
Abstract
Cardiovascular disease is the leading cause of death among patients receiving peritoneal dialysis. We aimed to develop and validate a risk prediction model for cardiovascular death within 2 years after the initiation of peritoneal dialysis (PD). A cohort including all patients registered with the Henan Peritoneal Dialysis Registry (HPDR) between 2007 and 2014. Multivariate logistic regression analysis was used to develop the risk prediction model. The HPDR data was randomly divided into two cohorts with 60% (1,835 patients) for model derivation, and 40% (1,219 patients) for model validation. The absolute rate of cardiovascular mortality was 14.2% and 14.4 in the derivation and validation cohort, respectively. Age, body mass index, blood pressure, serum lipids, fasting glucose, sodium, albumin, total protein, and phosphorus were the strongest predictors of cardiovascular mortality in the final model. Discrimination of the model was similar in both cohorts, with a C statistic above 0.70, with good calibration of observed and predicted risks. The new prediction model that has been developed and validated with clinical measurements that are available at the point of initiation of PD and could serve as a tool to screen for patients at high risk of cardiovascular death and tailor more intensive cardio-protective care.
Similar content being viewed by others

Introduction
In developing countries, the risk of mortality with end stage renal disease (ESRD) remains high, with cardiovascular disease (CVD) the primary cause of death1,2. Technological advances have allowed peritoneal dialysis (PD) to be increasingly applied to ESRD patients, especially in developing countries3,4,5. Despite these advances, mortality risk often remains high among ESRD patients accepting PD care2. Several risk prediction models have been developed to predict the future all-cause mortality risk among patients undergoing hemodialysis and PD, in both developed countries and developing coun tries5,6,7,8.
However, although CVD is the primary cause of mortality among patients with ESRD, for which successful preventative interventions exist, no risk prediction models have been developed identify patients receiving PD care, who have not received appropriate interventions previously and could benefit from cardio-protective interventions, or who have received interventions and not attained control threshold and could benefit from intensive cardio-protective interventions. Moreover, unlike patients under health care systems in many western countries, in developing countries, valid health information is difficult to obtain as a result of limited primary or secondary care systems able to accurately report pre-existing conditions and comorbidities4,9,10. Depending upon patient self-reported history may be misleading in this setting, we therefore wished to develop risk equations that could predict future CVD mortality largely using objective clinical data likely to be available in developing countries. Our study aimed to develop and validate a risk prediction model for predicting 2-year CVD mortality among people initialising PD care.
Results
Study participants
In our derivation cohort, we analysed information on 1,835 patients with 261 cardiovascular deaths within 2 years of initialisation of PD. The validation cohort had information on 1,219 patients with 176 cardiovascular deaths. Table 1 summarises the basic characteristics of the study population: patients in both cohorts had broadly similar characteristics.
Model development, performance measure, and validation
Univariate association between cardiovascular mortality and candidate predictors are listed in supplemental Table 1. Of the 26 candidate predictors, 11 were statistically significantly associated with cardiovascular mortality in our final multivariable model (Table 2). Table 3 shows apparent and internal validation performance statistics of our risk prediction model. After adjustment for optimism, our final risk prediction model was able to discriminate patients receiving PD care with and without cardiovascular mortality with a C statistics of 0.7318 (95% confidence interval 0.6988 to 0.7648). The agreement between the observed and predicted proportion of events showed good apparent calibration (Fig. 1, left), but a uniform shrinkage factor of 0.026 was needed to adjust predictors coefficients in the final model for optimism (Table 3). Box-1 shows our final risk prediction model, including real examples to illustrate the risk prediction equations.

Assessing calibration in the derivation cohort (left) and the derivation cohort (right).
Applying our final risk prediction model (supplemental Box-S1) to the validation cohort gave a C statistic of 0.7205 (0.6798 to 0.7613) and good calibration (Fig. 1, right), with calibration slope only slightly above 1 (Table 3). The performance of our model at various arbitrary thresholds in shown in Table 4.
Disscussion
Main findings
We have developed and validated a new risk prediction model to calculate the absolute risk of cardiovascular mortality during the first 2 years of initialisation of PD in a representative sample of patients receiving PD care in Henan, the province with the largest population size in China. Overall, our prediction model had good calibration and useful discrimination, with a C statistic of greater than 0.70 in both derivation and calibration cohorts data.
Strength and limitation of study
Our risk prediction algorithm has several advantages over those in use in many developing countries. The model is based on absolute risks determined and validated in two cohorts. It is built from reliable clinical variables that are usually examined among patients receiving PD care, implying that it can be readily applied in clinical practice and is amenable to further external validation in many regions and countries that provide routine PD care.
The methods used to derive and validate the model are similar to those for other risk prediction algorithms derived from the CPRD and QResearch databases11,12. The dataset used in this dataset was the largest dataset used for risk predictions among patients receiving PD care. The HPRD is the only PD registry data in Henan including all patients receiving PD care in Henan who will be followed up for their lifetime; therefore selection bias and respondent bias were relatively small in this study. The HPRD is located in Henan, the province with the largest population size in China, suggesting our study is likely to be a representativeness sample.
There were some limitations in our study. First, there was some distinctive difference between the patients in our study and typical European ESRD patients, for example, young age, lower BMI, lower prevalence of comorbidities and lower percentage of treatment, which suggested potential adjustments might be needed when applied our risk algorithm into external ESRD population, especially European ESRD populations. Second, some traditional risk factors, like smoking and prior health information were not accessible in our study. Third, the relative high missing percentage of some variables, for example, phosphorus and albumin might have some impact on extrapolation of our models especially in the external population, our risk algorithms were derived from imputed datasets though. Fourth, although our risk algorithm was helpful in populations where the access or the validity of previous information on cardiovascular risk factors and comorbidity were restricted, the external validation in more typical cohorts would still be warranted. Fifth, the threshold of absolute risk to define “high-risk” patients was not provided in this study, several thresholds as illustrations were provided though, as the definition would need to balance risks and benefits for patients and analyse cost effectiveness, which exceeded our study scope. Sixth, there were some calibration differences observed between the derivation and validation cohorts, with some predictors, particularly, higher transferrin levels, observed in the validation cohort.
The selection of predictors
All available variables in HPDR were reviewed by 5 independent clinicians and processed as candidate predictors following a consensus process. Our predictive model differs from existing algorithms developed in developed countries, by excluding multimorbidities, to take account of the difficulty in accessing such data which are not routinely recorded in the under-developed primary care system in China. The comorbidities, like existing cardiovascular disease, were eliminated by the final model, which might be explained by they are both common between patients with and without outcomes13.
The majority of predictors in our final model incorporated accurate and reliable clinical measurements9, which were usually examined at the time of entry into PD and were more likely to be accessible across PD clinics in China5. Moreover, our limited utilisation of self-reported information should lead to minimal recall bias. Our predictive algorithm can be easily validated with other external datasets.
Comparison with other studies
Mortality among patients undergoing PD varies with the ethnicity of the population, the characteristics within different datasets and lengths of follow-up time14. The PD registration dataset reported 29.7% all-cause mortality within 3 years7 and another Chinese study presented all-cause mortality as 19.4% within two years8. Cardiovascular mortality in a small dataset from Hong Kong, China, was 23.8% within 4 years15. On consideration of the lengths of follow-up time, our cardiovascular mortality of 14%, was comparable to other studies in Chinese PD populations.
In the risk prediction models for all-cause mortality in people receiving PD care, both the haemoglobin and albumin have been consistently associated with all-cause mortality6,7,15, as found in our study. In another Chinese cohort, fasting glucose, and diastolic blood pressure were also used in the prediction algorithm8, with similar associations identified in our study. Other established risk factors for cardiovascular mortality, like low density lipoprotein, systolic blood pressure, total cholesterol, and body mass index in general population were also utilised in our predictive algorithms16,17. Some novel predictors were introduced in our model, for example, total protein, sodium, phosphate. Both creatinine and eGFR used in prediction of all-cause mortality18,19 were eliminated by our final model. Different outcomes and variation between of datasets could be the reason20, and the sole utilisation of complete datasets or drop-off participants with missing values could be another reason21. In our prediction model, according to TRIPOD guidance14, we reported the percentage of missing variables and implemented multiple imputation both in our derivation and validations cohorts. In the model with imputed datasets, both creatinine and eGFR were eliminated by the final model. Unlike prediction tools developed in developed countries, little information on comorbidities or lifestyle factors were utilised in our model (like other models derived in Chinese populations) due to the difference in the care system and inaccurate self-reported information9,22.
Conclusion
We have developed and validated new risk prediction equations to quantify the absolute risks of cardiovascular mortality within two years in patients initialising PD care. Our study has two important implications for clinical practices. Firstly, our prediction model can be used as a tool to identify patients at high risk of cardiovascular mortality within two years of initiation of PD care. The algorithms are based on standard clinical measurements that are likely to be available at the point of initialisation of PD care. Secondly, our risk prediction model could be used to establish new treatment thresholds in clinical practice through consensus development of national guidance to provide intensive cardio-protective intervention to improve the survival probability in patients with high risks of cardiovascular mortality.
Methods
Data source and study population
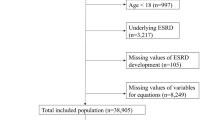
For this study, we used data from the Henan Peritoneal Dialysis Registry (HPDR) to develop and validate the risk score. Henan is a province in the Central of China with the population over 100 million. Briefly, the HPDR is operated under the auspices of the Department of Nephrology, the First Affiliated Hospital of Zhengzhou University and provides an independent audit and analysis of renal care in Henan, China. During the study period, information was prospectively collected electronically from all renal units across Henan. Data arriving at the HPDR are subjected to an algorithm which identifies suspicious values, which are then further verified and corrected where necessary by contacting the renal unit. This study was designed as a cohort study, which included all adults aged more than 18 years who commenced PD between 2007–2014 and who had at least two years’ follow-up. Patients who died, underwent transplant or whose kidney function recovered within 90 days after initialisation of dialysis were excluded (n = 16) to avoid a reverse causality association between predictors and outcome. This reflects the standard approach to investigating “real” ESRD patients among all those receiving PD care. We randomly allocated two thirds of patients to the derivation dataset and the remaining one third to a validation dataset. Ethics approval was granted by the Clinical Research Ethics Committee of the First Affiliated Hospital of Zhengzhou University. Written informed consent was obtained from all participants before inclusion.
Defining outcome, predictors, missing data and power calculation
We defined our primary outcome as recorded death with clinically diagnosed cardiovascular disease23,24. All available information, including demographic characteristics, self-reported comorbidities, and clinical measurements at the time of patients initialising the PD were evaluated by 5 clinicians. Predictors with agreement (≥3 clinicians) were included in the analysis for further evaluation as candidate predictors. Backward elimination in a multivariate logistic regression model, with inclusion of all candidate predictors, was applied to select the predictors for the final model. For predictors used in the final model, our derivation cohort had missing information on body mass index (13.51%), phosphorus (20.92%), albumin (19.92%), total protein (22.57%), total cholesterol (24.25%), low density lipoprotein (24.58%), fasting glucose (15.92%), sodium (8.02%), systolic blood pressure (4.82%), and diastolic blood pressure (4.82%). We used multiple imputation to replace missing values by using a chained equation approach based on all candidate predictors. We created 30 imputed datasets for missing variables that were then combined across all datasets by using Rubin’s rule to obtain final model estimates. With 261 cardiovascular deaths during the first two years of initiation of PD and 12 predictors in the final derivation cohort, we had an effective sample size of 14 final events per predictor, above the minimum requirement suggested by Peduzzi et al.25.
Statistical analysis for model derivation and validation
The methodology used in a previous prediction model was used in this study to derive and validate our risk algorithm12. We treated CVD mortality during the first two years of initialisation of PD as a binary outcome measure. For each candidate variable, we used a univariable logistic regression model to calculate the unadjusted odds ratio. Through backward elimination, we excluded candidate predictors from the multivariable model that were not statistically significant (P > 0.1 based on change in log likelihood)26. After elimination, we reinserted excluded predictors into the final model to further check whether they became statistically significant. We used fractional polynomials to model potential non-linear relations between outcome and continuous variables11. We also re-checked fractional polynomial terms at this stage and re-estimated them where necessary. We formed the risk equation for predicting the log odds of cardiovascular mortality by using the estimated β coefficients multiplied by the corresponding predictors included in our model, together with the average intercept across patient clusters. This process ultimately led to an equation for the predicted absolute risk of cardiovascular mortality: predicted risk = 1/(1 + e-riskscore), where the “risk score” is the predicted log odds of cardiovascular mortality from the developed model12.
We assessed the performance of the model in terms of the C statistic and calibration slope. The C statistic represents the probability that for any randomly selected patient with or without final event, the patient who had a final event had a higher predicted risk. A value of 0.50 represents no discrimination and 1.00 represents perfect discrimination. We then did internal validation to correct measures of predictive performance for optimism (over-fitting) by bootstrapping 100 samples of the derivation data. We repeated the model development process in each bootstrap sample (as outlined above, including variable selection) to produce a model, applied the model to the same bootstrap sample to quantify apparent performance, and applied the model to the original dataset to test model performance (calibration slope and C statistic) and optimism (difference in test performance and apparent performance). We then estimated the overall optimism across all models (for example, derive shrinkage coefficient = average calibration slope from each of the bootstrap samples)14. To account for over-fitting during the development process, we multiplied the original β coefficient by the uniform shrinkage factor in the final model. We re-estimated the intercept on the basis of the shrunken β coefficients to ensure that overall calibration was maintained, producing a final model.
We applied our risk prediction model to each patient in the validation cohort on the basis of the presence of one or more risk factors (Box 1). We examined the performance of this final model in terms of discrimination by calculating C statistics. We examined calibration by plotting agreement between predicted and observed risks across tenth of predicted risk.
We used Stata version 14 for all statistical analyses. This study was conducted and reported in line with the Transparent Reporting of a multivariate prediction model for individual Prediction or Diagnosis (TRIPOD) guidelines27.
Data Availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Change history
12 April 2018
A correction to this article has been published and is linked from the HTML and PDF versions of this paper. The error has been fixed in the paper.
References
Chow, F. Y., Polkinghorne, K. R., Chadban, S. J., Atkins, R. C. & Kerr, P. G. Cardiovascular risk in dialysis patients: a comparison of risk factors and cardioprotective therapy between 1996 and 2001. Nephrology (Carlton) 8, 177–183 (2003).
Herzog, C. A. et al. Cardiovascular disease in chronic kidney disease. A clinical update from Kidney Disease: Improving Global Outcomes (KDIGO). Kidney Int. 80, 572–586 (2011).
Yao, Q. & Duddington, M. Peritoneal dialysis in China. Perit. Dial. Int. 34(Suppl 2), S29–30 (2014).
Abraham, G. & Gupta, A. Safe and Cost-Effective Peritoneal Dialysis Access by Skilled Nephrologists in Developing Countries. Perit. Dial. Int. 36, 587–588 (2016).
Lin, S. Nephrology in China: a great mission and momentous challenge. Kidney Int. Suppl. 83, S108–10 (2003).
Sun, I. O. et al. Clinical significance of red blood cell distribution width in the prediction of mortality in patients on peritoneal dialysis. Kidney Res. Clin. Pract. 35, 114–118 (2016).
Wagner, M. et al. Predicting mortality in incident dialysis patients: an analysis of the United Kingdom Renal Registry. Am. J. Kidney Dis. 57, 894–902 (2011).
Zhao, C. et al. Risk score to predict mortality in continuous ambulatory peritoneal dialysis patients. Eur. J. Clin. Invest. 44, 1095–1103 (2014).
Hemke, A. C., Heemskerk, M. B., van Diepen, M., Dekker, F. W. & Hoitsma, A. J. Improved Mortality Prediction in Dialysis Patients Using Specific Clinical and Laboratory Data. Am. J. Nephrol. 42, 158–167 (2015).
Struijk, D. G. Peritoneal Dialysis in Western Countries. Kidney Dis. (Basel) 1, 157–164 (2015).
Hippisley-Cox, J., Coupland, C., Robson, J. & Brindle, P. Derivation, validation, and evaluation of a new QRISK model to estimate lifetime risk of cardiovascular disease: cohort study using QResearch database. BMJ 341, c6624 (2010).
Sultan, A. A. et al. Development and validation of risk prediction model for venous thromboembolism in postpartum women: multinational cohort study. BMJ 355, i6253 (2016).
Debray, T. P. et al. A new framework to enhance the interpretation of external validation studies of clinical prediction models. J. Clin. Epidemiol. 68, 279–289 (2015).
Moons, K. G. et al. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): explanation and elaboration. Ann. Intern. Med. 162, W1–73 (2015).
Wang, A. Y. et al. Long-term mortality and cardiovascular risk stratification of peritoneal dialysis patients using a combination of inflammation and calcification markers. Nephrol. Dial. Transplant. 24, 3826–3833 (2009).
Collins, G. S. & Altman, D. G. An independent external validation and evaluation of QRISK cardiovascular risk prediction: a prospective open cohort study. BMJ 339, b2584 (2009).
Hippisley-Cox, J. & Coupland, C. Derivation and validation of updated QFracture algorithm to predict risk of osteoporotic fracture in primary care in the United Kingdom: prospective open cohort study. BMJ 344, e3427 (2012).
Boyle, S. M., Li, Y., Wilson, F. P., Glickman, J. D. & Feldman, H. I. Association of Alternative Approaches to Normalizing Peritoneal Dialysis Clearance with Mortality and Technique Failure: A Retrospective Analysis Using the United States Renal Data System-Dialysis Morbidity and Mortality Study, Wave 2. Perit. Dial. Int. 37, 85–93 (2017).
Tamayo Isla, R. A. et al. Baseline Predictors of Mortality among Predominantly Rural-Dwelling End-Stage Renal Disease Patients on Chronic Dialysis Therapies in Limpopo, South Africa. PLoS One 11, e0156642 (2016).
Riley, R. D. et al. External validation of clinical prediction models using big datasets from e-health records or IPD meta-analysis: opportunities and challenges. BMJ 353, i3140 (2016).
van Staa, T. P., Gulliford, M., Ng, E. S., Goldacre, B. & Smeeth, L. Prediction of cardiovascular risk using Framingham, ASSIGN and QRISK2: how well do they predict individual rather than population risk? PLoS One 9, e106455 (2014).
Chen, J. Y. et al. A comorbidity index for mortality prediction in Chinese patients with ESRD receiving hemodialysis. Clin. J. Am. Soc. Nephrol. 9, 513–519 (2014).
Yu, D. & Simmons, D. Association between blood pressure and risk of cardiovascular hospital admissions among people with type 2 diabetes. Heart 100, 1444–1449 (2014).
Yu, D. & Simmons, D. Association between pulse pressure and risk of hospital admissions for cardiovascular events among people with Type 2diabetes: a population-based case-control study. Diabet. Med 32, 1201–1206 (2015).
Peduzzi, P., Concato, J., Kemper, E., Holford, T. R. & Feinstein, A. R. A simulation study of the number of events per variable in logistic regression analysis. J. Clin. Epidemiol. 49, 1373–1379 (1996).
Payne, B. A. et al. A risk prediction model for the assessment and triage of women with hypertensive disorders of pregnancy in low-resourced settings: the miniPIERS (Pre-eclampsia Integrated Estimate of RiSk) multi-country prospective cohort study. PLoS Med. 11, e1001589 (2014).
Collins, G. S., Reitsma, J. B., Altman, D. G. & Moons, K. G. Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD). Ann. Intern. Med. 162, 735–736 (2015).
Acknowledgements
We thank the First Affiliated hospital of Zhengzhou University approved this study. We thank Henan Peritoneal Dialysis Registry (HPDR) to provide the data for this study.
Author information
Authors and Affiliations
Contributions
D.Y. analysed the data and drafted the manuscript; Y. Cai. revised the statistical methods and revised the manuscript; Y. Chen. validated the method and re-analysed the data independently; T.C. and R.Q. revised the manuscript; D.S. designed the analysis framework and revised manuscript; Z.Z. designed the study, revised the analysis framework, revised the manuscript and interpreted the findings.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yu, D., Cai, Y., Chen, Y. et al. Development and validation of risk prediction models for cardiovascular mortality in Chinese people initialising peritoneal dialysis: a cohort study. Sci Rep 8, 1966 (2018). https://doi.org/10.1038/s41598-018-20160-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-20160-3
This article is cited by
-
Triglyceride glucose-body mass index and cardiovascular mortality in patients undergoing peritoneal dialysis: a retrospective cohort study
Lipids in Health and Disease (2023)
-
Prediction model for cardiovascular disease risk in hemodialysis patients
International Urology and Nephrology (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
