
Abstract
Given the rapid recent trend of urbanization, a better understanding of how urban infrastructure mediates socioeconomic interactions and economic systems is of vital importance. While the accessibility of location-enabled devices as well as large-scale datasets of human activities, has fueled significant advances in our understanding, there is little agreement on the linkage between socioeconomic status and its influence on movement patterns, in particular, the role of inequality. Here, we analyze a heavily aggregated and anonymized summary of global mobility and investigate the relationships between socioeconomic status and mobility across a hundred cities in the US and Brazil. We uncover two types of relationships, finding either a clear connection or little-to-no interdependencies. The former tend to be characterized by low levels of public transportation usage, inequitable access to basic amenities and services, and segregated clusters of communities in terms of income, with the latter class showing the opposite trends. Our findings provide useful lessons in designing urban habitats that serve the larger interests of all inhabitants irrespective of their economic status.
Similar content being viewed by others


Introduction
The recent trend of rapid global urbanization1 poses major economic, social and structural challenges to cities2, accentuated by the environmental, and population impacts of climate change3, 4. Added to this, rising economic inequality jeopardizes the health and livelihoods of many urban residents. Indeed, the percentage of Americans living in middle-income neighborhoods has decreased from 65 to 42% in the last 40 years, while the inhabitants of neighborhoods at the lower and higher ends of the income spectrum have grown5. Much of the urban growth has been driven by the less wealthy who have progressively moved from the rural areas to cities6. While the rise in economic inequality is a global phenomenon, different patterns are observed between countries and cultures. For instance, while low-income households are typically located in the outskirts in Paris, they live downtown in Detroit7. Such patterns of economic segregation and inequalities are connected as well to racial segregation, urban decay8 and gentrification9. In fact, over the course of history, many policies and resulting infrastructure changes were put in place in ways that hurt minority communities and already vulnerable portions of cities. This has been thoroughly documented in10 for the case of New York and similar instances have been occurring around the world. Understanding the factors behind this and developing public policy to alleviate these trends is therefore crucial to enhance social mobility and economic progress, as well as positively impact the health of citizens11,12,13,14.
To understand the unique sociodemographic and economic context of a city, one needs to take into account a number of factors. For instance, some cities in developing countries concentrate industry in city centers, leading to unfavorable urban conditions such as pollution15. These cities follow a distinct pattern of urbanization, transitioning from strong industrial centers to a decentralized manufacturing pattern16. Additionally, the layout of a city’s natural resources and amenities can bias a population to concentrate in locations other than the expected city center, although urban layout is by no means static. Development induces change in residential patterns change, even more so, during periods of gentrification, causing shifts in the income profile of neighborhoods over time9, 17. Varying welfare policies and housing market conditions affects cities differently across locations; the decline of neighborhoods into poorly maintained areas is more strongly felt in American cites than European ones8.
Residential inequality is only a partial view of the whole picture, given that cities are a product of several interconnected systems. City infrastructure and dynamics are significantly connected to their underlying social systems, in particular influencing development and productivity indicators18,19,20,21,22. Underlying these intra-city mechanics are the people, and their mobility patterns23. Indeed, the increasing accessibility of location-enabled devices and large-scale datasets of human activities, such as credit-card purchases, taxi rides and mobile phone usage are fueling significant advances in our understanding of human mobility behavior24,25,26,27,28,29,30,31,32. Yet, the connection of these observed mobility patterns with socioeconomic status is surprisingly unclear and in many cases contradictory.

Visualization of mobility data. Flows at the country level for the US (left-panel), with New York City shown in the inset. Flows at the country level for Brazil (right-panel), with Rio shown in the inset. (Map generated using the Shapely (https://pypi.org/project/Shapely/) and GeoPandas (https://geopandas.org/) packages in Python).
For instance, while mobility patterns across different socioeconomic classes exhibit very similar characteristics in Boston and Singapore33, a similar study in Louisville, KY, revealed that low-income residents tended to travel further on average than those in affluent ones34. On the other hand, analysis of cell phone data from an emerging Latin American economy revealed that wealthier citizens traveled to more locations and longer distances35. An analysis of mobility in Bogotá, Colombia found the most mobile population to be the upper-middle class instead of the wealthiest36. Employment status played a role in movement patterns in both Riyadh and Spain, where the unemployed tended to travel less and spend more time at home37, 38. Two studies in French municipalities found a connection between the diversity of location visits with income, but no connection to the distance traveled39, 40.
The variance in the results, indicate that the observed diversity in trends are the result of a complex interplay between urban infrastructure and socioeconomic processes. However, these were conducted in a relatively small set of cities, with different underlying datasets and methodologies. Greater clarity and insight may be uncovered by conducting the studies at scale, globally, and with a uniform methodology. To that effect, here, we explore the multiple facets connecting human travel behavior in a city to its socioeconomic landscape, through a country-wide analysis encompassing one hundred cities in the United States and Brazil. The two countries were selected due to their similarity in total population and the number of large cities, with one being a developed economy, while the other an emerging economy with markedly different socioeconomic characteristics. We find differences within and between the two countries, with two distinct classes of cities; one where there is a strong connection between the socioeconomic status of the residents and their movement patterns, and another class where there appears little-to-no connection. The latter class of cities are characterized by wider use of public transportation, equitable access to amenities and services as well as greater mixing among neighborhoods in terms of income profiles. The former class of cities show the opposite trends. We conclude with a discussion of the implications of our findings, including possible policy directions as it relates to urban planning.
Data description
Mobility data
The Google Aggregated Mobility Research Dataset contains anonymized mobility flows aggregated over 300 million users who have turned on the Location History setting, which is off by default. This is similar to the data used to show how busy certain types of places are in Google Maps, helping identify, for instance, when a local business tends to be the most crowded. The dataset aggregates flows of people between regions, specifically ZIP Code Tabulation Areas (ZCTAs) for the United States, and the comparable census Weighting Area (WA) for Brazil, both of which we generically refer to as sub-areas (SAs).
To produce this dataset, machine learning is applied to logs data to automatically segment it into semantic trips4. To provide strong privacy guarantees, all trips were anonymized and aggregated using a differentially private mechanism to aggregate the flows41. This research is done on the resulting heavily aggregated and differentially private data. No individual user data was ever manually inspected, only heavily aggregated flows of large populations were handled. As a result, the data is represented as a flow matrix \(\mathbf {T}\) whose elements \(T_{ij}\) correspond to annualized out-flows from location i to j for the year 2016. For the purposes of our analysis we consider the 50 largest cities in the United States and analogously in Brazil ranked according to their population. In Fig. 1, we show the resulting mobility network for the United States and Brazil, with New York and Rio shown as inset. The nodes correspond to cities, and the edges are weighted normalized flows between the various locations. The full list of cities along with their populations are shown in Supplementary Tables S1 and S2.
Socioeconomic indicators
To represent socioeconomic status we collected data from the most recent 2016 5-year American Community Survey (ACS) for the United States42, and analogously the 2010 decennial census for Brazil43. Among the metrics collected were age, race, level of education, population, median income, sex composition, among others. A representative sample of the data, aggregated at the level of ZCTA’s is shown for Rochester, NY in Supplementary Table S3, and at the level of WA’s for Campinas in Supplementary Table S4. The choice of resolution is driven by the fact that census-defined units are controlled for population.
In Supplementary Figs. S1 and S2, we show correlation matrices displaying the Spearman rank correlation between a selection of indicators for both countries, finding that household median income has the strongest correlation with a number of other measures. Given that income is an indicator that is queried in most sociodemographic surveys throughout the globe and is the most direct way to estimate the economic capacities of different groups to afford mobility costs, it serves as a parsimonious measure. Consequently, without loss of generality and for the purposes of simplicity, in what follows, we use household median income as a low-dimensional proxy for socioeconomic status. We make use of two different income metrics. The first, \(ID_{q}\), refers to the median income quintile of a given SA. When using this metric we define high and low income sub-areas as the top and bottom median income quintiles within their city. This metric is useful for simply categorizing the income of different sub-areas in a city. Our second metric, \(ID_{f}\), is based on separate census-defined income breaks. In this case income is represented as a probability vector of the percentage of residents within each nationally defined income bracket and allows for more fine-grained analysis of income distribution. For more details on the metrics see Supplementary Section S1.
Amenities
Mobility patterns of urban residents are not only influenced by considerations of cost or income constraints, but also by the number and diversity of amenities and services accessible to them. To collect this information, we query the OpenStreetMap (OSM) database44, that contains geo-referenced information for a broad array of urban amenities, including schools, banks, libraries, groceries and universities, to name a few. The OSM data contains 691 different types of urban facilities belonging to eight main classes: healthcare (e.g., hospital and pharmacy), sustenance (e.g., restaurant and cafe), financial (e.g., bank and ATM), education (e.g., library and university), art-culture (e.g., arts center and theater), entertainment (e.g., cinema and nightclub), transportation (bicycle parking and bus station) and others (e.g., police station and post office).
For the purposes of our analysis, we consider basic amenities related to food, healthcare, education and finance. A representative list of such amenities is shown for four different cities in the United States in Supplementary Table S5. To calculate the distance between a particular zip code and an amenity we use the geodesic distance between the centroid of the zip code and the coordinates of the amenity, represented by its latitude and longitude. This metric is an estimation of the characteristic distance the average individual in the zip code will need to travel to reach the amenity. It ignores population distribution within the zip code, as well as travel restrictions such as buildings and terrain to simplify computation. Despite these limitations, this distance is sufficient for our purposes.
Results
Mobility metrics
We characterize the mobility patterns of an area based on two representative quantities. The first metric is the average travel distance, or weighted average out-flow length, which is intended to capture the mobility-related costs that are directly proportional to travel distances. For each location i it can be computed as
where \(T_{ij}\) is the number of trips going from an area i to a different area j and \(d_{ij}\) is the geodesic distance between the centroid of the two areas. The second metric we consider is the total flow per capita originating from location i, computed as
where \(P_i\) is the population of location i. The city-level values are then computed by summing over all locations i within the city. The measure serves as a proxy for trip frequency which is a useful complement to trip distance, as it represents an activity rate. Activity patterns, which are connected to employment status38, combined with average distance traveled, indicate the distance and frequency of travel for residents in a given location. These factors are potentially influenced by the socioeconomic resources of the residents as well as their proximity to opportunities, and enables targeted ways of understanding the influence of city infrastructure and services on its residents.
We begin with a country-wide analysis of the mobility patterns of the lower and upper 20% of SA’s by median income. The choice of income range enables a first look at the trends for residents at the opposite end of the socioeconomic spectrum, that is those with the most and least potential constraints on their traveling behavior. In Fig. 2A,B, we plot the probability density functions for \(M_i^{dist}\) and \(M_I^{freq}\) in the United States and in Fig. 2C,D for Brazil. In the US, we find that poor residents generally travel shorter distances but more often than the rich. Conversely, in Brazil, we see that mobility is dominated by the wealthier individuals, who travel more frequently and for longer distances, with the magnitude of separation in the mobility metrics between the different income groups being more pronounced in Brazil. However, for both countries, there is considerable width and overlap to the distributions, suggestive of a diversity in trends for individual cities. To check whether these observed features are due to biases in the data coverage based on income, in Fig. S3, we plot the mobility outflow as a function of the population for both income brackets in the two countries. We find a strong monotonic dependence, indicating that the flow provides equal representation of population irrespective of income. Indeed this is reflective of the fact that both over \(90\%\) of households in the United States and Brazil own mobile phones and both countries rank among the top five in terms of smartphone usage (https://www.pewresearch.org/global/2016/02/22/smartphone-ownership-and-internet-usage-continues-to-climb-in-emerging-economies/).

Distribution of mobility metrics. Equations (1) and (2) for the upper and lower 20% residents in terms of income. (A) In the United States, flows originating from low-income areas (red) tend to be of slightly shorter length compared to the ones from the high-income regions (blue). (B) The opposite trend exists for travel frequency suggesting that wealthier residents travel less as compared to their poorer counterparts. (C) Like in the United States, in Brazil, trips originating from low-income areas are significantly shorter in comparison with those from high-income zones. However, the discrepancy is more accentuated than in American cities. (D) Unlike the United States, the frequency of trips is also much higher for wealthier residents in Brazil.
Socio-mobility correlations

Correlation between income and mobility. For each income bracket (divided into eight buckets), Spearman correlation between the share of residents and the average travel distance, as well as average travel frequency for the United States (A,B) and Brazil (C,D). The colors indicate the level of correlation from dark-blue (− 1) to dark orange (+1).
Given the observed country-level signal between the mobility metrics at the opposite ends of the income scale, we next conduct a more granular analysis across all census-determined income breaks \(ID_{f}\), and at the level of individual cities. Given an income distribution of n income intervals, we construct for each urban area, n income distribution vectors \(\mathcal {I}\) of m positions each \(\mathcal {I}_{j_{1\ldots n}} = [f_{1}, f_{2},\ldots ,f_{m}]\), where m denotes the number of SAs in that city. Here, \(f_m\) is the probability that an individual within the income interval n lives in SA m. We compute the Spearman rank correlation coefficient between each \(\mathcal {I}_{j}\) and the vectors for \(M^{freq}\) and \(M^{dist}\) for all m. For the results reported here, \(n=8\) for the United States and \(n=9\) for Brazil as determined by the respective censuses.
In Fig. 3, we plot these correlations for both mobility metrics for all hundred cities. In the United States, we see two distinct correlation patterns for both mobility variables: cities with strong correlations (depicted as darker colors) or cities with weak correlations (lighter colors) across income brackets. For the lower-income brackets in cities like San Antonio and Sacramento there is a marked negative correlation with \(M^{dist}\) (Fig. 3A) and a positive correlation with \(M^{freq}\) (Fig. 3B), indicating that low income populations in those cities tend to travel over shorter distances but more frequently. Surprisingly, for these same cities, when we look at the high-income regions of the plot, we see an opposite relationship, with trips being longer (positive correlation with \(M^{dist}\)) and less frequent (negative correlation with \(M^{freq}\)), a pattern that is observed in many other cities. Conversely, the other remaining cities display little-to-no socio-mobility correlations. For example, in New York, Seattle, Chicago and Washington DC, the correlations are quite weak throughout the entire income range, indicating that income has little influence on how far or how frequently people travel.
The Brazilian cities, on the other hand display markedly distinct trends. While there are a few cities with relatively little correlations such as Caxias do Sul, Campinas and Blumenau, the majority of cities display high positive correlations across metrics and income ranges, with the strongest signal being in the middle-income range (Fig. 3C,D). Whereas in the US, we see a mix of positive and negative correlations, in Brazil the correlations are by and large positive, except for the lowest income bracket being anti-correlated with travel frequency in a number of cities. The trends indicate a distinct mobility advantage for those higher up in the income scale both in terms of travel distance and frequency.

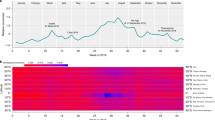
Clustering analyses of cities in United States. (A) Dendogram obtained from a divisive hierarchical clustering method to partition cities into two different groups color-coded in teal and orange. (B) Spearman correlation between eight income breaks (\(ID_{f}\)), and the average flow distance and out-strength per capita. (C) Fraction of the population using mass transit for each of the clusters. (D) Fraction of basic amenities accessible as a function of distance for 5 income breaks (\(ID_{q}\)) for each of the clusters.
City clusters
The results from Fig. 3 suggest a multiplicity of patterns in terms of the connection between mobility and income in both countries. In order to check if cities can be classified into distinct groups according to these trends, we implement a clustering method to partition the cities according to their socio-mobility correlation patterns. Using the Manhattan distance between the pairs of correlation values in each city, we perform a divisive hierarchical clustering45, finding a clear partition of the cities in the United States into two different groups, color-coded in teal and orange as shown in Fig. 4A. Some interesting trends are immediately apparent. The largest seven cities (\(\ge 5\hbox {M}\) inhabitants) are all in the orange cluster. On the other hand, the remaining cities are evenly distributed across both clusters, suggesting that population size is not a key factor in the observed partitioning (see Supplementary Section S4 for details on the clustering).
In Fig. 4B, we plot the correlations across the 8 income breaks, separately for each cluster. A clear distinction emerges, whereby the teal cluster exhibits both stronger positive and stronger negative correlations, with lower income brackets traveling shorter distances but more often than the wealthy. This is in stark contrast to the orange cluster, where income and mobility variables exhibit relatively flat correlations across all the income breaks. These cluster assignments, quantitatively confirm the trends seen in Fig. 3A, and suggests the existence of two different classes of cities in the United States; those where travel patterns are determined by income, and those which are broadly independent of socioeconomic characteristics.
We next investigate the factors behind this difference in correlations. A way to mitigate the disadvantages due to income is having efficient and cheap public transportation systems. In Fig. 4C, we plot the percentage of individuals that use public transit in either cluster (extracted from the census), finding that a larger fraction of residents in the orange cluster use mass transit methods compare to those residing in the teal one. We note from a previous analysis4, that those cities that are in the orange cluster tend to be more hierarchical and centralized in terms of mobility-flows as compared to those in the teal cluster that are sprawled and decentralized. Hierarchical cities have higher levels of infrastructure for public transit, and the observed higher usage of public transit is not just a behavioral feature but also reflects wider availability.
As mentioned earlier, another feature that might influence mobility patterns is the availability of amenities and services. Correspondingly, we check the typical distance residents of a particular location have to travel before they come across a number of basic amenities (food, healthcare, education and finance). For ease of display, instead of using all eight income breaks, we split the income groups into five categories (low, mid-low, mid, mid-high, high) and plot the fraction of amenities accessible up to 10km from the resident location (see Supplementary Section S1 for details on the income-breaks). Using this data we analyze the distances different income groups, \(ID_q\), would have to travel, in order to reach a certain percentage of basic amenities and plot our results in Fig. 4D. In the orange cluster, the accessibility of amenities is relatively stable across income groups, indicating that that in cities where low and high income groups move in similar ways, they tend to be at similar distances from basic amenities. This is either due to a more equitable distribution of resources, or the fact that both the wealthy and the less-so, tend to live in roughly the same areas. In contrast, within the teal cluster, we see an interesting trend, whereby, the distance traveled to reach the same fraction of amenities increases with income. In other words, the less wealthy live closer to basic amenities (at least in quantity, if not quality, a feature we investigate later), as compared to those with higher income. This is likely a reflection of the differences in urban organization between the orange and teal clusters, where in the latter, more sprawled configuration, lower income groups live in the inner-city (where a number of amenities are in close proximity), with the wealthier residents living in suburbs.
In order to check whether our results are broadly stable across multiple datasets of human mobility, we next conduct a similar analysis on publicly available commuting data from the United States census bureau’s LODES database46. Unlike the aggregate location history signals, this captures primarily work-home commuting trips. Nevertheless the aggregate mobility flows are strongly correlated with the LODES data up to around \(10^3\) commuters as seen in Fig. S5. Beyond this limit, the datasets diverge significantly indicating that the mobility data contains more information on non-commuting flows. With respect to the trends seen in Fig. 2, the commuting data is in qualitative agreement in terms of the average distance traveled, but differs in terms of the trip-frequency (Fig. S6). Here, there is little difference between the income groups in terms of how often they travel. The key reason here is the way that work-home commutes are calculated from the LODES database. Irrespective of how many times an individual commutes to work over the year, it is counted as a single instance of the flow. Thus apart from not capturing non-commuting flows, the LODES data is limited in terms of accurately reflecting the true number of trips made between locations.
With this in mind, we reproduce the clustering analysis conducted in Fig. 4 for the commuting data and plot the results in Fig. S7. The resulting clusters are shown in Fig. S7A and a comparison to the divisions in Fig. 4 yields a Fowlkes–Mallows index score of 0.847, indicating that the splits are by and large similar. Yet there are some notable differences; cities such as Portland, Seattle and Kansas City that were originally in the orange cluster are now found in the teal cluster. On the other hand, some cities in the teal cluster such as Detroit, Milwaukee and St. Louis move to the orange cluster. The correlation of the average distance traveled with \(ID_{f}\), mirrors that seen for Fig. 4 although the differences between the two clusters are less pronounced (Fig. S7B). On the other hand, the correlations with trip-frequency are markedly different, with the teal cluster now showing a flat trend, and the orange cluster showing a small positive trend with income. In terms of public transportation use in each cluster (Fig. S7C) the trends are the same, largely due to the fact that the major metropolitan areas with high prevalence of public-transit-usage remain in the orange cluster for both datasets. A similar pattern emerges in terms of the distance to amenities, split by \(ID_{q}\), with the orange cluster having little-to-no income dependence on amenity accessibility, whereas in the green cluster the higher income groups on average live further away from basic amenities (Fig. S7D). Subtle differences exist in terms of the precise fraction of amenities accessed between the two datasets. Thus the primary difference between the location and commuting data, is the weaker or lack of correlations with mobility metrics in the latter due to the lower resolution in trip-frequency. This results in the switching of some cities between the clusters (some rather misleading, as in putting Detroit and NYC in the same cluster as we will show later). The qualitative features extracted from both datasets, however, are the same attesting to the robustness of the analysis.

Diversity of urban amenities per median income quintile. Entropy of amenities in each of the sub-areas as a function of the median income in the United States (A) and Brazil (B). Entropy of amenities in each of the sub-areas as a function of the income in Detroit (C), a typical city of the teal cluster in the United States. Areas with higher median income tend also to have a higher diversity of amenities, a similar pattern seen for Rio de Janeiro (D) a typical city of the blue cluster in Brazil. In New York City, NY (E) (orange cluster), the trends are flat, and in Campinas (F) noisy, though higher-income areas on average, have higher amenity diversity.
Next, we analyze the cities in Brazil (Supplementary Figure S8A), resulting in two clusters of roughly the same size, color-coded yellow and blue. Unlike the more mixed patterns in the United States in terms of population size, nearly all the Brazilian cities in the blue cluster are the largest metropolitan areas and the capital cities of their respective states, with the exception of Lagos and Sao José dos Campos. Among the cities in the yellow cluster, the only state capital is Florianópolis. In Supplementary Fig. S8B, we plot the correlation of the mobility metrics with \(ID_{f}\) for each of the clusters, finding that the trends are quite different from that found in the United States. In both clusters there is an increase in correlation with the metrics as one goes up the the income ladder, with the strongest connection being in the middle income range. The correlations are always positive and stronger in magnitude than in the United States. In the yellow cluster while the lowest and highest income ranges travel similar distances, the wealthier travel much more frequently. In the blue cluster, the wealthy travel much longer distances and more frequently than the poor. Indeed, in both clusters the poor have similar movement patterns.
Public transit usage (Supplementary Fig. S8C) is moderately higher in the blue cluster (which also contains the largest cities in Brazil), but given the the similar trends seen for the mobility patterns for the lower income groups in both clusters, it does not play the same role as an equalizer as seen in the United States. In terms of access to the fraction of amenities, Supplementary Fig. S8D indicates that for both clusters, access is skewed to the higher income ranges, who have to travel less to access services as compared to the poor. The main difference between the two clusters is that residents in the blue group, have an even higher advantage for the wealthy as compared to the yellow cluster. Indeed, the Brazilian cities are similar to those in the teal cluster in the United States, the difference being that correlations with income are more pronounced, and the wealthy have an advantage in both flavors of mobility metrics.
Diversity of amenities
In the teal cluster for the United States, we found that the lower income groups were more proximate to basic services as compared to those in the higher income range. Note that this is a measure only of the number of such basic amenities and provides no information on the quality of such services. While defining quality is difficult and can be probably only be extracted from targeted surveys, a reasonable proxy is to measure the mix of amenities. Indeed, for instance, lower income residents in inner-cities may have access to a number of grocery stores, or corner-shops but may be lacking in financial or health-care services. To determine, this we examine the “diversity” of amenities for each each SA in the cities by measuring the entropy \(H_l ^a\) in each SA l (see Supplementary Section S6 for details of the calculation). Higher values of the entropy indicate a more homogenous distribution of the types of basic amenities, while lower values indicate that the distribution is dominated by a sub-type.

Socioeconomic in-flow heatmaps for selected cities in the US and Brazil. Colors represent the income level of the origin area that produced mobility flow into the plotted destination region. We see that cities such as Atlanta and Boston in the US experience considerable overlap between low and high income destinations, suggesting that income is not a defining factor in where people are able to live and go. In other cities like Detroit and Rochester, we see that the destinations of high and low income residents are relatively partitioned, suggesting that the particular land use decisions made in these cities have allowed lower income residents better access to amenities by living in the downtown areas. We see consistent separation between high and low income destinations in Brazil across all cities, suggesting that amenity access is generally shaped by residential location.
In Fig. 5A,B, we plot \(H_l ^a\) according to the income buckets \(ID_q\) at the country-level for the United States and Brazil. For the United States, the entropy is relatively flat across income, with a minor disadvantage for the lowest income bucket. In Brazil, on the other hand, a clear signal emerges, with a monotonically increasing trend of the entropy with income, indicating that the wealthy have access to a much wider mix of services as compare to the poor. This reinforces the advantage of the wealthy when coupled with the observation of closer access to a large fraction of total basic amenities as seen in Supplementary Fig. S8D. Even in the United States, the situation is more nuanced when we examine cities belonging to different clusters. In Fig. 5C, we plot the trend for Detroit, a representative city in the teal cluster, and in Fig. 5E, New York, an exemplar of the orange cluster. In Detroit we once again see a monotonic trend of \(H_l^a\) with \(ID_{q}\) indicating that while people of lower incomes are proximate to amenities in terms of their number, they have a distinct disadvantage with respect to the wealthy in terms of diversity of such services. In NY, on the other hand, the trend is flat, indicating that there is no income advantage when either accessing the number or type of amenities in the city. Thus similar to the mobility metrics, the primary difference between the the two clusters is the presence or absence of any correlation with income.
For the case of Brazil, Rio de Janeiro a city from the blue cluster also shows a wealth advantage (Fig. 5D) with a similar trend to Detroit, with a more pronounced difference between the lowest and highest income groups. Campinas (Fig. 5F) from the yellow cluster, shows more noisy trends, although even here there is a marked difference in the entropy between the lowest and highest income groups. The primary difference between the two clusters is that in one there is a clear monotonic trend, and in the other there is variability in the middle income range.
Spatial effects
Our analysis thus far has neglected any spatial effects, although the observed trends hint at differences in how cities are organized in terms of residences and their income distribution. For instance, we speculated that the difference between the orange and teal clusters in the United States are reflective of the differences in each city-type in how residences and amenities are spatially located. We next investigate whether such features indeed exist.
We begin by explicitly measuring the destinations of the upper 20% and lower 20% of SA’s in terms of median income. For each SA, we examine the in-flow and trace back to the origin of those flows to the income profile of the neighborhoods they originate from. For those regions where the in-flows are predominantly from low income areas, we color the region red, and for those where the origins are from high-income areas we color the region blue. In areas where there is an overlap of both flavors of flow, the regions are colored purple. In the left panel of Fig. 6 we show the results for four American cities, Detroit and Rochester from the teal cluster, and Atlanta and Boston from the orange cluster. For the latter cities, while there are regions exclusively visited by either high- or low-income groups, there are large areas of overlap particularly in the central parts of the city. Conversely, in both Rochester and Detroit, we see a more segregated profile, where there are two distinct regions of high- and low-income areas with relatively less overlap as compared to cities in the orange cluster. Additionally, as suspected from the results of our clustering analysis, the lower-income group tend to visit the city center, whereas the visits by higher-income groups are more concentrated in suburban areas. In the right panel of Fig. 6 we show the case for four Brazilian cities, with Brasilia and Campinas from the yellow cluster, and Sao Paolo and Rio de Janeiro from the blue cluster. In all four cities, there is a clear separation of regions visited in terms of income, with practically no overlap. Furthermore, unlike in the US, visits by the wealthy are overwhelmingly concentrated in the central part of the cities, with the poor by and large traversing the periphery. In terms of mixing of the income groups, there is little difference between the the two Brazilian clusters.

Income spatial autocorrelation. Ranking of Moran’s I values for cities in both the US (A) and Brazil (B) colored according to the cluster assigned. A high value (\(\sim 1\)) indicates that zip codes are grouped closely with zip codes of similar income, while a value close to 0 indicates a random arrangement. The average values for each cluster are shown as inset.
Where people visit in a city are reflective of the residential patterns. To determine how these are distributed, we next compute the spatial autocorrelation or Moran’s I \((I_M\)) of the SAs in each city in terms of the median income in that area (see Supplementary Information Section S7 for details of the calculation). The spatial autocorrelation lies in the range \(-1 \le I_M \le 1\), and is a measure for the similarity between the incomes of adjacent SAs. Its maximum value occurs for a perfectly segregated arrangement where all high- and low-income neighborhoods are adjacent only to each other, whereas the lowest values occur for a perfectly uniform distribution of incomes. A random arrangement with no spatial correlation yields values close to zero.
In Fig. 7A, we plot the results for the 50 cities in the United States, with each city colored according to the cluster it belongs to. As an inset we show the average values \(\langle I_M \rangle\) for each cluster. A very clear trend emerges where cities in the teal cluster have markedly higher values of \(\langle I_M \rangle\) than those in the orange cluster, indicating a more segregated profile of neighborhoods in terms of income. This serves as a quantitative confirmation for the different trends seen in each cluster in terms of their correlation with income and patterns of access to the number and diversity of amenities. For cities in the orange cluster, neighborhoods are organized in a more random fashion than the clustered ones in the teal cluster, and provides a possible explanation for the relatively more equitable access to basic services, the higher mixing in visitation patterns, and the general lack of correlations of mobility with income indicators. The comparatively more segregated residential patterns provide one possible causative mechanism for the trends seen in the teal cluster.
In Fig. 7B, we show the results for Brazil, once again finding a clear separation between the blue and yellow clusters, with the former having a larger value of \(\langle I_M\rangle\). While the differences in the connection between mobility and income is less pronounced between the two clusters, we recall that the blue cluster had higher correlations than the yellow one. The fact that cities in the blue cluster are more segregated, provides further evidence for residential patterns being a causative mechanism for the observed mobility patterns.
Limitations
These results should be interpreted in light of important limitations. First, the Google mobility data is limited to smartphone users who have opted in to Google’s Location History feature. These data may not be representative of the population as whole in all parts of the world, and their representativeness may vary by location. Importantly, these limited data are only viewed through the lens of differential privacy algorithms, specifically designed to protect user anonymity and obscure fine detail. Limitations also apply in terms of the data on amenities, given the nature of the source (based on voluntary reporting).
Discussion
Taken together our results shed greater clarity on the connection between socioeconomic features and movement patterns as compared to previous studies, given the scale of our investigation. A study of a hundred cities in two large countries comparable in size and population but differing in levels of economic development, revealed that cities can be broadly classified into two categories; those where resident’s movements are influenced by their income profile (with varying degrees of influence), and those where mobility is largely independent of their socioeconomic condition. This classification of course applies in an averaged sense, given the differences in cities both between and within the countries.
The two categories find their clearest manifestation in the United States, with a roughly even split between the 50 cities, that was uncovered with a clustering approach, with cities in the income-correlated cluster labeled teal and those in the weakly-correlated cluster, orange. The wider availability of public transportation in the orange cluster appears to be a feature that mitigates the correlation between income and movement, perhaps playing the role of an equalizing feature for those in the lower income brackets. Another key aspect is the availability and diversity of basic services. While lower-income residents in the teal cluster are on average closer to basic amenities, this appears to be a function of them living in the city-center, with the higher-income groups concentrated in suburbs. When it comes to the diversity of services available, there is a clear advantage to those in the higher-income bracket. These cities are also segregated by income, whereby high-income and low-income residents tend to be concentrated in specific areas. This is also manifested in the parts of the cities that they visit, with relatively little mixing between the income groups. Indeed, given the connection with income and race (Figs. S1, S2) this is also a reflection of racial segregation. By contrast, residents in cities belonging to the orange cluster have comparatively more equitable access to services in terms of both proximity and quality, and are less segregated in terms of both where they live and where they choose to visit.
In Brazil, we also find two categories, however unlike in the United States, movement in both clusters is correlated with socioeconomic features, with the difference being one cluster (blue) displays even stronger correlations then the other (yellow). While public transportation usage is comparable across cities, the accessibility to services in terms of proximity and quality is strongly skewed towards the highest income brackets in the blue cluster, although the income advantage is also found to a lesser extent in the yellow cluster. Additionally cities in the blue cluster have a more segregated residential profile than those in the yellow one. Both clusters, however display, a sharp divide between rich and poor in terms of which parts of the city is visited, with the rich being concentrated in the city-center and the poor primarily moving in the periphery. In some sense, the Brazilian cities mirror the teal cluster from the United States, with stronger differences in mobility in terms of the socioeconomic characteristics.
To validate our results, we also conducted our analysis on a different dataset; the commuting patterns extracted from the United States census. The qualitative results are essentially identical, with some differences in the clustering of the cities, stemming from the fact that the census does not accurately capture the frequency of travel. This resulted in a few cities changing clusters, but by and large the differences in terms of transportation usage, accessibility of services and residential segregation were preserved, attesting to the robustness of our analysis. A similar analysis could not be conducted for Brazil given that such data is not available in that country’s census. This points to another strength of this new approach: its applicability globally by leveraging aggregate signals such as mobility that are inexpensive to compute and available in a timely fashion. Methods relying on traditional census data do not generalize to many regions where census is unavailable, unreliable, or considerably delayed in time.
To the extent that it is undesirable to have cities with residents whose ability to navigate and access resources is dependent on their socioeconomic status, public policy measures to mitigate this phenomenon are the need of the hour. While it is difficult to disentangle the causal mechanisms behind the observed disparities, investment in affordable and robust public transportation may enhance equality of access48, although the extent of its efficacy may vary from region to region, given the observed differences between the United States and Brazil. Certainly more efforts must be made in terms of improving the quality of services in low-income areas. Given that this disparity might arise from the residential patterns seen in both countries, inclusive zoning and incentives to foster mixed-income neighborhoods may well be an effective policy49, 50. Indeed, such initiatives have been tried in cities such as New York, Boston and Chicago, which all incidentally lie in the orange cluster.
Nevertheless, much remains to be uncovered, in particular whether the reported trends here exist in countries in different regions and varying degrees of economic development. Effective strategies and measures will also vary from region to region and more tailored studies would be required to identify the contextual causes of different socio-mobility profiles. We anticipate many more studies along this direction in the near future.
References
Department of Economic and Social Affairs, United Nations. The speed of urbanization around the world. Popul. Facts 20, 1–2 (2018).
Danan, G., Gerland, P., Pelletier, F. & Cohen, B. Risk of exposure and vulnerability to natural disasters at the city level: A global overview. United Nations Depart. Econ. Soc. Affairs 2, 1–40 (2015).
Ford, A. et al. A multi-scale urban integrated assessment framework for climate change studies: A flooding application. Comput. Environ. Urban Syst. 75, 229–243 (2019).
Bassolas, A. et al. Hierarchical organization of urban mobility and its connection with city livability. Nat. Commun. 10, 20 (2019).
Bischoff, K. & Reardon, S. F. Residential segregation by income, 1970–2009. Divers. Dispar. Am. Enters New Century 43, 20 (2014).
Massey, D. S. The age of extremes: Concentrated affluence and poverty in the twenty-first century. Demography 33, 395–412 (1996).
Brueckner, J., Thisse, J. & Zenou, Y. Why is downtown Paris so rich and Detroit so poor? An amenity based explanation. Eur. Econ. Rev. 43, 91–107 (1999).
Andersen, H. S. Excluded places: The interaction between segregation, urban decay and deprived neighbourhoods. Hous. Theory Soc. 19, 153–169 (2002).
Brueckner, J. K. & Rosenthal, S. S. Gentrification and neighborhood housing cycles: Will America’s future downtowns be rich?. Rev. Econ. Stat. 91, 725–743 (2009).
Killeen, D. & Caro, R. A. The Power Broker: Robert Moses and the Fall of New York (Knopf, 1975).
Ostendorf, W., Musterd, S. & De Vos, S. Social mix and the neighbourhood effect. Policy ambitions and empirical evidence. Hous. Stud. 16, 371–380 (2001).
Musterd, S. Segregation, urban space and the resurgent city. Urban Stud. 43, 1325–1340 (2006).
Eagle, N., Macy, M. & Claxton, R. Network diversity and economic development. Science 328, 1029–1031 (2010).
Lobmayer, P. & Wilkinson, R. G. Inequality, residential segregation by income, and mortality in us cities. J. Epidemiol. Community Health 56, 183–187 (2002).
Henderson, V. Urbanization in developing countries. World Bank Res. Observ. 17, 89–112 (2002).
Henderson, J. V. Cities and development. J. Region. Sci. 50, 515–540 (2010).
Gauvin, L., Vignes, A. & Nadal, J.-P. Modeling urban housing market dynamics: Can the socio-spatial segregation preserve some social diversity?. J. Econ. Dyn. Control 37, 1300–1321 (2013).
Bettencourt, LMa. The origins of scaling in cities. Science 340, 1438–41 (2013).
Pan, W., Ghoshal, G., Krumme, C., Cebrian, M. & Pentland, A. Urban characteristics attributable to density-driven tie formation. Nat. Commun. 4, 1961 (2013).
Youn, H. et al. Scaling and universality in urban economic diversification. J. R. Soc. Interface 13, 20150937 (2016).
Lee, M., Barbosa, H., Youn, H., Holme, P. & Ghoshal, G. Morphology of travel routes and the organization of cities. Nat. Commun. 8, 2229 (2017).
Kirkley, A., Barbosa, H., Barthelemy, M. & Ghoshal, G. From the betweenness centrality in street networks to structural invariants in random planar graphs. Nat. Commun. 9, 2501 (2018).
Barbosa, H. et al. Human mobility: Models and applications. Phys. Rep. 734, 1–74 (2018).
Yuan, J., Zheng, Y. & Xie, X. Discovering regions of different functions in a city using human mobility and POIs. Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining-KDD ’12 186 (2012). arxiv:1010.0436.
Zhan, X., Hasan, S., Ukkusuri, S. V. & Kamga, C. Urban link travel time estimation using large-scale taxi data with partial information. Transport. Res. Part C Emerg. Technol. 33, 37–49 (2013).
Lenormand, M. et al. Influence of sociodemographic characteristics on human mobility. Sci. Rep. 5, 10075 (2015).
Wang, W., Pan, L., Yuan, N., Zhang, S. & Liu, D. A comparative analysis of intra-city human mobility by taxi. Phys. A 420, 134–147 (2015).
Luo, F., Cao, G., Mulligan, K. & Li, X. Explore spatiotemporal and demographic characteristics of human mobility via twitter: A case study of chicago. Appl. Geogr. 70, 11–25 (2016).
Louail, T., Lenormand, M., Murillo Arias, J. & Ramasco, J. J. Crowdsourcing the Robin Hood effect in cities. Appl. Netw. Sci. 2, 11 (2017).
González, M. C., Hidalgo, C. A. & Barabási, A. L. Understanding individual human mobility patterns. Nature 453, 779–782 (2008) (arxiv:0806.1256).
Di Clemente, R. et al. Sequences of purchases in credit card data reveal lifestyles in urban populations. Nat. Commun. 9, 20 (2018).
Alessandretti, L., Sapiezynski, P., Lehmann, S. & Baronchelli, A. Multi-scale spatio-temporal analysis of human mobility. PLoS One 12, e0171686 (2017).
Xu, Y., Belyi, A., Bojic, I. & Ratti, C. Human mobility and socioeconomic status: Analysis of Singapore and Boston. Comput. Environ. Urban Syst. 72, 51–67 (2018).
Shelton, T., Poorthuis, A. & Zook, M. Social media and the city: Rethinking urban socio-spatial inequality using user-generated geographic information. Landsc. Urban Plan. 142, 198–211 (2015).
Frias-Martinez, V. & Virseda, J. On the relationship between socio-economic factors and cell phone usage. In Proceedings of the Fifth International Conference on Information and Communication Technologies and Development, 76–84 (ACM, 2012).
Lotero, L., Hurtado, R. G., Floría, L. M. & Gómez-Gardeñes, J. Rich do not rise early: Spatio-temporal patterns in the mobility networks of different socio-economic classes. R. Soc. Open Scie. 3, 150654 (2016).
Llorente, A., Garcia-Herranz, M., Cebrian, M. & Moro, E. Social media fingerprints of unemployment. PLoS One 10, e0128692 (2015).
Almaatouq, A., Prieto-Castrillo, F. & Pentland, A. Mobile Communication Signatures of Unemployment. In Encyclopedia of Library and Information Sciences, Third Edition, vol. 1, 4814–4819 (CRC Press, 2009). arxiv:9780201398298.
Pappalardo, L., Pedreschi, D., Smoreda, Z. & Giannotti, F. Using big data to study the link between human mobility and socio-economic development. Proceedings—2015 IEEE International Conference on Big Data, IEEE Big Data 2015 871–878 (2015).
Gabrielli, L. et al. An analytical framework to nowcast well-being using mobile phone data. Int. J. Data Sci. Anal. 2, 75–92 (2016).
Wilson, R. et al. Differentially private SQL with bounded user contribution (2020).
United States Census Bureau. 2016 5-year American community survey [s0601]. https://www.census.gov/programs-surveys/acs (2016).
Brazilian Institute of Geography and Statistics (IBGE). 2010 population census summary. http://ghdx.healthdata.org/record/brazil-demographic-census-2010 (2010).
Openstreetmap contributors. https://www.openstreetmap.org. Accessed 2019.
Guénoche, A., Hansen, P. & Jaumard, B. Efficient algorithms for divisive hierarchical clustering with the diameter criterion. J. Classif. 8, 5–30 (1991).
United States Census Bureau. Longitudinal employer-household dynamics. https://lehd.ces.census.gov/data/ (2016).
Fowlkes, E. B. & Mallows, C. L. A method for comparing two hierarchical clusterings. J. Am. Stat. Assoc. 78, 553–569 (1983).
Teunissen, T., Sarmiento, O., Zuidgeest, M. & Brussel, M. Mapping equality in access: The case of bogotá’s sustainable transportation initiatives. Int. J. Sustain. Transport. 9, 457–467 (2015).
Graves, E. M. The structuring of urban life in a mixed-income housing community. City Community 9, 109–131 (2010).
Joseph, M. & Chaskin, R. Living in a mixed-income development: Resident perceptions of the benefits and disadvantages of two developments in chicago. Urban Stud. 47, 2347–2366 (2010).
Author information
Authors and Affiliations
Contributions
H.B., G.G. and S.H. designed the research. H.B., S.H. and B.D. did the statistical analysis. A.F., A.S., A.B., H.K., J.J.R. and G.G. analyzed the results. All authors wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Barbosa, H., Hazarie, S., Dickinson, B. et al. Uncovering the socioeconomic facets of human mobility. Sci Rep 11, 8616 (2021). https://doi.org/10.1038/s41598-021-87407-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-87407-4
This article is cited by
-
Infrequent activities predict economic outcomes in major American cities
Nature Cities (2024)
-
Future directions in human mobility science
Nature Computational Science (2023)
-
Unveiling the paths of COVID-19 in a large city based on public transportation data
Scientific Reports (2023)
-
COVID-19 is linked to changes in the time–space dimension of human mobility
Nature Human Behaviour (2023)
-
Disparities in expected driving time to opioid treatment and treatment completion: findings from an exploratory study
BMC Health Services Research (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
