
Abstract
The cardiac lipid panel (CLP) is a novel panel of metabolomic biomarkers that has previously shown to improve the diagnostic and prognostic value for CHF patients. Several prognostic scores have been developed for cardiovascular disease risk, but their use is limited to specific populations and precision is still inadequate. We compared a risk score using the CLP plus NT-proBNP to four commonly used risk scores: The Seattle Heart Failure Model (SHFM), Framingham risk score (FRS), Barcelona bio-HF (BCN Bio-HF) and Meta-Analysis Global Group in Chronic Heart Failure (MAGGIC) score. We included 280 elderly CHF patients from the Cardiac Insufficiency Bisoprolol Study in Elderly trial. Cox Regression and hierarchical cluster analysis was performed. Integrated area under the curves (IAUC) was used as criterium for comparison. The mean (SD) follow-up period was 81 (33) months, and 95 (34%) subjects met the primary endpoint. The IAUC for FRS was 0.53, SHFM 0.61, BCN Bio-HF 0.72, MAGGIC 0.68, and CLP 0.78. Subjects were partitioned into three risk clusters: low, moderate, high with the CLP score showing the best ability to group patients into their respective risk cluster. A risk score composed of a novel panel of metabolite biomarkers plus NT-proBNP outperformed other common prognostic scores in predicting 10-year cardiovascular death in elderly ambulatory CHF patients. This approach could improve the clinical risk assessment of CHF patients.
Similar content being viewed by others

Introduction
The prevalence of chronic heart failure (CHF) in the western world continues to increase, especially in patients older than 65 years1. CHF is a major burden on the health care system and is associated with high morbidity and mortality, including a poor quality of life2. An important aspect of CHF management is to ensure that clinicians and patients with CHF have the necessary knowledge and resources to make the best health decisions. A prognostic model is one such resource, defined as a formal combination of multiple predictors from which risks of a specific outcome can be calculated for individual patients.
Prognostic models are abundant in the literature, and the most popular ones include the SHFM (Seattle Heart Failure Model), FRS (Framingham Risk Score), MAGGIC (Meta-analysis Global Group in Chronic Heart Failure), and BCN Bio-HF (Barcelona Bio-Heart Failure Risk Calculator). The SHFM score is the most thoroughly validated and contains the most predictor variables of the four3. The MAGGIC score4 was developed from a dataset of over 39,000 patients across 30 studies and validated on more than 60,000 patients using 2 large CHF cohorts5,6. The FRS score was developed as a sex-specific risk score that can be conveniently used to calculate general cardiovascular disease (CVD) risk and risk of individual CVD events7. The BCN Bio-HF score contains 11 clinical variables with the most biomarker variables [NT-proBNP, high-sensitivity cardiac troponin T (hs-cTnT), high-sensitivity soluble ST2 (ST2)] and has been externally validated8,9. These models all use common clinical and demographic variables to predict the prognosis of CHF patients and have convenient online calculators. Although these scores have been validated, they have not been widely adopted possibly because they are not routinely calculated in clinical practice10,11,12, have poor reliability at the individual patient level5, suffer from a significant amount of missing data requiring imputation.
Metabolomics is a rapidly growing field in biomarker profiling that could help meet the need for more robust prognostic biomarkers. By applying nuclear magnetic resonance (NMR) spectroscopy and mass spectrometry (MS), it is now possible to analyze hundreds of metabolites from human samples such as blood, urine, saliva, and tissue, which can elucidate the outcome of complex networks of endogenous and exogenous biochemical reactions13. This approach could provide a more comprehensive signature of biochemical activities that could be associated with diet, medication, disease progression, and thus negative outcomes due to these complex mechanisms14,15. Previous studies have shown that metabolomic biomarkers can be used for risk prediction as well as diagnosis of CHF16,17,18,19,20,21,22,23,24,25,26,27,28.
One promising metabolomic biomarker panel in CHF patients is the cardiac lipid panel (CLP) which is supplemented by N-terminal pro–B-type natriuretic peptide (NT-proBNP). The CLP is consists of three specific metabolomics features: triacylglycerol (TAG) 18:1/18:0/18:0, phosphatidylcholine (PC) 16:0/18:2, and the sum of the 3 isobaric sphingomyelin (SM) species SM d18:1/23:1, SM d18:2/23:0, and SM d17:1/24:1. The diagnostic value of CLP was first discovered in a study by Mueller and colleagues, where they compared CHF patients to healthy controls, and found that CLP was able to improve the diagnostic performance over NT-proBNP alone29. The incremental prognostic value of the CLP was first assessed in a recent study which found it improved the discrimination and risk assessment over NT-proBNP and clinical risk factors30.
The objective of this study was to compare the performance of a risk score composed of the CLP panel plus NT-proBNP to the four commonly used traditional risk scores (SHFM, FRS, MAGGIC, BCN Bio-HF) to predict long-term cardiovascular mortality in ambulatory CHF patients. We hypothesized that the CLP risk score would improve our ability to classify risk of cardiovascular death in comparison to the four validated clinical risk prediction algorithms.
Results
Table 1 shows the baseline characteristics of the total population (n = 280) as well as the variables included in each score. Mean age of this sub-cohort was 72.1 (4.9) years, 26.4% were women, 45% patients had heart failure with reduced ejection fraction (HFrEF) (LVEF < 35%), and most patients were in NYHA functional class II (67.5%) with the remaining in NYHA class III. Hypertension was present in 80% of participants and 45% were current or former smokers; 29% had diabetes and 71% had CAD. During the follow-up period (mean = 81 months, SD = 33; median = 96 months), 95 (34%) patients met the primary outcome. There were 30 (11%) patients who met the secondary outcome of 3-year all-cause mortality. The sample selection criteria as well as the comparison of this sub cohort’s baseline characteristics to the source cohort has previously been reported30, however, this study analyzed 10 year follow up rather than the previously reported 4 year follow up.
All variables were available for each score except for the lymphocytes (%) variable in the SHFM score, which was imputed as previously described. The SHFM model had the highest number of variables (n = 17), followed by MAGGIC (n = 13), BCN Bio-HF (n = 12), FRS (n = 7), and CLP (n = 4). There were 13 overlapping variables which were included in at least 2 scores. The SHFM score included the most medication (n = 6) and laboratory (n = 5) variables, BCN Bio-HF is the only model with biomarker data (NT-proBNP) while MAGGIC included the most clinical (n = 7) and demographic variables (n = 3).
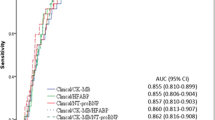
Table 2 shows the univariate Cox Regression results. The CLP (HR = 2.38, p < 0.001), SHFM (HR = 2.01, p = 0.002, MAGGIC (HR = 1.10, p < 0.001), and BCN Bio-HF (HR = 1.09, p = 0.0393) scores were significantly associated with the outcome while FRS was not. The hazard ratios for the secondary endpoint of 3-year all-cause mortality are shown in Supplemental Table 1. All scores had a higher HR than the primary outcome except for CLP and FRS. Figure 1 shows the AUC change over time (IAUC) for the 5 prognostic scores with the comparison of Uno’s concordance statistics for hypothesis testing. The IAUC was 0.53, 0.61, 0.68, 0.72, and 0.78 for FRS, SHFM, MAGGIC, BCN Bio-HF, and CLP, respectively. Harrell’s c statistics at 10 year follow up show similar results (Supplemental Table 2). The four traditional scores were all significantly different (p < 0.05) from the CLP score according to the difference in concordance statistic (Supplemental Table 3). The incremental value of the CLP to NT-proBNP is shown in Supplemental Figure 1, the NT-proBNP only IAUC was 0.71 while the CLP score (which incorporates the CLP biomarkers plus NT-proBNP) was 0.78 (p = 0.004). Discrimination analysis of the secondary outcome of 3-year all-cause mortality showed the CLP IAUC lowered to 0.76, and only CLP vs FRS remained significantly different (Supplemental Figure 2). The models showed adequate calibration except for FRS (calibration curve slope = 0.894) (Supplemental Figure 3).

Discrimination performance for each prognostic score for 10-year cardiovascular mortality. Integrated area under the curve (IAUC) for: SHFM (Seattle Heart Failure Model), FRS (Framingham Risk Score), and MAGGIC (Meta-analysis Global Group in Chronic Heart Failure), BCN Bio-HF (Barcelona Bio-Heart Failure Risk Calculator), and Cardiac Lipid Panel Risk Score (CLP). Total subjects, n = 280; total events, n = 95. p values were calculated from the differences in concordance statistic in comparison to the CLP score.
Competing event analysis showed the SHFM, MAGGIC, and the CLP models remained significantly associated with cardiovascular death, and all scores showed less association to non-cardiovascular death (Supplemental Table 4). The CIF curve, which accounted for non-cardiovascular mortality as a competing event, showed higher cumulative incidence of cardiovascular mortality with higher CLP scores (Supplemental Figure 4).
Figure 2 shows the hierarchical cluster dendrogram mapped to illustrate the assignment of patients into their respective clusters and the associated color map shows the range of each prognostic score and their distribution within each cluster. Hierarchical clustering grouped the patients in separate clusters accounting for the noise between smaller clusters. Each observation was treated as a unique cluster, and this method: (1) identified the two similar or close clusters, and (2) merged the two most similar clusters. Using this clustering technique, similar prognostic score data from participants were grouped together, such that the members in the same group were more similar to each other than the members in the other groups. We can infer from the cluster centres and cluster memberships that CLP risk score was better at grouping patients with respect to their cardiovascular mortality risk and associated clinical characteristics compared to the other four scores. The survival curves for each risk cluster are shown in Fig. 3. Rates of mortality were: low risk cluster (20%), moderate risk cluster (27%) and high-risk cluster (50%). Supplemental Figure 5 shows the constellation plot on a two-dimensional plane with nodes and links to describe relationship among component nodes. This plot is an alternate depiction of the dendrogram and illustrates the length between clusters and a balanced structure. Supplemental Figure 6 shows the scatterplot matrix of all 4 scores and clusters to illustrate the relationships between each prognostic score and risk cluster assignment.

Hierarchal cluster dendrogram of three risk clusters. Assignment of patients into risk clusters based on the prognostic scores. The clustering process can be viewed by reading the dendrogram from left to right. Each step consists of combining the two closest clusters into a single cluster. The joining of clusters is indicated by horizontal lines that are connected by vertical lines. The horizontal position of the vertical line represents the distance between the two clusters that are most recently joined to form the specified number of clusters. The prognostic scores used for clustering were: SHFM (Seattle Heart Failure Model), FRS (Framingham Risk Score), and MAGGIC (Meta-analysis Global Group in Chronic Heart Failure), BCN Bio-HF (Barcelona Bio-Heart Failure Risk Calculator), and Cardiac Lipid Panel Risk Score (CLP). Each prognostic score was standardized to the same scale (mean = 0; SD = 1). Ward’s minimum variance method was used for clustering. Blue dendrogram indicates the cluster 1 (low risk), n = 119; Grey dendrogram indicates cluster 2 (moderate risk), n = 44, Red dendrogram indicates cluster 3 (high risk), n = 117; Total subjects, n = 280.

Kaplan Meier survival curves for 10-year cardiovascular mortality stratified by each risk cluster. The following scores were used to derive the risk clusters: SHFM (Seattle Heart Failure Model), FRS (Framingham Risk Score), MAGGIC (Meta-analysis Global Group in Chronic Heart Failure), BCN Bio-HF (Barcelona Bio-Heart Failure Risk Calculator), and Cardiac Lipid Panel Risk Score (CLP). Each prognostic score was standardized to the same scale (mean = 0; SD = 1). Total subjects, n = 280; total events, n = 95.
Table 3 shows the cohort characteristics and the prognostic score distribution for each risk cluster. The three clusters were: low risk, n = 119; moderate risk, n = 44; high risk, n = 117. There were 11 out of the 50 cohort characteristics significantly different across the 3 clusters. In particular, patients in the highest risk cluster were older, with lower LVEF, higher NT-proBNP, and experienced a higher frequency of events. The SHFM, BCN Bio-HF, and CLP scoreswere significantly different across their respective risk clusters. Of the continuous risk scores (FRS, SHFM, MAGGIC, BCN Bio-HF), only SHFM and MAGGIC, had its highest mean score in the high-risk cluster. The categorical CLP score showed a skewed distribution of higher risk scores (3–4) in the moderate and high-risk clusters. In the high-risk cluster, the majority of subjects were scored with CLP scores of 3–4.
The correlation of the CLP biomarkers TAG, PC, and SM were most correlated with the clinical characteristics: triglycerides (r = 0.531, p < 0.001), total cholesterol (r = 0.431, p < 0.001), and LDL (r = 0.502, p < 0.001), respectively (Supplemental Figure 7).
Discussion
We found that a risk score based on a novel panel of three metabolite-based biomarkers plus NT-proBNP outperformed commonly used traditional prognostic models for predicting cardiovascular mortality in elderly ambulatory CHF patients. We first measured the association of each risk score with the outcome, followed by discrimination analysis, then cluster analysis, and finally correlation analysis of the individual CLP biomarkers with the clinical characteristics. In our study cohort, CLP score, showed the best discrimination compared to the other 4 scores. This indicates that the biomarker information included in the CLP score could more precisely classify high risk CHF patients than the information included in the 4 other risk scores. On the other hand, the biomarker information from the CLP is not as easily attainable and no convenient calculator exists yet, as these findings should first be validated in larger cohorts. Additionally, none of the other scores were originally developed for 10-year cardiovascular mortality. To the best of our knowledge there is no score specific for predicting 10-year risk of cardiovascular death, but it is not uncommon to use the scores such as FRS to predict different outcomes in similar studies31,32,33. Nevertheless, the other risk scores may be improved with the addition of common biomarkers in their score calculation. For instance, NT-proBNP is a well-established biomarker that is known to be associated with ventricular wall stress34 and is considered the gold-standard biomarker in CHF diagnosis and prognosis35. Only BCN Bio-HF contained NT-proBNP and it was the next best performing prognostic score after the CLP.
We performed cluster analysis to assess how well the risk scores could partition subjects into different risk groups, blinded to the study outcome. A strength of this approach is that clusters could define relevant groups of patients and could mitigate the problems of multicollinearity while determining if the predictive variables are useful in separating these groups. In our study, patients within each cluster varied along measures of age, laboratory parameters, days survived, as well as the prognostic scores. When comparing the score distributions across the three risk clusters, the CLP score showed a more homogenous grouping of patients according to their risk score stratification while the other scores showed a more heterogenous distribution across risk clusters. Several prior studies have used similar clustering methods to identify clinically relevant patient subgroups for CHF36,37, but we are not aware of previous studies using clustering methods to compare a novel biomarker score to other conventional prognostic scores for CHF.
The combination of the CLP’s metabolomic features with NT-proBNP into a risk score may help overcome limitations of using only traditional clinical risk factors. Furthermore, application of a single biomarker such as NT-proBNP for outcome prediction is limited by insufficient specificity (low predictive value or high false positive rate)38,39. Recently, it was reported that the CLP added incremental prognostic value to NT-proBNP in predicting 4-year cardiovascular mortality30. We used the same method to calculate the CLP score for this study, and we also confirmed that the CLP provided similar incremental value to NT-proBNP alone as previously found in the 4-year study30.Using an aggregate score rather than individual biomarkers for risk prediction can help more precisely stratify risk. A recent meta-analysis of 18 metabolomic prognostic biomarker studies for CVD found those which incorporated a selection of metabolites into a score (n = 5 studies) had the best prognostic performance rather than using the individual biomarker values16. Another systematic review20 reported 6 studies21,22,23,24,25,26 developed a metabolite-based score to predict CVD risk with each score composed between 4 and 16 biomarkers.
We have briefly mentioned the components of the CLP in the introduction section, in addition to improving risk prediction, developing a biomarker-based risk score could also improve our understanding of the pathophysiology and biological mechanisms involved in CHF. In the following paragraphs we would like to highlight those mechanisms based on previous research. The CLP metabolites can be grouped into three different lipid subclasses, sphingomyelin (SM) phosphatidylcholine (PC), and triglycerides (TAG), which have previously been found to be associated with cardiomyocyte stress/apoptosis40, intestinal microbial metabolism/inflammation19, and coronary artery disease41, respectively. Sphingomyelins are localized in cell membranes and lipoproteins, and their hydrolysis by sphingomyelinase leads to increased amounts of ceramide. Ceramide triggers the generation of reactive oxygen species (ROS) involved in the modulation of cell proliferation and apoptosis, neutrophil adhesion to the vessel wall, and vascular tone. Dysfunctional sphingomyelin and ceramide metabolism may lead to or aggravate cardiovascular diseases42. Lemaitre et al.43 reported that lipid species such as Cer-16 and SM-16 were associated with increased risk of heart failure. Sigruener et al.44 reported that the detection of sphingomyelin species SM 16∶0, 16∶1, 24∶1 and 24∶2 was increasingly associated with mortality in Ludwigshafen Risk and Cardiovascular Health (LURIC) study. The CLP biomarker panel consists of the sum of three monosaturated fatty acid carrying SM species: SM d18:1/23:1, SM d18:2/23:0, SM d17:1/24:1.
PC is the most abundant lipid in the human body and is subjected to chemical events like lipid peroxidation and ROS formation45. Myocardium suffers heavily from lipid peroxidation related injury46. PC carrying polyunsaturated fatty acids such as PC (16:0/18:2) which is a component of the CLP panel, have increased risk for lipid peroxidation47. Oxidative stress increases the formation of electrophilic aldehydes from native phospholipids leading to formation of adducts with tissue or plasma proteins thereby aggravating the pathophysiology of cardiovascular diseases48. Previous studies have shown that lipid peroxidation and ROS generation are associated with cardiac damage and raises mortality. Higher consumption of PC was found to increase the risk of organ injury and cardiovascular mortality49. Natural antioxidants like α-tocopherol have shown to reduce such oxidative stress and resulting inflammation thereby preventing the progression of cardiac injury50.
The molecules of TG are involved in the regulation of insulin-signaling pathways through the activation of several serine/threonine kinases, which suppress insulin receptors, thus inducing peripheral insulin resistance. Previous studies have shown that insulin resistance leads to inflammation and atherosclerosis51. Although the relationship between total triglycerides and insulin resistance and CVD risk are well established52, the relationships between individual serum TGs and insulin resistance is not well-established. Studies of individual TGs may help better characterize insulin resistance and CVD better than total triglycerides. For instance, it was previously found that saturated TG 16:0 fatty acid was positively associated with fasting serum insulin concentrations and that of essential 18:3 n-6 fatty acid was negatively associated53. Another study on individual TGs revealed that serum TG molecules containing saturated and monounsaturated fatty acids, such as TG(16:0/16:0/18:1) and TG(16:0/18:1/18:0), correlated positively, whereas those containing essential fatty acids, such as TG(18:1/18:2/18:2), negatively with features of insulin resistance54. The CLP consists of the saturated and monosaturated fatty acid carrying TAG 18:1/18:0/18:0.
These findings indicate that metabolomic studies may help gain a deeper understanding of the molecular mechanisms of CVD. Therefore, more detailed metabolomic analysis would hopefully lead to the discovery or further development of sensitive and specific lipid-based markers for cardiovascular risk.
Study limitations
These proof-of-concept findings should be interpreted as hypothesis generating to be used as a reference for validation studies on larger cohorts in the future. The homogeneity of this cohort, elderly patients with stable CHF, may have had an impact on the performance of the prognostic scores. Due to the inclusion and exclusion criteria of the CIBIS-ELD trial, these results may not have good external validity, and more research would be needed to validate the results. Performance and comparison of the risk scores may be affected by the fact that the models were designed using different endpoint definitions and cohorts. Risk categories that are clinically relevant for one model’s definition may not apply to a different model. The MAGGIC score estimates risk of all-cause mortality at one and at three years, the SHFM up to five years, and the BCN Bio-HF at one, two, and three years, and the FRS estimates risk of first CVD event, none of which were developed for the primary outcome of this study of 10-year cardiovascular mortality. The SHFM score may have been affected by the imputation of lymphocytes % as well as the lack of patients taking allopurinol. The BCN-bio HF score was updated in 201855 which could provide better predictive value than the 2014 version used in this study. We were limited by the availability of the data for the 2018 version of the BCN-bio HF score, since it required more parameters such as ARNi medication and number of HF hospitalizations in the previous year. The FRS was originally developed for coronary artery disease and not CHF, which may explain its poor performance on this cohort. The CLP biomarker kit was developed for routine use in the clinic; however, it is still a research biomarker panel pending regulatory approval and must be sent to a lab equipped with MS technology. Our findings are limited to this population of elderly CHF patients and future validation studies should be performed to include a more heterogenous cohort such as younger, more women, and early/ asymptomatic patients. Other common biomarkers such as ST2, hs-CRP, and troponins should be compared to the CLP as they are more readily available and do not require samples be sent to a specialized lab. The CLP panel was originally developed as a diagnostic and early detection biomarker for HFrEF, and clinicians and researchers should be cautious when using it as a prognostic tool, as these are still preliminary findings.
Conclusion
In a cohort of ambulatory CHF patients, we have shown that the prognostic scores included in this study were useful in stratifying patients into risk clusters. Our findings demonstrate that the CLP risk score comprising a panel of 3 novel metabolomic biomarkers and NT-proBNP, could improve the prediction of cardiovascular mortality over traditional prognostic scores. In the future, a broader array of biomarkers should be integrated into a more comprehensive risk score that may improve discrimination potential and risk stratification and the CLP offers a promise. The CLP score is a step in the direction of providing a more precise decision support tool to assist clinicians and patients in managing their CHF treatment.
Methods
Study population
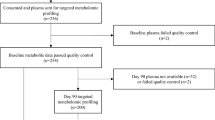
This study used a sub-cohort randomly selected from the Cardiac Insufficiency Bisoprolol Study in Elderly (CIBIS-ELD) trial, a multi-center, randomized, double-blind trial with ≥ 65-year-old patients being treated for CHF. The original study design and results of the CIBIS-ELD trial have been published previously56,57. Briefly, patients with CHF were randomized in a 1:1 fashion to receive two different beta-blockers, either bisoprolol or carvedilol, and up titrated every fortnight for 12 weeks and then followed at 10 years. From this source cohort (n = 883), there were n = 589 with available blood samples. Patients were randomly selected and included in the analysis only if they passed quality control58,59 resulting in a final set of 280 cases. The ethics committees of all participating centers approved the study protocol, and informed consent was signed by all participants prior to study participation. The ethics committees include: Germany: Ethikkommission der Charité on the 13th June 2007 (Amendment 5) (ref: 125/2004), Serbia: Ethics board of the University Hospital on the 31st March 2006 (ref: 6108/18), Slovenia: The national medical ethics committee on the 2nd July 2007 (ref: KME 188/06/07). The investigation conformed to the principles outlined in the Declaration of Helsinki60.
Biomarker measurements
Targeted metabolite profiling of the serum samples which passed quality control was performed at a specialized metabolomics lab using a commercially available kit. The kit uses a protocol based on a 1-phase extraction of the blood samples followed by gas chromatography mass spectrometry (GC–MS) (Agilent 6890 GC coupled to an Agilent 5973 MS-System) and liquid chromatography tandem-mass spectrometry (LC–MS/MS) (Agilent 1100 HPLC-System coupled to an Applied Biosystems API4000 MS/MS-System) analysis as previously described29. The analytical protocol was designed for routine measurement in the clinical practice setting; however, it is currently only available in specialized labs equipped with MS technology. The samples were stored at − 80 °C and transferred on dry ice prior to analysis. The three CLP metabolomic features and NT-proBNP measurements, were generated at baseline, only for the previously mentioned samples (n = 280). NT-proBNP was a measured using commercially available assays (Elecsys, Roche Diagnostics).
Calculating prognostic scores
Each prognostic score was calculated using the corresponding method proposed by the original authors (3–6). Only the scores which were developed in the follow-up time period, 2006–2016, were included in the analysis due to data availability. For calculating the SHFM score, % lymphocyte was missing, and the median (31%) of the normal range (20–40%) was imputed for all subjects. For calculating the BCN Bio-HF score, the model with clinical variables plus NT-proBNP was used since ST-2 and hs-cTnT were not available. The CLP risk score was calculated as the count of biomarkers above the Youden index cut-off61. The Youden’s index calculates each biomarker’s optimal cut-off from the Cox regression. There were 4 cut-off values, since four biomarkers are included in the score: three from the CLP and NT-proBNP. Based on the cut-off, a value of 1 or 0 was assigned if the biomarker value was above/below the cut-off value, or in the direction of greater risk, then all 4 values were summed to generate the final score for each subject. The score ranged from 0 to 4, higher scores indicating higher risk. The primary outcome, cardiovascular death, was defined as death by myocardial infarction, non-responding arrhythmia, asystole, chronic pump failure, or other cardiac cause and verified by a blinded committee of cardiologists.
Statistical analysis
Power and sample Size
The sample size was adjusted for an anticipated event rate of 0.34. A Cox regression of the log hazard ratio on a covariate with a standard deviation of 1.5 based on a sample of 257 observations achieves 80% power at a 0.050 significance level to detect a regression coefficient equal to 0.2. Adjusting for an anticipated loss to follow up rate of 10%, the final sample size would be 283.
Discrimination analysis and calibration
Categorical variables were expressed as number (%) and continuous variables were expressed as mean (SD). The primary outcome was 10-year cardiovascular death, and the secondary outcome was 3 year all-cause death, since all scores except for FRS were developed for this outcome. Cox Regression was performed on each of the prognostic scores, and hazard ratios and 95% confidence intervals were calculated to assess their relationship with the outcome.
For the survival models, integrated area under the receiver operator curves (IAUC) and Harrell’s c statistic62 were calculated to assess the discrimination of each score in predicting the outcome. Hypothesis testing of the change in discrimination was performed by calculating the differences in concordance statistics63. The IAUC curves are computed as a weighted average of the AUC values at all the event times, with the weights as the jumps of the Kaplan–Meier estimate of the survivor function. Calibration (i.e., the agreement between observed outcomes and predictions) of all models was assessed graphically, with calibration plots.
Competing event and cause-specific analysis was performed for all models with non-cardiovascular mortality as the competing event. The cumulative incidence function (CIF) was calculated for the CLP which was stratified by low (CLP score 0–1), moderate (CLP score 2), and high (CLP score 3–4) to assess CIF. The discrimination analysis and competing event and cause-specific analysis were performed using SAS software version 9.4 of the SAS System for Windows (SAS Institute, Inc., Cary, North Carolina)64. Calibration was analyzed using Stata Statistical Software version 1665.
Cluster analysis
Hierarchical cluster analysis was performed using Ward’s minimum variance method to assess each prognostic score’s ability to separate cases into risk groups. The distance between two clusters is the ANOVA sum of squares between the clusters summed over all variables. Only the 5 risk scores used as the input variables for the cluster analysis to examine how well they classified patients into a low, moderate, and high-risk of cardiovascular mortality. Data was standardized (mean of 0 and SD of 1), to perform clustering. The clinical characteristics and scores were compared across risk clusters. Comparisons among continuous variables were performed using Wilcoxon rank sum test; and Pearson’s chi-square test (or Fisher’s exact test) or Mantel–Haenszel Chi-square test for categorical and ordinal data, respectively. Kaplan–Meier curves were used to compare the survival distribution across risk clusters. Survival time was calculated from baseline until cardiovascular death or censoring at 10 year follow up. Cluster analysis was performed using JMP pro software version 1466. Kaplan–Meier curves were generated using SAS software version 9.4 of the SAS System for Windows (SAS Institute, Inc., Cary, North Carolina)64.
Correlation analysis
To investigate potential relationships between the CLP biomarker values and common clinical parameters, Pearson’s correlation coefficients were calculated, significant at the 0.01 level (2-tailed). Correlation analysis was performed using R software version 3.6.167.
References
MEMBERS, W. G. et al. Heart disease and stroke statistics─2012 update: A report from the American Heart Association. Circulation 125(1), e2 (2012).
Bui, A. L., Horwich, T. B. & Fonarow, G. C. Epidemiology and risk profile of heart failure. Nat. Rev. Cardiol. 8(1), 30–41 (2011).
Levy, W. C. et al. The Seattle Heart Failure Model: Prediction of survival in heart failure. Circulation 113(11), 1424–1433 (2006).
Pocock, S. J. et al. Predicting survival in heart failure: A risk score based on 39 372 patients from 30 studies. Eur. Heart J. 34(19), 1404–1413 (2013).
Allen, L. A. et al. Use of risk models to predict death in the next year among individual ambulatory patients with heart failure. JAMA Cardiol. 2(4), 435–441 (2017).
Sartipy, U. et al. Predicting survival in heart failure: Validation of the MAGGIC heart failure risk score in 51,043 patients from the Swedish Heart Failure Registry. Eur. J. Heart Fail. 16(2), 173–179 (2014).
D’Agostino, R. B. Sr. et al. General cardiovascular risk profile for use in primary care: the Framingham Heart Study. Circulation 117(6), 743–753 (2008).
Lupón, J. et al. Development of a novel heart failure risk tool: The Barcelona bio-heart failure risk calculator (BCN bio-HF calculator). PLoS ONE 9(1), e85466 (2014).
Lupón, J. et al. Validation of the Barcelona Bio-Heart Failure Risk Calculator in a cohort from Boston. Rev. Esp. Cardiol. (Engl. ed.) 68(1), 80–81 (2014).
Howlett, J. G. Should we perform a heart failure risk score? 4–5 (2013).
Aaronson, K. D. & Cowger, J. Heart failure prognostic models: Why bother?. Cir.c Heart Fail. 5(1), 6–9 (2012).
Steyerberg, E. W. et al. Prognosis research strategy (PROGRESS) 3: Prognostic model research. PLoS Med. 10(2), e1001381 (2013).
Albert, C. L. & Tang, W. H. W. Metabolic Biomarkers in heart failure. Heart Fail. Clin. 14(1), 109–118 (2018).
Gupte, A. A. et al. Mechanical unloading promotes myocardial energy recovery in human heart failure. Circ. Cardiovasc. Genet. 7(3), 266–276 (2014).
Bedi, K. C. Jr. et al. Evidence for intramyocardial disruption of lipid metabolism and increased myocardial ketone utilization in advanced human heart failure. Circulation 133(8), 706–716 (2016).
McGranaghan, P. et al. Predictive value of metabolomic biomarkers for cardiovascular disease risk: A systematic review and meta-analysis. Biomarkers 25(2), 101–111 (2020).
Cheng, M. L. et al. Metabolic disturbances identified in plasma are associated with outcomes in patients with heart failure: diagnostic and prognostic value of metabolomics. J. Am. Coll. Cardiol. 65(15), 1509–1520 (2015).
Ahmad, T. et al. Prognostic implications of long-chain acylcarnitines in heart failure and reversibility with mechanical circulatory support. J. Am. Coll. Cardiol. 67(3), 291–299 (2016).
Tang, W. H. et al. Prognostic value of elevated levels of intestinal microbe-generated metabolite trimethylamine-N-oxide in patients with heart failure: Refining the gut hypothesis. J. Am. Coll. Cardiol. 64(18), 1908–1914 (2014).
Ruiz-Canela, M. et al. Comprehensive metabolomic profiling and incident cardiovascular disease: A systematic review. J. Am. Heart Assoc. 6(10), e005705 (2017).
Shah, S. H. et al. Association of a peripheral blood metabolic profile with coronary artery disease and risk of subsequent cardiovascular events. Circ. Cardiovasc. Genet. 3(2), 207–214 (2010).
Shah, S. H. et al. Baseline metabolomic profiles predict cardiovascular events in patients at risk for coronary artery disease. Am. Heart J. 163(5), 844–850 (2012).
Rizza, S. et al. Metabolomics signature improves the prediction of cardiovascular events in elderly subjects. Atherosclerosis 232(2), 260–264 (2014).
Vaarhorst, A. A. et al. A metabolomic profile is associated with the risk of incident coronary heart disease. Am. Heart J. 168(1), 45–52 (2014).
Kume, S. et al. Predictive properties of plasma amino acid profile for cardiovascular disease in patients with type 2 diabetes. PLoS ONE 9(6), e101219 (2014).
Zheng, Y. et al. Associations between metabolomic compounds and incident heart failure among African Americans: The ARIC Study. Am. J. Epidemiol. 178(4), 534–542 (2013).
Lanfear, D. E. et al. Targeted metabolomic profiling of plasma and survival in heart failure patients. JACC Heart Fail. 5(11), 823–832 (2017).
Wurtz, P. et al. Metabolite profiling and cardiovascular event risk: A prospective study of 3 population-based cohorts. Circulation 131(9), 774–785 (2015).
Mueller-Hennessen, M. et al. A novel lipid biomarker panel for the detection of heart failure with reduced ejection fraction. Clin. Chem. 63(1), 267–277 (2017).
McGranaghan, P. et al. Incremental prognostic value of a novel metabolite-based biomarker score in congestive heart failure patients. ESC Heart Fail. 7, 3029–3039 (2020).
Towfighi, A., Markovic, D. & Ovbiagele, B. Utility of Framingham coronary heart disease risk score for predicting cardiac risk after stroke. Stroke 43(11), 2942–2947 (2012).
Chen, S. C. et al. Framingham risk score with cardiovascular events in chronic kidney disease. PLoS ONE 8(3), e60008 (2013).
Sara, J. D. et al. Utility of the Framingham Risk Score in predicting secondary events in patients following percutaneous coronary intervention: A time-trend analysis. Am. Heart J. 1(172), 115–128 (2016).
Weber, M. & Hamm, C. Role of B-type natriuretic peptide (BNP) and NT-proBNP in clinical routine. Heart 92(6), 843–849 (2006).
McKie, P. M. & Burnett, J. C. Jr. NT-proBNP: The gold standard biomarker in heart failure. J. Am. Coll. Cardiol. 68(22), 2437–2439 (2016).
Scherzer, R. et al. Association of biomarker clusters with cardiac phenotypes and mortality in patients With HIV infection. Circ. Heart Fail. 11(4), e004312 (2018).
Ahmad, T. et al. Clinical implications of chronic heart failure phenotypes defined by cluster analysis. J. Am. Coll. Cardiol. 64(17), 1765–1774 (2014).
Jensen, J., Ma, L. P., Bjurman, C., Hammarsten, O. & Fu, M. L. Prognostic values of NTpro BNP/BNP ratio in comparison with NTpro BNP or BNP alone in elderly patients with chronic heart failure in a 2-year follow up. Int. J. Cardiol. 155(1), 1–5 (2012).
Maisel, A. et al. State of the art: Using natriuretic peptide levels in clinical practice. Eur. J. Heart Fail. 10(9), 824–839 (2008).
Borodzicz, S., Czarzasta, K., Kuch, M. & Cudnoch-Jedrzejewska, A. Sphingolipids in cardiovascular diseases and metabolic disorders. Lipids Health Dis. 14, 55 (2015).
Do, R. et al. Common variants associated with plasma triglycerides and risk for coronary artery disease. Nat. Genet. 45(11), 1345–1352 (2013).
Li, X., Becker, K. A. & Zhang, Y. Ceramide in redox signaling and cardiovascular diseases. Cell. Physiol. Biochem. 26(1), 41–48 (2010).
Lemaitre, R. N. et al. Plasma ceramides and sphingomyelins in relation to heart failure risk: The Cardiovascular Health Study. Circul. Heart Fail. 12(7), e005708 (2019).
Sigruener, A. et al. Glycerophospholipid and sphingolipid species and mortality: The Ludwigshafen Risk and Cardiovascular Health (LURIC) study. PLoS ONE 9(1), e85724 (2014).
Reis, A. & Spickett, C. M. Chemistry of phospholipid oxidation. Biochim. Biophys. Acta (BBA) Biomembr. 1818(10), 2374–2387 (2012).
Gianazza, E., Brioschi, M., Fernandez, A. M. & Banfi, C. Lipoxidation in cardiovascular diseases. Redox Biol. 1(23), 101119 (2019).
Norris, S. E., Mitchell, T. W. & Else, P. L. Phospholipid peroxidation: Lack of effect of fatty acid pairing. Lipids 47(5), 451–460 (2012).
Tallman, K. A. et al. Phospholipid−protein adducts of lipid peroxidation: Synthesis and study of new biotinylated phosphatidylcholines. Chem. Res. Toxicol. 20(2), 227–234 (2007).
Zheng, Y. et al. Dietary phosphatidylcholine and risk of all-cause and cardiovascular-specific mortality among US women and men. Am. J. Clin. Nutr. 104(1), 173–180 (2016).
Wallert, M. et al. α-Tocopherol preserves cardiac function by reducing oxidative stress and inflammation in ischemia/reperfusion injury. Redox Biol. 1(26), 101292 (2019).
Ye, X., Kong, W., Zafar, M. I. & Chen, L. L. Serum triglycerides as a risk factor for cardiovascular diseases in type 2 diabetes mellitus: a systematic review and meta-analysis of prospective studies. Cardiovasc. Diabetol. 18(1), 1 (2019).
Miller, M. et al. Triglycerides and cardiovascular disease: A scientific statement from the American Heart Association. Circulation 123(20), 2292–2333 (2011).
Tremblay, A. J. et al. Associations between the fatty acid content of triglyceride, visceral adipose tissue accumulation, and components of the insulin resistance syndrome. Metabolism 53(3), 310–317 (2004).
Kotronen, A. et al. Serum saturated fatty acids containing triacylglycerols are better markers of insulin resistance than total serum triacylglycerol concentrations. Diabetologia 52(4), 684–690 (2009).
Bayés-Genís, A. & Lupón, J. The Barcelona Bio-HF calculator: A contemporary web-based heart failure risk score. JACC Heart Fail. 6(9), 808–810 (2018).
Dungen, H. D. et al. Bisoprolol vs. carvedilol in elderly patients with heart failure: Rationale and design of the CIBIS-ELD trial. Clin. Res. Cardiol. 97(9), 578–586 (2008).
Dungen, H. D. et al. Titration to target dose of bisoprolol vs. carvedilol in elderly patients with heart failure: The CIBIS-ELD trial. Eur. J. Heart Fail. 13(6), 670–680 (2011).
Kamlage, B. et al. Quality markers addressing preanalytical variations of blood and plasma processing identified by broad and targeted metabolite profiling. Clin. Chem. 60(2), 399–412 (2014).
Kamlage, B., Schmitz, O., Kastler, J., Catchpole, G., Dostler, M., Liebenberg, V., inventors; Metanomics Health GmbH, assignee. Means and Methods for Assessing the Quality of a Biological Sample. United States patent application US 14/767,059. (2016).
Rickham, P. P. Human experimentation. Code of ethics of the world medical association. Declaration of Helsinki. Br. Med. J. 2(5402), 177 (1964).
Youden, W. J. Index for rating diagnostic tests. Cancer 3(1), 32–35 (1950).
Harrell, F. E., Califf, R. M., Pryor, D. B., Lee, K. L. & Rosati, R. A. Evaluating the yield of medical tests. JAMA 247(18), 2543–2546 (1982).
Uno, H., Cai, T., Pencina, M. J., D’Agostino, R. B. & Wei, L. J. On the C-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Stat. Med. 30(10), 1105–1117 (2011).
SAS software, Version 9.4 of the SAS System for Windows. Copyright 2019 SAS Institute Inc. SAS and all other SAS Institute Inc. product or service names are registered trademarks or trademarks of SAS Institute Inc., Cary, NC, USA. http://support.sas.com.
StataCorp. Stata Statistical Software: Release 16. College Station, TX: StataCorp LLC. http://stata.com (2019).
JMP, Version 14. SAS Institute Inc., Cary, NC, 1989–2019. http://jmp.com.
R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/ (2019).
Acknowledgements
We would like to acknowledge the former staff of Metanomics Health GmbH (Berlin, Germany) as well as the patients and investigators participating in the CIBIS-ELD trial.
Funding
Funding is not applicable for this study. The original CIBIS-ELD study was funded by the German Federal Ministry of Education and Research (BMBF, Project No. 01GI0205). Charité – University Medicine Berlin holds the intellectual property under patents WO 2011092285, WO 2015028671, WO 2016034600, Means and methods for diagnosing heart failure in a subject, WO 2014060486, WO 2014060486, Means and methods for determining a clearance normalized amount of a metabolite disease biomarker in a sample, WO 2016016258 Means and methods for diagnosing heart failure on the basis of cholesterol parameters, sphingomyelins and/or triacylglycerols. CIBIS-ELD was supported by the German Federal Ministry of Education and Research (grant number 01GI0205). Sponsor according to ICH-GCP was the Charité - Universitätsmedizin (Berlin, Germany). Merck KGaA provided an unrestricted grant without any rights to influence trial design, data collection, data analysis, and interpretation or publication of CIBIS-ELD. The formerly existing Metanomics Health GmbH (Berlin, Germany) supported the presented analysis by a research grant and performed the measurements without any rights to influence design, data collection, data analysis, and interpretation, or publication of the current manuscript.
Author information
Authors and Affiliations
Contributions
Author T.T. was responsible for study conception and design; authors B.P., E.T., F.E., G.L., H.D.D., and T.T. were responsible for acquisition of data; authors A.S., D.O., E.V., F.B., J.S., M.R., P.L., P.M., and S.A. and were responsible for data analysis, and drafting and revision of the manuscript. All authors critically reviewed and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
McGranaghan, P., Saxena, A., Düngen, HD. et al. Performance of a cardiac lipid panel compared to four prognostic scores in chronic heart failure. Sci Rep 11, 8164 (2021). https://doi.org/10.1038/s41598-021-87776-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-87776-w
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
