
Abstract
Prediabetes and diabetes mellitus (preDM/DM) have become alarmingly prevalent among youth in recent years. However, simple questionnaire-based screening tools to reliably assess diabetes risk are only available for adults, not youth. As a first step in developing such a tool, we used a large-scale dataset from the National Health and Nutritional Examination Survey (NHANES) to examine the performance of a published pediatric clinical screening guideline in identifying youth with preDM/DM based on American Diabetes Association diagnostic biomarkers. We assessed the agreement between the clinical guideline and biomarker criteria using established evaluation measures (sensitivity, specificity, positive/negative predictive value, F-measure for the positive/negative preDM/DM classes, and Kappa). We also compared the performance of the guideline to those of machine learning (ML) based preDM/DM classifiers derived from the NHANES dataset. Approximately 29% of the 2858 youth in our study population had preDM/DM based on biomarker criteria. The clinical guideline had a sensitivity of 43.1% and specificity of 67.6%, positive/negative predictive values of 35.2%/74.5%, positive/negative F-measures of 38.8%/70.9%, and Kappa of 0.1 (95%CI: 0.06–0.14). The performance of the guideline varied across demographic subgroups. Some ML-based classifiers performed comparably to or better than the screening guideline, especially in identifying preDM/DM youth (p = 5.23 × 10−5).We demonstrated that a recommended pediatric clinical screening guideline did not perform well in identifying preDM/DM status among youth. Additional work is needed to develop a simple yet accurate screener for youth diabetes risk, potentially by using advanced ML methods and a wider range of clinical and behavioral health data.
Similar content being viewed by others

Introduction
Diabetes mellitus (DM) is a serious chronic condition associated with numerous long-term complications1. Prediabetes (preDM) is a precursor condition in which glucose levels are high, but not yet high enough to diagnose diabetes2. PreDM is reversible with lifestyle modification and weight loss, offering an avenue to avoid the adverse effects of diabetes2,3. Both these conditions have become alarmingly prevalent among youth4,5. According to a large prospective cohort study, an estimated 5,300 youth are diagnosed with type 2 DM annually in the US4, with a higher prevalence among older teens5. The overall prevalence of preDM among US adolescents based on nationally representative data was 17.7%, with higher rates in males (22.0%) than in females (13.2%), in non-Hispanic Blacks (21.0%) and Hispanics (22.9%) than in non-Hispanic Whites (15.1%)6, and in obese youth (25.7%) than in normal weight youth (16.4%)7. Compared to adults, DM in youth is more difficult to treat8 due to a more rapid decline in beta cell function, and an earlier onset of complications9,10. The potential health and economic impact of DM is therefore even greater for youth than adults, given the greater number of years living with the disease and time to develop long-term complications.
The American Diabetes Association (ADA) has published a guideline for identifying preDM and DM among youth based on measurement of biomarkers [plasma glucose level after an overnight fast (FPG), plasma glucose level two hours after an oral glucose load (2hrPG), or hemoglobin A1c (HbA1c)]11. In spite of this guideline, preDM is often underdiagnosed among youth12,13. For example, one study found that only 1% of adolescents with prediabetes reported having been told by a physician that they had the condition13. In addition, despite professional consensus, many youth do not receive recommended annual checkups and preventive services14. Even for those in care, oral glucose tolerance testing is generally not conducted, as it requires fasting and testing over 2–3 h, which is often challenging15,16,17. Thus, many youth with preDM/DM may be unaware of their condition, making it difficult to target the highest risk youth for prevention. A simple non-invasive, questionnaire-based screening tool is, therefore, a likely impactful first-line strategy to identify at-risk individuals before subjecting them to definitive testing and resource-intense prevention programs18,19,20.
Several such risk tools have been developed to detect the risk of prevalent (undiagnosed) and incident preDM and DM in adults21,22,23,24. For example, the ADA and the Centers for Disease Control and Prevention (CDC) have developed an easy-to-use patient self-assessment screener based on 7 questions to identify adults at risk for preDM and DM25,26. Surprisingly, there exists no similar tool for accurately screening for preDM/DM risk among youth, despite the clinical and public health importance of these conditions. ADA published and the American Academy of Pediatrics (AAP) endorsed the only widely used clinical screening guideline for health care providers to test asymptomatic children and adolescents11. However, this clinical guideline has not been validated using large youth health data sets and ADA diagnostic guidelines11. Furthermore, such guidelines may not perform equally in different age, sex and race/ethnicity subgroups27.
To address these critical knowledge gaps, and as a first step in the development of a youth diabetes risk screening tool, our objective was to examine the performance of the AAP/ADA screening guideline in identifying youth with preDM/DM. Disease determination in our study was based on biomarker (FPG, 2hrPG, and HbA1c) measurements in a large-scale dataset from the National Health and Nutrition Examination Survey (NHANES)28. We also examined how this screening guideline performed in age, sex, and racial/ethnic subgroups. Furthermore, hypothesis-free data-driven machine learning (ML) methods29 have recently helped improve disease diagnosis, prognosis, and treatment efficacy30,31,32. Inspired by these advances, we also investigated if ML methods applied to NHANES data can help improve preDM/DM screening performance33.
Methods
Study population
We utilized publicly available data from NHANES, a large ongoing cross-sectional survey that systematically gathers data from interviews, medical examinations, and laboratory testing for studying a range of health topics28. NHANES oversamples certain subgroups, such as African–Americans, Hispanics, Asians, older adults, and low income populations, to obtain reliable estimates of health status indicators for these groups.
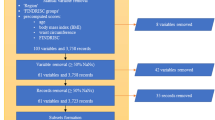
We selected 2970 youth aged 12–19 years from 2005 to 2016 NHANES data for which preDM/DM diagnostic biomarkers were available34. We excluded 112 participants that lacked information on BMI percentile, family history of diabetes, blood pressure measures or total cholesterol, making it impossible to apply the AAP/ADA screening guideline.
PreDM/DM status
PreDM/DM status was based on current ADA biomarker criteria (elevated levels of any of the three biomarkers: FPG ≥ 100 mg/dL, 2hrPG ≥ 140 mg/dL, or HbA1C ≥ 5.7%)11. Since few youth had DM based on biomarker diagnostic criteria (n = 13), we combined youth with preDM and DM into one category. We applied the AAP/ADA screening guideline using operationally defined equivalent variables available in NHANES (Table 1) on both the unweighted and weighted versions of the data. The results shown are on the unweighted data, unless otherwise specified.
As a sensitivity analysis, we also used a higher threshold level in FPG and HbA1C to define preDM/DM status: FPG > 110 mg/dL, 2hrPG ≥ 140 mg/dL, or HbA1C > 6.0%), as has been suggested by some organizations35.
Machine learning
As alternatives to expert-defined screeners, we explored automated ML methods29 for developing preDM/DM status (yes or no) classifiers directly from the youth NHANES data. We used the same five variables used in the AAP/ADA screening guideline, namely continuous BMI percentiles, family history of diabetes (yes/no), race ethnicity (non-Hispanic White vs. otherwise), hypertension (yes/no), and continuous total cholesterol levels, as features. Ten established algorithms and a five-fold cross-validation setup were used to generate and evaluate preDM/DM classifiers from the values of these features for the youth in our dataset. Details of this classifier generation and evaluation process are provided in Supplemental Information.
Evaluation of screeners
Both the AAP/ADA screening guideline, as well as the ML-based classifiers described above, produce binary classifications, specifically positive ( +) and negative ( −) preDM/DM determinations. Due to the inherent imbalance between these classes (Table 3), we used six appropriate measures36 to evaluate these classifications: sensitivity (recall +), specificity (recall–), positive predictive value (PPV, precision +), negative predictive value (NPV, precision −), and F-measures for the two classes. Table 3 and Supplemental Information provide definitions of these measures, and our detailed reasoning for focusing on them. We used the recommended Friedman and Nemenyi tests37 to assess the statistical significance of the comparisons of the predictive performances of all the ML methods tested, as well as the screening guideline.
We also assessed the six performance measures for the overall data and for sub-datasets stratified by sex (male, female), race/ethnicity (non-Hispanic White, non-Hispanic Black, Hispanic, other), and age groups (12–14 years, 15–17 years, and 18–19 years). We examined the agreement between the AAP/ADA screening guideline and biomarkers in defining preDM/DM using McNemar’s test and reported Kappa coefficient, which has a value ranging from 0 (no consistency) to 1 (complete consistency). We also tested equal Kappa coefficients across subgroups, and used the Breslow-Day test to examine the homogeneity of the odds ratios between preDM/DM status defined by the guideline and by biomarker measurements across subgroups. Analyses were conducted in SAS (v9.4).
Results
Performance of clinical preDM/DM screening guideline
Approximately 29% of the 2858 youth in our study population were classified as having preDM/DM based on ADA biomarker criteria (Table 2). The prevalence was about 35.5% according to the AAP/ADA screening guideline (Table 2). The weighted-NHANES preDM/DM prevalences were quite consistent, i.e., 27.6% and 36.3% according to the ADA biomarker criteria and AAP/ADA screening guideline respectively (Supplementary Table S1).
As shown in Table 3, the guideline correctly identified 43.1% of the youth with preDM/DM based on biomarkers (sensitivity), the PPV (precision +) was 35.2%, and the preDM/DM F-measure was 38.8%. We found poor agreement between preDM/DM determinations based on biomarkers and those based on the AAP/ADA screening guideline (Kappa coefficient 0.1 (95%CI: 0.06–0.14), p < 0.0001). The Kappa coefficients did not differ by sex, age, or race/ethnicity (p > 0.05), indicating that the guideline did not perform well in any of the subgroups. The agreement between preDM/DM determinations based on biomarkers and those based on the screening guideline differed between males and females (Breslow-Day test p = 0.02), and across the three age groups (p = 0.046). It did not differ across the four racial/ethnic groups (p = 0.42).
The predictive performance measures of the screening guideline also varied across the various subgroups (Fig. 1). The sensitivity (recall +) was higher among females than males (52.2% vs 38.2%), while the PPV (precision +) was lower among females (29.4% vs 41.1%). The guideline performed better for Hispanics and non-Hispanic Blacks than for non-Hispanic Whites and other racial/ethnic groups in terms of sensitivity (51.8% and 51.9% vs 23.4% and 32.5% respectively), while the PPV was similar (28.8%–37.6%) across the four racial/ethnic groups. Finally, the guideline performed the worst for those aged 12–14 years (sensitivity = 39.9%) and the best for those aged 18–19 years (sensitivity = 47.8%, PPV = 30.2%, and F-measure = 43.7%).

Variations in the performance of the American Diabetes Association pediatric screening guidelines in identifying youth with prediabetes/diabetes (preDM/DM) based on biomarker measurements across subgroups stratified by age group (12–14, 15–17, and 18–19), race/ethnicity (Hispanic, non-Hispanic Black, non-Hispanic White, other), and sex (female, male). Red lines denote the value of the corresponding evaluation measure obtained from the full study population (youth ages 12–19, National Health and Nutrition Examination Survey data, 2005–2016). preDM prediabetes; DM diabetes; F female; M male; Hisp Hispanic; NHB non-Hispanic Black; NHW non-Hispanic White; PPV positive predictive value; NPV negative predictive value. Results based on unweighted data.
Results from the sensitivity analysis using higher biomarker thresholds (FPG > 110 mg/dL, 2hrPG ≥ 140 mg/dL, or HbA1C > 6.0%) showed similar performance measures: sensitivity = 56.2%, specificity = 66.0%, PPV = 10.3%, NPV = 95.6%, F-measure = 17.3% and 78.1% for those with and without preDM/DM, respectively. Similar to results on unweighted NHANES data, we found that the AAP/ADA screening guideline performed unsatisfactorily in identifying youth with preDM/DM on weighted NHANES data as well (Supplementary Table S2): sensitivity = 36.34%, specificity = 74.05%, PPV = 34.79%, NPV = 75.33%, and F-measures = 35.55% and 74.68% for those with and without preDM/DM, respectively. Similar performance variations across sex, race/ethnicity and age subgroups were also found on the weighted NHANES data (Supplementary Figure S2).
Performance of ML-based preDM/DM classifiers
Figure 2 shows the five-fold cross-validation38-derived results of classifying preDM/DM status using ML methods, variables used in the screening guideline, and class labels (preDM/DM or not) defined using biomarker criteria. Across almost all the methods and evaluation measures, it was comparatively easier to produce more accurate predictions for the bigger non-preDM/DM class than the smaller preDM/DM one. Even so, the overall performance of the ML methods varied in a manner consistent with that of the screening guideline across the evaluation measures and classes. Furthermore, in each case, at least one ML method performed better than the screening guideline, especially for the harder to predict preDM/DM class. In particular, the naïve Bayes-based classifier performed equivalently or better than the guideline in terms of all the measures for this class (Friedman-Nemenyi test p = 9.216 × 10−5, 0.252 and 5.228 × 10−5 for PPV, sensitivity and F-measure respectively). This algorithm assumes conditional independence between the features, given the class labels. It then uses Bayes’ theorem to generate a simple classifier that calculates the posterior probability for a class label based on the values of the features for a given patient. The classifier based on this algorithm also performed better than or equivalently to the guideline for the non-preDM/DM class (p = 8.5 × 10−10, 0.225 and 0.005 for NPV, specificity and F-measure respectively). Several other methods, such as Logistic (Regression), LogitBoost, PART and J48 (decision tree), also performed statistically equivalently or better than the screening guideline. Overall, these results show that even with very few features (only five here), data-driven ML-based methods can help improve upon the performance of the AAP/ADA preDM/DM screening guideline.

Performance of machine learning algorithms in classifying individuals into prediabetes/diabetes (preDM/DM) and non-preDM/DM classes, evaluated in terms of predictive value, sensitivity/specificity and F-measures for both classes. The variables used in this classification were the same as those used in the American Diabetes Association pediatric screening guidelines, whose performance in terms of each measure is shown by a horizontal red line in the corresponding subplot. preDM prediabetes; DM diabetes; PPV positive predictive value; NPV negative predictive value.
Discussion
The recently increasing prevalence of preDM/DM among youth, even among those with normal weight7, and the underdiagnosis of these conditions despite serious long-term sequelae, point to a pressing need for the development of simple accurate screening tools for identifying at-risk youth. Towards that end, we conducted the first evaluation of a current pediatric clinical screening guideline recommended by the AAP and ADA on NHANES data, using preDM/DM status determined based on biomarker criteria (elevated FPG/2hrPG/HbA1C) for comparison. Despite the fact that the pediatric clinical screening guideline is meant for health care providers to identify youth at risk for diabetes, the sensitivity of the guideline in identifying NHANES youth with preDM/DM based on biomarkers was below 50%. The agreement between risk based on the clinical screening guideline and presence of preDM/DM based on biomarker criteria was similarly poor across demographic subgroups based on age, sex and race/ethnicity. On the other hand, we found that the prevalence of preDM/DM varied across these subgroups, and the association between preDM/DM status defined by the guideline and based on biomarkers differed between males and females, and potentially by age groups. Another study also reported variations in the performance of diabetes risk scores by sex and race/ethnicity among adult populations in NHANES27. Taken together, these results suggest the need for a better screener than the current one, and a screener that can perform well for subgroup populations.
Data-driven ML-based methods29 yielded improvements over the screening guideline in identifying youth with preDM/DM, despite using only the five variables (BMI, family history of diabetes, race/ethnicity, hypertension, and cholesterol levels) the guideline is based on. Combining many more relevant features from NHANES or other large data sets with rich clinical and behavioral health data, as well as powerful ML approaches like feature selection39 and deep learning40, is likely to substantially enhance our ability to develop a data-driven, relatively simple, and accurate screener for youth at risk for preDM/DM.
Of note, about half of the youth with preDM/DM in this study were of normal weight. Indeed, a recent study, also based on an examination of NHANES data, found that 16.4% of normal weight youth had preDM7. Another study found a relative annual increase in the incidence of type 2 diabetes, despite the fact that there was no significant increase in the prevalence of obesity among US youth in the same time period41. Factors other than weight status are known to increase risk of diabetes, including minority race/ethnicity and family history of diabetes7,41,42,43. Indeed, due to their relevance, these factors are included in the pediatric screening guideline that we evaluated in our study. There are likely other factors that impact diabetes risk that are yet to be discovered. Thus, although all normal weight youth may not be at risk of developing DM, there is still value in identifying all youth with preDM, even those that aren’t obese, because they have been shown to have increased cardiovascular risk44. This is exactly the perspective we adopted in our study.
Despite its promising findings, our study has some limitations. PreDM/DM status was determined based on one-time measurements of biomarkers due to the data availability in NHANES, whereas the ADA recommends repeated measurements11. Specifically, preDM diagnosis based on a single assessment may not capture youth truly at risk for progression to DM, because preDM in adolescence is sometimes transient and related to physiologic pubertal insulin resistance10,11. Furthermore, NHANES data, and thus, our evaluation, did not differentiate type 1 from type 2 diabetes. We do not expect this to substantially affect our results, since the prevalence of type 1 diabetes among youth is relatively low as compared to the combined prevalence of preDM and type 2 DM5,6. Another limitation is that we were not able to exactly apply the AAP/ADA pediatric clinical screening guideline because of missing information (history of maternal gestational diabetes during the child’s gestation, presence of acanthosis nigricans, diagnosis of polycystic ovary syndrome, and history of small-for-gestational-age birthweight), or information available in a different format (family history of diabetes). Finally, we only evaluated the ML-based methods on unweighted NHANES data, since there aren’t straightforward ways to apply and evaluate these methods on weighted data.
Despite these limitations, our study also has several strengths. To our knowledge, this is the first examination of the performance of a recommended pediatric clinical screening guideline for identifying preDM/DM status, determined using biomarker criteria, among youth. Our demonstration that the guideline did not perform well for this task points to the need for additional work to develop a simple yet accurate screener for youth diabetes risk. Studies focused on assessing youth preDM/DM risk to date have relied on relatively small sample sizes from localized clinical settings, and have sometimes included invasive blood tests that may not be the best initial strategy to assess risk45,46. In contrast, NHANES includes a large sample of individuals from across the United States, including well-represented age, sex, and racial/ethnic subgroups, as well as detailed biomarker, clinical, and behavioral health data. While NHANES data have been used to develop diabetes risk screeners for adults25,47,48, and to examine prevalence of preDM/DM among youth6,49, no studies before ours have used these data to develop and evaluate youth diabetes risk screeners. In particular, our investigation of machine learning methods applied to these data demonstrates the promise of automated data-driven methods for developing such screeners. Future work includes the use of more advanced ML methods applied to a wider range of clinical and behavioral health data available in NHANES to build better predictive tools for assessing preDM/DM risk. Such tools can be used by youth or their caretakers, as well as in clinical and community settings, to identify at-risk youth who can benefit from more intensive diabetes prevention programs.
References
Lotfy, M., Adeghate, J., Kalasz, H., Singh, J. & Adeghate, E. Chronic Complications of diabetes mellitus: A mini review. Curr. Diabetes Rev. 13(1), 3–10 (2017).
Perreault, L. & Faerch, K. Approaching pre-diabetes. J. Diabetes Complicat. 28(2), 226–233 (2014).
Love-Osborne, K. A., Sheeder, J. L., Nadeau, K. J. & Zeitler, P. Longitudinal follow up of dysglycemia in overweight and obese pediatric patients. Pediatr. Diabetes 19(2), 199–204 (2018).
Mayer-Davis, E. J. et al. Incidence trends of type 1 and type 2 diabetes among youths, 2002–2012. N. Engl. J. Med. 376(15), 1419–1429 (2017).
Dabelea, D. et al. Prevalence of type 1 and type 2 diabetes among children and adolescents from 2001 to 2009. JAMA 311(17), 1778–1786 (2014).
Menke, A., Casagrande, S. & Cowie, C. C. Prevalence of diabetes in adolescents aged 12 to 19 years in the United States, 2005–2014. JAMA 316(3), 344–345 (2016).
Andes LJ, Cheng YJ, Rolka DB, Gregg EW, Imperatore G. Prevalence of prediabetes among adolescents and young adults in the United States, 2005–2016. JAMA Pediatr. 2019:e194498.
Group TS et al. A clinical trial to maintain glycemic control in youth with type 2 diabetes. N. Engl. J. Med. 366(24), 2247–2256 (2012).
Dart, A. B. et al. Earlier onset of complications in youth with type 2 diabetes. Diabetes Care 37(2), 436–443 (2014).
Nadeau, K. J. et al. Youth-onset type 2 diabetes consensus report: Current status, challenges, and priorities. Diabetes Care 39(9), 1635–1642 (2016).
Arslanian, S. et al. Evaluation and management of youth-onset type 2 diabetes: A position statement by the American Diabetes Association. Diabetes Care 41(12), 2648–2668 (2018).
Bloomgarden, Z. T. Type 2 diabetes in the young: the evolving epidemic. Diabetes Care 27(4), 998–1010 (2004).
Lee, A. M., Fermin, C. R., Filipp, S. L., Gurka, M. J. & DeBoer, M. D. Examining trends in prediabetes and its relationship with the metabolic syndrome in US adolescents, 1999–2014. Acta Diabetol. 54(4), 373–381 (2017).
Black, L. I., Nugent, C. N. & Vahratian, A. Access and utilization of selected preventive health services among adolescents aged 10–17. NCHS Data Brief 246, 1–8 (2016).
Rhodes, E. T. et al. Screening for type 2 diabetes mellitus in children and adolescents: attitudes, barriers, and practices among pediatric clinicians. Ambul. Pediatr. 6(2), 110–114 (2006).
Anand, S. G., Mehta, S. D. & Adams, W. G. Diabetes mellitus screening in pediatric primary care. Pediatrics 118(5), 1888–1895 (2006).
Lee, J. M. et al. Screening practices for identifying type 2 diabetes in adolescents. J. Adolesc. Health 54(2), 139–143 (2014).
Brackney, D. E. & Cutshall, M. Prevention of type 2 diabetes among youth: a systematic review, implications for the school nurse. J. Sch. Nurs. 31(1), 6–21 (2015).
McCurley, J. L., Crawford, M. A. & Gallo, L. C. Prevention of type 2 diabetes in US hispanic youth: A systematic review of lifestyle interventions. Am. J. Prev. Med. 53(4), 519–532 (2017).
Knowler, W. C. et al. 10-year follow-up of diabetes incidence and weight loss in the Diabetes Prevention Program Outcomes Study. Lancet 374(9702), 1677–1686 (2009).
Brown, N., Critchley, J., Bogowicz, P., Mayige, M. & Unwin, N. Risk scores based on self-reported or available clinical data to detect undiagnosed type 2 diabetes: A systematic review. Diabetes Res. Clin. Pract. 98(3), 369–385 (2012).
Noble, D., Mathur, R., Dent, T., Meads, C. & Greenhalgh, T. Risk models and scores for type 2 diabetes: Systematic review. BMJ 343, d7163 (2011).
Barber, S. R., Davies, M. J., Khunti, K. & Gray, L. J. Risk assessment tools for detecting those with pre-diabetes: A systematic review. Diabetes Res. Clin. Pract. 105(1), 1–13 (2014).
Thoopputra, T., Newby, D., Schneider, J. & Li, S. C. Survey of diabetes risk assessment tools: concepts, structure and performance. Diabetes Metab. Res. Rev. 28(6), 485–498 (2012).
Bang, H. et al. Development and validation of a patient self-assessment score for diabetes risk. Ann. Intern. Med. 151(11), 775–783 (2009).
Prediabetes Risk Test: American Diabetes Association and Centers for Disease Control and Prevention; [Available from: https://www.cdc.gov/diabetes/prevention/pdf/Prediabetes-Risk-Test-Final.pdf.
Zhang, L., Zhang, Z., Zhang, Y., Hu, G. & Chen, L. Evaluation of Finnish Diabetes Risk Score in screening undiagnosed diabetes and prediabetes among U.S. adults by gender and race: NHANES 1999–2010. PLoS ONE 9(5), e97865 (2014).
Zipf, G. et al. National health and nutrition examination survey: plan and operations, 1999–2010. Vital Health Stat 1 56, 1–37 (2013).
Alpaydin, E. Introduction to Machine Learning (MIT Press, 2014).
Deo, R. C. Machine learning in medicine. Circulation 132(20), 1920–1930 (2015).
Pandey, G. et al. A nasal brush-based classifier of asthma identified by machine learning analysis of nasal RNA sequence data. Sci. Rep. 8(1), 8826 (2018).
Varghese, B. et al. Objective risk stratification of prostate cancer using machine learning and radiomics applied to multiparametric magnetic resonance images. Sci. Rep. 9(1), 1570 (2019).
Cleophas, T. J. & Zwinderman, A. H. Machine Learning in Medicine—a Complete Overview (Springer, 2015).
National Center for Health Statistics. NHANES Questionnaires, Datasets, and Related Documentation 2018 [Available from: https://wwwn.cdc.gov/nchs/nhanes/default.aspx.
Classification and Diagnosis of Diabetes. Standards of Medical Care in Diabetes-2019. Diabetes Care 42(Suppl 1), S13-s28 (2019).
Lever, J., Krzywinski, M. & Altman, N. Points of significance: Classification evaluation. Nat Methods 13(8), 603–604 (2016).
Demsar, J. Statistical Comparisons of classifiers over multiple data sets. J. Mach. Learn Res. 7, 1–30 (2006).
Arlot, S. & Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 4, 40–79 (2010).
Saeys, Y., Inza, I. & Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics (Oxford, England). 23(19), 2507–2517 (2007).
Ching, T. et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 15(141), 20170387 (2018).
Mayer-Davis, E. J., Dabelea, D. & Lawrence, J. M. Incidence trends of type 1 and type 2 diabetes among youths, 2002–2012. N. Engl. J. Med. 377(3), 301 (2017).
Zamora-Kapoor, A., Fyfe-Johnson, A., Omidpanah, A., Buchwald, D. & Sinclair, K. Risk factors for pre-diabetes and diabetes in adolescence and their variability by race and ethnicity. Prev. Med. 115, 47–52 (2018).
Zhang, Y. et al. High risk of conversion to diabetes in first-degree relatives of individuals with young-onset type 2 diabetes: A 12-year follow-up analysis. Diabetes Med. 34(12), 1701–1709 (2017).
Casagrande, S. S., Menke, A., Linder, B., Osganian, S. K. & Cowie, C. C. Cardiovascular risk factors in adolescents with prediabetes. Diabet Med. (2018).
Lee, J. M. et al. A risk score for identifying overweight adolescents with dysglycemia in primary care settings. J. Pediatr. Endocrinol. Metab. 26(5–6), 477–488 (2013).
Santoro, N. et al. Predicting metabolic syndrome in obese children and adolescents: look, measure and ask. Obes. Facts 6(1), 48–56 (2013).
Heikes, K. E., Eddy, D. M., Arondekar, B. & Schlessinger, L. Diabetes risk calculator: A simple tool for detecting undiagnosed diabetes and pre-diabetes. Diabetes Care 31(5), 1040–1045 (2008).
Herman, W. H., Smith, P. J., Thompson, T. J., Engelgau, M. M. & Aubert, R. E. A new and simple questionnaire to identify people at increased risk for undiagnosed diabetes. Diabetes Care 18(3), 382–387 (1995).
May, A. L., Kuklina, E. V. & Yoon, P. W. Prevalence of cardiovascular disease risk factors among US adolescents, 1999–2008. Pediatrics 129(6), 1035–1041 (2012).
Acknowledgements
The study was enabled in part by computational resources provided by Scientific Computing at the Icahn School of Medicine at Mount Sinai.
Funding
This work was supported by a National Institutes of Health grant [R01GM114434] and an IBM Faculty award to author G.P. and by a Cigna Foundation Grant [10005177] awarded to author N.V. This work was also supported by NIH grant P30 ES023515 and by a National Cancer Institute grant [1R21CA235153] award to author B.L.
Author information
Authors and Affiliations
Contributions
N.V., B.L., and G.P. conceived the study and wrote the manuscript. N.V. provided clinical expertise and supervised the study. B.L. prepared the relevant NHANES data and carried out the performance analyses of the screeners. L.W. and P.C. carried out the machine learning analyses under G.P.’s supervision. All the authors reviewed and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Vangeepuram, N., Liu, B., Chiu, Ph. et al. Predicting youth diabetes risk using NHANES data and machine learning. Sci Rep 11, 11212 (2021). https://doi.org/10.1038/s41598-021-90406-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-90406-0
This article is cited by
-
Recent applications of machine learning and deep learning models in the prediction, diagnosis, and management of diabetes: a comprehensive review
Diabetology & Metabolic Syndrome (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
