
Abstract
In this paper we investigate the relationship between direct-sum majorization formulation of uncertainty relations and entanglement, for the case of two observables. Our primary results are entanglement detection methods based on direct-sum majorization uncertainty relations. These detectors provide a set of sufficient conditions for detecting entanglement whose number grows linearly with the dimension of the state being detected.
Similar content being viewed by others

Introduction
Uncertainty relations is an essential element of quantum mechanics. They characterize intrinsic limitation on our ability to predict the outcomes of noncommuting observables simultaneously. There are various approaches to quantify these relations. The original formulation by Heisenberg1 applied the standard deviation to measure the uncertainty for momentum and position operators. This result was then generalized to arbitrary observables2. Later the entropic uncertainty relations emerged3,4,5,6,7,8,9 and found applications in the security analysis of quantum cryptographic protocols. In this approach, uncertainty is measured by entropy functions like Shannon10 and Rényi11. We refer to12 for a comprehensive review on this topic. However, entropies are by no means the most adequate to use. With this motivation, majorization is used to study uncertainty relations13. This line of research is further investigated in14,15,16.
Entanglement is one of the most counterintuitive phenomena of quantum mechanics and has been extensively investigated in the past decades17,18,19. Entangled states are key ingredient in quantum information processing, such as quantum teleportation20 and dense coding21. It is therefore important to decide whether a given quantum state is entangled or not. However, this problem is known to be computationally intractable22. As so, computationally tractable necessary conditions for entanglement detection, which provide a partial solution, have been the subject of active research in recent years23.
References 24,25 present several methods for detecting entanglement via variance based uncertainty relations. Similar methods have been designed using entropy based uncertainty relations26,27. One may wonder whether there exists a relationship between the majorization based uncertainty relation and entanglement. The answer is affirmative. In28, the author applies the tensor-product majorization formulation of uncertainty13 to the problem of entanglement detection. In this paper we use the direct-sum majorization uncertainty relation, developed in16, to design an entanglement detection method. As the direct-sum majorization bound has analytical solution while the tensor-product majorization bound does not, our direct-sum majorization based detection method is more practical than the tensor-product majorization based method.
The rest of this paper is structured as follows. We first briefly review the direct-sum majorization formulation of uncertainty. Then, we present our main result — an entanglement detection method based on the direct-sum majorization uncertainty. Example is given to illustrate how our method works.
Direct-sum Majorization Uncertainty Relations
This section presents a basic review of the majorization theory and the formulation of direct-sum majorization approach to uncertainty relations.
Majorization
Let \({{\mathbb{R}}}_{+}=[0,\infty )\) be the set of non-negative real numbers, \({{\mathbb{R}}}_{+}^{d}=\{({p}_{1},\ldots ,{p}_{d}):{p}_{i}\in {{\mathbb{R}}}_{+}\}\) be the set of d-dimensional real vectors with non-negative components. We denote by \(p\in {{\mathbb{R}}}_{+}^{d}\) a d-dimensional vector and by pi the i-th element of p. For any vector \(p\in {{\mathbb{R}}}_{+}^{d}\), let p↓ be the vector obtained from p by arranging the components of the latter in descending order. Given two vectors \(p,q\in {{\mathbb{R}}}_{+}^{d}\), p is said to be majorized by q and written \(p\,\prec \,q\) if
Intuitively, \(p\,\prec \,q\) means that the sum of largest k components of p is no larger than the sum of k largest components of q. The majorization order is a partial order, i.e., not every two vectors are comparable under majorization. When studying majorization among two vectors of different dimensions, we append 0(s) to the vector with smaller dimension so that two vectors have the same dimension.
A related concept is the supremum of a set of N vectors, defined as the vector that majorizes every element of the set and, is majorized by any vector that has the same property. We now briefly describe how to construct the supremum vector, more details can be found in13,29. Let \({\mathscr{S}}={\{{p}^{(n)}\in {{\mathbb{R}}}_{+}^{d}\}}_{n=1}^{N}\) a set of N vectors. To construct the supremum for \({\mathscr {S}}\), we define a (d + 1)-dimensional vector Ω with components Ω0 = 0, ∀k ∈ {1, …, d}
The desired supremum \({\omega }^{{\rm{\sup }}}:=({\omega }_{1}^{{\rm{\sup }}},\,\ldots ,\,{\omega }_{d}^{{\rm{\sup }}})\) is then given by
The construction given in Eq. (3) guarantees that ωsup majorizes every element of the set \({\mathscr {S}}\), but ωsup does not necessarily appear in a descending order and may, therefore, fails to be majorized by other vectors with the same property. In such case, we must perform a “flattening” process. This process starts with ωsup obtained in Eq. (3), and for every pair of components violating the descending order, say, \({\omega }_{k}^{{\rm{\sup }}} < {\omega }_{k+1}^{{\rm{\sup }}}\), replaces the pair by their mean such that the updated two elements are \({\hat{\omega }}_{k}^{{\rm{\sup }}}={\hat{\omega }}_{k+1}^{{\rm{\sup }}}=({\omega }_{k}^{{\rm{\sup }}}+{\omega }_{k+1}^{{\rm{\sup }}})/2\). This process continues until a descending vector corresponding to the supremum is obtained.
Direct-sum majorization uncertainty
We now briefly introduce the uncertainty relation characterized by direct-sum majorization relation. We remark that the results summarized here are originally presented in16.
Let H be a d-dimensional Hilbert space. Denote by \( {\cal{D}} (H)\) the set of quantum states in H. Let \({\mathbb{X}}\) and \({\mathbb{Z}}\) be two nondegenerate and noncommuting observables, and ρ be a state on H. Assume the spectral decompositions of \({\mathbb{X}}\) and \({\mathbb{Z}}\) are given by
where {|xi〉} and {|zj〉} are the eigenstates of \({\mathbb{X}}\) and \({\mathbb{Z}}\), respectively. These two set of eigenstates provide two orthonormal bases of H. We then define the probability distribution induced by the measurement of observable \({\mathbb{X}}\) for a system in state ρ in the usual manner
Similarly, measurement of observable \({\mathbb{Z}}\) for the system in state ρ induces a probability distribution given by
We are interested in the uncertainty relation induced by these two observables. In16 the direct-sum majorization approach is used to is to characterize the uncertainty about \(p({\mathbb{X}}|\rho )\) and \(q({\mathbb{Z}}|\rho )\):
where \({\omega }^{{\mathbb{X}}\oplus {\mathbb{Z}}}\) is a 2d-dimensional vector independent of ρ which can be explicitly calculated from observables \({\mathbb{X}}{\rm{and}}{\mathbb{Z}}\). Intuitively, \({\omega }^{{\mathbb{X}}\oplus {\mathbb{Z}}}\) is the supremum vector of the following set
Now we show how to compute \({\omega }^{{\mathbb{X}}\oplus {\mathbb{Z}}}\) analytically. From the definitions of p and q, we see that only the eigenstates of \({\mathbb{X}}\) and \({\mathbb{Z}}\) matter. We define a d × d unitary operator U whose elements are given by \({U}_{ij}=\langle {x}_{i}|{z}_{j}\rangle \). U is known as the overlap matrix16 as it characterizes the overlap of the two orthonormal bases. For each \(k\in \{1,\ldots ,d\}\), let SUB(U, k) be the set of submatrices of class k of U defined as
The symbols #cols(M) and #rows(M) denote the number of columns and rows of matrix M, respectively. Based on the concept of submatrices, we define the following set of coefficients, which is important in computing \({\omega }^{{\mathbb{X}}\oplus {\mathbb{Z}}}\):
where ||M|| is the operator norm equal to the maximum singular value of M, and the maximum is optimized over all submatrices of class k of U. By construction we have \({s}_{1}\le \cdots \le {s}_{d}=1\). In16 it is proved that
We append d − 1 0 s to s to make \({\omega }^{{\mathbb{X}}\oplus {\mathbb{Z}}}\) a 2d-dimensional vector. We remark that the vector s is not necessarily sorted in descending order, but we can use the “flattening” process described in the first section to make it so. To summarize, the direct-sum majorization uncertainty relation is characterized in the following theorem, originally proved in16.
Theorem 1
Let \({\mathbb{X}}\) and \({\mathbb{Z}}\) be two nondegenerate and noncommuting observables on H. For any state \(\rho \in {\cal{D}} (H)\), it holds that \(p({\mathbb{X}}|\rho )\oplus q({\mathbb{Z}}|\rho )\,\prec \,{\omega }^{{\mathbb{X}}\oplus {\mathbb{Z}}}\), where \({\omega }^{{\mathbb{X}}\oplus {\mathbb{Z}}}\) is defined in Eq. (11).
Entanglement Detection
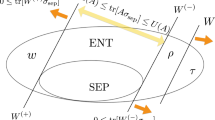
An entanglement detector decides whether a given bipartite state is separable by providing a condition that is satisfied by all separable states, and if violated, witnesses entanglement. In this section, we design a detection method based on the direct-sum majorization bound described above. As majorization relations, our detector actually provides a set of conditions whose number will grow with the dimension of the state. We first describe a majorization bound for all separable states. Then we show how this bound serves as a detector.
Majorization bounds
If an observable \({\mathbb{X}}\) is degenerate, the definition of \(p({\mathbb{X}}|\rho )\), given in Eq. (5), is not unique, since the spectral decomposition is not unique. By combining eigenstates with the same eigenvalue, however, there exists a unique spectral decomposition of the form \({\mathbb{X}}=\sum _{i}\,{\lambda }_{i}{P}_{i}\), with \({\lambda }_{i}\ne {\lambda }_{{i}^{\text{'}}}\) for \(i\ne {i}^{\text{'}}\) and Pi are orthogonal projectors of maximum rank30. Under this convention, we define for degenerate observable \({\mathbb{X}}\) the distribution pi = Tr[Piρ]. Our entanglement detection method relies on the degeneracy properties of the product observables on bipartite systems. It is possible that for two non-commuting observables \({{\mathbb{X}}}_{A}\) and \({{\mathbb{X}}}_{B}\), their product \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\) is degenerate. Consequently, it may happen that \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\) and \({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}\) have a common eigenstate, and this eigenstate is an entangled pure state. In such cases, the probabilities \(p({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}|{\rho }_{AB})\) and \(p({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}|{\rho }_{AB})\) will reflect the stated difference and may be capable of detecting entanglement. As an example, consider the Pauli Z operator σz on system A and B. The product observable on AB is given by \({\sigma }_{z}\otimes {\sigma }_{z}\). The spectral decomposition of \({\sigma }_{z}\otimes {\sigma }_{z}\) is (under our convention)
Similarly, we have \({\sigma }_{x}\otimes {\sigma }_{x}={P}_{+}-{P}_{-}\), where \({P}_{+}=|++\rangle \langle ++|+|--\rangle \langle --|\) and \({P}_{-}=\,|+-\rangle \langle +-|+\)\(|-+\rangle \langle -+|\), \(|+\rangle =(|0\rangle +|1\rangle /\sqrt{2}\), \(|-\rangle =(|0\rangle -|1\rangle /\sqrt{2}\). There exists no state \({\rho }_{A}\) that can result in certain outcomes for both σx and σz, because they do not commute. But there do exist an entangled state |Ψ〉 that can give certain outcomes for both \({\sigma }_{x}\otimes {\sigma }_{x}\) and \({\sigma }_{z}\otimes {\sigma }_{z}\), as they commute. By the Schmidt decomposition, they can be expressed in the same eigenbases which are possibly entangled.
Let \({\mathbb{X}}{}_{A}\) and \({\mathbb{X}}{}_{B}\) be two full rank observables on A and B, respectively. Assume their spectral decompositions are given by
Performing the product measurement \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\) on a bipartite state ρAB, we obtain a joint distribution
As \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\) might be degenerate, some elements p(i, j) are grouped together since they belong to the same eigenvalue. We denote by \(p({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}|{\rho }_{AB})\) the joint distribution after grouping. If we perform local measurements, we obtain marginal distributions \(p({{\mathbb{X}}}_{A}|{\rho }_{A})\) and \(p({{\mathbb{X}}}_{B}|{\rho }_{B})\). It is proved in [30, Lemma 1] that the joint distribution of a product state is majorized by the distribution of its marginal, which we restate here for completeness.
Lemma 2
Let \({\rho }_{AB}={\rho }_{A}\otimes {\rho }_{B}\) be a product state and let \({{\mathbb{X}}}_{A}\) and \({{\mathbb{X}}}_{B}\) be two observables on systems HA and HB, respectively. Then
Intuitively, this is because for the product observable \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\), its eigenstates are possibly entangled, and thus product state gives uncertain outcomes, however it is possible that the reduced state gives certain outcome for the corresponding local measurements.
Now we consider the effect of several product observables. Let \({{\mathbb{X}}}_{A}\) and \({{\mathbb{Z}}}_{A}\) be two observables on A, \({{\mathbb{X}}}_{B}\) and \({{\mathbb{Z}}}_{B}\) be two observables on B, respectively. For arbitrary product state \({\rho }_{AB}={\rho }_{A}\otimes {\rho }_{B}\), we obtain from Lemma 2 that
As the direct-sum operation preserves the majorization order31, we have
The RHS. of Eq. (18) is the direct-sum of two distributions. By the virtue of Theorem 1, it holds that
Combining Eqs. (18) and (19), we reach the following statement for arbitrary product states \({\rho }_{A}\otimes {\rho }_{B}\), one has
The majorization relation derived in Eq. (20) holds for product states. Now we show that this relation actually holds for arbitrary separable states. We are actually interested in the optimal state that majorizes all possible probability distributions \(p({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}|{\rho }_{AB})\oplus p({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}|{\rho }_{AB})\) induced by performing the measurements \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\) and \({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}\) on separable states ρAB. Such a state can be defined as
where SEP(HA: HB) is the set of separable states of the bipartite space \({H}_{A}\otimes {H}_{B}\). Let ΩSEP be the (d + 1)-dimensional vector for constructing the supremum \({\omega }_{{\rm{SEP}}}^{({{\mathbb{X}}}_{A}{{\mathbb{X}}}_{B})\oplus ({{\mathbb{Z}}}_{A}{{\mathbb{Z}}}_{B})}\) before the flattening process. That is, \({\omega }_{{\rm{SEP}}}^{({{\mathbb{X}}}_{A}{{\mathbb{X}}}_{B})\oplus ({{\mathbb{Z}}}_{A}{{\mathbb{Z}}}_{B})}\) is obtained from ΩSEP using Eq. (3) after the flattening process. We now show by contradiction that each element of ΩSEP is achieved by some pure product state. Let μl be the l-th component of ΩSEP, where l ≤ d + 1. By Eq. (2), we can assume without loss of generality that μl is achieved by some separable state \({\hat{\rho }}_{AB}=\sum _{k}\,{\lambda }_{k}|{\phi }_{k}^{A}\rangle \langle {\phi }_{k}^{A}|\otimes |{\phi }_{k}^{B}\rangle \langle {\phi }_{k}^{B}|\), where \(\{|{\phi }_{k}^{A}\rangle \}\) and \(\{|{\phi }_{k}^{B}\rangle \}\) are orthonormal bases of A and B, respectively. Denote by I (J) be subsets of distinct index pairs from \(\{1,\ldots ,d\}\times \{1,\ldots ,d\}\), and by |I| (|J|) the size (number of elements) of I (J). We assume the two probability sequences achieving μl are given by I and J satisfying |I| + |J| = l. That is,
where p and q are the joint distributions given by product measurements \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\) and \({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}\), respectively. From the linearity of the trace function, we have
Thus
That is to say, if \({\hat{\rho }}_{AB}\) achieves μl, then \({\hat{\rho }}_{AB}\) must be a pure product state, otherwise we can find a pure state which gives larger μl by simply choosing the eigenstate of \({\hat{\rho }}_{AB}\) with the largest eigenvalue. To summarize, we reduce the optimization over all separable states required in Eq. (21) to the optimization over all pure product states:
For an arbitrary separable state (be it pure or not) \({\rho }_{AB}\), it then holds that
where the first relation follows from the definition of ωSEP , and the second relation follows from Eqs. (27) and (20). We have the following theorem.
Theorem 3
Let \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\) and \({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}\) be two product observables. For arbitrary separable state \({\rho }_{AB}\in {\cal{D}} ({H}_{A}\otimes {H}_{B})\), it holds that
where \({\omega }^{{{\mathbb{X}}}_{A}\oplus {{\mathbb{Z}}}_{A}}\) is defined in Eq. (11). Similarly, one has
The detection framework
Theorem 3 states that majorization of \(p({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}|{\rho }_{AB})\oplus p({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}|{\rho }_{AB})\) by \({\omega }^{{{\mathbb{X}}}_{A}\oplus {{\mathbb{Z}}}_{A}}\) is a necessary condition for the separability of ρAB and its violation signals the existence of entanglement. This statement provides an operational method of entanglement detection. Given a bipartite state \({\rho }_{AB}\in {\cal{D}} ({H}_{A}\otimes {H}_{B})\), we first calculate the direct-sum probability distribution \(p({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}|{\rho }_{AB})\oplus p({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}|{\rho }_{AB})\) induced by the product measurements \({{\mathbb{X}}}_{A}\otimes {{\mathbb{X}}}_{B}\) and \({{\mathbb{Z}}}_{A}\otimes {{\mathbb{Z}}}_{B}\) by sampling from the source multiple times and gathering statistics. Then we investigate the majorization relation between this quantity and \({\omega }^{{{\mathbb{X}}}_{A}\oplus {{\mathbb{Z}}}_{A}}\). If \({\omega }^{{{\mathbb{X}}}_{A}\oplus {{\mathbb{Z}}}_{A}}\) does not majorize the direct-sum distribution, then we conclude that ρAB is entangled. However, if \({\omega }^{{{\mathbb{X}}}_{A}\oplus {{\mathbb{Z}}}_{A}}\) majorizes the distribution, we can say nothing about ρAB: it can be separable, it can also be entangled.
The proposed method is a collection of detectors. Indeed, Theorem 3 states the following fact. For arbitrary separable state ρAB and arbitrary \(k\in \{1,\,\ldots ,\,2d\}\), it holds that
As the first and the last d inequalities are trivial, we have d − 1 effective inequalities in total, thus d − 1 detectors. Violation of any of these inequalities is sufficient to detect entanglement in a given state.
Example
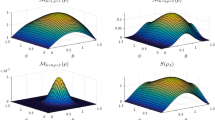
Here we give an example illustrating how to use our proposed method to detect the entanglement of Werner states with Pauli σx and σz observables. First, using the construction method discussed around Eq. (11), we obtain
The Werner family of two-qubit states32 is of the form:
where p ∈ [0, 1], \(|\Phi \rangle =(|00\rangle +|11\rangle )/\sqrt{2}\) and 1 is the identity operator. It is known that ρw(p) is entangled if and only if p > 1/3. If we perform the measurements of the product observables \({\sigma }_{x}\otimes {\sigma }_{x}\) and \({\sigma }_{z}\otimes {\sigma }_{z}\) on a system in state ρw(p), we obtain the same probability distribution by Eq. (12), i.e.,
As so, the direct-sum of these two probability distributions is
According to Theorem 3, ρw(p) violates the separability condition of Eq. (29) if \({\omega }^{{\sigma }_{x}\oplus {\sigma }_{z}}\) fails to majorize the direct-sum quantity in Eq. (35), which occurs when
resulting \(p > 1/\sqrt{2}\). That is to say, our method can detect the entanglement of ρw(p) for \(p > 1/\sqrt{2}\). Obviously, our obtained bound is not tight for the Werner states. However, by optimizing over all possible observables, we can possibly improve the bound for Werner states. Our main point of this example is show that our framework can detect entanglement, say for the Werner states when p is large enough. It remains as an interesting problem to figure out for what states our detection framework has good performance.
Conclusions
In this paper, we have studied the relationship between direct-sum majorization formulation of uncertainty relations and entanglement. We have designed entanglement detection methods based on such a formulation. Our detectors provide a set of sufficient conditions for detecting entanglement whose number grows linearly with the dimension of the state being detected. The proposed entanglement detection methods are of practical importance, as they are experimental friendly and relatively easy to implement.
Several interesting problems remain open. What’s the relation between our entanglement detection method based on direct-sum majorization and that based on tensor-product majorization28? Can we obtain stronger detection method by considering a tomographically complete set of observables? We hope the results presented here can stimulate further investigations on the relations among uncertainty relations, majorization, and entanglement.
References
Heisenberg, W. Uber den anschaulichen inhalt der quantentheoretischen kinematik und mechanik. Z. Phys. 43, 172–198 (1927).
Robertson, H. P. The uncertainty principle. Phys. Rev. 34, 163 (1929).
Białynicki-Birula, I. & Mycielski, J. Uncertainty relations for information entropy in wave mechanics. Commun. Math. Phys. 44, 129–132 (1975).
Deutsch, D. Uncertainty in quantum measurements. Phys. Rev. Lett. 50, 631 (1983).
Maassen, H. & Uffink, J. B. Generalized entropic uncertainty relations. Phys. Rev. Lett. 60, 1103 (1988).
Renes, J. M. & Boileau, J.-C. Conjectured strong complementary information tradeoff. Phys. Rev. Lett. 103, 020402 (2009).
Berta, M., Christandl, M., Colbeck, R., Renes, J. M. & Renner, R. The uncertainty principle in the presence of quantum memory. Nat. Phys. 6, 659–662 (2010).
Tomamichel, M. & Renner, R. Uncertainty relation for smooth entropies. Phys. Rev. Lett. 106, 110506 (2011).
Coles, P. J., Colbeck, R., Yu, L. & Zwolak, M. Uncertainty relations from simple entropic properties. Phys. Rev. Lett. 108, 210405 (2012).
Shannon, C. A mathematical theory of communication. The Bell Syst. Tech. J. 27, 379–423 (1948).
Rényi, A. et al. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics (The Regents of the University of California, 1961).
Coles, P. J., Berta, M., Tomamichel, M. & Wehner, S. Entropic uncertainty relations and their applications. Rev. Mod. Phys. 89, 015002 (2017).
Partovi, M. H. Majorization formulation of uncertainty in quantum mechanics. Phys. Rev. A 84, 052117 (2011).
Friedland, S., Gheorghiu, V. & Gour, G. Universal uncertainty relations. Phys. Rev. Lett. 111, 230401 (2013).
Puchała, Z., Rudnicki, Ł. & Życzkowski, K. Majorization entropic uncertainty relations. J. Phys. A: Math. Theor. 46, 272002 (2013).
Rudnicki, Ł., Puchała, Z. & Życzkowski, K. Strong majorization entropic uncertainty relations. Phys. Rev. A 89, 052115 (2014).
Plenio, M. B. & Virmani, S. An Introduction to Entanglement Measures. arXiv:quant-ph/0504163 ArXiv: quant-ph/0504163 (2005).
Horodecki, R., Horodecki, P., Horodecki, M. & Horodecki, K. Quantum entanglement. Rev. modern physics 81, 865 (2009).
Hayashi, M. Quantum Information Theory: Mathematical Foundation (Springer, 2016).
Bennett, C. H. et al. Teleporting an unknown quantum state via dual classical and einstein-podolsky-rosen channels. Phys. Rev. Lett. 70, 1895 (1993).
Bennett, C. H. & Wiesner, S. J. Communication via one-and two-particle operators on einstein-podolsky-rosen states. Phys. Rev. Lett. 69, 2881 (1992).
Gurvits, L. Classical complexity and quantum entanglement. J. Comput. Syst. Sci. 69, 448–484 (2004).
Gühne, O. & Tóth, G. Entanglement detection. Phys. Reports 474, 1–75 (2009).
Giovannetti, V., Mancini, S., Vitali, D. & Tombesi, P. Characterizing the entanglement of bipartite quantum systems. Phys. Rev. A 67, 022320 (2003).
Hofmann, H. F. & Takeuchi, S. Violation of local uncertainty relations as a signature of entanglement. Phys. Rev. A 68, 032103 (2003).
Giovannetti, V. Separability conditions from entropic uncertainty relations. Phys. Rev. A 70, 012102 (2004).
Gühne, O. Characterizing entanglement via uncertainty relations. Phys. Rev. Lett. 92, 117903 (2004).
Partovi, M. H. Entanglement detection using majorization uncertainty bounds. Phys. Rev. A 86, 022309 (2012).
Cicalese, F. & Vaccaro, U. Supermodularity and subadditivity properties of the entropy on the majorization lattice. IEEE Transactions on Inf. Theory 48, 933–938 (2002).
Gühne, O. & Lewenstein, M. Entropic uncertainty relations and entanglement. Phys. Rev. A 70, 022316 (2004).
Marshall, A., Olkin, I. & Arnold, B. Inequalities: Theory of Majorization and Its Applications. Springer Series in Statistics. (Springer New York, 2010).
Werner, R. F. Quantum states with einstein-podolsky-rosen correlations admitting a hidden-variable model. Phys. Rev. A 40, 4277 (1989).
Acknowledgements
This work is supported by the National Natural Science Foundation of China (61300050), the Chinese National Natural Science Foundation of Innovation Team (61321491), the National Key R&D program of China (2019YFA0308700), the Jiangsu Province Natural Science Foundation, (BK20191249), and the Program B for Outstanding PhD Candidate of Nanjing University.
Author information
Authors and Affiliations
Contributions
K.W. and N.W. contributed equally to this work. N.W. proposed the detection idea, K.W. formalized this idea to make it applicable. All authors participated in writing and reviewing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, K., Wu, N. & Song, F. Entanglement Detection via Direct-Sum Majorization Uncertainty Relations. Sci Rep 10, 452 (2020). https://doi.org/10.1038/s41598-019-57302-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-57302-0
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
