
Abstract
Even though ghost imaging (GI), an unconventional imaging method, has received increased attention by researchers during the last decades, imaging speed is still not satisfactory. Once the data-acquisition method and the system parameters are determined, only the processing method has the potential to accelerate image-processing significantly. However, both the basic correlation method and the compressed sensing algorithm, which are often used for ghost imaging, have their own problems. To overcome these challenges, a novel deep learning ghost imaging method is proposed in this paper. We modified the convolutional neural network that is commonly used in deep learning to fit the characteristics of ghost imaging. This modified network can be referred to as ghost imaging convolutional neural network. Our simulations and experiments confirm that, using this new method, a target image can be obtained faster and more accurate at low sampling rate compared with conventional GI method.
Similar content being viewed by others


Introduction
Ghost imaging (GI) is a relatively new imaging method compared with conventional imaging methods. Since the first GI experiment conducted by Pittman and Y.H.Shih in 19951, ghost imaging has made great progress and extended into many related fields2,3,4,5,6,7,8,9,10,11,12,13,14,15,16. Although GI shares a similar imaging scheme with single-pixel imaging (SPI), their studies were conducted separately in computer science and optics17. While GI has advantages over conventional imaging methods, its imaging speed (without substantial image quality loss) remains a big problem. Several attempts to improve the imaging speed were reported recently. Most of them focus on either improving the method of data acquisition18,19,20,21,22,23, or the processing method in GI24,25,26,27,28,29. A widely used method in ghost imaging is the basic correlation method1. Unfortunately, the basic correlation method requires long data acquisition times. Compressed sensing (CS) is increasingly used for GI because it permits the reconstruction of targets even at a low sampling rate30,31. O.S. Magana-Loaiza et al. proposed a proof-of-principle object-tracking protocol using a ghost imaging scheme32. They utilized the CS protocol to minimize both the number of photons and the number of measurements required to form a quantum image of the tracked object. Recently, Z. Yang et al. introduced a new technique, which allows sensing of an object with fewer measurements than to other schemes that use pixel-by-pixel imaging33. They achieved object identification with a technique based on CS, confirming the potential impact of CS. However, CS requires a large number of computations, causing long signal processing times that limit the imaging speed of GI.
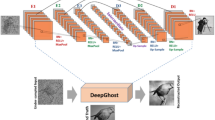
In this study, we focus on methods that can quickly reconstruct an image along with high accuracy, as well as reduce the computational effort. To achieve this, we replaced the current method for GI with a method that benefits from “deep learning”. Deep learning is the most popular system optimization method and represents an extension of machine learning. It is applicable to many domains of science, business and government34,35,36,37. We attempt to utilize the advantages of deep learning to enhance the performance of GI. More specifically, the goal of our technique is to reconstruct the target image quickly and accurately at low sampling rate. A novel deep learning ghost imaging (DLGI) method is proposed that is consistent with the GI principle. Although the CS algorithm has a large computational challenge to acquire an ideal target image, it can reconstruct a rudimentary target image quickly at low sampling rate. Therefore, the CS algorithm is utilized in the preprocessing procedure to obtain a rudimentary target image quickly as the input of the network. Within the broad field of deep learning, the convolutional neural networks (CNN) are widely used for image recognition38,39,40. Mousavi et al. proposed a fast reconstruction algorithm based on deep CNN network, which can reconstruct the original image with fewer sample points. The proposed method solves the problem of low efficiency and limited application conditions of CS algorithm41. Usually, the CNN output is a scalar that is defined as a classifier. Our goal is to complete the image reconstruction. Consequently, the input and output of conventional CNN are modified to fit our needs. The new CNN used in our DLGI method is called GI convolutional neural network (GICNN). By utilizing GICNN, input data at low sampling rate can be trained. As a result, a complete mapping can be built between the input data and the label. The target image can be quickly and accurately reconstructed at low sampling rate, when testing. The schematic diagram of the DLGI method is shown in Fig. 1.

Schematic Diagram of DLGI. y represents the data received by the bucket detector, A is the speckle irradiated on the target, and x is the target to be reconstructed. A rudimentary image of the target can be obtained quickly using a low sampling rate with the CS algorithm. This rudimentary image is used as the input of the GICNN. The image with full sampling rate is treated as the label. After training, the target image can be obtained quickly and accurately, even if data pass through the GICNN at a low sampling rate.
In this paper, a novel deep learning ghost imaging method is proposed, which has advantages both in calculation speed and image accuracy. A special convolutional neural network is designed according to the features of GI. Our method can also be used for other conventional imaging methods using similar imaging processes to GI.
Results
Our imaging configuration is based on the CGI framework8, as shown in Fig. 2, which consists of a target (an aircraft model), a Digital Micro-mirror Device (DMD), and a bucket detector. We used a CCD camera to simulate the bucket detector by summing all the pixels to obtain the whole intensity. The DMD projects a sequence of 64*64 random speckles onto the target, and the reflected light is detected by the CCD that gives the echo signals. Here, we define the full sampling rate as 4096 (64*64) detections. Correspondingly, 20% sampling rate stands for 819 detections.

Schematic of the Experiment. The target is an aircraft model. The DMD is placed slightly lower to avoid blocking the echo signal. The photon flux was about 30 μW/cm2. The distance between aircraft model and DMD is 27.5 cm. From aircraft model to CCD is 45 cm, and from CCD to DMD is 17.5 cm.
Simulation Testing
Firstly, we carried out numeriacal simulation for the whole imaging process based on the setup of Fig. 2. In order to train the GICNN, we randomly selected 100 samples with 20% sampling rate as training samples. Every sample has a label with full sampling rate. After training, 10 other samples were entered for testing. Three different sampling rates (5%, 10% and 20%) were selected to test the effect of DLGI method. The simulation testing results are shown in Fig. 3.

Simulation Results. (a–d) Show the four different attitudes, respectively. The first line is 5% sampling rate. The second line is 10% sampling rate. The third line is 20% sampling rate.
Independent of the sampling rate, the system is capable of obtaining the target image from a rudimentary input. With such low sampling rates, both the basic correlation method and the CS algorithm cannot acquire a clear target image quickly. The image qualities improve with increasing sampling rates. Furthermore, we changed the attitude of the target for training and testing to better demonstrate the GICNN. The head of aircraft is rotated 90 degrees, 180 degrees and 270 degrees, respectively. It can be seen from Fig. 3(a–d) that we can obtain the target image from the rudimentary input regardless of attitude. The simulation was conducted to verify the method. To better demonstrate our method, a real scene physical experiment is carried out below.
Physical Experiment
The schematic of the physical experiment is shown in Fig. 2. We performed 300000 bucket detections to form sample set. Subsequently, 200 samples were randomly selected from the sample set for training, and 100 other samples were randomly selected from sample set for testing. Similarly, the GICNN was trained at 20% sampling rates. The 5% sampling rates, 10% sampling rates, 15% sampling rates and 20% sampling rates were tested. The experimental results are shown in Fig. 4.

Experimental Results. (a–d) Show the results of the aircraft model at different attitudes using 5%, 10%, 15% and 20% sampling rates, respectively. (e) Is the training label obtained by the CCD camera.
Figure 4 shows that a clear target image can be obtained after the testing data had passed through the network. As the sampling rate increases, the image becomes clearer. When the sampling rate reaches 20%, the target image can be practically reconstructed. We compared DLGI with other conventional GI algorithms with respect to peak signal-to-noise-ratio (PSNR) and imaging time. Note that, data collection time was not considered in our comparison, the results are the pure time consuming of reconstruction.
Table 1 shows that the DLGI method shortens the imaging time considerably. When the PSNR of the output images are similar (about 26 dB, just like the image quality in Fig. 4(d)), the DLGI method at 20% sampling rate is much faster than the basic correlation method and the CS algorithm. In our physical experiment, the sparsity of the aircraft scene is low. Therefore, the PSNR of CS result is not ideal with under-sampling. To compare with other methods under similar PSNR, the sampling rate for CS was also full sampling rate. As mentioned at the beginning of the results section, the full sampling means 4096 (64*64) detections. Note that, the results of DLGI method at other sampling rates are also much faster than both the basic correlation method and the CS algorithm. As the sampling rate increases, the imaging time decreases. The time of transforming the echo signal into a rudimentary image was not been considered, which was less than 1 second. Despite the transformation time, the results of DLGI method are still much faster than other methods. In addition, we added different levels of noise during the data acquisition process in our experiment. In particular, we selected 0 dB, -5 dB, -10 dB, -15 dB and -20 dB for a comparison. The image qualities were evaluated based on PSNR. The results of the comparison are shown in Fig. 5.

Results of the Comparison. The CS algorithm, basic correlation method and DLGI method with four different sampling rates (5%, 10%, 15% and 20%) were selected in our comparison experiments.
Figure 5 shows that the image qualities improve with the increasing of the measurement SNR. However, the image qualities of the DLGI method are significantly better than the other methods under all levels of the measurement SNR. The best performance is the DLGI method at 20% sampling rate. Even though the image qualities of the CS algorithm and basic correlation method do not differ a lot from the DLGI method, their required processing-times are much longer than the DLGI method - see Table 1.
Diverse Scenes
In order to study the applicability of our method in different complexities scenes, we carried out different nature scenes including the cat and Lena. The results are shown in Fig. 6.

Results of Diverse Scenes. (a–c) Show the input, the reconstructed result and the target, respectively.
The amount of training data were all 500 samples for the two scenes. The PSNR of the cat in Fig. 6(b) is 16.3713 dB, and Lena is 15.1714 dB. The results show that the simple scenes (the cat) can obtain better results under same amount of training data. Then, we increased the training data of complex scenes (Lena).
We increased the amount of training data of Lena from 500 samples to 1000 samples. The PSNR of Lena in Fig. 7(c) is 16.0147 dB. Figure 7 shows that with the increase in the amount of training data, the reconstruction results of complex scenes are enhanced. The above results indicate that different complexities scenes require different amount of training data. The complex scenes require large amount of training data, and the simple scenes require small.

Results of Increasing the Amount of Training Data. (a–d) Show the input, the reconstructed result under 500 samples, the reconstructed result under 1000 samples and the target, respectively.
Discussion
Our study presents a novel deep learning GI method. The optimization through artificial intelligence has been successfully used in many other fields, we investigated this possibility in this paper. GI utilizes the correlation between reference arm and signal arm to complete the image reconstruction of the target1. CGI uses calculation instead of detection to obtain the information in the reference arm8. In other words, GI is an imaging method, where a target is reconstructed from the received signal if the detection signal is known and random. Figure 8 shows the different methods involved in GI.

Different Processing Methods of GI. The current mainstream ghost imaging processing methods are given.
Performing the correlation calculation between echo signal and the independent speckle patterns at target plane directly is the basic correlation method.
where 〈·〉 means the ensemble average. I b represents the echo signal that the bucket detector received and I(x, y) represents the speckle patterns distribution in the target plane. Subsequently, the target image can be obtained through normalized correlation calculation between them. Although this method is simple, the effective is low. The CS algorithm we employed is fast iterative shrinkage threshold algorithm (FISTA)42,43. FISTA is suitable for the preprocessing procedure reconstruction because it converges quickly. The reconstruction model, based on FISTA, can be summarized as follow
where α = Ψ · X denotes the sparse in the representation basis Ψ, λ is regularization parameter. y represents the data received by the bucket detector, A represents the speckle patterns at the target plane, and X represents the target to be reconstructed.
All methods require the independent speckle patterns at target plane as well as an echo signal, but the method we proposed is different from the basic correlation method and the CS algorithm. Our approach does not change the data acquisition procedure of conventional GI method, it opens doors to improvement using modern deep learning principles. Optimization using the model in Eq. (2) can quickly produce a rudimentary target image for CNN. CNN utilizes several layers like convolution layer, pooling layer and linear layer to extract the characteristics of the input image. By constantly training and adjusting the parameters within the network, CNN can perform complete mapping between input and output. In the convolution layer, a weight matrix was utilized to extract the feature information from the input image, which can be regarded as a filter. The filter moves on the picture at a certain step size. A combination of different weight is used to extract a feature class. Another combination of weight is used to extract another feature type. It is necessary to learn the parameters from the input image to extract information so that the network can perform a correct prediction. As the network structure becomes deeper, the characteristics of weight matrix extraction become more complex and increasingly applicable to solve the given problem. The convolution parameters affect the result greatly. Sometimes the image is too large and we need to reduce the number of training parameters. It is necessary to introduce the pooling layer periodically between the convolution layers to reduce the image size. The ramp function is chosen as the activation function. Normally, a conventional linear layer outputs various classes to produce a one-dimensional vector to output the most likely of them. We redesigned the the output of the linear layer to obtain the target image. From the above simulations and experiments we can see that the DLGI method we proposed is effective, and deep learning can be used successfully in GI. The target can be reconstructed by our method should be in the data set that we have trained. The more kinds of targets are trained, the more targets can be reconstructed. Meanwhile, the applicability of our method for an unknown target imaging will be the focus of our next step.
In conclusion, a novel deep learning GI method is proposed. We modify the convolution neural network according to the features of GI. Then, a clear target image can be obtained when the under sampled data pass through our trained network. A series of simulations and experiments results show that the DLGI method can obtain the target image faster and more accurate at low sampling rate compared with conventional GI method. Our method provides a way of introducing the artificial intelligence into GI. Moreover, other imaging methods similar to GI process can be applied to our method.
Methods
In this section, a detailed introduction to the network in DLGI method is presented. Because the CNN requires a picture as the input, a preprocessing procedure is added. The purpose of the preprocessing procedure is to complete the initial image reconstruction so that the rudimentary target image can be offered to CNN. The CS algorithm is utilized to obtain the rudimentary target image. Convolution layer, pooling layer and linear layer are selected to build our network. We added the ramp function between conv1 and pool1, conv2 and pool2, pool2 and linear to eliminate the negative number. Note that, the output of the linear layer was redesigned to produce the target image. The linear layer contains each pixel of the target image. Each pixel has its own weight, and the weight parameters are continually adjusted according to the input during the training process. Depending on the size of the desired output image, we reshaped this one-dimensional vector into the output target image. The number of pixels in the final output target image is equal to that in the one-dimensional vector. The normalized mean squared error (NMSE) is used as a loss function to adjust the difference between the output and the label. We used Mathematica 11.1 and a desktop computer with an NVIDIA Quadro K4000 graphics card to train our network. The network is shown in Fig. 9.

Schematic of the Network. Our network consists of two convolution layers, two pooling layers and one linear layer. The ramp function was added to serve as activation function between the first convolutional layer and the pooling layer, between the second convolutional layer and the pooling layer, as well as between the second pooling layer and the last linear layer.
References
Pittman, T. B., Shih, Y. H., Strekalov, D. V. & Sergienko, A. V. Optical imaging by means of two-photon quantum entanglement. Phys. Rev. A 52, 3429–3432 (1995).
Bennink, R. S., Bentley, S. J. & Boyd, R. W. Two-photon coincidence imaging with a classical source. Phys. Rev. Lett. 89, 113601 (2002).
Gatti, A. et al. Ghost Imaging with Thermal Light: Comparing entanglement and classical correlation. Phys. Rev. Lett. 93, 093602 (2004).
Gatti, A., Brambilla, E., Bache, M. & Lugiato, L. A. Correlated imaging, quantum and classical. Phys. Rev. A 70, 013802-1–013802-10 (2004).
Valencia, A. et al. Two-photon imaging with thermal light. Phys. Rev. Lett. 94, 063601 (2005).
Ferri F. et al. High resolution ghost imaging experiments with classical thermal light. European Quantum Electronics Conference. IEEE 257 (2005).
Shih, Y. Quantum imaging. IEEE J. Sel. Topics Quantum Eletron. 13, 1016–1030 (2007).
Shapiro, J. H. Computational ghost imaging. Phys. Rev. A. 78, 061802 (2008).
Meyers, R., Deacon, K. S. & Shih, Y. H. Ghost-imaging experiment by measuring reflected photons. Physics Review A 77, 041801 (2008).
Shih, Y. The physics of ghost imaging. J. Quantum Inf. Process. 11, 949–993 (2012).
Sammy, R. & Adesso, G. Nature of light correlations in ghost imaging. Scientific Reports 2, 651 (2012).
Jeffrey, H. S. et al. Ghost Imaging without Discord. Scientific Reports 3, 1849 (2013).
Gong, W. & Han, S. High-resolution far-field ghost imaging via sparsity constraint. Scientific Reports 5, 9280 (2015).
Gong, W. High-resolution pseudo-inverse ghost imaging. Photonics Research 5, 234–237 (2015).
Luo, C., Xu, H. & Cheng, J. High-resolution ghost imaging experiments with cosh-Gaussian modulated incoherent sources. Journal of the Optical Society of America A Optics Image Science & Vision 3, 482–5 (2015).
Luo, C. L. & Zhuo, L. Q. High-resolution computational ghost imaging and ghost diffraction through turbulence via a beam-shaping method. Laser Physics Letters 1, 015201 (2017).
Bian L, Suo J, Dai Q, F Chen. Experimental comparison of single-pixel imaging algorithms. arXiv:1707.03164 (2017).
Gong, W. et al. Three-dimensional ghost imaging lidar via sparsity constraint. Scientific Reports 6, 26133 (2016).
Liu, Z. et al. Spectral camera based on ghost imaging via sparsity constraints. Scientific Reports 6, 25718 (2016).
Sun, S. et al. Multi-scale Adaptive Computational Ghost Imaging. Scientific Reports 6, 37013 (2016).
Dong, S., Zhang, W., Huang, Y. & Peng, J. Long-distance temporal quantum ghost imaging over optical fbers. Scientific Reports 6, 26022 (2016).
Yuwang, W. et al. High speed computational ghost imaging via spatial sweeping. Scientific Reports 7, 45323 (2017).
Hartmann, S. & Elsäßer, W. A novel semiconductor-based, fully incoherent amplifed spontaneous emission light source for ghost imaging. Scientific Reports 7, 41866 (2017).
Katz Ori, Y., Bromberg & Silberberg, Y. Ghost Imaging via Compressed Sensing. Frontiers in Optics Optical Society of America (2009).
Jiying, L., Jubo, Z., Chuan, L. & Shisheng, H. High-quality quantum imaging algorithm and experiment based on compressive sensing. Opt. Lett. 35, 1206–1208 (2010).
Katkovnik, V. & Astola, J. Compressive sensing computational ghost imaging. Journal of the Optical Society of America A 29, 1556–1567 (2012).
Dong, X. L. Application of compressed sensing in ghost imaging system. Journal of Signal Processing (2013).
Abmann, M. & Bayer, M. Compressive adaptive computational ghost imaging. Scientific Reports 3, 1545 (2013).
Li, L. Z. et al. Super-resolution ghost imaging via compressed sensing. Acta Physica Sinica 63, 224201 (2014).
Candes, E. J., Wakin, M. B. & Wakin, M. B. An introduction to compressive sampling. IEEE Signal Process. Mag. 25(2), 21-30. IEEE Signal Processing Magazine, 25, 21–30 (2008).
Candès, E. J. The restricted isometry property and its implications for compressed sensing. Comptes Rendus Mathematique 346, 589–592 (2008).
Magana-Loaiza, O. S., Howland, G. A., Malik, M. & Howell, J. C. Compressive object tracking using entangled photons. Applied Physics Letters 23, 231104–231104-4 (2013).
Yang, Z. et al. Digital spiral object identification using random light. Light: Science & Applications 6, e17013 (2017).
Goldberg, D. E. Genetic Algorithms in Search. Optimization and Machine Learning 7, 2104–2116 (1990).
Hinton, G. E., Osindero, S. & Teh, Y. W. A fast learning algorithm for deep belief nets. Neural Computation 18, 1527 (2006).
Seeger, M. Gaussian processes for machine learning. International Journal of Neural Systems 14, 69–106 (2008).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Lawrence, S., Giles, C. L. & Tsoi, A. C. et al. Face recognition: a convolutional neural-network approach. IEEE Transactions on Neural Networks 8, 98–113 (1997).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. International Conference on Neural Information Processing Systems, 1097–1105 (2012).
Ren, S. et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis & Machine Intelligence 39, 1137 (2017).
Mousavi, A. & Baraniuk, R. G. Learning to invert: Signal recovery via Deep Convolutional Networks. IEEE International Conference on Acoustics, 2272–2276 (2017).
Beck, A. & Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM journal on imaging sciences 2, 183–202 (2009).
Bhotto, M. Z. A., Ahmad, M. O. & Swamy, M. N. S. An improved fast iterative shrinkage thresholding algorithm for image deblurring. SIAM journal on imaging sciences 8, 1640–1657 (2015).
Acknowledgements
This work was supported by 111 Project of China (Grant No. B14040), Shaanxi Provincial Postdoctoral Science Foundation No. 2017BSHYDZZ13, Shaanxi Provincial Natural Science Foundation under Grant 2017ZDXM-GY-009, National Natural Science Foundation of China (No. 61471292, 61501365, 61471388, 61331005, 11503020).
Author information
Authors and Affiliations
Contributions
Y. He and G. Wang proposed the scheme and designed the simulations and experiments. G. Dong, S. Zhu and H. Chen conducted data processing and analyzing. Y. He wrote the manuscript. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
He, Y., Wang, G., Dong, G. et al. Ghost Imaging Based on Deep Learning. Sci Rep 8, 6469 (2018). https://doi.org/10.1038/s41598-018-24731-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-24731-2
This article is cited by
-
Deep learning approach for denoising low-SNR correlation plenoptic images
Scientific Reports (2023)
-
Far-field super-resolution ghost imaging with a deep neural network constraint
Light: Science & Applications (2022)
-
Deep unfolding for singular value decomposition compressed ghost imaging
Applied Physics B (2022)
-
Improving the performance of ghost imaging via measurement-driven framework
Scientific Reports (2021)
-
A residual-based deep learning approach for ghost imaging
Scientific Reports (2020)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
