
Abstract
Human communication is commonly represented as a temporal social network, and evaluated in terms of its uniqueness. We propose a set of new entropy-based measures for human communication dynamics represented within the temporal social network as event sequences. Using real world datasets and random interaction series of different types we find that real human contact events always significantly differ from random ones. This human distinctiveness increases over time and by means of the proposed entropy measures, we can observe sociological processes that take place within dynamic communities.
Similar content being viewed by others

Introduction
Despite living in social communities and witnessing people communicate, at the first glance, we may not recognize clear patterns or trends of dynamic changes in communication – the general impression may be that people interact almost randomly. Even though many studies1,2,3,4 show that human interactions are not random, still some vital questions need to be addressed such as how specific and how stable over time are they? Additionally, communication traces are the main source for interactions represented by social networks5, hence, the questions about communication dynamics simultaneously address the problem of stability of temporal networks.
Despite the fact that temporal social networks have been studied for several years, there is no fixed and commonly agreed set of measures quantifying their dynamics. It is partially caused by the fact that there are many representations of temporal networks, such as event sequences, interval graphs, time windows, etc. It is hard to develop a comprehensive measure that will cover all the models. Therefore, we may expect that the development of dynamic measures will proceed differently than in the case of static networks.
One of the most important concepts introduced in temporal setting is the time-respecting path, i.e. the path connecting nodes vi and vj in such a way that all intermediate nodes are visited in non-decreasing time order6. Starting with that metric, it was possible to define a number of natural subsequent measures, such as temporal connectedness5 between nodes representing the reachability from the source node to destination node in a given time, temporal diameter as a largest temporal distance between any two nodes or characteristic temporal path length that defines the temporal distance over all pairs of nodes7. Another important aspect of time-varying networks is the interevent time distribution8 that defines the frequency of events; it can be used to verify how bursty is the behavior in a given network. To quantify differences in burstiness, the expected number of short-time interactions is used to characterize the early-time dynamics of a temporal network9. Lastly, a number of centrality measures were adapted or developed from scratch to describe the position of the node in the network, in particular: temporal betweenness10, temporal closeness11, and temporal degree10.
Entropy-based measures, in turn, were utilized by Takaguchi et al.12 to evaluate the predictability of the partner sequence for individuals. In 2013, Kun Zhao et al.13 proposed entropy-based measure to quantify how many typical configurations of social interactions can be expected at any given time, taking into account the history of the network dynamic processes. L. Weng et.al used Shannon entropy to show how Twitter users focusing on topics (memes) comparing to the entire system14.
We use the entropy to capture human communications dynamics – event sequences (ES) depicting human interactions, which are also one of the basic lossless representations of temporal network15. In general, an event sequence is a time ordered list of interactions between pairs of individuals/agents within a given social group.
Three main approaches to compute entropy for temporal networks represented as an event sequence are proposed: (1) the first order entropy, based on the probability of a node to appear as a speaker, or in other words, an initiator of event, (2) the second order entropy, based on probability of the event occurrence, that is probability of interaction between unique pair of nodes, (3) the third order entropy denoting probability of succession appearance, i.e. probability of unique pair of events. Each type of entropy captures different aspect of dynamics and have potential to be useful for different applications. For each new entropy measure, its maximum value can be estimated for a given number of nodes. This value is used for normalization and definition of relative entropy measures that allow us to compare entropies for different datasets.
This paper is organized as follow. In the first section, we present results of our experiments followed by main findings and conclusions. The second section broadly discusses meaning of findings and provides some insight for further work. The last section contains the detailed description of our experiments: experimental setup, datasets used and definitions of all entropies.
Results
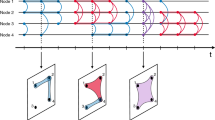
We compute entropy values for four different dataset with data of real human interactions: (1) face-to-face meetings at HyperText conference, (2) text messages exchanged between students for six semesters (NetSense), (3) email communications in the manufacturing company, and (4) face-to-face interactions between patients and hospital staff members. We compute time-line of entropy by taking a window from the beginning of network existence to point in time that we want to know the entropy value. In other words, we compute entropy cumulatively for on-line stream of interaction data. To provide the baseline for real event sequences, we generate 100 artificial event sequences for each dataset with the same numbers of nodes, events and timestamps by randomly reselecting pairs of nodes involved in each event. In the static networks, such procedure would be called rewiring. Distributions of random event sequencies are discussed later in Subsection on datasets. The average value of entropy for random event sequences is computed and compared against the values for the real network using Z-score – the distance measure that, in general, shows the number of standard deviations by which the value of entropy for real sequence is above the mean value of random streams. The negative values of Z-score mean that entropies for real data are smaller than random ones and greater the difference is more negative Z-scores are. The general concept of experiments is presented in Fig. 1.

General schema of experiments. K = 100 was used. From original (real) event sequence, event timestamps are extracted as a base for random sequence generator. Entropy value is computed for real event sequence and artificial sequences. We compare results for real data with summarized results for artificial data using Z-score.
The first observation made about the nature of entropy is that the maximum value of entropy is non-decreasing over time since it directly depends on the non-decreasing number of distinct nodes in the event sequence. By normalizing entropy with its maximum, we obtain the relative entropies within the range [0,1]. Our experimental results show that entropy of random networks tend to reach the maximum value faster for first-order entropies and slower for higher-order ones. In Fig. 2A, we can observe that entropy for random sequences have the shape suggesting that they converge to some maximum value, i.e. 1 in case of the normalized entropy. In Fig. 2B we can observe similar tendency for non-normalized entropy. However, the relative entropy values for the real network seem to stabilize earlier around the smaller value. We can clearly observe such case for first-order entropy as well as converging shape for higher-order ones. The similar observations were made for all other examined datasets. Figure 2C presents the Z-score for non-normalized second-order entropy, and the gray areas around the fitted straight line trend show the extent of single standard deviation. The inset at Fig. 2D shows Standard Deviations of entropies of the networks randomized by rewiring of the node connections. Each standard deviation is used as a denominator in computation of the respective network Z-score.

The NetSense dataset, the 1st semester. (A) Values of normalized entropies. Solid lines refer to the original event sequence and dashed ones present the average value for the baseline – random sequences. (B) Values of non-normalized entropies. (C) Z-score for non-normalized second-order entropy with the computed trend and marked standard deviation (gray area). Inset (D) Standard Deviations (SD’s) of entropies of the randomized networks; each SD is used as a denominator in computation of the respective network Z-score.
We split each dataset into reasonable parts selected empirically for more convenient analysis. Most clear observations were noted for non-normalized second-order entropy, see Fig. 3, even though the same phenomena can be seen for all datasets and all entropies. The main finding that can be derived from our results is that entropy decreases over time except for some rare cases, which are explained later on. The results for face-to-face contacts on the first two days of the conference, see Fig. 3A, are similar in terms of their dynamics, however, the last day is significantly different. It means that participants know each other much better on the last day and they interact much more consciously, i.e. with the smaller number of peers. A similar effect is observable for university students, see Fig. 3B. The entropy decreases with each consecutive year of study and it is the lowest for the last, sixth semester. Further, the results of manufacturing company emails communication shows that for consecutive months value of entropy decreases with the exception of June 2010, see Fig. 3C. We suppose that this month breaks from the pattern because of vacations - it may be the month when majority of employees go on vacation, what significantly changes dynamics of communication. Similarly, for face-to-face contacts among hospital stuff and patients, Fig. 3D, we can note that entropy decreases in consecutive days except on the 6th of December. This day is usually celebrated as Saint Nicolas Day, which makes people significantly change their common pattern of communication.

Value of non-normalized second-order entropy for all examined datasets. Solid lines refer to the real event sequences; upper dashed lines – to average values of random sequences. Each dataset is divided into parts for more convenient analysis. Parts were selected empirically. Different level of entropies for random sequences (especially for NetSense and hospital) comes from either smaller or greater number of interacting nodes in a given period. (A) In consecutive days of conference entropy of communication decreases which is especially clear for last day of conference. (B) Students tend to be more selective in their communication in later semesters than at the beginning of studies. (C) Manufacture company employees communicate with similar dynamic over time but decreasing tendency of the entropy can be still observed with the exception of one month probably related to holiday period. (D) Hospital staff and patients contacts shows decreasing entropy over consecutive days with the exception of 6th of December, usually celebrated as Saint Nicolas Day, which may influence contacts dynamic.
We also measure distance of real sequence entropy from random sequence entropy using Z-score distance measure. The results confirm that there is a clear difference between reality and randomness. A sample plot of Z-score is presented in Fig. 2C. While difference We can observe that Z-score decreases over time (absolute value is rising) or in other words the difference between reality (smaller and stable over time entropy) and randomness (greater entropy and still growing in time) becomes more and more clear over time. While this distance depends on a number of standard deviation from average, we present standard deviation on Fig. 2D as a function of time, to demonstrate that the growth of this distance is not caused only by decreasing standard deviation.
To show the difference between datasets, we compare entropy values, i.e. their normalized versions to exclude network size effect (different number of individuals), separately for the first- and second-order entropies, see Fig. 4. The greatest first-order value and lowest deviation is observed in the manufacturing company. It means that almost every employee needs to show up every working day in the company and interacts with the same frequency and stability of contacts with most of the other workers (the greatest second-order entropy). This suggests that communication in the company is decentralized and rather ‘flat’. Patients in the hospital appear and disappear (low first-order entropy) but if they are present, they interact more randomly than students, who communicate much more within their encapsulated social/learning groups (low second-order entropy). Randomness of interactions between hospital staff members and patients as well as conference participants is comparable (second-order entropy) - they do not know each other so much, even though the first-order values suggest that there is less rotation among conference attendees appearance (first-order) than in hospital. The diversity of contacts (high standard deviation of second-order entropy) in hospital is the greatest, it means that depending on time, the social groups are more or less integrated, e.g. interactions among staff members and between patients are different. Interactions among students and employees are most stable (low standard deviation). Based on these observations, we conclude that different approaches to entropy computation (entropy order) can measure different aspects of communication dynamics.

Comparison of average value of normalized entropy obtained incrementally (measured in 50 equally distributed points in dataset period): (A) the first-order, (B) the second-order. X-axis labels: hospdata - dataset of hospital face-to-face contacts, htdata - conference face-to-face contacts, mandata - email communication in manufacturing company, netsense - student text communication. Boxes shows median (black horizontal line) with the 1st and the 3rd quartile. Points refers to outliers and vertical lines to range of main observations.
Discussion
The results of our experiments provide some interesting insights about human communication dynamics. Firstly, we can confirm the general intuition that people do not communicate randomly. This obvious fact now finds quantitative confirmation also in the temporal network context.
The second important observation is that entropy decreases over time, i.e. for consecutive periods. Referring to the examined dataset, we can explained it with a human tendency to narrow their circle of friends with whom they usually communicate. In other words, while people are getting to know each other, they discover their preferences for interlocutors to talk to. It is opposite to the case of the early stage of groups formation, when people communicate more or less randomly. It is clearly seen in Fig. 3B, for the NetSense dataset which contains text communication of freshman students who start their studies at a new university. Similarly, we can observe decreasing entropy in other datasets independently of trend of random sequence entropy.
Another observation is that the distance from entropy of the real sequence to entropy of the random sequence, in general, increases over time, see Fig. 2C with the sample of Z-score distance values; similar trends arise for all other datasets. A group of people unfamiliar to each other engages in nearly random interactions which increasingly become non-random as familiarity of people in the group increases with time.
We recognized some potential of entropy-based measures in solving problems like detection of social communities from dynamic data about human activities. Our hypothesis is that entropy is able to distinguish different groups in the event sequence since the groups may have different dynamic profile of interactions (different entropy levels), e.g. within hospital staff members and separately among patients.
It should be noted that we considered events in the sequence to be directed interactions in our experiments. However, in some applications it may more be meaningful to treat events as undirected contacts.
Methods
In this section, we present in details all methods, measures and datasets we used in the experiments.
Temporal network representation
All experiments are performed on event sequences (ES)16, which are lossless representations of temporal social network and the most popular form of traces about human communication15. Since it is the most atomic representation, it fits to the real processes better than aggregated approaches like an aggregated weighted network17 or a time-window graph18.
An event sequence (ES) is a time ordered list of events and each event evijk captures a single time-stamped interaction between two individuals in the observed system, i.e. evijk is a triple \(e{v}_{ijk}=\{{s}_{i},{r}_{j},{t}_{k}\}\), where si is the sender/initiator and rj – the receiver of interaction at time tk. We also assume that the event can happen only between two different individuals (nodes):
We also want to define evij as an edge between two nodes, that is eij = (si, rj). It exists if there is any event from si to rj at any time. Note that edges are directed: (si, rj) ≠ (rj, si), i.e. eij ≠ eji. The set of all edges derived from a given event sequence ES is denoted as E. Let us define V as a set of all distinct individuals (nodes) participating in all considered events, i.e. \(V=\{s,r:(s,r)\in E\vee (r,s)\in E,s\ne r\}\). N denotes the size of set V: N = |V|. For further consideration let us define the space of possible edges Ω(E), i.e. the set of all possible pairs \(\{(s,r):s,r\in V,s\ne r\}\). Hence, |Ω(E)| = N(N − 1).
Some measures in the experiments are computed for the aggregated network, which is a static generalization of the event sequence ES that is simply a directed graph G defined by a tuple: G = (V, E).
Entropy-based measures for temporal network
In this section, we would like to propose a holistic approach - new measures for temporal networks designed especially to quantify temporal networks properties in terms of inner dynamic processes. The proposed measures are the main novelty of this work, even though they implement entropy – the concept well known in physics and information theory. Entropy is a probabilistic description of general systems properties capturing its randomness level. In particular, based on the event sequence (ES) as the representation of temporal network, we propose various entropy measures.
In general, we utilize entropy S known in information theory as information entropy or Shannon entropy, which is defined as follows:
where p(i) is occurrence probability of state or object i, and O is the set of all possible states/objects19.
First-order (node) entropy
The first approach is based on probability of occurrences of individual nodes si, rj ∈ V, i.e. humans participating in interactions – events \(e{v}_{ijk}=\{{s}_{i},{r}_{j},{t}_{k}\}\). It is the first-order entropy measure that can be considered in three variants: (1) node being a speaker/sender si, (2) node as a listener/receiver rj or (3) node occurring as a speaker si or listener rj. Using the basic definition of entropy (1), we define the first-order (node) entropy S1 as:
where p1(v) is probability of occurrence for node v ∈ V in the appropriate role – the sender, receiver or any of these two. Choice of the role (and the entropy version) depends on what kind of analysis we want to perform. In this paper, we use probability of node occurrences as the sender, because we assume that interaction initiators are more significant than the receivers.
The node entropy measures the diversity of node popularity in the temporal network. In other words, the greater entropy means that the nodes have rather equal probability of occurrence and the small one denotes that some nodes occur significantly more frequently than the others. Entropy has the maximum value when probabilities for all nodes from V are equal. The equal probabilities emerge when all nodes occur the same number of times, e.g. only once or all twice etc. Hence, the equal probabilities are:
Then, the maximum possible value of entropy for a given set of nodes V is defined as:
Second-order (edge) entropy
The second approach utilizes probabilities of occurrence of edge eij from E. We defined the second-order (edge) entropy, as:
where p2(eij) is a probability of edge eij, i.e. probability that events evijk are related to edge eij. This entropy of the temporal network provides information about how uncertain (random) pairs of nodes (individuals) interact with each other. The greater edge entropy value reflects that the distribution of participating pairs is close to uniform distribution while the smaller value means that some pairs interact more frequently than the others.
We can estimate the maximum value of edge entropy, assuming that probabilities for all possible edges are equal, i.e. all possible pairs of nodes si, rj appear in the same number of events evijk. The number of possible edges is |Ω(E)| = N(N − 1). Then, we have:
With this probability maximum value of edge entropy would be defined as:
For larger number of nodes (large N), we have: \({S}_{2}^{M}\approx 2{S}_{1}^{M}\).
Third-order (succession) entropy
The next approach is based on probability of occurrence two particular node pairs (edges) in events one directly after another. We refer to such a pair of edges as succession. Event sequence ES is a list of M events ordered by time: \(ES=(e{v}_{1},e{v}_{2}\mathrm{,...,}e{v}_{k},e{v}_{k+1}\mathrm{,...,}e{v}_{M})\), and \(e{v}_{k}=({s}_{i},{r}_{j},{t}_{k}),e{v}_{k+1}\)\(\,=\,({s}_{i^{\prime} },{r}_{j^{\prime} },{t}_{k+1})\iff {t}_{k}\le {t}_{k+1}\). For two consecutive events evk and evk+1, we can extract participating nodes \({s}_{i},{r}_{j},{s}_{i^{\prime} },{r}_{j^{\prime} }\), respectively, i.e. edges \({e}_{ij},{e}_{i^{\prime} j^{\prime} }\in E\). Such two edges define the single kth edge succession occurrence \(s{c}_{k}=({e}_{ij},{e}_{i^{\prime} j^{\prime} })\) and the set of distinct successions (unique pairs of edges) is denoted by SC. Obviously, it may happen that \({e}_{ij}={e}_{i^{\prime} j^{\prime} }\). The set of all potentially possible successions is Ω(SC) with size |Ω(SC)|. This size is limited by the maximum size of the edge set E for a given set of nodes V: \(|{\rm{\Omega }}(SC)|={|{\rm{\Omega }}(E)|}^{2}={N}^{2}{(N-\mathrm{1)}}^{2}\).
Using probability of succession we can define succession entropy:
where p3(sc) is a probability of edge succession sc.
The value of succession entropy quantifies information about how uncertain (random) is presence of particular succession of edge pairs in the event sequence. Similarly to previous approaches, we can find the maximum value of succession entropy by assuming equal distribution of succession probabilities:
For these probabilities, the maximum value of succession entropy would be:
For larger quantity of nodes (big N): \({S}_{3}^{M}\approx 4{S}_{1}^{M}\).
In real datasets it may happens that some events occur at the same time. In such case order of those events is pretty much arbitrary and yet choice of the order influences the value of third-order entropy. We examined robustness of this measure by conducting simple experiment which is described in Supplementary Information section.
Normalized entropy
To compare entropies among datasets with different sizes, we propose the normalized entropy for each previously defined entropy. The normalized entropy for event sequence ES is a ratio of regular entropy to its maximum value:
where o is one of entropy types; first-order: o = 1, second-order: o = 2, or third-order: o = 3.
Such normalized definition makes it possible to compare entropy for event sequences independent of their sizes – numbers of participating nodes, i.e. humans in the social network, see Figs 2A and 4.
Note that the experiments were carried out in the incremental setup, i.e. maximum entropy \({S}_{o}^{M}\) was re-calculated after each event for the given incrementally (cumulatively) increased event sequence. It means that the number of all participating nodes N increases over time since new nodes appeared in the sequence, see Supplementary Fig. 7. The value of N directly impacts on maximum entropy value, Eqs 5, 8 and 11 and as a result on its normalized version.
Datasets
All our experiments were carried out on empirical temporal social networks - event sequences - as well as on artificial ones, randomly generated.
Real event sequences
-
NetSense - text messages. The dataset contains phone and text communication among students at University of Notre Dame. The dataset was created to map peers’ social network and contains data from 3 years (6 semesters) starting from September 6, 201120.
-
Hospital ward dynamic contact network. This dataset contains the temporal network of contacts between patients, patients and health-care workers (HCWs) and among HCWs in a hospital ward in Lyon, France, from Monday, December 6, 2010 to Friday, December 10, 2010. The study included 46 HCWs and 29 patients21. Contacts were collected using proximity sensors which do not provide direction of the contact. However, for our experiments, we consider it as directed communication for easier comparison with other datasets.
-
Hypertext 2009 dynamic contact network. The dataset was collected during the ACM Hypertext 2009 conference, where the SocioPatterns project deployed with the Live Social Semantics application. Conference attendees volunteered to wear radio badges that monitored their face-to-face proximity. The dataset published here represents the dynamical network of face-to-face proximity of 110 conference attendees over about 2.5 days22. Collecting method does not provide direction of contacts but for easier comparison with other datasets, we consider contacts as directed.
-
Manufacturing emails. This is the internal email communication between employees of a mid-sized manufacturing company. The network is directed and nodes represent employees while events correspond to individual emails23.
The dataset profiles are presented in Table 1.
Random event sequences
For each real event sequence, we generate corresponding random event sequences to provide a baseline for our experiments. The new event sequences were generated preserving timestamps and set of nodes from the real event sequence. Hence, the acquired event sequences are the same in size and have the same set of nodes but different distribution and order of events. We generated an event sequence with following algorithm:
-
1.
Take the real event sequence ES and extract distinct nodes from event’s senders and receivers – create set of nodes V.
-
2.
Take the next event from the real event sequence, starting from the first one and keep its timestamp tk.
-
3.
Randomly select the sender si ∈ V (according to selected distribution).
-
4.
Randomly select the receiver rj ∈ V (according to selected distribution).
-
5.
If the sender and receiver are the same, repeat step 4.
-
6.
Create event \(e{v}_{ijk}=({s}_{i},{r}_{j},{t}_{k})\).
-
7.
If it is the last event in the real sequence ES – stop, otherwise go to step 2.
We tested the random selection with uniform, normal, and exponential distributions. In agreement with our with our intuition, The results of the experiments show that uniform distribution yields the highest entropy. Yet, the differences between distributions in terms of entropy are insignificant. Accordingly, we have used only the uniform distribution for random selection of events in the experiments.
For each real event sequence, we generated 100 random event sequences.
Evaluation
We used Z-score measure to evaluate distance between entropy value of the real network and its random analogues, see Fig. 2C. The Z-score value is defined as follows:
where S is the observation from the real data and μ, σ are mean and standard deviation of random variable, respectively. In our case, observation S is the value of appropriate entropy (S1, S2, S3) for the real event sequence. Randomly generated 100 event sequences, in turn, are aggregated with mean μ and standard deviation σ of their entropy values.
References
Zhao, K., Karsai, M. & Bianconi, G. Entropy of dynamical social networks. PloS one 6, e28116 (2011).
Song, C., Qu, Z., Blumm, N. & Barabási, A.-L. Limits of predictability in human mobility. Sci. 327, 1018–1021 (2010).
Pham, H., Shahabi, C. & Liu, Y. Ebm: an entropy-based model to infer social strength from spatiotemporal data. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, 265–276 (ACM, 2013).
Eagle, N. & Pentland, A. S. Reality mining: sensing complex social systems. Pers. ubiquitous computing 10, 255–268 (2006).
Nicosia, V. et al. Graph metrics for temporal networks. In Temporal Networks, 15–40 (Springer, 2013).
Grindrod, P., Parsons, M. C., Higham, D. J. & Estrada, E. Communicability across evolving networks. Phys. Rev. E 83, 046120 (2011).
Tang, J., Scellato, S., Musolesi, M., Mascolo, C. & Latora, V. Small-world behavior in time-varying graphs. Phys. Rev. E 81, 055101 (2010).
Karsai, M. et al. Small but slow world: How network topology and burstiness slow down spreading. Phys. Rev. E 83, 025102 (2011).
Doyle, C., Szymanski, B. K. & Korniss, G. Effects of communication burstiness on consensus formation and tipping points in social dynamics. Phys. Rev. E 95, 062303 (2017).
Tang, J., Musolesi, M., Mascolo, C., Latora, V. & Nicosia, V. Analysing information flows and key mediators through temporal centrality metrics. In Proceedings of the 3rd Workshop on Social Network Systems, 3 (ACM, 2010).
Kim, H. & Anderson, R. Temporal node centrality in complex networks. Phys. Rev. E 85, 026107 (2012).
Takaguchi, T., Nakamura, M., Sato, N., Yano, K. & Masuda, N. Predictability of conversation partners. Phys. Rev. X 1, 011008 (2011).
Zhao, K., Karsai, M. & Bianconi, G. Models, entropy and information of temporal social networks. In Temporal Networks, 95–117 (Springer, 2013).
Weng, L., Flammini, A., Vespignani, A. & Menczer, F. Competition among memes in a world with limited attention. Sci. reports 2, 335 (2012).
Holme, P. Modern temporal network theory: a colloquium. The Eur. Phys. J. B 88, 1–30 (2015).
Holme, P. Network reachability of real-world contact sequences. Phys. Rev. E 71, 046119 (2005).
Holme, P. Epidemiologically optimal static networks from temporal network data. Plos Comput. Biol 9, e1003142 (2013).
Krings, G., Karsai, M., Bernhardsson, S., Blondel, V. D. & Saramäki, J. Effects of time window size and placement on the structure of an aggregated communication network. EPJ Data Sci. 1, 1 (2012).
Shannon, C. E. A mathematical theory of communication. ACM Sigmobile Mob. Comput. Commun. Rev. 5, 3–55 (2001).
Striegel, A. et al. Lessons learned from the netsense smartphone study. ACM SIGCOMM Comput. Commun. Rev. 43, 51–56 (2013).
Vanhems, P. et al. Estimating potential infection transmission routes in hospital wards using wearable proximity sensors. PLoS ONE 8, e73970, https://doi.org/10.1371/journal.pone.0073970 (2013).
Isella, L. et al. What’s in a crowd? analysis of face-to-face behavioral networks. Journal of Theoretical Biology 271, 166–180, http://www.sciencedirect.com/science/article/B6WMD-51M60KS-2/2/cb31bee32b340b3044c724b88779a60e, https://doi.org/10.1016/j.jtbi.2010.11.033 (2011).
Michalski, R., Palus, S. & Kazienko, P. Matching organizational structure and social network extracted from email communication. In Business Information Systems, 197–206 (Springer, 2011).
Acknowledgements
This work was partially supported by the National Science Centre, Poland, projects No. 2015/17/D/ST6/04046 and 2016/21/B/ST6/01463; European Union’s Horizon 2020 research and innovation program under the Marie Skłodowska-Curie grant agreement No. 691152 (RENOIR); the Polish Ministry of Science and Higher Education fund for supporting internationally co-financed projects in 2016–2019 No. 3628/H2020/2016/2; as well as by the Army Research Laboratory under Cooperative Agreement No. W911NF-09-2-0053 (the Network Science CTA), by DARPA under Agreement No. W911NF-17-C-0099, and by the Office of Naval Research (ONR) Grant no. N00014-15-1-2640.
Author information
Authors and Affiliations
Contributions
B.K.S. conceived the idea of using entropy to measure dynamics of temporal social networks. M.K. created the drafted formulas. M.K., P.K. and B.K.S. structured the final concept and formulas, designed experiments and analyzed the results. M.K. executed all experiments. R.M. contributed to related work and revised the preliminary results. M.K., P.K. and B.K.S. drafted the manuscript. All authors critically reviewed the manuscript and approved the final version.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kulisiewicz, M., Kazienko, P., Szymanski, B.K. et al. Entropy Measures of Human Communication Dynamics. Sci Rep 8, 15697 (2018). https://doi.org/10.1038/s41598-018-32571-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-32571-3
Keywords
This article is cited by
-
Hibernation Model Based on Polariton Successive Filtering
National Academy Science Letters (2020)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
