
Abstract
Evolutionary processes, speciation in woody bamboos are presently little understood. Here we used Dendrocalamus sinicus Chia & J.L. Sun as a model species to investigate dispersal or vicariance speciation in woody bamboos. Variation in three chloroplast DNA (cpDNA) fragments and eight simple sequence repeat markers (SSR) among 232 individuals sampled from 18 populations across the known geographic range of D. sinicus was surveyed. D. sinicus populations exhibited a high level of genetic differentiation which divided them into two groups that are consistent with different culm types. Eleven haplotypes and two lineages (Straight-culm and Sinuous-culm lineages) were identified from phylogenetic analyses, and a strong phylogeographic structure across the distribution range was found. The demographic and spatial expansion times of the Straight-culm lineage were calculated as 11.3 Kya and 20.8 Kya, respectively. The populations of D. sinicus had experienced dispersal and long-term isolation, although this trace was diluted by contemporary gene flow revealed by SSR data. Our results provide an phylogeographic insight to better understand the speciation processes of woody bamboos.
Similar content being viewed by others

Introduction
The biggest grasses in the world, bamboos belong to the subfamily Bambusoideae of the Poaceae, and include some 115 genera with more than 1400 species1,2. These taxa are naturally distributed in all continents except Europe and Antarctica, and their centers of species diversity are the tropical and subtropical regions of Asia, Africa and South America2. Bamboos are a significant natural resource throughout much of the world, providing food and raw materials for construction, paper pulp and manufacturing, etc.3. Many woody bamboos have a life cycle peculiar among angiosperms, in having a very long vegetative period of several decades to even 150 years, followed by gregarious flowering and monocarpy4. So far, due to lack of fossil material, long vegetative growth periods and unpredictable flowering episodes, the evolution and speciation of woody bamboos have always been an interesting but stubbornly difficult topic4,5,6,7.
Speciation is crucial to biodiversity and can be categorized in non-geographic and geographic modes8. On the aspect of non-geographic mode of bamboos, chromosome doubling and hybridization are generally deemed as the main mechanism for modern species diversity of bamboos9,10,11. In regard to woody bamboos, the chromosome allopolyploid may account for the origin of major lineages and subsequent radiation speciation10, for example, the diversity of modern temperate and tropical woody bamboos10,11. Meanwhile, the hybrid speciation among woody bamboos has been observed occasionally in the nature12. On the other hand, vicariance and dispersal speciation are viewed as two main modes of geographic speciation in plant and animal13,14. Based on the modern distribution pattern in the world, the species diversity of bamboos is generally regarded as the result of vicariance speciation7,14, which was supported by evidence of molecular bamboo systematics4,10,11. However, does dispersal speciation happen at the level of species among woody bamboos? As far as we know, there is little research report in this field. To further understand this question, more comprehensive studies are required, especially at the population level.
In this study, we use Dendrocalamus sinicus Chia & J. L. Sun as a model to gain further insights into this topic. D. sinicus is among the largest bamboos known in the world, with culms reaching over 30 m high and 30 cm in diameter, and has been acknowledged as the strongest bamboo known15. This typical paleotropical woody bamboo occurs naturally only at elevations of 600–1,500 m in south and southwestern Yunnan Province in southwest China16. D. sinicus also seems to have an interesting variation from its more northerly distribution to the south based on culm shape. The more northerly populations in southwestern Yunnan have the typically straight culms of erect clumped bamboos, whereas in the more southerly populations, clumps often develop culms that are not straight, with the lower half frequently including curved portions giving somewhat sinuous internode sequences16 (Fig. S1). Additionally, in intermediate areas between the main localities of these two variants, D. sinicus clumps have been observed to bear a mixture of both straight as well as sinuous culms17.
How did this variation and its distribution come about? Although both dispersal and vicariance have been suggested as significant in shaping the evolution and biogeography of bamboos7,14, there is as yet very little research into speciation and evolutionary processes for this important group of plants. The recent demonstration of molecular techniques in elucidating the phylogenetics, taxonomy and evolutionary history of bamboos and other plant species18,19,20,21,22,23 has prompted our own inquiry, and the relatively limited distribution of D. sinicus makes it of special interest for studying the pattern of differentiation in the world’s biggest woody bamboo. The use of maternally inherited chloroplast DNA (cpDNA) in phylogeographic analyses can help infer historical range shifts and recolonization routes of a species18. Biparentally inherited nuclear simple sequence repeat variations (SSR) are more powerful for understanding ongoing demographic processes such as contemporary gene exchange24.
In the present paper we assemble molecular methods (using cpDNA and SSR markers) and migration patterns between populations in order to reveal the contemporary population structure of D. sinicus, to infer its evolutionary history, and to assess the main genetic characteristics that could help inform woody bamboo geographic speciation, i.e. dispersal or vicariance speciation.
Results
cpDNA data
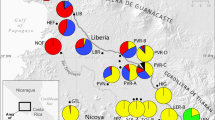
A total of 1947 bp combined cpDNA sequences were aligned which resulted in 10 polymorphic sites and 11 haplotypes (Tables S1 and S2). The geographic distribution of haplotypes among 18 Dendrocalamus sinicus populations is shown in Fig. 1. The most frequent haplotype H1 was found in 158 individuals (68.1% of all samples), mainly among the northern populations. Another common haplotype was H2 which occurred in 64 individuals (27.6% of all samples) from southern populations. H5 was shared by populations 13 and 16. Haplotypes 3, 4, 6, 7 and 8, 9, 10, 11 were exclusive to populations 14, 13, 16, 12, 12, 15, 9, 2, respectively.

Haplotype distribution in 18 Dendrocalamus sinicus populations based on combined sequences of three loci. Colored circles represent the population locations. Maps were drawn using the software ArcGIS version 10.2 (http://desktop.arcgis.com) and modified using Photoshop (Adobe Corporation, California, America).
Maximum parsimony analysis of the 11 cpDNA haplotypes of D. sinicus and the outgroup D. latiflorus resulted in three most parsimonious trees, each with a length of 26 steps, a consistency index (CI) of 0.500, and a retention index (RI) of 0.683. The Bayesian (BI) tree agreed with the MP tree at nearly all nodes. The topology of the strict consensus tree (Fig. 2a) indicates a single deep phylogenetic split between haplotypes of D. sinicus. Although the clades were not well supported (bootstrap values < 50%), they did show high posterior probability values. Haplotypes H2, 4, 6, 7, 9, and 10 formed a clade with 0.95 posterior probability; the other five haplotypes formed another clade with 0.87 posterior probability. Five populations (9, 12, 13, 14 and 16) have haplotypes from both lineages, and all of them were distributed in the central region except for 16 (southern region). The network analysis (Fig. 2b) revealed a similar structure to the phylogenetic tree (Fig. 2a) and segregated all haplotypes into two lineages, here called the Straight-culm Lineage and Sinuous-culm Lineage. Based on their interior location and high frequencies25, H1 and H2 appeared to be the ancestral types for the two lineages. Within each lineage, H8 and H11 were derived from H1; and H4, H6, H7 and H9 were derived from H2.

(a) Strict consensus tree obtained by analysis of 11 cpDNA haplotypes of Dendrocalamus sinicus, with D. latiflorus used as outgroup. The numbers on the left of the dash sign (/) indicate posterior probabilities from the Bayesian analysis; the numbers on the right indicate bootstrap values (>50%). (b) The 95% confidence network of 11 cpDNA haplotypes. The size of circles corresponds to the frequency of each haplotype. Each solid line represents one mutational step that interconnects two haplotypes for which parsimony is supported at the 95% level. The small open circles indicate hypothetical missing haplotypes.
The result of the SAMOVA analysis indicated that two groups of populations (K = 2) were the best grouping option with the highest FCT value (Fig. S2). One group (named the TZ group, population components see Table 1) was assigned the 12 H1-dominant populations with straight culms; another group (named the WQ group) was assigned the remaining six H2-dominant sinuous-culmed populations. AMOVA indicated that most of the variation (93.13%) related to differences between the two groups, 0.88% among populations within groups and 5.99% within populations (Table 2).
The estimates of haplotype, nucleotide diversity (Hd and π) and genetic diversity parameters are given in Tables 3 and 4. Hd ranged from 0.000 to 0.636, and π from 0.000 to 0.221. At the species level, Hd was 0.462, π was 0.00196, HS was 0.106 (±0.047), and HT was estimated as 0.497 (±0.0843). At the group level, the WQ group exhibited higher genetic diversity (0.231, 0.00067, 0.215 and 0.238 for Hd, π, HS and HT) compared with the TZ group (0.050, 0.00058, 0.052, 0.077). We also detected highly significantly (P ≤ 0.01) larger NST values (0.875) compared to GST (0.787), indicating there is a strong phylogeographic structure across the distribution range of D. sinicus (Table 4). At the group level, the WQ group also showed a significantly strong (P ≤ 0.05) phylogeographic structure, but this was not manifest in the TZ group.
The mismatch distribution of cpDNA haplotypes was clearly bimodal and differed strongly from that predicted by a model of sudden population expansion (Fig. 3a). This prediction was also reflected in positive and non-significant D and Fu’s Fs values (Table 5). These data suggest relatively stable population sizes in D. sinicus. At the group level, populations from the WQ group also stayed stable, revealed by a clearly multimodal pattern in the mismatch distribution analysis (Fig. 3c), in accordance with negative and non-significant D and Fu’s Fs values (Table 5). Thus, the WQ group accorded with the assumptions of neutrality. In contrast, the unimodal mismatch distribution for the TZ group was found to be consistent with the expected distribution in the expansion model (Fig. 3b) and coupled with significantly negative values of D and Fs (Table 5), suggesting possible recent population expansion. Based on the value of τ, the demographic and spatial expansion times of the TZ group were calculated as 11.3 Kya and 20.8 Kya, respectively (Table 5).

Distribution of the number of pairwise nucleotide differences for cpDNA sequence data in: (a) all populations (b) the TZ lineage (c) the WQ lineage of Dendrocalamus sinicus. The green solid line shows observed values, whereas the red dashed line represents expected values under a model of sudden (stepwise) population expansion.
SSR data
For the eight microsatellite loci used in our research, 68.8% population-locus combinations deviated significantly from HWE.
A total of 78 alleles for the eight loci were detected in 232 samples, among which 14 were exclusive (Table 1). Genetic diversity estimates varied among populations and groups (Table 3). Values for numbers of alleles (NA) ranged from 18 to 37, effective numbers of alleles (NE) from 1.88 to 2.97, observed heterozygosity (HO) from 0.375 to 0.567 and expected heterozygosity (HE) from 0.356 to 0.629. Allelic richness (AR) estimates among all populations ranged from 2.25 to 4.40. Inbreeding index values ranged from −0.378 to 0.449, which indicate considerable variation in the intensity of inbreeding among populations (Table 3).
At the species level, total genetic diversity HT = 0.743, and mean genetic diversity within populations HS = 0.567 (Table 4). Diversity estimates for the TZ group (HT = 0.712, HS = 0.572) were a little higher than for the WQ group (HT = 0.636, HS = 0.557). Coefficients of gene differentiation (GST and G’ST) were also calculated in Table 4.
The STRUCTURE analysis showed that Log-likelihood values of the data increased considerably when raising K = 2 (Fig. 4a) and began to flatten out afterwards. Based on the second-order rate of change in values of K (ΔK), the most likely number of genetic clusters for the complete dataset was also estimated at 2. The likelihood Ln (K) averaged over replicates increased with K, and the uptrend reached a plateau after K = 2, suggesting that K = 2 is the probable true number of clusters (Fig. 4b). Although the MedMeaK and MaxMeaK methods suggested K = 5 and 6 to be the best configurations respectively (Fig. S3), our sample collection did not conform to the condition of uneven sample size, and here we have adopted K = 2 to divide clusters.

Bayesian clustering results of the STRUCTURE analysis for nSSR data of 18 populations of Dendrocalamus sinicus (232 individuals). Number of clusters (K) was from one to 10 in 20 independent runs. (a) STRUCTURE-estimated genetic clustering (K = 2, 3, 4, 5, 6), each vertical bar represents an individual and its estimated proportion in K clusters. Black lines separate different populations. Population codes are identified in Table 1. (b) Dot plot representing the mean estimate of Ln posterior probability of data for K = 1–10 (20 replicates), the standard deviation of each mean L(K) value is given as a black vertical line; the pink line represents distribution of ΔK.
Meanwhile, the population-based NJ tree (Fig. 5) also suggested a strong pattern of regional differentiation with a high bootstrap value (99.1%) separating the TZ and WQ groups. Moreover, PCO of the SSR phenotypes of Dendrocalamus sinicus (Fig. S4) separated all individuals from the TZ and WQ groups along the first axis (PCO1, explaining 28.53% of the total variance), and both groups were separated from the central along PCO2 (18.45%).These confirmed the existence of two distinct genetic units corresponding to the Straight-culm and Sinuous-culm lineages, with the exception of a few individuals (Fig. S4).

Neighbor-joining tree representing the genetic relationships among 18 populations of Dendrocalamus sinicus, based on Nei’s (1987) unbiased genetic distance (D) calculated from SSR data. Population codes are identified in Table 1, and branches are color-coded as in Figs 4 and 5. Numbers by nodes are bootstrap values (>50%) from 1000 replicates.
The AMOVA results indicated significant genetic differentiation (FST = 0.306, P < 0.001), with 13.29% of the variation among groups, 17.35% of the variation among populations within groups, and the rest of the variation (69.36%) within populations (Table 2). The results of isolation by distance at the species and regional levels are given in Fig. S5; there is a significant effect of isolation by distance at the species level (R = 0.419, P = 0.003, Fig. S5a) and for the TZ group (R = 0.412, P = 0.007, Fig. S5b). However, this relationship disappeared with respect to the WQ group (R = 0.322, P = 0.273, Fig. S5c).
The BARRIER analysis revealed two possible genetic boundaries; however, the bootstrap support of less than 49.4% (<50%) suggested no significant genetic barriers were detected through the distribution area (Fig. S6).
Bottleneck analysis detected seven population having experienced recent bottleneck effects in both groups (Table S3). Five of them (populations 1, 3, 4, 5, 7) were from the TZ group and the other two (populations 15, 18) were from the WQ group.
Estimations of migration patterns among three regions: the Northern (main distribution of TZ lineage), Southern (main distribution of WQ lineage) and Intermediate regions
The result of the MIGRATE-N analysis indicated that based on cpDNA data, migration rates (with 95% confidence) between the Northern, or Southern, and the Intermediate populations were largely asymmetrical, with migration from the Intermediate populations into the Northern (m = 0.681) or the Southern populations (m = 0.695) typically greater than in the reverse direction (0.617 and 0.623 respectively, Table S4). The estimated number of migration events per generation was 153064 for cpDNA. On the other hand, based on SSR data, the number of migration events per generation estimated was 1827, and migration from the Intermediate populations into the Northern populations (m = 0.469) was greater than in the reverse direction (m = 0.372). However, migration from the Intermediate (m = 0.396) into the Southern populations was lower than in the reverse direction (Table S4). This suggests that populations of Dendrocalamus sinicus can exchange alleles through migration, although it is not to the same extent among different regions. As a whole, migration rates from the Intermediate populations into the Northern or Southern populations were higher than that in the reverse directions.
The migration models test with MIGRATE-N indicated that ancestral gene flow direction was from the Intermediate regions to northern or southern regions based on cpDNA data. However, a full model with two population sizes and two migration rates was supported by SSRs data (Table S5).
Additionally, the pollen-to-seed migration ratio (r = mp/ms) among D. sinicus populations was estimated as 9.89.
Discussion
Genetic structure and differentiation among Dendrocalamus sinicus populations
At the species level, Dendrocalamus sinicus shows high total genetic diversity represented by HT = 0.497 (cpDNA) and 0.743 (SSR), and the mean genetic diversity among populations is much higher than that within populations (Table 4). The results of the NJ tree, Bayesian clustering and PCO analysis based on SSR genotyping also indicated that the species has differentiated into two distinct groups: the TZ group (red coded in Figs 4, 5 and S5) and WQ group (green coded). The two markers both revealed the same split into two groups corresponding with distinct culm morphological differences. The total genetic diversity of the WQ group is obviously higher than that of the TZ group based on cpDNA and SSR data (Tables 2 and 4), which is consistent with results of Li et al.26. It is worth noting an obvious discordance between the two data sets (Tables 2 and 4). For the SSR data, there was 13.29% of variation between the two groups, whereas the extent was 93.13% in cpDNA. This conflict may provide us an insight into the demographic history of D. sinicus. Non-recombinant cpDNA allows an inference of historical range shift and recolonization routes27,28, unlike SSR markers which can reveal more on contemporary gene flow between populations20.
At the group level, a pronounced phylogeographic structure was also uncovered by the genetic differential coefficient within the WQ group and the total populations based on cpDNA data (Table 4), implying a long period of genetic and geographic isolation among D. sinicus populations. In addition, the SSR data detected positive isolation by distance among all populations and within the TZ group (Fig. S5), which was in accord with the breeding system and pollination characteristics of this species29, i.e., highly restricted pollen transmission and seed dispersal among populations under natural conditions, especially within the WQ group. In nature, the populations of D. sinicus only disperse over relatively short distances with limited seed dispersal16,17.
On the other hand, the genetic differentiation of D. sinicus populations (GST = 0.787, Table 4) is larger than the average genetic differentiation in angiosperms using maternally inherited markers (GST = 0.637)30, implying lack of seed transmission among D. sinicus populations. With biparentally inherited markers, the detected genetic differentiation (GST = 0.237) of D. sinicus was slightly less than D. membranaceus (GST = 0.252)31, and far less than D. giganteus (GST = 0.847) and D. brandisii (GST = 0.842)32. The different results from plastid and nuclear DNA imply that the pollen transmission may far exceed seed dispersal in the sexual reproduction of D. sinicus17.
Moreover, the pollen-to-seed migration ratio (r = mp/ms) estimated among populations of D. sinicus (r = 9.89) was much less than the average among Angiosperms and Conifers assessed (mean = 17)30. The contemporary probability of hybrids between the TZ and WQ groups in the wild would appear to be minimal. During the last c. 30 years, sporadic flowering and seed set in TZ populations of D. sinicus have been observed in natural populations in southern Yunnan, whereas sporadic flowering was rare with almost no seed set among WQ populations17,33. Our own observations of several flowering clumps of D. sinicus in the wild showed that their flowering times were not synchronous, which could explain a lack of pollination and seed set29. What is more important is that, based on cpDNA and SSR data, both groups of D. sinicus showed significant genetic differentiation which was consistent with geographic isolation.
Lineage divergence and demographic history
Lineage divergence and demographic history can provide insight into the speciation process18,19,20. The SAMOVA analysis (Fig. S2), tree topology (Fig. 2a) and network analysis (Fig. 2b) of cpDNA data are consistent with the hypothesis that Dendrocalamus sinicus was initially split into two lineages, i.e., the Straight-culm and Sinuous-culm lineages. Among 18 extant populations, a total of 11 populations (61.1%) possessed at least one exclusive haplotype or allele (Table 1), indicating a long period of isolation between populations. AMOVA analysis of cpDNA shows 93.13% variation between groups. Meanwhile, there were five mixed populations (with haplotypes from both lineages) based on cpDNA data, with four of them (populations 9, 12, 13 and14) from the intermediate area between the main localities of the lineages, and one (population 16) located in the southernmost area. The results of bidirectional migration rates analyses (Table S4) showed that the main migration directions were from the intermediate area to the north and south parts of its distribution, which indicated that the intermediate area of the two lineages may be the center of origin of D. sinicus. Interestingly, populations 13 and 16, separated by 178.4 km in distance and the Lancang-Mekong River, shared a rare chloroplast haplotype H5 which clustered in the Straight-culm lineage (Table 1, Fig. 2a). Seed exchange between these two populations under natural conditions seems impossible, so a possible explanation may be either human-mediated introduction which allowed secondary contact between the two lineages16.
The records of the Guliya ice core indicated that the Younger Dryas cooling event affecting most areas of the Northern Hemisphere ended around 10.9 Kya ~ 10.8 Kya BP, marking the end of the last glacial period and passage into the Holocene34. The mismatch distribution test and neutrality test of D. sinicus populations both detected expansion within the Straight-culm lineage (Fig. 3, Table 5), with an estimated time around 11.3 Ka (under the demographic expansion model), which on the whole kept the same step with the end of the Younger Dryas cooling event. It may be a result that the Straight-culm lineage which occurred in cool areas can adapt to the warmer area in the south, while the Sinuous-culm lineage may not be able to survive with a relatively cooler climate at higher latitudes in the northern area of its distribution16.
Evolutionary and speciation implications
In the present study, a strong phylogeographic structure across the distribution range of Dendrocalamus sinicus, with the Straight-culm and Sinuous-culm lineages, has been confirmed through phylogenetic analyses of cpDNA and SSR variation. By and large, the distribution areas of this species are divided into three regions, namely the northern, the southern and the intermediate regions (Fig. 1). The migration model analyses using MIGRATE-N indicated that ancestral gene flow direction was mainly from the Intermediate regions to northern or southern regions based on CpDNA data (Tables S4 and S5). Meanwhile, almost all private haplotypes occurred at the Intermediate regions (Table 1, Fig. 2), and the genetic diversity within the northern (main part of TZ group) and southern populations (main part of WQ group) were much lower than that of the populations from the Intermediate regions (Tables 3 and 4), suggesting that the Intermediate region is a diversity center of this species and a founder effect existing within the TZ group.
Reviewing the geological and biogeological events associated with the distribution area of D. sinicus, we found that the geological conditions of this area have been stable since the late Tertiary35,36,37, and there is no large river and mountain barrier between the distribution areas38. Furthermore, no strong genetic barrier was detected using SSR data (Fig. S5) in this study, which indicated no obvious geographical condition for vicariance speciation in D. sinicus. Recent phylogenetic study of the flora of southern Yunnan also illustrated that geological changes and associated dispersals across biomes have existed since the late Tertiary37. Meanwhile, hybridization between two culm-shape lineages has not been observed in different variants in the past thirty years16,17,33.
To sum up, the relatively independent distribution areas of different culm-shape types of D. sinicus shows that this bamboo species is experiencing a process of dispersal speciation, which provides a good case for studying speciation among woody bamboos. Therefore, these results imply that the overall extant genetic diversification of D. sinicus could be due to long distance dispersal, rather than vicariance. The modern distribution pattern of two culm types is probably the result of different altitude and latitude conditions associated with populations of two lineages, respectively (Table 1).
Materials and Methods
Plant material sampling
We collected leaf samples from 232 individuals (clumps) of 18 populations covering the entire geographic range of Dendrocalamus sinicus (Fig. 1, Table 1). Nine to 16 individuals/clumps at least 100 m apart from each other were sampled in each population. Employing the concept of McClure39, we treated each clump as a potential genet and the culms within as ramets of a clone, and we assumed that an assortment of genetic material existed within each population. Fully developed leaves collected for DNA extraction were rapidly dried and preserved in silica gel. Vouchers for each population were deposited at the Herbarium of the Research Institute of Resources Insects, Chinese Academy of Forestry. Dendrocalamus latiflorus was chosen as outgroup in the cpDNA haplotypes analysis, based on previous phylogenetic study40.
Laboratory procedures
We extracted genomic DNA using a modified 4x cetyltrimethyl ammonium bromide (CTAB) extraction protocol41. Three cpDNA intergenic spacer regions with rich information, i.e., rpl32-trnL, rbcL-psaI and trnG-trnT, were chosen for sequencing based on Zhang et al.42. The 20 µl PCR mix contained 10 µl 2× PCR buffer including KCl2 (100 mM), MgCl2 (3 mM), dNTP mixture (0.5 mM), Taq polymerase (0.1 Uµl−1), TrisCl (20 mM, PH = 8.3) (Transgen, Beijing, China), as well as 1 µl each primer (5 µM), 1 µl template DNA (c. 30–50 ng genomic DNA), and finally 7 µl distilled deionized water. Polymerase Chain Reactions (PCR) were performed on a Veriti 96 WellThermal Cycler (Applied Biosystems, Foster City, California, USA). The cycling conditions were template denaturation at 97 °C for 3 min followed by 32 cycles of 94 °C for 40 s, 52 °C for 40 s, 72 °C for 1 min, and a final step of 72 °C for 7 min.
PCR products were visualized on 1% TAE agarose gels and then purified using a Sangon Purification Kit (Sangon, Shanghai, China). The purified products were used for bi-directional sequencing using the PCR primers and the PRISM Dye Terminator Cycle Sequencing Ready Reaction Kit (Applied Biosystems, Foster City, CA, USA). The products were run on an ABI 3730 xl DNA Sequencer. All sequences were deposited in GenBank under accession numbers KP213841- KP213854, and KP289037- KP289039 (Table S2).
Eight pairs of nSSR markers with higher genetic information, i.e., Den005, Den007, Den033, Den034, Den036, Den058, Den075 and Den09643, were selected to detect the genetic divergence among 18 populations of Dendrocalamus sinicus. Loci selected for this study have only one or two alleles among all the genotyped individuals. PCRs for the microsatellites were performed separately for each locus in 20 µl volumes with 8.8 µl ddH2O, 0.6 µl of DNA extract, 0.3 µl of each fluorescently labelled primer and 10 µl 2× Taq PCR MasterMix (Transgen, Beijing, China), which comprised of 0.5 mM dNTPs, 100 mM KCl, 3 mM MgCl2 and 1 U HotStar Taq. PCR thermal cycling conditions were 3 min denaturation at 94 °C, 35 cycles of 30 s denaturation at 94 °C, 40 s annealing at 48 °C (Den058), 50 °C (Den033 and Den036), 52 °C (Den034, Den075 and Den096) or 61 °C (Den006 and Den007), 50 s extension at 72 °C and a single 7 min extension step at 72 °C. PCR products were scanned with QIAxcel Capillary Gel Electrophoresis (QIAGEN, Irvine, USA). Fragment sizes were determined using QIAxcel BioCaculator and analyzed with the software GenALEx version 6.444.
Chloroplast DNA analysis
We assembled and edited sequences in Sequencher version 4.1.4 (Gene Codes Corporation, Ann Arbor, Michigan, USA). Multiple alignments of sequences and subsequent manual adjustments were obtained using Geneious Pro version 4.8.545. The inversions were treated as indels according to Simmons & Ochoterena46. The matrix of combined cpDNA sequences was constructed for the following analysis since the cpDNA in plants generally do not recombine47.
All the combined cpDNA sequences were assigned to different haplotypes using DNASP version 5.1048, and relatedness between haplotypes were constructed using TCS program version 1.2125 with 95% statistical parsimony criteria. We investigated the distribution of the number of pairwise nucleotide differences for cpDNA sequence data according to the method of Rogers & Harpending49.
Phylogenetic relationships between haplotypes of Dendrocalamus sinicus were analyzed using Maximum Parsimony (MP) in PAUP* version 4.0 beta 1050 with D. latiflorus as outgroup. We initially use a Modeltest version 3.751 based on hierarchical Likelihood Ratio Tests (hLRTs) to find a best-fitting model applied to Bayesian Inference analysis. We performed full heuristic tree searches with 1000 random stepwise addition, using the TBR branch swapping, ‘MulTrees’ options. To assess the bootstrap supports, we used 1000 replicates. We also calculated Bayesian posterior probabilities using the software program MrBayes version 3.1.252 with a Monte Carlo Markov Chain (MCMC) length of 2 × 106 generations.
To identify clusters of genetically similar populations, we ran a spatial analysis of molecular variance (SAMOVA) in SAMOVA 1.053 using K = 2–9, and chose the number of groups that gave the highest FCT, or the number of groups for which FCT began to plateau54. We excluded configurations with one or more single-population groups, because this indicates that the group structure is disappearing55. To partition variations within and among defined groups and populations, we performed analysis of molecular variance (AMOVA) using ARLEQUIN version 3.056.
Molecular diversity indices, including the number of haplotypes, haplotype diversity (Hd) and nucleotide diversity (π), were estimated using DNASP version 5.10. The existence of phylogeographic structure was tested following Pons & Petit57. Mean genetic diversity within populations (HS), total genetic diversity (HT), genetic differentiation (GST), and genetic differentiation considered as genetic distance between haplotypes (NST), were obtained using PERMUT version 1.0 (http://www.pierroton.inra.fr/genetics/labo/Software/). A permutation approach was used to test the significance of the differences between GST and NST27 with the same program.
To investigate evidence of recent population expansion, we tested the null hypothesis of spatial expansion using mismatch distribution analysis. The goodness-of-fit was tested with the sum of squared deviations (SSD) between observed and expected mismatch distributions48 and Harpending’s raggedness index58 (HRag), using a parametric bootstrap approach59 with 1000 replicates in Arlequin. We constructed the mismatch distributions of pairwise genetic differences in each group using Dnasp. For the expanding population group identified, we used the formula t = τ/2 u to estimate the time since expansion began. Values for u were calculated as u = μkg, where μ is the number of substitutions per site per year (s/s/y), k is the average sequence length of the cpDNA region under study, and g is the generation time in years. The paleotropical bamboos diversified from an estimated ca. 15 Mya and followed by rapid radiation within the lineages11. We adopted the overall synonymous substitution rate of cpDNA in palaeotropical woody bamboos, 9.03 × 10−10 s/s/y, as the value of μ60. The value for k was 1947 bp, and 76 years was used as an approximation for generation time according to Janzen’s record of Dendrocalamus giganteus61. We also used Fu’s FS62 and Tajima’s D63 test of selective neutrality to infer demographic history of all populations as well as each group. We estimate the statistical significance by performing 1000 random permutations in Arlequin.
Microsatellite data analysis
The Hardy-Weinberg equilibrium (HWE) for each population and each locus was tested in FASTAT version 2.9.3.264. We calculated the number of alleles (NA), private alleles (NP), effective number of alleles (NE), expected heterozygosity (HE), and observed heterozygosity (HO), for each population and group in GenALEx. FSTAT was used to estimate Allelic richness (AR), inbreeding index (FIS), total genetic diversity (HT), genetic differentiation based on the allelic frequencies (GST), and the standardized measure of genetic differentiation (G’ST).
To reveal the phylogenetic relationships among populations, we generated a neighbour-joining (NJ) tree with bootstrap values inferred from 1000 replicates using the program PHYLIP version 3.665, based on Nei’s genetic distance66 (D) among all pairs of populations estimated in the procedure MSA version 4.0567. A further analysis of population genetic admixture was taken in STRUCTURE version 2.368 to conduct a Bayesian analysis at eight SSR loci. For K = 1 to 10, we performed 20 independent runs for 105 iterations after a burn-in period of 105 with no prior information on the origin of individuals. The combination of ‘admixture’ and ‘allele frequencies correlated’ model was used for the analysis. To determine the most probable value of K, we chose the corrected DeltaK method described by Evanno et al.69, corrected posterior probability method68, the MedMeaK and the MaxMeaK methods described by Puechmaille70. All the analyses were completed using Kestimator V.1.1270. For each K, ΔK was computed based on absolute value of the second-order rate of change of the likelihood distribution. STRUCTURE results were displayed with the software Distruct version 1.171. To gain a clearer view of genetic clusters, we conducted a principal coordinate (PCO) analysis among all 232 individuals in the program GenAlEx44.
Analysis of molecular variance (AMOVA) was performed to assess the genetic differentiation among groups and between populations within groups (identified by phylogenetic analyses) using the program Arlequin 3.056. To detect isolation by distance and evaluate the relative influences of gene flow and drift on the population structure at both the species and group levels, we conducted a Mantel test between matrices of pairwise genetic distance (calculated by Arlequin) and geographic distance obtained (calculated by GenAlEx) with 999 random permutations in GenAlEx. We used the BARRIER program version 2.272 to identify geographical locations where major genetic barriers among populations occurred based on 1000 Nei’s genetic distance matrices. The input files for the BARRIER analysis were from two parts— the X/Y coordinates of the original points (locations of the sampled populations) and genetic distance matrix with 100 replications calculated by MSA 4.05.
Finally, to test if the populations had experienced recent historical population declines, we used the program Bottleneck 1.2.0273 to examine the deviation from mutation-drift equilibrium. We chose the two-phase model (TPM) and Wilcoxon test based on the type of molecular marker and the number of loci.
Estimation on migration patterns among the Northern, Southern and intermediate distribution areas of Dendrocalamus sinicus
To detect the bidirectional migration rates between different extant distributions of D. sinicus, we divided its 18 extant populations into three regions: the Intermediate (including populations 9, 12–14), Northern (main distribution of TZ lineage, including populations 1–8, 10 and 11, named the TZ’ region in Table S4) and Southern (main distribution of WQ lineage, including populations 15–18, named the WQ’ region in Table S4) regions based on distributional geography and haploid composition. The bidirectional migration rates among the three areas were estimated using the program MIGRATE-N 3.6.1174. A full model with two migration rates (gene flow in and out of the populations) M = m/μ, where m is the immigration rate per generation among populations and μ is the mutation rate per generation per locus, was evaluated with this program. The model comparison was done using Bayes factors that need the accurate calculation of marginal likelihoods. These likelihoods were calculated using thermodynamic integration in MIGRATE-N 3.6.11. We also used Migrate-N to test the relative support for different migration models to address specific dispersal hypotheses. The probability of four models were evaluated using marginal likelihoods and Bayes factors74: (1) a full model with two population sizes and two migration rates (from population A to population B and from B to A), (2) a model with two population sizes and one migration rate to A, (3) a model with two population sizes and one migration rate to B, (4) a model where A and B are part of the same panmictic population. All other settings were at default values except the increment between samples placed at 1,000; samples per replicate was set at 10,000; and burn-ins per replicate were set at 50,000,000, and 1,000 replicates.
The pollen-to-seed migration ratio (r = mp/ms) was calculated following the formula according to Petit et al.30.
References
Bamboo Phylogeny Group. An updated tribal and subtribal classification for the Bambusoideae (Poaceae). In: Process of the 9 th World Bamboo Congress. (eds Gielis, J. & Potters, G.) 3–27 (World Bamboo Organization Antwerp Belgium, 2012).
Li, D. Z. & Stapleton, C. Bambuseae. In: Flora of China (Volume 9, Poaceae) (eds Wu, Z. Y., Raven, P. H. & Hong, D. Y.) 1–180 (Science Press Beijing & Missouri Botanic Garden Press St. Louis USA, 2006).
Sun, M. S., Yan, B., Xu, T. & Yu, L. X. Resources and Utilization of Bamboo Plants 1–34 (Science Press Beijing, 2015).
Wysocki, W. P., Clark, L. G., Attigala, L., Ruiz-Sanchez, E. & Duvall, M. R. Evolution of the bamboos (Bambusoideae; Poaceae): a full plastome phylogenomic analysis. BMC Evolutionary Biology 15, 50, https://doi.org/10.1186/s12862-015-0321-5 (2015).
Goh, W. L. et al. Multi-gene region phylogenetic analyses suggest reticulate evolution and a clade of Australian origin among paleotropical woody bamboos (Poaceae: Bambusoideae: Bambuseae). Plant Systematics and Evolution 299(1), 239–257, https://doi.org/10.1007/s00606-012-0718-1 (2013).
Wang, L. et al. The earliest fossil bamboos of China (middle Miocene, Yunnan) and their biogeographical importance. Review of Palaeobotany and Palynology 197, 253–265, https://doi.org/10.1016/j.revpalbo.2013.06.004 (2013).
Guo, Z. H. & Li, D. Z. Advances in the systematics and biogeography of the Bambusoideae (Gramineae) with remarks on some remaining problems. Acta Botanica Yunnanica 24 ( 4 ), 431–438, doi: 0253-2700(2002)04-0307-08 (2002).
Segherloo, I. H. et al. Genetic and morphological support for possible sympatric origin of fish from subterranean habitats. Scientific Reports 8, 2909, https://doi.org/10.1038/s41598-018-20666-w (2018).
Triplett, J. K., Oltrogge, K. A. & Clark, L. G. Phylogenetic relationships and natural hybridization among the North American woody bamboos (Poaceae: Bambusoideae: Arundinaria). American Journal of Botany 97(3), 471–492, https://doi.org/10.3732/ajb.0900244 (2010).
Triplett, J. K., Clark, L. G., Fisher, A. E. & Wen, J. Independent allopolyploidization events preceded speciation in the temperate and tropical woody bamboos. New Phytologist 204(1), 66–73, https://doi.org/10.1111/nph.12988 (2014).
Zhang, X. Z. et al. Multi-locus plastid phylogenetic biogeography supports the Asian hypothesis of the temperate woody bamboos (Poaceae: Bambusoideae). Molecular Phylogenetics and Evolution 96, 118–129, https://doi.org/10.1016/j.ympev.2015.11.025 (2016).
Wong, K. M. & Low, Y. W. Hybrid zone characteristics of the intergeneric hybrid bamboo × Gigantocalamus malpenensis (Poaceae: Bambusoideae) in Peninsular Malaysia. Gardens’ Bulletin Singapore 63(1 & 2), 375–383 (2011).
Wiley, E. O. Parsimony Analysis and Vicariance Biogeography. Systematic Zoology 37(3), 271–290, https://doi.org/10.1093/sysbio/37.3.271 (1988).
Wu, Z. Y., Lu, A. M., Tang, Y. C., Chen, Z. D. & Li, D. Z. The families and genera of Angiosperms in China, pp. 322–328 (Science Press, Beijing, 2003).
Li, H. J. The biggest bamboo on Earth—Dendrocalamus sinicus. Bamboo 32(6), 5 (2011).
Hui, C. M., Yang, Y. M. & Du, F. Biological characters, development and utilization of rare bamboo species, Dendrocalamus sinicus. 1–12 (Yunnan Science and Technology Publishers Kunming China, 2006).
Gu, Z. J., Yang, H. Q., Sun, M. S. & Yang, Y. M. Distribution characteristics, flowering and seeding of Dendrocalamus sinicus in Yunnan, China. Forest Research 25 ( 1 ), 1–5, doi: 1001-1498(2012)01-0001-05 (2012).
Bai, W. N., Liao, W. J. & Zhang, D. Y. Nuclear and chloroplast DNA phylogeography reveal two refuge areas with asymmetrical gene flow in a temperate walnut tree from East Asia. New Phytologist 188(3), 892–901, https://doi.org/10.1111/j.1469-8137.2010.03407.x (2010).
Yan, H. F. et al. Population expanding with the phalanx model and lineages split by environmental heterogeneity: a case study of Primula obconica in subtropical china. PLoS ONE 7(9), e41315, https://doi.org/10.1371/journal.pone.0041315 (2012).
Liu, J. et al. Geological and ecological factors drive cryptic speciation of yews in a biodiversity hotspot. New Phytologist 199(4), 1093–1108, https://doi.org/10.1111/nph.12336 (2013).
Ma, P. F., Zhang, Y. X., Guo, Z. H. & Li, D. Z. Evidence for horizontal transfer of mitochondrial DNA to the plastid genome in a bamboo genus. Scientific Reports 5, 11608, https://doi.org/10.1038/srep11608 (2015).
Li, H. L. et al. Large-scale phylogenetic analyses reveal multiple gains of actinorhizal nitrogen-fixing symbioses in angiosperms associated with climate change. Scientific Reports 5, 14023, https://doi.org/10.1038/srep14023 (2015).
Zhao, H. S. et al. Developing genome-wide microsatellite markers of bamboo and their applications on molecular marker assisted taxonomy for accessions in the genus. Phyllostachys. Scientific Reports 5, 8018, https://doi.org/10.1038/srep08018 (2015).
Pauwels, M. et al. Nuclear and chloroplast DNA phylogeography reveals vicariance among European populations of the model species for the study of metal tolerance, Arabidopsis halleri (Brassicaceae). New Phytologist 193(4), 916–928, https://doi.org/10.1111/j.1469-8137.2011.04003.x (2012).
Clement, M., Posada, D. & Crandall, K. A. TCS: a computer program to estimate gene genealogies. Molecular Ecology 99(10), 1657–1659, https://doi.org/10.1046/j.1365-294x.2000.01020.x (2000).
Li, P., Du, F., Pu, X. L. & Yang, Y. M. RADP analysis of different variant types of Dendrocalamus sinicus. Acta Botanica Yunnanica 26 ( 3 ), 290–296, doi: 0253-2700(2004)03-0290-07 (2004).
Petit, R. J. et al. Identification of refugia and post-glacial colonization routes of European white oaks based on chloroplast DNA and fossil pollen evidence. Forest Ecology and Management 156(1-3), 49–74, https://doi.org/10.1016/S0378-1127(01)00634-X (2002).
Petit, R. J. et al. Glacial refugia: hotspots but not melting pots of genetic diversity. Science 300(5625), 1563–1565, https://doi.org/10.1126/science.1083264 (2003).
Chen, L. N., Cui, Y. Z., Wong, K. M., Li, D. Z. & Yang, H. Q. Breeding system and pollination of two closely related bamboo species. AoB PLANTS 9(3), plx021, https://doi.org/10.1093/aobpla/plx021 (2017).
Petit, R., Duminil, J., Fineschi, S. A., Salvini, D. & Vendramin, G. Comparative organization of chloroplast, mitochondrial and nuclear diversity in plant populations. Molecular Ecology 14(3), 689–701, https://doi.org/10.1111/j.1365-294X.2004.02410.x (2005).
Yang, H. Q., An, M. Y., Gu, Z. J. & Tian, B. Genetic diversity and differentiation of Dendrocalamus membranaceus (Poaceae: Bambusoideae), a declining bamboo species in Yunnan, China, as based on Inter-Simple Sequence Repeat (ISSR) analysis. International Journal of Molecular Sciences 13(4), 4446–4457, https://doi.org/10.3390/ijms13044446 (2012).
Yang, H. Q., Sun, M. S., Ruan, Z. Y., Dong, Y. R. & Liang, N. Study on provenance differentiation of four typical tropical clump bamboos in Yunnan, China. Forest Research 27 ( 2 ), 168–173, doi: 1001-1498(2014)02-0168-06 (2014).
Du, F., Xue, J. R., Yang, Y. M., Hui, C. M. & Wang, J. Study on flowering phenomenon and its type of bamboo in Yunnan in past fifteen years. Scientia Silvae Sinicae 36(6), 57–68, https://doi.org/10.11707/j.1001-7488.20000616 (2000).
Shi, Y. F., Li, J. J. & Li, B. Y. Uplift and Environmental Changes of Qinghai-Tibetan Plateau in the Late Cenozoic (Guangdong Science and Technology Press Guangzhou, 1998).
Yunnan Geology and Mineral Bureau. Atlas of geology and palaeogeography of Yunnan. 1–228 (Yunnan Science & Technology Press Kunming China, 1995).
Metcalfe, I. Palaeozoic and Mesozoic tectonic evolution and palaeogeography of East Asian crustal fragments: The Korean peninsula in context. Gondwana Research 9, 24–46 (2006).
Liu, S. Y., Zhu, H. & Yang, J. A phylogenetic perspective on biogeographical divergence of the flora in Yunnan, Southwestern China. Scientific Reports 7, 43032, https://doi.org/10.1038/srep43032 (2017).
Tapponnier, P. et al. The Ailao Shan/Red River metamorphic belt: Tertiary left-lateral shear between Indochina and South China. Nature 343, 431–437 (1990).
McClure, F. A. The Bamboos, a Fresh Perspective. (Harvard University Press MA USA, 1966).
Yang, H. Q. et al. A molecular phylogenetic and fruit evolutionary analysis of the major groups of the paleotropical woody bamboos (Gramineae: Bambusoideae) based on nuclear ITS, GBSSI gene and plastid trnL-F DNA sequences. Molecular Phylogenetics and Evolution 48(3), 809–824, https://doi.org/10.1016/j.ympev.2008.06.001 (2008).
Doyle, J. J. & Doyle, J. L. A rapid DNA isolation procedure for small quantities of fresh leaf material. Phytochemical Bulletin 19, 11–15 (1987).
Zhang, Y. J., Ma, P. F. & Li, D. Z. High-throughput sequencing of six bamboo chloroplast genomes: phylogenetic implications for temperate woody bamboos (Poaceae: Bambusoideae). PLoS ONE 6(5), e20596, https://doi.org/10.1371/journal.pone.0020596 (2011).
Dong, Y. R., Zhang, Z. R. & Yang, H. Q. Sixteen novel microsatellite markers developed for Dendrocalamus sinicus (Poaceae), the strongest woody bamboo in the world. American Journal of Botany 99(9), e347–e349, https://doi.org/10.3732/ajb.1200029 (2012).
Peakall, R. & Smouse, P. E. GENALEX 6: genetic analysis in Excel: population genetic software for teaching and research. Molecular Ecology Note 6(1), 288–295, https://doi.org/10.1111/j.1471-8286.2005.01155.x (2006).
Drummond, A. J., Nicholls, G. K., Rodrigo, A. G. & Solomon, W. Estimating mutation parameters, population history and genealogy simultaneously from temporally spaced sequence data. Genetics 161(3), 1307–1320 (2002).
Simmons, M. P. & Ochoterena, H. Gaps as characters in sequence-based phylogenetic analyses. Systematic Biology 49(2), 369–381, https://doi.org/10.1093/sysbio/49.2.369. (2000).
Reboud, X. & Zeyl, C. Organelle inheritance in plants. Heredity 72, 132–140, https://doi.org/10.1038/hdy.1994.19 (1994).
Librado, P. & Rozas, J. DnaSP v5: a software for comprehensive analysis of DNA polymorphism data. Bioinformatics 25(11), 1451–1452, https://doi.org/10.1093/bioinformatics/btp187 (2009).
Rogers, A. R. & Harpending, H. Population growth makes waves in the distribution of pairwise genetic differences. Molecular Biology and Evolution 9(3), 552–569 (1992).
Swofford, D. L. PAUP. Phylogenetic Analysis Using Parsimony (*and other methods), Version 4.0b10. (Sinauer Associates Sunderland Massachusetts, 2002).
Posada, D. & Crandall, K. A. MODELTEST: testing the model of DNA substitution. Bioinformatics 14(9), 817–818, https://doi.org/10.1093/bioinformatics/14.9.817 (1998).
Ronquist, F. & Huelsenbeck, J. P. MrBayes 3: Bayesian phylogenetic inference under mixed models. Bioinformatics 19(12), 1572–1574, https://doi.org/10.1093/bioinformatics/btg180 (2003).
Dupanloup, I., Schneider, S. & Excoffier, L. A simulated annealing approach to define the genetic structure of populations. Molecular Ecology 11(12), 2571–2581, https://doi.org/10.1046/j.1365-294X.2002.01650.x (2002).
Gugger, P. F., Sugita, S. & Cavender-Bares, J. Phylogeography of Douglas-fir based on mitochondrial and chloroplast DNA sequences: testing hypotheses from the fossil record. Molecular Ecology 19(9), 1877–1897, https://doi.org/10.1111/j.1365-294X.2010.04622.x (2010).
Magri, D. et al. A new scenario for the Quaternary history of European beech populations: palaeobotanical evidence and genetic consequences. New Phytologist 171(1), 199–221, https://doi.org/10.1111/j.1469-8137.2006.01740.x (2006).
Excoffier, L., Laval, G. & Schneider, S. Arlequin (version 3.0): an integrated software package for population genetics data analysis. Evolutionary Bioinformatics Online 1, 47–50 (2005).
Pons, O. & Petit, R. J. Measuring and testing genetic differentiation with ordered versus unordered alleles. Genetics 144(3), 1237–1245 (1996).
Harpending, H. C. Signature of ancient population growth in a low-resolution mitochondrial DNA mismatch distribution. Human Biology 66(4), 591–600 (1994).
Schneider, S. & Excoffier, L. Estimation of past demographic parameters from the distribution of pairwise differences when the mutation rates very among sites: application to human mitochondrial DNA. Genetics 152(3), 1079–1089 (1999).
Wu, M. et al. The Complete Chloroplast Genome of Guadua angustifolia and Comparative Analyses of Neotropical-Paleotropical Bamboos. PloS one 10(12), e0143792, https://doi.org/10.1371/journal.pone.0143792 (2015).
Janzen, D. H. Why bamboos wait so long to flower. Annual Review of Ecology and Systematics 7, 347–391 (1976).
Fu, Y. X. Statistical tests of neutrality of mutations against population growth, hitchhiking and background selection. Genetics 147(2), 915–925 (1997).
Tajima, F. Statistical-method for testing the neutral mutation hypothesis by DNA polymorphism. Genetics 123(3), 585–595 (1989).
Goudet, J. FSTAT, a program to estimate and test gene diversities and fixation indices (version 2.9.3.2). Available at, http://www2.unil.ch/izea/sotwares/fstat.html 16/8/2015 (Université de Lausanne, 2002).
Felsenstein, J. PHYLIP (Phylogeny Infrence Package) Version 3.6. (Department of Genome Sciences University of Washington Seattle WA, 2005).
Nei, M., Tajima, F. & Tateno, Y. Accuracy of estimated phylogenetic trees from molecular data. Journal of Molecular Evolution 19, 153–170, https://doi.org/10.1007/BF02300753 (1983).
Dieringer, D. & Schlotterer, C. Microsatellite analyser (MSA): a platformindependent analysis tool for large microsatellite data sets. Molecular Ecology Notes 3(1), 167–169, https://doi.org/10.1046/j.1471-8286.2003.00351.x (2003).
Pritchard, J. K., Stephens, M. & Donnelly, P. Inference of population structure using multilocus genotype data. Genetics 155(2), 945–959 (2000).
Evanno, G., Regnaut, S. & Goudet, J. Detecting the number of clusters of individuals using the software STRUCTURE: a simulation study. Molecular Ecology 14(8), 2611–2620, https://doi.org/10.1111/j.1365-294X.2005.02553.x (2005).
Puechmaille, S. J. The program structure does not reliably recover the correct population structure when sampling is uneven: Subsampling and new estimators alleviate the problem. Molecular Ecology Resources 16(3), 608–627, https://doi.org/10.1111/1755-0998.12512 (2016).
Rosenberg, N. A. Distruct: a program for the graphical display of population structure. Molecular Ecology Notes. 4(1), 137–138, https://doi.org/10.1046/j.1471-8286.2003.00566.x (2004).
Manni, F., Guerard, E. & Heyer, E. Geographic patterns of (genetic, morphologic, linguistic) variation: how barriers can be detected by using Monmonier’s algorithm. Human Biology 76(2), 173–190, https://doi.org/10.1353/hub.2004.0034 (2004).
Cristescu, R., Sherwin, W. B., Handasyde, K., Cahill, V. & Cooper, D. W. Detecting bottlenecks using BOTTLENECK 1.2.02 in wild populations: the importance of the microsatellite structure. Conservation Genetics 11(3), 1043–1049, https://doi.org/10.1007/s10592-009-9949-2 (2010).
Beerli, P. & Palczewski, M. Unified framework to evaluate panmixia and migration direction among multiple sampling locations. Genetics. 185(1), 313–326, https://doi.org/10.1534/genetics.109.112532 (2010).
Acknowledgements
The authors thank two anonymous reviewers for their valuable comments and suggestions, and thank Zhirong Zhang and Dr. Lianming Gao (Kunming Institute of Botany, Chinese Academy of Sciences) for their help in laboratory work and data analyses. The research was supported by the Fundamental Research Funds of the Chinese Academy of Forestry, CAF (CAFYBB2017ZX001-8), the National Natural Science Foundation of China (31270662, 31070593), Department of Sciences and Technology of Yunnan Province (2014HB041, 2008OC001) and Research Institute of Resources Insects (riricaf2012005M).
Author information
Authors and Affiliations
Contributions
J.-B.Y., Y.-R.D. and Z.-J.G. conducted molecular laboratory work, analyzed the data; J.-B.Y., Y.-R.D., K.-M.W. and H.-Q.Y. wrote the paper; H.-Q.Y. and D.-Z.L. conceived the experiments; Z.-J.G. and H.-Q.Y. collected the samples.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, J.B., Dong, Y.R., Wong, K.M. et al. Genetic structure and differentiation in Dendrocalamus sinicus (Poaceae: Bambusoideae) populations provide insight into evolutionary history and speciation of woody bamboos. Sci Rep 8, 16933 (2018). https://doi.org/10.1038/s41598-018-35269-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-35269-8
Keywords
This article is cited by
-
Genetic diversity assessed in Ethiopian highland bamboo [Oldeania alpina (K. Schum) Stapleton] populations revealed by microsatellite markers
CABI Agriculture and Bioscience (2024)
-
Genome-wide discovery of single- and multi-locus simple sequence repeat markers and their characterization in Dendrocalamus strictus: a commercial polyploid bamboo species of India
Genetic Resources and Crop Evolution (2023)
-
Ecological niche modelling and population genetic analysis of Indian temperate bamboo Drepanostachyum falcatum in the western Himalayas
Journal of Plant Research (2023)
-
Population genetic analysis illustrated a high gene diversity and genetic heterogeneity in Himalayacalamus falconeri: a socio-economically important Indian temperate woody bamboo taxon
Journal of Plant Biochemistry and Biotechnology (2023)
-
Genome survey sequencing-based SSR marker development and their validation in Dendrocalamus longispathus
Functional & Integrative Genomics (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
