
Abstract
Identifying influential spreaders in complex networks is crucial in understanding, controlling and accelerating spreading processes for diseases, information, innovations, behaviors, and so on. Inspired by the gravity law, we propose a gravity model that utilizes both neighborhood information and path information to measure a node’s importance in spreading dynamics. In order to reduce the accumulated errors caused by interactions at distance and to lower the computational complexity, a local version of the gravity model is further proposed by introducing a truncation radius. Empirical analyses of the Susceptible-Infected-Recovered (SIR) spreading dynamics on fourteen real networks show that the gravity model and the local gravity model perform very competitively in comparison with well-known state-of-the-art methods. For the local gravity model, the empirical results suggest an approximately linear relation between the optimal truncation radius and the average distance of the network.
Similar content being viewed by others

Introduction
Network science is playing an increasingly significant role in many domains including physics, sociology, engineering, biology, management, and so on1. The heterogeneous nature of real networks2 asks for a crucial question: How to quantitatively measure a node’s importance in a dynamical process? Taking spreading dynamics as an example, a popular star in Twitter may remarkably accelerate a rumor and a few superspreaders could largely expand the epidemic prevalence of a disease3. Therefore, a good answer to the above question, namely an efficient algorithm to identify influential spreaders in complex networks, can help to better control the outbreak of an epidemic4, optimize the use of limited resources to facilitate the dissemination of information5, prevent catastrophic disruptions of power grid or the Internet6, discover the candidates of drug target and essential proteins7, and so on. Till far, most known methods only make use of the structural information8, which can be roughly classified into neighborhood-based centralities and path-based centralities.
Typical representatives of the neighborhood-based centralities are degree centrality9 (DC), H-index10 and k-shell decomposition method11 (KS). For DC, nodes with larger degrees are more influential. For H-index, nodes connecting with many large-degree neighbors are more influential. KS assigns a k-shell index to each node based on its topological location, where nodes closer to the core of the network will get higher k-shell indices, and nodes in the periphery will get lower k-shell indices. The nodes with higher k-shell indices are considered to be more influential. Besides, PageRank12 and LeaderRank13 are two representative neighborhood-based iterative methods, both suggesting that the influence of a node is determined by the influences of its neighbors. Two well-studied path-based centralities are closeness centrality14 (CC) and betweenness centrality15 (BC). CC claims that a node averagely closer to other nodes is more influential while BC assumes that a node locating in many shortest paths is of high influence.
Inspired by the gravity law, recently, Ma et al.16 proposed two gravity-law-based algorithms by considering both neighborhood information and path information (see Methods for the details of algorithms). Analogously, we proposed a variant algorithm named gravity model (GM), which also takes into account both neighborhood information and path information, where a node with larger degrees (neighborhood information) and averagely shorter distances to other nodes (path information) is more influential. Furthermore, we propose a local version of the gravity model (named as local gravity model, LGM for short) to lower the computational complexity and reduce the possible noise caused by interactions at distance. Such local model only accounts for pairwise interactions within a truncation radius. Empirical results show that GM and LGM perform very competitively in comparison with well-known state-of-the-art methods. In particular, for LGM, an empirically linear relation between the optimal truncation radius and the average distance of the network is observed.
Results
Algorithms
Individually speaking, nodes with large degrees are likely to be more influential. In addition, a node is of higher impacts on nearby nodes17. According to the above issues and inspired by the gravity law, we regard the degree of a node as its mass, and the shortest distance between two nodes as their distance. Hence a node i’s influence can be estimated as
where ki is the degree of node i, dij is the shortest distance between node i and node j, and j runs over all nodes other than i. Obviously, a node with many neighbors and be close to most nodes is more influential according to Eq. 1. Such method is named as gravity model as it adopts the formula of the gravity law.
Although GM can identify the nodes averagely closer to other nodes and with larger degrees, it has two shortcomings. Firstly, to calculate shortest distances between all node pairs is time-consuming for large-scale networks18. Secondly, in real propagation a node is hard to impact other nodes at distance and to estimate the interacting strength between distant nodes is usually inaccurate since the step-by-step decaying influence will be disturbed by accumulated noise19. Therefore, by introducing a truncation radius, we only consider the pairwise interactions within the truncation radius. Hence a node i’s influence can be estimated as
where R is the truncation radius. Such method (Eq. 2) is named as local gravity model as it only takes into account local information of the network.
Data description
In this paper, fourteen real networks from disparate fields are used to test the performance of GM and LGM, including three collaboration networks (Jazz, NS and GrQc), four communication networks (EEC, Email, PG and Enron), four social networks (PB, Facebook, WV and Sex), one transportation network (USAir), one infrastructure network (Power) and one technological network (Router). Jazz20 is a collaboration network of jazz musicians. NS21 is a co-authorship network of scientists working on network science. GrQc22 is a collaboration network of eprint articles in arXiv categories General Relativity and Quantum Cosmology. EEC23 describes email interchanges between institution members of a large European research institution. Email24 describes email interchanges between users including faculty, researchers, technicians, managers, administrators, and graduate students of the Rovira i Virgili University. PG22 is a snapshot of the Gnutella peer-to-peer file sharing network from August 2002. Enron25 is the Enron email network. PB26 is a network of US political blogs. Facebook27 describes social circles from Facebook. WV28 is a network of Wikipedia who-votes-on-whom. Sex29 is a bipartite network in which nodes are females (sex sellers) and males (sex buyers) and links between them are established when males write posts indicating sexual encounters with females. USAir30 is the US air transportation network. Power31 is the power grid of the western United States. Router32 is a symmetrized snapshot of the structure of the Internet at the level of autonomous systems. These networks’ topological features (including the number of nodes, the number of links, the average degree, the average distance, the clustering coefficient31, the assortative coefficient33, the degree heterogeneity34 and the epidemic threshold35 of the SIR model36) are shown in Table 1.
Empirical results
We apply the well-known SIR model36 to compare the rankings of influences produced by algorithms and simulations. Initially, one node (called seed) in the network is in the infected state (I) and the others are in the susceptible state (S). Each of the infected nodes can infect its susceptible neighbors with probability β. And in each step, every infected node changes to be recovered and will never participate in the dynamics with probability λ. The spreading process repeats until there are no more infected nodes in the network. The influence of any node i can be estimated by
where Nr is the number of recovered nodes at the end of the dynamics. For simplicity, we set λ = 1, and the corresponding epidemic threshold34 is
where 〈k〉 and 〈k2〉 denote the average degree and the second-order moment of the degree distribution.
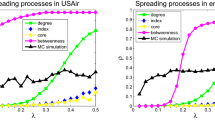
Given a network and the transmission probability β, to obtain the standard ranking of nodes’ influences, we implement 1000 independent runs, in each run every node is selected once as the seed once. The accuracy of an algorithm is measured by the Kendall’s Tau (τ)37 between the standard ranking and the ranking by the algorithm (see details in Methods). A larger value of τ means a stronger correlation between the two sequences and thus a better performance. Table 2 compares the accuracies of the two proposed algorithms (i.e., GM and LGM) and seven benchmark algorithms (see details about the benchmark algorithms in Methods). The transmission probability for each case is fixed as β = βc (for more values of β, see Fig. 1) and the parameters in relevant algorithms are all adjusted to their optimal values subject to the largest τ.

The algorithms’ accuracies for different β, measured by the Kendall’s Tau (τ).
As shown in Table 2, both GM and LGM are very competitive. In particular, G+ and LGM perform best among the nine algorithms. Notice that, G+ also adopts the gravity formula16 (see Methods) but a node’s mass in G+ is defined as its k-shell index so G+ is indeed a global index. The results reported in Table 2 demonstrate the advantage of gravity models (e.g., G, G+, GM, LGM) and show that a local index (LGM) can outperform most benchmark algorithms including some global indices. As shown in Fig. 1, results for other values of β not too far from the threshold are consistent to the one at βc, suggesting the robustness of our findings.
Since to determine the optimal truncation radius, denoted by R*, asks for more computation, we want to see whether topological information can be used to profile R*. As shown in Fig. 2, R* approximately scales linearly with the average distance, as
at β = βc. Such approximately linear relation also holds for other values of β not so far from βc. This empirical relation can save computational cost in practice.

The relation between R* and 〈d〉 for β = βc. Fourteen pentagrams represent fourteen networks and the slope of the blue line is 1/2. The pentagram in black is the outlier – the Enron network. Although the optimal truncation radius R* = 7 is much different from what Eq. 5 predicts (i.e., R = 2), the algorithmic accuracy at R = 2 (τ = 0.4949) is very close to the best accuracy at R* = 7 (τ = 0.5075) in comparison with the traditional methods (e.g., about 0.34 for BC, 0.42 for CC and 0.46 for DC, KS and H-index). That is to say, to apply Eq. 5 can still achieve much better algorithmic performance than the traditional methods.
Discussion
To measure influences of nodes in a certain networked dynamics, a straightforward method is to estimate the interacting strengths between node pairs in advance. The gravity law is a simple, elegant and representative formula that estimates the interacting strength between two nodes by simultaneously considering the intrinsic influences of the two nodes themselves and the distance between them. In this paper, the gravity model (Eq. 1) makes use of both the neighborhood information and the path information, which were separately adopted in many previous methods. Furthermore, to reduce the computational complexity and to avoid the accumulated noises through long paths, we proposed a local version of the gravity model (LGM, see Eq. 2). Both GM and LGM are very competitive, and of particular interests, the LGM requires less computation yet performs even better. Indeed, LGM is one of the two best-performed methods among many well-known benchmark algorithms.
A potential disadvantage of LGM is that it has a free parameter, namely the truncation radius R. The negative effects of the existence of R are twofold. Firstly, it asks for more computation to determine the optimal value of R. Secondly, if the optimal value, say R*, is very large, the computational complexity of LGM will be more or less the same to GM. Fortunately, as shown in Fig. 2, we found an empirical relation between R* and the average distance 〈d〉, so that if the computational resource is highly limited, we can use the relation (see Eq. 5) to approximate R*. In addition, since most real networks are of small-world property31,38, R* should be small and thus it requires much less computation than GM. Fortunately, the difference between two rankings of nodes produced by neighboring R will quickly converge to a very small value, so that to choose a small value of R will probably perform very well. In Table 3, we show the values of τ(R), which is the Kendall’s tau between two rankings of nodes’ influences with truncation radius being R and R + 1. One can observe that after R = 5, all networks are of τ(R) > 0.97 and a half of them are of τ(R) > 0.99. This indicates a strong saturation, namely the increasing of R will produce almost the same rankings if the value of R is already large.
Another similar model (named G+, see Eq. 11) shows very close performance to LGM. In comparison, LGM is more efficient since it completely depends on the local topological structure and thus can be calculated not only faster but also under the case where the global topology is not known. In the absence of global topology, G+ cannot be obtained since it sets a node’s k-shell index as its mass, and to determine the k-shell index needs the knowledge of the whole network. In despite the difference between G+ and LGM, the very good performance of G+ and LGM strongly suggest the validity and advantage of the usage of the gravity law to estimate the interacting strength. Of course, both G+ and LGM are very simple and general, which can be further improved by the following aspects (also leaving as open issues for future studies). Firstly, by introducing a few tunable parameters that can adjust the relative importance of mass and distance (e.g., to replace d2 by some da and/or to replace k by some kb) may result in more accurate predictions as indicated by known variants of the gravity law in other applications39. Secondly, we should explore how the topological features and dynamical processes affect the prediction accuracy and thus improve the original methods by introducing some topology-dependent and/or dynamics-sensitivity items40,41. Thirdly, the original gravity law is symmetric, while due to the different roles of different nodes or the essentially asymmetric nature of the dynamics42,43, the influence from node i onto node j could be different from the influence from node j onto node i, where an asymmetric form of the gravity law may be relevant.
Methods
The Kendall’s Tau
The Kendall’s Tau37 is an index measuring the correlation strength between two sequences. Considering two sequences with N elements, X = (x1, x2, …, xN) and Y = (y1, y2, …, yN). Any pair of two-tuples (x1, y1) and (xj, yj) (i ≠ j) are concordant if both xi > xj and yi > yj or both xi < xj and yi < yj. They are discordant if xi > xj and yi < yj or xi < xj and yi > yj. If xi = xj or yi = yj, the pair is neither concordant nor discordant. The Kendall’s Tau of two sequences X and Y can be calculated as
where n+ and n− denote the number of concordant and discordant pairs, respectively. It can be seen that the extent to which τ exceeds zero indicates the strength of the correlation.
Benchmark centralities
Degree Centrality9 of node i is defined as
where A = {aij} is the adjacency matrix, that is, aij = 1 if i and j are connected and 0 otherwise.
H-index10 of node i, denoted by H(i), is defined as the maximal integer satisfying that there are at least H(i) neighbors of node i whose degrees are all no less than H(i). Such index is an extension of the famous H-index in scientific evaluation44 to network analysis.
Closeness Centrality14 of node i is defined as
Betweenness Centrality15 of node i is defined as
where gst is the number of shortest paths between nodes s and t, and gst(i) is the number of shortest paths between nodes s and t that pass through node i.
Gravity Centrality16 (G) of node i is defined as
where ks(i) is the k-shell index of node i, and ψi is the set of nodes whose distance to node i is less than or equal to 3.
Extended Gravity Centrality16 (G+) of node i is defined as
where Λi is the set of neighbors of node i.
Data Availability
All relevant data are available at https://github.com/MLIF/Network-Data.
References
Newman, M. E. J. Networks (Oxford University Press, Oxford, 2018).
Caldarelli, G. Scale-Free Networks: Complex Webs in Nature and Technology (Oxford University Press, Oxford, 2007).
Lloyd-Smith, J. O., Schreiber, S. J., Kopp, P. E. & Getz, W. M. Superspreading and the effect of individual variation on disease emergence. Nature 438, 355–359 (2005).
Pastor-Satorras, R. & Vespignani, A. Immunization of complex networks. Phys. Rev. E 65, 036104 (2002).
Morone, F. & Makse, H. A. Influence maximization in complex networks through optimal percolation. Nature 524, 65–68 (2015).
Albert, R., Albert, I. & Nakarado, G. L. Structural vulnerability of the North American power grid. Phys. Rev. E 69, 025103 (2004).
Csermely, P., Korcsmáros, T., Kiss, H. J., London, G. & Nussinov, R. Structure and dynamics of molecular networks: a novel paradigm of drug discovery: a comprehensive review. Pharmacol. Ther. 138, 333–408 (2013).
Lü, L. et al. Vital nodes identification in complex networks. Phys. Rep. 650, 1–63 (2016).
Bonacich, P. Factoring and weighting approaches to status scores and clique identification. Math. Sociol. 2, 113–120 (1972).
Lü, L., Zhou, T., Zhang, Q. M. & Stanley, H. E. The H-index of a network node and its relation to degree and coreness. Nat. Commun. 7, 10168 (2016).
Kitsak, M. et al. Identification of influential spreaders in complex networks. Nat. Phys. 6, 888–893 (2010).
Brin, S. & Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 30, 107–117 (1998).
Lü, L., Zhang, Y. C., Yeung, C. H. & Zhou, T. Leaders in social networks, the delicious case. PLoS One 6, e21202 (2011).
Freeman, L. C. Centrality in social networks conceptual clarification. Soc. Networks 1, 215–239 (1979).
Freeman, L. C. A set of measures of centrality based on betweenness. Sociometry 40, 35–41 (1977).
Ma, L. L., Ma, C., Zhang, H. F. & Wang, B. H. Identifying influential spreaders in complex networks based on gravity formula. Physica A 451, 205–212 (2015).
Christakis, N. A. & Fowler, J. H. The spread of obesity in a large social network over 32 years. N. Engl. J. Med. 357, 370–379 (2007).
Floyd, R. W. Algorithm 97: shortest path. Commun. ACM 5, 345 (1962).
Chen, D., Lü, L., Shang, M. S., Zhang, Y. C. & Zhou, T. Identifying influential nodes in complex networks. Physica A 391, 1777–1787 (2012).
Gleiser, P. & Danon, L. Community structure in Jazz. Adv. Complex Syst. 6, 565 (2003).
Newman, M. E. J. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 74, 036104 (2006).
Leskovec, J., Kleinberg, J. & Faloutsos, C. Graph evolution: densification and shrinking diameters. ACM Trans. Knowl. Discov. Data 1, 2 (2007).
Yin, H., Austin, R., Benson, J. L. & David, F. G. Local higher-order graph clustering. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 555–564 (ACM Press, 2017).
Guimerȧ, R., Danon, L., Díaz-Guilera, A., Giralt, F. & Arenas, A. Self-similar community structure in a network of human interactions. Phys. Rev. E 68, 065103 (2003).
Leskovec, J., Lang, K. J., Dasgupta, A. & Mahoney, M. W. Community structure in large networks: natural cluster sizes and the absence of large well-defined clusters. Internet Math. 6, 29–123 (2009).
Adamic, L. A. & Glance, N. The political blogosphere and the 2004 U.S. election: divided they blog. In Proceedings of the 3rd international workshop on Link discovery. 36–43 (ACM Press, 2005).
Mcauley, J. J. & Leskovec, J. Learning to discover social circles in ego networks. Adv. Neural Inf. Process. Syst. 25, 548–556 (2012).
Leskovec, J., Huttenlocher, D. & Kleinberg, J. Predicting positive and negative links in online social networks. In Proceedings of the 19th international conference on World Wide Web. 641–650 (ACM Press, 2010).
Rocha, L. E., Liljeros, F. & Holme, P. Simulated epidemics in an empirical spatiotemporal network of 50,185 sexual contacts. PLoS Comput. Biol. 7, e1001109 (2011).
Batageli, V. & Mrvar, A. Pajek Datasets. Available at, http://vlado.fmf.uni-lj.si/pub/networks/data/ (2007).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440–442 (1998).
Spring, N., Mahajan, R., Wetherall, D. & Anderson, T. Measuring ISP topologies with rocketfuel. IEEE/ACM Trans. Networking 12, 2–16 (2004).
Newman, M. E. J. Assortative mixing in networks. Phys. Rev. Lett. 89, 208701 (2002).
Hu, H. B. & Wang, X. F. Unified index to quantifying heterogeneity of complex networks. Physica A 387, 3769–3780 (2008).
Castellano, C. & Pastor-Satorras, R. Thresholds for epidemic spreading in networks. Phys. Rev. Lett. 105, 218701 (2010).
Hethcote, H. W. The mathematics of infectious diseases. SIAM Rev. 42, 599–653 (2009).
Kendall, M. A new measure of rank correlation. Biometrika 30, 81–89 (1938).
Amaral, L. A. N., Scala, A., Barthelemy, M. & Stanley, H. E. Classes of small-world networks. PNAS 97, 11149–11152 (2000).
Yan, X. Y., Zhou, T. & Destination Choice Game: A Spatial Interaction Theory on Human Mobility. Natural Resources 2, 234–239 (2018).
Klemm, K., Serrano, M. Á., Eguíluz, V. M. & San Miguel, M. A measure of individual role in collective dynamics. Sci. Rep. 2, 292 (2012).
Liu, J. G., Lin, J. H., Guo, Q. & Zhou, T. Locating influential nodes via dynamics-sensitive centrality. Sci. Rep. 6, 21380 (2016).
Yan, G., Fu, Z. Q. & Chen, G. Epidemic threshold and phase transition in scale-free networks with asymmetric infection. Eur. Phys. J. B 65, 591–594 (2008).
Wang, W. et al. Asymmetrically interacting spreading dynamics on complex layered networks. Sci. Rep. 4, 5097 (2014).
Hirsch, J. E. An index to quantify an individual’s scientific research output. Proc. Natl. Acad. Sci. USA 102, 16569–16572 (2005).
Acknowledgements
The authors acknowledge DataCastle to hold the related world-wide competition and to share the data. This work is partially supported by National Natural Science Foundation of China (61473073, 61104074, 61433014), Fundamental Research Funds for the Central Universities (N161702001, N171706003), and Program for Liaoning Excellent Talents in University (LJQ2014028).
Author information
Authors and Affiliations
Contributions
Z.L., T.R. and T.Z. devised the research project. S.M.L. and Y.X.Z. performed the research. Z.L., T.R., S.M.L., Y.X.Z. and T.Z. analyzed the data. Z.L., T.R., X.Q.M., S.M.L., Y.X.Z. and T.Z. wrote the paper.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, Z., Ren, T., Ma, X. et al. Identifying influential spreaders by gravity model. Sci Rep 9, 8387 (2019). https://doi.org/10.1038/s41598-019-44930-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-44930-9
This article is cited by
-
Quantification and measurement of relationship between movies and actors for production resources optimisation and box office business success: insights and reflections using network science approach
Social Network Analysis and Mining (2024)
-
Identifying influential nodes in complex networks using a gravity model based on the H-index method
Scientific Reports (2023)
-
A mechanics model based on information entropy for identifying influencers in complex networks
Applied Intelligence (2023)
-
Efficient community-based influence maximization in large-scale social networks
Multimedia Tools and Applications (2023)
-
Identifying influential spreaders by gravity model considering multi-characteristics of nodes
Scientific Reports (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
