
Abstract
Postmortem interval (PMI) evaluation remains a challenge in the forensic community due to the lack of efficient methods. Studies have focused on chemical analysis of biofluids for PMI estimation; however, no reports using spectroscopic methods in pericardial fluid (PF) are available. In this study, Fourier transform infrared (FTIR) spectroscopy with attenuated total reflectance (ATR) accessory was applied to collect comprehensive biochemical information from rabbit PF at different PMIs. The PMI-dependent spectral signature was determined by two-dimensional (2D) correlation analysis. The partial least square (PLS) and nu-support vector machine (nu-SVM) models were then established based on the acquired spectral dataset. Spectral variables associated with amide I, amide II, COO−, C-H bending, and C-O or C-OH vibrations arising from proteins, polypeptides, amino acids and carbohydrates, respectively, were susceptible to PMI in 2D correlation analysis. Moreover, the nu-SVM model appeared to achieve a more satisfactory prediction than the PLS model in calibration; the reliability of both models was determined in an external validation set. The study shows the possibility of application of ATR-FTIR methods in postmortem interval estimation using PF samples.
Similar content being viewed by others

Introduction
Postmortem interval (PMI) evaluation remains a challenge in the forensic community because routine methods rely on subjective evaluation of body signs alone during the early phase (usually within 24 h postmortem), including algor mortis, livor mortis, rigor mortis distribution, and corneal turbidity1. In recent years, an increasing number of investigations have focused on postmortem chemical changes in biofluids, especially the vitreous humor and blood2,3, to identify biomarkers for PMI estimation, since they are readily available at crime scenes or during autopsy. There is ample evidence that multiple components in pericardial fluid (PF), including heart-specific proteins (cardiac troponin and creatine kinase MB), mRNAs, and electrolytes (Ca2+ and Mg2+), may be used to determine specific causes of death and elucidate the underlying mechanisms4,5,6. However, the potential of PF as a medium for PMI determination has not been documented sufficiently. Only a few studies indicate that electrolytes in PF tend to be used as parameters for PMI estimation. For instances, Balasooriya et.al showed that changes in K+, phosphates, and Na+ concentrations are significantly correlated with PMI7. Subsequently, Dalbir et al. established mathematical models based on electrolytic parameters for PMI prediction in independent samples8. Nevertheless, limited variables in PF are taken into account in the above studies; in addition, there is no evidence that other substances could contribute to sequential postmortem changes.
Fourier transform infrared (FTIR) spectroscopy is a powerful analytical tool for identifying chemical constituents and elucidating compound structures in various forms in real-world samples according to the vibrational modes of their molecular functional groups9,10. FTIR has the capacity to perform global assessment of components found in samples with no need of sample preparation, which is practically impossible with other routine analytical approaches. In forensic investigations, FTIR has been extensively utilized in multiple evidence-based cases at a crime scene, including questioned documents11, banknotes12, paints13, fibers14, hair15 and gunshot residues16. Alternatively, the feasibility of FTIR for chemically analyzing biological specimens has been demonstrated by other studies; indeed, multiple macromolecules, such as proteins, lipids, carbohydrates, and nucleic acids, can be monitored simultaneously in an FTIR spectrum based on their unique infrared absorption frequencies17,18. However, due to the complexity and heterogeneity of biological systems, a variety of data processing methods have emerged to interpret and select spectral features. In this context, two-dimensional (2D) correlation analysis is commonly used to uncover overlapped bands and discriminate very complex mixtures under the conditions of external perturbations, such as time, temperature, concentration and oxidation19,20,21,22,23. Moreover, a combination of FTIR spectroscopy and chemometric methods, including partial least square (PLS) and support vector machine (SVM) models, can convert the characteristic spectral pattern into a classifier or discriminator for automatic classification and prediction among different sample categories24,25.
In our research team, much efforts have been devoted to characterizing postmortem changes in biological samples by FTIR spectroscopy. We found that some spectral parameters, e.g. peak intensities and areas, are correlated with PMI in different tissues26,27. Recently, PMI groups of the rabbit plasma are successfully distinguished by FTIR spectroscopy coupled with PLS models28. The present study primarily focused on PF due to its advantages. For instance, large amounts of PF are easily obtained in contrast to VH; meanwhile, PF is less susceptible to microbial contamination and bacterial degradation compared with blood samples. To the best of our knowledge, this is the first study of PMI estimation based on infrared spectroscopic analysis of PF.
Materials and Methods
Animal model
A total of 99 male Japanese rabbits (6 months; 2.5–2.8 kg) were purchased from the animal center of Xian Jiaotong University. They were socially housed under a 12 h light/dark cycle with food and water ad libitum. The animal experiments were approved by the Committee of Laboratory Care and Use of Xian Jiaotong University. All methods were performed in accordance with the relevant guidelines and regulations outlined by the Committee of Laboratory Care and Use of Xian Jiaotong University. The rabbits were sacrificed by air injection through the ear-rim vein, and carcasses were placed in isolated chambers at a constant temperature of 25 °C. PF samples were harvested from the pericardium using sterile syringe needles within 48 h postmortem at 6 h intervals (11 rabbits per time point). The samples were then immediately submitted to centrifugation at 14000 rpm for 10 minutes to eliminate particle matters, which may cause Mie-type scattering. The supernatants were obtained and snap frozen in liquid nitrogen until use for FTIR analysis. The animals were randomly divided into calibration (8 rabbits per group) and validation (3 rabbits per group) groups.
FTIR measurements
Spectroscopic measurements were performed on a Nicolet IS 50 FTIR spectrometer(Thermo Scientific Fisher, USA) coupled with an ATR accessory (Smart Orbit Diamond, Thermo Scientific Fisher, USA). When an infrared beam is directed onto the ATR diamond crystal with a high refractive index, the generated evanescent waves penetrate a few microns on the sample surface and are subsequently attenuated or altered due to energy absorption. ATR-FTIR measures such energy variation for selected wavelengths, and produces corresponding infrared spectra. Peak intensity and position in an infrared spectrum are primarily dependent upon global vibrational modes of molecular functional groups in a given sample. In this study, the laboratory environment was kept at a temperature of 37 °C, with a relative humidity below 20%, in order to remove atmospheric water vapor as much as possible. Before FTIR measurements, approximately 100 μL of the thawed sample was shaken on a vortex mixer for 30 s and mixed with a micropipettor. Next, a sample aliquot (1 μL) was carefully deposited on the ATR diamond window and sufficiently dried with an air dryer. Spectra were collected at frequencies ranging from 1800 to 900 cm−1, with a resolution of 4 cm−1 and 32 scans. Background spectra collected on blank ATR spectra were automatically subtracted. For each sample, nine replicates were automatically averaged to produce a spectrum in order to eliminate loading errors.
Two-dimensional (2D) correlation analysis
All FTIR spectra in each PMI group were averaged. Average spectra in all groups were normalized by SNV and analyzed by the 2Dshige software package (Shigeaki Morita, Osaka Electro-Communication University, Japan; version 1.3).
Chemometrics
PLS and nu-SVM regression models were established with MATLAB R2014a (MathWorks, USA). Spectral datasets were preprocessed by SNV and second derivatives (25 points smoothing) within a frequency window of 1800–900 cm−1. The predictor X corresponded to the matrix of spectral intensity while the response variable Y was associated with PMI values. To reduce computational complexity in establishing a nu-SVM model, the dimensions of preprocessed spectra were reduced to 8 latent factors by principal component analysis (PCA). This method can transform a high dimensional dataset into a lower dimensional orthogonal feature set while retaining maximum information from the original high dimension dataset29,30. In this study, these 8 latent factors explained rough 98% of the variance. The calibration dataset was used to establish mathematical models. Their reliability was evaluated by 8-fold cross-validation and a permutation test to avoid overfitting, which usually renders models impractical in predicting independent samples accurately. In 8-fold cross-validation, the calibration dataset was divided into 8 equal sized sub-datasets, each of which contained spectra from 9 PMI groups. Of the 8 sub-datasets, one was retained as the test dataset, and spectral categories in this sub-dataset were predicted by the model established using the remaining sub-datasets. This process was repeated 8 times, and the determination coefficient (R2) and root-mean-square error of cross-validation (RMSECV) were assessed each time; these parameters represented the goodness of fitting between actual and predictive PMI values, and the global predictive error, respectively. Performances of the PLS and nu-SVM models were compared by unpaired t-test based on R2 and RMSECV, using Prizm 5.0 (GraphPad Software Inc., La Jolla, CA). P < 0.05 was considered statistically significant. Data were expressed as mean ± standard deviation (SD). In the next step, the established PLS and nu-SVM models were used to estimate PMI values in the validation group. Determination coefficient (Q2) and root-mean-square of prediction (RMSEP) values were also calculated to evaluate the generalization of the above models.
Results and Discussion
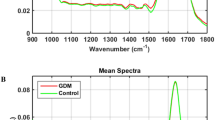
Figure 1 shows a comparison of average spectra with SNV normalization from 1800–900 cm−1 among different PMI groups; the absorption bands were mainly associated with proteins, lipids, nucleic acids, and carbohydrates. According to previous studies29,30,31,32,33,34, molecule assignments are summarized in Table 1. The two most prominent peaks were related to proteins, including a band at around 1650 cm−1 arising from amide I (mostly the C=O stretching vibrations of the peptide back bone) and a band at around 1540 cm−1 assigned to amide II (N-H bending coupled with C-N stretching). Both bands are highly sensitive to conformational changes, and several absorption peaks related to protein secondary structures contribute to the peak shapes of amide I and II bands. The band at around 1453 cm−1 originated from asymmetric and symmetric C-H bending modes of proteins, while that at 1398 cm−1 resulted from COO− vibrations of fatty acids, amino acids and polypeptides. In the frequency range of 1200–900 cm−1, the band at 1078 cm−1 was assigned to symmetric phosphate (vsPO2 −) and C-O stretching modes of nucleic acids and carbohydrates, respectively, while those at around 1033 and 926 cm−1 resulted from C-O or C-OH vibrations of carbohydrates. In this study, vibrations by fatty and nucleic acids are negligible because the PF contains only low levels of both macromolecule types; thus, their functional groups are not detected by ATR-FTIR spectroscopy. Although multiple substances can be identified globally in spectral profiles, PMI groups cannot be distinguished based only on these spectra.

A comparison of average spectra with SNV normalization among PMI groups from 0 to 48 h postmortem.
Minor differences in spectra among PMI groups were elucidated by 2D correlation analysis. The latter method provides a robust analysis of kinetic changes in spectral data resulting from external perturbation such as temperature, concentration and oxidation, and determines whether spectral changes are correlated as well as the order of chemical changes in samples. In this study, the external perturbation was biochemical changes in the PF with PMI development. The results of 2D correlation analysis showed two types of correlation spectra, including synchronous (Φ (ν1, ν2)) and asynchronous (Ψ (ν1, ν2)) spectra (Fig. 2). In synchronous spectra (Fig. 2A), the auto-peaks at the diagonal line corresponded to the autocorrelation function of spectral intensity variations due to postmortem disturbance. The stronger the intensities of such peaks, the more sensitive they are to postmortem changes. The cross-peaks at the non-diagonal line provided information on relative correlations between pairs of spectral variables; positive features (red) were in the same direction, and negative (blue) ones in the opposite direction. In contrast, asynchronous spectra (Fig. 2B) showed the sequence of kinetic changes, with cross-peaks corresponding to counterparts in the synchronous spectral map. According to Noda’s rules35, when cross-peak signals are the same for both synchronous and asynchronous maps, intensity changes of spectral variables on the x-axis occur before those on the y-axis, and vice versa.

The results of 2D correlation analysis include synchronous (A) and asynchronous spectral maps (B).
The results of 2D correlation analysis are summarized in Table 2. The most sensitive variables were mainly associated with proteins as strongest auto-peaks were found at 1656, 1581, and 1517 cm−1, all of which represent various protein secondary structures in the amide I and II structures. A broad auto-peak was found at around 1324 cm−1, involving amide III of proteins as well as COO− vibration from amino acids and polypeptides, while a band at around 1089 cm−1 corresponded to C-O or C-OH vibrations from carbohydrates. These findings demonstrated that spectral changes at 1656, 1517, and 1324 cm−1 were found simultaneously before those at 1581 and 1089 cm−1, but chemical changes in both stages showed no significant correlation with PMI progression. In the early stage, the band at 1656 cm−1 is considered one of the characteristic absorption peaks of blood cells36. We assume that postmortem infiltration of hemoglobin and/or other proteins with similar structures into the PF may be responsible for such signal, resulting in color change of the PF from clear to dark red. The bands at around 1517 and 1324 cm−1, both of which had an opposite variation direction, reflected the process of protein degradation into various amino acids and polypeptides. The spectral variations at around 1581 (from proteins) and 1089 cm−1 (from carbohydrates) likely derived from specific glycoproteins leaked into the PF as the biological barriers collapse thoroughly at the later stage.
In the next step, chemometrics was employed to estimate PMI according to the FTIR spectral dataset. The PLS algorithm can extract principal components (referred to as latent factors) simultaneously from the predictor X and the response variable Y to construct a predictive model. Figure 3A demonstrates that the PLS model using 7 latent factors yielded a relatively satisfactory result (R2 = 0.97 ± 0.0067; RMSECV = 2.54 ± 0.45) in 8-fold cross-validation. Furthermore, this model was interpreted by calculating the variable importance in projection (VIP) for all spectral variables, the weighted sum of squares of the PLS weights37. Predictors with VIP values above 1.0 were considered influential variables for distinguishing PMI groups. The larger the VIP value for each variable, the more important the variable to the PLS model. In Fig. 3B, the main influential variables arose from proteins and related degradation products (including Amide I, Amide II, C-H bending and COO− vibrations), followed by C-O or C-OH vibrations from carbohydrates. This finding further highlights the importance of protein degradation in the PF for PMI estimation.

The cross-validation results of the PLS model using spectral variables within 1800–900 cm−1. (A) The regression plot between the predicted and actual PMI. The black line represents the reference line where the predicted PMI scores are closer to it, the higher fitting of goodness will be. (B) The plot of VIP scores displays the contribution of the spectral variables to the distinction in the PLS model. The variables with VIP scores above 1.0 (marked by a red dot line) are considered most significant, and their assignments are symbolized.
In Fig. 4A, the nu- SVM model achieved a better prediction with higher R2 value (0.98 ± 0.0082) and lower RMSECV (2.38 ± 0.42) compared with the PLS model (R2, P < 0.05; RMSECV, P < 0.05). This may be due to the ability of the nu-SVM model to avoid difficulties of using linear functions in high dimensional feature space. Indeed, nu-SVM regression introduces the new penalty parameter nu, which was set to 0.02 in this study. This parameter controls the number of support vectors and training errors. In SVM regression, only support vectors were used for the final PMI estimation. A Radial Basis Function (RBF) kernel with parameter cost and gamma was selected for non-linear transformation that maps observations into a high-dimensional space. The parameter gramma is a regulation constant that affects the generalization performance of the nu-SVM model, while cost refers to the cost factor, which controls the balance between calibration errors and model complexity. The best combination of the parameters gramma and cost was determined according to the minimal predictive error of cross-validation in the form of a two-dimensional grid search (Fig. 4B).

The cross-validation results of the nu-SVM model using spectral variables within 1800–900 cm−1. (A) The regression plot between the predicted and actual PMI. The black line represents the reference line. (B) The optimal combination of nu-SVM parameters, including gramma and cost is marked by the position of the red sign “X” where the minimum error can be obtained.
Figure 5 shows the predicted results in the validation group using the PLS and nu-SVM models, respectively. The Q2 and RMSEP values of both models were generally close to their R2 and RMSCV, respectively. Moreover, a permutation test was performed to assess whether the established models were over-fitted by randomly permuting class labels and refitting new models with the same number of components as the original ones. Well fitted and meaningful models have significantly higher R2 and Q2 values than permuted data. In Fig. 6, the y-intercept values of the regression line were 0.08 and −0.1 for R2 for Q2, respectively, in the PLS model; 0.08 and −0.09, respectively, were obtained in the nu-SVM model. Both tests suggested that the PLS and nu-SVM models were reliable in predicting PMI in independent samples.

The prediction results of the PLS (A) and nu-SVM (B) regression models in an independent dataset which is not included in the calibration group.

The PLS and nu-SVM models are validated by 50 random permutation tests as shown in (A) and (B) respectively, whose results indicate both models were acceptable.
As reported previously, some metabolites and proteins in biological samples could be considered biomarkers for PMI estimation. For example, studies have shown that the concentrations of certain metabolites in plasma and muscle samples from rats are highly correlated with PMI38,39. Pittner and colleagues have identified degradation profiles of candidate proteins in human muscle tissues for delimiting certain periods of time postmortem, even under heterogeneous conditions such as variations in ambient temperature, age, sex, and cause of death40. Along with PF advantages, the current spectroscopic study suggests that the PF may be a potential medium for PMI estimation in forensic practice. Given limitations of ATR-FTIR spectroscopy, omics approaches, such as metabolomics and proteomics, are invaluable in identifying specific substances in the PF, which can greatly contribute to the discovery of new biomarkers for PMI estimation.
Conclusion
In this work, ATR-FTIR spectroscopy was applied for the first time to acquire biochemical information in PF samples from rabbits within 48 h postmortem. Along with 2D correlation analysis, spectroscopic findings suggested that PMI-dependent changes in the PF almost solely derive from molecular vibrations of proteins, polypeptides, and amino acids, and are associated with time-ordered protein degradation. Moreover, the nu-SVM and PLS models were established to predict PMI, with the SVM model yielding a more satisfactory prediction according to 8-fold-cross-validation. Overall, the present findings demonstrate that ATIR-FTIR spectroscopy combined with chemometrics may be used to determine PMI, offering a promising new approach in the forensic field.
References
Li, C. et al. Research progress in the estimation of the postmortem interval by Chinese forensic scholars. Forensic Sciences Research 1, 3–13 (2016).
Passos, M. L. et al. Estimation of postmortem interval by hypoxanthine and potassium evaluation in vitreous humor with a sequential injection system. Talanta 79, 1094–1099, https://doi.org/10.1016/j.talanta.2009.02.054 (2009).
Costa, I. et al. Promising blood-derived biomarkers for estimation of the postmortem interval. Toxicology Research 4, 1443–1452 (2015).
Remmer, S., Kuudeberg, A., Tõnisson, M., Lepik, D. & Väli, M. Cardiac troponin T in forensic autopsy cases. Forensic Science International 233, 154–157, https://doi.org/10.1016/j.forsciint.2013.09.010 (2013).
Deliligka, A. et al. Potential use of pericardial cTnI, Mg2+ and Ca2+ in the forensic investigation of seawater drowning in Greece: An initial assessment. Legal Medicine 23, 30–33, https://doi.org/10.1016/j.legalmed.2016.09.003 (2016).
Gonzálezherrera, L., Valenzuela, A., Marchal, J. A., Lorente, J. A. & Villanueva, E. Studies on RNA integrity and gene expression in human myocardial tissue, pericardial fluid and blood, and its postmortem stability. Forensic Science International 232, 218–228, https://doi.org/10.1016/j.forsciint.2013.08.001 (2013).
St Balasooriya, B. A., Hill, C. A. & Williams, A. R. The biochemical changes in pericardial fluid after death. An investigation of the relationship between the time since death and the rise or fall in electrolyte and enzyme concentrations and their possible usefulness in determining the time of death. Forensic Science International 26, 93–102 (1984).
Singh, D., Prashad, R., Sharma, S. K. & Pandey, A. N. Estimation of postmortem interval from human pericardial fluid electrolytes concentrations in Chandigarh zone of India: log transformed linear regression model. Legal Medicine 8, 279–287, https://doi.org/10.1016/j.legalmed.2006.06.004 (2006).
Zhang, J. et al. Characterization of protein alterations in damaged axons in the brainstem following traumatic brain injury using fourier transform infrared microspectroscopy: a preliminary study. Journal of Forensic Sciences 60, 759–763, https://doi.org/10.1111/1556-4029.12743 (2015).
Zhang, J. et al. Chemical Analysis in the Corpus Callosum Following Traumatic Axonal Injury using Fourier Transform Infrared Microspectroscopy: A Pilot Study. Journal of Forensic Sciences 60, 3268–3275, https://doi.org/10.1111/1556-4029.12871 (2015).
Zięba-Palus, J. & Kunicki, M. Application of the micro-FTIR spectroscopy, Raman spectroscopy and XRF method examination of inks. Forensic Science International 158, 164–172, https://doi.org/10.1016/j.forsciint.2005.04.044 (2006).
Sonnex, E., Almond, M. J., Baum, J. V. & Bond, J. W. Identification of forged Bank of England £20 banknotes using IR spectroscopy. Spectrochimica Acta Part A Molecular & Biomolecular Spectroscopy 118, 1158–1163, https://doi.org/10.1016/j.saa.2013.09.115 (2014).
Lambert, D., Muehlethaler, C., Esseiva, P. & Massonnet, G. Combining spectroscopic data in the forensic analysis of paint: Application of a multiblock technique as chemometric tool. Forensic Science International 263, 39–47, https://doi.org/10.1016/j.forsciint.2016.03.049 (2016).
Espinoza, E., Przybyla, J. & Cox, R. Analysis of fiber blends using horizontal attenuated total reflection Fourier transform infrared and discriminant analysis. Applied Spectroscopy 60, 386–391, https://doi.org/10.1366/000370206776593609 (2006).
Manheim, J., Doty, K. C., Mclaughlin, G. & Lednev, I. K. Forensic Hair Differentiation Using Attenuated Total Reflection Fourier Transform Infrared (ATR FT-IR) Spectroscopy. Applied Spectroscopy 70, 1109–1117, https://doi.org/10.1177/0003702816652321 (2016).
Bueno, J., Sikirzhytski, V. & Lednev, I. K. Attenuated Total Reflectance-FT-IR Spectroscopy for Gunshot Residue Analysis: Potential for Ammunition Determination. Analytical Chemistry 85, 7287–7294, https://doi.org/10.1021/ac4011843 (2013).
Theophilou, G., Lima, K. M., Martin-Hirsch, P. L., Stringfellow, H. F. & Martin, F. L. ATR-FTIR spectroscopy coupled with chemometric analysis discriminates normal, borderline and malignant ovarian tissue: classifying subtypes of human cancer. Analyst 141, 585–594, https://doi.org/10.1039/c5an00939a (2015).
Kozicki, M. An attenuated total reflection (ATR) and Raman spectroscopic investigation into the effects of chloroquine on Plasmodium falciparum-infected red blood cells. Analyst 140, 599–602, https://doi.org/10.1039/c4an01904k (2015).
Czarnecki, M. A., Ozaki, H. M., Y. Suzuki, M. & Iwahashi, M. Resolution Enhancement and Band Assignments for the First Overtone of OH Stretching Modes of Butanols by Two-Dimensional Near-Infrared Correlation Spectroscopy. 2. Thermal Dynamics of Hydrogen Bonding in n- and tert-Butyl Alcohol in the Pure Liquid States. Journal of Physical Chemistry A 102, 9117–9123 (1998).
Muik, B., Lendl, B., Molinadiaz, A., Valcarcel, M. & Ayoracañada, M. J. Two-dimensional correlation spectroscopy and multivariate curve resolution for the study of lipid oxidation in edible oils monitored by FTIR and FT-Raman spectroscopy. Analytica Chimica Acta 593, 54–67, https://doi.org/10.1016/j.aca.2007.04.050 (2007).
Yamaguchi, Y., Nge, T. T., Takemura, A., Hori, N. & Ono, H. Characterization of uniaxially aligned chitin film by 2D FT-IR spectroscopy. Biomacromolecules 6, 1941–1947 (2005).
Wang, Y. et al. Two-Dimensional Fourier Transform Near-Infrared Spectroscopy Study of Heat Denaturation of Ovalbumin in Aqueous Solutions. Journal of Physical Chemistry B 102, 629–633 (1998).
Tang, B., Wu, P. & Siesler, H. W. In situ study of diffusion and interaction of water and mono- or divalent anions in a positively charged membrane using two-dimensional correlation FT-IR/attenuated total reflection spectroscopy. Journal of Physical Chemistry B 112, 2880–2887, https://doi.org/10.1021/jp075729 (2008).
Lu, Y., Du, C., Yu, C. & Zhou, J. Classifying rapeseed varieties using Fourier transform infrared photoacoustic spectroscopy (FTIR-PAS). Computers & Electronics in Agriculture 107, 58–63 (2014).
Mistek, E. & Lednev, I. K. Identification of species’ blood by attenuated total reflection (ATR) Fourier transform infrared (FT-IR) spectroscopy. Analytical and Bioanalytical Chemistry 407, 7435–7442, https://doi.org/10.1007/s00216-015-8909-6 (2015).
Ke, Y., Li, Y. & Wang, Z. Y. The Changes of Fourier Transform Infrared Spectrum in Rat Brain. Journal of Forensic Sciences 57, 794–798, https://doi.org/10.1111/j.1556-4029.2011.02036.x. (2012).
Huang, P. et al. Analysis of postmortem metabolic changes in rat kidney cortex using Fourier transform infrared spectroscopy. Spectroscopy 22, 21–31 (2008).
Zhang, J. et al. Characterization of postmortem biochemical changes in rabbit plasma using ATR-FTIR combined with chemometrics: A preliminary study. Spectrochimica Acta Part A Molecular & Biomolecular Spectroscopy 173, 733–739, https://doi.org/10.1016/j.saa.2016.10.041 (2016).
Nunes, K. M., Andrade, M. V., Santos Filho, A. M., Lasmar, M. C. & Sena, M. M. Detection and characterisation of frauds in bovine meat in natura by non-meat ingredient additions using data fusion of chemical parameters and ATR-FTIR spectroscopy. Food Chemistry 205, 14–22, https://doi.org/10.1016/j.foodchem.2016.02.158 (2016).
Martin-Mata, J. et al. Thermal and spectroscopic analysis of organic matter degradation and humification during composting of pig slurry in different scenarios. Environmental Science & Pollution Research 23, 17357–17369, https://doi.org/10.1007/s11356-016-6838-3 (2016).
Lopes, J. et al. FTIR and Raman Spectroscopy Applied to Dementia Diagnosis Through Analysis of Biological Fluids. Journal of Alzheimers Disease 52, 801–812 (2016).
Talpur, M. Y. et al. Application of multivariate chemometric techniques for simultaneous determination of five parameters of cottonseed oil by single bounce attenuated total reflectance Fourier transform infrared spectroscopy. Talanta 129, 473–480, https://doi.org/10.1016/j.talanta.2014.04.002 (2014).
Beekes, M., Lasch, P. & Naumann, D. Analytical applications of Fourier transform-infrared (FT-IR) spectroscopy in microbiology and prion research. Veterinary Microbiology 123, 305–319, https://doi.org/10.1016/j.vetmic.2007.04.010 (2007).
Kretlow, A. et al. FTIR-microspectroscopy of prion-infected nervous tissue. Biochimica Et Biophysica Acta 1758, 948–959, https://doi.org/10.1016/j.bbamem.2006.05.026 (2006).
Lu, R. et al. Probing the secondary structure of bovine serum albumin during heat-induced denaturation using mid-infrared fiberoptic sensors. Analyst 140, 765–770 (2015).
Webster, G. T. et al. Discriminating the intraerythrocytic lifecycle stages of the malaria parasite using synchrotron FT-IR microspectroscopy and an artificial neural network. Analytical Chemistry 81, 2516–2524 (2009).
Chong, I. G. & Jun, C. H. Performance of some variable selection methods when multicollinearity is present. Chemometrics & Intelligent Laboratory Systems 78, 103–112 (2005).
Sato, T. et al. A preliminary study on postmortem interval estimation of suffocated rats by GC-MS/MS-based plasma metabolic profiling. Analytical & Bioanalytical Chemistry 407, 3659–3665, https://doi.org/10.1007/s00216-015-8584-7 (2015).
Kaszynski, R. H. et al. Postmortem interval estimation: a novel approach utilizing gas chromatography/mass spectrometry-based biochemical profiling. Analytical & Bioanalytical Chemistry 408, 3103–3112, https://doi.org/10.1007/s00216-016-9355-9 (2016).
Pittner, S. et al. Postmortem muscle protein degradation in humans as a tool for PMI delimitation. International Journal of Legal Medicine 130, 1547–1555, https://doi.org/10.1007/s00414-016-1349-9 (2016).
Acknowledgements
The research is funded by Shanghai Key Laboratory of Forensic Medicine (No. KF1601) and the National Science Foundation of China (No. 81730056, 81671869, 81273339, 81722027) and the Science and Technology Committee of Shanghai Municipality (17DZ2273200/16DZ2290900)
Author information
Authors and Affiliations
Contributions
Ji Zhang and Bing Li wrote the main manuscript and prepared all figures. Yijiu Chen, Ping Huang and Zhenyuan Wang oversaw the project and assisted with the writing of the manuscript. Other authors designed and performed the experiments. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, J., Li, B., Wang, Q. et al. Application of Fourier transform infrared spectroscopy with chemometrics on postmortem interval estimation based on pericardial fluids. Sci Rep 7, 18013 (2017). https://doi.org/10.1038/s41598-017-18228-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-18228-7
This article is cited by
-
Metabolomics investigation of post-mortem human pericardial fluid
International Journal of Legal Medicine (2023)
-
Attenuated total reflection-Fourier transform infrared spectroscopy: a universal analytical technique with promising applications in forensic analyses
International Journal of Legal Medicine (2022)
-
A preliminary study on early postmortem submersion interval (PMSI) estimation and cause-of-death discrimination based on nontargeted metabolomics and machine learning algorithms
International Journal of Legal Medicine (2022)
-
Extraction and Characterization of Nanocellulose from Raw Oil Palm Leaves (Elaeis guineensis)
Arabian Journal for Science and Engineering (2020)
-
An investigation on annular cartilage samples for post-mortem interval estimation using Fourier transform infrared spectroscopy
Forensic Science, Medicine and Pathology (2019)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
