
Abstract
Neural activity research has recently gained significant attention due to its association with sensory information and behavior control. However, the current methods of brain activity sensing require expensive equipment and physical contact with the tested subject. We propose a novel photonic-based method for remote detection of human senses. Physiological processes associated with hemodynamic activity due to activation of the cerebral cortex affected by different senses have been detected by remote monitoring of nano‐vibrations generated by the transient blood flow to the specific regions of the human brain. We have found that a combination of defocused, self‐interference random speckle patterns with a spatiotemporal analysis, using Deep Neural Network, allows associating between the activated sense and the seemingly random speckle patterns.
Similar content being viewed by others


Introduction
With its connection to sensory information and behavior control, neural activity research has recently received considerable attention. However, the current methods of brain activity sensing, involve expensive equipment and require physical proximity with the subject. Sensation is a physiological process involving sensory systems of a body responding to a stimuli and providing data for perception1. Human sensory systems are involved in daily activities, both consciously and unconsciously, and a study of the senses, especially their connection with brain activity, has been gaining in popularity in recent years. Brain activity analysis using electroencephalography (EEG) has received considerable attention2,3,4,5,6, particularly in relation to the five basic human senses: sight2, touch7, hearing8,9, smell10,11,12,13 and taste14. In addition to EEG, a number of optical techniques have also been employed for monitoring the human brain activity using image contrast analysis15,16 and cross-correlation based analysis of a laser speckle imaging17. While these methods mainly deal with a laser speckle image and its relation to temporal fluctuations, extracting semantic information from sensory activity is still lacking.
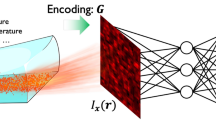
The temple area of the human head is located in front of the cerebral cortex and is not an optical quality surface. Therefore, when a rough surface is illuminated by a laser beam, the back scattered light forms secondary speckle patterns, which are possible to image clearly by a digital camera with defocused optics. Analysis of temporal changes in the spatial distribution of the speckle patterns can be related to nano-vibrations of the illuminated surface due to the hemodynamic process associated with the transient flow of the blood occurring during human brain activation17.
The speckle-based remote sensing has been used for the development of different biomedical applications, such as monitoring of the heart rate18, breathing19, blood pressure20, blood oximetry21, blood coagulation22,23, bone fractures24, melanoma25, and neural activity17. Prior methods for classifying speckle patterns used a single frame26 or full video frame-by-frame21 data obtained by averaging the model predictions on all frames of the video and providing a threshold for selecting the desired output. The prior classification methods used a Convolutional Neural Network (CNN) to encode data from a single frame. However, speckle pattern data recorded over successive periods could be characterized as time series data27. Due to this temporal dependency, we hypothesize that using a recurrent neural network architecture would provide improved results.
We propose a new method for classification and detection of three basic senses: smell, taste, and hearing. Detection of senses is based on projecting a laser beam on the specific area of the human head being associated with the cerebral cortex activity, (see Fig. 1) and analyzing the recorded speckle patterns using DNN. To ascertain reliability of our approach, the results were compared with a synchronized and simultaneously recorded EEG, known to be an effective method for detecting brain activity related to human senses2. We trained an EEG-based DNN using the recorded EEG data and compared it to the results of the speckle-based DNN to find out conformity between the two approaches.

Experimental setup, including laboratory equipment and headset, for synchronized recording of speckle patterns and EEG signal obtained from the cerebral cortex of the human brain. While participating in the data acquisition process the subject smells an alcohol-soaked cotton ball, while the camera EEG are synchronized and are simultaneously recording the data.
Our study could be of importance for patients suffering from stroke or cancer28,29,30,31 and experiencing irregularities in their basic senses, especially in taste and smell. The frequently occurring loss of taste and smell associated with COVID-19 is also noteworthy32,33. The olfactory neurons, which detect odors in the air and send signals to the brain, are one possible pathway for sensory loss34. Predicting sensory loss with relative simplicity and remotely can contribute to the discovery of COVID-19 virus carriers as well.
Results
The experimental setup, shown in Fig. 1, comprises a laser, illuminating the temple area of a human head, and defocused high-speed camera, recording the reflected speckle patterns, an EEG device synchronized with the camera and a computer for the data processing. Eight healthy participants ranging in age from 29 to 74 have been tested in the two conditions: without and under stimulation of each sense.
Figure 2 shows samples of the recorded speckle pattern for each sense in a consecutive timely related order from left to right. Figure 2a displays speckle patterns related to the sense of smell. Figure 2a1 represents the activated sense and Fig. 2a2 the inactive sense. Figure 2b displays the sense of taste: Fig. 2b1 represents the activated sense and Fig. 2b2 the inactive sense. Figure 2c displays the sense of hearing: Fig. 2c1 represents the activated sense and Fig. 2c2 the inactive sense.

Sample frames from the dataset. (a) sample frames of smell sense. (b) sample frames of hearing sense. (c) sample frames of taste sense. For each sense (1) is representing frames of an active sense while (2) represents an inactive sense.
Classification of the speckle patterns and its association to a specific brain activity was carried out using DNN. Results of our validation are given in Table 1, showing that our model achieved precision score of 92% and reached accuracy of 95%, while being faster and maintaining high recall of 98%. Table 1 also shows comparison of our model with the previous two methods for back scattered laser speckle patterns classification21,26 having accuracy of 82% and 89%.
Figure 3 presents the sensory recognition of our speckle based DNN for each subject and the average sensory recognition for each of the three senses, including value margins for all tested subjects. Figure 3a shows Speckle-based DNN predictions for the sense of smell, Fig. 3b—for the sense of hearing, and Fig. 3c—for the sense of taste. The blue columns in each figure represents the active sense predictions, while the orange columns—the inactive sense.

Speckle-based ML model sensory recognition for each subject and the average predictions for all participants for each of the three senses, including value margins for all tested subjects. Prediction details: First subject—male, age 29; Second subject—male, age 55; Third subject—male, age 74; Fourth subject—female, age 25; Fifth subject—male, age 49; Sixth subject—female, age 35; Seventh subject—male, age 50; Eight subject—male, age 55. The senses of smell (a), hearing (b), and taste (c) are all represented by Speckle-based DNN predictions. While the corresponding sense was active, the blue columns in each of the figures represents model predictions, while the orange columns represents model predictions when the sense was inactive.
The main benchmark according to which the results of our model are is verifiable is the sensing model based on the EEG input. Figure 4 shows our speckle-based model and the EEG model predictions for one tested subject. The speckle based and the EEG inputs were recorded simultaneously during 10 s period while the sense of smell was active. The speckle-based model predicted 120 input batches, each containing 64 frames recorded under 750 frames per second (FPS). In order to compare the EEG and the speckle-based model predictions, the percentage of matching values in the sample shown in Fig. 4was calculated. For the presented sample, the matching value is 92%, indicating that matching of EEG and our optical model are significant and high. For other tested participants the models matching value was in the range of 92–97%. Table 2 shows that the EEG-based DNN achieved an accuracy of 83% while maintaining a recall of 100% and precision of 75% in active-sense classification task.

Comparison between the optical and EEG ML sense activity predictions. The predictions are based on simultaneous 10 s speckle and EEG inputs for one of the subjects while the sense of smell was active. The X-axis represents the time, and the binary EEG and speckle-based models’ predictions are shown on the Y-axis (0 when the sense is inactive and 1 when the sense is active).
Discussion
The current methods for sensing human brain activity, such as EEG and MRI, require significant resources , expensive equipment and close proximity or physical contact with a patient. We propose a new photonic-based remote monitoring method for detection of human senses by combining a deep learning approach with spatiotemporal analysis of defocused self-interference random speckle patterns reflected from the specific temple area of the human head. This work provides further evidence for the hypothesis that physiological processes associated with the hemodynamic activity of the brain due to stimulation of the cerebral cortex by different senses, could be identified by remote monitoring of nano-vibrations produced by the transient blood flow to the specific regions of the head.
The precise distribution of blood flow, as well as the resultant speckle patterns, are both subject-dependent. However, we do not measure or analyze the speckle pattern itself, but rather the temporal changes it exhibits. The differences, or changes, are entirely the result of blood activity that began in the particular cortex when the particular sense is activated. We hypothesize that this assumption will hold true for any and all participants since human structural component is essentially comparable in terms of the relevant cortexes located in similar areas of the brain.
Temporal changes in the spatial distribution of the random speckle patterns can affect precision of the single frame method : the single frame might not represent whole recording session26.
One major limitation of the secondary speckle patterns classification using full video frame-by-frame method is the noise added due to the multiplicity of frames required to obtain prediction21. Namely, the first and the last recorded frames could contain irrelevant information due to subject’s behavior and unintentional head movements.
The two prior methods are based on a convnet model, which does not consider temporal dependency related to speckle pattern signal.
Our model, compared to the previously applied methods, includes a ConvLSTM layer that considers temporal dependency being found in our data in addition to the image processing capabilities of the convolution layers.
The underlying physiological processes of the human brain activity are time-dependent, hence, the ConvLSTM based model allows to learn important features related to the hemodynamic activity due to activation of the cerebral cortex of the human brain.
Figure 3 shows that sensory activity detection can be classified using learning-based methods. No significant difference in the model identification was found between the different types of senses or subjects, since in all cases the model input is expressed through the nano‐vibrations associated with neural activity due to activation of the cerebral cortex of the subject's brain.
The comparison between the photonic and EEG-methods for human senses detection and classification shows high conformity between EEG and our speckle-based model.
Methods
Experimental setup
The experimental setup comprises a green laser (770 µW, 532 nm), Basler saA1300-200um area scan camera with defocused optics to generate and capture the speckle patterns, EEG electrodes, OpenBCI EEG headband with Ganglion bio-sensing 4-channels boar and a computer. The video and EEG were synchronized to record brain signals simultaneously.
Data was collected from Eight healthy participants, ages 29–74, in a shuttered and controlled laboratory environment to prevent background noises. Each subject was seated on a distance of 50 cm from the camera, as shown in Fig. 1. The subject’s head was restrained in a headset equipped with a protective gear for the purpose of directing the left side of the head to the sensor and mitigating involuntary head movements. Each subject’s smell, taste and hearing sense-related brain activity was recorded in two conditions. First, in the state of rest without sensory stimulation. Second, under stimulation of each sense by performing a relevant action. In order to stimulate the sense of smell the subject smelled an alcohol-soaked cotton ball; the sense of taste was stimulated with sweet chocolate and the sense of hearing with a continuous constant-frequency noise.
A high-speed digital camera with defocused optics recorded the temporal changes of the speckle images during 10 s sampling for each test. The frame rate was set to 750 FPS and spatial resolution of 32 × 32 pixels. Data collection was performed on separate dates, with each subject recorded five times in one continuous session. The dataset contained roughly 240,000 frames where each subject's video contained a unique identification, including the subject's ID, the duration of the measurement, the sense type, and a binary sign symbolizing activity or inactivity of the sense.
The videos from different recording days were sub-divided into training and test datasets prior to subdividing them into specific frames. Data for all tested subjects was included in the training and test sets, preventing any mixing between the training and test datasets, which could have occurred with a simple random split.
Quantitative assessment and comparison of our proposed method used the metrics provided in Eqs. (2–5) with TP: True Positive, TN: True Negative, FP: False Positive and FN: False Negative, calculated pixelwise by the logical operators given in Eq. (1).
where the tuple \({(x}_{i},{y}_{i})\) is the model prediction and label for sample i.
The Institutional review board of Bar-Ilan University provided the ethics approval for the study. All participants provided informed consent for participation in the study. The experiments were carried out in accordance with relevant guidelines and regulations. Although deconstructed for lab optimization purposes, the device is entirely laser safe, tissue safe, etc., as previously obtained from international regulators.
Model
We propose to process the sequential speckle images by using a 2D ConvLSTM layer35 consisting of the LSTM layer with internal matrix multiplications along with 2D convolution operations. In our configuration, the speckle based data passes through the ConvLSTM cells and retains the original input dimensions instead of being projected onto a 1D feature vector, as seen in Fig. 5.

DNN classifier architecture. A visualization of the model in operation on a speckle input signal is shown. With state-to-state kernels of size 3 × 3, the ConvLSTM single layer network contains 64 hidden states and input-to-state for 64 input frames. Since the required model's prediction is a binary classification task, we concatenated all forecasting network's states and fed them into a 256-unit dense with ReLU activation, which speeds up our model's training phase by reducing the gradient of the computational process. To produce the final prediction, we added a dense layer with two units on top of the model.
The main equations of the ConvLSTM layer35 are given below (Eq. 6):
where ∗ denotes the convolution operator; ◦ is the Hadamard product \(; {{\mathrm{X}}_{1}\dots \mathrm{X}}_{\mathrm{t}}\) represent the model input\(; {\mathrm{C}}_{1}\dots {\mathrm{C}}_{\mathrm{t}}\) are the ConvLSTM cell outputs \(; {\mathrm{H}}_{1}\dots {\mathrm{H}}_{\mathrm{t}}\) are the hidden states\(; {\mathrm{o}}_{\mathrm{t}},{\mathrm{f}}_{\mathrm{t}},{\mathrm{i}}_{\mathrm{t}}\) are the ConvLSTM layer's 3D tensors, with the last two dimensions being spatial dimensions.
The ConvLSTM is defined by the inputs, past states of its local neighbors and the potential state of a certain cell in the grid. Before implementing the convolution operation, padding is required to ensure that the states and the inputs have the same number of rows and columns.
For the ConvLSTM model, the patch size to 1 × 1 was set to represent each 32 × 32 frame by a 32 × 32 × 3 tensor. The ConvLSTM single layer network contained 64 hidden states and input-to-state for 64 input frames, with state-to-state kernels of size 3 × 3. The output from the ConvLSTM encoder was directed into a fully connected, binary classification head, which contained 256-unit and ReLU activations.
Training was implemented in TensorFlow. Additional implementation details include binary cross-entropy as a loss function and dropout to reduce overfitting. We used the Adam optimizer with beta_1 = 0.9, beta_2 = 0.999. The batch size was 64 and learning rate—− 0.001. Training was performed on a single 1080Ti GPU and took roughly 20 epochs to converge.
EEG data classification
In order to verify the validity of the proposed method, the EEG and the speckle pattern recordings were synchronized. To perform classification of the EEG signal, we used a CNN with three 1D-Conv layers with a ReLU activation function and a 1D-MaxPooling operation followed by two fully connected layers36. No further preprocessing was used prior to the EEG-based model.
Additional implementation details include binary cross-entropy used as a loss function and the Adam optimizer. Training was performed on a single 1080Ti GPU and took roughly 10 epochs to converge.
Comparison of the validation methods
Prior methods for analyzing speckle patterns required a single frame26 or the entire video frame-by-frame21, achieved by averaging the model predictions across all frames of the video and giving a threshold for attempting to pick the desired outcome. Prior classification techniques utilized a Convolutional Neural Network (CNN) to encode data from a single frame.
TensorFlow implemented those two approaches for training. Additional implementation details include binary cross-entropy as a loss function and dropout to reduce overfitting. We used the Adam optimizer with beta_1 = 0.9, beta_2 = 0.999. The batch size was 32 and learning rate—0.001. Training was performed on a single 1080Ti GPU and took roughly 40 epochs to converge. Table 1 shows the validation results, which demonstrate that our method achieved a precision score of 92%, an accuracy score of 95%, while being faster and maintaining a high recall of 98%. Table 1 also compares our model to the previous two methods for back scattered laser speckle pattern classification, which had accuracy of 82 and 89%, respectively.
Conclusions
This paper presents a new speckle based photonic method for remote monitoring and detection of the three basic human senses: smell, taste, and hearing.
Base of the method is a combination of spatiotemporal analysis of defocused self-interference random speckle patterns reflected from the specific temple area of the head with a deep learning approach.
The study provides further evidence for the hypothesis that physiological processes associated with hemodynamic brain activity due to stimulation of the cerebral cortex by different senses could be identified by remote monitoring of nano-vibrations produced by transient blood flow to the specific regions of the head. The developed DNN showed high accuracy in classifying active and inactive senses.
Our method offers an alternative and much simpler solution for detecting specific brain activity which otherwise require significant resources (for example EEG or MRI devices). Furthermore, future development of our method could allow remote monitoring and evaluation of human brain activity on a large scale due to the low cost and flexibility of the system.
Data availability
The data generated to support the findings of this study are available from the corresponding author upon reasonable request.
Code availability
The code is available at https://github.com/zeevikal/senses-speckle.
References
Proctor, R. W. & Proctor, J. D. Sensation and perception. Handbook of human factors and ergonomics, 55—90 (2006).
Alarcão, S. M. & Fonseca, M. J. Emotions recognition using EEG signals: A survey. IEEE Trans. Affect. Comput. 10, 374–393 (2019).
Zhuang, X., Sekiyama, K. & Fukuda, T. Evaluation of human sense by biological information analysis. In 20th Anniversary MHS 2009 and Micro-Nano Global COE - 2009 International Symposium on Micro-NanoMechatronics and Human Science 74–79. https://doi.org/10.1109/MHS.2009.5352071 (2009).
Lee, M. & Cho, G. Measurement of human sensation for developing sensible textiles. Hum. Factors Ergon. Manuf. 19, 168–176 (2009).
Park, K. H. et al. Evaluation of human electroencephalogram change for sensory effects of fragrance. Ski. Res. Technol. 25, 526–531 (2019).
Fukai, H., Tomita, Y. & Mitsukura, Y. A design of the preference acquisition detection system using the EGG. Int. J. Intell. Inf. Syst. 2, 19–25 (2013).
Nakamura, T., Tomita, Y. & Mitsukura, Y. A method of obtaining sense of touch by using EEG. Inf. 14, 621–632 (2011).
Zoefel, B. & VanRullen, R. EEG oscillations entrain their phase to high-level features of speech sound. Neuroimage 124, 16–23 (2016).
Christensen, C. B., Harte, J. M., Lunner, T. & Kidmose, P. Ear-EEG-based objective hearing threshold estimation evaluated on normal hearing subjects. IEEE Trans. Biomed. Eng. 65, 1026–1034 (2018).
Lorig, T. S. The application of electroencephalographic techniques to the study of human olfaction: A review and tutorial. Int. J. Psychophysiol. 36, 91–104 (2000).
Martin, G. N. Human electroencephalographic (EEG) response to olfactory stimulation: Two experiments using the aroma of food. Int. J. Psychophysiol. 30, 287–302 (1998).
Saha, A., Konar, A., Chatterjee, A., Ralescu, A. & Nagar, A. K. EEG analysis for olfactory perceptual-ability measurement using a recurrent neural classifier. IEEE Trans. Hum. Mach. Syst. 44, 717–730 (2014).
Saha, A., Konar, A., Rakshit, P., Ralescu, A. L. & Nagar, A. K. Olfaction recognition by EEG analysis using differential evolution induced Hopfield neural net. Proc. Int. Jt. Conf. Neural Netw. https://doi.org/10.1109/IJCNN.2013.6706874 (2013).
Park, C., Looney, D. & Mandic, D. P. Estimating human response to taste using EEG. Proc. Annu. Int. Conf IEEE Eng. Med. Biol. Soc. EMBS 15, 6331–6332. https://doi.org/10.1109/IEMBS.2011.6091563 (2011).
Boas, D. A. & Dunn, A. K. Laser speckle contrast imaging in biomedical optics. J. Biomed. Opt. 15, 011109 (2010).
Jiang, M. et al. Dynamic imaging of cerebral blood flow using laser speckle during epileptic events. Biomed. Opt. Biomed. 2012, 195–201. https://doi.org/10.1364/biomed.2012.btu3a.45 (2012).
Ozana, N. et al. Remote photonic sensing of cerebral hemodynamic changes via temporal spatial analysis of acoustic vibrations. J. Biophoton. 13, 1–12 (2020).
Zalevsky, Z. et al. Simultaneous remote extraction of multiple speech sources and heart beats from secondary speckles pattern. Opt. Express 17, 21566 (2009).
Lengenfelder, B. et al. Remote photoacoustic sensing using speckle-analysis. Sci. Rep. 9, 1–11 (2019).
Golberg, M., Ruiz-Rivas, J., Polani, S., Beiderman, Y. & Zalevsky, Z. Large-scale clinical validation of noncontact and continuous extraction of blood pressure via multipoint defocused photonic imaging. Appl. Opt. 57, B45 (2018).
Kalyuzhner, Z., Agdarov, S., Bennett, A., Beiderman, Y. & Zalevsky, Z. Remote photonic sensing of blood oxygen saturation via tracking of anomalies in micro-saccades patterns. Opt. Express 29, 3386 (2021).
Ozana, N. et al. Demonstration of a remote optical measurement configuration that correlates with breathing, heart rate, pulse pressure, blood coagulation, and blood oxygenation. Proc. IEEE 103, 248–262 (2015).
Beiderman, Y. et al. Remote estimation of blood pulse pressure via temporal tracking of reflected secondary speckles pattern. J. Biomed. Opt. 15, 061707 (2010).
Bishitz, Y. et al. Noncontact optical sensor for bone fracture diagnostics. Biomed. Opt. Express 6, 651 (2015).
Ozana, N. et al. Remote optical configuration of pigmented lesion detection and diagnosis of bone fractures. Photonic Ther. Diagn. XII 9689, 968916 (2016).
Kalyzhner, Z., Levitas, O., Kalichman, F., Jacobson, R. & Zalevsky, Z. Photonic human identification based on deep learning of back scattered laser speckle patterns. Opt. Express 27, 36002 (2019).
Connor, J. T., Martin, R. D. & Atlas, L. E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 5, 240–254 (1994).
Banerjee, T. K., Roy, M. K. & Bhoi, K. K. Is stroke increasing in India—preventive measures that need to be implemented. J. Indian Med. Assoc. 103 162, 164, 166 passim–162, 164, 166 passim (2005).
Green, T. L., McGregor, L. D. & King, K. M. Smell and taste dysfunction following minor stroke: a case report. Can. J. Neurosci. Nurs. 30, 10–13 (2008).
Penry, W. H. T. R. J. P. & Kiffin, J. Complex partial seizures clinical characteristics and differential diagnosis. Handb. Park. Dis. Fifth Ed. 33, 11515–11515 (1983).
Nguyen, M. Q. & Ryba, N. J. P. A smell that causes seizure. PLoS ONE 7, 1–10 (2012).
Tong, J. Y., Wong, A., Zhu, D., Fastenberg, J. H. & Tham, T. The prevalence of olfactory and gustatory dysfunction in COVID-19 patients: A systematic review and meta-analysis. Otolaryngol. Head Neck Surg. (United States) 163, 3–11 (2020).
Walker, A., Pottinger, G., Scott, A. & Hopkins, C. Anosmia and loss of smell in the era of covid-19. BMJ 370, 1–4 (2020).
Cooper, K. W. et al. COVID-19 and the chemical senses: Supporting players take center stage. Neuron 107, 219–233 (2020).
Shi, X. et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 802–810 https://arxiv.org/abs/1506.04214 (2015).
Craik, A., He, Y. & Contreras-Vidal, J. L. Deep learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 16(3), 031001 (2019).
Author information
Authors and Affiliations
Contributions
Z.K created the models and conducted the training. All authors contributed to the design of the study, conducting the tests, interpreting the results, and writing the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kalyuzhner, Z., Agdarov, S., Orr, I. et al. Remote photonic detection of human senses using secondary speckle patterns. Sci Rep 12, 519 (2022). https://doi.org/10.1038/s41598-021-04558-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-04558-0
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
