
Abstract
Although advancing the therapeutic alternatives for treating deadly cancers has gained much attention globally, still the primary methods such as chemotherapy have significant downsides and low specificity. Most recently, Anticancer peptides (ACPs) have emerged as a potential alternative to therapeutic alternatives with much fewer negative side-effects. However, the identification of ACPs through wet-lab experiments is expensive and time-consuming. Hence, computational methods have emerged as viable alternatives. During the past few years, several computational ACP identification techniques using hand-engineered features have been proposed to solve this problem. In this study, we propose a new multi headed deep convolutional neural network model called ACP-MHCNN, for extracting and combining discriminative features from different information sources in an interactive way. Our model extracts sequence, physicochemical, and evolutionary based features for ACP identification using different numerical peptide representations while restraining parameter overhead. It is evident through rigorous experiments using cross-validation and independent-dataset that ACP-MHCNN outperforms other models for anticancer peptide identification by a substantial margin on our employed benchmarks. ACP-MHCNN outperforms state-of-the-art model by 6.3%, 8.6%, 3.7%, 4.0%, and 0.20 in terms of accuracy, sensitivity, specificity, precision, and MCC respectively. ACP-MHCNN and its relevant codes and datasets are publicly available at: https://github.com/mrzResearchArena/Anticancer-Peptides-CNN. ACP-MHCNN is also publicly available as an online predictor at: https://anticancer.pythonanywhere.com/.
Similar content being viewed by others

Introduction
Cancer is one of the deadliest diseases in the world. Even though there are several ways of treating some of the cancer types, still there is no certain treatment for most of the cancers. Two of the major treatment strategies for cancer are radiation therapy and chemotherapy1,2. However, they are both expensive and have long term negative side effects1. In addition, cancer cells can become resistant to the chemotherapeutic drugs1. Therefore, there is a demand for finding new low cost and more effective treatments for cancer3. Among the newly introduced treatment methods for this deadly disease, anticancer peptides (ACP) have gained a lot of attention in the recent years as a less toxic and potentially more effective treatment for cancer3,4.
ACPs are short peptides consisting of 10 to 50 amino acids which are typically derived from antimicrobial peptides5. ACPs perform a wide range of cytotoxic activities against cancer cells while leave benign cells intact which is the reason behind their high specificity and low side effects6. Additionally, ACPs have low production cost, they are easy to synthesize and modify, and they have excellent tumour penetration capabilities7. In the past few years, many ACP based treatment options have been tested on a wide variety of cancer cells. However, only a few of them have been cleared for further clinical trials8,9. Hence, rapid identification of potential ACPs is important for cancer therapeutic advancement. However, identification of these peptides through wet-lab experiments is relatively costly and time consuming1. Therefore, there is a demand for fast and accurate computational methods to tackle this problem. Among different computational methods, machine learning has merged as a promising approach to identify ACPs efficiently and effectively.
During the past few years, a wide range of traditional Machine Learning (ML) methods have been proposed to identify ACPs. These traditional ML techniques require a set of hand-engineered features to represent protein sequences for the classification purpose. Thus, various methods for extracting effective features to represent proteins and peptides in an effective manner that contain significant discriminatory information for the classification purpose have been proposed. AntiCP was the first ML model for ACP identification that was proposed in1. In this model, peptide sequences are formulated by amino acid composition (AAC), split AAC (using N-terminal and C-terminal residues), dipeptide composition (DPC), and binary profiles features (BPF)1. Afterwards, these features are passed as input to a Support Vector Machine (SVM) classifier for separating the ACPs from the non-ACPs.
Shortly after that, Hajisharifi et al., proposed two methods for ACP identification using SVM10. In the first method, SVM was employed for separating ACPs from non-ACPs. They used pseudo-amino acid composition (PseAAC) method on different combinations of 6 physicochemical properties of the amino acids to extract features. In the second method, the binary classification was performed using SVM with a local alignment-based kernel method designed for feature extraction from peptide sequence10. Later on, Chen et al. proposed iACP, where gapped dipeptide compositions (g-gap DPC) were used for feature extraction from peptide sequences, and SVM with radial basis function (RBF) kernel was used for the classification purpose3.
More recently, Manavalan et al., proposed MLACP to tackle this problem. To build this model, AAC, DPC, atomic composition (ATC) of the sequences, and physicochemical properties of the residues were used for feature extraction while, SVM and Random Forest (RF) classifiers were used for ACP identification11. At the same time, Akbar et al., proposed iACP-GAEnsc, which used g-gap DPC, reduced amino acid alphabet composition (RAAAC), and PseAAC based on hydrophobicity and hydrophilicity of the amino acids (Am-PseAAC) for feature extraction. They also proposed an ensemble of different classifiers that combined SVM, RF, Probabilistic Neural Network (PNN), Generalized Regression Neural Network (GRNN), and K-nearest Neighbour (KNN) classification models for ACP identification12.
Later on, Xu et al., proposed a hybrid sequence-based model, where the peptides were converted to feature vectors through g-gap DPC to tackle this problem. They also used SVM and RF as their employed classifiers13. At the same time Kabir et al., proposed TargetACP, where the peptides were represented using split AAC, correlation factors extracted from PSSM profiles (PsePSSM), and composite protein sequence representation (CPSR). They also used SVM, RF and KNN classifiers as their employed models14.
Most recently, Schaduangrat et al. proposed ACPred, where different combinations of AAC, DPC, PseAAC, Am-PseAAC, and physicochemical properties were used for peptide representation. They also used SVM and RF classifiers for the ACP identification prediction4. At the same time, Wei et al., proposed ACPred-FL, where AAC, g-gap DPC, BPF, amino acid-specific physicochemical property-based bit vectors and composition-transition-distribution (CTD) methods were used for feature extraction. Similarly, they used SVM based ensemble model as their employed classifier15.
During the revision stage of this manuscript, Charoenkwan et al. proposed a sequence-based method iACP-FSCM with an emphasis on model interpretability, where 11 local and global amino acid composition-based features were utilized with a weighted-sum-based prediction mechanism16. Furthermore, Agrawal et al. proposed a sequence-based method AntiCP 2.0 along with two ACP identification datasets17. AntiCP 2.0 has been shown to outperform all the existing ACP identification methods with state-of-the-art accuracy. In a recent review article, Basith et al.18 (Sir, please fix the citation order) presented a concise summary of 16 ML methods developed so far for ACP identification.
Using traditional ML models (SVM, RF, KNN, etc.), the systems’ performances depend on the underlying manual feature extraction mechanisms. However, formulating problem-specific optimal feature representation for these sequences is not a trivial task and requires significant iterations of trial and error. In recent years, deep learning (DL) methods attracted tremendous attention to tackle challenging problems related to biological sequences because in many cases, unlike traditional ML algorithms, they do not require manual feature extraction to represent the input data15,16,17,18,19,20,21,22,23,24,25. Several DL methods, such as Convolutional Neural Network (CNN)20,26, Recurrent Neural Network (RNN)20, word embedding27,28, and autoencoder29,30,31 have been successfully employed for feature extraction and classification for DNA, RNA, and protein sequences. Methods such as CNN and RNN exploit spatial locality and ordering information of the residues for ensuring that the extracted features retain a significant amount of discriminatory information from biological sequences.
However, none of the studies related to ML-based ACP identification explored automated feature extraction using DL methods until recently, when ACP-DL was proposed in32. Although Timmons et al. proposed a deep neural network architecture ENNAACT for ACP identification33, it still operates on manually extracted features (AAC, DPC, g-gap DPC among others). To the best-of-our-knowledge ACP-DL is the only DL-based automated feature extraction method proposed for this problem, so far. ACP-DL uses bidirectional long-short-term-memory (LSTM) recurrent layers for extracting features from peptide sequences followed by a fully-connected layer with a sigmoid neuron for classification. ACP-DL extracts features from two one-hot vector-based peptide representation techniques (binary profile and k-mer sparse matrix) that only depict the presence of a specific amino acid or a group of amino acids along different positions of the sequences. As a result, physicochemical properties or evolutionary substitution information of the residues, which contain significant information regarding anticancer activities of peptide sequences are not utilized in ACP-DL’s feature representation process4,12,14,15. As a result, although the predictive performance of ACP-DL is quite impressive, there is still room for improvement.
Although recurrent layers are reliable for converting biological sequences into fixed-size features vectors20, convolutional layers have also demonstrated promising performance addressing similar problems. In fact, CNN have been demonstrated as an effective technique for feature extraction and classification for DNA, RNA, peptides, and protein sequences in a wide range of studies33,34,35,36,37,38,39,40,41. However, CNN has never been used for ACP classification task.
In this study, we hypothesize that a new representation technique that depict the residues’ evolutionary relationship and their physicochemical characteristics can embellish the feature extraction process for ACP identification since this type of information contains signals necessary for elucidating the structure and function of peptides. With this viewpoint, we are proposing a method called ACP-MHCNN, which consists of three jointly trained groups of stacked CNNs for interactive feature extraction from three distinct information sources for ACP identification. Our results demonstrate that ACP-MHCNN outperforms the current state-of-the-art methods on several well-established ACP identification datasets with a substantial margin. On ACP-500/ACP-164 benchmark dataset, ACP-MHCNN outperforms ACP-DL by 6.3%, 8.6%, 3.7%, 4.0%, and 0.20 in terms of accuracy, sensitivity, specificity, precision, and Matthews correlation coefficient (MCC), respectively. Our model and all its relevant codes and datasets are publicly available at: https://github.com/mrzResearchArena/Anticancer-Peptides-CNN. ACP-MHCNN is also publicly available as an online predictor at: https://anticancer.pythonanywhere.com.
Materials and methods
In this section, we represent the benchmarks that are used in this study. We also present our sequence representation as well as the proposed feature extraction and classification models.
Benchmark datasets
In this study, we use three independent benchmarks to study the effectiveness and generality of our proposed method. These benchmarks are namely, ACP-740, ACP-240, and the combination of ACP-500 and ACP-164.
ACP-740 dataset was introduced in32. For constructing ACP-740, initially, 388 experimentally validated ACPs (positive samples) were collected, among which 138 were from3 and 250 were from29. Correspondingly, 456 antimicrobial peptides (AMP) without anticancer activity (negative samples) were initially collected, among which 206 were from3 and 250 were from29. Subsequently, using CD-HIT, 12 positive samples and 92 negative samples were removed to ensure that none of the peptide sequence pairs have more than 90% similarity as it was done in previous studies32, which resulted in a dataset with 740 samples (376 positives + 364 negatives). The ACP-240 dataset, which was also introduced in32, consists of 240 samples where 129 experimentally validated ACPs are the positive samples, and 111 AMPs without anticancer activity are the negative samples. To avoid performance over-estimation due to homology bias, using the same procedure as ACP 740, redundancy reduction was performed with a 90% threshold to construct ACP-240.
On the other hand, ACP-500 and ACP-164, were constructed in15, where ACP-500 is used for training and validation, while ACP-164 is used as an independent test dataset. For constructing these two datasets, initially, 3212 positive samples were collected, among which 138 were from3, 225 were from1, and 2849 were from42. The initial 2250 negative samples were collected from1. After performing redundancy reduction using CD-HIT with a 90% similarity threshold, 332 positive samples and 1023 negative samples remained. From these remaining non-redundant sequences, 250 positive samples and 250 negative samples were randomly selected for constructing ACP-500, whereas ACP-164 contains the remaining 82 positive samples along with 82 randomly selected negative samples.
Numerical representation for peptide sequences
Although ACP-MHCNN does not require manual feature extraction, it is crucial to encode the sequences in numerical formats since the initial feature extraction layer of any DL architecture performs mathematical operations on the input for extracting class-discriminative activations. Such information is then passed as input to nodes in the subsequent layers. In this study, we exploit three peptide representation methods that are described in the following three sections. Since it has been shown in15,32 that considering k amino acids from the N-terminus of a peptide is sufficient for capturing its anticancer activity, we have represented each sequence using its k N-terminus residues. In our experiments, we have set k = 15. For sequences having length less than 15, post-padding has been applied as it is explained in details in43.
Binary profile feature (BPF) representation
In our first representation method, each of the 20 amino acids (A, R, N, D, C, Q, E, G, H, I, L, K, M, F, P, S, T, W, Y, and V) is represented using a binary one-hot vector of length 20. For example, A is represented as [1, 0,…, 0], R is represented as [0, 1,…,0], V is represented as [0, 0, …, 1], and so on. This representation encodes each sequence into a k × 20 matrix. Manually extracted short-range sequence patterns such as AAC, DPC, split AAC and long-range sequence patterns such as g-gap DPC have been successfully employed with traditional ML models for ACP identification1,3,10,11,12,13,14,15. We hypothesize that our model’s feature detection mechanism can capture both short-range and long-range sequence patterns that distinguish the peptides with anticancer activity from BPF representation.
Physiochemical-based (AAIs) representation
Basak et al., used a numerical representation for proteins for identifying length 5 conserved peptides through molecular evolutionary analysis44. The underlying numerical representation method proposed in45 utilized an alphabet reduction strategy where the amino acids are divided into non-overlapping groups based on their side chain chemical property. The findings from these two studies have implied that amino acid physicochemical properties can facilitate the identification of evolutionarily conserved motifs, which are in turn important for maintaining the appropriate structure or function of the molecules. When these conserved motifs go through changes in the primary structure level, the amino acid residues are usually replaced with the ones with similar physicochemical properties. This phenomenon highlights the significant impact of exploring physicochemical properties for motif identification with respect to similarity among the substitute amino acids. Since our model identifies peptides with specific functions, discovering these motifs can strengthen our model.
Moreover, hand-engineered features based on amino acid physicochemical properties have been shown to improve ACP identification in a series of studies that have used traditional machine learning models4,10,11,12,15. We hypothesize that our feature extraction mechanism can identify similar features from a peptide representation based on the amino acids’ physicochemical properties. With these assumptions, our physicochemical property-based representation replaces each of the residues in a peptide sequence with a 31-dimensional vector (composed of 0/1 elements) that depict various physicochemical properties. As a result, each of the sequences is encoded into a k × 31 matrix.
For each amino acid, a unique 31-dimensional vector is formed through the concatenation of a 10-bit vector and a 21-bit vector. Elements of the 10-bit vector depict the membership of a specific amino acid in 10 overlapping groups based on its physicochemical properties as it was explained in15. Elements of the 21-bit vector are determined based on membership of a specific amino acid in the 7*3 = 21 groups formed by dividing them into 3 groups based on 7 physicochemical properties namely, polarity, normalized Van der Waals volume, hydrophobicity, secondary structures, solvent accessibility, charge, and polarizability as it was done in15.
Evolutionary information-based (BLO62) representation
BLOSUM is a symmetric 20 × 20 matrix constructed by Henikoff et al., in46, where each entry is proportional to the probability of substitution of a given amino acids with another amino acid in a protein (substitution probability in evolutionarily related proteins). Each entry in this matrix can be represented using the following equation:
where, \({p}_{ij}\) is the probability of amino acids ‘i’ and ‘j’ being aligned in homologous sequence alignments, \({f}_{i}\) is the probability that amino acid ‘i’ appears in any protein sequence, \({f}_{j}\) is the probability that amino acid ‘j’ appears in any protein sequence, and \(\lambda\) is the scaling factor for rounding off the entries in the matrix to convenient integer values.
The observed substitution frequency for every possible amino acid pair (including identity pairs) is calculated from a large number of trusted pairwise alignments of homologous sequences as it is explained in46. If an entry M(i,j) is positive, the number of observed substitutions between amino acids i and j is more than random expectation. Thus, these substitutions are conservative (these substitutions occur more frequently than other random substitutions in homologous sequences). Therefore, each of the 20 rows of this matrix is a vector containing 20 elements that depict a specific amino acid’s evolutionary relationship with other amino acids. Here, we use BLOSUM matrix for retrieving a 20-dimensional vector for each of the 20 amino acids and use these vectors for encoding each peptide sequence into a k × 20 matrix. We hypothesize that our feature extraction architecture can automatically extract discriminative evolutionary features for ACP identification from this sequence representation. Among different BLOSUM matrix variations, we have used BLOSUM62 as the most popular one in this study.
Multi-headed convolutional neural network architecture
CNN is a specialized neural network where each neuron in a given layer is connected to a group of neighbouring nodes in the previous layer. These layers drastically reduce parameter overhead and extract translation-invariant meaningful features by exploiting spatial locality structure in data through local connectivity and weight sharing47. A convolutional layer usually consists of several kernels where each kernel detects some specific local pattern in different input locations47. Since hand-engineered feature extraction methods such as AAC, DPC, g-gap DPC, PseAAC, and PsePSSM utilize ordering of neighbouring residues and their correlation information with respect to evolutionary and physicochemical properties for feature generation from peptide sequences, using convolutional kernels for automatically approximating similar features is a rational choice. Moreover, well-defined ordering among the residues in peptide primary structure, the residues' inherent local neighbourhood structures, and the presence of similar patterns (sequence motifs) at different locations across a peptide make these sequences perfect candidates for feature extraction through convolutional kernels.
The feature extraction mechanism in our proposed model consists of groups of stacked convolutional layers. Each convolutional layer group extracts features from a different representation of the peptide sequence. Since we have use three representation methods that serve as sources of discriminative information, our model contains three parallel layer groups. Each of these groups extract short-range and long-range patterns from a unique sequence representation using two stacked convolutional layers with varying number of kernels. The number of kernels in the layers and size of these filters are hyperparameters tuned through cross-validation48.
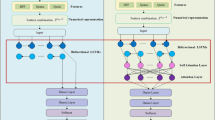
The output feature maps of the second convolutional layer of each of the three groups are flattened, and the three resulting vectors are concatenated. The unified vector from this concatenation is passed through a dense layer with ReLU (Rectified Linear Unit) activation function for recombining the features extracted from different sequence representations49. It is to be mentioned that each element of the input vector for this dense recombination layer is calculated from a single information source (BPF or physicochemical or evolutionary representation) during forward-propagation. In contrast, elements of this layer’s output vector can be aggregated from multiple information sources. Hence, this layer enables seamless interaction between different convolutional groups that extract patterns from different representations and facilitates joint feature learning from multiple information sources during back-propagation50. These complex non-linear features are then passed as inputs to a dense layer with SoftMax activation function51, which draws a linear decision boundary on the derived feature space for separating the anticancer peptides from peptides without anticancer activity. Figure 1 represents the architecture of our proposed model for joint feature extraction from multiple information sources.

The general architecture of ACP-MHCNN. We extract BPF, physicochemical, and evolutionary-based features. We then feed the extracted features to a multi-headed deep convolutional neural network (MHCNN) to predict Anti-Cancer peptides.
Since the tmypraining data is limited for this task, there is a possibility for overfitting when training a deep-CNN model. To avoid overfitting, we adopt both L2 regularization and dropout methods in the feature extraction step to build out model52. L2 and dropout have been shown to be effective methods to address overfitting issue when the number of training samples are limited52. To be specific, the feature extraction occurs in all layers of the three parallel convolutional groups and the dense recombination layer after concatenation. Therefore, here high dropout rates (>=0.5) are employed after each of these layers during the training phase to mitigate overfitting. These dropout rates are determined through cross-validation. Note that, the three convolutional layer groups that extract features from three distinct sequence representations are jointly trained alongside the dense recombination layer for minimizing cross entropy loss function53. Therefore, our model can simultaneously interact with the three information sources for detecting complex and ambiguous patterns. Optimal values for our model's weights and biases are learned by employing Adam optimizer50 with a learning rate determined through cross-validation.
ACP-DL, the only deep learning-based architecture proposed to date for anticancer peptide identification, employed stacked bidirectional LSTM layers for feature extraction which is an intuitive choice given a recurrent model’s capability of capturing global sequence-order information32. However, the recurrent connections and the gates also introduce a large number of parameters that need to be tuned. This can lead to overfitting since the number of training instances is limited. Moreover, since only 15 N-terminus amino acids have been considered for feature extraction, LSTM’s long-range sequence-order-effect detection capabilities remain underutilized while the parameter overhead remains32. In this study, we do not add any recurrent layer on top of the output feature maps from the final convolutional layers to avoid this issue.
Furthermore, it is to be noted that the kernels in the final layer of each convolutional group have an effective receptive field of length 6 due to hierarchical relationship between the stacked layers (length 4 kernels to length 3 kernels)47. This effective receptive field should provide sufficient coverage for extracting both short-range and long-range patterns from sub-sequences of length 15. In addition, since we extract features from short sub-sequences, reducing the temporal dimension of the intermediate feature maps (outputs of the first and second convolutional layers of each group) is not required for learning higher order features. Hence, we do not add any pooling layers between the feature extraction layers within the convolutional groups47. The absence of pooling layers also reduces potential loss of sequence order information that can be exploited by the kernels in the final convolutional layers in the groups for detecting long-range patterns47.
To analyse the contribution of features extracted from each of the information sources, we carry out experiments using all possible combinations of the three representations. This results in seven models (3C1 + 3C2 + 3C3) with 1, 2 or 3 convolutional groups. All these combinations are summarized in Table 1. The performance for our architecture using these seven combinations is reported in the following section.
For ACP-740 and ACP-240, our model’s hyperparameters are tuned on ACP-740 through cross-validation, and the same model configuration is used for ACP-240. For ACP-500 and ACP-164, hyperparameter tuning is performed on ACP-500 through cross-validation. ACP-240 and ACP-164 have been kept untouched during hyperparameter tuning to avoid performance overestimation. Table 2 shows detailed hyperparameter configurations for different ACP identification datasets used in this study.
Results and discussion
In this section, we present how we carry out the performance evaluation of our proposed model, our achieved results, and then discuss them.
Evaluation metrics
The evaluation metrics that have been used for measuring the performance of our classification method are Accuracy, Sensitivity, Specificity, Precision, and Matthews correlation coefficient (MCC). These metrics are described through the following equations:
where, tp is the number of correctly predicted positive instances, tn is the number of correctly predicted negative instances, fp is the number of incorrectly predicted negative instances, and fn is the number of incorrectly predicted positive instances. The range of values for Accuracy, Sensitivity, Specificity, and Precision is 0 to 100 percent. 100% represents an ideal classifier (totally accurate) and 0% represents the worst possible model (totally inaccurate). In addition, MCC has a range from − 1 to + 1. A value of 0 in MCC represent a random classifier with no correlation, + 1 represent perfect positive correlation and − 1 represents perfect negative correlation.
Contribution analysis for different sequence representations
For each of the representation combinations summarized in Table 1, we have performed experiments on ACP-740 and ACP-240 using fivefold-cross validation, and the corresponding results are reported in Table 3 and 4, respectively. For ACP-500 and ACP-164, we train and tune the models on ACP-500 and test them on ACP-164. The corresponding results are reported in Table 5.
As shown in Table 3, for the ACP-740 dataset, among the single-representation combinations (C1, C2, and C3), the representation depicting evolutionary information of the amino acid residues (C3) performs better compared to BPF and physicochemical-based representations (C1 and C2) on all six performance measures. As shown in Tables 4 and 5, similar results are observed for single representation models for ACP-240 and ACP-164. These results indicate that when it comes to feature extraction from a single peptide representation, evolutionary information contributes the most for separating the ACPs from the non-ACPs compared to BPF and physicochemical-based representation.
Among the two-representation combinations (C4, C5, and C6), C5 (BPF + evolutionary), and C6 (physicochemical property + evolutionary information) performs better than C4 (BPF + physicochemical property) which further underscores the importance of the features extracted from evolutionary information for ACP identification. Moreover, C5 and C6 (two-representation combinations containing evolutionary information) perform better than C3 (the best performing single-representation combination containing evolutionary information only). This aspect of the results manifests that our proposed joint pattern extraction strategy from multiple representations through parallel-convolutional-groups can effectively embellish the features learned from a strong primary representation (evolutionary information in this case) through potential ambiguity resolution using other secondary representations (BPF and physicochemical property-based information in this case).
This hypothesis has been further corroborated by the performance of the all-representation combination (C7) on all datasets. As shown in Tables 3, 4, and 5, the model trained on C7 consisting of three parallel convolutional groups that extract features from all three representations performs better than the other combinations (C1 to C6). Therefore, we use this all-representation combination model to train ACP-MHCNN and compare its performance with state-of-the-art methods in the following subsection. To provide more insight into our achieved results, we present receiver operating characteristic (ROC) curves for our achieved results. The ROC curve for ACP-740 (using fivefold cross validation), ACP-240 (using fivefold cross validation), and ACP-164 (using ACP-500 as the training dataset) are shown in Figs. 2, 3, and 4, respectively. The results for ACP-MHCNN when it is trained on ACP-740 dataset and tested on ACP-240 and ACP-164 datasets are provided in Table S1.

ROC curve for ACP-740 dataset for the fivefold cross-validation on the experiment. As shown in these figures, we constantly achieve very high Area Under the Curve (AUC) value.

ROC curve for ACP-240 dataset for the fivefold cross-validation on the experiment. Similar to the results reported for ACP-740 dataset, we constantly achieve very high Area Under the Curve (AUC) value.

ROC curve for ACP-500/164. Here we used ACP-500 as a training dataset and ACP-164 as a testing dataset on the experiment.
As shown in these figures, we constantly achieve very high Area Under the Curve (AUC) value. We achieve 0.90, 0.88, and 0.93 for ACP-740, ACP-240, and ACP-164, respectively. The consistent AUC achieved on these three benchmarks using different evaluation methods demonstrates the generality of our proposed model. In addition, achieving 0.93 in AUC on ACP-164 which is an independent test set demonstrates the potential of ACP-MHCNN on identifying ACP for new unseen samples.
We perform additional experiments to study the performance of our proposed method when full sequences are utilized instead of partial sequences. For these experiments, the longest sequence in each dataset was kept untouched and rest of the sequences were post-padded accordingly for matching the longest sequence’s length42. These results are reported in Tables 6, 7, and 8, respectively.
By comparing Tables 6 (ACP-740 full sequence), Table 7 (ACP-240 full sequence), and Table 8 (ACP-500/164 full sequence) with Tables 3 (ACP-740 partial sequence), Table 4 (ACP-240 partial sequence), and Table 5 (ACP-500/164 partial sequence), respectively, it can be observed that using full sequences degrade our model’s performance for most of the representation combinations. Moreover, for all three datasets, the performance of the model with the all-representation combination (C7) degrades significantly (for ACP-240, C7 performs much worse compared to C3) when full sequences are used. These observations suggest that using k N-terminus sequence performs better than complete sequences for ACP identification task using the current version of our model.
One of the potential causes behind performance degradation using full sequence is that the sufficient effective receptive field assumptions for long-range pattern extraction discussed in “Multi-headed convolutional neural network architecture” no longer holds when long sequences are used. These results have corroborated our decision of considering only k N-terminus residues for feature extraction.
We also compared ACP-MHCNN with some of the widely used classical Machine Learning classifiers in similar studies such as Support Vector Machine (SVM), Random Forest RF, Extra Tree (ET), eXtreme Gradient Boosting (XGB), k-Nearest Neighbours (KNN), Decision Tree (DT), Naive Bayes (NB), and Adaptive Boosting (AB)54,55,56. To do this, we convert BPF, Physicochemical Properties, and Evolutionary Information to vector from matrix and use to train these classifiers. The result for this comparison on ACP-740, ACP-240, and ACP-500/164 are shown in Table 9. As shown in this Table, ACP-MHCNN significantly outperform these classifiers. The main reason is the ability of ACP-MHCNN to automatically extract related features from the input matrix compared to traditional ML models which require further steps to extract relevant information. Such comparison demonstrates the importance of automated feature extraction to enhance the prediction performance.
Comparison with state-of-the-art methods
In this section, we compare ACP-MHCNN with ACP-DL as the state of the art and also the only DL based ACP identification model proposed to date32. Yi et al., tested their proposed ACP-DL on ACP-740 and ACP-240 datasets using 5-fold cross-validation. We use the same evaluation strategies and metrics for a fair comparison while estimating our ACP-MHCNN’s performance on ACP-740 and ACP-240 datasets. To investigate the generality of ACP-MHCNN even further, we compare it with ACP-DL on ACP500/ACP164 dataset as well. In this experiment, ACP-500 is used for training and tuning the model, and ACP-164 is used as the independent dataset. During all these experiments, ACP-DL is trained using the implementation details available in the accompanying GitHub repository (https://github.com/haichengyi/ACP-DL). It is to be noted that, during our experiments, ACP-DL obtained accuracies of 80% and 81.3% on ACP-740 and ACP-240, respectively.
Comparison between ACP-MHCNN and ACP-DL on all the datasets is shown in Table 10. As shown in this table, ACP-MHCNN outperforms ACP-DL on all datasets for every evaluation metric. To be precise, on ACP-740, ACP-MHCNN scores 6.0%, 7.5%, 4.5%, 4.7%, and 0.12 more than ACP-DL in terms of accuracy, sensitivity, specificity, precision, and MCC, respectively. Similarly, on ACP-240 ACP-MHCNN scores 1.8%, 6.0%, 4.4% and 0.02 more than ACP-DL in terms of accuracy, specificity, and MCC, respectively.
ACP-MHCNN also significantly outperforms ACP-DL on the ACP-500/ACP-164 dataset that was used to investigate the generalizability of our model. On ACP-500/ACP-164 ACP-MHCNN outperforms ACP-DL by 6.3%, 8.6%, 3.7%, 4.0%, and 0.20 in terms of accuracy, sensitivity, specificity, precision, and MCC respectively. ACP-MHCNN and its relevant codes as well as the datasets used in this study are all publicly available at: https://github.com/mrzResearchArena/Anticancer-Peptides-CNN. ACP-MHCNN is also publicly available as an online predictor at: https://anticancer.pythonanywhere.com.
Additionally, we have trained and tested ACP-MHCNN on two datasets proposed by Agrawal et al. in the recently published method AntiCP 2.017. The two datasets are main and alternate and contain their respective training and external validation partitions. ACP-MHCNN has substantially outperformed ACP-DL on both datasets. These results are shown in Table 11.
Table 11 clearly shows ACP-MHCNN outperforms ACP-DL by a large margin. We also compare ACP-MHCNN with several existing ACP identification methods on both main and alternate datasets used in17, and the results are shown in Table 12. This comparison shows that ACPred-LAF16, iACP-FSCM57, and AntiCP-2.017 slightly outperforms ACP-MHCNN, and all outperform other existing methods by significant margin on these two specific datasets. It is worth noting that, since AntiCP-2.0 and all of the existing methods reported in Table 12 are traditional machine learning models while ACP-MHCNN is composed of several convolutional layers with much larger effective hypotheses space, the sizes of the training partitions of main and alternate datasets are the bottleneck for ACP-MHCNN when it comes to generalization capability. In future work, we need to mitigate this limitation through some data augmentation scheme or self-supervised pre-training or both.
Conclusion
In this study, we propose a new deep neural network architecture called ACP-MHCNN consisting of parallel convolutional groups which jointly learn and combine features from three different peptide representation methods for accurate identification of ACPs. The architecture extracts sequence-based features from residue-order information (using BPF representation), physicochemical property-based features from 31 bit-vector representation of the residues (elements of these vectors depict various physicochemical properties of the amino acids), and evolutionary features from BLOSUM62 matrix-based representation of the peptides.
Although hand-engineered features extracted from these information sources have been successfully employed for ACP identification, automatic feature extraction has hardly been explored for this problem. Before this study, ACP-DL was the only method that has used deep feature extraction for ACP identification32. It has used recurrent layers for extracting features from two residue-order-based peptide representations and leaves significant room for improvement. In the current study, we attempt to address the limitations of ACP-DL by improving the sequence representation and feature extraction methods. For sequence representation, we consider the residues' evolutionary and physicochemical characteristics alongside their ordering so that the downstream feature extraction layers can embed the sequences in spaces with additional discriminative information. For feature extraction, we jointly train three parallel convolutional layer groups so that the combined feature vector contains discriminative patterns extracted from three sources. Our method’s performance could improve further by incorporating some carefully chosen manually extracted features that have been applied successfully in different ACP identification methods through a fourth parallel track with fully connected layers. Additionally, since the BPF representation is sparse, our feature extraction method could benefit from adding an embedding layer at the beginning of the BPF track. Once more experimental training data is available, we would be able to incorporate more parameters in our model without the risk of overfitting and explore these directions. Additionally, we would like to employ embedding techniques used in natural language processing (NLP) tasks, such as Word2Vec58 and FastText59 for k-mer feature extraction. Since these embeddings are local and preserve sequence-order information, sequence representations consisting of these embeddings can be readily added as parallel branches to our model. Furthermore, inspired by the success of self-supervised pre-training on NLP tasks, several pre-trained models for protein sequences have recently been made publicly available. Among them, UDSMProt60, a LSTM sequence model trained on unlabeled Swiss-Prot protein sequences in a self-supervised autoregressive manner has shown remarkable performance on protein-level classification tasks after fine tuning. Another convolutional transformation and attention-based model ProteinBERT61, pre-trained on sequence-correction and GO annotation prediction tasks, has shown impressive performance on protein-level regression tasks after fine tuning. We want to explore the possibility of combining ACP-MHCNN for fine tuning these pre-trained models for ACP identification in future work.
The positive effects of these improvements are manifested in the experimental results obtained on well-established ACP identification datasets, where ACP-MHCNN has significantly outperformed ACP-DL using different evaluation measures for every dataset investigated in this study. Hence, we believe our current study's findings add significantly to the existing knowledge on computational method development for ACP identification. ACP-MHCNN, its relevant codes, and the datasets used in this study are all publicly available at: https://github.com/mrzResearchArena/Anticancer-Peptides-CNN. ACP-MHCNN is also publicly available as an online predictor at: https://anticancer.pythonanywhere.com.
References
Tyagi, A. et al. In silico models for designing and discovering novel anticancer peptides. Sci. Rep. 3, 1–8 (2013).
Shoombuatong, W., Schaduangrat, N. & Nantasenamat, C. Unraveling the bioactivity of anticancer peptides as deduced from machine learning. EXCLI J. 17, 734 (2018).
Chen, W., Ding, H., Feng, P., Lin, H. & Chou, K. C. iACP: A sequence based tool for identifying anticancer peptides. Oncotarget 7, 16895 (2016).
Schaduangrat, N., Nantasenamat, C., Prachayasittikul, V. & Shoombuatong, W. Acpred: A computational tool for the prediction and analysis of anticancer peptides. Molecules 24(10), 1973 (2019).
Mader, J. S. & Hoskin, D. W. Cationic antimicrobial peptides as novel cytotoxic agents for cancer treatment. Expert Opin. Investig. Drugs 15, 933–946 (2006).
Huang, Y., Feng, Q., Yan, Q., Hao, X. & Chen, Y. Alpha-helical cationic anticancer peptides: A promising candidate for novel anticancer drugs. Mini Rev. Med. Chem. 15, 73–81 (2015).
Otvos, L. Jr. Peptide-based drug design: Here and now. Methods Mol. Biol. 494, 1–8 (2008).
Boohaker, R. J., Lee, M. W., Vishnubhotla, P., Perez, J. M. & Khaled, A. R. The use of therapeutic peptides to target and to kill cancer cells. Curr. Med. Chem. 19, 3794–3804 (2012).
Thundimadathil, J. Cancer treatment using peptides: Current therapies and future prospects. J. Amino Acids 2012, 967347 (2012).
Hajisharifi, Z., Piryaiee, M., Beigi, M. M., Behbahani, M. & Mohabatkar, H. Predicting anticancer peptides with chous pseudo amino acid composition and investigating their mutagenicity via ames test. J. Theor. Biol. 341, 34–40 (2014).
Manavalan, B. et al. Mlacp: Machine-learning-based prediction of anticancer peptides. Oncotarget 8, 77121 (2017).
Akbar, S., Hayat, M., Iqbal, M. & Jan, M. A. iACP-GAEnsC: Evolutionary genetic algorithm based ensemble classification of anticancer peptides by utilizing hybrid feature space. Artif. Intell. Med. 79, 62–70 (2017).
Lei, X., Liang, G., Wang, L. & Liao, C. A novel hybrid sequence-based model for identifying anticancer peptides. Genes 9, 158 (2018).
Kabir, M. et al. Intelligent computational method for discrimination of anticancer peptides by incorporating sequential and evolutionary profiles information. Chemom. Intell. Lab. Syst. 182, 158–165 (2018).
Wei, L., Zhou, C., Chen, H., Song, J. & Ran, Su. Acpred-fl: A sequence-based predictor using effective feature representation to improve the prediction of anti-cancer peptides. Bioinformatics 34(23), 4007–4016 (2018).
Charoenkwan, P. et al. Improved prediction and characterization of anticancer activities of peptides using a novel flexible scoring card method. Sci. Rep. 11(1), 1–13 (2021).
Agrawal, P. et al. AntiCP 2.0: An updated model for predicting anticancer peptides. Brief. Bioinform. 22(3), 153 (2021).
Basith, S. et al. Machine intelligence in peptide therapeutics: A next-generation tool for rapid disease screening. Med. Res. Rev. 40(4), 1276–1314 (2020).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521(7553), 436–444 (2015).
Daniel, Q. & Xie, X. DanQ: A hybrid convolutional and recurrent deep neural network for quantifying the function of DNA sequences. Nucleic Acids Res. 44(11), e107–e107 (2016).
Yang, B. et al. BiRen: predicting enhancers with a deep-learning-based model using the DNA sequence alone. Bioinformatics 33(13), 1930–1936 (2017).
Alipanahi, B., Delong, A., Weirauch, M. T. & Frey, B. J. Predicting the sequence specificities of dna- and rna-binding proteins by deep learning. Nat. Biotechnol. 33, 831 (2015).
Bosco, G. L. & Di Gangi, M. A. Deep learning architectures for dna sequence classification. Fuzzy Logic Soft Comput. 10147, 162–171 (2017).
Busia, A. et al. A deep learning approach to pattern recognition for short dna sequences. BioRxiv 2019, 353474 (2019).
Rizzo, R., Fiannaca, A., La Rosa, M. & Urso, A. A deep learning approach to dna sequence classification. Comput. Intell. Method Bioinform. Biostat. 9874, 129–140 (2016).
Wang, L., You, Z. H., Huang, D. S. & Zhou, F. Combining high speed elm learning with a deep convolutional neural network feature encoding for predicting protein-rna interactions. IEEE/ACM Trans. Comput. Biol. Bioinform. 17, 972–982 (2018).
Zou, Q., Xing, P., Wei, L. & Liu, B. Gene2vec: Gene subsequence embedding for prediction of mammalian n6-methyladenosine sites from mRNA. RNA 25(2), 205–218 (2019).
You, Z.-H., Lei, Y.-K., Gui, J., Huang, D.-S. & Zhou, X. Using manifold embedding for assessing and predicting protein interactions from highthroughput experimental data. Bioinformatics 26(21), 2744–2751 (2010).
Wei, L., Ding, Y., Ran, Su., Tang, J. & Zou, Q. Prediction of human protein subcellular localization using deep learning. J. Parallel Distrib. Comput. 117, 212–217 (2018).
Wang, Y. et al. Predicting protein interactions using a deep learning method-stacked sparse autoencoder combined with a probabilistic classification vector machine. Complexity https://doi.org/10.1155/2018/4216813 (2018).
Yi, H.-C. et al. A deep learning framework for robust and accurate prediction of ncrnaprotein interactions using evolutionary information. Mol. Ther. 11, 337–344 (2018).
Yi, H. C. et al. HAcp-dl: A deep learning long short-term memory model to predict anticancer peptides using high-efficiency feature representation. Mol. Ther. 17, 1–9 (2019).
Timmons, P. B. & Hewage, C. M. ENNAACT is a novel tool which employs neural networks for anticancer activity classification for therapeutic peptides. Biomed. Pharmacother. 133, 111051 (2021).
Gu, J. et al. Recent advances in convolutional neural networks. Pattern Recogn 77, 3354–3377 (2015).
Yamashita, R., Nishio, M., Do, R. K. G. & Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 9(4), 611–629 (2018).
Shin, H. et al. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 35(5), 1285–1298 (2016).
Amin, R. et al. iPromoter-BnCNN: A novel branched CNN based predictor for identifying and classifying sigma promoters. Bioinformatics 36, 4869–4875 (2019).
Zeng, H., Edwards, M. D., Liu, G. & Gifford, D. K. Convolutional neural network architectures for predicting DNA–protein binding. Bioinformatics 32(12), 121–127 (2016).
Zhou, X., Hu, B., Lin, J., Xiang, Y. & Wang, X. ICRCHIT: A deep learning based comment sequence labeling system for answer selection challenge. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), 210–214 (Association for Computational Linguistics, 2015).
Chen, T., Ruifeng, Xu., He, Y. & Wang, X. Improving sentiment analysis via sentence type classification using bilstm-crf and cnn. Expert Syst. Appl. 72, 221–230 (2017).
Oh, J., Wang, J. & Wiens, J. Learning to exploit invariances in clinical time-series data using sequence transformer networks. CoRR 85, 332–347 (2018).
Tyagi, A. et al. CancerPPD: A database of anticancer peptides and proteins. Nucleic Acids Res. 43, D837 (2015).
Dwarampudi, M. & Reddy, N. V. Effects of Padding on LSTMs and CNNs. arXiv preprint. arXiv:1903.07288 (2019).
Basak, P. et al. An evolutionary analysis identifies a conserved pentapeptide stretch containing the two essential lysine residues for rice l-myo-inositol 1-phosphate synthase catalytic activity. PLoS ONE 12(9), e0185351 (2017).
Das, J. K., Das, P., Ray, K. K., Choudhury, P. P. & Jana, S. S. Mathematical characterization of protein sequences using patterns as chemical group combinations of amino acids. PLoS ONE 11(12), e0167651 (2016).
Henikoff, S. & Henikoff, J. G. Amino acid substitution matrices from protein blocks. Proc. Natl. Acad. Sci. USA 89(22), 10915–10919 (1992).
Koo, P. K. & Eddy, S. R. Representation learning of genomic sequence motifs with convolutional neural networks. PLoS Comput. Biol. 15(12), e1007560 (2019).
Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Ijcai 14(2), 1137–1145 (1995).
Yarotsky, D. Error bounds for approximations with deep relu networks. Neural Netw. 94, 103–114 (2017).
Kingma, D. P., & Ba, J. Adam: A Method for Stochastic Optimization. arXiv preprint. arXiv:1412.6980(2014)
Narayan, S. The generalized sigmoid activation function: Competitive supervised learning. Inf. Sci. 99(1–2), 69–82 (1997).
Kukačka, J., Golkov, V., & Cremers, D. Regularization for Deep Learning: A Taxonomy. arXiv preprint. arXiv:1710.10686 (2017)
Janocha, K., & Czarnecki, W. M. On Loss Functions for Deep Neural Networks in Classification. arXiv preprint. arXiv:1702.05659 (2017)
Dipta, S. R. et al. SEMal: Accurate protein malonylation site predictor using structural and evolutionary information. Comput. Biol. Med. 125, 104022 (2020).
Muhammod, R. et al. PyFeat: A Python-based effective feature generation tool for DNA, RNA and protein sequences. Bioinformatics 35, 3831–3833 (2019).
Jani, M. R. et al. iRecSpot-EF: Effective sequence based features for recombination hotspot prediction. Comput. Biol. Med. 103, 17–23 (2018).
He, W., Wang, Y., Cui, L., Su, R. & Wei, L. Learning embedding features based on multisense-scaled attention architecture to improve the predictive performance of anticancer peptides. Bioinformatics https://doi.org/10.1093/bioinformatics/btab560 (2021).
Goldberg, Y. & Levy, O. word2vec Explained: Deriving Mikolov et al.'s Negative-Sampling word-Embedding Method. arXiv preprint. arXiv:1402.3722 (2014).
Athiwaratkun, B., Wilson, A. G. & Anandkumar, A. Probabilistic Fasttext for Multi-sense Word Embeddings. arXiv preprint. arXiv:1806.02901 (2018).
Strodthoff, N. et al. UDSMProt: Universal deep sequence models for protein classification. Bioinformatics 36(8), 2401–2409 (2020).
Brandes, N. et al. ProteinBERT: A universal deep-learning model of protein sequence and function. bioRxiv https://doi.org/10.1101/2021.05.24.445464 (2021).
Author information
Authors and Affiliations
Contributions
S.A. conceived and initiated this study. S.A., R.M.Z.H. performed the experiments. S.A., S.Ad., A.S., S.S. and A.D. wrote the manuscript. Z.H. helped with literature review and designed the online server. A.D., S.S. mentored and analytically reviewed the paper. All the authors reviewed the article.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ahmed, S., Muhammod, R., Khan, Z.H. et al. ACP-MHCNN: an accurate multi-headed deep-convolutional neural network to predict anticancer peptides. Sci Rep 11, 23676 (2021). https://doi.org/10.1038/s41598-021-02703-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-02703-3
This article is cited by
-
HormoNet: a deep learning approach for hormone-drug interaction prediction
BMC Bioinformatics (2024)
-
ACPred-BMF: bidirectional LSTM with multiple feature representations for explainable anticancer peptide prediction
Scientific Reports (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
