
Abstract
Boson sampling can simulate physical problems for which classical simulations are inefficient. However, not all problems simulated by boson sampling are classically intractable. We show explicit classical methods of finding boson sampling distributions when they are known to be highly sparse. In the methods, we first determine a few distributions from restricted number of detectors and then recover the full one using compressive sensing techniques. In general, the latter step could be of high complexity. However, we show that this problem can be reduced to solving an Ising model which under certain conditions can be done in polynomial time. Various extensions are discussed including a version involving quantum annealing. Hence, our results impact the understanding of the class of classically calculable problems. We indicate that boson samplers may be advantageous in dealing with problems which are not highly sparse. Finally, we suggest a hybrid method for problems of intermediate sparsity.
Similar content being viewed by others

Introduction
Simulating complicated quantum systems on classical or quantum simulators is an interesting problem with the industrial impact. It is simply cheaper to test many, e.g., molecular configurations in the simulators than synthetizing the molecules and testing their crucial properties experimentally. However, some problems are believed to be of complexity for which classical computers are inefficient. Huh et al.1,2 showed that the statistics of Franck–Condon (FC) factors3,4 for vibronic transitions in large molecules5,6 is equivalent to the statistics of samples in a version of boson sampling7,8,9,10,11,12,13,14,15—the Gaussian boson sampling16,17,18. Although, it is widely accepted that boson sampling from interferometers described by the average-case Haar-random unitary transformations or Gaussian-random matrices is classically computationally inefficient7, it is not clear if particular problems of quantum chemistry belong to this class, as the related matrices are not typically Haar- or Gaussian-random1,19. Indeed, calculating permanents of large matrices, which is the main issue in the scattershot boson sampling, can be efficiently tractable if the matrices were of low rank or consisted of non-negative numbers20,21.
In this paper we discuss the case when we a priori know that the statistics of outputs from boson sampling is sparse. This knowledge can be based on experience with similar problems, symmetries or other physical properties. We analyze examples of relevant physical systems with approximately sparse vibronic-spectra that can be simulated on a Gaussian boson sampling-type simulator in22. There, sparsity of a spectrum is expected based on shapes of typical spectra of some types of molecules and the intuition that the most significant transitions in 0K are likely these with only a few phonons involved in just a few modes. In the present paper, we introduce methods of at least approximate classical computation of the sparse statistics. We discuss recovering the joint statistics of outcomes of all detectors from statistics of outcomes of only chosen detectors which we call marginal distributions. We use the fact that for boson sampling marginal distributions for small number of modes can be efficiently calculated. Then we apply appropriately modified compressive sensing methods to efficiently recover the joint statistics. Up to our knowledge this is the first result dealing with classical simulability of boson sampling with sparse output. Moreover, we develop original methods to improve the efficiency of the classical algorithms for compressive sensing reconstruction, namely the so-called polynomial time matching pursuit (PTMP) that can be extended to other methods, for instance, gradient pursuit23. Finally, our novel approach has an impact on interdisciplinary studies on molecular vibronic spectroscopy22, compressive sensing, and quantum computing with hybrid devices.
Let us summarize our arguments. For scattershot boson sampling computability of marginal distributions for small number of modes is implied by the result of Gurvits cited together with the proof in the Aaronson and Arkhipov paper7 as follows:
Theorem 1
(Gurvits’s k-photon marginal algorithm) There exists a deterministic classical algorithm that, given a unitary matrix \(U\in {\mathbb {C}}_{M\times M}\), indices \(i_1, \ldots , i_k \in [M]\), and occupation numbers \(j_1, \ldots , j_k\in \{0, \ldots , N\}\), computes the joint probability
in \(N^{O(k)}\)time.
Here, \(S=(s_1,\ldots ,s_M)\sim D_U\) means that the occupation numbers S are sampled according to the probability distribution over possible outputs of U. If k is small, as we assume in this paper, calculating marginal distributions is efficient. The counterpart of this theorem for Gaussian boson sampling is discussed in the Discussion and implemented in22. In our approach we use the compressive sensing methods26,27,28,29,30,31,32 to recover the joint sparse distribution from marginal ones. We show how to do that efficiently. Our arguments are inspired by works from the field of quantum compressive sensing33,34,35,36,37,38 and similar ones that consider recovering full information about states of high dimensional systems from states of low-dimensional subsystems34.
We notice that the complexity bottleneck of the matching pursuit algorithm that allows us to reconstruct a sparse probability vector from marginal distributions is in the support detection step, i.e., in localization of the largest element from a long list. This procedure typically would require the number of steps and bits of memory which is O(d), where d is the length of the list. However, we can use the following theorem concerning the support detection of the matching pursuit algorithm aiming at recovering the global statistics of outcomes of a set of detectors from the statistics of outcomes of pairs of the detectors (marginal distributions).
Theorem 2
The support detection is equivalent to solving the Ising model of a 1-dim chain of classical spins with interactions given by the entries of the marginal distributions.
The theorem is explained in detail and proven in “Complexity of the reconstruction” section. It implies that the support detection scheme has an efficient solution if the corresponding Ising model can be efficiently solvable. In the case discussed in this paper the list the maximum of which is to be found in the support detection step may be written as the local nearest-neighbor interaction Hamiltionian of a classical spin chain. Localization of the maximum energy configuration is efficient in this problem both in terms of the number of operations and memory39,40.
Our work is related to a general problem whether sparsity of the output of a quantum computer guarantees classical simulability. In24,25 there was shown that the existence of an efficient classical randomized algorithm for entries of all marginal distributions and the sparsity assumption indeed guarantee this for the circuit-based computing device. However, this result is not automatically applicable to boson sampling. Moreover, in our approach we relax one of the assumptions considering only computability of some marginal distributions for limited number of modes which extends the class of known classically tractable problems consistent with the boson sampling architecture.
Results
Marginal distributions and compressive sensing
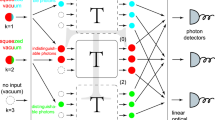
Let us start considering the following scenario. For some unitary transformation U which reflects features of a physical system we want to simulate the transition probabilities \(x=|\langle \Psi |U|n_1,n_2,\ldots ,n_M\rangle |^2\) from a given M-mode initial state \(|\Psi \rangle \) to all occupation numbers states \(|n_1,n_2,\ldots ,n_M\rangle \) (the left hand side of Fig. 1) that may be recorded by simultaneous readouts of M photon resolving detectors. We assume that there can be \(0,1,\ldots ,N-1\) possible photons in each output mode. So, the searched vector x is of length \(N^M\). Here, we allow for the total photon number not being preserved. In this way we can consider the situation with losses or Gaussian boson sampling using the same formalism. We claim that if x is sparse, i.e., it contains at most \({\mathfrak {s}}\) non-zero entries, where \({\mathfrak {s}}\ll N^M\), it is possible to efficiently find x calculating the statistics of marginal distributions from smaller number of detectors measuring only chosen modes and ignoring the rest (the right hand part of Fig. 1).

Red or blue bars—the statistics of simultaneous readouts of different numbers of photons at the output of an interferometer. Left hand side: The distributions measured directly by M photon-number-resolving detectors. All combinations of possible numbers of photons in M modes form an \(N^M\) dimensional vector. Right hand side: marginal distributions of the occupation numbers in two chosen modes.
To analyze the problem in detail let us introduce the following notation. Vector x can be decomposed in the basis of measured sets of occupation numbers as follows
Here, the numbers \(\alpha _{n_1,\ldots ,n_N}\) are non-negative, sum up to one and only s of them are non-zero. We will use the following convention
where the lower line indicates the positions of 1 in each vector component of the tensor product and there is appropriate number of 0s in place of dots. In this explanation we will use a notation for two-detector simultaneous readouts, however the formalism can be extended to simultaneous readouts of a different number of detectors if necessary. The measurement of modes i and j leads to the marginal probability distribution
where \(y_{n_i, n_j}\) is the sum of all entries \(\alpha _{n_1,\ldots ,n_N}\) with fixed \(n_i\) and \(n_j\). We get this distribution observing frequencies of outcomes from given modes independently of what happens in the remaining modes. In the chosen convention the rows of the so-called measurement matrix A are binary patterns as follows
where \(\odot \) means the entry-wise multiplication and
Here \(\mathbf{1}=(1,1,1,\ldots )\) and \((\cdot \cdot 1\cdot \cdot \cdot )\) are N dimensional vectors. The entry-wise multiplication preserves the tensor product structure and can be executed as the entrywise multiplication in each part of the tensor product.
Probabilities of k different simultaneous readouts form a k-dim vector
where A is a \(k\times N^M\) binary matrix. If x is sparse in the basis incoherent with the rows of the measurement matrix it can be determined based on the number of measurements \(k\ll N^M\) as the most sparse solution of \(y=Ax'\). This can be seen as the constraint l1 norm minimization problem. It is solvable by many known algorithms used in compressive sensing31. In the next part we analyze the complexity of particular algorithms adapted to minimize the computational costs and memory requirements.
Complexity of the reconstruction
Assume that we are focused on simultaneous readouts of different photon numbers in neighboring modes. The corresponding marginal distributions can be calculated in polynomial time in the number of modes. Indeed, Gurvits’s Algorithm from7 calculates \(k=N^2M\) of coincidences in all neighboring modes in \(N^{O(2)}N^2M\) steps. The dimensionality of the sparse vector is \(d=N^M\). We allow for sub-linear scaling of the number of non-zero entries \({\mathfrak {s}}\). Therefore, we keep \(O({\mathfrak {s}})\) and O(d) well separated. Moreover, we assume that problems of complexity \(O({\mathfrak {s}})=O(k)\) are efficiently tractable. From the readouts for marginal distributions, we want to recover the most sparse joint distribution knowing the measurement matrix. So, our goal is to solve the underdetermined problem \(y=Ax\), where y is a k-dimensional measurement vector of marginal distributions, x is a d-dimensional sparse vector which is searched. In our case, rows of A are well structured patterns. This implies that it is easy to multiply A by any sparse vector. For instance, assume that we know that an entry \(\kappa \) of a vector is non-zero. We decompose \(\kappa \) as a N-inary number which gives us immediately its tensor product representation as in (2) consistent with the structure of A. For example, assuming that \(N=2\), position 14 is represented as 01101 (corresponding to binary 13 as 0 occupies the first position) which corresponds to
This vector has just one non-zero element in the 14th entry. It is immediate to show what is its overlap with a particular row of A which, for instance, can be of the form
We need to check only relevant modes.
To solve the underdetermined problem \(y=Ax\) we discuss in detail two first-order greedy algorithms. We consider the matching pursuit41 method which is simple but in general less accurate, and the gradient pursuit which can be more accurate and faster but slightly more computationally demanding23. These two algorithms are enough to discuss the bottleneck for the memory and computational costs, and to show how to overcome these problems. In particular, our modification of the matching pursuit leads to a new algorithm which we call the polynomial time matching pursuit (PTMP).
The standard matching pursuit protocol finds the s-sparse solution. It is summarized as follows: I. (Initialization) At step 0: the residual \(r^0=y\) and the approximate solution is \(x^0=0\). II. (Support detection) In step i recognize the column of A denoted by \(A^t\) which is the most similar to the current residue \(r^{i-1}\) by solving \(t=\mathrm{argmax}_{t'}|(A^T r^{i-1})_{t'}|\). III. (Updating) Update the solution only in index t i.e., \(x^i_t=x^{i-1}_t+(A^T r^{i-1})_t\) and update the residue using tth column of A as follows \(r^i=r^{i-1}-(A^T r^{i-1})_tA^t\). IV. Continue iterating until a stopping criterion is matched.
Let us notice that the first and the third part of the algorithm can strongly benefit from the sparsity of vectors involved. Moreover, for any t, vector \(A^t\) can be found operationally (multiplication of A and a sparse vector). So, \(A^t\) does not need to be stored beforehand and the memory and computational costs of these parts are O(k)—size of \(r_i\). The entire procedure can be iterated until a given sparsity \({\mathfrak {s}}\) of the solution is achieved.
Finally, let us consider the operational costs of the support detection part. Without exploiting the structure of A we require O(kd) bits of memory to store the matrix and the same for the operational costs for multiplication \(A^T r_{i-1}\). Moreover, without smart tricks, typically, we would need at least O(d) steps to find the maximum value from the list \(A^T r_{i-1}\). The same amount of memory is needed to store the list. However, considering specific features of the problem we can overcome the bottleneck. As for finding the index of the largest element of a list, we notice that it is equivalent to finding the leading eigenvector of the diagonal matrix (Hamiltonian) with the list on the diagonal. We know that for some local Hamiltonians, i.e., the Hamiltonians consisted in sums of local interactions, there are computationally efficient methods for finding the eigenvectors. Let us notice that in our problem \(A^T r\) in the support detection part can be written exactly as a diagonal local Hamiltonian. To simplify the explanation let us consider first an example with the readouts from a single detector only. A row of measurement matrix A corresponding to \(n_m\) photons in mode m is given as \(\gamma _{n_m}\) in (5). Observing all \(n_m\) from only mode m we have
where \(A_{[m]}\) is a submatrix of A corresponding to different photon numbers recorded in mode m. Here, \(r_{[m]}\) is part of the residual vector that corresponds to rows of \(A_{[m]}\). Measurements of other modes have also form of the local Hamiltonians if understood as diagonal matrices. So, the same holds for \(A^T r\). For simultaneous readouts of 2 neighboring modes we have
which written in the diagonal form is a part of a typical nearest neighbor local Hamiltonian for a one dimensional spin chain. It is clear from this notation that the matrix vector multiplication \(A^T r\) requires negligible operational costs and O(k) bits of memory to store d long vector in its compressed representation as a sum of local matrices.
Using these observations, the support finding from the matching pursuit algorithm can be determined much faster than in O(d) time. If we consider just two neighboring modes simultaneous readouts our problem can be described in terms of the classical spin chain formalism, i.e., Ising model with nearest neighbor interaction. We can use an explicit strategy from, e.g.,40 to find the optimal configuration of the classical spin chain which is equivalent to finding the position of the maximal value in our \(A^Tr\) list. Indeed, \(h_{m,m+1}(i_m,i_{m+1})\) from the algorithm40 is equivalent to \(r_{(i-1)_m,(i-1)_{m+1}}\). This procedure reduces the computational costs of the support detection to \(2MN^2\) (factor 2 is from the necessity to repeat the procedure for \(-A^Tr\) as we are looking for the largest element in the absolute value). The matching pursuit with the modification increasing its efficiency is called the polynomial time matching pursuit (PTMP). We use this method to reconstruct vibronic spectra of some molecules from their marginal distributions in22.
It is easy to generalize the observation about the relation between \(A^Tr\) and the Ising Hamiltonian. If the marginal distributions are not restricted to nearest neighbor modes, but to pairs of arbitrary modes, vector \(A^Tr\) is equivalent to Ising model with non-local interactions. This proves the Theorem 2. Solving this general Ising model, however, may be NP-complete48. We discuss the possible extension in the final Discussion part.
PTMP although computationally simple is not the fastest one as the same support index may need to be used many times. Also it does not guarantee the accurate solution, as the solution is expressed based on relatively small number of columns of A in which y is decomposed. Some modifications of the method can lead faster to more accurate results. Among them there is an orthogonal matching pursuit algorithm (OMP)42 in which in each step the support is updated and kept in the memory. The solution is approximated by the vector of coefficients in the best 2-norm approximation of the measurement vector y in terms of the selected columns of A. Another algorithm, gradient pursuit (GP)23 updates the solution by correcting it in the direction of the largest gradient of the 2-norm mentioned above by a given step. As discussed in23 the only additional cost over what we have in the matching pursuit is the cost of calculating the step size. This can be however done efficiently in PTMP due to an easy way of finding the product of a sparse vector and matrix A. The convergence rates depend on contracting properties of A and a chosen algorithm.
Accuracy of the reconstruction
For successful compressive sensing reconstruction the so-called coherence between the rows of a measurement matrix and the sparsity basis must be low. Roughly speaking it means that a particular measurement is sensitive to changes in a large part of the measured vector. For this reason random unstructured matrices are of particular interest as they are incoherent with almost any basis. However, random matrices are problematic for large scale tasks. They are expensive in terms of storage and operational costs as the inefficient matrix vector multiplication is usually needed43. Therefore, structured matrices which can be defined operationally and do not need to be stored are also desired. In our case, measurement matrix A is structured and of low coherence with respect to the measured space basis. However, the usefulness of a specific matrix depends as well on the reconstruction algorithm. As we do not have theoretical predictions regarding convergence of considered protocols with the measurement matrix, we tested the performance of the GP algorithm with A numerically. We have measured 1000 randomly chosen distributions with \({\mathfrak {s}}=4,5,6\) non-zero entries for the problem with \(M=6\) output modes and \(N=4\) different events measured in each mode. Matrix A was associated with all 2-neighboring modes coincidence measurements. So, A is a \(80\times 4096\) matrix. We have tested how often \(X=x_{test}^Tx_{solved}/|x_{test}|^2\) is larger than a given threshold, where \(x_{test}\) and \(x_{solved}\) are the randomly chosen measured signal used in the simulation and the reconstructed signal respectively. We iterated the algorithm not more than 50 times. For \({\mathfrak {s}}=4\) we observe that in about \(80\%\) cases \(X>0.9\) and in \(74\%\) cases \(X>0.99\). For \({\mathfrak {s}}=5\), we have \(X>0.9\) and \(X>0.99\) in \(64\%\) and \(56\%\) of situations respectively. Finally, for \({\mathfrak {s}}=6\) we observe \(X>0.9\) and \(X>0.99\) in \(47\%\) and \(37\%\) of cases respectively. As there are many possible more complicated and more accurate algorithms which can still share the feature of the reduced complexity we predict that these numbers can be improved. However, testing them further is out of the scope of this paper. How PTMP works in practice is analyzed in a separate paper22. There, we observe that the distribution can be only approximately sparse fort the algorithm to reconstruct the most significant picks.
Discussion
In this paper we show that if we a priori know that boson sampling samples according to a sparse distribution and the sparsity is high enough we can calculate the first-order approximation of this distribution efficiently on a classical computer. The crucial steps are to calculate the marginal distributions using the Gurvits’s k-Photon Marginal Algorithm and then to use an algorithm for compressively sensed sparse signal recovery. Many of these algorithms quickly converge assuming that the support localization, as discussed in this paper, is efficient. We show that due to the specific form of the marginal measurements the problem can be reduced to finding the optimal configuration in a 1 dimensional classical spin chain with local interactions. The latter is known to be efficient.
For Gaussian boson sampling the only difference is in computing the marginal distributions. In this case evolving an input states through the interferometer and finding partial states for given modes is easy44. The statistics of photons of these states requires computing loop Hafnians17,18,45,46 of appropriate matrices which for two mode Gaussian states are still classically tractable. In consequence, we can use the relation between Franck–Condon factors and the Gaussian boson sampling1 and apply the algorithm described in this paper to find Franck–Condon factors under the condition that their distribution is sparse. This new approach is tested in22.
Let us discuss shortly when the boson sampling distribution can be sparse. If small number of photons is present in the interferometer boson sampling may be similar to the classical particle sampling, because the photons mostly do not collide. In this case the global distribution may be sparse and, as an effect of the classical process, classically simulable. However, the sparse distribution does not imply that there are only a few photons or that the photons do not collide. As an effect of interference all photons may be detected by only a few configurations of detectors most of the time. Analogous situation can be seen in quantum algorithms on a quantum circuit-based quantum computer with qubits. The final distribution of the register states is approximately highly sparse while it is an effect of non-trivial interference. So, the technique presented in this paper is applicable in situations when the sparsity of the global distribution is an effect of various mechanisms including a small number of photons or significant amount of non-trivial quantum interference. We want to notice that the high sparsity is not typical in boson sampling with randomly chosen unitary transformations, however, may appear when the sampler is to simulate physical systems.
In this paper we have investigated the situation with only nearest neighbor modes measurements. This restricts the tolerable sparsity for the method. When the sparsity decreases (\({\mathfrak {s}}\) increases) a larger amount of data is needed. Implementing three or more nearest neighbors modes measurements is one of the solutions. We could think as well about relaxing the nearest modes requirement and investigating the situation with non-local measurements. Then more advanced techniques from the theory of spin glass could be applied. More specifically, there exists a correspondence between finding the minimum energy configuration for a spin model and solving the MAX-CUT problem for a graph47,48. This correspondence implies that the spin glass problem is in general NP-complete. However, for restricted classes of graphs (planar graphs) MAX-CUT can be solved in polynomial time49,50. Using the correspondence between graphs and spin models and the correspondence between spin models and support detection in our algorithm we can solve the support detection problem in polynomial time even with not necessary nearest neighbor modes measurements. This would allow us to use our methods to less sparse problems.
Finally, our function \(A^Tr\) to be minimized when restricted to pairs of binary modes is equivalent to the Hamiltonian \(H=\sum _{i>j}H_{i,j}\), where
Here, \(\sigma ^z_i\) is the Pauli z matrix in mode i. The coefficients can be chosen to correspond to \(r_{n_i,n_j}\) from (10). The ground state of Hamiltonian H can be found efficiently by simulated or quantum annealing under some conditions about spectrum of H and the correspondence of H to the connections in the annealer51,52,53. In our approach we have some freedom in choosing pairs of modes to guarantee that these conditions are satisfied. So, the simulated or quantum annealing could be used to extend our approach.
Our technique can be applied to marginal distributions measured in realistic experiments or calculated assuming uniform losses54,55. The joint distribution after losses may be interpreted as a lossless distribution multiplied by a stochastic matrix L describing the process of losses, where L is in the form of a tensor product. The measurement matrix from our technique is now the product of A defined as previously and L. The new measurement matrix inherits features allowing for keeping the complexity tractable. We could also invert the loss on modes involved in marginal measurements. The impact of losses will be a direction of further studies.
References
Huh, J., Guerreschi, G. G., Peropadre, B., McClean, J. R. & Aspuru-Guzik, A. Boson sampling for molecular vibronic spectra. Nat. Photon. 9, 615–620 (2015).
Huh, J. & Yung, M.-H. Vibronic boson sampling: generalized gaussian boson sampling for molecular vibronic spectra at finite temperature. Sci. Rep. 7, 1 (2017).
Franck, J. Elementary processes of photochemical reactions. Trans. Faraday Soc. 21, 536–542 (1925).
Condon, E. U. Nuclear motions associated with electron transitions in diatomic molecules. Phys. Rev. 54, 858–872 (1928).
Doktorov, E. V., Malkin, I. A. & Manko, V. I. Dynamical symmetry of vibronic transitions in polyatomic-molecules and Franck–Condon principle. J. Mol. Spectrosc. 64, 302–326 (1977).
Jankowiak, H.-C., Stuber, J. L. & Berger, R. Vibronic transitions in large molecular systems: rigorous prescreening conditions for Franck–Condon factors. J. Chem. Phys. 127, 234101 (2007).
Aaronson, S., & Arkhipov, A. The computational complexity of linear optics. In Proceedings of the Forty-Third Annual ACM Symposium on Theory of Computing (ACM, New York, 2011), 333-342 (2011).
Spring, J. B. et al. Boson sampling on a photonic chip. Science 339, 798–801 (2013).
Tillmann, M. et al. Experimental boson sampling. Nat. Photon. 7, 540–544 (2013).
Shchesnovich, V. S. Sufficient condition for the mode mismatch of single photons for scalability of the boson-sampling computer. Phys. Rev. A 82, 022333 (2014).
Tichy, M. C., Mayer, K., Buchleitner, A. & Molmer, K. Stringent and efficient assessment of boson-sampling devices. Phys. Rev. Lett. 113, 020502 (2014).
Motes, K. R., Gilchrist, A., Dowling, J. P. & Rohde, P. P. Scalable boson sampling with time-bin encoding using a loop-based architecture. Phys. Rev. Lett. 113, 120501 (2014).
Gard, B. T., Motes, K. R., Olson, J. P., Rohde, P. P. & Dowling, J. P. An Introduction to boson-bampling. In From Atomic to Mesoscale: The Role of Quantum Coherence in Systems of Various Complexities (eds Malinovskaya, S. A. & Novikova, I.) (WSPC, New Jersey, 2015).
Wang, H. et al. High-efficiency multiphoton boson sampling. Nat. Photon. 11, 361–365 (2017).
Wang, H. et al. Boson Sampling with 20 Input Photons and a 60-Mode Interferometer in a \(10^14\)-Dimensional Hilbert Space. Phys. Rev. Lett. 123, 250503 (2019).
Lund, A. P. et al. Boson sampling from a Gaussian state. Phys. Rev. Lett. 113, 100502 (2014).
Hamilton, C. et al. Gaussian boson sampling. Phys. Rev. Lett. 119, 170501 (2017).
Quesada, N. Franck–Condon factors by counting perfect matchings of graphs with loops. J. Chem. Phys. 150, 164113 (2019).
Cao, Y. et al. Quantum chemistry in the age of quantum computing. Chem. Rev. 119, 10856–10915 (2019).
Jerrum, M., Sinclair, A. & Vigoda, E. A polynomial-time approximation algorithm for the permanent of a matrix with non-negative entries. J. ACM 51, 671–697 (2004).
Barvinok, A. I. Two algorithmic results for the traveling salesman problem. Math. Oper. Res. 21, 65–84 (1996).
Valson Jacob, K., Kaur, E., Roga, W. & Takeoka, M. Franck–Condon factors via compressive sensing. Phys. Rev. A. arXiv:1909:02935 (2020).
Blumensath, T. & Davies, M. Gradient pursuit. IEEE Trans. Sig. Proc. 56, 2370–2382 (2008).
Schwarz, M., & V. d. Nest, M. Simulating quantum circuits with sparse output distributions. Electr. Coll. Comp. Compl (ECCC) 20, 154. arXiv:1310.6749 (2013).
Pashayan, H., Barlett, S. D., & Gross, D. From estimation of quantum probabilities to simulation of quantum circuits. Quantum 4, 223 (2020).
Donoho, D. L. For most large underdetermined systems of equations, the minimal l1-norm near-solution approximates the sparsest near-solution. Commun. Pure Appl. Math. 59, 907–934 (2006).
Candes, E. & Tao, T. Near-optimal signal recovery from random projections: universal encoding strategies. IEEE Trans. Inf. Theory 52, 5406–5425 (2006).
Baraniuk, R., Davenport, R. M., DeVore, R. & Wakin, M. A simple proof of the restricted isometry property for random matrices. Constr. Approx. 28, 253–263 (2008).
Candes, E. & Tao, T. Decoding by linear programming. IEEE Trans. Inf. Theory 51, 4203–4215 (2005).
Foucard, S. & Rauhut, H. A Mathematical Introduction to Compressive Sensing (Springer, Berlin, 2013).
Draganic, A., Orovic, I. & Stankovic, S. On some common compressive sensing algorithms and applications—Review paper. Facta Univ. Seri. Electron. Energ. 30, 477–510 (2017).
Candes, E., Romberg, J. & Tao, T. Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 52, 489–509 (2006).
Gross, D., Liu, Y.-K., Flammia, S. T., Becker, S. & Eisert, J. Quantum state tomography via compressed sensing. Phys. Rev. Lett. 105, 150401 (2010).
Cramer, M. et al. Efficient quantum state tomography. Nat.Commun. 1, 149 (2010).
Liu, Y.-K. Universal low-rank matrix recovery from Pauli measurements. Adv. Neural Inf. Process Syst. (NIPS) 24, 1638–1647 (2011).
Flammia, S. T., Gross, D., Liu, Y.-K. & Eisert, J. Quantum tomography via compressed sensing: error bounds, sample complexity and efficient estimators. New J. Phys. 14, 095022 (2012).
Shabani, A. et al. Efficient measurement of quantum dynamics via compressive sensing. Phys. Rev. Lett. 106, 100401 (2011).
Shabani, A., Mohseni, M., Lloyd, S., Kosut, R. L. & Rabitz, H. Estimation of many-body quantum Hamiltonians via compressive sensing. Phys. Rev. A 84, 012107 (2011).
Ising, E. Beitrag zur Theorie des Ferromagnetismus. Z. Phys. 31, 253–258 (1925).
Schuch, N. & Cirac, J. I. Matrix product state and mean-field solutions for one-dimensional systems can be found efficiently. Phys. Rev. A 82, 012314 (2010).
Mallat, S. G. & Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 41, 3397–3415 (1993).
Zhang, T. Sparse recovery with orthogonal matching pursuit under RIP. IEEE Trans. Inf. Theory 57, 6215–6221 (2011).
Cevher, V., Becker, S. & Schmidt, M. Convex optimization for big data: scalable, randomized, and parallel algorithms for big data analytics. IEEE Signal Process. Mag. 31, 32–43 (2014).
Bartlett, S. D., Sanders, B. C., Braunstein, S. L. & Nemoto, K. Efficient classical simulation of continuous variable quantum information processes. Phys. Rev. Lett. 88, 097904 (2002).
Kruse, R., Hamilton, C. S., Sansoni, L., Barkhofen, S., Silberhorn, C., & Jex, I. A detailed study of Gaussian boson sampling. Phys. Rev. A 100, 032326 (2019).
Quesada, et al. Simulating realistic non-Gaussian state preparation. Phys. Rev. A 100, 022341 (2019).
Barahona, F. On the computational complexity of Ising spin glass models. J. Phys. A. Math. Gen. 15, 3241–3253 (1982).
Zhang, S.-X. Classification on the computational complexity of spin models. arXiv:1911.04122 (2019).
Orlova, G. I. & Dorfman, Y. G. Finding the maximal cut in a graph. Eng. Cyber. 10, 502–506 (1972).
Hadlock, F. Finding a maximum cut of a planar graph in polynomial time. SIAM J. Comput. 4, 221–225 (1975).
Lucas, A. Ising formulations of many NP problems. Front. Phys. 2, 1–15 (2014).
Kirkpatrick, S., Gelatt, C. D. & Vecchi, M. P. Optimization by simulated annealing. Science 220, 671–680 (1983).
Kadowaki, T. & Nishimori, H. Quantum annealing in the transverse Ising model. Phys. Rev. E 58, 5355–5363 (1998).
Renema, J., Shchesnovich, V., & Garcia-Patron, R. Classical simulability of noisy boson sampling. arXiv:1809.01953 (2018).
Oszmaniec, M. & Brod, D. J. Classical simulation of photonic linear optics with lost particles. New J. Phys. 20, 092002 (2018).
Acknowledgements
We would like to thank Nicolás Quesada, Raúl García-Patrón and Jonathan Dowling for constructive comments. This work was supported by JST CREST Grant No. JPMJCR1772.
Author information
Authors and Affiliations
Contributions
W.R. and M.T. contributed to developing the concepts. W.R. wrote the main paper text and prepared the figure. All authors reviewed the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Roga, W., Takeoka, M. Classical simulation of boson sampling with sparse output. Sci Rep 10, 14739 (2020). https://doi.org/10.1038/s41598-020-71892-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-71892-0
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
