
Abstract
Global environmental research requires long-term climate data. Yet, meteorological infrastructure is missing in the vast majority of the world’s protected areas. Therefore, gridded products are frequently used as the only available climate data source in peripheral regions. However, associated evaluations are commonly biased towards well observed areas and consequently, station-based datasets. As evaluations on vegetation monitoring abilities are lacking for regions with poor data availability, we analyzed the potential of several state-of-the-art climate datasets (CHIRPS, CRU, ERA5-Land, GPCC-Monitoring-Product, IMERG-GPM, MERRA-2, MODIS-MOD10A1) for assessing NDVI anomalies (MODIS-MOD13Q1) in two particularly suitable remote conservation areas. We calculated anomalies of 156 climate variables and seasonal periods during 2001–2018, correlated these with vegetation anomalies while taking the multiple comparison problem into consideration, and computed their spatial performance to derive suitable parameters. Our results showed that four datasets (MERRA-2, ERA5-Land, MOD10A1, CRU) were suitable for vegetation analysis in both regions, by showing significant correlations controlled at a false discovery rate < 5% and in more than half of the analyzed areas. Cross-validated variable selection and importance assessment based on the Boruta algorithm indicated high importance of the reanalysis datasets ERA5-Land and MERRA-2 in both areas but higher differences and variability between the regions with all other products. CHIRPS, GPCC and the bias-corrected version of MERRA-2 were unsuitable and not important in both regions. We provide evidence that reanalysis datasets are most suitable for spatiotemporally consistent environmental analysis whereas gauge- or satellite-based products and their combinations are highly variable and may not be applicable in peripheral areas.
Similar content being viewed by others

Introduction
Peripheral regions are important refuges for endangered species and pristine vegetation communities. Therefore, numerous conservation areas were established in such locations and long-term monitoring measures have shown to be vital for analysis of global environmental changes1,2. Apart from direct anthropogenic impacts, climate variables are the decisive drivers of vegetation variations and strong shifts are predicted in this type of regions2,3. Hence, long-term climate datasets are essential for understanding potential ecosystem changes. However, remote regions are often also characterized by poor meteorological infrastructure. This is clearly illustrated by the comparison of national park areas4, here defined as IUCN Category II protected areas, and the GPCC full data product5, the world’s largest precipitation station data base6, that shows that 92% of the area of terrestrial national parks is situated in raster cells without available station data during the last climate normal period 1981–2010 (Appendix 1). There has also been a global decline in the availability of gauge precipitation data since the 1990s6. Inadequate or no station data may lead to poor performance of gridded precipitation products and also limits possibilities of independent product evaluation7,8,9. The temporal variations introduce additional analytical uncertainties and although a large number of station-based evaluations exist10,11,12,13,14, their results are generally not transferable to regions with poor station data infrastructure9. Finally, station-based evaluation studies may suffer from a positive bias by utilizing the same or similar stations as those integrated in the gridded datasets.
Consequently, effective monitoring of the world’s protected areas, and vegetation change in general, requires an assessment of spatial climate products and variables in remote areas and their ability to explain vegetation anomalies. Several studies analyzed the relationship between normalized difference vegetation index (NDVI) variations and selected spatial climate datasets over larger areas15,16,17,18,19. However, comprehensive research approaches on the performance of potentially available climate datasets and variables in remote regions are missing. Relevant research on mountain areas is scarce and shows no significant climate-vegetation-relationships or only very low correlations in large parts of these regions even with some of the most popular datasets16,18,19. Furthermore, most studies working with medium resolution NDVI data in remote areas concentrate on one single variable or climate dataset and a comparison of the performance of different products is missing20,21,22,23,24. Therefore, scientific insights into the reliability of the various spatial climate products for detecting ecological change in regions with insufficient station data are lacking.
In order to close this research gap, and to identify applicable products for analyzing biological changes in peripheral ecosystems with poor meteorological infrastructure, we evaluate a large set of recent state-of-the-art gridded climate products and their ability to explain vegetation anomalies in two remote national parks of Afghanistan. These parks are particularly suitable to assess correlations of vegetation and gridded climate products in remote locations due to their cool, arid to semi-arid setting and the associated coupling of water availability and temperature with vegetation productivity, their complex topography, limited or absent station data, influence of different climate regimes and the very low proportion of direct agricultural activities such as tillage or irrigation9,25,26,27,28. To cover vegetation changes in complex terrain, we used NDVI anomalies from the moderate resolution MODIS product MOD13Q129 during the period 2001 to 2018. Gridded climate products were selected based on their currentness, their temporal coverage, their station-assessed performance in other regions9,13,30, and to encompass various product categories as given in Sun et al.31. Additionally, we also include the MODIS snow product MOD10A132 as a spatial climate indicator because snow variables were significantly affecting vegetation anomalies in existing studies23,33,34,35. In summary, we utilize CHIRPS 2.036, CRU TS4.0337, ERA5-Land38, the GPCC Monitoring Product Version 639, IMERG GPM40, MERRA-241 and MOD10A132 to derive test variables for the analysis. Our leading hypothesis is that climate datasets that are less dependent on observational data, such as reanalysis and satellite products, outperform gauge-based raster data in regions with poor station data availability. Furthermore, we expect the high-resolution snow product to be particularly suitable for explaining vegetation anomalies compared to the other, relatively coarse datasets. Therefore, we aim to present a reliable spatial methodology to answer the following main research questions: (i) Which state of the art climate products, climate variables and temporal intervals are suitable to assess vegetation anomalies in remote protected areas?; (ii) How strong is the correlation between climate and vegetation anomalies and what is the areal extent of the correlation?; and (iii) Are the results transferable between regions?
Methods
Study area
We chose protected areas in Wakhan and Band-e-Amir national parks in Afghanistan for this study, as they represent two different environmental settings with diverse influencing climate systems. The Wakhan study area is located in the high mountains of the Pamir and Hindukush with elevations between 2,900 and 6,300 m (Fig. 1). The climate is cold and dry, with an average precipitation of about 200 mm in the valleys, and represents the transition zone from the Westerlies to the Indian summer monsoon with precipitation maxima in spring and summer9,27. The region forms the headwaters of a main Central Asian stream, the Amu Darya, rendering it crucial for large scale water supply42.

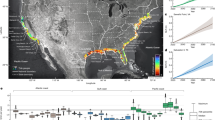
Overview of (a) the research areas with an overlay of missing station data in the GPCC Monitoring Product 2001–2018 (EPSG 4326), (b) the Band-e-Amir (EPSG 32642 with 20 km grid overlay), and (c) the Wakhan research areas (EPSG 32643 with 20 km grid overlay). Monthly missing station data in the lower Band-e-Amir cell is 98% (GPCC data:39, relief data:43,44). Created using QGIS 3.12 (http://qgis.osgeo.org/)45.
A large number of rare or vulnerable species exists, including the snow leopard (Panthera uncia) or the Marco polo sheep (Ovis ammon polii), and the diverse flora harbors about 20% of endemic species28,46. Varying water availability and temperature regimes lead to well-defined vegetation communities with riparian areas, dwarf-shrub cushion steppes, alpine grasslands and scree vegetation or glaciers at very high altitudes cf.47. The selection of the research boundaries, enclosing a total area of 17,000 km2, was based on an existing classification raster of vegetation communities which served to exclude non-vegetated areas and detect potential differences between vegetation classes. The Band-e-Amir study area, comprising Afghanistan’s first national park, is located in the west-central Hindukush mountains with elevations from 1,600 m to 4,300 m. In winter and spring, climate is dominated by cyclone offshoots from the west which intensify in spring48. During summer months, the entire region is influenced by an almost stationary subtropical high-pressure cell. This causes a characteristic precipitation pattern with a maximum in spring and almost no precipitation during summer months26. Vegetation comprises azonal riparian communities and dwarf-shrub cushion steppes reaching up to the highest elevations. Glaciers do not exist in this region. The protected areas provide habitat to several endemic plants, birds and vulnerable mammals, such as the Persian leopard (Panthera pardus tulliana), urial (Ovis orientalis) or Pallas cat (Otocolobus manul), and they include the unique travertine dammed lakes of Band-e-Amir26,49,50,51. Economically, both regions are dominated by pasture farming and only small areas are used for cropping.
Methodological principle and utilized datasets
Our methodology is based on the well-established concept that vegetation conditions are dependent on the climate52,53, in turn leading to close coupling of associated anomalies18. This holds especially true for arid to semi-arid regions54. In the absence of independent station data, i.e. data that is not included in the gridded products as well, we make use of this knowledge in the evaluation of gridded climate datasets. Where climate datasets accurately represent regional climate conditions, a robust correlation with the vegetation status of large parts of relatively pristine regions can be expected, and such correlation should be observed for different types of datasets55. In contrast, climate datasets that do not adequately represent regional climate conditions are unlikely to show significant and robust correlations with temporal variations of vegetation. The level of direct human activities in the selected study areas with the potential to interfere with the relationships of climate and vegetation is low and moreover, would affect all datasets in a similar way. Therefore, the connection of climate variables with vegetation conditions is used as important proxy to assess the suitability of the products in peripheral regions.
The following sections provide an overview of the datasets used in our analyses together with a rationale for their selection. All these datasets were originally obtained with the help of sophisticated creation algorithms. A comprehensive description of the datasets is out of scope of this study and can be found in the cited literature .
MODIS NDVI: MOD13Q1
Vegetation data was used as the variable of interest of this study. We selected MODIS NDVI to derive vegetation anomalies as it is an essential and widely used parameter for vegetation monitoring and change detection56. To obtain optimal pixel values, we used the MOD13Q1 product. It provides 16-day NDVI values with a resolution of 250 m and a temporal coverage from February 2000 to present and is generated from a daily dataset based on several quality criteria such as low clouds and high NDVI29. In analogy to existing anomaly research57, to avoid potentially varying effects of different gap-filling approaches due to changing regional performance58,59, to minimize possible influence of snow effects and seasonally poor vegetation conditions in mountains33, and to maximize the generally low vegetation signal in drylands60, we used the mean maximum NDVI during and after the peak of the vegetation period to derive vegetation anomalies. Vegetation peaks occur during June and July in the Band-e-Amir region and during July and August in Wakhan, respectively. As snow effects in summer months are unlikely in the Band-e-Amir region, we also included the month of August in our analysis of this region to achieve consistency with averaging periods of climate variables as described in the corresponding section of this publication. Therefore, the original data was averaged to monthly maximum values, reprojected to the UTM reference system and then clipped to the research areas. Finally, vegetation peak anomalies (Wakhan: July–August, Band-e-Amir: June–August) for each year of the period 2001–2018 were calculated while the mean value of the whole period served as a reference, resulting in a time series of annual vegetation anomalies covering 18 years. Autocorrelation posed a possible issue in this time series—either by inflating correlations due to superposition of global climate patterns or by interfering with significance testing. By applying the method outlined by Hyndman61 we were able to confirm for both areas, Wakhan and Band-e-Amir, that autocorrelation did not present itself as a confounding factor.
CHIRPS 2.0
The Climate Hazards Group InfraRed Precipitation with Station data (CHIRPS) is a gridded precipitation dataset with a resolution of 0.05° ranging from 1981 to near present that has been developed for data sparse regions by combining a variety of station data, a multitude of satellite observations (thermal infrared, microwave) and forecast models36. Existing research shows good performance of the data in other regions30. The CHIRPS product was utilized to derive precipitation variables.
CRU TS4.03
The Climatic Research Units’ (CRU) most recent product version TS4.03 is a spatial climate dataset with a 0.5° resolution covering the period 1901 to 2018 which is derived from interpolated station values using a long-term climatology37. We included this dataset as it is one of the most widely used climate products19,20,62. In this study, precipitation and temperature variables were derived from this product.
ERA5-Land
At 0.1°, ERA5-Land is a higher resolution version of the European Centre for Medium-Range Weather Forecasts ERA5 climate reanalysis dataset with a coverage from 1981 until present. It has been available since mid-2019 (publication date 2019-Jul-12) and is thus one of the latest reanalysis datasets. Reanalysis data combines models and observational inputs into a consistent product based on physical principles38. The starting point of a reanalysis dataset is a numerical weather prediction model. ERA5 uses the Integrated Forecast System cycle 41r2 (Cy41r2), which is combined with a large number of observations (observations of wind, temperature, relative humidity and pressure from in-situ and upper-air soundings, airplane measurements, a multitude of satellites, rain rate from ground-based radar–gauge composite observations since 2009,…) by means of data assimilation techniques63. Thereby, a cost function is minimized so that the final analysis is close to the forecast and the observations. For ERA5, a linearized quadratic 4D-Var cost function is used for data assimilation in the atmosphere. For land surface variables, ERA5 implements the land data assimilation system (LDAS), which is connected to 4D-Var63. The approach, which is used to construct a long-term climate dataset by combining data of past periods with the current model, is usually referred to as “reanalysis” or “retrospective analysis”64. This dataset is a promising candidate for deriving valuable climate parameters of remote mountain regions, because of its high resolution and its foundation in physical laws. The dataset offers a large number of climatic variables. In this analysis, we used temperature, precipitation, snow cover, soil water in the uppermost layer and skin reservoir content. Soil water content is defined as the volume of water from the surface (0 cm) to 7 cm depth in m3/m3. The skin reservoir includes water on vegetation and on soil, i.e. dew and water intercepted by plants38.
GPCC Monitoring Product Version 6
The dataset is based on the interpolation of precipitation anomalies from long term climatologies using gauge data in a resolution of 1° and a temporal coverage from 1982 to two months before present39. In several evaluation studies, GPCC precipitation products outperformed other datasets65,66,67 and it is considered as the largest precipitation database worldwide6. We utilized precipitation variables from the near-realtime monitoring product, referred to as GPCC MP in this manuscript, because the more accurate full data product currently ends in 2016.
IMERG GPM
Integrated Multi-satellitE Retrievals for GPM (IMERG) with a resolution of 0.1° and a data range from mid-2000 to present uses multiple passive microwave satellite observations which are adjusted with gauge observations40. Different versions of this product exist and we selected the current version 06B final run for our analysis. This product is usually available 3.5 months after the observation and includes gauge analysis, forward and backward morphing. We included precipitation variables from this relatively new satellite product as previous research showed good performance in complex terrain68.
MERRA-2
The Modern-Era Retrospective analysis for Research and Applications version 2 (MERRA-2) is a reanalysis product with a 0.5° X 0.625° resolution and a data range from 1980 to present41. We used the 2d, Monthly mean, Time-Averaged, Single-Level, Assimilation, Surface Flux Diagnostics V5.12.4 product for our analysis (MERRA-2 tavgM_2d_flx_Nx). In analogy to ERA5, it delivers a large range of climate variables. The numerical weather prediction model in this reanalysis dataset is the Goddard Earth Observing System Model, Version 5 (GEOS-5). To combine the model and observations, the Atmospheric Data Assimilation System (ADAS), version 5.12.4 is applied. The analysis is processed with a three-dimensional variational (3DVAR) algorithm based on a Gridpoint Statistical Interpolation (GSI) analysis scheme and a first-guess-at-appropriate-time (FGAT) procedure69. The analysis is used to correct the forecast system state with an incremental analysis update (IAU). Compared to previous versions, a major advancement of this product is the additional assimilation of space-based aerosol observations69. We used 2 m temperature (referred to as temperature 2 m), surface air temperature (referred to as temperature), precipitation and gauge-corrected precipitation from this product. The uncorrected precipitation is the amount generated by the model without surface observations of precipitation, whereas the corrected precipitation is derived using globally available products based on surface observations69,70.
MODIS snow: MOD10A1 V6
Snow is considered a major climate factor influencing vegetation growth in cold drylands23,33,71,72. The MODIS MOD10A1 V6 product provides daily Normalized Difference Snow Index (NDSI) data from the Terra satellite with a resolution of 500 m from February 2000 until present32. To remove cloud cover and other invalid pixels, we performed a simple gap-filling approach. All pixels with > 60% of invalid data during the time series from 2001 to 2018 were excluded from the analysis as they were considered unsuitable for the gap-filling approach. However, only 5% of the area was affected by this criterion in the Wakhan region and no pixels with > 60% missing data were found in the Band-e-Amir region. In the remaining pixels, gaps were filled by a linear interpolation method. Invalid cells at the beginning and end of the time series were filled using the closest available value. Although several gap-filling approaches exist, we selected this approach due to its simplicity, transferability, user-friendliness, independence and effectiveness cf.73. After gap-filling, we derived two additional snow metrics in addition to the raw NDSI, fractional snow cover (FSC) and snow cover duration (SCD). FSC was calculated based on the formula given in Salomonson and Appel74 as:
Values below zero and above 100 were truncated to 0% and 100%. SCD was calculated as the sum of days with NDSI above 0.2 following Riggs et al.75. All daily estimates were finally aggregated to monthly values. In the near future, a gap-filled version of the product, MOD10A1F, will be available from the NASA Distributed Active Archive Center (DAAC) at the National Snow and Ice Data Center73.
All climate datasets were reprojected and resampled to match the NDVI dataset using nearest neighbor interpolation. While different resampling techniques exist, we selected this approach to preserve the original dataset values76, and avoid variations related to resampling as stated in existing research77.
Vegetation classification
Vegetation classifications are frequently used to support studies on vegetation-climate relationships19,22,62. As substantial areas in the Wakhan region are permanently covered by glaciers, snow or rocks, information on vegetated areas from an existing supervised classification was used to exclude such unvegetated regions. The respective classification utilized 370 field mapped ground truthing points and cloud free, Sentinel 2 satellite images from 2018 with a random forest classification approach and showed a validated overall accuracy of 92%78,79. The original classification was reprojected and resampled to match the NDVI dataset. Finally, all non-vegetated pixels of the spatial datasets were excluded from the analysis in the Wakhan region. Furthermore, the classification was used to test for potential differences between riparian vegetation, dwarf-shrub cushion steppes and alpine grasslands. In the Band-e-Amir region, no classification was used as no glaciers or permanent snow exist and the whole area is potentially vegetated.
Selection of averaging periods for climate variables
Vegetation response to climate variations is characterized by significant temporal and spatial variability19. Therefore, ideal temporal averaging periods depend on the specific environment and the derivation must be based on individual vegetation-climate interrelationships of the research area. A frequently used variable is the hydrological year21,23,35. We slightly adapted this to match vegetation growth and defined the hydrological year in our research area as the 12-month period before the vegetation peak. Therefore, hydrological year anomalies were calculated based on averages from July of the previous year until June of the year in question, i.e. the year of the vegetation anomaly. By controlling soil moisture availability until summer and determining the start of the growing season, winter and spring climate conditions may be among the most important factors influencing vegetation growth16,19,34. We calculated several anomaly periods that consider the respective seasons accordingly: winter half year (November to April), Spring (March–May) and the transition period February to March. Finally, summer was also reported as relevant for Central Asian ecosystems16,72. Hence, we included the summer period (June–August) and the combined spring–summer period (March-August). MODIS snow variable anomalies were not calculated for time periods including summer months. In addition to influences of the current year, long-term responses of vegetation to climate variations exist, especially in semi-arid regions16,80,81. Therefore, we also included two-year averages of all seasonal climate variables. All anomalies were calculated with the respective average of all years as a reference value.
Statistical analysis
The multitude of analyzed climate datasets, variables and the different temporal periods led to a total number of 156 potential features for analyzing vegetation anomalies. Most existing studies are either based on pixel correlations16,19,23,33 or correlation analysis of regionally averaged anomalies62. As both approaches provide valuable information, the former on the spatial performance and pattern, the latter on the strength of the overall correlation, we combined respective approaches. To assess which products are suitable for explaining vegetation anomalies for each region in general, we performed correlation analyses using area averaged anomalies. However, hypothesis testing with the large number of potential features leads to a multiple testing problem as 200 independent hypothesis tests at the 5% significance level would lead to the expectation of 10 false rejections of the null hypothesis. Therefore, we applied the Benjamini–Hochberg procedure82 to compute adjusted p value thresholds for all climate variables controlling the false-discovery rate (FDR) at a level of 5%. The respective approach was successfully applied by existing remote sensing studies83,84. To asses uncertainty of the correlation coefficients, we computed bootstrap bias-corrected and accelerated (BCa) 95% confidence intervals85 using 2500 replicates as respective method showed good performance in comparable studies86,87. A per pixel analysis was conducted in addition to area averaged significance tests to derive information on the spatial performance of variables following the methodology of Abdi et al.88. Thereby, we computed correlation and p values for each cell and summarized the percentage of significant pixels (p ≤ 0.05) in relation to the analyzed total area. By combining both approaches, we aim to achieve a consistent picture on the temporal and spatial performance of climate variables and their ability to explain vegetation differences.
Climate product variables are considered as good explanatory variables for vegetation anomalies if they show a significant overall correlation controlled at a FDR < 5%, and if the correlation is significant in the majority (≥ 50%) of analyzed pixels. Respective variables are referred to as highly suitable variables in this manuscript. In the Wakhan research area, we conducted this analysis separately for the vegetation classes riparian vegetation, dwarf-shrub cushion steppes and alpine grasslands to assess community-based differences.
We selected Pearson’s correlation coefficient as the main statistical method as preliminary studies in comparable environments suggested a linear relationship between vegetation anomalies and climate data16,19,23,34,53,81. However, some studies state a non-linear response of vegetation to climate variations18. To also consider non-linear interlinkages, we repeated the analysis using Spearman rank correlation to assess potential differences of the different methods. As results are expected to be variable due to the high dimensionality and the comparably low number of available years, we additionally assessed the stability of suitable datasets using different variable selection approaches in a prediction context. We applied two different methods in this study, as a comparison of different approaches is suggested if modeling is performed with high dimensional data89. One approach, which is methodologically comparable to our correlation analysis, is the calculation of models with single stepwise forward selection based on Pearson’s correlation and 100 repeated, threefold cross-validation cf.84. Thereby, we quantified the proportion of the selection as the best variable in relation to the total number of selections. Additionally, we chose the Boruta algorithm to assess variable importance and selection, as it is considered as the most powerful approach in high dimensional settings by recent studies90. In this approach, variables are randomly shuffled to create shadow variables, and importance scores are then calculated using these shadow variables and original predictors, i.e. the climate variables, to predict vegetation anomalies with a random forest regression91. Finally, only variables that have significantly higher scores than the shadow variables are considered as important92. We used the R package Boruta with a maximal number of importance source runs of 500 and a p value of 0.05. As the process is variable due to stochasticity of the random forest classifier91, we repeated the whole procedure 500 times and quantified the percentage of confirmed selections and the mean importance of selected variables over all repetitions.
Results
Overall correlations and highly suitable variables
The comparison of correlation methods showed that highly suitable variables for analyzing vegetation anomalies were almost identical in the Spearman and Pearson approach (Tables 1, 2, Appendix 2, Appendix 3). Generally, more variables were considered as highly suitable with the latter, linear method. Therefore, we focus on the presentation of results using the Pearson correlation in this section. Results showed that only variables of four products, MERRA-2, ERA5-Land, MODIS MOD10A1 and CRU, may be considered as highly suitable for vegetation analysis in the Wakhan research area (Table 1).
In total, 18 variables were considered as good explanatory variables, including eight from the MOD10A1 product, five from MERRA-2, four from ERA5-Land and one from CRU. All variables showed positive correlations and were directly or indirectly associated with precipitation. Temperature anomalies did not show significant correlations. Reanalysis datasets were ranked highest in both correlation coefficient and percentage of significant pixels. MERRA-2 precipitation during the hydrological year performed best with a R of 0.82 with 95% BCa confidence interval [0.6/0.91] and with 78% of the analyzed pixels showing a significant correlation. Other MERRA-2 precipitation variables showed similar correlations. ERA5-Land and MODIS snow variables also indicated good performance for explaining vegetation anomalies. CRU precipitation was also a highly suitable variable in the research area. CHIRPS, GPCC MP and IMERG, as well as the gauge corrected variables of MERRA-2 were not significant and did not provide highly suitable variables in the Wakhan research area. Temporal periods comprised different time sections whereby most included spring months.
The Band-e-Amir analysis resulted in 49 highly suitable variables (Table 2). Thereby, five were derived from the CRU product, 22 from ERA5-Land, three from IMERG, 11 from MERRA-2 and eight from the MODIS snow product. The majority of suitable variables (n = 37) were associated with precipitation and positively correlated with vegetation anomalies. However, 12 temperature variables indicated negative correlations with vegetation. Reanalysis datasets resulted in the highest correlation coefficients and percentage of significant pixels. ERA5-Land precipitation during the hydrological year performed best with a R of 0.92 with 95% BCa confidence interval [0.72/0.97] and 97% of the pixels showing a significant correlation. MERRA-2 precipitation products resulted in slightly weaker performance. CRU and IMERG showed lower correlation values but most pixels were significant. MODIS snow variables were found to be highly suitable but regions with significant correlations were smaller. Regarding temperature variables, ERA5-Land and MERRA-2 resulted in the highest correlations and the largest percentage of significant raster cells. In terms of the temporal periods, spring months were again included in the majority of the highly suitable variables. CHIRPS, GPCC MP and the gauge corrected MERRA-2 precipitation variables were not among the important explanatory variables.
Regarding the variation in a prediction context, the occurrences of datasets and variables averaged over all repeated stepwise variable selections and folds (n = 300) showed a considerable majority of the best datasets in both regions (Table 3). In Wakhan, 61% of the best variables were MERRA-2 precipitation parameters and in Band-e-Amir, 78% were ERA5-Land hydrological parameters. The other selected product variables were similar to the overall correlation analysis, but the percentage of selection was low.
The 500-repeated Boruta algorithm showed that reanalysis datasets had the highest importance and were considered as important in all repetitions in both research areas (Table 4). In Band-e-Amir, the IMERG dataset was also among the most important products and temperature variables of reanalysis datasets were listed as well. Furthermore, CRU precipitation was considered as important variable in both regions. In Wakhan, CRU temperature and, to a lesser extent, MODIS snow anomalies were also among the important variables. GPCC, CHIRPS and the bias corrected version of MERRA-2 were not listed as important variables.
The visual comparison of anomalies of different climate data products with the highest correlations showed relatively similar directions to NDVI anomalies in most years although magnitudes were different between the products (Fig. 2). In general, consistency between climate data and NDVI was considerably higher in the Band-e-Amir region. Regarding climate datasets in Wakhan, there was higher agreement between the reanalysis datasets compared to MODIS snow cover. In Band-e-Amir, anomaly directions of datasets were almost identical with two exceptions of the IMERG product.

Standardized anomalies of the three highest correlated variables selected from different climate data products (colored bars) compared to MODIS NDVI anomalies (green line) in the Wakhan region (a) and the Band-e-Amir region (b). Created using R 4.0.3. (https://www.R-project.org/)93.
Spatial correlation patterns
The spatial pattern of significant values generally showed large agreement regarding the non-significant areas between the three best variables selected from different products in both research areas (Figs. 3, 4). Most non-significant regions were located in valleys and near rivers. In the Wakhan region, higher correlations were found for the northwestern area with lower values in the southeast. Furthermore, the MODIS snow product indicated more non-significant areas in the eastern valleys compared to the other products. In the Band-e-Amir region, reanalysis datasets showed much higher correlations in many areas. Generally, lower correlations were found in lowlands and basins in the northeast, southeast and southwest. Higher correlations were generally found in the northwest and central regions.

Vegetation units (a), significant Pearson’s correlation of MERRA-2 precipitation/Hydrological-year (b), ERA5-Land precipitation/Spring–Summer (Mar-Aug) (c), and MODIS-NDSI/Spring (Mar-May) (d) in the Wakhan region (projection: UTM zone 43 N). Created using QGIS 3.12 (http://qgis.osgeo.org/)45.

Significant Pearson’s correlation of ERA5-Land precipitation/ Hydrological-year (a), MERRA-2 precipitation/ Hydrological-year (b), and CRU precipitation/ Hydrological-year (c) in the Band-e-Amir region (projection: UTM zone 42 N). Created using QGIS 3.12 (http://qgis.osgeo.org/)45.
The separate analysis of different vegetation units in the Wakhan region illustrated some community related differences with 32 highly suitable variables in alpine grasslands, 15 in dwarf-shrub cushion steppes and only four in riparian communities (Appendix 4). Many variables were similar to the combined analysis but in alpine grasslands, CRU temperature was also among the highly suitable variables with a significant negative correlation (e.g. Pearson’s r of − 0.66 for CRU temperature/Spring two-year average). Furthermore, significant correlations with NDVI anomalies were found on larger areas in this vegetation unit, especially with snow variables (e.g. 75% of significant pixels with MODIS-NDSI/Spring). In dwarf-shrub cushion steppes, variables were similar to the overall analysis with a slightly better performance of the best variables (MERRA-2 precipitation hydrological-year r = 0.84 and 79% significant pixels). Main differences were found for riparian communities where only MERRA-2 precipitation variables were considered highly suitable.
Discussion
This is the first research approach that systematically assesses and compares the potential of multiple state-of-the-art gridded climate datasets for analyzing vegetation change in peripheral protected areas with lacking meteorological infrastructure. Results clearly show that reanalysis datasets are most suitable in respective regions and that this outcome is consistent between different research areas and between different cross validation folds. These findings are supported by some studies successfully utilizing reanalysis datasets in ecological21,94,95,96, hydrological97 or epidemiological research98. Furthermore, Dee et al.99 consider reanalysis products as the most accurate and homogenous datasets in recent decades which is in agreement with this study. Reanalysis datasets may also provide advantages in regions with a considerable proportion of snow among total precipitation as they are not affected by undercatch errors that frequently lead to measurement errors between 20 to 50% in station data9,100. However, comparisons between different products are scarce and most studies used station-based datasets such as CRU or GPCC to analyze vegetation anomalies16,19,20,62,80,101,102. This widespread utilization of station-based datasets for ecological research may be due to the existence of numerous research approaches that evaluated raster products with gauge data and stated good associated performances11,13,65,66,67,103. However, these studies may be positively biased due to overlap of validation and incorporated stations and by ignoring temporal variations in gridded datasets9. Although station-based interpolations may constitute important predictors for vegetation change in many regions, which was also partly valid in this study for CRU TS4.03, the presented analysis indicates that those datasets are less suitable for vegetation anomaly analysis in peripheral regions compared to reanalysis datasets. In both research areas, variables of the GPCC MP are unsuitable for analyzing vegetation anomalies. However, if it is required to analyze long time spans of 100 years or more, only gauge datasets are available. The presented findings provide evidence that CRU TS4.03 is better suited for vegetation analysis in data-poor regions of Central Asia compared to the GPCC MP but this may be regionally variable. Our results also indicate that the MODIS snow product provides important climate variables in cold drylands which is supported by research for other regions23,33 whereby significant correlations are higher and more extensive in the Wakhan region of this study. Although respective variables were also highly suitable for analyzing vegetation anomalies in the Band-e-Amir region, the considerably lower correlation values imply strong regional differences. However, the fine spatial resolution of the MODIS snow product in comparison to the other, relatively coarse datasets suggests large potential of this variable for finer scale analyses. The derivation of snow cover using time series of moderate to high resolution sensors with appropriate temporal resolution, such as Sentinel-1 or Sentinel-2104,105, may be promising for deriving climate indicators in the future.
Variables of the satellite based IMERG dataset revealed only weak, non-significant relationships with vegetation anomalies and thus are unsuitable for explaining vegetation variations in the Wakhan region. However, in the Band-e-Amir area, this product was not among the highest correlated variables, but it is a suitable climate dataset. The latter result is backed by other studies that successfully applied IMERG GPM data for drought monitoring or productivity analysis106,107. The unsuitability of IMERG GPM in the high mountain Wakhan region may be explained by the worsened performance and precipitation underestimation in higher altitudes as outlined by Lu et al.108. Surprisingly, the CHIRPS 2.0 data; which was explicitly designed for monitoring global environmental change in data sparse regions and which showed good results in Africa30,109, is not suitable for analyzing vegetation changes in both of our research areas. A major reason for this may be the limited ability of the algorithm to detect snowfall as shown by Bai et al. in China110. Furthermore, this product combines two data types that were not or only partly suitable in the respective regions, as it uses interpolated station data similar to GPCC, and the satellite based Tropical Rainfall Measuring Mission Multi-satellite Precipitation Analysis which is the predecessor to IMERG GPM109. Therefore, our analysis indicates that the performance of CHIRPS may be problematic in some remote mountain areas outside of Africa. Another remarkable result is that the bias-corrected version of MERRA-2 is unsuitable for vegetation change analysis in our study as opposed to the uncorrected version that ranked among the best datasets. This is in contrast to existing research which showed improvement of reanalysis data for hydrological analysis after observation based bias correction in North America111. However, the density of observation data is comparably high in North America and hence, bias correction approaches are more likely to improve reanalysis data in those areas. In regions with poor meteorological infrastructure, where only a small number of stations is available that are potentially located far from the raster pixel in question, the correction algorithm may potentially distort the physically based reanalysis model. Furthermore, mountain regions may be particularly susceptible to errors based on small station numbers as many regions are not sufficiently represented in complex topography9.
Regarding the different variables, precipitation was positively correlated to vegetation anomalies and can be considered as the most suitable variable for predicting vegetation anomalies. This result is typical for drylands where vegetation growth is usually constrained by precipitation whereas it is more resilient to temperature anomalies18,19. However, temperature anomalies are important in some regions and negative correlations indicate indirect effects on plant available water by increasing snowmelt and evapotranspiration. These findings partly contradict results of other regions where spring temperature showed a positive correlation with vegetation but was in agreement concerning summer temperatures with negative correlations62. This shows that temperature effects on vegetation may be highly variable on spatial and temporal scales34. The biological importance of the spring season is supported by other results and underlines that different time periods influence vegetation variations19,34. Similarly, results also showed that long term anomalies are important in explaining yearly vegetation anomalies in dryland regions16. The yearly precipitation sum before the vegetation peak, i.e. the hydrological year, was the most important temporal period which shows that all seasons have impacts on vegetation anomalies. Their combination in anomaly calculation may therefore contribute to vegetation change analysis despite missing correlation of some individual seasons with vegetation.
The 100 repeated threefold cross validation and the 500-repeated Boruta algorithm showed that there was some variability of the best variables when different years are considered, but in most folds and repetitions, the same products were selected as in the overall correlation and spatial performance analysis. This indicates that the results are robust over various yearly feature sets. However, it is important to consider notable uncertainties of the correlation coefficients due to the limited number of years, as indicated by the 95% BCa confidence intervals with wide intervals for variables with lower overall correlation. Furthermore, the multi-variate Boruta approach also showed that some climate datasets, such as the IMERG product in Band-e-Amir, may provide important additional information that may not be included in the reanalysis products. Some datasets were also not considered as important with this method if compared to the correlation analysis, such as the MODIS snow variables in Band-e-Amir. This may be due to multi-collinearity among variables and no new information compared to the better performing reanalysis datasets. Although dataset performance was partly consistent between the regions, especially regarding reanalysis data, the correlation was higher for most variables and more products were found to be suitable for vegetation change analysis in the Band-e-Amir region. The climatic situation of the research areas is one important reason for this difference. The Band-e-Amir region represents a relatively stationary, large scale climate system in Central Asia with seasonally dominating pressure systems48. Therefore, anomalies of distant climate stations may be also representative for this region. This situation stands in stark contrast to the Wakhan area which forms the boundary between different climate influence zones, the Westerlies and the Indian summer monsoon27. A transition zone leads to a complex situation with spatially and temporarily varying moisture sources and suitable climate products must equally represent both climate systems. This may be impossible for station-based datasets when they are characterized by low gauge density7,8. Similarly, satellite data and combined datasets may not be sufficiently calibrated to the regional conditions or to represent both climate systems112,113.
The spatial pattern of the correlations also suggests a better representation of precipitation originating from the west, with higher correlation values in Wakhan in the northwest compared to the increasingly monsoonal influenced southeast. However, the majority of the spatial patterns may be explained by small scale differences. In both regions, most non-significant areas were found in valleys and hydrological sinks. The missing correlation in those regions is based on the dominance of other drivers for vegetation growth which are not immediately influenced by climatic variations. Direct human activities, such as agriculture and tillage, which are mostly found in the vicinity of rivers due to the need of irrigation for crops26,114, leads to the decoupling of climate and vegetation anomalies cf.16. This may be especially true for the Band-e-Amir region and low altitude areas in Wakhan. The separate analysis of different vegetation communities in Wakhan also shows the influence of different ecological drivers. In riparian vegetation communities, precipitation of only one dataset (MERRA-2) was highly suitable for explaining vegetation anomalies and the spatial extent of significant correlations was lower. This indicates that other factors, such as glacial meltwater, flooding or precipitation upstream of the watershed, are also important for variations in vegetation anomalies in those communities or that there are less constraints for vegetation growth due to water limitation in those regions19. The better suitability of some variables in alpine grasslands may be explained by the higher importance of snow as water source in high altitudes compared to lower elevations33. This is also a reason for the suitability of temperature and the respective negative correlation in this community, as positive temperature anomalies increase direct evaporation of snow and so lead to a reduced moisture availability for vegetation in higher regions.
In conclusion, our research hypotheses on the various datasets were only partly supported by our results and several novel findings contribute to research of global vegetation change. Reanalysis datasets are more appropriate for spatiotemporally consistent and comparable analysis of vegetation changes in regions with poor meteorological infrastructure. The performance of gauge-based datasets, satellite products and combinations of both is regionally variable and some datasets may be problematic for homogenously analyzing conservation or peripheral areas. Snow variables derived from remote sensing sensors with increased resolution were highly suitable but were not better in analyzing vegetation anomalies than several other datasets in this study. Therefore, we suggest the utilization of reanalysis datasets for studying climate-vegetation interrelationships in data poor conservation areas in recent decades. The suitability of respective products also indicates high potential of more complex climate variables that can be derived from reanalysis parameters, such as drought indices57,81,95, for upcoming research applications of vegetation anomalies in remote regions.
Data availability
All utilized raster datasets are available for download free of charge from the respective sources in the reference list.
References
Gaston, K. J., Jackson, S. F., Cantú-Salazar, L. & Cruz-Piñón, G. The Ecological Performance of Protected Areas. Annu. Rev. Ecol. Evol. Syst. 39, 93–113 (2008).
Williams, S. E. et al. Research priorities for natural ecosystems in a changing global climate. Glob. Change Biol. 26, 410–416 (2020).
Hoffmann, S., Irl, S. D. H. & Beierkuhnlein, C. Predicted climate shifts within terrestrial protected areas worldwide. Nat. Commun. 10, 4787 (2019).
IUCN & UNEP. The World Database on Protected Areas (WDPA). www.protectedplanet.net. (UNEP-WCMC, 2018).
Schneider, U., Becker, A., Finger, P., Meyer-Christoffer, A. & Ziese, M. GPCC Full Data Monthly Product Version 2018 at 0.25°: Monthly Land-Surface Precipitation from Rain-Gauges built on GTS-based and Historical Data. 10.5676/DWD_GPCC/FD_M_V2018_025; ftp://ftp.dwd.de/pub/data/gpcc/html/fulldata-monthly_v2018_doi_download.html; accessed on 26 March 2019. (2018).
Schneider, U., Finger, P., Meyer-Christoffer, A., Ziese, M. & Becker, A. Global Precipitation Analysis Products of the GPCC. Deutscher Wetterdienst, Abt. Hydrometeorologie, Weltzentrum für Niederschlagsklimatologie (WZN) 17 (2018).
Hofstra, N., Haylock, M., New, M. & Jones, P. D. Testing E-OBS European high-resolution gridded data set of daily precipitation and surface temperature. J. Geophys. Res. 114, D21101 (2009).
Prein, A. F. & Gobiet, A. Impacts of uncertainties in European gridded precipitation observations on regional climate analysis: UNCERTAINTY IN EUROPEAN PRECIPITATION. Int. J. Climatol. 37, 305–327 (2017).
Zandler, H., Haag, I. & Samimi, C. Evaluation needs and temporal performance differences of gridded precipitation products in peripheral mountain regions. Sci. Rep. 9, 15118 (2019).
Liu, M. et al. Evaluation of high-resolution satellite rainfall products using rain gauge data over complex terrain in southwest China. Theor. Appl. Climatol. 119, 203–219 (2015).
Fu, Y. et al. Assessment of multiple precipitation products over major river basins of China. Theor. Appl. Climatol. 123, 11–22 (2016).
Hu, Z., Hu, Q., Zhang, C., Chen, X. & Li, Q. Evaluation of reanalysis, spatially interpolated and satellite remotely sensed precipitation data sets in central Asia: Central Asia Precipitation. J. Geophys. Res. Atmos. 121, 5648–5663 (2016).
Hu, Z. et al. Evaluation of three global gridded precipitation data sets in central Asia based on rain gauge observations. Int. J. Climatol. 38, 3475–3493 (2018).
Beck, H. E. et al. Global-scale evaluation of 22 precipitation datasets using gauge observations and hydrological modeling. Hydrol. Earth Syst. Sci. 21, 6201–6217 (2017).
Iwasaki, H. NDVI prediction over Mongolian grassland using GSMaP precipitation data and JRA-25/JCDAS temperature data. J. Arid Environ. 73, 557–562 (2009).
Gessner, U. et al. The relationship between precipitation anomalies and satellite-derived vegetation activity in Central Asia. Glob. Planet. Change 110, 74–87 (2013).
Los, S. O. Testing gridded land precipitation data and precipitation and runoff reanalyses (1982–2010) between 45° S and 45° N with normalised difference vegetation index data. Hydrol. Earth Syst. Sci. 19, 1713–1725 (2015).
Papagiannopoulou, C. et al. Vegetation anomalies caused by antecedent precipitation in most of the world. Environ. Res. Lett. 12, 074016 (2017).
Chen, Z., Wang, W. & Fu, J. Vegetation response to precipitation anomalies under different climatic and biogeographical conditions in China. Sci. Rep. 10, 830 (2020).
Eckert, S., Hüsler, F., Liniger, H. & Hodel, E. Trend analysis of MODIS NDVI time series for detecting land degradation and regeneration in Mongolia. J. Arid Environ. 113, 16–28 (2015).
Otto, M., Höpfner, C., Curio, J., Maussion, F. & Scherer, D. Assessing vegetation response to precipitation in northwest Morocco during the last decade: an application of MODIS NDVI and high resolution reanalysis data. Theor. Appl. Climatol. 123, 23–41 (2016).
Formica, A. F., Burnside, R. J. & Dolman, P. M. Rainfall validates MODIS-derived NDVI as an index of spatio-temporal variation in green biomass across non-montane semi-arid and arid Central Asia. J. Arid Environ. 142, 11–21 (2017).
Wang, X., Wu, C., Peng, D., Gonsamo, A. & Liu, Z. Snow cover phenology affects alpine vegetation growth dynamics on the Tibetan Plateau: Satellite observed evidence, impacts of different biomes, and climate drivers. Agric. For. Meteorol. 256–257, 61–74 (2018).
Verbyla, D. & Kurkowski, T. A. NDVI–Climate relationships in high-latitude mountains of Alaska and Yukon Territory. Arct. Antarct. Alp. Res. 51, 397–411 (2019).
Breckle, S.-W. Flora and vegetation of Afghanistan. badr 1, 155–194 (2007).
Bedunah, D. J., Shank, C. C. & Alavi, M. A. Rangelands of Band-e-Amir National Park and Ajar Provisional Wildlife Reserve, Afghanistan. Rangelands 32, 41–52 (2010).
Pohl, E., Knoche, M., Gloaguen, R., Andermann, C. & Krause, P. Sensitivity analysis and implications for surface processes from a hydrological modelling approach in the Gunt catchment, high Pamir Mountains. Earth Surf. Dyn. 3, 333–362 (2015).
Soelberg, J. & Jäger, A. K. Comparative ethnobotany of the Wakhi agropastoralist and the Kyrgyz nomads of Afghanistan. J. Ethnobiol. Ethnomed. https://doi.org/10.1186/s13002-015-0063-x (2016).
Didan, K. MOD13Q1 MODIS/terra vegetation indices 16-day L3 global 250m SIN Grid V006. NASA EOSDIS Land Process. DAAC https://doi.org/10.5067/MODIS/MOD13Q1.006 (2015).
Dinku, T. et al. Validation of the CHIRPS satellite rainfall estimates over eastern Africa. Q. J. R. Meteorol. Soc. 144, 292–312 (2018).
Sun, Q. et al. A review of global precipitation data sets: data sources, estimation, and intercomparisons. Rev. Geophys. 56, 79–107 (2018).
Hall, D. K. & Riggs, G. A. MOD10A1 MODIS/Terra Snow Cover Daily L3 Global 500m SIN Grid, Version 6. Boulder, Colorado USA. NASA National Snow and Ice Data Center Distributed Active Archive Center. https://doi.org/10.5067/MODIS/MOD10A1.006. Accessed on 25 March 2020. (2016).
Wang, K. et al. Snow effects on alpine vegetation in the Qinghai-Tibetan Plateau. Int. J. Digit. Earth 8, 58–75 (2013).
Chen, X., An, S., Inouye, D. W. & Schwartz, M. D. Temperature and snowfall trigger alpine vegetation green-up on the world’s roof. Glob. Change Biol. 21, 3635–3646 (2015).
Asam, S. et al. Relationship between spatiotemporal variations of climate, snow cover and plant phenology over the Alps—an earth observation-based analysis. Remote Sens. 10, 1757 (2018).
Funk, C. C. et al. CHIRPS-2.0. A quasi-global precipitation time series for drought monitoring: U.S. Geological Survey Data Series 832, 4 p. http://pubs.usgs.gov/ds/832/. Accessed on 25 March 2020. (2014).
Harris, I., Jones, P. D., Osborn, T. J. & Lister, D. H. Updated high-resolution grids of monthly climatic observations—the CRU TS3.10 Dataset. Int. J. Climatol. 34, 623–642 (2014).
Copernicus Climate Change Service. C3S ERA5-Land reanalysis . Copernicus Climate Change Service, https://cds.climate.copernicus.eu/cdsapp#!/home. Accessed on 25 March 2020. (2019).
Schneider, U., Becker, A., Finger, P., Meyer-Christoffer, A. & Ziese, M. GPCC Monitoring Product Version 6: Near Real-Time Monthly Land-Surface Precipitation from Rain-Gauges based on SYNOP and CLIMAT data. 10.5676/DWD_GPCC/MP_M_V6_100; ftp://ftp.dwd.de/pub/data/gpcc/monitoring_v6/. Accessed on 25 March 2020. (2018).
Huffman, G. J., Stocker, E. F., Bolvin, D. T., Nelkin, E. J. & Jackson, T. GPM IMERG Final Precipitation L3 1 month 0.1 degree x 0.1 degree V06, Greenbelt, MD, Goddard Earth Sciences Data and Information Services Center (GES DISC),https://doi.org/10.5067/GPM/IMERG/3B-MONTH/06. Accessed on 25 March 2020. (2019).
Global Modeling and Assimilation Office. MERRA-2 tavgM_2d_flx_Nx: 2d,Monthly mean,Time-Averaged,Single-Level,Assimilation,Surface Flux Diagnostics V5.12.4; https://doi.org/10.5067/0JRLVL8YV2Y4. Accessed on 25 March 2020. (Goddard Earth Sciences Data and Information Services Center (GES DISC), 2015).
Unger-Shayesteh, K. et al. What do we know about past changes in the water cycle of Central Asian headwaters? A review. Glob. Planet. Change 110, 4–25 (2013).
Amante, C. & Eakins, B. W. ETOPO1 1 Arc-Minute Global Relief Model: Procedures, Data Sources and Analysis. NOAA Technical Memorandum NESDIS NGDC-24. National Geophysical Data Center, NOAA. https://doi.org/10.7289/V5C8276M, Accessed on 25 March 2020. (2009).
Jpl, N. A. S. A. NASA shuttle radar topography mission global 1 arc second data set. NASA EOSDIS Land Process. DAAC. https://doi.org/10.5067/MEaSUREs/SRTM/SRTMGL1.003 (2013).
QGIS Development Team. GIS Geographic Information System. Version 3.12 București. Open Source Geospatial Foundation Project. http://qgis.osgeo.org/. (2020).
Smallwood, P. D. & Shank, C. C. From buffer zone to national park: Afghanistan’s Wakhan National Park. In Collateral Values Vol. 25 (eds Lookingbill, T. R. & Smallwood, P. D.) 213–233 (Springer, Berlin, 2019).
Vanselow, K. A. The high-mountain pastures of the Eastern Pamirs (Tajikistan): an evaluation of the ecological basis and the pasture potential. (Erlangen, Nürnberg, Univ., Diss., 2011).
Breckle, S. W. & Rafiqpoor, M. D. Field Guide Afghanistan—Flora and Vegetation. (Scientia Bonnensis, 2010).
Moheb, Z. & Bradfield, D. Status of the common leopard in Afghanistan. ISSN 1027–2992. Cat News 61, (2014).
Mohibbi, A. A. & Cochard, R. Residents’ resource uses and nature conservation in Band-e-Amir National Park, Afghanistan. Environ. Dev. 11, 141–161 (2014).
Moqanaki, E. M. et al. Distribution and status of the Pallas’s cat in the south-west part of its range. ISSN 1027–2992. Cat News Special Issue 13, (2019).
Gray, T. I. & Tapley, B. D. Vegetation health: Nature’s climate monitor. Adv. Space Res. 5, 371–377 (1985).
Sun, J. & Qin, X. Precipitation and temperature regulate the seasonal changes of NDVI across the Tibetan Plateau. Environ. Earth Sci. 75, 291 (2016).
Anyamba, A. & Tucker, C. J. Analysis of Sahelian vegetation dynamics using NOAA-AVHRR NDVI data from 1981–2003. J. Arid Environ. 63, 596–614 (2005).
Quetin, G. R. & Swann, A. L. S. Empirically derived sensitivity of vegetation to climate across global gradients of temperature and precipitation. J. Clim. 30, 5835–5849 (2017).
Meroni, M., Fasbender, D., Rembold, F., Atzberger, C. & Klisch, A. Near real-time vegetation anomaly detection with MODIS NDVI: timeliness vs. accuracy and effect of anomaly computation options. Remote Sens. Environ. 221, 508–521 (2019).
Rita, A. et al. The impact of drought spells on forests depends on site conditions: the case of 2017 summer heat wave in southern Europe. Glob. Change Biol. 26, 851–863 (2020).
Kandasamy, S., Baret, F., Verger, A., Neveux, P. & Weiss, M. A comparison of methods for smoothing and gap filling time series of remote sensing observations – application to MODIS LAI products. Biogeosciences 10, 4055–4071 (2013).
Liu, R., Shang, R., Liu, Y. & Lu, X. Global evaluation of gap-filling approaches for seasonal NDVI with considering vegetation growth trajectory, protection of key point, noise resistance and curve stability. Remote Sens. Environ. 189, 164–179 (2017).
Zandler, H., Brenning, A. & Samimi, C. Quantifying dwarf shrub biomass in an arid environment: comparing empirical methods in a high dimensional setting. Remote Sens. Environ. 158, 140–155 (2015).
Hyndman, R. J. Discussion of ‘High-dimensional autocovariance matrices and optimal linear prediction’. Electron. J. Stat. 9, 792–796 (2015).
Propastin, P. A., Kappas, M. & Muratova, N. R. Inter-annual changes in vegetation activities and their relationship to temperature and precipitation in Central Asia from 1982 to 2003. J. Environ. Inf. 12, 75–87 (2008).
Hersbach, H. et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 146, 1999–2049 (2020).
Parker, W. S. Reanalyses and observations: what’s the difference?. Bull. Am. Meteorol. Soc. 97, 1565–1572 (2016).
El Kenawy, A. M. & McCabe, M. F. A multi-decadal assessment of the performance of gauge- and model-based rainfall products over Saudi Arabia: climatology, anomalies and trends: RAINFALL PRODUCTS IN SAUDI ARABIA. Int. J. Climatol. 36, 656–674 (2016).
Song, S. & Bai, J. Increasing winter precipitation over arid Central Asia under global warming. Atmosphere 7, 139 (2016).
Ahmed, K., Shahid, S., Wang, X., Nawaz, N. & Najeebullah, K. Evaluation of gridded precipitation datasets over arid regions of Pakistan. Water 11, 210 (2019).
Anjum, M. N. et al. Performance evaluation of latest integrated multi-satellite retrievals for Global Precipitation Measurement (IMERG) over the northern highlands of Pakistan. Atmos. Res. 205, 134–146 (2018).
Gelaro, R. et al. The modern-era retrospective analysis for research and applications, Version 2 (MERRA-2). J. Clim. 30, 5419–5454 (2017).
Reichle, R. H. et al. Land surface precipitation in MERRA-2. J. Clim. 30, 1643–1664 (2017).
Peng, S., Piao, S., Ciais, P., Fang, J. & Wang, X. Change in winter snow depth and its impacts on vegetation in China. Glob. Change Biol. https://doi.org/10.1111/j.1365-2486.2010.02210.x (2010).
Qiu, B. et al. Satellite-observed solar-induced chlorophyll fluorescence reveals higher sensitivity of alpine ecosystems to snow cover on the Tibetan Plateau. Agric. For. Meteorol. 271, 126–134 (2019).
Hall, D. K., Riggs, G. A., DiGirolamo, N. E. & Román, M. O. Evaluation of MODIS and VIIRS cloud-gap-filled snow-cover products for production of an Earth science data record. Hydrol. Earth Syst. Sci. 23, 5227–5241 (2019).
Salomonson, V. V. & Appel, I. Development of the Aqua MODIS NDSI fractional snow cover algorithm and validation results. IEEE Trans. Geosci. Remote Sens. 44, 1747–1756 (2006).
Riggs, G., Hall, D. & Román, M. O. VIIRS Snow Cover Algorithm Theoretical Basis Document (ATBD). 38 (2015).
Zhu, A.-X. Resampling Raster. In International Encyclopedia of Geography: People, the Earth, Environment and Technology (eds Richardson, D. et al.) 1–5 (Wiley, New York, 2017). https://doi.org/10.1002/9781118786352.wbieg0878.
Behnke, R. et al. Evaluation of downscaled, gridded climate data for the conterminous United States. Ecol. Appl. 26, 1338–1351 (2016).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Zandler, H. Wakhan Rangeland Assessment Report 2018. Unpublished report. (2018).
Camberlin, P., Martiny, N., Philippon, N. & Richard, Y. Determinants of the interannual relationships between remote sensed photosynthetic activity and rainfall in tropical Africa. Remote Sens. Environ. 106, 199–216 (2007).
Vicente-Serrano, S. M. et al. Response of vegetation to drought time-scales across global land biomes. Proc. Natl. Acad. Sci. 110, 52–57 (2013).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. B 57, 289–300 (1995).
Peña, M. A., Brenning, A. & Sagredo, A. Constructing satellite-derived hyperspectral indices sensitive to canopy structure variables of a Cordilleran Cypress (Austrocedrus chilensis) forest. ISPRS J. Photogram. Remote Sens. 74, 1–10 (2012).
Zandler, H., Brenning, A. & Samimi, C. Potential of space-borne hyperspectral data for biomass quantification in an arid environment: advantages and limitations. Remote Sens. 7, 4565–4580 (2015).
Efron, B. & Tibshirani, R. An Introduction to the Bootstrap (Chapman & Hall, London, 1993).
Banik, S. & Kibria, B. M. Confidence intervals for the population correlation coefficient ρ. Int. J. Stats. Med. Res. 5, 99–111 (2016).
Mudelsee, M. Estimating Pearson’s correlation coefficient with bootstrap confidence interval from serially dependent time series. Math. Geol. 35, 651–665 (2003).
Abdi, A. M. et al. The El Niño – La Niña cycle and recent trends in supply and demand of net primary productivity in African drylands. Clim. Change 138, 111–125 (2016).
Lima, E., Davies, P., Kaler, J., Lovatt, F. & Green, M. Variable selection for inferential models with relatively high-dimensional data: Between method heterogeneity and covariate stability as adjuncts to robust selection. Sci. Rep. 10, 8002 (2020).
Degenhardt, F., Seifert, S. & Szymczak, S. Evaluation of variable selection methods for random forests and omics data sets. Brief. Bioinform. 20, 492–503 (2019).
Kursa, M. B. & Rudnicki, W. R. Feature selection with the Boruta package. J. Stat. Soft. https://doi.org/10.18637/jss.v036.i11 (2010).
Diesing, M. Deep-sea sediments of the global ocean. https://essd.copernicus.org/preprints/essd-2020-22/ (2020) 10.5194/essd-2020-22.
R Core Team. R: A Language and Environment for Statistical Computing. Version 4.0.3. https://www.R-project.org/. (R Foundation for Statistical Computing, 2020).
Daham, A., Han, D., Rico-Ramirez, M. & Marsh, A. Analysis of NVDI variability in response to precipitation and air temperature in different regions of Iraq, using MODIS vegetation indices. Environ. Earth Sci. 77, 389 (2018).
Chen, S., Gan, T. Y., Tan, X., Shao, D. & Zhu, J. Assessment of CFSR, ERA-Interim, JRA-55, MERRA-2, NCEP-2 reanalysis data for drought analysis over China. Clim. Dyn. 53, 737–757 (2019).
Kath, J. et al. Not so robust: robusta coffee production is highly sensitive to temperature. Glob. Change Biol. https://doi.org/10.1111/gcb.15097 (2020).
Mahto, S. S. & Mishra, V. Does ERA-5 outperform other reanalysis products for hydrologic applications in India?. J. Geophys. Res. Atmos. 124, 9423–9441 (2019).
Royé, D., Íñiguez, C. & Tobías, A. Comparison of temperature–mortality associations using observed weather station and reanalysis data in 52 Spanish cities. Environ. Res. 183, 109237 (2020).
Dee, D. P., Källén, E., Simmons, A. J. & Haimberger, L. Comments on “Reanalyses Suitable for Characterizing Long-Term Trends”. Bull. Am. Meteorol. Soc. 92, 65–70 (2011).
Rasmussen, R. et al. How well are we measuring snow: the NOAA/FAA/NCAR winter precipitation test bed. Bull. Am. Meteorol. Soc. 93, 811–829 (2012).
Yuan, X., Li, L. & Chen, X. Increased grass NDVI under contrasting trends of precipitation change over North China during 1982–2011. Remote Sens. Lett. 6, 69–77 (2015).
Wang, X., Ciais, P., Wang, Y. & Zhu, D. Divergent response of seasonally dry tropical vegetation to climatic variations in dry and wet seasons. Glob. Change Biol. 24, 4709–4717 (2018).
Basheer, M. & Elagib, N. A. Performance of satellite-based and GPCC 7.0 rainfall products in an extremely data-scarce country in the Nile Basin. Atmos. Res. 215, 128–140 (2019).
Piazzi, G. et al. Cross-country assessment of H-SAF snow products by sentinel-2 imagery validated against in-situ observations and webcam photography. Geosciences 9, 129 (2019).
Lievens, H. et al. Snow depth variability in the Northern Hemisphere mountains observed from space. Nat. Commun. 10, 4629 (2019).
Sur, C., Park, S.-Y., Kim, T.-W. & Lee, J.-H. Remote sensing-based agricultural drought monitoring using hydrometeorological variables. KSCE J. Civ. Eng. 23, 5244–5256 (2019).
Geruo, A., Velicogna, I., Zhao, M., Colliander, A. & Kimball, J. S. Satellite detection of varying seasonal water supply restrictions on grassland productivity in the Missouri basin, USA. Remote Sens. Environ. 239, 111623 (2020).
Lu, X. et al. Correcting GPM IMERG precipitation data over the Tianshan Mountains in China. J. Hydrol. 575, 1239–1252 (2019).
Funk, C. et al. The climate hazards infrared precipitation with stations—a new environmental record for monitoring extremes. Sci. Data 2, 150066 (2015).
Bai, L., Shi, C., Li, L., Yang, Y. & Wu, J. Accuracy of CHIRPS satellite-rainfall products over Mainland China. Remote Sens. 10, 362 (2018).
Berg, A. A., Famiglietti, J. S., Walker, J. P. & Houser, P. R. Impact of bias correction to reanalysis products on simulations of North American soil moisture and hydrological fluxes. J. Geophys. Res. 108, ACL2-1-ACL2-5 (2003).
Sahoo, A. K., Sheffield, J., Pan, M. & Wood, E. F. Evaluation of the tropical rainfall measuring mission multi-satellite precipitation analysis (TMPA) for assessment of large-scale meteorological drought. Remote Sens. Environ. 159, 181–193 (2015).
Zambrano, F., Wardlow, B., Tadesse, T., Lillo-Saavedra, M. & Lagos, O. Evaluating satellite-derived long-term historical precipitation datasets for drought monitoring in Chile. Atmos. Res. 186, 26–42 (2017).
Dörre, A. Local knowledge-based water management and irrigation in the western pamirs. Int. J. EI 1, 254–266 (2018).
Acknowledgements
We highly appreciate the provision of datasets to the scientific community by all institutions and spatial product creators free of charge. Furthermore, we would like to thank the Wildlife Conservation Society (WCS) Afghanistan for providing the vegetation information that was gathered by the first author. The work of WCS in Afghanistan during the study period was supported by the UNDP GEF grant AA/Pj/PIMS: 00076820/0088001/5038; and Fondation Segré grant "Transboundary Conservation of Mountain Monarchs in Afghanistan and Pakistan”. We also thank Mattias Roth for proof-reading and language correction. Finally, we thank two anonymous reviewers for their time and effort in reviewing the manuscript. This publication was funded by the German Research Foundation (DFG) and the University of Bayreuth in the funding programme Open Access Publishing.
Funding
Open Access funding enabled and organized by Projekt DEAL.. Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
H.Z. designed the study, conducted the analysis and wrote the manuscript. T.S. performed gap-filling of the MODIS snow product and reviewed the manuscript. K.V. contributed to method discussion and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zandler, H., Senftl, T. & Vanselow, K.A. Reanalysis datasets outperform other gridded climate products in vegetation change analysis in peripheral conservation areas of Central Asia. Sci Rep 10, 22446 (2020). https://doi.org/10.1038/s41598-020-79480-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-79480-y
This article is cited by
-
Interrelations of vegetation growth and water scarcity in Iran revealed by satellite time series
Scientific Reports (2022)
-
Overall negative trends for snow cover extent and duration in global mountain regions over 1982–2020
Scientific Reports (2022)
-
Monitoring and assessment of glaciers and glacial lakes: climate change impact on the Mago Chu Basin, Eastern Himalayas
Regional Environmental Change (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
