
Abstract
Nepal’s dual burden of undernutrition and over nutrition warrants further exploration of the population level differences in nutritional status. The study aimed to explore, for the first time in Nepal, potential geographic and socioeconomic variation in underweight and overweight and/or obesity prevalence in the country, adjusted for cluster and sample weight. Data came from 14,937 participants, including 6,172 men and 8,765 women, 15 years or older who participated in the 2016 Nepal Demography and Health Survey (NDHS). Single-level and multilevel multi-nominal logistic regression models and Lorenz curves were used to explore the inequalities in weight status. Urban residents had higher odds of being overweight and/or obese (OR: 1.89, 95% CI: 1.62–2.20) and lower odds of being underweight (OR: 0.81, 95% CI: 0.70–0.93) than rural residents. Participants from Provinces 2, and 7 were less likely to be overweight/obese and more likely to be underweight (referent: province-1). Participants from higher wealth quintile households were associated with higher odds of being overweight and/or obese (P-trend < 0.001) and lower odds of being underweight (P-trend < 0.001). Urban females at the highest wealth quintile were more vulnerable to overweight and/or obesity as 49% of them were overweight and/or obese and nearly 39% at the lowest wealth quintile were underweight.
Similar content being viewed by others

Introduction
The prevalence of overweight and obesity has increased dramatically during the past four decades while underweight rates has decreased, posing a major public health challenge both in developing and developed countries. In 2016, the World Health Organization (WHO) estimated more than 1.9 billion adults aged 18 years and older were overweight, and of these over 650 million adults were obese. Globally, the estimated prevalence of overweight increased from 21.5% in 1975 to 39% in 2014, and the prevalence of obesity nearly tripled from 4.7% in 1975 to 13.1% in 20141. Over the same time span, the prevalence of underweight adults fell from about 14% to 9%2,3.
The dual burden of underweight and overweight and/or obesity is an emerging challenge for many low- and middle-income countries (LMICs), including Nepal3,4,5. The United Nations Food and Agriculture Organization estimates that globally 815 million people mostly in low income countries suffer from chronic undernutrition 6. Nepal has a chronic problem of undernutrition, but lately, overweight and/or obesity has emerged as an important public health concern7. Nepal’s population, estimated at 26.5 million as of 2011, is projected to rise to 30.4 million by 20218. This escalating population growth coupled with less impressive economic growth in Nepal raises a grave concern in the context of ensuring safe and sufficient food supply to the growing population and thus the problem of chronic undernutrition may be further aggravated. According to STEPS Survey Nepal 2013, 8.8% of the Nepalese adults aged 15–69 years were underweight9. It was estimated that around half (54%) of the Nepalese population were suffering from chronic food insecurity and the situation is particularly worse in western mountainous regions10.
Sedentary life style and increased access to processed food, especially in urban areas, has resulted in substantial growth in overweight and/or obesity4,5,11. A survey in 2013 estimated that nearly 21% of Nepalese adults aged 15–69 years were overweight and/or obese. The same survey showed geographical discrepancies in prevalence of overweight and/or obesity with higher prevalence among residents of urban areas and hills12.
Previous studies using Nepal Demography and Health Survey (NDHS) 201613,14 showed variation in underweight and overweight and/or obesity by individual level factors, i.e., women compared to men, urban residents compared to rural residents, and wealthy individuals were more likely to be overweight and/or obese. Although individual characteristics play an important role in manifesting health outcomes, including weight status, recent evidence suggest that health is also determined by population level characteristics such as residence, neighborhood’s walkability, availability of food and so on. Previous studies have extensively focused on individual characteristics associated with weight status among Nepalese population13,14 and less is known about the geographic variations in overweight/obesity burden as well as how much of the variation is explained by individual and geographic factors. Furthermore, socioeconomic factors are known to contribute to the geographic variation in other health outcomes15,16 and plausibly may contribute to the geographic variation in underweight and overweight and/or obesity. Yet, there is a paucity of data currently describing these upstream etiologies. If such an association is found, such data could provide insights to policy makers and program implementers to better understand the relationships between socio-economic, geographic, and nutritional variances.
This study aims to address this data gap by analyzing variation in underweight and overweight and/or obesity by indicators of geographic residence and socioeconomic indicators, using the nationally representative data from the NDHS 2016.
Results
Prevalence of underweight and overweight and/or obesity
A total of 14,937 participants (41.3% of men and 58.7% of women) from Nepal’s 77 districts, across seven provinces, were included in the analyses. The prevalence of underweight and overweight and/or obesity was 19.2% and 18.2%, respectively. Based on the Asian cutoff for Body Mass Index (BMI >22.9 kg/m2), the prevalence of overweight and/or obesity was 31.4%. In bivariate analyses (Table 1), participants age, sex, educational level, marital status, and household wealth quintiles and geographic location of their residency were associated with their weight status. A higher proportion of the youngest (15–25 years) and the oldest (55 years and above) participants wereunderweight whereas participants of middle age (25–54 years) were overweight. A higher proportion of females, those with no education or only preschool education, and living in urban areas were underweight (Table 1).
Prevalence of underweight and overweight and/or obesity by wealth quintiles and geography
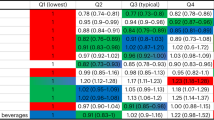
The heat map (Fig. 1, Supplementary Fig. 1) for the prevalence of overweight and/or obesity and underweight by age categories and wealth quintiles suggests that middle-aged adults (35–54 years) in the highest wealth quintile (quintile 5) are more vulnerable to overweight and/or obesity; the prevalence for the age category in the given wealth quintile was greater than 50% based on both global classification of BMI (BMI >24.9 kg/m2) and the classification for Asians (BMI >22.9 kg/m2). The heat map for undernutrition shows that older adults, aged 65 and above, in the lower- and mid-wealth quintiles (quintiles 1, 2, 3) were vulnerable to underweight, where more than one-third of the older adults in the given quintiles were underweight (Fig. 1, Supplementary Fig. 1).

Heat map showing the prevalence of overweight/obeisty (BMI >24.9 kg/m2) and underweight (<18.5 kg/m2) by age groups and household wealth quintiles.
The geospatial analyses in Fig. 2 show the prevalence of overweight and/or obesity and underweight by wealth quintiles. The prevalence of underweight was higher among the residents of Province-2 who belonged to lower wealth quintiles (quintile 1, 2, and 3). Overweight and/or obesity was more prevalent (>40% by global cutoff and >50% by Asian cutoff) among the residents of Province-3, 4, and 6 who belonged to higher wealth quintiles (quintile 4 and 5) (Fig. 2).

Overweight and/or obesity (>24.9 kg/m2), overweight and/or obesity (>22.9 kg/m2) and underweight (<18.5 kg/m2) by wealth status. Socio-economic status (SES) is defined using principal component analysis into quintiles: ‘poorest’ and ‘poor’ is merged as ‘Poor SES’, ‘richer’ and ‘richest’ is merged as ‘Rich SES’ whereas ‘middle’ remained as 'Middle SES'.
The geospatial analyses presented in Fig. 3 shows the prevalence of overweight and/or obesity and underweight by gender and residence. Undernutrition, particularly among females and rural residents, is comparatively higher in Province-2; prevalence ranged between 30–40%. Overweight and/or obesity was higher (≥30%) in Provinces-3 and 4, specifically among females and urban residents (Fig. 3).

Overweight and/or obesity (>24.9 kg/m2), overweight and/or obesity (>22.9 kg/m2) and underweight (<18.5 kg/m2) by sex and residence.
Single-level multinomial regression
In the single-level multinomial analyses (Tables 2 and 3), to assess the association between participants’ weight and their socio-economic characteristics, participant’s socio-economic and locational characteristics were associated with their both overweight and/or obesity and underweight status (Tables 2 and 3). After adjusting for age, sex, education, marital status, wealth quintiles, residency, ecological region, and provinces, compared to participants with no or only preschool education, those with any level of formal education had higher odds of being overweight and/or obese, and lower odds of being underweight (Table 2). Compared to rural residents, urban residents had higher odds of being overweight and/or obese (OR:1.89, 95% CI: 1.62–2.20) or lower odds of being underweight (OR:0.81, 95% CI: 0.70–0.93). Provinces wise, compared to the Province 1, participants from the Province 2, and 7 were less likely to be overweight and/or obese and more likely to be underweight. Ecologically, residents of Terai region had lower odds of being overweight and/or obese (OR: 0.81, 95% CI: 0.67–0.98) or higher odds of being underweight (OR: 1.74, 95% CI: 1.33–2.27) (Table 2).
Participants with higher wealth quintiles were associated with higher odds of being overweight and/or obese and lower odds of being underweight (Table 3).
Multinomial regression
The null model, containing no explanatory variables, i.e., only the outcome and a constant, was used to illustrate the total variance in overweight and/or obesity associated with individual and locational (and district) characteristics. The intercept and the Intra-class Correlation Coefficient (ICC) for provinces and districts were significantly different than zero in all the models, suggesting that the log-odds varied significantly between the provinces and the districts. For the null model, the ICC for level 2 and level 3 was 6.8 and 7.3, respectively. This means that about 15% of the variance in overweight and/or obesity is explained by population differences (6.8% due to the systematic differences between provinces and 7.3% due to districts) and more than 85% of the variance is attributable to individual differences. In the fully adjusted model 4, the ICC reduced to 4.1% intra-provincial correlation and 2.9% intra-district correlation suggesting that only a small variation in overweight and/or obesity was explained by random differences between the provinces and the districts.
The value of Akaike’s information criteria (AIC) and Schwarz Bayesian information criteria (SBIC) were reduced with the addition of covariates across the four models suggesting that the subsequent model improved over the previous model. The model 4 was the best fitting model as suggested by the smallest value of AIC and SBIC compared to the preceding model (Table 4). Compared to the null model, the proportional change in the variance of overweight and/or obesity, due to addition of age, sex, wealth quintiles, education, marital status, and residency in the model 4, was 39.7% across provinces and 60.3% across districts which indicated that 39.7% of the provincial variance and 60.3% of the variance by districts in the empty model was attributable to differences in age, sex, wealth quintiles, education, marital status, and residency.
In the best fitting multilevel model, older ages compared to the youngest (15–25 years), female sex, any level of school education compared to illiterate or with only preschool education, residing in urban areas, and higher wealth quintiles compared to the first quintile was associated with higher odds of being overweight and/or obese. Never married participants were less likely to be overweight and/or obese than those married (OR: 0.34, 95% CI: 0.27–0.42) (Table 4).
In the multilevel analyses for underweight, the intra-provincial correlation and intra-district correlation for underweight was 3.5% and 2.1%, respectively which slightly increased to 4.6% and 3.8%, respectively in the final model (model 4). Thus, only a small variation in underweight was explained by random differences between the provinces and the districts, and the individual differences explained most of the variance. As suggested by the smaller value of AIC and SBIC, model 4 was the best fitting model. Compared to the null model, there was a decrease in the proportion of provincial (31.4%) and district level (81.0%) variance with the addition of individual-level predictors in the final model.
The best fitting multilevel model for underweight suggests that compared to the youngest age group (15–25 years), adults in the middle ages (25–55 years) had lower odds of being underweight but the older adults (>65 years) had higher odds of being underweight (OR:1.85, 95% CI: 1.50–2.29). Compared to illiterate or with only preschool education, participants with any level of school education were less likely to be underweight. Being married appeared to be protective against underweight compared to being unmarried (OR:2.30, 95% CI:1.99–2.67), and previously married (OR:1.20, 95% CI:1.02–1.42) participants were more likely to be underweight than their married counterparts. Urban residents were less likely to be underweight compared to rural (OR:0.87, 95% CI: 0.76–0.99) but the statistical significance was borderline. The financial privilege was protective against underweight, as participants in the higher wealth quintiles had lower odds of being underweight compared to the first quintile (Table 5).
Socio-economic inequalities in weight status: Lorenz curves analyses
Analyses using the Lorenz curves (Fig. 4, Supplementary Fig. 2), used for understanding inequality between richer and poorer and disaggregated by sex and residency, further confirmed the earlier findings in multivariable regression that showed a positive association between weight status and wealth quintiles. The Lorenz curves for the prevalence of underweight (Fig. 4A) shows that underweight status was most heavily concentrated among poor males and females in the urban area and among rich males and females in the rural area. The concentration curve graph shows that, urban female at the bottom 20% were more vulnerable as nearly 39% were underweight and at the top 20% nearly 19% were underweight (Fig. 4A).

Lorenz curves showing the gradient in overweight and/or obesity (>24.9 kg/m2) and underweight (<18.5 kg/m2).
Overweight and/or obesity prevalence was concentrated among the rich as shown by all the curves below the line of equality. Particularly, urban females at the highest wealth quintile were more vulnerable as 49% were overweight and/or obese (Fig. 4B). This is not very different from the overweight and/or obesity gradient based on Asian BMI cut off (Supplementary Fig. 2).
Discussion
Summary of evidence
This study reports the prevalence of underweight and overweight and/or obesity, estimated by measures of height and weight, in a nationally representative sample of Nepalese adults. The findings of this study provide evidence of the dual burden of underweight and overweight and/or obesity, demonstrating that this is an urgent priority for the health of Nepal. Our study demonstrates that the prevalence of overweight and/or obesity was higher in younger adults and undernutrition was higher among the older adults. Based on wealth indicators, individuals from richer households were least likely to be underweight and more likely to overweight and/or obese. The multilevel analyses suggest that only a small variation in overweight and/or obesity and underweight can be explained by random differences between the provinces and the districts, and the individual differences explained most of the variance.
Comparison to existing studies
Though the prevalence and factors affecting underweight and overweight and/or obesity from NDHS 2016 were reported in earlier studies13,14, none of these studies examined the geographical and socio-economic variation of weight status with a detailed spatial mapping of BMI status. And, both studies have some methodological limitations. For example, Al Kibria13 used the same weight for the underweight vs normal weight comparison, and overweight and/or obesity vs normal weight comparisons, though they were analysed separately using multivariable logistic regression analysis. Though, a detailed account of modeling process was lacking in these studies13,14. These shortcomings have been addressed in our study. We used a hierarchical multi-nominal regression analysis design where normal weight used as referent category and compared against underweight and overweight and/or obesity under the same model. Further, we used the multilevel analysis to examine the population level differences in BMI status, and Lorenz curves to study socio-economic inequalities in BMI status. Both multi-nominal and multilevel analysis explored the same set of predictor variables and the findings have high congruence between two modeling approaches. Multilevel analysis is accounted for the presence of data hierarchies and the random residual components at each level in the study17. It is superior to the traditional logistic regression modeling17, however, we did not aim to compare the results between single level and multi-level analysis. Our study focuses on describing the drivers of nutritional transition, and their policy implications than the effect sizes of estimates.
Dual burden of underweight and overweight and/or obesity
A notable proportion of participants were found to be underweight. The finding was not surprising given that historically undernutrition has been a significant public health problem in Nepal18. Underweight status appeared to be a major concern among the older adults in our study which is in line with previous evidence that the nutritional well-being of older adults is particularly neglected in Nepal19,20.
On the other hand, recently overweight and/or obesity has emerged as a notable public health concern. It is particularly of concern among young adults, given that being obese increases the vulnerability to sequelae of cardio-metabolic diseases. The national STEPS survey on non-communicable diseases risk factors, conducted in 2013, also provides evidence that Nepalese adults are becoming overweight and/or obese (obesity: 21%)9. Two aspects of Nepalese society, the traditional norms of being obese and rapid urbanization, may be attributed to the rise in obesity. Being overweight is culturally desirable in Nepalese society and is even used as a proxy of family’s ability to afford food as well as a measure of their relative wealth status21. This traditional phenomenon has been further complicated by the rapid urbanization which has increased the accessibility and affordability of energy-rich, sugary commercialized foods, and simultaneously, a more sedentary lifestyle22,23,24.
Socio economic status (SES) and nutritional status
The relationship between weight status and SES was expected, yet interesting. We found a high prevalence of overweight and/or obesity among wealthier individuals, measured in terms of wealth index, and a high prevalence of underweight among poorer individuals. This is not unexpected, and consistent with other data from Nepal and globally15,25. The poorest quintile were two times more likely to be underweight than the richest quintile, whereas the richest quintile were 7.2 times more likely to be overweight and/or obese than the poorest quintile. However, the disparity in underweight across socio-economic groups is much more evident within urban areas compared to rural areas although there was no statistically significant association of residence with underweight. This large disparity between rich and poor subgroups in Nepal might be associated with ongoing rapid urbanization that will further widen income and social inequities. These findings corroborate to those reported by previous studies conducted in other LMICs5,15,26.
A higher burden of underweight status among the lower socio economic group in urban regions could be attributable to rapid growth of cities along with growth of urban poor27. Globally, South Asia has the largest proportion of the population living in slums and is urbanizing at the fastest rate28. The people living in these slums are often beyond the remit of public services and are forced to endure disparities in essential health services and health and nutrition indicators29. Policymakers cannot ignore the sheer scale and uncontrollable urban growth and as more and more of the populations in LMICs become urbanized, so the need for special attention for this population subgroup is growing30. In addition, the urbanization also incites inflation which makes consumption of fruits and vegetables expensive and increasingly difficult for urban poor. Thus the consumption of unhealthy foods along with the transition to sedentary occupations from subsistence agriculture might be the reasons behind the shift in the burden of obesity to lower-SES groups in LMICs31. With rapid urbanization, the urban poor subgroup in Nepal is also at risk for double burden of undernutrition and overweight and/or obesity.
Geographic drivers
In the geospatial analyses, underweight status was more prevalent among the residents of Province 2, Province 6 and Province 7 whereas overweight and/or obesity was more prevalent among the residents of Province 3 and 4. Overweight and/or obesity is more prevalent in provinces and districts with higher affluence and underweight in less affluent provinces. For example, Province 1 and 3, with human development index (HDI) of 0.507 and 0.506, are the most developed provinces in terms of HDI as well as other indicators of economic growth, followed by Province 4 (HDI: 0.493). At the lower end, Province 6 (HDI: 0.39), Province 7 (HDI: 0.416), and Province 2 (HDI: 0.422) have the lowest HDI, with the majority of the population residing in the village and semi-urban area and engaged in agrarian activities as a primary source of income. When comparing the districts, the top three districts in terms of HDI are from Province-3: Kathmandu (HDI: 0.632), Lalitpur (0.601), Kaski (0.576), and the bottom three are from Province 7: Bajura (0.364), Bajhang (0.365), and Kalikot (0.374)32. At the individual level—underweight showed a negative trend in dose-response manner with household SES and overweight showed a positive trend. Low SES groups from low HDI districts and high SES groups from high HDI districts are particularly vulnerable to poor nutritional status and needs vigilant attention. In line with our findings, geographic disparitities in overweight and/or obeseity has been reported in previous studies from Nigeria and neighbouring India where overweight and/or obesity was more prevalent in Southern India 33 and south-eastern Nigeria34 compared to other regions of these countries.
Nepal is in a transitional phase and has recently transformed into a federal setup with seven administrative provinces. The several decades of political instability and ten years of armed conflict that ended in 2006, plunged Nepal into poverty. The situation is particularly grave for the Province 2, Province 6 and Province 7 with approximately half of their population being poor35. Though Province 2, the plains of Nepal has been the major region for crop production, food insecurity in this province is on the rise due to annual floods, crop failures and feudalistic distribution of land in agriculture. The difficult terrain in Province 6 and Province 7, along with poor crop harvest and poor income from agriculture and livestock has been the major reasons behind highest poverty incidence in these provinces. Other reasons are out-migration of youth into Persian Gulf countries and in-migration of richer households from rural to urban areas leaving the poorer behind as they are less likely to migrate because of lack of affordability36. Along with that, these provinces were the worst affected region during armed conflict. This is also reflected in higher underweight prevalence in these provinces and remains a challenge for Nepal.
Strengths and limitations
Our study adds to the growing literature surrounding nutritional status in Nepal. To date, nationally representative data are limited in Nepal, and the prevalence, estimated in the earlier studies, are based on small sample sizes and among a homogenized population in a limited geography. This study is based on a large nationally representative sample consisting of both urban and rural populations in Nepal. This is the first study exploring the socio-economic and geographical disparities in the prevalence of underweight and overweight and/or obesity in the Nepalese context. Further, we defined overweight and/or obesity based on two different criteria, the global criteria and the criteria recommended for Asians. Our geospatial analyses may be helpful to the new provincial governments, especially in the context of recent federalization of the country, to design the targeted interventions based on local needs.
Our study also has several limitations. This study is cross-sectional in nature, and thus limits any causal inferences. Likewise, BMI and SES were measured only at one point, but such measurements are likely to change over time. Given the methods of our data sample, we were unable to assess the impact of such changes at different stages of the life course. Additionally, the lack of information regarding dietary habits, alcohol intake, or physical activity in the NDHS database hindered our ability to scrutinize some important determinants of nutritional status and the possibility of residual confounding cannot be ruled out. The geospatial mapping was entirely limited to data-visualization, and further studies needs to be carried out to identify the area-level hotspots of endemic underweight and overweight and/or obesity in Nepal. Despite the limitations, our study provides new insights into socio-economic and geographic determinants of weight status in Nepal.
Conclusion
This study reaffirmed the earlier evidence that the dual burden of underweight and overweight and/or obesity is a significant public health problem in Nepal. The BMI status varied by indicators of socio-economic well-being which further confirms the role of the household’s economic well-being in the current epidemiological transition. Overweight and/or obesity among the younger adults and undernutrition among the elderly should receive special attention.
Methods
Data sources
This study is based on a secondary analysis of the 2016 NDHS, a cross-sectional and nationally representative data. The 2016 NDHS uses multi-stage (two stages in rural areas and three stages in urban areas) stratified cluster sampling technique. A total of 383 primary sampling units (PSU) or clusters were selected nationally, and 30 households were selected from each of these PSU with an equal probability proportion to size criterion yielding a final sample size of 11,040 households. From these households, 14,937 individuals, including 6,172 males and 8,765 females, provided height and weight measurements. Data includes individuals from all the 77 districts in the country, across all seven provinces. The full report on the 2016 NDHS study design and sampling technique is available elsewhere37,38. Ethical approval for 2016 NDHS was obtained from Nepal Health Research (NHRC) – Ethical Review Board and ICF Institutional Review Board.
Anthropometry measurements
The trained field research staffs measured the height and weight of the participants. BMI was calculated as weight in kilograms divided by the square of the height in meters (kg/m2). We followed two standard classifications of BMI. First, we used the global standard to categories BMI as underweight (<18.5 kg/m2), normal (18.5–24.9 kg/m2), overweight (25–29.9 kg/m2), and obese (>30 kg/m2); the latter two categories were combined to form a single category overweight and/or obese (≥25 kg/m2)39. Further, to provide a comparative context in the figures (heat map, geospatial maps, and Lorenz curves), we also calculated and presented the prevalence of overweight and/or obese (≥23 kg/m2) following the recommendation by WHO’s expert consultation on BMI classifications for Asians40.
Explanatory variables
The explanatory variables that were selected for analysis can be grouped into socio-demographic, and geographic variables. We considered age of the participants, sex, educational status and wealth index under socio-demographic variables. Educational status was grouped into four categories: no formal schooling, primary schooling, secondary schooling and those with higher education (includes high school, college/university, postgraduate and above). The principal component analysis was used to determine wealth index which included information on number and kinds of consumer goods such as bicycle or car owned by household and housing characteristics (such as the source of drinking water, availability of toilet facilities41. Place of residence (rural/urban), Province and Ecological zone (Mountain/Hill/Terai) were included under geographic variables. The province was categorized into seven administrative divisions, according to the current administrative structure of Nepal, and compared against Province-1. Province 1 was chosen a reference category as it is most advantaged in political and economic means Nepal42. Wealth quintiles were computed by dividing the distribution into five equal categories, each comprising 20% of the population.
Data analysis
Multivariable analysis
Analyses were adjusted for cluster and sample weight to ensure representativeness of provinces and to the urban and rural areas. Rao-Scott chi-square tests were used to assess the association between weight status and the explanatory variables in the bivariate analyses. Univariate multinomial logistic regression was performed to assess the association of weight status with various socio-demographic factors, as listed in Table 1, with normal weight as the reference category. We built three hierarchical models under multinomial analyses. Model 1 was adjusted for age and sex; model 2 was adjusted for variables from the model 1 plus education (E), marital status (M), wealth quintiles (SES), and residency (R). Model 3 was adjusted by adding ecological region (Ec) and provinces (P) to the model 2. Model 4 contained all the variables from the model 3 excluding the wealth quintiles. The fully adjusted model is summarized as:
BMIij = j, if alternative j is selected. Where BMI is a categorical outcome variable with possible values from i to j43.
Trend tests were performed for wealth quintiles and education (both used as an ordinal variable in the models) to evaluate the linear trends. The multinomial analysis accounting for complex survey design of NDHS 2016 was conducted based on earlier established procedure in SAS 9.444.
Multilevel analysis
The hierarchical nature of NDHS data allowed us to perform a hierarchical generalized linear modeling using PROC GLIMMIX procedure in SAS 9.445. Such dataset is ideal for exploring socio-economic and geographic differences in BMI status at individual and population level. We performed three-level analyses with individuals at level 1 (a), districts at level 2 (b), and provinces at level 3 (c), using the same set of predictor variable used in multivariable analysis. In the multi-level analyses, the model 1 is an empty model. The detailed model building process for three-level multilevel analysis is described by Kim et al.46 using BMI as a continuous outcome variable, and is adapted for categorical BMI as a categorical variable. The study found that the residuals are independently and identically distributed at the individual, and population level in NDHS 201646. We further tested the model fit and influence statistics for the hierarchical data (Supplementary Material 1).
In the equation above, B0 is the average BMI across all the provinces and the bracketed terms are the random effect terms association with individual, districts and provinces.V0C, u0bc, e0abc are the residual associated at the province, district and individual level respectively.
The model 2 was adjusted for age and sex.
The model 3 was adjusted for model 2 variables plus wealth quintiles.
The model 4 contained the model 3 variables plus education, marital status, and residency.
The intraclass correlation coefficient (ICC) (a measure of the amount of variation in outcome due to a given level) is calculated using the formula below where \({\tau }_{00}\) is the covariance parameter estimate.
The proportional change in variance (a measure of change in the area level variance between the empty model and a given successive model) was calculated based on the earlier established procedure in SAS v9.445.
The value of AIC and SBIC were used as model fit statistics.
Geographic analysis and Lorenz curves
The geospatial analyses of provinces of Nepal were performed in SAS v9.4 using GMAP procedure47. The Lorenz curve assessed the socio-economic inequality in underweight and overweight and/or obesity among rural and urban residents. This curve has been used to assess the inequality gradient related to socio-economic status (SES) in various health indicators48,49,50. We plotted the cumulative percentage of the sample, ranked by SES on X-axis and the corresponding cumulative percentage of weight status, by sex and urban-rural residence, was plotted on the Y-axis. A curve above the line of equality indicates a greater concentration of the outcome among the poor and a curve below the line indicates a greater concentration of outcome among the rich.
Ethical approval and consent to participate
The 2016 Nepal Demographic and Health Survey protocol received ethical approval by the Nepal Health Research (NHRC) – Ethical Review Board and ICF Institutional Review Board. The survey was conducted in accordance with relevant guidelines/regulations. An informed written consent was obtained from all the participants.
References
World Health Organization (WHO). Obesity and overweight. Fact sheet. Available online: http://www.who.int/mediacentre/factsheets/fs311/en/ (2017).
NCD Risk Factor Collaboration. Trends in adult body-mass index in 200 countries from 1975 to 2014: a pooled analysis of 1698 population-based measurement studies with 19·2 million participant. The Lancet 387, 1377–1396 (2016).
Akhtar, S. Malnutrition in South Asia: A Critical Reappraisal. Crit Rev Food Sci Nutr 56, 2320–2330, https://doi.org/10.1080/10408398.2013.832143 (2016).
Bishwajit, G. Nutrition transition in South Asia: the emergence of non-communicable chronic diseases. F1000Res 4, 8, https://doi.org/10.12688/f1000research.5732.2 (2015).
Popkin, B. M., Adair, L. S. & Ng, S. W. Global nutrition transition and the pandemic of obesity in developing countries. Nutr Rev 70, 3–21, https://doi.org/10.1111/j.1753-4887.2011.00456.x (2012).
FAO, IFAD, UNICEF, WFP & WHO. The State of Food Security and Nutrition in the World 2017. Building resilience for peace and food security. (2017).
United States Agency International Development (USAID). Nepal: Nutrition profile, Available online: https://www.usaid.gov/sites/default/files/documents/1864/Nepal-Nutrition-Profile-Mar2018-508.pdf (2018).
Government of Nepal. National Planning Commission: Central Bereau of Stastistics. Population projection 2011–2031. Available online: https://cbs.gov.np/wp-content/upLoads/2018/12/PopulationProjection2011-2031.pdf (2014).
Non communicable diseases risk factors: STEPS survey Nepal. Available online: http://www.searo.who.int/nepal/mediacentre/non_communicable_diseases_risk_factors_steps_survey_nepal_2013.pdf (2013).
Government of Nepal. Central Bureau of Statistics. Food and agriculture organization of United Nations. Food and nutrition security in Nepal: A status report. Available online: http://moad.gov.np/public/uploads/201721855-final%20Food%20NS%202015.pdf (2016).
Doak, C. M., Adair, L. S., Bentley, M., Monteiro, C. & Popkin, B. M. The dual burden household and the nutrition transition paradox. Int J Obes (Lond) 29, 129–136, https://doi.org/10.1038/sj.ijo.0802824 (2005).
Aryal, K. K. et al. The Burden and Determinants of Non Communicable Diseases Risk Factors in Nepal: Findings from a Nationwide STEPS Survey. PLoS One 10, e0134834, https://doi.org/10.1371/journal.pone.0134834 (2015).
Al Kibria, G. M. Prevalence and factors affecting underweight, overweight and obesity using Asian and World Health Organization cutoffs among adults in Nepal: Analysis of the Demographic and Health Survey 2016. Obes Res Clin Pract, https://doi.org/10.1016/j.orcp.2019.01.006 (2019).
Rawal, L. B. et al. Prevalence of underweight, overweight and obesity and their associated risk factors in Nepalese adults: Data from a Nationwide Survey, 2016. PLoS One 13, e0205912, https://doi.org/10.1371/journal.pone.0205912 (2018).
Biswas, T., Garnett, S. P., Pervin, S. & Rawal, L. B. The prevalence of underweight, overweight and obesity in Bangladeshi adults: Data from a national survey. PLoS One 12, e0177395, https://doi.org/10.1371/journal.pone.0177395 (2017).
Mishra, S. R., Ghimire, S., Shrestha, N., Shrestha, A. & Virani, S. S. Socio-economic inequalities in hypertension burden and cascade of services: nationwide cross-sectional study in Nepal. J Hum Hypertens. https://doi.org/10.1038/s41371-019-0165-3 (2019).
University of Bristol. What are multilevel models and why should I use them? Available online: http://www.bristol.ac.uk/cmm/learning/multilevel-models/what-why.html (2017).
Government of Nepal. Status of food and nutrition security in Nepal. Available online: http://moad.gov.np/public/uploads/1749913226-St%20Rep_%20Food%20and%20Nutrition%20Secu.pdf (2018).
Ghimire, S., Baral, B. K. & Callahan, K. Nutritional assessment of community-dwelling older adults in rural Nepal. PLoS One 12, e0172052, https://doi.org/10.1371/journal.pone.0172052 (2017).
Ghimire, S. et al. Depression, malnutrition, and health-related quality of life among Nepali older patients. BMC Geriatr 18, 191, https://doi.org/10.1186/s12877-018-0881-5 (2018).
Simkhada, P., Poobalan, A., Simkhada, P. P., Amalraj, R. & Aucott, L. Knowledge, attitude, and prevalence of overweight and obesity among civil servants in Nepal. Asia Pac J Public Health 23, 507–517, https://doi.org/10.1177/1010539509348662 (2011).
Mishra, S. R., Kallestrup, P. & Neupane, D. Country in Focus: confronting the challenge of NCDs in Nepal. Lancet Diabetes Endocrinol 4, 979–980, https://doi.org/10.1016/S2213-8587(16)30331-X (2016).
Vaidya, A., Shakya, S. & Krettek, A. Obesity prevalence in Nepal: public health challenges in a low-income nation during an alarming worldwide trend. Int J Environ Res Public Health 7, 2726–2744, https://doi.org/10.3390/ijerph7062726 (2010).
Zeljko Pedisic, Nipun Shrestha, Paul D. Loprinzi, Suresh Mehata, Shiva Raj Mishra, (2019) Prevalence, patterns, and correlates of physical activity in Nepal: findings from a nationally representative study using the Global Physical Activity Questionnaire (GPAQ). BMC Public Health 19 (1).
Jayawardena, R., Byrne, N. M., Soares, M. J., Katulanda, P. & Hills, A. P. Prevalence, trends and associated socio-economic factors of obesity in South Asia. Obes Facts 6, 405–414, https://doi.org/10.1159/000355598 (2013).
Biswas, T., Islam, M. S., Linton, N. & Rawal, L. B. Socio-Economic Inequality of Chronic Non-Communicable Diseases in Bangladesh. PLoS One 11, e0167140, https://doi.org/10.1371/journal.pone.0167140 (2016).
Hong, S. A., Peltzer, K., Lwin, K. T. & Aung, S. The prevalence of underweight, overweight and obesity and their related socio-demographic and lifestyle factors among adult women in Myanmar, 2015–16. PLoS One 13, e0194454, https://doi.org/10.1371/journal.pone.0194454 (2018).
Ellis, P. & Mark, R. Leveraging Urbanization in South Asia: Managing Spatial Transformation for Prosperity and Livability. South Asia Development Matters. Washington, DC: World Bank (2016).
Adams, A. M., Nambiar, D., Siddiqi, S., Alam, B. B. & Reddy, S. Advancing universal health coverage in South Asian cities: a framework. BMJ 363, k4905, https://doi.org/10.1136/bmj.k4905 (2018).
Elsey, H. et al. Improving household surveys and use of data to address health inequities in three Asian cities: protocol for the Surveys for Urban Equity (SUE) mixed methods and feasibility study. BMJ Open 8, e024182, https://doi.org/10.1136/bmjopen-2018-024182 (2018).
Ford, N. D., Patel, S. A. & Narayan, K. M. Obesity in Low- and Middle-Income Countries: Burden, Drivers, and Emerging Challenges. Annu Rev Public Health 38, 145–164, https://doi.org/10.1146/annurev-publhealth-031816-044604 (2017).
Government of Nepal. National planning commission. Nepal human development report 2014. Available online: https://www.npc.gov.np/human_development_indicators_by_district/ (2014).
Siddiqui, S. T., Kandala, N. B. & Stranges, S. Urbanisation and geographic variation of overweight and obesity in India: a cross-sectional analysis of the Indian Demographic Health Survey 2005–2006. Int J Public Health 60, 717–726, https://doi.org/10.1007/s00038-015-0720-9 (2015).
Kandala, N. B. & Stranges, S. Geographic variation of overweight and obesity among women in Nigeria: a case for nutritional transition in sub-Saharan Africa. PLoS One 9, e101103, https://doi.org/10.1371/journal.pone.0101103 (2014).
Government of Nepal. National Planning Commission. Oxford Poverty and Human Development Initiative, University of Oxford. Nepal’s multidimensional poverty index (2018).
Gurung, Y. B. Migration from Rural Nepal. A Social Exclusion Framework. available online: https://www.cmi.no/file/?638 (2008).
Ministry of Health and population, New ERA, ICF. Nepal Demographic and Health Survey 2016. Kathmandu, Nepal: Ministry of Health, Nepal. Available online, https://www.dhsprogram.com/pubs/pdf/fr336/fr336.pdf (2016).
Mehata, S. et al. Prevalence, awareness, treatment and control of hypertension in Nepal: data from nationally representative population-based cross-sectional study. J Hypertens 36, 1680–1688, https://doi.org/10.1097/HJH.0000000000001745 (2018).
World Health Organization (WHO). Physical status: the use and interpretation of anthropometry. Report of a WHO Expert Committee. WHO Technical Report Series 854. Geneva: World Health Organization (1995).
World Health Organization (WHO). World Health Organization Expert Consultation. Appropriate body-mass index for Asian populations and its implications for policy and intervention strategies. Lancet (London, England) 363, 157 (2004).
Vyas, S. & Kumaranayake, L. Constructing socio-economic status indices: how to use principal components analysis. Health Policy Plan 21, 459–468, https://doi.org/10.1093/heapol/czl029 (2006).
Asian Development Bank (ADB). Country Poverty Analysis (Detailed) Nepal. Available online: https://www.adb.org/sites/default/files/linked-documents/cps-nep-2013-2017-pa-detailed.pdf (2017).
Gill. Multinomial logit regression: Probability of going to college given intelligence, siblings, parent’s education and IQ. Available online: https://masterofeconomics.org/2010/08/20/multinomial-probit-regression-probability-of-going-to-college-given-intelligence-siblings-parents-education-and-iq/ (2010).
Flom, P. L. Multinomial and ordinal logistic regression using PROC LOGISTIC. Available online: https://www.lexjansen.com/nesug/nesug05/an/an2.pdf (2010).
Ene, M., Leighton, E. A., Blue, G. L. & A., B. B. Multilevel Models for Categorical Data Using SAS PROC GLIMMIX: The Basics. Available online: https://support.sas.com/resources/papers/proceedings15/3430-2015.pdf. In SAS Global Forum 2015 Proceedings (2015).
Kim, R., Kawachi, I., Coull, B. A. & Subramanian, S. V. Contribution of socioeconomic factors to the variation in body-mass index in 58 low-income and middle-income countries: an econometric analysis of multilevel data. The Lancet Global Health 6, e777–e786, https://doi.org/10.1016/S2214-109X(18)30232-8 (2018).
Zdeb, M. The Basics of Map Creation with SAS/GRAPH. Available online: https://www.lexjansen.com/nesug/nesug09/ff/FF02.pdf. In Paper 251–29, SUGI 29 (2004).
Kakwani, N., Wagstaff, A. & van Doorslaer, E. Socioeconomic inequalities in health: Measurement, computation, and statistical inference. Journal of Econometrics 77, 87–103, https://doi.org/10.1016/S0304-4076(96)01807-6 (1997).
O’Donnell, O. A. & Wagstaff, A. Analyzing health equity using household survey data: a guide to techniques and their implementation. World Bank Publications (2008).
Wagstaff, A. & Van Doorslaer, E. Measuring inequalities in health in the presence of multiple-category morbidity indicators. Health Economics 3, 281–291, https://doi.org/10.1002/hec.4730030409 (1994).
Author information
Authors and Affiliations
Contributions
N.S. and S.R.M. conceived the idea for the study. N.S. and S.R.M. conceptualised the study. S.R.M., S.G. and N.S. conducted statistical analyses. N.S., S.R.M., S.G., B.G., P.M.S.P. and D.S. contributed to writing the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shrestha, N., Mishra, S.R., Ghimire, S. et al. Application of single-level and multi-level modeling approach to examine geographic and socioeconomic variation in underweight, overweight and obesity in Nepal: findings from NDHS 2016. Sci Rep 10, 2406 (2020). https://doi.org/10.1038/s41598-019-56318-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-56318-w
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
