Energy 45, 23791–23808 (2020).
Wahbah, M., Feng, S. F., EL-Fouly, T. H. M. & Zahawi, B. Wind speed probability density estimation using root-transformed local linear regression. Energy Convers. Manag. 199, 111889 (2019).
Ye, X. W., Ding, Y. & Wan, H. P. Statistical evaluation of wind properties based on long-term monitoring data. J. Civ. Struct. Health 10, 987–1000 (2020).
Gungor, A., Gokcek, M., Ucar, H., Arabaci, E. & Akyüz, A. Analysis of wind energy potential and Weibull parameter estimation methods: a case study from turkey. Int. J. Environ. Sci. Te. 17, 1011–1020 (2020).
Yan, J., Zhang, H., Liu, Y., Han, S. & Li, L. Uncertainty estimation for wind energy conversion by probabilistic wind turbine power curve modelling. Appl. Energy 239, 1356–1370 (2019).
Wang, L., Liu, J. & Qian, F. Wind speed frequency distribution modeling and wind energy resource assessment based on polynomial regression model. Int. J. Electr. Power Energy Syst. 130, 106964 (2021).
Acknowledgements
We would like to thank the anonymous reviewers and the editor for their valuable comments and suggestions, which have greatly enhanced the clarity of the paper. The authors also wish to acknowledge the staff of the Gansu Province Special Equipment Inspection and Testing Institute for providing wind data used in this study.
Author information
Authors and Affiliations
Contributions
W.Z. is responsible for developing methods, drawing charts, analyzing results, and writing the original draft. L.W. is responsible for data curation and methodology improvements.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Z., Liu, W. Wind energy potential assessment based on wind speed, its direction and power data. Sci Rep 11, 16879 (2021). https://doi.org/10.1038/s41598-021-96376-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-96376-7
This article is cited by
-
Multivariate Analysis of Wind Characteristics for Optimal Irrigation Planning in Miandoab Plain, Urmia Lake
Iranian Journal of Science and Technology, Transactions of Civil Engineering (2024)
-
The power of progressive active learning in floorplan images for energy assessment
Scientific Reports (2023)
-
Focus on using nanopore technology for societal health, environmental, and energy challenges
Nano Research (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
