
Abstract
Comprehensive characterization of non-Poissonian, bursty temporal patterns observed in various natural and social processes is crucial for understanding the underlying mechanisms behind such temporal patterns. Among them bursty event sequences have been studied mostly in terms of interevent times (IETs), while the higher-order correlation structure between IETs has gained very little attention due to the lack of a proper characterization method. In this paper we propose a method of representing an event sequence by a burst tree, which is then decomposed into a set of IETs and an ordinal burst tree. The ordinal burst tree exactly captures the structure of temporal correlations that is entirely missing in the analysis of IET distributions. We apply this burst-tree decomposition method to various datasets and analyze the structure of the revealed burst trees. In particular, we observe that event sequences show similar burst-tree structure, such as heavy-tailed burst-size distributions, despite of very different IET distributions. This clearly shows that the IET distributions and the burst-tree structures can be separable. The burst trees allow us to directly characterize the preferential and assortative mixing structure of bursts responsible for the higher-order temporal correlations. We also show how to use the decomposition method for the systematic investigation of such correlations captured by the burst trees in the framework of randomized reference models. Finally, we devise a simple kernel-based model for generating event sequences showing appropriate higher-order temporal correlations. Our method is a tool to make the otherwise overwhelming analysis of higher-order correlations in bursty time series tractable by turning it into the analysis of a tree structure.
Similar content being viewed by others
Introduction
A variety of dynamical processes in natural and social phenomena are known to be non-Poissonian or bursty, as observed in solar flares1, earthquakes2,3, neuronal firings4, and human activities5,6 to name a few. Traditionally, long-term temporal correlations have been characterized in terms of 1/f noise7,8,9, autocorrelation function10,11,12,13, or Hurst exponent10,11,14,15,16. More recently, temporally correlated behavior, called bursts, has gained attention5,6. Bursts are rapidly occurring events in short-time periods alternating with long inactive periods. The mechanisms behind bursty temporal patterns have been studied by a number of modeling approaches5,6,12,17,18,19,20,21,22,23,24,25,26. It is also well-known that bursty interactions between elements of the systems influence the dynamical processes taking place in those systems, such as spreading or diffusion27,28,29,30,31,32,33,34. Therefore, characterization of the bursty temporal patterns is crucial to understand the underlying mechanisms for the emergent dynamics observed in various complex systems.
Temporal correlations in event sequences can be understood not only by statistical properties of time intervals between two consecutive events, i.e., interevent times (IETs), but also by correlations between IETs35,36. The temporal correlations due to the heavy-tailed IET distributions have been extensively studied in recent years (see a recent book reviewing the literature on the topic6). In contrast, characterization and understanding of the sequence of IETs is far from being fully explored. The correlations between IETs have been described in terms of memory coefficient35 and bursty train size distribution12 among others6. The memory coefficient is a Pearson correlation coefficient between two consecutive IETs. To capture the structure beyond pairwise correlations the notion of bursty trains has been suggested. The size of bursty train or burst size is defined as the number of consecutive events that are not separated by IETs larger than some fixed length of time interval, which we call time window. Several empirical distributions of burst sizes are found to show heavy tails or power-law tails for a wide range of time windows12,37, which clearly implies the existence of higher-order correlations between IETs than simply expected by the memory coefficient. These findings naturally raise an important question: what is the origin of such higher-order temporal correlations? This issue has rarely been explored, except for a recent numerical study demonstrating the role of the tendency of bigger (smaller) bursts to be followed by bigger (smaller) ones in the higher-order temporal correlations36.
We stress that the burst-size distribution of a time series is far from capturing the entire structure of temporal correlations present in the time series: The burst-size distributions are often based on a few or even a single—often arbitrarily chosen—time windows, which limits the interpretation of the results to these specific time windows. Further, information on the correlations between consecutive bursts is missing in the burst-size distributions. This information is crucial for understanding the mechanisms behind the higher-order correlations between IETs evidenced by heavy-tailed burst-size distributions, as well as for exploring the implications of this type of higher-order correlations. Therefore, it is strongly required to go beyond the current state of the art and devise a method for comprehensively characterizing the structure of temporal correlations in event sequences.
In this paper we propose a method of representing an event sequence by a burst tree, which is then decomposed into a set of IETs and an ordinal burst tree. These two aspects together fully determine the event sequence but can still be analyzed independently of each other. The IET distribution reveals the temporal scales between two consecutive events, while the ordinal burst tree does the same for their higher-order correlation structure. As the IET distributions have been extensively analyzed in the literature6, we focus mostly on the higher-order correlation structure in the event sequences. By estimating the so-called merging kernel from the revealed ordinal burst tree, we empirically demonstrate that the burst-tree decomposition is indeed useful to directly characterize the preferential and assortative mixing structure of bursts responsible for the higher-order correlations between IETs. Further, we observe that event sequences show similar burst-tree structure, such as heavy-tailed burst-size distributions, despite of very different IET distributions. This indicates that the IET distributions and the burst-tree structures can be separable also in the generative mechanisms of the time series. The burst-tree structure also allows us to construct novel microcanonical randomized reference models for event sequences38, which can be used to explore the implications of higher-order correlations in a controlled and meaningful way. Finally, we successfully generate event sequences showing the empirically observed higher-order temporal correlations using a simple model based on the burst-tree structure.
Burst-tree decomposition method
We propose the burst-tree decomposition method for detecting the temporal correlation structure in an event sequence. A bursty train has been characterized by a set of rapidly occurring events in a short-time period. Precisely, for a given time window \(\Delta t\), a bursty train is defined as a set of events such that interevent times (IETs) between any two consecutive events in the bursty train are less than or equal to \(\Delta t\), while those between events in different bursty trains are larger than \(\Delta t\)12. The number of events in each bursty train is called a burst size. In one limiting case, when \(\Delta t\) is smaller than the minimum IET of the given event sequence, denoted by \(\tau _{\mathrm{min}}\), each event constitutes a burst of size 1 on its own because every event is separated from its previous and next events by IETs larger than \(\tau _{\mathrm{min}}\). In the other limiting case, when \(\Delta t\) is larger than the maximum IET of the given event sequence, denoted by \(\tau _{\mathrm{max}}\), each event occurs within \(\Delta t\) since its previous event. Therefore, all events belong to one burst, which we call a giant burst. Then by increasing \(\Delta t\) continuously from \(\tau _{\mathrm{min}}\) to \(\tau _{\mathrm{max}}\), the bursts of size 1 will consecutively merge to form bigger bursts, finally ending up with a giant burst, see Fig. 1a for a schematic diagram. Such a merging process can be fully described by a rooted tree whose leaf nodes, internal nodes, and the root node correspond to the events, the mergings or merged bursts, and the giant burst, respectively. Note that the root node is also an internal node. Hence, this burst tree of the event sequence reveals the entire structure of temporal correlations, precisely, the information on which bursts are merged with which other bursts as the time window continuously increases. This information is totally missing in the burst-size distributions that are often measured at several discrete values of the time window. We remark that the burst tree derived from events in the time axis can be seen as a hierarchical data clustering of points in one-dimensional space using the nearest neighbor distance39.

(a) Schematic diagram for the burst-tree decomposition method of an event sequence. The lower horizontal arrow denotes a time axis and blue vertical lines are events. The upper burst tree is derived by increasing the time window \(\Delta t\) from 0 to the maximum IET \(\tau _{\mathrm{max}}\) of the event sequence. At the bottom of the tree are the leaf nodes (red empty circles). Each internal node (red filled circle) in the tree denotes the merging of its left and right children, and the number next to the internal node is the burst size after merging. The height of the internal node corresponds to the IET between the last event of the left child and the first event of the right child. The horizontal dashed line indicates an example of time window, leading to the sequence of detected burst sizes, \(\{3,6,1,4\}\). (b) A burst tree derived from a part of the edit sequence by the most active Wikipedia editor, namely, editor 1. (c–f) Empirical results of the editor 1’s event sequence of \(n\approx 1.1\times 10^6\) in terms of the IET distribution \(P(\tau )\), burst-size distributions \(Q_{\Delta t}(b)\) for several values of \(\Delta t\), the memory coefficient between consecutive bursts \(M_b\) as a function of \(\Delta t\), and the merging kernel \(K(b_v,b_w)\). In the panel (d), \(\langle b\rangle _{\Delta t}\) is the average burst size for a given \(\Delta t\). In the panel (e), the error bars denote standard deviations in binning the data. Vertical dashed lines in panels (c,e) denote 1 day.
We start by introducing a notation for event sequences. A given event sequence of \(n+1\) events can be described by an ordered set of event timings \(\{{\hat{t}}_0,\ldots ,{\hat{t}}_n\}\). In most cases \({\hat{t}}_0\) indicates the beginning time of data collection. Otherwise, its relationship to the beginning time of data collection can be used to infer IET distributions40. For convenience we shift timings by \({\hat{t}}_0\) using \(t_i\equiv {\hat{t}}_i-{\hat{t}}_0\) for the ith event. This leads to the shifted event sequence \({\mathscr {E}}\equiv \{t_0,\ldots ,t_n\}\) with \(t_0=0\) by definition. From \({\mathscr {E}}\) the sequence of IETs is derived as \(\{\tau _1,\ldots ,\tau _n\}\) by the definition of \(\tau _i\equiv t_i-t_{i-1}\).
Using the shifted event sequence \({\mathscr {E}}\) we can now formally define the burst tree. Firstly, each of \(n+1\) leaf nodes of the tree represents a single event, i.e., a burst of size 1. Secondly, each of n internal nodes of the tree, indexed by u, represents a merging of two consecutive bursts, indexed by v and w, respectively. Here v (w) is the index of the earlier (later) burst among them or the left (right) child of its parent node u. The IET between bursts v and w, i.e., the time interval between the last event in v and the first event in w, is associated with the internal node u, and this IET is denoted by \({\hat{\tau }}_u\). Note that the distribution of \({\hat{\tau }}_u\)s is exactly the same as that of \(\tau _i\)s, denoted by \(P(\tau )\). Although the leaf nodes are not associated with any IET by construction, we set their associated IETs as 0 for convenience. The index u for the internal node follows the rank of its associated IET in \(\{{\hat{\tau }}_u\}\), e.g., \(u=1\) for the root node as \({\hat{\tau }}_1=\tau _{\mathrm{max}}\). In sum, each internal node is represented by a tuple of \((u,v,w,{\hat{\tau }}_u)\), and the burst tree by \({\mathscr {T}}\equiv \{(u,v,w,{\hat{\tau }}_u)\}\) for \(u=1,\ldots ,n\). Once the burst tree is derived, the burst size for each internal node u, denoted by \(b_u\), is computed as being equal to \(b_v+b_w\).
The burst tree \({\mathscr {T}}\) is an alternative representation of the event sequence \({\mathscr {E}}\). That is, the event sequence \({\mathscr {E}}\) can be exactly reconstructed by two steps. (1) Internal nodes of \({\mathscr {T}}\) are visited in the inorder, where the inorder traversal is a depth-first way of traversing a tree by which one first visits the left (earlier) subtree before visiting the branching node and lastly the right (later) subtree. (2) Then the ith event timing for \(i=1,\ldots ,n\) is set as \(t_i=t_{i-1}+{\hat{\tau }}_{u(i)}\), where u(i) denotes the ith visited internal node by the inorder traversal. We denote the above equivalence by \({\mathscr {E}} \, \widehat{=}\, {\mathscr {T}}\). Now \({\mathscr {T}}\) can be decomposed into the IET distribution \(P(\tau )\) and the ordinal burst tree \({\mathscr {G}}\equiv \{(u,v,w)\}\). Here the ordinal burst tree retains the information on the ranks or orders of internal nodes, while the information on the IETs is discarded. As before, \({\mathscr {T}}\) can be exactly reconstructed by associating the uth largest IET in \(P(\tau )\) to the internal node u in \({\mathscr {G}}\). We denote this equivalence by \({\mathscr {T}} \, \widehat{=} \, (P(\tau ),{\mathscr {G}})\). By transitivity, \({\mathscr {E}}\) is also equivalent to \((P(\tau ),{\mathscr {G}})\), i.e., \({\mathscr {E}} \, \widehat{=} \, (P(\tau ),{\mathscr {G}})\).
We note that if more than two consecutive bursts are separated by IETs of the same length, hence merged to the same node at the same time, then the order in which those bursts are merged in a pairwise manner is not well defined. In such cases, we randomly and uniformly choose two consecutive bursts and merge them into one burst, and repeat this binary merging until all these bursts are merged into one burst. These corner cases leading to the non-binary merging are insignificant for the analysis of the datasets in the next section (see Supplementary Methods and SI Fig. S1a,b). We also remark that the burst-tree decomposition method has some conceptual resemblance to visibility graphs41 in a sense that both methods map time series onto graphs.
Higher-order structure in data
Data description
We consider four time series datasets: English Wikipedia, Twitter, heartbeat, and Japan University Network Earthquake Catalog (JUNEC). (1) We analyze edit sequences by editors from the English Wikipedia dump on October 2, 201542. Each edit is recorded with the timing of edit in a resolution of seconds. As a case study, we choose one of the most active human editors, who edited more than 1.1 million times for over 8.5 years until 2015. We call this editor as the editor 1. (2) We also analyze activity patterns of Twitter users in a dataset collected in 200943. The data contains timings of tweets in a resolution of seconds. As an example, we focus on the most active user, who turns out to be a bot account, with around 87 thousand tweets in the time period, which we call the user 1. (3) We then analyze the heartbeat time series of healthy individuals or subjects (normal sinus rhythm) measured for 24-h period in a resolution of milliseconds44, which was downloaded from PhysioBank45. Here each event denotes each beat. We focus on one of the subjects, which we call the subject 1. (4) Finally, we analyze the earthquake sequence in the JUNEC including around \(2.0\times 10^5\) earthquakes occurred in Japan from July 1, 1985 to December 31, 199846.
Preferential and assortative mixing structure
As a case study, we analyze the Wikipedia editor 1’s event sequence of \(n\approx 1.1\times 10^6\) using the burst-tree decomposition method. In Fig. 1b, we show a burst-tree structure derived from a part of the event sequence by the editor 1. We also find a power-law scaling in the interevent time (IET) distribution, i.e., \(P(\tau )\sim \tau ^{-\alpha }\) with \(\alpha =1.77(1)\) for \(30<\tau <10^4\) in seconds, as shown in Fig. 1c.
We first demonstrate that the burst-size distribution for a given time window is indeed directly derived from the burst tree: A burst-size distribution \(Q_{\Delta t}(b)\) for a time window \(\Delta t\) is simply obtained from the cross-section of the burst tree by the horizontal line at the height of \(\Delta t\) as graphically depicted in Fig. 1a. Here each crossing point between the burst tree and the horizontal dashed line indicates a burst, leading to the sequence of burst sizes as \(\{3,6,1,4\}\). Precisely, we collect pairs of a child (either leaf node or internal node) and its parent satisfying the condition that an IET associated with the child is smaller than or equal to \(\Delta t\), while its parent is associated with an IET larger than \(\Delta t\). Denoting the time-ordered set of such children by \(C_{\Delta t}\), the burst-size distribution \(Q_{\Delta t}(b)\) is directly obtained from the burst sizes \(b_u\) of nodes \(u \in C_{\Delta t}\). We find for the editor 1 that \(Q_{\Delta t}(b)\sim b^{-\beta }\) with \(\beta =2.52(5)\) for a wide range of \(\Delta t\), as shown in Fig. 1d.
The reason why burst-size distributions show power-law tails, often with the same power-law exponent, for a wide range of time window in several empirical analyses has been elusive6. A recent numerical study demonstrated the role of the tendency of bigger (smaller) bursts to be followed by bigger (smaller) ones in the higher-order temporal correlations36. This tendency of assortative mixing can be directly tested by measuring correlations between consecutive bursts. For this, we introduce a memory coefficient \(M_b\) for a given \(\Delta t\) as a Pearson correlation coefficient between burst sizes of two consecutive nodes in \(C_{\Delta t}\) as follows:
where \(n_b = |C_{\Delta t}|\) is the number of bursts and \(b^{(k)}\) denotes the burst size of the kth node in \(C_{\Delta t}\) for \(k=1,\ldots ,n_b\). \(\mu _1\) (\(\mu _2\)) and \(\sigma _1\) (\(\sigma _2\)) denote the average and standard deviation of burst sizes of nodes except for the last (the first) node in \(C_{\Delta t}\), respectively. Note that a similar definition has been proposed to measure the correlation between consecutive IETs35. Positive \(M_b\) implies a tendency of big (small) bursts to be followed by big (small) ones. The opposite tendency can be observed for the negative \(M_b\), while \(M_b=0\) indicates the absence of correlations between consecutive burst sizes. Figure 1e shows that \(M_b\) for the editor 1 has positive values of \(0.2\sim 0.3\) for several decades of \(\Delta t\), clearly revealing the assortative mixing structure of bursts. Note that large fluctuations of \(M_b\) for \(\Delta t>1\) day might be due to the finite-size effect.
The origin of power-law behaviors in burst-size distributions as well as other higher-order temporal correlations including the positive correlation between consecutive bursts can be more systematically investigated using the burst-tree structure derived from the event sequence. For this, we observe that the merging process of bursts with increasing \(\Delta t\) from \(\tau _{\mathrm{min}}\) to \(\tau _{\mathrm{max}}\) can be interpreted as a stochastic process for coalescence in physical or networked systems47. Instead of \(\Delta t\), we use the cumulative number of binary mergings, denoted by s, as an auxiliary time in the merging process. Then the merging process can be described as follows: at the time step \(s=0\) (i.e., \(\Delta t<\tau _{\mathrm{min}}\)) we have \(n+1\) events, equivalently, \(n+1\) bursts of size 1. At each time step s, one has \(n+1-s\) bursts, whose burst-size distribution is denoted by \(Q_s(b)\). A pair of bursts among \(n+1-s\) bursts are randomly chosen with a probability proportional to a function of burst sizes of the pair. This function is called the merging kernel, denoted by \(K(b_v,b_w)\), for the pair of burst sizes \(b_v\) and \(b_w\). Then these two bursts are merged into another burst of size \(b_v+b_w\). This process is repeated until all events eventually belong to a giant burst (i.e., \(\Delta t\ge \tau _{\mathrm{max}}\)).
We consider the empirical ordinal burst tree \({\mathscr {G}}\) as a realization of the above merging process. As each merging corresponds to an internal node u in \({\mathscr {G}}\), the time step s is related to the node index u as \(s=n-u\). For estimating the merging kernel from \({\mathscr {G}}\), we define \(m_s(b_v,b_w)\) at the time step s (i.e., for the internal node \(u=n-s\)) as having a value of 1 if its child nodes have burst sizes \(b_v\) and \(b_w\), and 0 otherwise. The merging kernel is now estimated using the following formula:
Intuitively speaking, the expectation value of \(m_s(b_v,b_w)\) essentially corresponds to the possibility that two bursts of sizes \(b_v\) and \(b_w\) are chosen at the time step s, which is proportional to \(K(b_v,b_w)\times Q_s(b_v) Q_s(b_w)\). Here we have assumed that the merging kernel is constant over the time step. Equation (2) has been modified from the formula that was introduced to numerically estimate the kernel for the preferential attachment mechanism in the growing scale-free network48: in a growing network newly introduced nodes choose some of existing nodes for making connections to them, which is governed by a function (or kernel) of the number of connections (or degree) of the existing node. If the kernel is a linear function of the degree, the degree distribution of the network follows a power law, hence the name of the scale-free network49. Therefore, we expect the estimated merging kernel to reveal the mechanism behind the power-law burst-size distributions observed in the data.
From the merging kernel estimated for the editor 1 in Fig. 1f, we make three important observations: (1) \(K(b_v,b_w)\) shows a high profile in the diagonal part around the line of \(b_v=b_w\), while it has low values in the off-diagonal part. (2) The diagonal cross-section K(b, b) is an overall increasing function of b. (3) \(K(b_v,b_w)\) shows an overall symmetric behavior with respect to the diagonal axis, implying \(K(b,b')\approx K(b',b)\). The observation (1) indicates that bigger (smaller) bursts tend to be followed by bigger (smaller) ones, i.e., the assortative mixing of bursts, which is consistent with the observation of positive \(M_b\) for a wide range of \(\Delta t\). This tendency can also be quantified in terms of the Pearson correlation coefficient for the pairs of \((b_v,b_w)\) for a subset of internal nodes u whose associated IETs are the same as \(\Delta t\), denoted by \(M_{lr}\) (see Supplementary Methods). The \(M_{lr}\) reveals the \(\Delta t\)-dependence of the assortative mixing structure, which is missing in the merging kernel estimation. The observation (2) implies the preferential mixing structure of bursts, by which bigger bursts tend to be followed by other bursts within shorter time intervals than the smaller bursts. Conclusively, these empirical evidences enable us to understand the power-law behavior of burst-size distributions in Fig. 1d by means of the preferential and assortative mixing structure. Further, the observation (3) can be interpreted in the context of the time asymmetry regarding the issues of nonlinearity or irreversibility in time series50,51,52,53. The overall symmetric behavior of \(K(b_v,b_w)\) might be due to the time symmetry in terms of consecutive burst sizes (see Supplementary Methods).

Empirical results for the tweet sequence of Twitter user 1 of \(n\approx 8.5\times 10^4\) (top), the heartbeat time series of subject 1 of \(n\approx 1.1\times 10^5\) (middle), and Japanese earthquake sequence (JUNEC) of \(n\approx 2.0\times 10^5\) (bottom), in terms of the IET distribution \(P(\tau )\), burst-size distributions \(Q_{\Delta t}(b)\), the memory coefficient between consecutive bursts \(M_b\), and the merging kernel \(K(b_v,b_w)\) (from left to right), respectively. In panels (b,f,j), \(\langle b\rangle _{\Delta t}\) is the average burst size for a given \(\Delta t\). In panels (c,g,k), the error bars denote standard deviations in binning the data.
Our framework of the burst-tree decomposition can be straightforwardly applied to any other event sequences. We have analyzed edit sequences of other active editors in the English Wikipedia, tweet sequences of active Twitter users, heartbeat time series of healthy subjects, and the earthquake sequence in the JUNEC. Among them, the results for the Twitter user 1, for the heartbeat subject 1, and for the earthquake sequence are summarized in Fig. 2, while those for other Wikipedia editors, other Twitter users, and other heartbeat subjects are presented in SI Figs. S2–S4. For most event sequences analyzed, we find heavy-tailed burst-size distributions \(Q_{\Delta t}(b)\) for several values of \(\Delta t\), positive \(M_b\) for a wide range of \(\Delta t\), and merging kernels \(K(b_v,b_w)\) with overall increasing K(b, b).
Interestingly, as shown in Fig. 2, we commonly observe nontrivial structure of burst trees, such as heavy-tailed burst-size distributions, irrespective of the functional form of IET distributions \(P(\tau )\). This clearly shows not only that the IET distributions and the burst-tree structures are separable—as is evident from the equivalence relation of \({\mathscr {E}} \, \widehat{=} \, (P(\tau ),{\mathscr {G}})\)—but also that there is no strong connection between them.
Finally, we remark that there could be alternative mechanisms behind the power-law distributions of burst sizes. Since the merging process with increasing \(\Delta t\) is similar to the percolation process with increasing connectivity between elements of the system, one can hypothesize that the power-law burst-size distribution could correspond to the power-law distribution of connected component sizes at the percolation transition point. However, this analogy may not be plausible because the power-law burst-size distribution is observed for a wide range of \(\Delta t\) in our empirical analysis, while the power-law distribution of connected component sizes appears only at the percolation transition point in the conventional percolation problem54,55. By measuring the fraction of the largest burst size and the susceptibility as functions of \(\Delta t\) for the editor 1, we find that the percolation transition occurs around at \(\Delta t\approx 1\) day (see Supplementary Methods and SI Fig. S1c), supporting our argument against the analogy to the percolation problem.
Randomized reference models
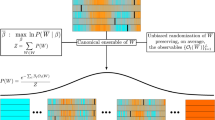
Next, we demonstrate that our burst-tree decomposition method can be useful to systematically characterize temporal correlations or features in event sequences. For this, we adopt the methodology of microcanonical randomized reference models (MRRMs) for event sequences. The MRRMs have been extensively applied to characterize various features in temporal networks, see the paper by Gauvin et al. 38 and references therein. These MRRMs can be defined with the set of features they retain, and here we denote by \({\mathbf {P}}[X]\) the MRRM which exactly retains the feature X, while maximally randomizing everything else. The MRRMs can be ordered according to the amount of information they preserve, such that the simpler or less informative the features are, the more of the original data is shuffled or randomized. In our work, we adopt the framework of the MRRMs for analyzing event sequences. So far only very simple features discarding higher-order correlations such as the IET distribution have been considered in the literature38. To investigate the effects of keeping higher-order structures, compared to keeping only the simple ones, we will study the higher-order MRRMs based on the burst-tree structure.
The simplest MRRM used here is the one that only keeps the number of events, \({\mathbf {P}}[n+1]\). This MRRM randomizes the timings of events by assigning to each event a random timing drawn from a uniform distribution in the entire time period \([t_0,t_n]\). In the limit of large n this results in a Poisson process with an event rate determined only by the number of events and the time period56. The next simplest MRRM, denoted by \({\mathbf {P}}[n+1,P(\tau )]\), retains the number of events and the IET distribution, which we call the IET MRRM. By permuting IETs in the empirical IET sequence, the IET MRRM only keeps correlations between two consecutive events, while all the higher-order correlations considering more than two consecutive events are destroyed.
There are several possibilities of devising MRRMs based on the burst-tree structure. Here we are interested in the question about whether the arrow of time is relevant to the structure of temporal correlations. To study this issue, we first define an unoriented ordinal burst tree \(\hat{{\mathscr {G}}}=\{(u, [v, w])\}\), which is the same as the ordinal burst tree \({\mathscr {G}}\) defined in the previous section, except that the set [v, w] does not carry any information on the left-right orientation of v and w. Now we devise an MRRM, denoted by \({\mathbf {P}}[P(\tau ),\hat{{\mathscr {G}}}]\), which keeps all features other than the left-right orientation of bursts. This MRRM is implemented by randomly swapping the left and right children for each internal node u, enabling us to call it the left-right MRRM. It strictly conserves the features measured by \(P(\tau )\), \(Q_{\Delta t}(b)\), and K(b, b), while it may destroy other features, e.g., measured by \(M_b\). The features conserved in the above three MRRMs are summarized in Table 1. For the Wikipedia editor 1 and Twitter user 1, one can also introduce variants of the left-right MRRM by limiting the shuffling only to internal nodes with IETs larger (or smaller) than a fixed timescale of 1 day, aiming to destroy the left-right structure for the timescale longer (or shorter) than 1 day. The results of these variants are included in SI Figs. S5 and S6.
Using the empirical event sequences, we test if the features that are not necessarily destroyed by the randomization still remain after the randomization. For each MRRM, we generate 100 randomized event sequences to measure various quantities for detecting the corresponding features for each randomized event sequence, from which we obtain the curves of median, 95th and 5th percentiles to compare them to the original curves. As for the merging kernel, we compare the results of its diagonal cross-section K(b, b) instead of \(K(b_v,b_w)\) for effective comparison.
As an example, we find for the editor 1 that the shuffling of event timings destroys all temporal correlations, while the shuffling of IETs does the same apart from the IET distribution as expected, as shown in Fig. 3a–c. Interestingly, the shuffling of the left-right children turns out to barely destroy the feature measured by \(M_b\) as depicted in Fig. 3d. It implies that the correlations between two consecutive burst sizes (measured by \(M_b\)) might be dominated by those between sibling bursts (measured by the merging kernel). The complete results of the MRRM for the editor 1 are shown in SI Fig. S5. We also find the similar results for other datasets, i.e., the Twitter user 1, the heartbeat subject 1, and the JUNEC. For the complete results of MRRMs for the Twitter user 1, the heartbeat subject 1, and the JUNEC, see Supplementary Methods and SI Figs. S6–S8, respectively.

Results of two microcanonical randomized reference models (MRRMs) for the Wikipedia editor 1’s edit sequence using 100 randomized sequences for each MRRM: (a–c) IET MRRM and (d) left-right MRRM. In all panels, the median is plotted by the red solid curve, while 95th and 5th percentiles by the orange solid curves. The original curves are also plotted by blue symbols for comparison. Vertical dashed lines in panels (c,d) denote 1 day.

Simulation results of the kernel-based model using the model kernel in Eq. (3) with various sets of parameter values, as depicted in the left panels. For each case, 100 event sequence of \(n=10^5\) are generated, also using the IET distribution in Eq. (4) with \(\alpha =1.8\). By aggregating the detected burst sizes in 100 event sequences, we obtain the burst-size distributions \(Q_{\Delta t}(b)\) for several values of \(\Delta t\), rescaled by the average burst size \(\langle b\rangle _{\Delta t}\) (center panels). The curves of memory coefficients \(M_b\) are averaged over 100 event sequences (right panels), where the error bars denotes the standard errors.
The conclusion of the above MRRM study is that the features of the burst tree we observed for the data cannot be explained by randomness, but there is much more structure in the time series than just the IET distributions. Further, the temporal order of the bursts does not have a major effect on the observed burst-tree structure. Based on this conclusion, one can devise a simple model, mainly exploiting the merging kernel, for generating the event sequence with the empirically observed higher-order temporal correlations, as discussed in the next subsection.
Kernel-based modeling
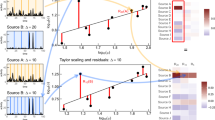
Based on the empirical findings for the merging kernel, we can devise a simple model to reproduce the temporal correlations observed in the empirical event sequences. To generate an event sequence consisting of \(n+1\) events, we need an interevent time (IET) distribution \(P(\tau )\) for drawing n IETs, and an ordinal burst tree \({\mathscr {G}} = \{(u,v,w)\}\) with n internal nodes for the higher-order correlations between those IETs. For constructing the ordinal burst tree with n internal nodes, we begin with \(n+1\) events or leaf nodes, i.e., \(n+1\) bursts of size 1. Then two bursts, say b and \(b'\), are randomly chosen with a probability proportional to a model kernel \(K(b,b')\). These two bursts are merged and randomly set as the left and right children of the merged burst, i.e., their parent node. This parent node is indexed by n as this node will be associated with the smallest IET in \(P(\tau )\). The next merging leads to another parent node to be indexed by \(n-1\), and so on. This binary merging is repeated until we end up with the giant burst of size \(n+1\). Inspired by the empirical merging kernels, e.g., in Figs. 1f and 2d,h,l, we adopt the following model kernel:
with positive parameters \(c_1\), \(c_2\), and \(c_3\). The first parenthesis of the right hand side in Eq. (3) describes an increasing behavior of the diagonal cross-section along the line of \(b=b'\) for the preferential mixing of bursts. The second parenthesis is to implement the symmetrically decaying behavior with respect to the diagonal axis, which is for the assortative mixing of bursts. For example, see the heatmap of this model kernel for \(c_1=3\), \(c_2=100\), and \(c_3=4\) in Fig. 4a.
Once the ordinal burst tree is ready, we draw n random numbers from an IET distribution \(P(\tau )\) to get a set of n IETs, \(\{\tau _i\}\). Precisely, we use a power-law IET distribution with an exponent \(\alpha >1\):
After assigning the IETs in \(\{\tau _i\}\) to the internal nodes in \({\mathscr {G}}\), e.g., the largest IET to the root node, the event sequence of \(n+1\) events is obtained by setting \(t_0=0\) and then by calculating the event timings as \(t_i=t_{i-1}+{\hat{\tau }}_{u(i)}\), where u(i) denotes the ith visited internal node when traversing the ordinal burst tree in the inorder. This event sequence is analyzed to find that our simple kernel-based model successfully generates the event sequence showing the heavy-tailed burst-size distributions for several values of \(\Delta t\) as well as positive \(M_b\) for a wide range of \(\Delta t\), as shown in Fig. 4b,c.
Using our kernel-based model, we can test if both preferential and assortative mixing structures are necessary for the power-law burst-size distributions. The case with only assortative mixing can be studied by setting \(c_1=0\), leading to the constant K(b, b), as depicted in Fig. 4d. This leads to thinner tails of \(Q_{\Delta t}(b)\) than those for the case with \(c_1>0\). Yet the positive \(M_b\) are observed, implying that the assortative mixing is not sufficient to generate the power-law burst-size distributions. Next, we consider the case only with the preferential mixing by setting \(c_2=0\). Then the diagonal part of \(K(b,b')\) is no longer higher than the off-diagonal part, as depicted in Fig. 4g. It turns out that tails of \(Q_{\Delta t}(b)\) are thinner than those for the case with \(c_2>0\). Further, the values of \(M_b\) are almost zero or even slightly negative for a wide range of \(\Delta t\), because big and small bursts can be merged with each other more easily. Therefore, we conclude that both preferential and assortative mixing structures are necessary for obtaining the power-law \(Q_{\Delta t}(b)\) and positive \(M_b\) simultaneously. Finally, we test the effect of \(c_3\) on the results: The smaller \(c_3\) leads to the steeper decay of \(K(b_v,b_w)\) along the direction perpendicular to the diagonal axis, as shown in Fig. 4j. We find no considerable differences in \(M_b\) as well as in \(Q_{\Delta t}(b)\). In particular, the shapes of \(Q_{\Delta t}(b)\) are quite similar to the case with the larger \(c_3\), probably because the heavy tails of \(Q_{\Delta t}(b)\) are largely affected by the characteristics of the diagonal cross-section K(b, b).
We also have tested other functional forms of the model kernel to draw the qualitatively same conclusions, see Supplementary Methods and SI Figs. S9 and S10. In addition, we remark that the asymmetric behavior between sibling bursts can be easily implemented in our model, e.g., by assigning a bigger (smaller) burst among chosen b and \(b'\) to the right (left) child with a probability p (\(q=1-p\)). Then the case with \(p=q=1/2\) reduces to our model, while the asymmetry can be implemented when \(p,q\ne 1/2\).
We remark that our kernel-based modeling approach could be useful to better understand the underlying or generative mechanisms leading to the bursty event sequences. The preferential and assortative mixing of bursts in our model is essentially similar to the reinforcement mechanism proposed by Karsai et al. 12, such that the bigger bursts tend to be followed by more events and/or bigger bursts. However, our model enables to control different burst-mixing behaviors more explicitly than previous modeling approaches12,23. In this sense, our kernel-based model can be reformulated into a more intuitive, generative model, which is left for future work.
Conclusion
The comprehensive characterization of temporal correlations observed in various natural and social processes is crucial to the understanding of the underlying mechanisms behind such temporal processes. Non-Poissonian or bursty temporal patterns in empirical event sequences have been studied mostly in terms of heterogeneous interevent times (IETs), while the higher-order correlations between IETs are far from being fully understood due to the lack of the proper characterization method. In this paper we have proposed the burst-tree decomposition method that first represents an event sequence by a burst tree without loss of information on the temporal correlations, which is then decomposed into a set of IETs and an ordinal burst tree. This implies that the ordinal burst tree, together with an IET distribution, can exactly reproduce the original event sequence. Using our burst-tree decomposition method one can systematically study the structure of temporal correlations: The preferential and assortative mixing structure of bursts is empirically validated by measuring the novel memory coefficient between consecutive bursts as well as the merging kernel. The correlations between two consecutive burst sizes is found to be dominated by those between sibling bursts. In addition, the burst-tree decomposition turns out to be useful for the systematic investigation of temporal correlations in the framework of randomized reference models38. Finally, based on the empirically estimated merging kernels, we devise a kernel-based model to successfully generate event sequences showing the higher-order temporal correlations observed in the empirical datasets.
We remark that once the ordinal burst tree is derived or given, it can be associated with any other set of IETs, irrespective of the functional form of the IET distribution. This clearly shows that the IET distributions and the burst-tree structures can be separable. Further, apparently very different event sequences might have the similar temporal correlation structure when their burst trees look similar to each other. We have observed this type of phenomenon in the empirical event sequences that show heavy-tailed burst-size distributions despite of very different IET distributions. In addition, mapping the structure of temporal correlations onto a tree enables to propose other novel quantities for measuring various higher-order correlations as a tree structure is more intuitive and better visualized than the time series itself. Finally, we have considered only a binary tree in our work, while for more realistic decomposition of the event sequences in various datasets more complex trees than a binary tree can be used in a future.
Data availability
The datasets analyzed in the work have been downloaded from publicly available data repositories.
Code availability
Source codes for analyzing data and modeling in the manuscript have been deposited into the public repository GitHub in https://github.com/h2jo/burst_tree.
References
Wheatland, M. S., Sturrock, P. A. & McTiernan, J. M. The waiting-time distribution of solar flare hard X-ray bursts. Astrophys. J. 509, 448–455. https://doi.org/10.1086/306492 (1998).
Corral, Á. Long-term clustering, scaling, and universality in the temporal occurrence of earthquakes. Phys. Rev. Lett. 92, 108501. https://doi.org/10.1103/PhysRevLett.92.108501 (2004).
de Arcangelis, L., Godano, C., Lippiello, E. & Nicodemi, M. Universality in solar flare and earthquake occurrence. Phys. Rev. Lett. 96, 051102. https://doi.org/10.1103/physrevlett.96.051102 (2006).
Kemuriyama, T. et al. A power-law distribution of inter-spike intervals in renal sympathetic nerve activity in salt-sensitive hypertension-induced chronic heart failure. BioSystems 101, 144–147. https://doi.org/10.1016/j.biosystems.2010.06.002 (2010).
Barabási, A.-L. The origin of bursts and heavy tails in human dynamics. Nature 435, 207–211. https://doi.org/10.1038/nature03459 (2005).
Karsai, M., Jo, H.-H. & Kaski, K. Bursty Human Dynamics (Springer, Cham, 2018).
Bak, P., Tang, C. & Wiesenfeld, K. Self-organized criticality: An explanation of the 1/f noise. Phys. Rev. Lett. 59, 381–384. https://doi.org/10.1103/physrevlett.59.381 (1987).
Weissman, M. B. 1/f noise and other slow, nonexponential kinetics in condensed matter. Rev. Mod. Phys. 60, 537–571. https://doi.org/10.1103/revmodphys.60.537 (1988).
Ward, L. & Greenwood, P. 1/f noise. Scholarpedia 2, 1537. https://doi.org/10.4249/scholarpedia.1537 (2007).
Kantelhardt, J. W., Koscielny-Bunde, E., Rego, H. H. A., Havlin, S. & Bunde, A. Detecting long-range correlations with detrended fluctuation analysis. Phys. A 295, 441–454. https://doi.org/10.1016/s0378-4371(01)00144-3 (2001).
Allegrini, P. et al. Spontaneous brain activity as a source of ideal 1/f noise. Phys. Rev. E 80, 061914. https://doi.org/10.1103/PhysRevE.80.061914 (2009).
Karsai, M., Kaski, K., Barabási, A.-L. & Kertész, J. Universal features of correlated bursty behaviour. Sci. Rep. 2, 397. https://doi.org/10.1038/srep00397 (2012).
Yasseri, T., Sumi, R., Rung, A., Kornai, A. & Kertész, J. Dynamics of conflicts in Wikipedia. PLoS One 7, e38869. https://doi.org/10.1371/journal.pone.0038869 (2012).
Peng, C.-K. et al. Mosaic organization of DNA nucleotides. Phys. Rev. E 49, 1685–1689. https://doi.org/10.1103/PhysRevE.49.1685 (1994).
Rybski, D., Buldyrev, S. V., Havlin, S., Liljeros, F. & Makse, H. A. Scaling laws of human interaction activity. Proc. Nat. Acad. Sci. 106, 12640–12645. https://doi.org/10.1073/pnas.0902667106 (2009).
Rybski, D., Buldyrev, S. V., Havlin, S., Liljeros, F. & Makse, H. A. Communication activity in a social network: Relation between long-term correlations and inter-event clustering. Sci. Rep. 2, 560. https://doi.org/10.1038/srep00560 (2012).
Vázquez, A. et al. Modeling bursts and heavy tails in human dynamics. Phys. Rev. E 73, 036127. https://doi.org/10.1103/physreve.73.036127 (2006).
Malmgren, R. D., Stouffer, D. B., Motter, A. E. & Amaral, L. A. N. A Poissonian explanation for heavy tails in e-mail communication. Proc. Nat. Acad. Sci. 105, 18153–18158. https://doi.org/10.1073/pnas.0800332105 (2008).
Malmgren, R. D., Stouffer, D. B., Campanharo, A. S. L. O. & Amaral, L. A. On universality in human correspondence activity. Science 325, 1696–1700. https://doi.org/10.1126/science.1174562 (2009).
Jo, H.-H., Pan, R. K., Perotti, J. I. & Kaski, K. Contextual analysis framework for bursty dynamics. Phys. Rev. E 87, 062131. https://doi.org/10.1103/physreve.87.062131 (2013).
Masuda, N., Takaguchi, T., Sato, N. & Yano, K. Self-exciting point process modeling of conversation event sequences. In Temporal Networks (eds Holme, P. & Saramaki, J.) 245–264 (Springer, Berlin, 2013).
Wang, P., Zhou, T., Han, X.-P. & Wang, B.-H. Modeling correlated human dynamics with temporal preference. Phys. A 398, 145–151. https://doi.org/10.1016/j.physa.2013.12.014 (2014).
Jo, H.-H., Perotti, J. I., Kaski, K. & Kertész, J. Correlated bursts and the role of memory range. Phys. Rev. E 92, 022814. https://doi.org/10.1103/physreve.92.022814 (2015).
García-Pérez, G., Boguñá, M. & Serrano, M. Á. Regulation of burstiness by network-driven activation. Sci. Rep. 5, 9714. https://doi.org/10.1038/srep09714 (2015).
Zipkin, J. R., Schoenberg, F. P., Coronges, K. & Bertozzi, A. L. Point-process models of social network interactions: Parameter estimation and missing data recovery. Eur. J. Appl. Math. 27, 502–529. https://doi.org/10.1017/S0956792515000492 (2016).
Lee, B.-H., Jung, W.-S. & Jo, H.-H. Hierarchical burst model for complex bursty dynamics. Phys. Rev. E 98, 022316. https://doi.org/10.1103/physreve.98.022316 (2018).
Vazquez, A. Impact of memory on human dynamics. Phys. A 373, 747–752. https://doi.org/10.1016/j.physa.2006.04.060 (2007).
Karsai, M. et al. Small but slow world: How network topology and burstiness slow down spreading. Phys. Rev. E 83, 025102(R). https://doi.org/10.1103/physreve.83.025102 (2011).
Miritello, G., Moro, E. & Lara, R. Dynamical strength of social ties in information spreading. Phys. Rev. E 83, 045102(R). https://doi.org/10.1103/physreve.83.045102 (2011).
Rocha, L. E. C., Liljeros, F. & Holme, P. Simulated epidemics in an empirical spatiotemporal network of 50,185 sexual contacts. PLoS Comput. Biol. 7, e1001109. https://doi.org/10.1371/journal.pcbi.1001109 (2011).
Jo, H.-H., Perotti, J. I., Kaski, K. & Kertész, J. Analytically solvable model of spreading dynamics with non-poissonian processes. Phys. Rev. X 4, 011041. https://doi.org/10.1103/physrevx.4.011041 (2014).
Delvenne, J.-C., Lambiotte, R. & Rocha, L. E. C. Diffusion on networked systems is a question of time or structure. Nat. Commun. 6, 7366. https://doi.org/10.1038/ncomms8366 (2015).
Artime, O., Ramasco, J. J. & San Miguel, M. Dynamics on networks: Competition of temporal and topological correlations. Sci. Rep. 7, 41627. https://doi.org/10.1038/srep41627 (2017).
Hiraoka, T. & Jo, H.-H. Correlated bursts in temporal networks slow down spreading. Sci. Rep. 8, 15321. https://doi.org/10.1038/s41598-018-33700-8 (2018).
Goh, K.-I. & Barabási, A.-L. Burstiness and memory in complex systems. Europhys. Lett. 81, 48002. https://doi.org/10.1209/0295-5075/81/48002 (2008).
Jo, H.-H. Modeling correlated bursts by the bursty-get-burstier mechanism. Phys. Rev. E 96, 062131. https://doi.org/10.1103/physreve.96.062131 (2017).
Wang, W. et al. Temporal patterns of emergency calls of a metropolitan city in China. Phys. A 436, 846–855. https://doi.org/10.1016/j.physa.2015.05.028 (2015).
Gauvin, L., et al. Randomized reference models for temporal networks (2018). 1806.04032.
Gan, G., Ma, C. & Wu, J. Data Clustering: Theory, Algorithms, and Applications (Society for Industrial and Applied Mathematics, Philadelphia, 2007).
Kivelä, M. & Porter, M. A. Estimating inter-event time distributions from finite observation periods in communication networks. Phys. Rev. E 92, 052813. https://doi.org/10.1103/physreve.92.052813 (2015).
Lacasa, L., Luque, B., Ballesteros, F., Luque, J. & Nuño, J. C. From time series to complex networks: The visibility graph. Proc. Nat. Acad. Sci. 105, 4972–4975. https://doi.org/10.1073/pnas.0709247105 (2008).
English Wikipedia. https://dumps.wikimedia.org/.
Yang, J. & Leskovec, J. Patterns of temporal variation in online media. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining 177–186 (ACM Press, Hong Kong, 2011). https://doi.org/10.1145/1935826.1935863.
Stein, P. & Goldsmith, R. Normal Sinus Rhythm RR Interval Database. https://doi.org/10.13026/C2S881 (2003).
PhysioBank. https://physionet.org/physiobank/.
Japan University Network Earthquake Catalog. http://wwweic.eri.u-tokyo.ac.jp/CATALOG/junec/.
Aldous, D. J. Deterministic and stochastic models for coalescence (aggregation and coagulation): A review of the mean-field theory for probabilists. Bernoulli 5, 3–48. https://doi.org/10.2307/3318611 (1999).
Pham, T., Sheridan, P. & Shimodaira, H. PAFit: A statistical method for measuring preferential attachment in temporal complex networks. PLoS One 10, e0137796. https://doi.org/10.1371/journal.pone.0137796 (2015).
Barabási, A.-L. & Albert, R. Emergence of scaling in random networks. Science 286, 509–512. https://doi.org/10.1126/science.286.5439.509 (1999).
Theiler, J., Eubank, S., Longtin, A., Galdrikian, B. & Doyne Farmer, J. Testing for nonlinearity in time series: The method of surrogate data. Phys. D Nonlinear Phenomena 58, 77–94. https://doi.org/10.1016/0167-2789(92)90102-s (1992).
Daw, C. S., Finney, C. E. A. & Kennel, M. B. Symbolic approach for measuring temporal “irreversibility”. Phys. Rev. E 62, 1912–1921. https://doi.org/10.1103/physreve.62.1912 (2000).
Porporato, A., Rigby, J. R. & Daly, E. Irreversibility and fluctuation theorem in stationary time series. Phys. Rev. Lett. 98, 094101. https://doi.org/10.1103/physrevlett.98.094101 (2007).
Donges, J. F., Donner, R. V. & Kurths, J. Testing time series irreversibility using complex network methods. Europhys. Lett. 102, 10004. https://doi.org/10.1209/0295-5075/102/10004 (2013).
Stauffer, D. & Aharony, A. Introduction to Percolation Theory 2nd edn. (Taylor & Francis, Boca Raton, 1994).
Newman, M. E. J. Networks: An Introduction 1st edn. (Oxford University Press, Oxford, 2010).
Kivelä, M. et al. Multiscale analysis of spreading in a large communication network. J. Stat. Mech Theory Exp. 2012, P03005. https://doi.org/10.1088/1742-5468/2012/03/p03005 (2012).
Acknowledgements
The authors thank Woo-Sik Son for providing us with the preprocessed dataset of the English Wikipedia. H.-H.J. acknowledges financial support by Basic Science Research Program through the National Research Foundation of Korea (NRF) Grant funded by the Ministry of Education (NRF-2018R1D1A1A09081919).
Author information
Authors and Affiliations
Contributions
H.-H.J., T.H., and M.K. conceived and designed the work, analyzed and interpreted the data, created the new software used in the work, and drafted and revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jo, HH., Hiraoka, T. & Kivelä, M. Burst-tree decomposition of time series reveals the structure of temporal correlations. Sci Rep 10, 12202 (2020). https://doi.org/10.1038/s41598-020-68157-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-68157-1
This article is cited by
-
Copula-based analysis of the autocorrelation function for simple temporal networks
Journal of the Korean Physical Society (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
