
Abstract
A novel predictive modeling framework for the spread of infectious diseases using high-dimensional partial differential equations is developed and implemented. A scalar function representing the infected population is defined on a high-dimensional space and its evolution over all the directions is described by a population balance equation (PBE). New infections are introduced among the susceptible population from a non-quarantined infected population based on their interaction, adherence to distancing norms, hygiene levels and any other societal interventions. Moreover, recovery, death, immunity and all aforementioned parameters are modeled on the high-dimensional space. To epitomize the capabilities and features of the above framework, prognostic estimates of Covid-19 spread using a six-dimensional (time, 2D space, infection severity, duration of infection, and population age) PBE is presented. Further, scenario analysis for different policy interventions and population behavior is presented, throwing more insights into the spatio-temporal spread of infections across duration of disease, infection severity and age of the population. These insights could be used for science-informed policy planning.
Similar content being viewed by others
Introduction
Epidemic modeling and forecasting has gained renewed interest since late 2019 when the world was affected by the novel coronavirus pandemic (named Covid-19). Several computational studies to predict the human-to-human spread of Covid-19 have been reported1,2,3,4,5,6,7. Most of these efforts have been based on compartmental models and stochastic models (including agent-based models)8. In compartmental models (e.g., SIR, SEIR, SEIRS, DELPHI8,9), the population is divided into different compartments and the dynamics of the different compartments are modeled by a system of coupled ordinary differential equations (ODE). Here, the interaction among compartments is usually deterministic, whereas random processes are used to model the spread of infections in stochastic models. Very recently, the ODE-based compartment models have been extended to incorporate spatial dynamics using Partial Differential Equations (PDEs) that describe the evolution of each compartment10. Agent-based models are stochastic models that undertake a bottom-up approach of modeling individual members of a population and the dynamics of their interaction in terms of probabilities of movement and contact.
More than the total number of infections, it is essential to have more insightful predictions, e.g., infected population distribution across their age and level of infection severity for science-informed policy intervention and public health planning. The population distribution over the duration of infection is crucial for planing antiviral treatments, quarantine, ventilator support and contact tracing. This requirement necessitates a comprehensive and computationally efficient predictive modeling framework. Even though these features could be incorporated in ODE-based compartmental and stochastic agent-based models, it is very complex and computationally expensive. To overcome these challenges, we propose a novel partial differential equation-based spatio-temporal predictive modeling framework for forecasting the spread of infectious disease in heterogeneous populations in open geographies. The roots for our model lie in the population balance equations that are popular in chemical engineering and process studies11.
In the proposed model, the infected population density is defined as a scalar field on a high-dimensional space. Specifically for predicting the spread of Covid-19, a six-dimensional model is presented. The first three dimensions are the space and time, and the other three are the infection severity, duration of the infection (i.e., time since infection), and age of the population. New infections, impact of quarantine, testing, contact tracing, immunity, intervention policy impact, health infrastructure, recovery, and death are all modeled on this six-dimensional space based on data-driven functions (where available), and/or simple algebraic and integral functions. Notably, our PDE-based model in the present paper is more compact and a versatile description of the spread of the disease compared to compartmental models, and computationally efficient compared to agent-based models. To showcase the capability of our distribution-based predictive modeling framework for infectious disease spread, we apply it to model and predict the spread of Covid-19 in India. Further, we present a scenario analysis, which could be used to draw insights for policy interventions.
Results
The population balance model
Let \(T_\infty\) be a given final time and \(\Omega :=\Omega _x\otimes \Omega _\ell\) be the computational domain of interest. Here, \(\Omega _x\subset {\mathbb {R}}^2\) is the spatial domain defining the geographical region of interest and \(\Omega _\ell \subset {\mathbb {R}}^n\), where n is the number of internal directions. Each of the n-internal directions represents the property of the population on which a distribution needs to be predicted. Suppose the properties of interest are the infection severity, duration of the infection and age of the population, then a model with three internal directions could be used as follows. Let \(\Omega _\ell :=L_v\times L_d\times L_a\) be the internal domain, where \(L_v=[0, 1]\) denotes the infection severity interval, \(L_d=[0,d_{\infty }]\) denotes the duration of infection, \(d_{\infty }\) is the maximum duration of infection, \(L_a=[0, a_{\infty }]\) denotes the age interval and \(a_{\infty }\) is the maximum age of the population. The infection index \(\ell _v\in L_v\) quantifies the severity of the infection among the infected population. Specifically, the population with infection index \(\ell _v=0\) is completely disease-free, with \(\ell _v = 1\) has maximum severity, with \(\ell _v\ge v_{\text {sym}}\) shows symptoms and those with \(\ell _v<v_{\text {sym}}\) are asymptomatic. The duration of infection index \(\ell _d\in L_d\) quantifies the time since a population has been exposed to and contracted the disease. Specifically, the population that just contracted the disease has \(\ell _d=0\). Typically, a person is asymptomatic until they reach \(\ell _v=v_{\text {sym}}\), and the duration elapsed \(\ell _d\) is the incubation period in which the disease is sub-clinical and that population is actively spreading the disease. After recovery, a population doesn’t necessarily go to \(\ell _v=0\), rather they reach \(\ell _v<v_{\text {r}eco}\).
Let \(I(t,{\mathbf{x}},{{\ell }})\), where \(t\in (0,T_\infty ],~ {\mathbf{x}}\in \Omega _x\) and \({{\ell }}\in \Omega _\ell\), be the infected number density function of the population. To describe the evolution of the active infected population size distribution, we propose the population balance equation
Here, \({\mathbf{u}}\) denotes the advection vector that quantifies the multiscale spatial movement of the population in a differential neighbourhood of \(\Omega _{x}\) (e.g., migrant laborers, daily commute for work, logistics-related travel, periodic gathering for religious and social events), \({\mathbf{n}}\) is the outward unit normal vector to \(\Omega _x\), \(\partial {\Omega }^{-}:= \{{\mathbf{x}}\in \partial {\Omega _{x}} \ |~ {\mathbf{u}}\cdot {\mathbf{n}}<0 \ \}\), \(g_n\) is the flux that quantifies the net addition of the infected population into \(\Omega _{\text {x}}\) from outside (the spatial movement of the population across the border of the domain \(\partial \Omega _{\text {x}}\)), and \(I_0\) is the initial distribution of the infected population. Further, \({\mathbf{G}} = (G_{\ell _v}, G_{\ell _d}, G_{\ell _a})^T\) is the internal growth vector, where
Here, \(\beta\) is the immunity of the infected population, \(\gamma\) is the pre-medical history of the infected population and \(\alpha\) is the effective treatment index. Next, we define the rate term \(C = C_R + C_{ID},\) where \(C_R(t,{\mathbf{x}},{{\ell }})\) is a recovery rate function that quantifies the rate of recovery of the population from the infection, and \(C_{ID}(t,{\mathbf{x}},{{\ell }})\) is the infectious death rate. We also define a source term \(F = C_T(t,{\mathbf{x}},{{\ell }})\) that quantifies the point-to-point movement of infected population (e.g., by air, train etc) within \(\Omega _x\), which are not included in \({\mathbf{u}}\) and \(g_n\). Moreover, \(C_T\) and \({\mathbf{u}}\) need to be defined in such a way that the net internal movement of infected population within \(\Omega _{x}\) is conserved. Moreover, \(B_{\text {n}uc}\) is the nucleation function that quantifies the infection transmission from the infected to the susceptible population and it is a function of several parameters as follows
Here \({\mathbf{X}} \in \Omega\), \(\sigma , H\) and \(S_D\) are the interactivity, hygiene and social distancing indices respectively. Finally, the total population N(t) at a given time \(t\in (0,T_\infty ]\) is defined by
Here, \(N_S\), \(N_B\), \(N_R\), \(N_I\), \(N_Q\) \(N_{ID}\) and \(N_D\) are the number of susceptible, newborn, recovered, infected (symptomatic/asymptomatic), quarantined, infectious death and natural death populations, respectively. The given initial and boundary conditions and the above defined parameters close the population balance system.
Modeling of parameters
The proposed population balance model (1) is comprehensive and built on the basis of several parameters as defined above. This framework is very versatile and provides us the means to incorporate the effects of different parameters that describe the complex infectious disease spread dynamics into a singe PDE. Fitting these parameters accurately using either data-driven approaches10 or appropriate assumptions from literature makes the model very robust. In this section, we describe the modeling of each parameter.
Nucleation term
The nucleation term \(B_{\text {n}uc}\) quantifies the new infection number density that is added to the system at \(\ell _d=0\) for all t, \({\mathbf{x}}\), \(\ell _v\), and \(\ell _a\). Depending on how the susceptible population interacts with the infected population, new infections are added to the system. We call this addition as nucleation (borrowing the terminology from process engineering), which is modelled as
Here, \(\gamma _Q\in [0,1]\) in (3) determines the fraction of the infected population in quarantine and it can be modeled as in equation (5). Further, the factor \(\gamma _Q\) is dependent on the level of screening including testing, strictness of enforcing isolation and compliance of susceptible general public. Suppose \(\gamma _Q = 1\), i.e., if the entire infected population is kept under strict isolation, newly infected population will be zero and eventually there will be no spread of disease. However, due to economic, social and democratic reasons, implementing such a strategy is nearly impossible and there is bound to be spread, i.e., \(\gamma _Q<1\). Moreover, the integral on the right-hand side of equation (3) is the total non-quarantined number density of the infected population at \((t,{\mathbf{x}})\), and R is the rate at which the non-quarantined population infects the susceptible population. The factor R is modelled as in equation (4), where \(R_0\) is the basic reproduction rate,
Here, the interactivity index \(\sigma \in [0,1]\), hygiene index \(H\in [0,1]\), and social distancing index \(S_D\in [0,1]\). Suppose \(\sigma =0\) then everything is under perfect lockdown and \(R \rightarrow 0\). In case \(S_D=1\), everyone is following perfect social distancing and \(R \rightarrow 0\). Moreover, the newly infected population has to be added at different age (\(\ell _a\)) and infection \((\ell _v)\) levels for which the factors \(f_4\) and \(f_5\) are introduced. We propose to use logistic functions fitted to data from literature for \(f_1,~f_2,~f_3\); the normalized demography at \((t,{\mathbf{x}})\) for \(f_4(t,{\mathbf{x}},\ell _a)\), and a Gaussian mixture with two components so that maxima is at \(v_{\text {sym}}\) and tails are proportional to the interval length over \([0,v_{\text {sym}}]\) and \([v_{\text {sym}},1]\) for \(f_5(\ell _v)\). In addition, the constant in \(f_5\) is chosen such that the integral of \(f_5\) over its support is one. This condition is imposed to ensure that \(R_0\) can be interpreted as the basic reproduction rate used in standard epidemiological models12. The parameters \(v_{\text {sym}}\), \(d_{\text {sym}}\), \(a_{\text {r}isk}\), \(b_v\), \(b_d\), \(b_a\), \(b_{\sigma }\), \(b_H\), \(b_{S_D}\), \(\sigma _c\), \(H_c\), \(S_{D_c}\) can be estimated from experimental and clinical evidence. Furthermore, in light of new evidence, the functional forms of \(f_1\) to \(f_5\) can easily be modified. Finally, \(\sigma (t)\), \(S_D(t)\) and H(t) change over time due to increased awareness, government measures and compliance by people.
Growth factor
The growth factor \(G_{\ell _v}\) quantifies how the infected number density is advected along the direction of \(l_v\), that is, how the infection becomes mild to severe/critical and vice-versa in the infected population. We can model it as a function of the medical history, immunity of the population, which in turn are functions of the age \(l_a\), treatment and socio-economic status. Nevertheless, as a simple first order model, we propose a nonlinear function of the age,
where \(K_g\) is a non-dimensionalization factor, p is a power of nonlinearity and \(a_{\text {r}isk}\) is the age offset.
Recovery rate and infectious death rate
In general, the recovery rate \(C_R\) and infectious death rate \(C_{ID}\) depend on \(\ell _v\), and in turn are functions of hospital facilities, age, and health state of the population. These rates can be modeled directly from clinical data for all ordinates \(\ell _v,~\ell _d,~\ell _a\). For the exact functional forms refer to the Supplementary Information.
Initial infection number density
The initial number density \(I_0({\mathbf{x}},{{\ell }})\) can be estimated directly from available official data on the day of starting the simulation. However, the data is available only in terms of total number of tested and confirmed cases at a \({\mathbf{x}}\)-location and the dependence on \({{\ell }}\) needs to be estimated via appropriate data-driven and analytical functions. As such, first we utilize data from a period of 14 days, along with the log-normal distribution of incubation period13 to calculate the initial number density \(N_D({\mathbf{x}})\) at all the spatial points \({\mathbf{x}}\), but integrated over the three internal ordinates (\(\ell _v,\ell _d,\ell _a\)), i.e.,
where \(N_i({\mathbf{x}})\) is the data of tested and positive. For the distribution along the internal ordinates, we propose to use the following initial infection number density distribution
Here the first term in the square brackets is the normalized demography function (same as \(f_4\)), second term is the log-normal incubation period function with fitted13 \(a_2=0.42\) and \(b_2=1.62\), and \(f_5\) is same as before.
Covid-19 epidemic spread predictions
To exhibit the capabilities of the proposed model, the forecast of Covid-19 spread in India is presented here. The numerical scheme and the fitted model parameters are given in the Supplementary Information. The proposed model and numerical schemes are implemented in our in-house finite element package14,15 and have been verified in our earlier studies with applications to process engineering16,17.
With the spread of Covid-19 in India, the federal government imposed a nation-wide lockdown from March 25, 2020. To simulate the spread of infections starting from March 23, 2020, the initial distribution of infected population is estimated using the data of active cases from March 23 to April 5 according to equations (7) and (8). Then the infection spread forecast for one year is computed by solving the PBE system (1). Further, data until June 21, 2020 is utilized to select the parameters (e.g., \(S_D\), \(C_R\), \(C_{ID}\), \(\gamma _Q\)) that best explains the actual data. Thereafter, the control parameter \(S_D\) is varied to perform scenario analyses as presented next.
Scenario analysis
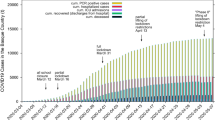
Different future scenarios are predicted by varying \(S_D(t)\) based on the anticipated individual behavior (social distancing, hygiene practice, compliance to government rules etc.) and government policies (quarantine rules, lockdown rules etc.). The first scenario, named Current Trend follows business as usual assuming further relaxation to lockdown rules. A second variant named Better Scenario assumes better compliance in the social distancing and other measures to control the spread of the disease. Sunday, and Sunday & Wednesday lockdowns are imposed on the Current Trend scenario to formulate the third and fourth scenarios respectively. These lockdown scenarios are introduced to measure the impact of periodic lockdowns on the effectiveness of these strategies to control the disease spread. The active (\(N_I\)), recovered (cumulative \(N_{R}\)), deaths (cumulative \(N_{ID}\)) and total (sum of active, recovered and deaths) predicted by the four scenarios for the duration between March 23, 2020 and March 22, 2021 are shown as time-series plots in Fig. 1. In the Current Trend, a peak of 0.975 million ‘Active Cases’ is predicted in the last week of October 2020, and there will be around 21 million ‘Active Cases’, 450,000 deaths and 9.1 million total cases at the end of March 2021. The peak of the Better Scenario is predicted in the second week of September 2020 with 0.478 million ’Active Cases’, which is lower than the Current Trend. Further, there will be around 14,200 ‘Active Cases’, 0.188 million deaths and 3.74 million total cases at the end of March 2021. The weekly lockdown scenarios assume that a complete lockdown is imposed on Sunday or Sunday and Wednesday. During this lockdown, there is a complete restriction of people’s movement similar to the nationwide lockdown imposed between Mar 25 and April 14 in India. With Sunday Lockdown, a peak of 0.365 million ‘Active Cases’ is sustained for about two weeks during 5–20 September 2020, and there will be around 30,200 thousand ‘Active Cases’, 0.167 million deaths and 3.32 million total cases at the end of March 2021. With Sunday and Wednesday lockdown, a peak of 0.197 million ‘Active Cases’ is sustained for the period 27 June to 15 July 2020, and there will around 2800 ‘Active Cases’, 70,300 deaths and 1.39 million total cases at the end of March 2021. The insets in each panel of Fig. 1 show the comparison with actual data and thereby validate the model. In addition, the time series plots for other scenarios including a worse-case scenario can be found at IISc-Model website18.

Time series forecast of active, total infections, recovered and deceased cases of Covid-19 in India from Mar 23, 2020 to Mar 22, 2021. The inset shows a zoom with comparison of the model forecast with the data until July 14, 2020.
A key insight needed for the central government in India was to identify which states needed additional assistance in containing the spread of the virus. For this purpose, we first fit the parameters of the model to match the reported national data. Thereafter, the estimates are computed for individual states with the above tuned parameters. Figure 2 shows the actual data (until July 14, 2020) and the computed estimates for the states of Karnataka (KA) and Maharashtra (MH). The data of KA follows the computed estimate closely, whereas the actual data indicates more infections and active cases in MH than the estimate. This observation indicates that MH needs further assistance than KA (as of July 14, 2020) to contain covid-19 spread. Such insights can be used by the authorities to introduce state-wise lockdown policies and to plan infrastructure for quarantine, treatments etc. The estimates computed with the above tuned parameters for other states (as of July 14, 2020) can be seen at our IISc-Model website18. Further, to capture the recent dynamics of the spread in the individual states following the graded re-opening of the economy, we have re-started the simulation with the updated initial condition on Aug 1, 2020. These updated predictions can also be seen at our website18.

The actual data of KA (green) and MH (red), until July 14, 2020 compared to the estimates computed with the parameters fitted for the reported national data.
Population distribution
Our PBE model in fact predicts the distribution of the infected population over all the internal ordinates \(\ell _v,~\ell _d,~\ell _a\). In the previous section, we have shown only the total number of infected, recovered and deceased populations. Now, to showcase one of the unique features of the model, we present and discuss the predicted population distribution for the Sunday lockdown scenario.

Distributions of active Covid-19 population along the internal ordinates at different time instances. The population has been integrated over \(\Omega _x\).

Distributions of recovered Covid-19 population along the internal ordinates at different time instances. The population has been integrated over \(\Omega _x\).
Figure 3 shows the predicted distribution of active Covid-19 infected population over the ordinates \(\ell _v\), \(\ell _d\) and \(\ell _a\) at different time instances (day 60, 120, 180, 240, 300 and 365) with their corresponding dates.
Predicting the severity of the infected population is crucial to plan the hospital requirements including antiviral treatments, quarantine, hospitalisation, ventilator support, and oxygen support. In particular, the information of asymptomatic and symptomatic infected population helps the policymakers to plan quarantine rules. Moreover, the death rate is a function of the severity of infection and is crucial to predict the causalities arising from the infection spread. The duration of infection plays a key role in epidemic modeling. Classical models usually assume a constant duration. However, the recovery and the death of the patient depend on the immunity, age and health of the patient, medical treatments etc and thus the duration of infection need not be a constant. In the proposed model, the duration of infection is considered as an independent internal ordinate. The recovered population distribution over the duration of infection and other internal ordinates for days 60, 120, 180, 240, 300 and 365 is shown in Fig. 4 along with their corresponding dates. Crucially, the predicted distribution with duration of infection, especially at initial stages, is key to plan for testing and to make effective decisions on quarantine, hospitalization and discharging from hospitals. Finally, the age of the population is pivotal in epidemics like Covid-19 since it affects children and aged population severely. Therefore, it is incorporated into the proposed model as another independent ordinate. In fact, the newly infected population is added from the susceptible population across the age distribution through the nucleation term. Moreover, the response to the antiviral treatment, death and recovery rates depend on age-specific health complications such as diabetics, cardiovascular disease, can also be incorporated in the PBE model with appropriate functions that depend on the age of the population.
Discussion
Our spatio-temporal modeling framework is the first comprehensive partial differential equation model for predicting infectious disease spread. Computationally, our model is efficient compared to agent-based stochastic models. Mathematically, our PDE system is more compact and comprehensive compared to ODE-based compartmental models. Specifically, the PDE is a continuum description of the infected population whereas the compartmental models are a discrete representation. Crucially, in contrast to the existing models, our model provides an insight into the distribution of infected population (presented in previous sections). This information is important to plan policy interventions, especially in Covid-19 like pandemics. Not only prognostic estimates, but also diagnostic estimates for more detailed analysis using distribution can be performed with the proposed framework.
With more data and employing data-driven and machine learning approaches, we could further refine the parameters and functional forms of different model components to derive more insightful predictions. For example, to derive insights into the reopening of the workplace and educational institutions, the nucleation and advection vector could be modeled to account for interactions between different age groups and movement of people between homes and these places. The potential options for refining the model are virtually endless. In particular, there is no restriction on the choice of number of internal coordinates. For example, in addition to \(\ell _v, \ell _d, \ell _a\), profession, mobility history, etc can also be added as internal coordinates.
Even though we have emphasized Covid-19 pandemic in the present paper, the proposed model can readily be used for forecasting any other infectious disease spread. In future, a data assimilative framework for a real-time update of forecasts can also be implemented.
References
Singh, R. & Adhikari, R. Age-structured impact of social distancing on the Covid-19 epidemic in India. Preprint at arXiv:2003.12055 (2020).
Harsha, P. et al. COVID-19 Epidemic Study II: Phased Emergence From the Lockdown in Mumbai. Preprint at arXiv:2006.03375 (2020).
Pandey, G., Chaudhary, P., Gupta, R. & Pal, S. SEIR and Regression Model based COVID-19 outbreak predictions in India. Preprint at arXiv:2004.00958 (2020).
Ranjan, R. Predictions for COVID-19 outbreak in India using Epidemiological models. Preprint at https://doi.org/10.1101/2020.04.02.20051466 (2020).
Bouchnita, A. & Jebrane, A. A hybrid multi-scale model of COVID-19 transmission dynamics to assess the potential of non-pharmaceutical interventions. Chaos Solitons Fractals 138, 109941 (2020).
Gharakhanlou, N. M. & Hooshangi, N. Spatio-temporal simulation of the novel coronavirus (Covid-19) outbreak using the agent-based modeling approach (case study: Urmia, Iran). Inform. Med. Unlocked 20, 100403 (2020).
Wang, H. & Yamamoto, N. Using a partial differential equation with google mobility data to predict COVID-19 in Arizona. Math. Biosci. Eng. 17, 4891–4904. https://doi.org/10.3934/mbe.2020266 (2020).
Vynnycky, E. & White, R. An introduction to infectious disease modelling (OUP, Oxford, 2010).
Bertsimas, et. al. Covid Analaytics Website. https://www.covidanalytics.io/home. Accessed on June 10 (2020).
Jha, P. K., Cao, L. & Oden, J. T. Bayesian-based predictions of Covid-19 evolution in Texas using multispecies mixture-theoretic continuum models. Comput. Mech.https://doi.org/10.1007/s00466-020-01889-z (2020).
Ramkrishna, D. & Mahoney, A. W. Population balance modeling. Promise for the future. Chem. Eng. Sci. 57, 595–606 (2002).
Grassly, N. C. & Fraser, C. Mathematical models of infectious disease transmission. Nat. Rev. Microbiol. 6, 477–487 (2008).
Lauer, S. A. et al. The incubation period of coronavirus disease 2019 (Covid-19) from publicly reported confirmed cases: estimation and application. Ann. Intern. Med. 172, 577–582 (2020).
Ganesan, S. et al. An object oriented parallel finite element scheme for computations of pdes: Design and implementation. In 2016 IEEE 23rd International Conference on High Performance Computing Workshops (HiPCW), pp. 2–11, https://doi.org/10.1109/HiPCW.2016.023 (2016).
Wilbrandt, U. et al. ParMooN—a modernized program package based on mapped finite elements. Comput. Math. Appl. 74, 74–88 (2016).
Ganesan, S. & Tobiska, L. Operator-splitting finite element algorithms for computations of high-dimensional parabolic problems. Appl. Math. Comput. 219, 6182–6196 (2013).
Ganesan, S. An operator-splitting Galerkin/SUPG finite element method for population balance equations: stability and convergence. ESAIM: M2AN 46, 1447–1465 (2012).
Ganesan, S. & Subramani, D. IISc-Model Website. https://cmg.cds.iisc.ac.in/covid/. Accessed on October 1 (2020).
Acknowledgements
DS acknowledges the partial support from IISc Start-up grant, DST-INSPIRE Faculty Research Grant (04/2018/003591), and Arcot Ramachandran Young Investigator Award. S.G. acknowledges the support from SERB (MTR/2017/000898) and DRDO (NRB-368/HYD/15-16) for the grants that supported development of ParMooN.
Author information
Authors and Affiliations
Contributions
S.G. and D.S. contributed equally and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ganesan, S., Subramani, D. Spatio-temporal predictive modeling framework for infectious disease spread. Sci Rep 11, 6741 (2021). https://doi.org/10.1038/s41598-021-86084-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-86084-7
This article is cited by
-
Identification of Early Warning Signals of Infectious Diseases in Hospitals by Integrating Clinical Treatment and Disease Prevention
Current Medical Science (2024)
-
Scaling of agent-based models to evaluate transmission risks of infectious diseases
Scientific Reports (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
