
Abstract
Methamphetamine (MA) is a highly addictive psychostimulant that disturbs the central nervous system; therefore, diagnosis of MA addiction is important in clinical and forensic toxicology. In this study, a MA self-administration rat model was used to illustrate the gene expression profiling of the rewarding effect caused by MA. RNA-sequencing was performed to examine changes in gene expression in rat whisker follicles collected before self-administration, after MA self-administration, and after withdrawal sessions. We identified six distinct groups of genes, with statistically significant expression patterns. By constructing the functional association network of these genes and performing the subsequent topological analysis, we identified 43 genes, which have the potential to regulate MA reward and addiction. The gene pathways were then analysed using the Reactome and Knowledgebase for Addiction-Related Gene database, and it was found that genes and pathways associated with Alzheimer’s disease and the heparan sulfate biosynthesis were enriched in MA self-administration rats. The findings suggest that changes of the genes identified in rat whisker follicles may be useful indicators of the rewarding effect of MA. Further studies are needed to provide a comprehensive understanding of MA addiction.
Similar content being viewed by others

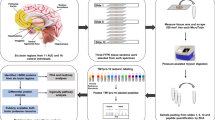

Introduction
Addiction is a representative disorder of the brain’s reward system and occurs over time from high chronic exposure to an addictive stimulus, such as an abuse drug1. The defining feature of addiction is compulsive and out-of-control drug use2. The uncontrolled drug use may lead to criminal or anti-social behaviour, violence, physical dependence, or psychological addiction3.
Methamphetamine (MA), the second most abused illegal psychostimulant, affects the central nervous system4. MA has pervasive effects not only on the dopaminergic system, but also on diverse neurotransmitter systems, such as noradrenergic and serotonergic systems, in the brain. Converging evidence suggests that chronic MA use is associated with immunological dysfunction and impaired neurogenesis in the limbic dopaminergic system5. The reported neurotoxicity induced by MA might be related to reactive oxygen species6, apoptotic processes7, and excitotoxicity8, which might be a major cause of neurodegenerative disorders, in the dopaminergic and serotonergic systems. Clinical observation suggests that MA causes long-lasting injury to the brain. Moreover, diverse clinical symptoms, such as depression, suicidal ideation, and psychotic behaviour, are observed in people who are addicted to MA9.
MA abuse and addiction have become a serious worldwide issue since the 1990s. Ease of manufacture and distribution is the major factor linked to increased use of MA10. In Republic of Korea, MA is the most widely used illegal drug, and 100% of persons treated for drug problems in the country are MA abusers11. In particular, MA abuse is a growing serious problem in youths; thus, investigation on MA abuse is needed to understand the seamy side of MA. Therefore, testing for MA abuse is crucial for assessing the reality of intoxication and evaluating the level of drug impairment.
Testing for MA abuse is largely dependent on biofluids, such as urine, blood, and plasma. Urine is the most used traditional specimen; urine testing is a valuable measure of drug use in patients who use the drug regularly12. However, urine testing has limitations for those with moderate drug use because of the short drug detection time13. In contrast, the use of the hair has several advantages, such as ease of collection, noninvasiveness, and a long detection window (months to years), for toxicological analysis14. Interestingly, a recent report suggests that scalp hair follicles can be used to find genes associated with brain diseases because the brain is an ectodermal tissue and shares the developmental origins with scalp hair follicle15. Moreover, the hair follicle system, which is a well-coordinated miniorgan within the skin, has been used to detect stressors, such as neurohormone, neurotransmitters, and cytokines16, as well as to diagnose traumatic brain injury17. Therefore, it could be valuable to study changes in gene expression in hair follicles, instead of brain tissues, in order to identify novel indicators related to the rewarding effect of MA in living donors.
The development of addiction is accompanied by changes in the signal transduction pathway and cellular gene expression in the brain. Many addiction-related genes and pathways have been identified18,19,20; however, the exact mechanism underlying MA addiction has not been fully elucidated. Previous studies have implied that exposure to MA causes complex molecular alterations; therefore, a comprehensive multigene level approach is needed to understand the drug addiction mechanisms, and it is important to identify the principal molecular network underlying MA addiction by analysing alteration in gene networks.
RNA-sequencing (RNA-seq) is transcriptome profiling and uses deep-sequencing technologies. RNA-seq is used to investigate the expression of unknown and known candidate genes with higher sensitivity than microarray. Genes that are significantly upregulated or downregulated can be determined in certain conditions by quantifying changes in RNA expression between different conditions21. However, RNA-seq alone may not provide pragmatic results in a multigenic disease, such as drug addiction, because of extensive raw data; therefore, data management and computational screening are needed. The integration of bioinformatics and biological network analysis enables RNA-seq to define specific groups of genes that are related to drug addiction behaviour22. Recent advances in bioinformatics facilitate analysis of complex signalling transduction in cells through investigation of multiple types of interaction networks23. Biological network analysis is a powerful tool using computable networks in the biological system24. Gene-gene association network analysis provides a novel method of analyzing a large number of differentially expressed genes by classifying them into different gene groups based on their function or signalling pathway annotation25. In the network analysis, degree, which is the number of edges connecting a node, and betweenness centrality (BC), which is how central the node is to the network, are used to show the importance of the genes26.
In this study, RNA-seq was used to illustrate transcriptome profiling of whisker follicles in MA self-administered rats. We also investigated alteration in the gene networks (rather than individual gene expression), signalling networks, and the signalling pathways, and the alteration may be responsible for the rewarding effect of MA. The results may serve to reveal the complicated gene-gene interaction mechanisms of the rewarding effect caused by MA.
Results
A MA self-administration rat model
Saline or MA self-administration in rats was performed according to the experimental schedule as indicated in Fig. 1A. Figure 1B shows the number of lever responses during self-administration (2 h each day, 16 days) under the fixed-rate 1 (FR1) schedule. The number of drug infusions in MA self-administration rats gradually increased compared with that in saline self-administration rats and showed <10% variation during the last 3 days of the experiment. The mean number (mean ± SEM) of MA infusions on the final day was 40 ± 7.7. Subsequently, stably responding MA self-administration rats (n = 6) underwent a withdrawal session of 30 days. A two-way analysis of variance (ANOVA) showed a significant difference in the number of infusions between saline and MA self-administered rats (p < 0.01).

Methamphetamine self-administration (MASA). (A) The experimental timeline of saline or methamphetamine self-administration and the sampling time-points of MASA. (B) The number of infusions in saline or methamphetamine self-administration rats. MA self-administered rats (n = 6) had a significantly greater infusion number than did saline self-administration rats (n = 6). Statistical analysis was performed using the two-way analysis of variance (ANOVA) and the student Newman-Keuls test. Error bars represent the mean ± SEM (n = 6). *p < 0.05, **p < 0.01, and ***p < 0.001.
RNA-seq and gene expression profiling
RNA-seq was performed using the whisker follicle samples collected from 3 representative rats before self-administration (CON), after MA self-administration (MASA), and after withdrawal (WD) sessions, and the three rats were selected based on the statistical procedure and showed less variation per day during the self-administration session. A total of 8,680 differentially expressed transcripts were analysed using one-way ANOVA in both groups. The quantitative value of each transcript abundance was used to perform a principal component analysis (PCA).
The differentially expressed genes at the three time-points (CON, MASA, and WD) were clustered based on the quantitative results of transcripts following the PCA analysis (Fig. 2A). The differentiation was primarily represented by the first principal component (PC1), accounting for 75.65% of the observed variance. The secondary principal component (PC2) showed 10.79% of the variance. The fundamental difference in RNA abundance between the three time-points accounted for the separation; therefore, principal components could achieve clear separation (Fig. 2A). In the hierarchical clustering analysis (Fig. 2B), it was found that the individual samples were well clustered according to their conditions. Distinct gene expression abundances at each time-point are presented as a heat map in Fig. 2C.

Quality assessment of RNA-sequencing (RNA-seq) data. (A) Grouping of samples via principal component analysis based on gene expression abundance. (B) Hierarchical clustering of genes. (C) A heat-map of the 8,680 expressed genes. Gene expression abundance decreases from red to green.
Gene expression pattern analysis
A total of 1,890 genes were identified with same expression patterns after primary data alignment and further filtration (Fig. 3A). In addition, 455 and 205 genes were up- and down-regulated, respectively, at the MASA session compared with the CON session (MASA/CON); 67 and 1,776 genes were significantly up- and down-regulated, respectively, at the WD session compared with the MASA session (WD/MASA) (Fig. 3A). It is noteworthy that more genes (1,776) were down-regulated after MA withdrawal. A time-series correlation of changes in expression identified 666 genes with differential expression patterns in the three rats. According to the mRNA abundance ratios (MASA/CON, WD/MASA), the genes were classified into 6 groups: 3 up-up regulated (Group 1), 422 up-down regulated (Group 2), 2 constant-up regulated (Group 3), 51 constant-down regulated (Group 4), 25 down-up regulated (Group 5), and 163 down-down regulated genes (Group 6) (Fig. 3B,C). Notably, the expression of 422 transcripts in Group 2 gradually increased at the MASA session and decreased to the baseline at the WD session (Fig. 3B,C). In contrast, expression of 163 transcripts in Group 6 decreased at the MASA session and then did not decrease further at the WD session (Fig. 3B,C).

Gene expression pattern analysis of RNA-seq data. (A) Flow chart of RNA-seq data processing. Transcriptome profiling in whisker follicle samples collected at the three time-points (control [CON], MASA, and withdrawal [WD]). Differentially expressed transcripts among the three time-points were identified through a one-way ANOVA. (B) Gene expression pattern analysis. The expression patterns of genes were classified into six groups. All graphs are expressed as the normalised value of gene expression. (C) The number of genes in each group.
Network analysis of differentially expressed genes (DEGs)
Physical and functional links of altered genes were investigated based on the assumption that gene pairs that interact or share similar functions tend to interact within the cellular systems27,28. To analyse the changes in mRNA abundances under MA addiction and withdrawal, the functional association network was generated using the 432 seed genes among 666 altered genes based on information about the physical and functional links of these genes. The physical link represents protein-protein interaction, and the functional link represents a relationship between two proteins if they share a substrate in a metabolic pathway and are co-expressed, co-regulated, or involved in the same protein complex. It was found that the network was divided into two prominent subnetworks of up-down regulated (Group 2/red) and down-down regulated genes (Group 6/blue) based on gene expression patterns (Fig. 4A). Interestingly, more links were found within a group (link to the identical group) than between groups (link to the different group). Among 1,466 links in the network, 815 (55.6%) were found to be intra-regulatory links (Fig. 4B). Subsequently, the fraction of links per gene was measured. Links within a group were 2.07-fold more than the expected value (Mann-Whitney U test, p value = 2.59 e−8; Fig. 4C). The results indicate that the two distinct sub-networks of up-down regulated (Group 2) and down-down regulated (Group 6) genes tend to cluster themselves and might have distinct functional roles in the gene functional network.

Functional association network analysis of differentially expressed genes. (A) Functional association network in MASA and WD rat whisker follicles. Nodes in the same group are coded with the same colour. Orange and red nodes represent up-regulation in MASA and up-down-regulation in WD, respectively. Yellow and green nodes show constant expression in MASA and up-down-regulation in WD, respectively. Cyan and blue nodes show downregulation in MASA and up-down-regulation in WD, respectively. The links between the same colour nodes are displayed using identical colours. (B) A comparison of link numbers “within” and “between” groups. The number of links according to link type. “Within” is a link to the identical group. “Between” is a link to the different groups. (C) Likelihood scores of “within” groups. Statistical analysis was performed using the Mann-Whitney U test. ***P < 0.001. (D) Distribution of addiction-related genes in the network. Links between the same colour nodes are displayed with identical colours. (E) Mean betweenness centrality (BC) scores of the six groups and addiction-related gene group (addiction). Statistical analysis was performed using the Mann-Whitney U test. **p < 0.01. (F) Relative fold-enrichment BC scores of the six groups and addiction-related gene group. Statistical analysis was performed using the hypergeometric test. ***p < 0.001.
Network mapping of addiction-related genes
The gene functional network was analysed based on a topological parameter, BC, which reflects the importance of genes in the network. The BC score is the minimum number of links connecting one protein to another in the network; thus, a high BC score implies that genes undergo more number of the shortest paths in the network. Therefore, the protein with the highest BC score derives a lot of importance from its position in the network. To check whether the constructed network contains the gene sets involved in MA addiction, known addiction-related genes from Knowledgebase for Addiction-Related Gene (KARG) database were mapped to the functional network. Subsequently, 1,256 addiction-related genes were collected from 105, 346, 474, and 331 genes mapped from low-throughput (LT) data, mouse, human, and high-throughput (proteomics and microarray) data, respectively, in KARG. As a result, 82 addiction-related genes (6.5%) were mapped in the functional association network that consisted of 432 genes (Fig. 4D). The average BC score of known addiction-related genes was higher than that of other genes (Mann-Whitney U test, p = 0.006; Fig. 4E). The relative fold-enrichment of known addiction-related genes with the top 10% of BC scores was 2.07-fold higher than that of all genes in the 6 groups (Hypergeometric test, p = 5.38 × 10−4; Fig. 4F). Finally, top 43 ranked genes, by the BC score, were selected as possible markers of MA addiction (Table 1). Hsp90ab1 (BC score, 0.2127), Akt1 (BC score, 0.1694), and Src (BC score, 0.1171) were identified with the highest BC scores and might act as molecular bridges to connect multiple other proteins in this network. These genes have been previously reported as addiction-related genes18,29,30. Genes with high BC score tend to interact with many different functional groups and are important for controlling information flow in the network. Furthermore, 17 out of 43 genes (39.5%) were mapped as pre-designated addiction-related genes, suggesting that the current approach of network analysis confers a high level of reliability and confidence in the selection of genes that are related to MA addiction. Addiction-related genes with high BC scores could be identified based on their importance in information flow in the altered gene-gene network under addiction-withdrawal conditions.
Functional analysis using reactome
To assess the biological relevance of the 43 top ranked genes, functional enrichment analysis was performed using the Reactome database (Reactome. 2004). Biologically related gene sets were identified and labeled with the Reactome terms. The main enriched pathways and genes are presented in Table 2. As expected, the pathways included genes that function in the regulation of cell-cell communication, developmental biology, diseases, extracellular matrix organization, hemostasis, the immune system, metabolism, and signal transduction. In addition, several genes associated with the progression of Alzheimer’s disease (AD) were observed (Fig. 5). It is noteworthy that all well-known signalling pathway-related genes, such as transforming growth factor beta 1 (Tgfb1), epidermal growth factor receptor (Egfr), and proto-oncogene tyrosine-protein kinase (Src), activate nuclear factor-κB (NF-κB) and thereby regulate the expression of amyloid-β precursor protein (APP), which is associated with AD. Moreover, most genes associated with biosynthesis of heparan sulfate, a member of the glycosaminoglycan family, were upregulated at the MASA session (Fig. 5).

Schematic of the signalling pathways altered in MA self-administration. An increased expression of genes related to Alzheimer’s disease (AD) and heparan sulfate biosynthesis is observed in MASA. Activation of nuclear factor-κB leads to up-regulation of amyloid-β precursor protein, which is associated with AD.
Discussion
MA abuse is a major health concern and a social problem worldwide, and the mechanism of addiction still remains unclear. Clinically, it is crucial to understand MA addiction because of a current lack of effective pharmacotherapy and a high recurrence rate31. Therefore, it is important to make an accurate diagnosis of MA abuse and addiction in clinical medicine. In fact, non-invasive diagnostic tools or reliable biomarkers used to determine MA abuse and addiction are being sought.
The purpose of the present study was to investigate the transcriptional changes caused by rewarding effects in MA self-administration rats. Drug addiction is not a static condition but a chronic relapsing disorder, which develops with the repetition of rewarding and withdrawal effects caused by temporary drug use and abstinence, respectively. Therefore, it is not enough to only study static changes of genes for MA addiction. The transcriptional gene changes caused by initial reward and withdrawal could affect the following stages and play a key role in MA addiction. To find diagnostic genes in this process, we examined dynamic changes in mRNA expression in the rat whisker follicle during MA self-administration. We used the short-access rat model of MA self-administration and measured the number of drug infusions that each rat chose (reward rate), and it was found that the rat showed an increased rewarding effect upon repeated MA administration. Analysis of RNA-seq data revealed that time-dependent changes of gene expression patterns at the three time-points (CON, MASA, and WD) were different. Notably, the majority of genes showed a similar pattern of changes in expression: an initial increase followed by a decrease during MASA and WD, suggesting that these genes may play a similar role in maintaining the reward state caused by MA.
Network analysis is a tool for gene prioritization and can facilitate a better understanding of network interconnections among interactive genes. Functional gene-gene association network analysis is an effective way to understand the interaction of a large number of genes25. The importance of genes can be determined by measuring BC scores in the network32,33. In this study, a topological centrality analysis was performed using a functional association network to narrow down the candidate genes related to MA addiction, and 43 genes were selected as core genes in the network.
The top three core genes were heat shock protein (HSP) 90-beta 1 (Hsp90ab1), RAC-alpha serine/threonine-protein kinase (Akt1), and Src. They have been previously reported as drug addiction-related genes18,29,30; therefore, it is possible that they play an important role in MA addiction. The gene with the highest BC score was Hsp90ab1 (BC score, 0.2127), and Hsp90-beta protein, encoded by Hsp90ab1 gene, is a molecular chaperone maintaining the functional stability and viability of cells34. The expression of Hsp90ab1 in the rat frontal cortex increases after morphine self-administration35. Furthermore, Akt1, which had the second highest BC score (0.1694) in this study, is implicated in excessive alcohol drinking behaviours36. Src-family kinase activation is necessary for incentive, motivational, and/or memory processes that promote contextual cocaine-seeking behaviours30. To determine the biological function of 43 genes that could act as a functional core in the constructed gene network, we performed functional enrichment analysis using the Reactome database. Reactome categorises large quantities of genes and proteins into functions and pathways based on a massive database37. Using the Reactome database, we identified the main enriched pathways of the selected 43 genes and discovered eight functional groups: cell-cell communication, developmental biology, diseases, extracellular matrix organization, hemostasis, the immune system, metabolism, and signal transduction. Notably, a prominent increase in the expression of genes related with AD and heparan sulfate biosynthesis was found.
AD is a chronic neurodegenerative disease and the most common age-related dementia38. Previous studies suggest that MA abuse is related to long-term damage in the human brain39. In fact, clinical studies using proton magnetic resonance spectroscopy showed that the level of N-acetyl-aspartate, a neuronal marker, reduced by 5% in MA abusers, and the reduction was also observed in several brain diseases, such as AD, stroke, and epilepsy39. The representative characteristics of AD are progressive loss of cognitive abilities, severe neurodegeneration, and neuroinflammation40. One of the hallmarks of AD is the formation of neuritic plaques, which contain filamentous extracellular β-amyloid (Aβ) aggregates. Aβ is generated by sequential cleavage of APP by NF-κB-dependent activation of β- and γ-secretase41. A previous study revealed that MA enhanced Aβ accumulation through alpha7 nicotinic acetylcholine receptor in brain endothelial cells42. In agreement with the aforementioned results, an increased expression of NF-κB, APP, and Aβ was found in the whisker follicles in MA self-administered rats in this study.
Heparan sulfate biosynthesis is another interesting pathway in this study. Heparan sulfate proteoglycans (HSPGs) are macromolecules located in the cell surface and extracellular matrix. HSPGs consist of core protein-linked glycosaminoglycan chains43. The core proteins of HSPGs are agrin, perlecan, glypicans, and syndecans (Sdc). In this study, a significant increase in the expression of Sdc2 was found at the MASA session. In addition, most of genes included in the heparan sulfate pathway showed the same expression pattern as did Sdc2. According to previous studies, Sdc has four categories of functions: (1) growth factor receptor activation44; (2) matrix adhesion45; (3) cell to cell adhesion46; and (4) tumour suppression and progression47. Sdc2 is involved in synaptic formation48, and Sdc3 has been identified as a resilience factor of cocaine addiction49. Consequently, transcriptional alteration of Sdc2 at the MASA session may be an important marker of MA addiction.
Drug addiction is a complicated, chronic disorder and is conceptualised as a cycle comprising rewarding effect, withdrawal effect, craving, and relapse to drug seeking behaviour50,51. Briefly, intake of drugs initially causes rewarding effect, and tolerance and withdrawal effects gradually occur after repeated use of the drugs. To escape the effects, craving to the drug intake arises, leading to relapse of drug-seeking behaviour. Therefore, a validated model of intravenous drug self-administration relevant to the transition to addiction is needed to uncover the complicated clinical situation in human addicts. In the present study, rats were allowed to self-administer MA 2 h daily for 16 days to determine the mechanism underlying the transition from initial drug use to drug addiction. However, the present study has some limitations. For example, a short access rat model of MA self-administration was used in this study. Recent studies have shown that rats with extended access to MA, compared with rats with short access to MA, showed enhanced MA-primed reinstatement of drug-seeking and cognitive deficits52,53,54,55. Moreover, extended limited daily access to MA self-administration in animal models mimics the course of MA administration in human55. Therefore, the model in the present study can be used to study the reward process, which is an initial step of the MA addiction. However, a follow-up study with long access self-administration would be needed to understand MA addiction in human.
In conclusion, the present findings suggest that the alteration of the gene expression and signalling networks in the whisker follicles in MA self-administered rats can be used to understand the biological changes and MA rewarding effects induced by MA self-administration. Further studies should be needed to determine the differential changes in gene expression between the whisker follicle and the brain to strengthen our conclusion.
Methods
Animals
Adult male Sprague-Dawley rats (Daehan Animal, Seoul, Republic of Korea), 310–350 g in weight, were housed individually in the laboratory animal facility in room temperature (22 ± 2 °C) and humidity (60 ± 2%) controlled cages on a 12 h light/dark cycle (lights on at 7:00 AM). Animals had access to food and water ad libitum. All experimental procedures were approved by the institutional animal care and use committee at Daegu Hanny University, Daegu, Republic of Korea (DHUMC-D-13002-PRO-02, 2013). The experiments were carried out in accordance with the university’s scientific research guidelines and regulations.
MA self-administration and sample collection
MA self-administration was conducted as previously described56. Briefly, rats were habituated to their environment for 1 week, and they were then implanted with chronic indwelling jugular catheters and assigned to the control (n = 6) or MA self-administration (n = 6) group. One week after surgery, rats were given food training. Subsequently, they were treated with a FR1 schedule of MA self-administration with 2 h access per day to MA hydrochloride (0.05 mg·kg·infusion−2) dissolved in sterile heparinised saline (3 U·mL−1) for 2 weeks. If animals had shown the stable infusion numbers for 3 consecutive days (variation less than 10% of the mean infusion number of the 3 days), the mean infusion number was regarded as the baseline. Saline self-administered rats received heparinised saline infusions during the self-administration period. All responses were recorded using MED associated software. Samples were collected 3 times during the experiment: Control (CON) samples were collected before MASA; MASA samples were collected within 2 hours after the last MA self-administration; and WD samples were collected 1 month after MASA.
RNA isolation
Whisker samples were collected and stored at −80 °C before RNA extraction after rats were sacrificed. Total RNA was isolated from the whisker roots (hair follicles) using the spin column type RNA extraction kit (Bioneer, Republic of Korea). The quality and concentration of RNA were measured using a filter-based multi-mode microplate reader (FLUOstar Omega, BMG LABTECH, Germany). Residual genomic DNA was removed by incubation with RNase-free DNase I for 30 min at 37 °C.
Construction of transcriptome libraries
The mRNA sequencing libraries were prepared according to the Illumina TruSeq RNA sample preparation kit v2 (Illumina, Inc., San Diego, CA, USA). Briefly, 1 μg total RNA was used for polyA mRNA selection using streptavidin-coated magnetic beads, followed by thermal fragmentation of selected mRNA. The 200–500 bp fragmented mRNA was used as a template for cDNA synthesis by reverse transcriptase with random primers. The cDNA was converted into double-stranded DNA that was end-repaired (to incorporate the specific index adaptors for multiplexing), purified, and amplified for 15 cycles. The quality and functionality of the final amplified libraries were examined with a DNA high sensitivity chip on an Agilent 2100 Bioanalyzer (Agilent Technologies, Palo Alto, CA, USA). Libraries were prepared according to the Illumina’s protocol. Briefly, random fragmentation of the DNA or cDNA, followed by 5′ and 3′ adapter ligation, was conducted. Alternatively, “tagmentation” combined the fragmentation and ligation reactions into a single step, which greatly increased the efficiency of the library preparation process. Subsequently, adapter-ligated fragments were PCR amplified and gel-purified. The concentration of each library was measured by real-time PCR. Agilent 2100 Bioanalyzer was used for profiling the distribution of insert size. For cluster generation, the library was loaded into a flow cell where fragments were captured on a lawn of surface-bound oligos complementary to the library adapters. Each fragment was then amplified into distinct clonal clusters through bridge amplification. After cluster generation was completed, the clustered libraries were sequenced by Illumina HiSeqTM 2500 according to the manufacturer’s instructions (Illumina Inc., USA), and paired-end sequencing was performed for 100 cycles using TruSeq rapid SBS kit or TruSeq SBS kit v4. The sequencing protocol, the HiSeqTM 2500 system user guide part #15011190 Rev. V HCS 2.2.58, was used in this study.
Sequencing data analysis
Sequencing raw images were generated using HiSeqTM Control Software (HCS v2.2), and base calling was performed through an integrated primary analysis software called RTA (v1.18). Images generated by HiSeqTM2500 were converted into nucleotide sequences by base calling and were stored in the FASTQ format using the Illumina package bcl2fastq (v1.8.4). Clean reads were generated by filtering the dirty reads, which contained adaptors and unknown or low phred quality scored-bases, from raw reads. Clean reads were mapped to reference Rattus norvegicus genome (rn6) and gene sequences using a conventional Tuxedo protocol. Reading mismatches of ≤5 bases were allowed in the alignment. Reads that matched with reference rRNA sequences were also mapped and removed. Tophat2 software and the Cufflinks package (v2.2.1) were used to calculate FPKM (Fragments per kb per million reads) values for each gene used for subsequent data analysis. DEGs were analysed using one-way ANOVA, Student’s t-test (p < 0.05), and fold changes. Hierarchical clustering and PCA were also performed with the GeneSpring 7.3 software (Agilent Technologies).
Gene expression pattern analysis
Transcripts that were differentially expressed between the groups were analysed using one-way ANOVA. After primary data alignment and further filtration to find transcripts with >1.1 or <0.9 fold-change between groups, 1,890 transcripts were quantified, and 666 genes were next identified with same patterns in both MASA/CON and WD/MASA.
Functional association network analysis
The STRING-database (ver. 10.0) was used to conduct a rat gene functional association network using physical and functional link information extracted via the retrieval of interacting with a confidence score over 400. Network visualization and calculation of BC32,33 were performed using Cytoscape 2.857.
Statistical analysis
Data were analysed using a two-way ANOVA followed by a Student Newman-Keuls test in the self-administration experiment. Data from the self-administration group were compared with those from the saline self-administration group, and *p < 0.05, **p < 0.01, or ***p < 0.001 was considered statistical significance. The differences in the RNA-seq results within groups were evaluated by PCA. Differentially expressed transcripts between the groups were calculated using a one-way ANOVA. The Mann-Whitney U test was performed to compare links in the network, and the hypergeometric test was used for the comparison of relative fold-enrichment in the network.
References
Nestler, E. J. Cellular basis of memory for addiction. Dialogues in clinical neuroscience 15, 431–443 (2013).
Ross, S. & Peselow, E. The neurobiology of addictive disorders. Clinical neuropharmacology 32, 269–276 (2009).
Fillmore, M. T. Drug abuse as a problem of impaired control: current approaches and findings. Behavioral and cognitive neuroscience reviews 2, 179–197, https://doi.org/10.1177/1534582303257007 (2003).
Scott, J. C. et al. Neurocognitive effects of methamphetamine: a critical review and meta-analysis. Neuropsychol Rev 17, 275–297, https://doi.org/10.1007/s11065-007-9031-0 (2007).
Larsen, K. E., Fon, E. A., Hastings, T. G., Edwards, R. H. & Sulzer, D. Methamphetamine-induced degeneration of dopaminergic neurons involves autophagy and upregulation of dopamine synthesis. J Neurosci 22, 8951–8960 (2002).
Wen, D. et al. Cholecystokinin-8 inhibits methamphetamine-induced neurotoxicity via an anti-oxidative stress pathway. Neurotoxicology 57, 31–38, https://doi.org/10.1016/j.neuro.2016.08.008 (2016).
Warren, M. W. et al. Calpain and caspase proteolytic markers co-localize with rat cortical neurons after exposure to methamphetamine and MDMA. Acta Neuropathol 114, 277–286, https://doi.org/10.1007/s00401-007-0259-9 (2007).
Smith, K. J., Butler, T. R., Self, R. L., Braden, B. B. & Prendergast, M. A. Potentiation of N-methyl-D-aspartate receptor-mediated neuronal injury during methamphetamine withdrawal in vitro requires co-activation of IP3 receptors. Brain Res 1187, 67–73, https://doi.org/10.1016/j.brainres.2007.10.019 (2008).
Kalechstein, A. D., Newton, T. F. & Green, M. Methamphetamine dependence is associated with neurocognitive impairment in the initial phases of abstinence. J Neuropsychiatry Clin Neurosci 15, 215–220, https://doi.org/10.1176/jnp.15.2.215 (2003).
Degenhardt, L. & Hall, W. Extent of illicit drug use and dependence, and their contribution to the global burden of disease. Lancet (London, England) 379, 55–70, https://doi.org/10.1016/S0140-6736(11)61138-0 (2012).
United Nations Office on Drugs and Crime (UNODC), 2017. World Drug Report 2017, http://www.unodc.org/wdr2017/field/4.1_Treatment.xlsx (2017).
Owen, G. T., Burton, A. W., Schade, C. M. & Passik, S. Urine drug testing: current recommendations and best practices. Pain Physician 15, ES119–133 (2012).
Frederick, D. L. Toxicology testing in alternative specimen matrices. Clinics in laboratory medicine 32, 467–492, https://doi.org/10.1016/j.cll.2012.06.009 (2012).
Lee, S. et al. Analysis of pubic hair as an alternative specimen to scalp hair: a contamination issue. Forensic Sci Int 206, 19–21, https://doi.org/10.1016/j.forsciint.2010.06.009 (2011).
Maekawa, M. et al. Utility of Scalp Hair Follicles as a Novel Source of Biomarker Genes for Psychiatric Illnesses. Biological psychiatry 78, 116–125, https://doi.org/10.1016/j.biopsych.2014.07.025 (2015).
Arck, P. C. et al. Stress inhibits hair growth in mice by induction of premature catagen development and deleterious perifollicular inflammatory events via neuropeptide substance P-dependent pathways. The American journal of pathology 162, 803–814, S0002-9440(10)63877-1 (2003).
Zhang, J. et al. Transcriptional profiling in rat hair follicles following simulated Blast insult: a new diagnostic tool for traumatic brain injury. PloS one 9, e104518, https://doi.org/10.1371/journal.pone.0104518 (2014).
Bolanos, C. A. & Nestler, E. J. Neurotrophic mechanisms in drug addiction. Neuromolecular medicine 5, 69–83, https://doi.org/10.1385/nmm:5:1:069 (2004).
Koob, G. F. & Le Moal, M. Drug addiction, dysregulation of reward, and allostasis. Neuropsychopharmacology: official publication of the American College of Neuropsychopharmacology 24, 97–129, S0893-133X(00)00195-0 (2001).
Nestler, E. J. Molecular mechanisms of drug addiction. Neuropharmacology 47 1, 24–32, S0028390804001911 (2004).
Sharma, D., Kim, M. S. & D’Mello, S. R. Transcriptome profiling of expression changes during neuronal death by RNA-Seq. Experimental biology and medicine (Maywood, N. J.) 240, 242–251, https://doi.org/10.1177/1535370214551688 (2015).
Zhu, L. et al. mRNA changes in nucleus accumbens related to methamphetamine addiction in mice. Scientific reports 6, 36993, https://doi.org/10.1038/srep36993 (2016).
Sivachenko, A. Y., Yuryev, A., Daraselia, N. & Mazo, I. Molecular networks in microarray analysis. Journal of bioinformatics and computational biology 5, 429–456, S0219720007002795 (2007).
Sharan, R. & Ideker, T. Modeling cellular machinery through biological network comparison. Nature biotechnology 24, 427–433, nbt1196 (2006).
Breen, M. S. et al. Candidate gene networks and blood biomarkers of methamphetamine-associated psychosis: an integrative RNA-sequencing report. Translational psychiatry 6, e802, https://doi.org/10.1038/tp.2016.67 (2016).
Proulx, S. R., Promislow, D. E. & Phillips, P. C. Network thinking in ecology and evolution. Trends in ecology & evolution 20, 345–353, S0169-5347(05)00088-1 (2005).
Huh, W. K. et al. Global analysis of protein localization in budding yeast. Nature 425, 686–691, https://doi.org/10.1038/nature02026 (2003).
Jeon, J. et al. Network clustering revealed the systemic alterations of mitochondrial protein expression. PLoS computational biology 7, e1002093, https://doi.org/10.1371/journal.pcbi.1002093 (2011).
Chen, J. C., Chen, P. C. & Chiang, Y. C. Molecular mechanisms of psychostimulant addiction. Chang Gung medical journal 32, 148–154 (2009).
Xie, X., Arguello, A. A., Wells, A. M., Reittinger, A. M. & Fuchs, R. A. Role of a hippocampal SRC-family kinase-mediated glutamatergic mechanism in drug context-induced cocaine seeking. Neuropsychopharmacology 38, 2657–2665, https://doi.org/10.1038/npp.2013.175 (2013).
Brackins, T., Brahm, N. C. & Kissack, J. C. Treatments for methamphetamine abuse: a literature review for the clinician. Journal of pharmacy practice 24, 541–550, https://doi.org/10.1177/0897190011426557 (2011).
Freeman, L. C. Centrality in social networks conceptual clarification. Social Networks 1, 215–239, https://doi.org/10.1016/0378-8733(78)90021-7 (1978).
Riquelme Medina, I. & Lubovac-Pilav, Z. Gene Co-Expression Network Analysis for Identifying Modules and Functionally Enriched Pathways in Type 1 Diabetes. PloS one 11, e0156006, https://doi.org/10.1371/journal.pone.0156006 (2016).
Chiosis, G. Targeting chaperones in transformed systems–a focus on Hsp90 and cancer. Expert opinion on therapeutic targets 10, 37–50, https://doi.org/10.1517/14728222.10.1.37 (2006).
Koshimizu, T. A. et al. Inhibition of heat shock protein 90 attenuates adenylate cyclase sensitization after chronic morphine treatment. Biochemical and biophysical research communications 392, 603–607, https://doi.org/10.1016/j.bbrc.2010.01.089 (2010).
Neasta, J., Ben Hamida, S., Yowell, Q. V., Carnicella, S. & Ron, D. AKT signaling pathway in the nucleus accumbens mediates excessive alcohol drinking behaviors. Biological psychiatry 70, 575–582, https://doi.org/10.1016/j.biopsych.2011.03.019 (2011).
Croft, D. et al. The Reactome pathway knowledgebase. Nucleic acids research 42, D472–477, https://doi.org/10.1093/nar/gkt1102 (2014).
Ferri, C. P. et al. Global prevalence of dementia: a Delphi consensus study. Lancet (London, England) 366, 2112–2117, S0140-6736(05)67889-0 (2005).
Ernst, T., Chang, L., Leonido-Yee, M. & Speck, O. Evidence for long-term neurotoxicity associated with methamphetamine abuse: A 1H MRS study. Neurology 54, 1344–1349 (2000).
Serrano-Pozo, A., Frosch, M. P., Masliah, E. & Hyman, B. T. Neuropathological alterations in Alzheimer disease. Cold Spring Harbor perspectives in medicine 1, a006189, https://doi.org/10.1101/cshperspect.a006189 (2011).
Guo, Q., Robinson, N. & Mattson, M. P. Secreted beta-amyloid precursor protein counteracts the proapoptotic action of mutant presenilin-1 by activation of NF-kappaB and stabilization of calcium homeostasis. J Biol Chem 273, 12341–12351 (1998).
Liu, L. et al. Alpha7 nicotinic acetylcholine receptor is required for amyloid pathology in brain endothelial cells induced by Glycoprotein 120, methamphetamine and nicotine. Sci Rep 7, 40467, https://doi.org/10.1038/srep40467 (2017).
Christianson, H. C. & Belting, M. Heparan sulfate proteoglycan as a cell-surface endocytosis receptor. Matrix biology: journal of the International Society for Matrix Biology 35, 51–55, https://doi.org/10.1016/j.matbio.2013.10.004 (2014).
Ma, P. et al. Heparanase deglycanation of syndecan-1 is required for binding of the epithelial-restricted prosecretory mitogen lacritin. The Journal of cell biology 174, 1097–1106, jcb.200511134 (2006).
Bernfield, M. et al. Biology of the syndecans: a family of transmembrane heparan sulfate proteoglycans. Annual Review of Cell Biology 8, 365–393, https://doi.org/10.1146/annurev.cb.08.110192.002053 (1992).
Carey, D. J. Syndecans: multifunctional cell-surface co-receptors. The Biochemical journal 327(Pt 1), 1–16 (1997).
Choi, S. et al. Transmembrane domain-induced oligomerization is crucial for the functions of syndecan-2 and syndecan-4. The Journal of biological chemistry 280, 42573–42579, M509238200 (2005).
Hu, H. T., Umemori, H. & Hsueh, Y. P. Postsynaptic SDC2 induces transsynaptic signaling via FGF22 for bidirectional synaptic formation. Scientific reports 6, 33592, https://doi.org/10.1038/srep33592 (2016).
Chen, J. et al. Hypothalamic proteoglycan syndecan-3 is a novel cocaine addiction resilience factor. Nature communications 4, 1955, https://doi.org/10.1038/ncomms2955 (2013).
Cami, J. & Farre, M. Drug addiction. The New England journal of medicine 349, 975–986, https://doi.org/10.1056/NEJMra023160 (2003).
Goldstein, R. Z. & Volkow, N. D. Drug addiction and its underlying neurobiological basis: neuroimaging evidence for the involvement of the frontal cortex. Am J Psychiatry 159, 1642–1652, https://doi.org/10.1176/appi.ajp.159.10.1642 (2002).
Edwards, S. & Koob, G. F. Escalation of drug self-administration as a hallmark of persistent addiction liability. Behav Pharmacol 24, 356–362, https://doi.org/10.1097/FBP.0b013e3283644d15 (2013).
Mandyam, C. D. et al. Varied access to intravenous methamphetamine self-administration differentially alters adult hippocampal neurogenesis. Biological psychiatry 64, 958–965, https://doi.org/10.1016/j.biopsych.2008.04.010 (2008).
Recinto, P. et al. Levels of neural progenitors in the hippocampus predict memory impairment and relapse to drug seeking as a function of excessive methamphetamine self-administration. Neuropsychopharmacology 37, 1275–1287, https://doi.org/10.1038/npp.2011.315 (2012).
Schwendt, M. et al. Extended methamphetamine self-administration in rats results in a selective reduction of dopamine transporter levels in the prefrontal cortex and dorsal striatum not accompanied by marked monoaminergic depletion. J Pharmacol Exp Ther 331, 555–562, https://doi.org/10.1124/jpet.109.155770 (2009).
Yoon, S. S. et al. Acupuncture suppresses morphine self-administration through the GABA receptors. Brain research bulletin 81, 625–630, https://doi.org/10.1016/j.brainresbull.2009.12.011 (2010).
Cline, M. S. et al. Integration of biological networks and gene expression data using Cytoscape. Nature protocols 2, 2366–2382, https://doi.org/10.1038/nprot.2007.324 (2007).
Acknowledgements
This study was supported and funded by the Basic Science Research Program of the National Research Foundation of Korea (NRF), the Ministry of Education (NRF-2016R1A6A1A03011325) and the Bio & Medical Technology Development Program of the NRF, and the Ministry of Science, and ICT & Future Planning (NRF-2015M3A9E1028327).
Author information
Authors and Affiliations
Contributions
S.H.S. and W.J.J. performed the experiments and participated in writing the manuscript. J.H. performed the network analysis and wrote the manuscript. B.P., J.H.J., Y.H.S., and C.H.Y. participated in the experimental design and analysed the results. S.L. and C.H.J. were responsible for the study concept and design and supervised the manuscript editing.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Song, SH., Jang, WJ., Hwang, J. et al. Transcriptome profiling of whisker follicles in methamphetamine self-administered rats. Sci Rep 8, 11420 (2018). https://doi.org/10.1038/s41598-018-29772-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-29772-1
This article is cited by
-
Changes in digestive enzyme activities during the early ontogeny of the South American cichlid (Cichlasoma dimerus)
Fish Physiology and Biochemistry (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
