
Abstract
The ability to measure and record high-resolution depth images at long stand-off distances is important for a wide range of applications, including connected and automotive vehicles, defense and security, and agriculture and mining. In LIDAR (light detection and ranging) applications, single-photon sensitive detection is an emerging approach, offering high sensitivity to light and picosecond temporal resolution, and consequently excellent surface-to-surface resolution. The use of large format CMOS (complementary metal-oxide semiconductor) single-photon detector arrays provides high spatial resolution and allows the timing information to be acquired simultaneously across many pixels. In this work, we combine state-of-the-art single-photon detector array technology with non-local data fusion to generate high resolution three-dimensional depth information of long-range targets. The system is based on a visible pulsed illumination system at a wavelength of 670 nm and a 240 × 320 array sensor, achieving sub-centimeter precision in all three spatial dimensions at a distance of 150 meters. The non-local data fusion combines information from an optical image with sparse sampling of the single-photon array data, providing accurate depth information at low signature regions of the target.
Similar content being viewed by others

Introduction
Imaging technology capable of measuring high resolution three-dimensional depth information has developed significantly in recent years. Such 3D imaging technology is required in a range of emerging application areas: for example, the gaming industry requires accurate high-speed player position information1; the defense sector requires long-range target identification for several scenarios2,3; and in the automotive sector, situational awareness technology will play a key role in the future of connected and autonomous vehicles4,5,6. In parallel with the technological advances in 3D imaging hardware, computational image processing has been shown to be extremely powerful7. Artificial neural networks can be trained to identify images in low-light levels8,9, and optimization procedures, based on prior information, can be used to de-noise, upscale, and enhance 3D images10,11. Whilst each application has differing performance requirements, ultimately the future of three-dimensional imaging will rely on a combination of state-of-the-art camera technology and advanced image processing methods12,13.
LIDAR (light detection and ranging) is a commonly used method for determining the distance of an object based on the time of flight of the optical signal returned from the target14,15,16. Here a pulsed illumination source is used in combination with a single-photon detector. Once the return signal is measured, the round-trip time of the return signal is estimated and the distance to the target can be deduced. Many LIDAR systems operate in a point-like fashion, where the distance to a point on an object is measured. If full three-dimensional imaging is required, the source is scanned over the object and the depth information is built up pixel by pixel.
The maximum range of a LIDAR system is limited by a number of factors, including the optical power levels and the geometry of the receive channel (aperture diameter, etc.). A major factor limiting maximum range is the type of optical detection scheme, with single-photon detection being considered a potential option, due to its high sensitivity and excellent surface-to-surface resolution. For example, single-photon detection has been used in demonstrations at over 10 km range in daylight conditions17,18,19,20,21, allowing detailed reconstruction of non-cooperative targets. Superconducting nanowire single-photon detectors have shown good performance in LIDAR and depth profiling applications19,22, however their low operating temperatures (i.e. <4 K) has limited their use in practical applications. SPAD (single-photon avalanche diode) detectors have shown great potential for LIDAR applications being operated at, or near, room temperature, as well as being highly sensitive and exhibiting low jitter (typically <100 ps). As examples, SPADs have been used in a range of LIDAR and depth imaging demonstrations: 1 km imaging using Si-SPADs17, imaging at 1550 nm wavelength with InGaAs/InP SPADs18, and 10 km imaging at λ = 1150 nm20. In each case, detailed three-dimensional reconstruction was possible. Single-photon counting LIDAR has been demonstrated in several applications, including remote sensing for geodesy23, for target identification in clutter3,24, and for airborne analysis of forestry25 and multispectral analysis of arboreal physiological parameters26.
Over the past several years, single-photon sensitive detectors have been used to observe laser propagation in air27,28, to detect objects hidden from the line-of-sight29,30,31,32,33, and to image in the presence of scattering media34,35,36,37,38,39,40. In particular, progress is being made in the development and implementation of SPAD detectors in the form of dense pixel arrays41,42,43,44. Such detectors take advantage of metal-oxide-semiconductor (CMOS) technology, so that an array of SPADs can be fabricated and integrated onto a small chip45,46. SPAD arrays consist of large number of pixels that provide high spatial resolution while maintaining single-photon sensitivity and picosecond timing resolution47. They are ideal candidates for three-dimensional ranging and imaging due to their high-spatial resolution and temporal characteristics11.
In this work we demonstrate a high-resolution three-dimensional imaging system based on a silicon CMOS SPAD array and an active illumination system. The precision of the system is measured to be less than a centimeter in all three spatial dimensions at a stand-off distance of 150 meters. We then combine our results with a non-local data fusion algorithm48,49,50 that can complete missing depth information by exploiting information from a co-registered optical RGB image taken with a digital camera. We use weighted color and depth information to fill in the missing information51,52, and assume that close regions have local correlations in depth53,54,55. This ability to fill in missing information is extremely powerful as it can enable large areas of depth information to be gathered from a small subset of data. Our results demonstrate the capability of such sensors at measuring depth at long distances and illustrate the potential for extremely high-resolution imaging at distance. To summarise, the main contribution of our work is the use of a state-of-the-art SPAD array sensor in conjunction with advanced, bespoke image processing algorithms, enabling accurate three-dimensional images with colour representation to be reconstructed from data measured at large stand-off distances.
Results
Experimental setup
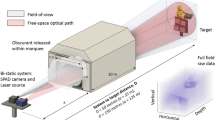
The system is configured in a bistatic setup comprising three parts: the transmitter, the receiver and the associated system control components as shown in Fig. 1 (see Methods for further details). The Single-Photon Counting Imager (SPCImager) is a SPAD-based time-gated image sensor implemented in 0.13 μm silicon CMOS with 8 μm pixel pitch and 26.8% fill factor. It operates over a wavelength range of around 350 nm–1000 nm. This is one of the largest-format SPAD detector arrays produced to date. It is a high frame-rate imager (up to 10 kfps) that offers high spatial resolution with its array of 240 by 320 pixels, and picosecond timing resolution with its time-gating capability. The rise time of the electronic gate is of the order of tens of picoseconds. The minimum width of this gate is 18 ns.

Experimental setup for SPAD-based time-gated image sensing. The distance from the SPAD camera and laser to the target is 150 m. The inset photograph is the co-registered RGB image captured and used for the non-local fusion image processing. The series of images represent sample preprocessed images corresponding to ten consecutive gate positions. Depth information is gained by scanning the location of the gate.
The stand-off distance from the active imaging system to the target scene is ~150 m. Data for a three-dimensional image is collected by scanning the laser beam over the target surfaces in a 20 by 20 grid, corresponding to a 1.2 m by 1.2 m area, and recording the respective signal returning from the scene for a single gate setting (see Supplementary Information for an illustration of the scanning procedure), and then repeating this process for a series of different gate settings. The laser illumination spot is defocused such that it approximately covers a 50 by 50 pixel area. This size of illumination is chosen as a good compromise between the number of scan positions and the signal return from the target. A laser with higher power would enable flood illumination or a greater distance to the target. The exposure time per scan position is 215 μs, and 256 bit planes are added together per scan position (chosen empirically). We measure an intensity related to the reflectivity of the objects in the target scene.
The gate width for the acquisitions is 18 ns, corresponding to a distance of 2.7 m (d = t * c/2), but time at which the gate is open can be shifted in timing increments which are significantly less, in this case 250 ps. Whilst a 250 ps increment corresponds to a depth of 3.75 cm, the total error in the depth measurements is considerably less than this, as multiple photon measurements are made at each pixel for each timing step, allowing improved depth resolution. The total error in the depth measurements is related to the shift of the gate, the rise time of its leading edge, and our ability to fit to the observed data.
Depth imaging at 150 m
After the data acquisition and initial processing, we have a 240 by 320 by 51 three-dimensional data cube. For each pixel in the 240 by 320 array, we can expect the recorded intensity to be approximately zero when the target depth is outside the time gate of the SPAD camera. Otherwise, it is a non-zero constant. The observed data, yn,k, is the number of photon counts measured by pixel n at at particular gate location k. This observed data can be fitted to a function, sn,k, to establish the target depth and refelctivity information at each pixel. We apply the following fitting function sn,k to the data yn,k:
where erf\((\,\cdot \,)\) denotes the error function, h ≥ 0 is a fixed impulse response (IR) intrinsic parameter that represents the width of the leading edge, and dn ≥ 0 and rn ≥ 0 are related to the target’s depth and intensity respectively. Here, we assume the absence of background bn = 0, ∀ n, since the noise has been removed at the preprocessing stage. Although we utilize the erf\((\,\cdot \,)\) function, other kinds of bounded monotonic increasing functions in the real number domain, such as arctan\((\,\cdot \,)\), may also be considered. Figure 2 in the Supplementary Information section shows sample fits for three different depths. In this data, one can see that the precision at which we can establish depth information is significantly less than the gate width.
Figure 2 shows 3D reconstructions of the target scene obtained by combining the depth and intensity information retrieved using the non-linear least squares fitting method. The results have been cropped to the scene (228 by 228 pixels). We apply a correction to the retrieved depth profile to account for the fall time mismatch of the electronic gate of the SPAD sensor. In order to determine the range and surface-to-surface resolution of our system, we analyze a patch of 25 by 25 pixels for each panel of the depth board target. Clockwise, from the top left these panels are separated by 10 cm, 10 cm, 10 cm and 30 cm, and we record separations of 9.3 ± 1.1 cm, 8.8 ± 1.1 cm, 11.1 ± 1.1 cm, and 29.1 ± 1.1 cm, respectively. All separations were accurately established to within one standard deviation. The standard deviation of depth calculated using all the panels was established to be 0.8 cm.

Three-dimensional reconstruction of the target scene at 150 m distance. (a) Retrieved depth information. (b) The intensity information from the SPAD overlaid on top of the retrieved depth information. (c) The intensity information from a colour camera overlaid on top of the retrieved depth information.
Non-local fusion-based image processing
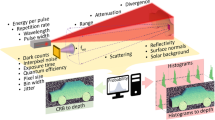
LIDAR data acquisition is performed by scanning several beam locations at each depth. This can lead to a high acquisition time, creating a bottleneck for the deployment of such a system in real-life applications. It is therefore important to deal with this challenge, and there are two ways to do this: (i) reduce the number of bit planes summed at each depth position (i.e. reduce the dwell time), and (ii) perform compressed sensing by considering under-sampled and random beam scans. Both solutions lead to sparse pixels containing fewer photons and, consequently, having a higher noise level. Under these conditions, using the noise statistics for parameter estimation is necessary but not sufficient to obtain good parameter estimates for Eq. (1). In addition, rapidly scanning the laser across a scene can lead to areas with little or no depth information. This limitation can be overcome by carefully considering prior information. For example, it is known that images exhibit strong spatial correlations, i.e. images tend to be smooth and composed mainly of low spatial frequencies, and the same can be said for depth. This prior information can be used by considering regularization terms that account for correlations in the estimated depth and intensity images.
The core of our algorithm is to make use of a co-registered optical image, which has complete RGB intensity information for every pixel, and prior knowledge about the object to help fill in missing information in the depth profile. This missing information arises as we do not consider all of the measured scan positions, but we simulate a rapid scan thus losing depth information about certain pixels. As a result, we have pixels in the image where we have complete depth information and pixels where we have no depth information. We do, however, have complete RGB color information provided by the optical image. Our algorithm makes use of a core assumption: the depths of two objects are strongly correlated with the similarity of their RGB values and a function of the distance between them, i.e. two objects that are close by and have similar colors will also be at similar depths. This means that there will be a correlation in the depth of pixels with the same color, and this correlation will be stronger the closer those pixels are. This assumption is extremely powerful as it enables us to fill in the depth information about an object when we only have knowledge about the RGB value. Note that similar assumptions are commonly adopted for the restoration of depth maps, as in52,56.
In our non-local optimization, we consider four terms. The first term ensures agreement between our data and a Poisson statistical noise model while the second imposes non-negativity on the estimated parameter values. Of particular interest are the third and fourth terms which are our regularization terms for the target’s depth and intensity respectively. Each of these regularization terms is the sum of weighted differences between each pixel and other pixels located in a predefined field of nearby pixels.
To obtain the weights for the intensity regularization function, we first take the optical image and rescale this to the same resolution of the depth image (228 by 228 pixels). For every pixel in the image, we then calculate the difference between the RGB value of that pixel and the RGB value of each nearby pixel in the predefined field, for each of the three RGB color channels (the field is defined to be a 15 by 15 pixel square centered on each starting pixel). The differences of the three RGB channels are summed and averaged for the pixel leading to a weight value for each pixel and each direction. These weights are only calculated between each pixel and the 15 by 15 square region around it, in order to improve the efficiency of the calculation.
This approach enforces small weighted differences between similar pixels in the image while preserving sharp edges by considering an \({\ell }_{1}\) norm to compute pixel differences (see Eq. (11) in Supplementary Materials). Note that other commonly used transformations can be applied to the RGB image before computing the weights, such as YUV or YCrCb57, and this can be easily included in the proposed algorithm. Each 15 by 15 matrix of differences is reshaped to a 225 by 1 vector, such that we have a 228 by 228 by 225 array containing all weighted differences for all pixels. This matrix w has elements wnm where the index n corresponds to the pixel of interest, and m corresponds to the direction from that pixel (see Supplementary Information for details). For the regularization of the depth, we take each intensity weight in the matrix and further weight this with the normalized vector distance between each pixel n and the corresponding m th pixel, leading to the matrix v. The non-local fusion image processing is summarized in Fig. 3, and further details regarding the weights are given in the Supplementary Section.

Non-local data fusion. For every pixel in the optical image, differences in RGB color values are calculated, summed and averaged for that pixel and every other pixel in a predefined field. This is then weighted by the normalized vector distance between the pixels to obtain a weight for the regularization function to fill in the depth information missing from the scene.
Figure 4 shows the results of the non-local fusion algorithm. These data correspond to 25%, 10%, and 5% of scan positions, which relate then to 83.7%, 61.8%, and 35.8% of pixels respectively. Again, we have applied a correction to the retrieved depth profile to account for the fall time mismatch of the SPAD sensor gate. Significant improvement in the three-dimensional image is observed after data processing, even in the case where 5% of the scan positions are used. Features such as the mannequin’s arm and head can be recognized in the processed data, even when they are not present in the original depth data set. This shows the clear advantage of the proposed algorithm in data reconstruction with an extremely reduced number of scan positions, which could correspond to a significantly reduced acquisition time.

3D reconstruction of the target scene using (a) 25%, (b) 10%, and (c) 5% of the scanned positions before and after non-local data fusion.
Discussion
The system has performed exceptionally well at recording three-dimensional depth information at a distance of 150 m. We are able to record depth data with a standard deviation less than one centimeter using a gate separation of 0.25 ns (7.5 cm). Lower standard deviations will be possible if smaller gate separations are used.
The drawback of the system in its current form is the time required to generate first an image and then scan the gate position. The time taken to collect all the data was around 2 hours. In principle, the same data could be collected in a fraction of the time. The total acquisition time for each of the images in the 20 by 20 scan is only 215 μs. This means that the total exposure time for all 400 images is only 100 ms. We should therefore be able to get an intensity image at a frame rate of around 10 frames per second. It would then take a total of 5 seconds to generate the 3D data cube, which contains all the 3D information. Additionally, the next generation of SPAD detector arrays with TCSPC capabilities will provide the ability to capture 3D depth data at higher acquisition rates58.
The system offers potential detection in low visibility and low light level environments. In particular, the time-gated imaging approach may be extended to degraded visual environments in which a scattering medium, e.g. dust, fog, rain, smoke, and snow, is present. By not activating the sensor until the outgoing photon has penetrated the medium to reach the object of interest, the main advantage that this approach provides is the capability to reject light that has been backscattered from everywhere else in the scene and, as a result, obtain an image that would otherwise be severely degraded by early backscattered photons.
It would be interesting to generalise the proposed method outlined in this work to account for a variety of different scenarios. These could include multiple multi-layer imaging, e.g. through foliage or semi-transparent surfaces, or imaging through obscurants, e.g. through fog, snow, rain or sand. In these scenarios, we will have to account for the lack of complete colour and intensity information across the entire image. These challenging scenarios are of significant interest and of relevance to the automotive industry. We are actively pursuing this as future research.
Methods
Details of experimental setup
A photograph of the system is shown in Fig. 5. The transmitter (see Fig. 6) is a scanning pulsed illumination system mounted on an M6-threaded 300 mm by 450 mm aluminum breadboard attached to a Kessler K-Pod heavy-duty tripod with Hercules 2.0 pan-and-tilt tripod head. The light beam from a visible picosecond pulsed laser diode head (PicoQuant LDH-P-C-670M, 671 nm peak wavelength, 15 MHz repetition rate, 40 mW average power) is reshaped using a 1-inch N-BK7 plano-convex cylindrical lens (f = 50 mm) before being coupled, using two 1-inch broadband dielectric mirrors, into a 50 μm core diameter multimode fiber patch cable (0.22 NA, 1 m). The fiber input is mounted onto a manual XYZ flexure stage (Elliot Scientific) with a microscope objective lens (0.30 NA, f = 7.5 mm); the output is mounted onto a 30 mm cage mount system. The light exiting the fiber (average power ~19 mW) is launched into the motor and mirror assembly of a dual-axis scanning Galvanometer mirror positioning system (Thorlabs GVS012/M), after which it passes through an f-theta scanning lens (EFL = 254 mm). The object distance to the scanning lens is changed by adjusting the position of the fiber cage mount and the position of the Galvanometer scanner, which is mounted on a dovetail optical rail. This allows us to control the size of the illuminating spot at the target. There is a trade-off when selecting the size of the illumination at the target. On the one hand, it is ideal to have a large spot illuminate the target as images can be formed quickly without the need to scan. On the other hand, larger return signals can be achieved if the spot is focused at the target.

Photograph of the scanning pulsed illumination system and SPAD camera.

Imaging system and target scene. (a) Shows a schematic of the transmitter, the receiver and the associated system control components. (b) Front-profile photograph of the mannequin and the 1 m depth board target located at 150 m stand-off distance. Lighting conditions are as in the experiment. (c) Side-profile photograph of the targets.
The receiver (see Fig. 6) consists of a tripod-mounted commercial zoom lens (Nikon AF-S NIKKOR 200–400 mm f/4G ED-IF VR) onto which a SPAD camera is mounted. For the experiment, the focal length of the lens is set to f = 250 mm and the aperture is set to f/4. Inside the aluminum camera housing, between the lens and the SPAD sensor, we place a 1.5 nm bandpass filter to limit the background light and accept only the incoming light that matches the peak wavelength of the laser source. An Opal Kelly XEM6310-LX45 FPGA integration module provides the electronic readout from the SPAD sensor chip via USB 3.0 to a control computer; see Fig. 6. The computer also connects to the Galvanometer scanning system through a DAQ device (National Instruments NI USB-6211), controlling the range and number of steps that the scanner takes. A laser driver (PicoQuant PDL 800-D) controls the pulse repetition rate and output power of the laser diode. A pulse pattern generator (Keysight 83114A) triggers the laser and SPAD camera, allowing synchronization between the return photons and the electronic gate. It also controls scanning of the temporal delay of the gate.
The cyan section in Fig. 6 shows a birds-eye view of the composite elements of the target scene located at 150 meters from the system. The photographs (inset in Fig. 6) show the front and side profiles of the target objects. In the scene, a mannequin is dressed in camouflage military clothing with its arms positioned to vary the range of depths that is measured across the scene. Behind the mannequin, we place a 1 m square wooden depth target comprising four 0.5 m square panels at incremental depths of 0 cm, 10 cm, 20 cm, and 30 cm (measured clockwise from the top-left panel).
SPAD-based time-gated image sensing
The system performs time-gated imaging using a pulsed picosecond light source and the SPCImager operated in gated mode. When the laser diode emits a pulse, the SPAD camera is triggered to acquire data for the gate duration of 18 ns. By introducing a temporal delay to the trigger signal from the laser diode, we synchronize the return light signal with the electronic gate of the camera in order to image photons returning from a pre-determined range. The SPCImager is a single-photon sensor that gives a binary output indicating whether or not a photon is present. A bit plane is a single exposure of the camera’s sensor and is a 240 by 320 array of 0 s and 1 s. Multiple bit planes are required to build up an image with any an intensity grayscale.
Data acquisition
Time-gating of the camera enables sectioning of the target scene. The gate width is set to 18 ns, i.e. all photons arriving within 18 ns of the temporal delay are captured. However, the rise time of the gate is very fast, so objects can come in and out of the captured image very clearly, depending on the location of the gate. That is to say, the gate can be delayed so that the return light from certain objects are inside the imaging gate and are seen by the camera, but the return light from other objects are located outside of the gate and therefore rejected. Three-dimensional information about a target is gained by temporally scanning the gate across the object and measuring the precise time at which the object enters the gate. This time is then converted into distance. In this experiment, images at 51 temporal gate positions are recorded. The spacing between each image is chosen to be 0.25 ns, corresponding to a separation of approximately 7.5 cm in distance.
The depth and intensity information of the target surface is obtained by first generating a three-dimensional data cube consisting of intensity images taken at different depths. The depth at which these images are captured is determined by the location of the gate. Each image at a particular depth is constructed from individual image frames that correspond to around 400 different laser illumination positions. Each of these frames record the information from the target scene and noise, which is a combination of the background light and dark counts from the sensor. We find that the noise associated with background light does not change significantly from frame to frame. This is in contrast to the noise associated with dark counts; pixels with high dark count rates can have a high variation from frame to frame. There are, however, only a few pixels with very high dark count rates (more that 90% of the pixels have a dark count rate of less than 10 kHz), and this can be accounted for easily. We deal with each of these sources of noise separately (see Supplementary Information).
Range ambiguity
The fixed repetition rate of the laser was 15 MHz. This corresponds to a pulse separation of 20 m leading to a range maximum stand-off distance free of range ambiguity of only 10 m. Whilst the subject of this paper is to describe target depth profile reconstruction of more distant targets, we acknowledge that such a level of range ambiguity is not ideal. In order to remove range ambiguity in such measurements, there are several possible strategies: (1) use of a source a sufficiently lower repetition rate (with higher energy laser pulses); (2) the application of several different source repetition rates in sequence; and (3) use of pseudo-random sequences of laser pulses to avoid all ambiguity as demonstrated previously59.
References
Kolb, A., Barth, E., Koch, R. & Larsen, R. Time-of-Flight Cameras in Computer Graphics. Computer Graphics Forum 29, 141–159 (2010).
Shen, X., Kim, H.-S., Satoru, K., Markman, A. & Javidi, B. Spatial-temporal human gesture recognition under degraded conditions using three-dimensional integral imaging. Optics Express 26, 13938–13951 (2018).
Tobin, R. et al. Long-range depth profiling of camouflaged targets using single-photon detection. Optical Engineering 57, 1–10 (2018).
Schwarz, B. LIDAR: Mapping the world in 3D. Nature Photonics 4, 429–430 (2010).
Niclass, C., Inoue, D., Matsubara, H., Ichikawa, T. & Soga, M. Development of Automotive LIDAR. Electronics and Communications in Japan 98, 28–33 (2015).
Itzler, M. A. et al. Geiger-Mode LiDAR: From Airborne Platforms To Driverless Cars. In Imaging and Applied Optics (Optical Society of America, 2017).
Altmann, Y. et al. Quantum-inspired computational imaging. Science 361, 1–7 (2018).
Nasrabadi, N. M. Pattern Recognition and Machine Learning. Journal of Electronic Imaging 16 (2007).
Niu, Z. et al. Photon-limited face image super-resolution based on deep learning. Optics Express 26, 22773–22782 (2018).
Altantawy, D. A., Saleh, A. I. & Kishk, S. Single depth map super-resolution: A self-structured sparsity representation with non-local total variation technique. IEEE International Conference on Intelligent Computing and Information Systems 43–50 (2017).
Ren, X. et al. High-resolution depth profiling using a range-gated CMOS SPAD quanta image sensor. Optics Express 26, 5541–5557 (2018).
Kirmani, A. et al. First-Photon Imaging. Science 343, 58–61 (2014).
Howland, G. A., Dixon, P. B. & Howell, J. C. Photon-counting compressive sensing laser radar for 3D imaging. Applied Optics 50, 5917–5920 (2011).
Jaboyedoff, M. et al. Use of LIDAR in landslide investigations: a review. Natural Hazards 61, 5–28 (2012).
Simard, M., Pinto, N., Fisher, J. B. & Baccini, A. Mapping forest canopy height globally with spaceborne lidar. Journal of Geophysical Research 116, 1–12 (2011).
Dong, P. & Chen, Q. LiDAR remote sensing and applications (CRC Press, Boca Raton, FL, 2017).
McCarthy, A. et al. Long-range time-of-flight scanning sensor based on high-speed time-correlated single-photon counting. Applied Optics 48, 6241–6251 (2009).
McCarthy, A. et al. Kilometer-range depth imaging at 1550 nm wavelength using an InGaAs/InP single-photon avalanche diode detector. Optics Express 21, 22098–22113 (2013).
McCarthy, A. et al. Kilometer-range, high resolution depth imaging via 1560 nm wavelength single-photon detection. Optics Express 21, 8904–8915 (2013).
Pawlikowska, A. M., Halimi, A., Lamb, R. A. & Buller, G. S. Single-photon three-dimensional imaging at up to 10 kilometers range. Optics Express 25, 11919–11931 (2017).
Kang, Y. et al. Fast Long-Range Photon Counting Depth Imaging With Sparse Single-Photon Data. IEEE Photonics Journal 10, 1–10 (2018).
Warburton, R. E. et al. Subcentimeter depth resolution using a single-photon counting time-of-flight laser ranging system at 1550 nm wavelength. Optics Letters 32, 2266–2268 (2007).
Glennie, C. L., Carter, W. E., Shrestha, R. L. & Dietrich, W. E. Geodetic imaging with airborne LiDAR: the Earth’s surface revealed. Reports on Progress in Physics 76, 1–24 (2013).
Henriksson, M., Larsson, H., Grönwall, C. & Tolt, G. Continuously scanning time-correlated single-photon-counting single-pixel 3-D lidar. Optical Engineering 56, 031204 (2017).
Swatantran, A., Tang, H., Barrett, T., DeCola, P. & Dubayah, R. Rapid, High-Resolution Forest Structure and Terrain Mapping over Large Areas using Single Photon Lidar. Scientific Reports 6, 1–12 (2016).
Wallace, A. M. et al. Design and Evaluation of Multispectral LiDAR for the Recovery of Arboreal Parameters. IEEE Transactions on Geoscience and Remote Sensing 52, 4942–4954 (2014).
Velten, A. et al. Femto-Photography: Capturing and Visualizing the Propagation of Light. ACM Transactions on Graphics 32, 1–8 (2013).
Gariepy, G. et al. Single-photon sensitive light-in-fight imaging. Nature Communications 6, 1–6 (2015).
Velten, A. et al. Recovering three-dimensional shape around a corner using ultrafast time-of-flight imaging. Nature Communications 3, 1–8 (2012).
Gariepy, G., Tonolini, F., Henderson, R., Leach, J. & Faccio, D. Detection and tracking of moving objects hidden from view. Nature Photonics 10, 23–26 (2015).
Chan, S., Warburton, R. E., Gariepy, G., Leach, J. & Faccio, D. Non-line-of-sight tracking of people at long range. Optics Express 25, 10109–10117 (2017).
Laurenzis, M., Velten, A. & Klein, J. Dual-mode optical sensing: three-dimensional imaging and seeing around a corner. Optical Engineering 56, 031202 (2017).
Caramazza, P. et al. Neural network identification of people hidden from view with a single-pixel, single-photon detector. Scientific Reports 8, 1–6 (2018).
Laurenzis, M., Christnacher, F., Monnin, D. & Scholz, T. Investigation of range-gated imaging in scattering environments. Optical Engineering 51, 061303 (2012).
Maccarone, A. et al. Underwater depth imaging using time-correlated single-photon counting. Optics Express 23, 33911–33926 (2015).
Halimi, A., Maccarone, A., McCarthy, A., McLaughlin, S. & Buller, G. S. Object Depth Profile and Reflectivity Restoration From Sparse Single-Photon Data Acquired in Underwater Environments. IEEE Transactions on Computational Imaging 3, 472–484 (2017).
Satat, G., Tancik, M., Gupta, O., Heshmat, B. & Raskar, R. Object classification through scattering media with deep learning on time resolved measurement. Optics Express 25, 17466–17479 (2017).
Satat, G., Tancik, M. & Raskar, R. Towards photography through realistic fog. In IEEE International Conference on Computational Photography (IEEE, 2018).
Zhu, J. et al. Demonstration of measuring sea fog with an SNSPD-based Lidar system. Scientific Reports 7, 1–7 (2017).
Tobin, R. et al. Depth imaging through obscurants using time-correlated single-photon counting. In Itzler, M. A. & Campbell, J. C. (eds) Advanced Photon Counting Techniques XII, 1–9 (SPIE, 2018).
Albota, M. A. et al. Three-dimensional imaging laser radars with Geiger-mode avalanche photodiode arrays. Lincoln Laboratory Journal 13 (2002).
Niclass, C., Rochas, A., Besse, P.-A. & Charbon, E. Design and characterization of a CMOS 3-D image sensor based on single photon avalanche diodes. IEEE Journal of Solid-State Circuits 40, 1847–1854 (2005).
Zappa, F., Tisa, S., Tosi, A. & Cova, S. Principles and features of single-photon avalanche diode arrays. Sensors and Actuators A: Physical (2007).
Shin, D. et al. Photon-efficient imaging with a single-photon camera. Nature Communications 7, 1–7 (2016).
Dutton, N. A. W., Parmesan, L., Holmes, A. J., Grant, L. A. & Henderson, R. K. 320 × 240 oversampled digital single photon counting image sensor. In 2014 IEEE Symposium on VLSI Circuits, 1–2 (IEEE, 2014).
Gyongy, I. et al. A 256 × 256, 100-kfps, 61 Sensor for Time-Resolved Microscopy Applications. IEEE Transactions on Electron Devices 65, 547–554 (2018).
Gyongy, I., Dutton, N. A. W. & Henderson, R. K. Single-Photon Tracking for High-Speed Vision. Sensors 18, 1–14 (2018).
Buades, A., Coll, B. & Morel, J.-M. A review of image denoising algorithms, with a new one. SIAM Journal on Multiscale Modeling and Simulation: A SIAM Interdisciplinary Journal 4, 490–530 (2005).
Dabov, K., Foi, A., Katkovnik, V. & Egiazarian, K. Image denoising by sparse 3D transform-domain collaborative filtering. In IEEE Transactions on Image Processing, 2080–2095 (2007).
Salmon, J., Harmany, Z., Deledalle, C.-A. & Willett, R. Poisson Noise Reduction with Non-local PCA. Journal of Mathematical Imaging and Vision 48, 279–294 (2014).
Park, J., Kim, H., Tai, Y.-W., Brown, M. S. & Kweon, I. S. High-Quality Depth Map Upsampling and Completion for RGB-D Cameras. In IEEE Transactions on Image Processing, 5559–5572 (2014).
Yang, J., Ye, X., Li, K., Hou, C. & Wang, Y. Color-Guided Depth Recovery From RGB-D Data Using an Adaptive Autoregressive Model. In IEEE Transactions on Image Processing, 3443–3458 (2014).
Rudin, L. I., Osher, S. & Fatemi, E. Nonlinear total variation based noise removal algorithms. Physica D 60, 259–268 (1992).
Iordache, M.-D., Bioucas-Dias, J. M. & Plaza, A. Total Variation Spatial Regularization for Sparse Hyperspectral Unmixing. In IEEE Transactions on Geoscience and Remote Sensing, 4484–4502 (2012).
Lanaras, C., Bioucas-Dias, J., Baltsavias, E. & Schindler, K. Super-Resolution of Multispectral Multiresolution Images from a Single Sensor. In IEEE Conference on Computer Vision and Pattern Recognition Workshops (2017).
Rapp, J. & Goyal, V. K. A Few Photons Among Many: Unmixing Signal and Noise for Photon-Efficient Active Imaging. IEEE Transactions on Computational Imaging 3, 445–459 (2017).
Lebrun, M., Buades, A. & Morel, J. M. A Nonlocal Bayesian Image Denoising Algorithm. SIAM Journal on Imaging Sciences 6, 1665–1688 (2013).
Henderson, R. K. et al. A 192 × 128 Time Correlated Single Photon Counting Imager in 40 nm CMOS Technology. In European Solid-State Circuits Conference, 54–57 (2018).
Krichel, N. J., McCarthy, A. & Buller, G. S. Resolving range ambiguity in a photon counting depth imager operating at kilometer distances. Optics Express 18, 9192–9206 (2010).
Acknowledgements
This work was funded by the Engineering and Physical Sciences Research Council (EPSRC, UK) through the Quantum Technology Hub in Quantum Enhanced Imaging (EP/M01326X/1), by the European Research Council TOTALPHOTON grant through the EU’s Seventh Framework Program (FP/2007–2013)/ERC GA 339747, by the UK Royal Academy of Engineering under the Research Fellowship Scheme (RF/201718/17128), by the Royal Society (URF\R1\180153) and by the Defense Science and Technology Laboratory’s Defense and Security Accelerator (DASA). The assistance of Phil Soan in organizing and coordinating the Imaging Through Obscurants (ITO) Fog and Smoke Trial at the DSTL Porton Down laser range is gratefully acknowledged. The authors appreciate the support of STMicroelectronics who fabricated the SPCImager.
Author information
Authors and Affiliations
Contributions
S.C. and J.L. performed the experiments and drafted the manuscript. S.C., A.H., S.M. and F.Z. performed data analysis. R.H. designed the CMOS SPAD pixel architecture and I.G. provided support with the SPAD array. R.B. wrote the LabView VI that allows 3D visualization of an object by overlaying its depth profile with an intensity profile. G.B. and J.L. led the project. All authors contributed to scientific discussions and to the final manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chan, S., Halimi, A., Zhu, F. et al. Long-range depth imaging using a single-photon detector array and non-local data fusion. Sci Rep 9, 8075 (2019). https://doi.org/10.1038/s41598-019-44316-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-44316-x
This article is cited by
-
Image-Based Deformation Measurement of Aerodynamic Heating Surfaces Using Time-Gated Active Imaging Digital Image Correlation
Experimental Mechanics (2023)
-
Robust real-time 3D imaging of moving scenes through atmospheric obscurant using single-photon LiDAR
Scientific Reports (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
